
Detecting and Isolating Adversarial Attacks Using Characteristics of the Surrogate Model Framework


Abstract
:1. Introduction
Work Motivation
- There are no well-established AA detection methods that attempt to analyze machine learning models during their operations that can work in a black-box scenario.
2. Related Work
2.1. Adversarial Attacks
2.2. Adversarial Defenses
- Reconstruction-based Methods: These techniques rely on reconstructing the input and comparing it with the original input to identify adversarial perturbations. One approach is to use autoencoder-based methods for input reconstruction [22]. This technique can be part of a larger detection framework, such as [23].
- Feature Squeezing: This technique can be used both for the detection of adversarial examples and for increasing the innate robustness of machine learning models. Since it reduces the search space available to an adversary by compressing the amount of expressiveness in the input, it makes all adversarial modifications more apparent thanks to the simplification of model inputs [24].
- Classifier-based Methods: These approaches involve training a separate classifier to discern between adversarial and legitimate inputs, such as Metzen et al.’s method using a trained auxiliary neural network [21]. Another example is a MagNet framework, which consists of both detector and reformer networks. Detector networks are used to classify examples as either normal or adversarial, by approximating the manifold of normal examples. The reformer network is then used to move adversarial examples towards the manifold of normal examples—resulting in the correct classification of adversarial examples with small perturbation [23].
