
Personalized Advertising Design Based on Automatic Analysis of an Individual’s Appearance




Abstract
:Featured Application
Abstract
1. Introduction
Biases and Attributions for Personalized Recommendations
2. Style Model
2.1. Apparent Style
2.2. Seven Universal Styles Model
3. Related Work
4. Methodology
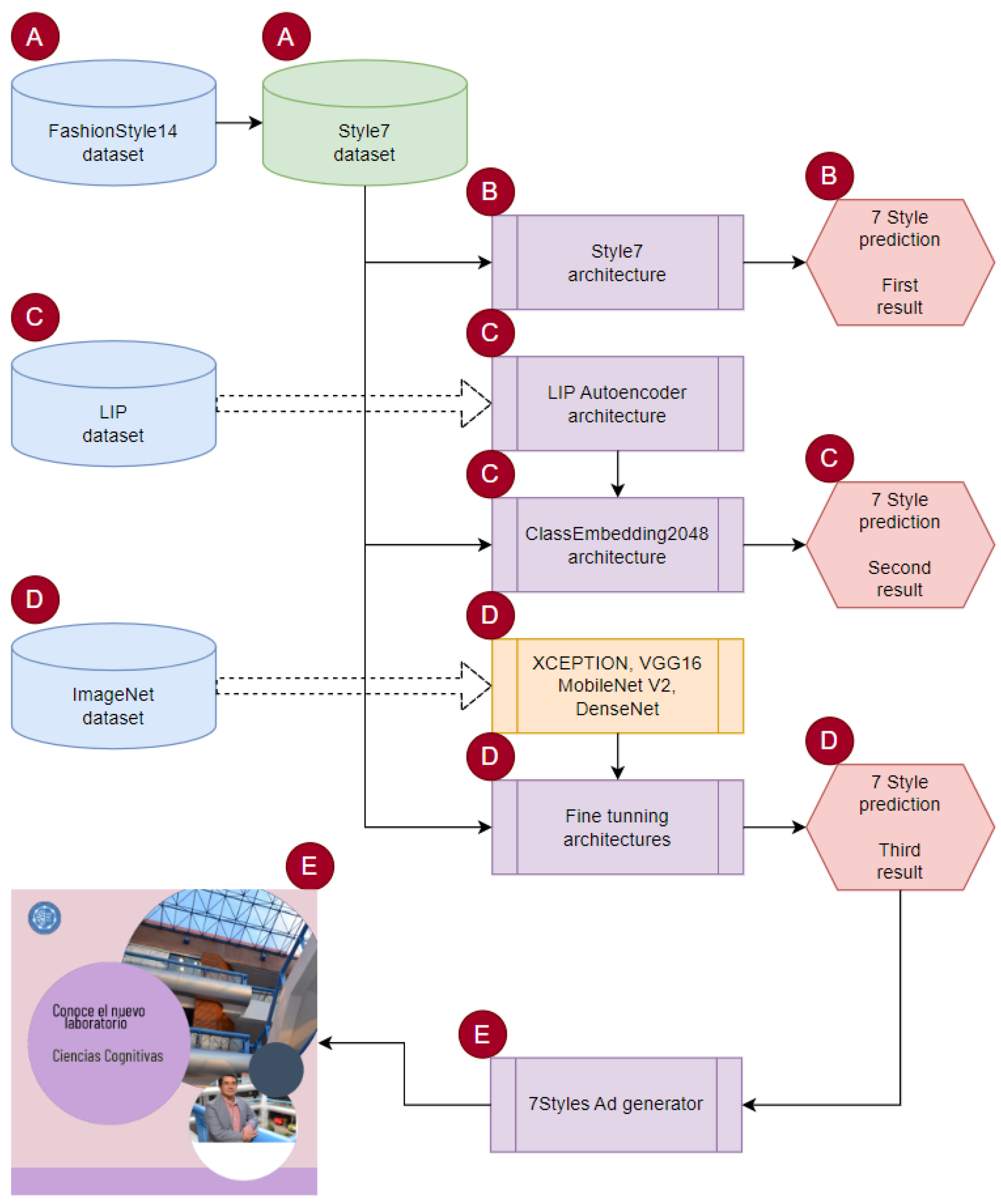
- Dataset creation: We began by creating a dataset for the seven-style model. Rather than focusing on creating the largest possible dataset, we explored various deep learning approaches, as illustrated in Figure 1;
- Deep learning approaches: We examined different deep learning approaches to predict the style of clothing. These approaches involved training supervised, semi-supervised, and transfer learning models using the created dataset. These models aim to accurately classify clothing into the seven universal styles;
- Expert system design: Once the style was predicted, we designed an expert system that generates personalized ads based on the predicted style. The expert system takes into account the guidelines and characteristics associated with each style to create an ad that resonates with the individual’s preferences and interests.