- Adversarial Training: This technique aims to improve the model’s resilience against adversarial attacks by explicitly including adversarial examples in the training process. The underlying idea is to expose the model to these specially crafted deceptive inputs during training, forcing the model to learn from these examples and consequently enhancing its robustness. Goodfellow et al. proposed the concept in their pioneering work, thus adding a new dimension to the understanding of model generalization and resilience [12].
- Defensive Distillation: This technique involves training the model to provide softer output distributions rather than discrete class labels, thereby rendering the model’s decision boundaries smoother and less prone to adversarial perturbations. The distillation process increases the model’s resilience against adversarial attacks by reducing the effectiveness of small perturbations on the input. The technique was described in depth by Papernot et al. [25].
- Feature Squeezing: This technique aims to mitigate the risk of adversarial attacks by reducing the complexity of model inputs, effectively limiting the scope for adversarial manipulation. By squeezing or reducing the input data’s expressiveness, the technique narrows down the available search space that an adversary could exploit [24].
- Certified Defenses: These methods provide mathematical guarantees of a model’s robustness against adversarial attacks. Rather than solely relying on empirical assessments of model performance, these defenses offer a theoretical underpinning to ensure robustness, thus contributing to a more rigorous and reliable model defense. The core concept is to mathematically certify a region around each data point within which the model’s prediction remains consistent, hence making it robust against adversarial perturbations [26].
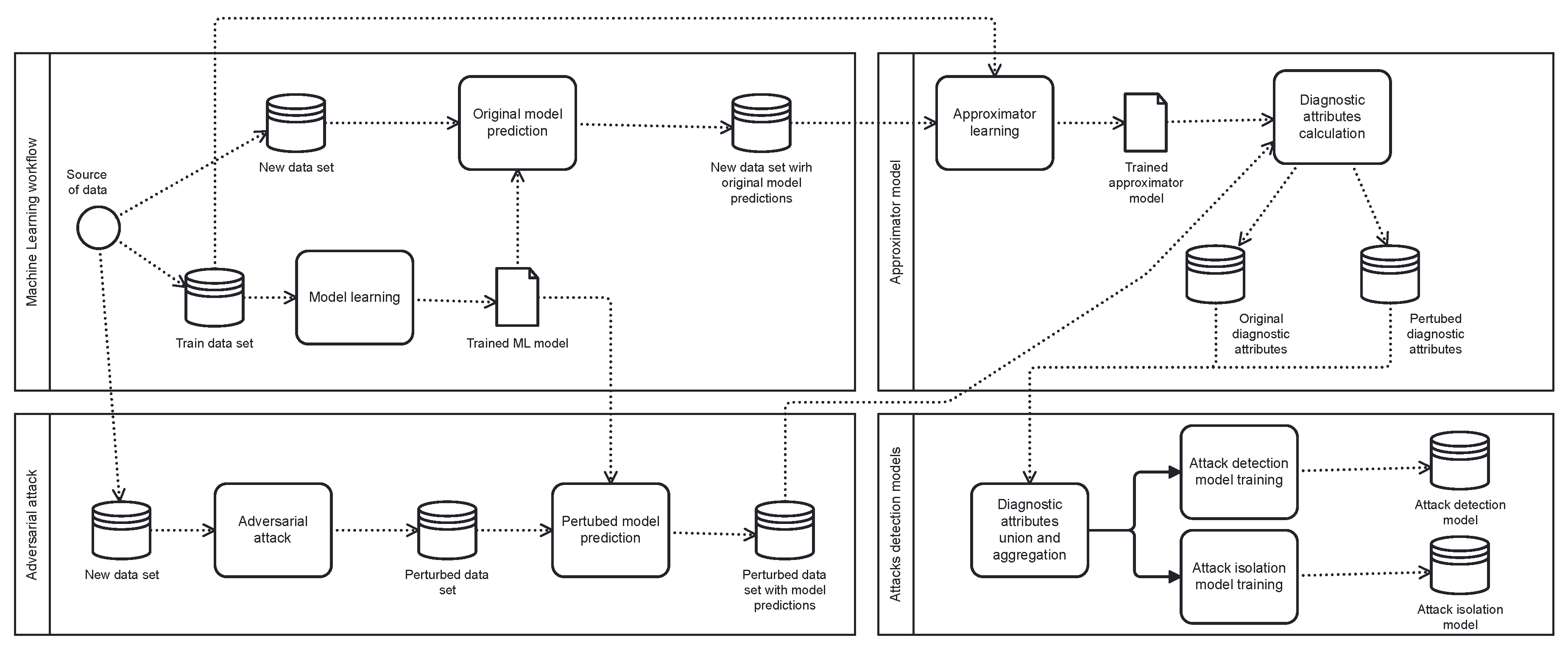
3. Methods
3.1. Attacks Detected
- Academic renown of the original publication and subsequent publications exploring each specific attack;
- Suitability to operate on tabular data;
- Attempt to hide their operations—perturbances introduced are minimally required for a successful attack;
- Having an available implementation code base.
- Initialization (Hop): A starting point for the adversarial example is identified, which lies on the opposite side of the decision boundary compared to the target input.
- Binary Search (Skip): A binary search strategy is implemented to bring the adversarial example closer to the decision boundary without crossing it.
- Gradient Estimation (Jump): By making small perturbations to the adversarial example and observing the model’s outputs, an approximation of the gradient at the decision boundary is estimated. This gradient information is then utilized to make a controlled jump that slightly crosses the decision boundary, making the adversarial example more effective.
3.2. Approximator Learning
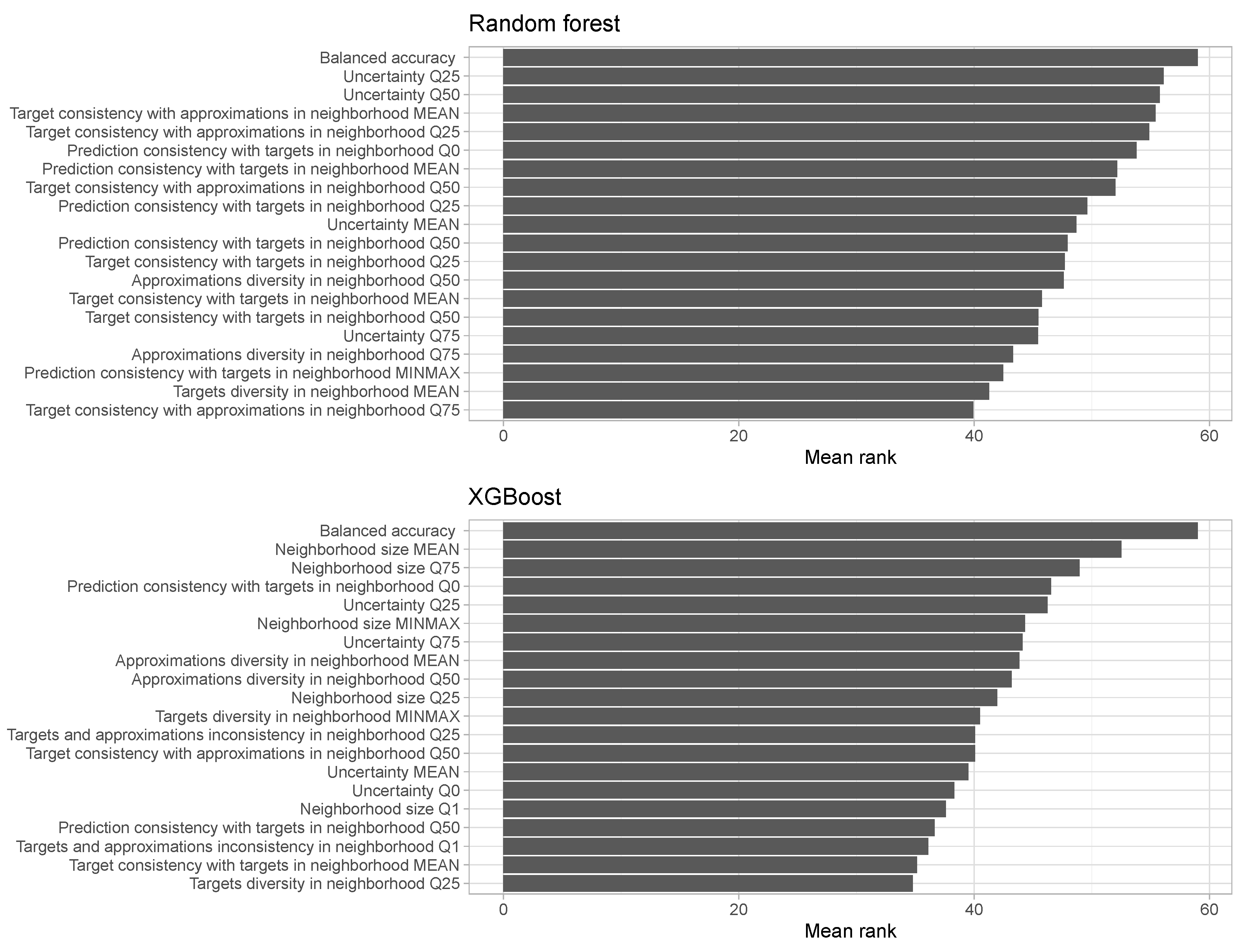
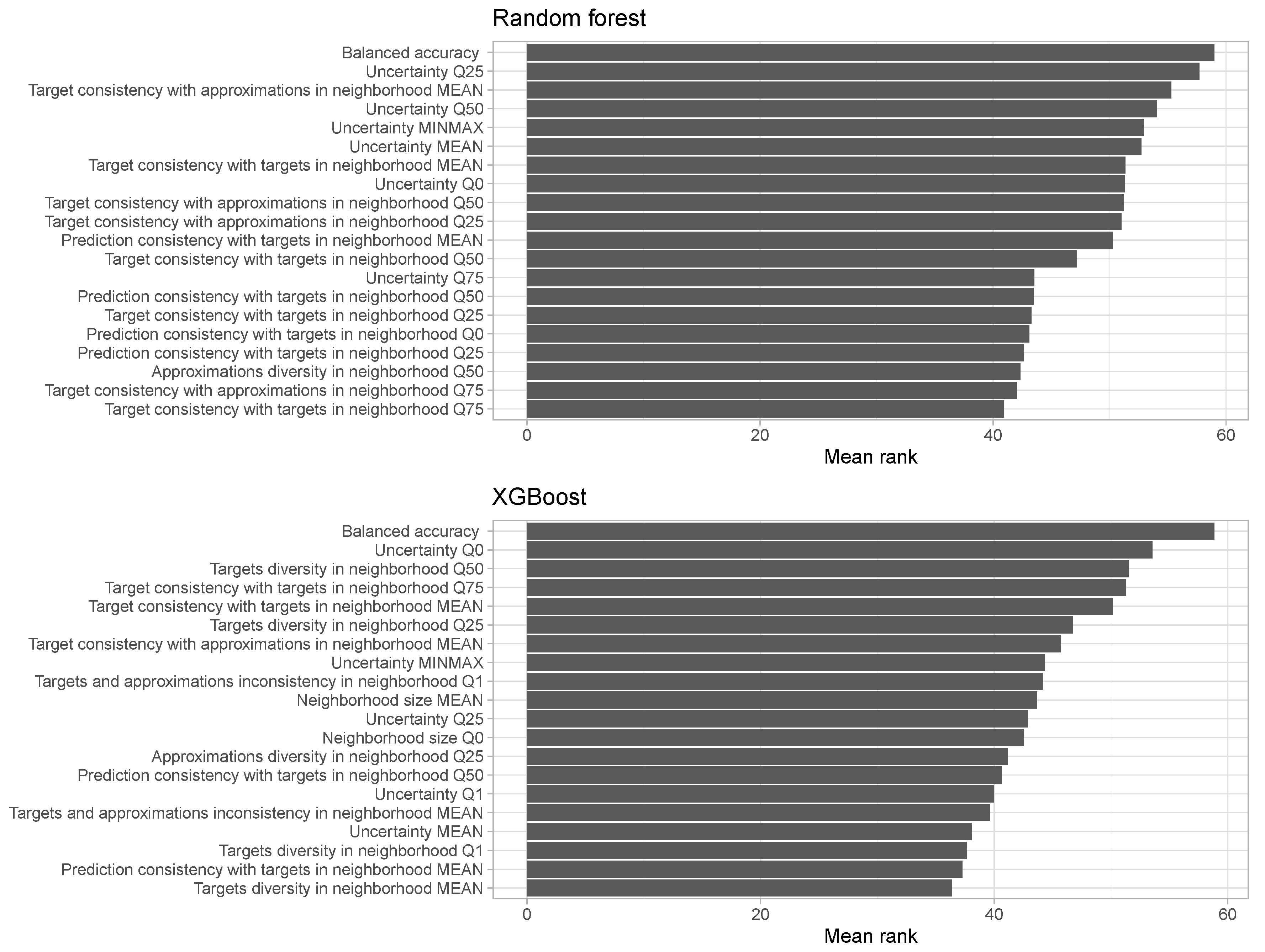
- Target consistency with approximations in the neighborhood—measures the consistency of the target of the diagnosed instance with the approximations from the neighborhood of this instance. It expresses how often values from are the same as .
- Prediction consistency with targets in the neighborhood—measures the consistency of the prediction of the diagnosed instance with the targets from the neighborhood of this instance. It expresses how often values from are the same as .