- A.
- Creating the Style7 dataset: Using the FashionStyle14 dataset [50] as a basis, we generated a new set of images called the Style7 dataset;
- B.
- Supervised training: We trained the Style7 architecture using supervised learning techniques, obtaining the first prediction result;
- C.
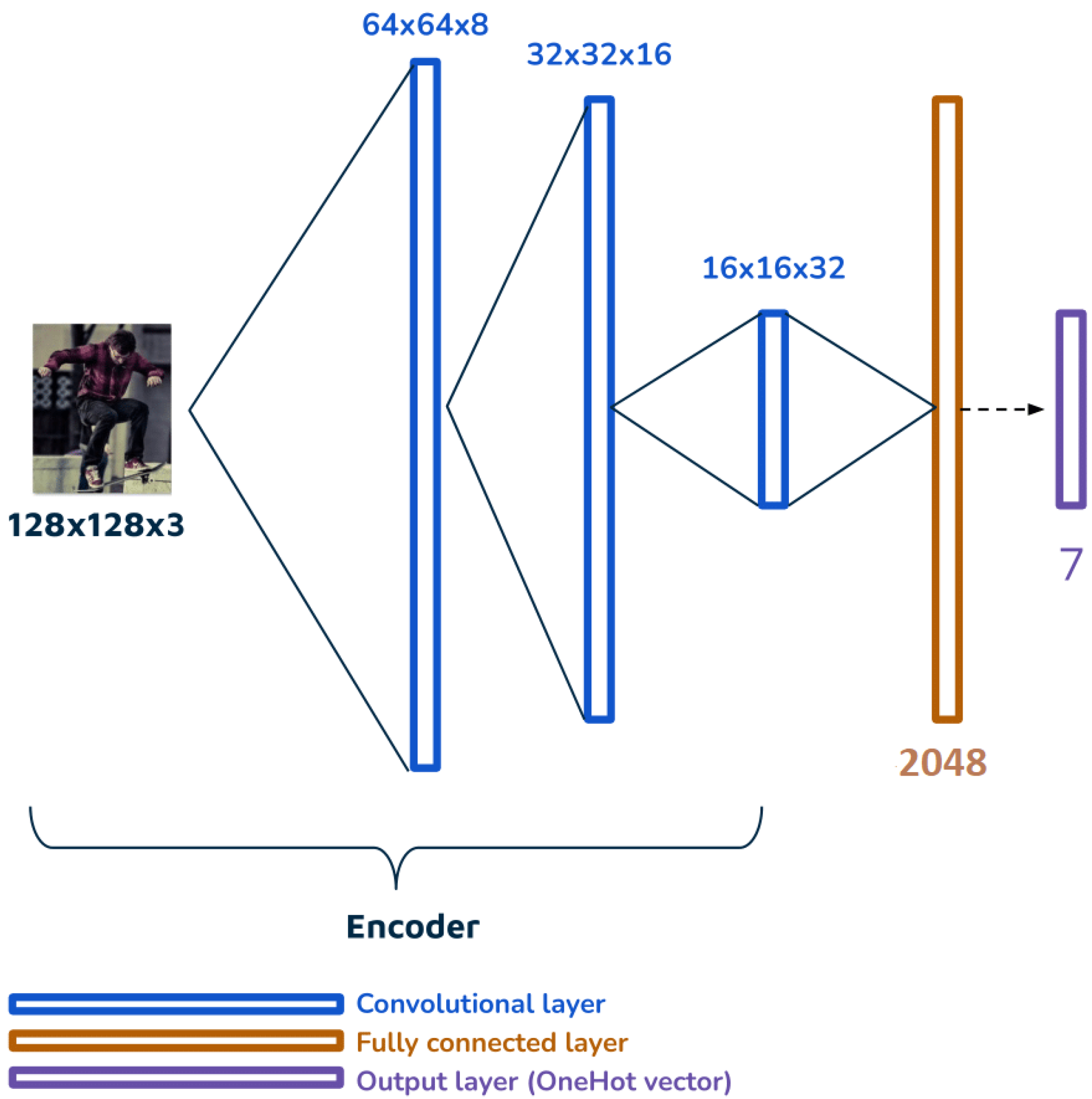
- Semi-supervised approach: We employed a semi-supervised approach where we first trained the LIP autoencoder architecture using the LIP dataset [51]. Subsequently, we utilized the decoder component of this architecture, referred to as the ClassEmbedding2048 architecture. We fed the Style7 dataset into this model and obtained the second prediction result;
- D.