- Target consistency with targets in the neighborhood—measures the consistency of the target of the diagnosed instance with the targets from the neighborhood of this instance. It expresses how often values from agree with the class of x, i.e., .
- Targets and approximations inconsistency in the neighborhood—measures the inconsistency of targets and approximations in the neighborhood of the diagnosed instance. This attribute is calculated as , where is the ground truth target class of , and is the approximation of its probability.
- Targets diversity in the neighborhood—measures the diversity of targets in the neighborhood of the diagnosed instance in comparison to the diversity of targets calculated on the whole diagnosed data set. It is calculated as , where p is the prior probability distribution of decision classes and is the distribution of decision classes in the neighborhood of x.
- Approximations diversity in the neighborhood—measures the diversity of approximations in the neighborhood of the diagnosed instance in comparison to the diversity of approximations calculated on the whole diagnosed data set. It refers to , where is the distribution of the approximated predictions in .
- Uncertainty—we define a normalized entropy of a classification distribution as , where l is a number of classes. In a case when the prior is not uniform, we need to transform it by scaling the simplex space. Let us take the distribution norm of with respect to p as . It measures the distribution with the units of the prior distribution. Let us define a p-simplex off-centering as . Then we obtain the prior-off-centered normalized entropy , which, for the sake of simplicity, we will denote as , which is the prediction uncertainty of model M calculated for a diagnosed instance x.
- Neighborhood size—the number of instances in the neighborhood of the diagnosed instance.
4. Experiments
4.1. Data Preparation
4.2. Scenarios
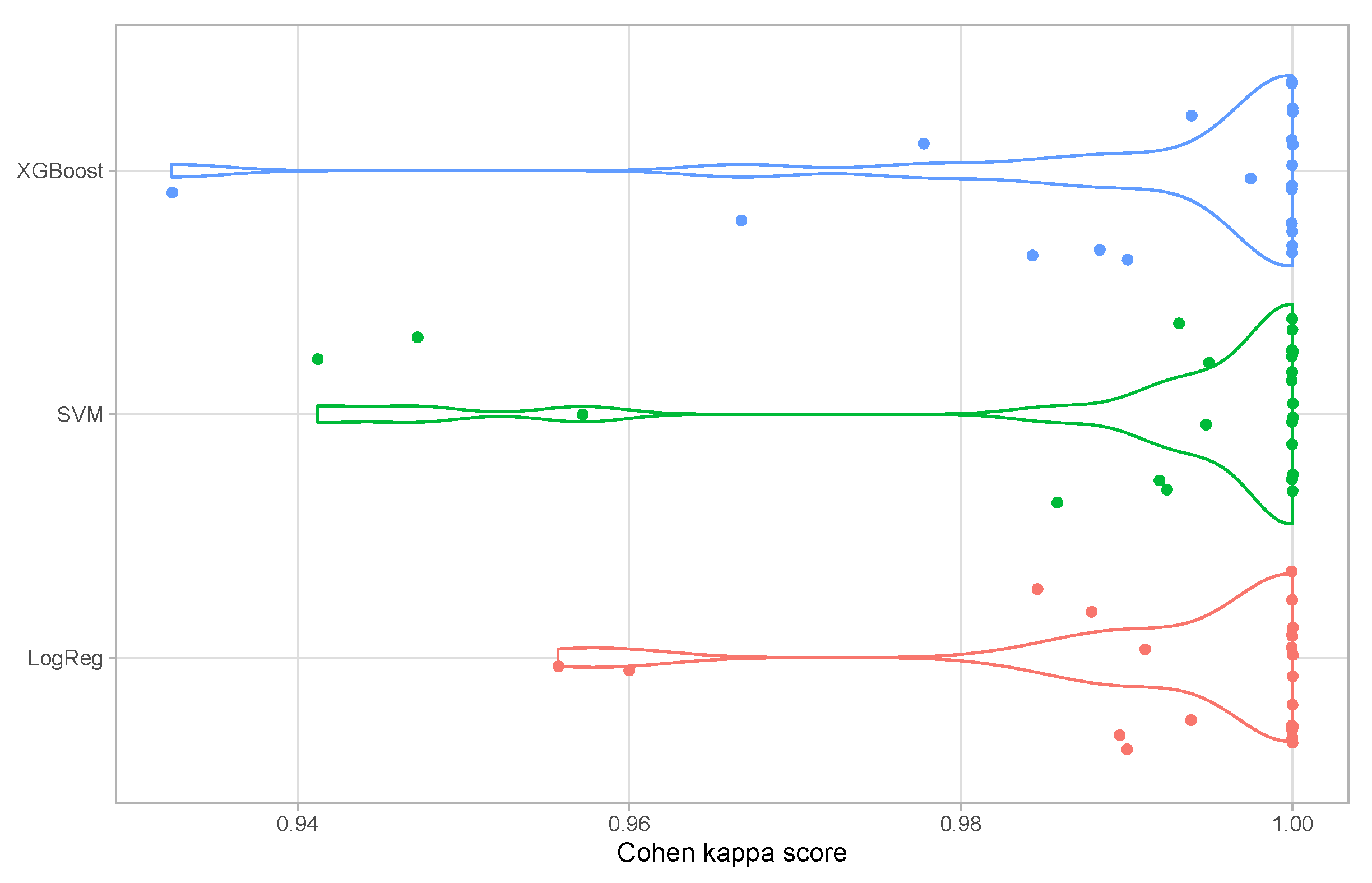
4.3. Attack Detection
4.4. Attack Isolation
5. Conclusions and Future Works
- Increasing the quality of classifiers, by training them on larger representations of known attack methods and data sets. New data sets and new adversarial examples will become available as a direct result of implementation activities performed by the QED Software company and will focus on real-life examples of attacks and data in attack-prone environments.
- Testing different hierarchical approaches to the classifier construction—chaining attack detection classifiers with attack identification ones.
- Combining the resulting classifiers with external input sources explaining changes in data characteristics. This includes methods for concept drift detection, anomaly detection, and expert reasoning.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical Black-Box Attacks against Machine Learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Liang, H.; He, E.; Zhao, Y.; Jia, Z.; Li, H. Adversarial Attack and Defense: A Survey. Electronics 2022, 11, 1283. [Google Scholar] [CrossRef]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. A survey on adversarial attacks and defences. CAAI Trans. Intell. Technol. 2021, 6, 25–45. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning About Data; Springer Science & Business Media: Dordrecht, The Netherlands, 1991. [Google Scholar]
- Skowron, A.; Polkowski, L. Rough Sets in Knowledge Discovery 1: BASIC Concepts; CRC Press: Berlin, Germany, 1998. [Google Scholar]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial Attacks and Defenses in Deep Learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Kireev, K.; Kulynych, B.; Troncoso, C. Adversarial Robustness for Tabular Data through Cost and Utility Awareness. In Proceedings of the NeurIPS ML Safety Workshop, Virtual, 9 December 2022. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Biggio, B.; Roli, F. Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 2154–2156. [Google Scholar] [CrossRef]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning Attacks against Support Vector Machines. In Proceedings of the 29th International Conference on International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; Omnipress: Madison, WI, USA, 2012; pp. 1467–1474. [Google Scholar]
- Barreno, M.; Nelson, B.; Joseph, A.D.; Tygar, J.D. The security of machine learning. Mach. Learn. 2010, 81, 121–148. [Google Scholar] [CrossRef]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. arXiv 2019, arXiv:1904.02144. [Google Scholar]
- Hashemi, M.; Fathi, A. PermuteAttack: Counterfactual Explanation of Machine Learning Credit Scorecards. arXiv 2020, arXiv:2008.10138. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Grosse, K.; Manoharan, P.; Papernot, N.; Backes, M.; Mcdaniel, P. On the (Statistical) Detection of Adversarial Examples. arXiv 2017, arXiv:1702.06280. [Google Scholar]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. Detecting adversarial perturbations with neural networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Li, T.; Wang, L.; Li, S.; Zhang, P.; Ju, X.; Yu, T.; Yang, W. Adversarial sample detection framework based on autoencoder. In Proceedings of the 2020 International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Bangkok, Thailand, 30 October–1 November 2020; pp. 241–245. [Google Scholar] [CrossRef]
- Meng, D.; Chen, H. MagNet: A Two-Pronged Defense against Adversarial Examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. arXiv 2018, arXiv:1704.01155. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar] [CrossRef]
- Cohen, J.; Rosenfeld, E.; Kolter, Z. Certified Adversarial Robustness via Randomized Smoothing. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 1310–1320. [Google Scholar]
- Janusz, A.; Zalewska, A.; Wawrowski, L.; Biczyk, P.; Ludziejewski, J.; Sikora, M.; Ślęzak, D. BrightBox—A rough set based technology for diagnosing mistakes of machine learning models. Appl. Soft Comput. 2023, 141, 110285. [Google Scholar] [CrossRef]
- Maszczyk, C.; Kozielski, M.; Sikora, M. Rule-based approximation of black-box classifiers for tabular data to generate global and local explanations. In Proceedings of the 2022 17th Conference on Computer Science and Intelligence Systems (FedCSIS), Sofia, Bulgaria, 4–7 September 2022; pp. 89–92. [Google Scholar]
- Henzel, J.; Tobiasz, J.; Kozielski, M.; Bach, M.; Foszner, P.; Gruca, A.; Kania, M.; Mika, J.; Papiez, A.; Werner, A.; et al. Screening support system based on patient survey data—Case study on classification of initial, locally collected COVID-19 data. Appl. Sci. 2021, 11, 10790. [Google Scholar] [CrossRef]
- Skowron, A.; Ślęzak, D. Rough Sets Turn 40: From Information Systems to Intelligent Systems. In Proceedings of the 17th Conference on Computer Science and Intelligence Systems, FedCSIS 2022, Sofia, Bulgaria, 4–7 September 2022; Volume 30, pp. 23–34. [Google Scholar] [CrossRef]
- Stawicki, S.; Ślęzak, D.; Janusz, A.; Widz, S. Decision Bireducts and Decision Reducts—A Comparison. Int. J. Approx. Reason. 2017, 84, 75–109. [Google Scholar] [CrossRef]
- Nicolae, M.I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.2.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set Name | Number of Instances | Number of Attributes | Number of Classes |
|---|---|---|---|
| Bioresponse | 3751 | 1776 | 2 |
| churn | 5000 | 20 | 2 |
| cmc | 2000 | 47 | 10 |
| cnae-9 | 1080 | 856 | 9 |
| dna | 3186 | 180 | 3 |
| har | 10,299 | 561 | 6 |
| madelon | 2600 | 500 | 2 |
| mfeat-factors | 2000 | 47 | 10 |
| mfeat-fourier | 2000 | 76 | 10 |
| mfeat-karhunen | 2000 | 47 | 10 |
| mfeat-zernike | 2000 | 47 | 10 |
| nomao | 34,465 | 118 | 2 |
| optdigits | 2000 | 47 | 10 |
| pendigits | 10,992 | 16 | 10 |
| phoneme | 5404 | 5 | 2 |
| qsar-biodeg | 1055 | 41 | 2 |
| satimage | 6430 | 36 | 6 |
| semeion | 1593 | 256 | 10 |
| spambase | 2000 | 47 | 10 |
| wall-robot-navigation | 5456 | 24 | 4 |
| wdbc | 569 | 30 | 2 |
| wilt | 4839 | 5 | 2 |
| Data Set | Model | Attack | Bacc | n_obs | Neigh_Size_Mean | Neigh_Size_q0 | ⋯ |
|---|---|---|---|---|---|---|---|
| Bioresponse | lin | hsj | 0.26 | 751.00 | 178.06 | 67.00 | ⋯ |
| Bioresponse | lin | org | 0.74 | 751.00 | 264.75 | 122.00 | ⋯ |
| Bioresponse | lin | per | 0.36 | 751.00 | 263.78 | 122.00 | ⋯ |
| Bioresponse | lin | zoo | 0.00 | 751.00 | 261.08 | 120.00 | ⋯ |
| Bioresponse | svm | hsj | 0.50 | 751.00 | 277.85 | 66.00 | ⋯ |
| Bioresponse | svm | org | 0.77 | 751.00 | 408.08 | 208.00 | ⋯ |
| Bioresponse | svm | per | 0.52 | 751.00 | 402.40 | 207.00 | ⋯ |
| Bioresponse | svm | zoo | 0.02 | 751.00 | 358.64 | 95.00 | ⋯ |
| Bioresponse | xgb | hsj | 0.22 | 751.00 | 178.99 | 77.00 | ⋯ |
| Bioresponse | xgb | org | 0.78 | 751.00 | 290.35 | 150.00 | ⋯ |
| Bioresponse | xgb | per | 0.31 | 751.00 | 285.49 | 151.00 | ⋯ |
| Bioresponse | xgb | zoo | 0.64 | 751.00 | 290.25 | 148.00 | ⋯ |
| churn | lin | hsj | 0.42 | 1000.00 | 9.57 | 2.00 | ⋯ |
| churn | lin | org | 0.58 | 1000.00 | 58.20 | 5.00 | ⋯ |
| churn | lin | per | 0.42 | 1000.00 | 25.49 | 4.00 | ⋯ |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| Scenario Name | Description | Application |
|---|---|---|
| 10-fold cross-validation | Cross-validation stratified by variable of interest | detection, isolation |
| one-data-set-out | One data set is treated as a test data set and the rest of data is a training data set | detection, isolation |
| one-model-out | Data for one model type is treated as a test data set and the rest of data is a training data set | detection, isolation |
| one-attack-out | Data for one attack type is treated as a test data set and the rest of data is a training data set | detection |
| Scenario Name | RF | XGB |
|---|---|---|
| 10-fold cross-validation | 0.9107 (0.1050) | 0.9557 (0.0679) |
| one-attack-out | 0.9495 (0.0437) | 0.9596 (0.0350) |
| one-data-set-out | 0.9015 (0.1599) | 0.9520 (0.1167) |
| one-model-out | 0.9364 (0.0441) | 0.9164 (0.0621) |
| Scenario Name | RF | XGB |
|---|---|---|
| 10-fold cross-validation | 0.6560 (0.1542) | 0.7625 (0.0961) |
| one-data-set-out | 0.7443 (0.2213) | 0.8030 (0.1512) |
| one-model-out | 0.7102 (0.1476) | 0.7216 (0.1379) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biczyk, P.; Wawrowski, Ł. Detecting and Isolating Adversarial Attacks Using Characteristics of the Surrogate Model Framework. Appl. Sci. 2023, 13, 9698. https://doi.org/10.3390/app13179698
Biczyk P, Wawrowski Ł. Detecting and Isolating Adversarial Attacks Using Characteristics of the Surrogate Model Framework. Applied Sciences. 2023; 13(17):9698. https://doi.org/10.3390/app13179698
Chicago/Turabian StyleBiczyk, Piotr, and Łukasz Wawrowski. 2023. "Detecting and Isolating Adversarial Attacks Using Characteristics of the Surrogate Model Framework" Applied Sciences 13, no. 17: 9698. https://doi.org/10.3390/app13179698
APA StyleBiczyk, P., & Wawrowski, Ł. (2023). Detecting and Isolating Adversarial Attacks Using Characteristics of the Surrogate Model Framework. Applied Sciences, 13(17), 9698. https://doi.org/10.3390/app13179698