- Transfer learning: We adopted a transfer learning approach by selecting four pre-trained architectures, which were initially trained by their respective authors using the ImageNet dataset [52]. We fine-tuned these architectures using the Style7 dataset, resulting in the third prediction result;
- E.
- 7Styles ad generator: A person’s style prediction and consumer photo could then be provided as input to the 7Styles ad generator, which generates a personalized ad tailored to the individual’s style.
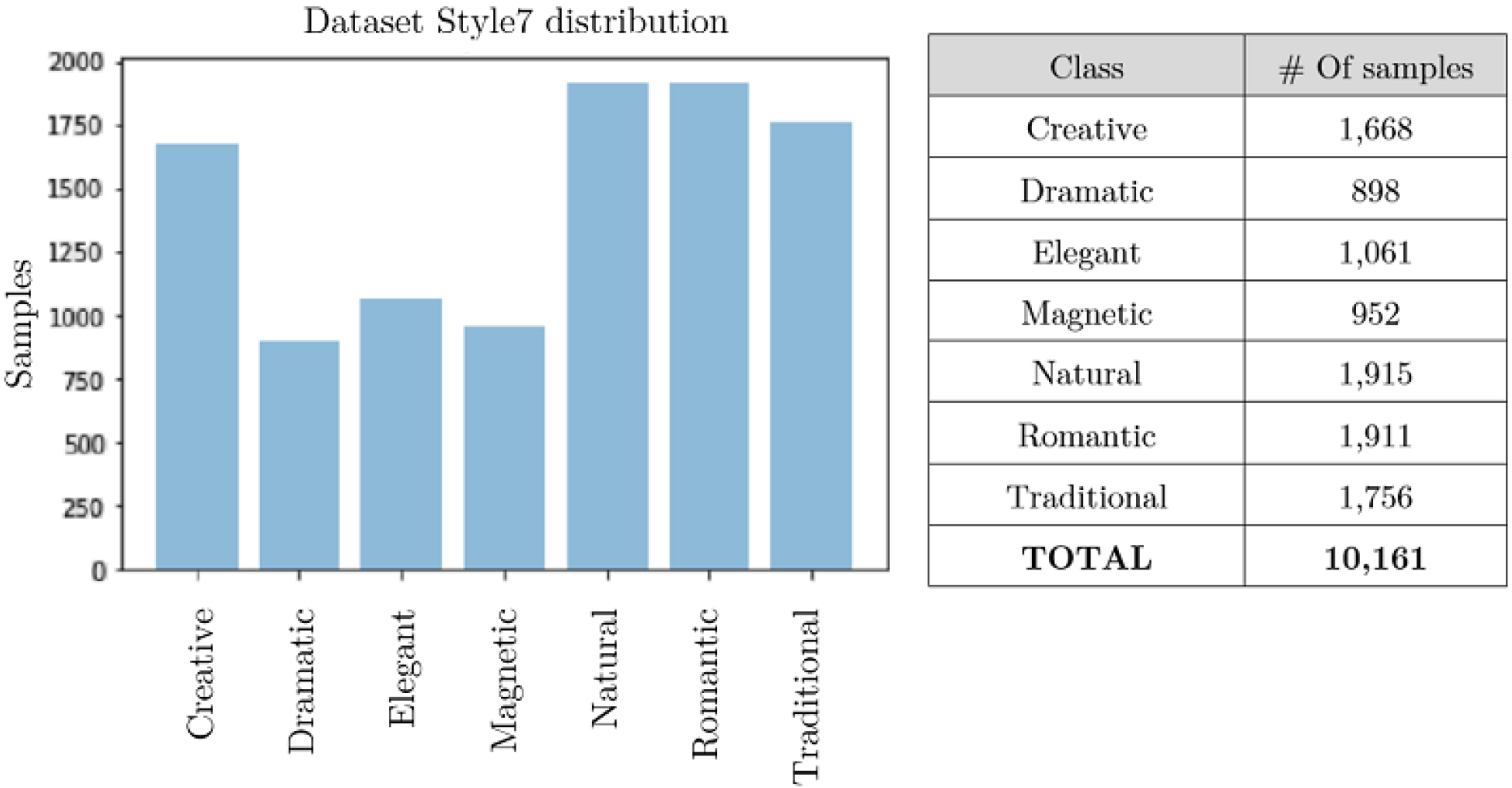
4.1. Style7 Dataset
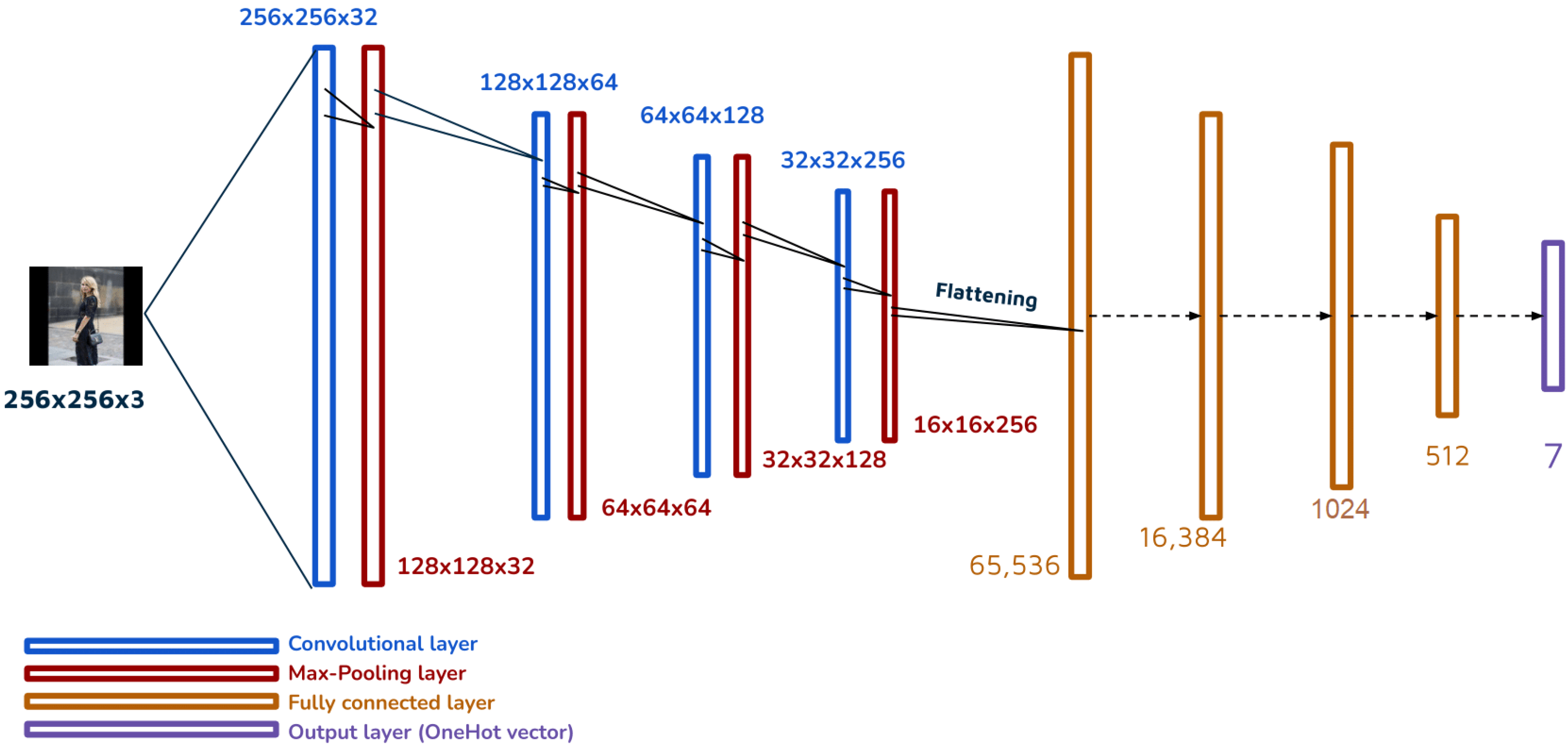
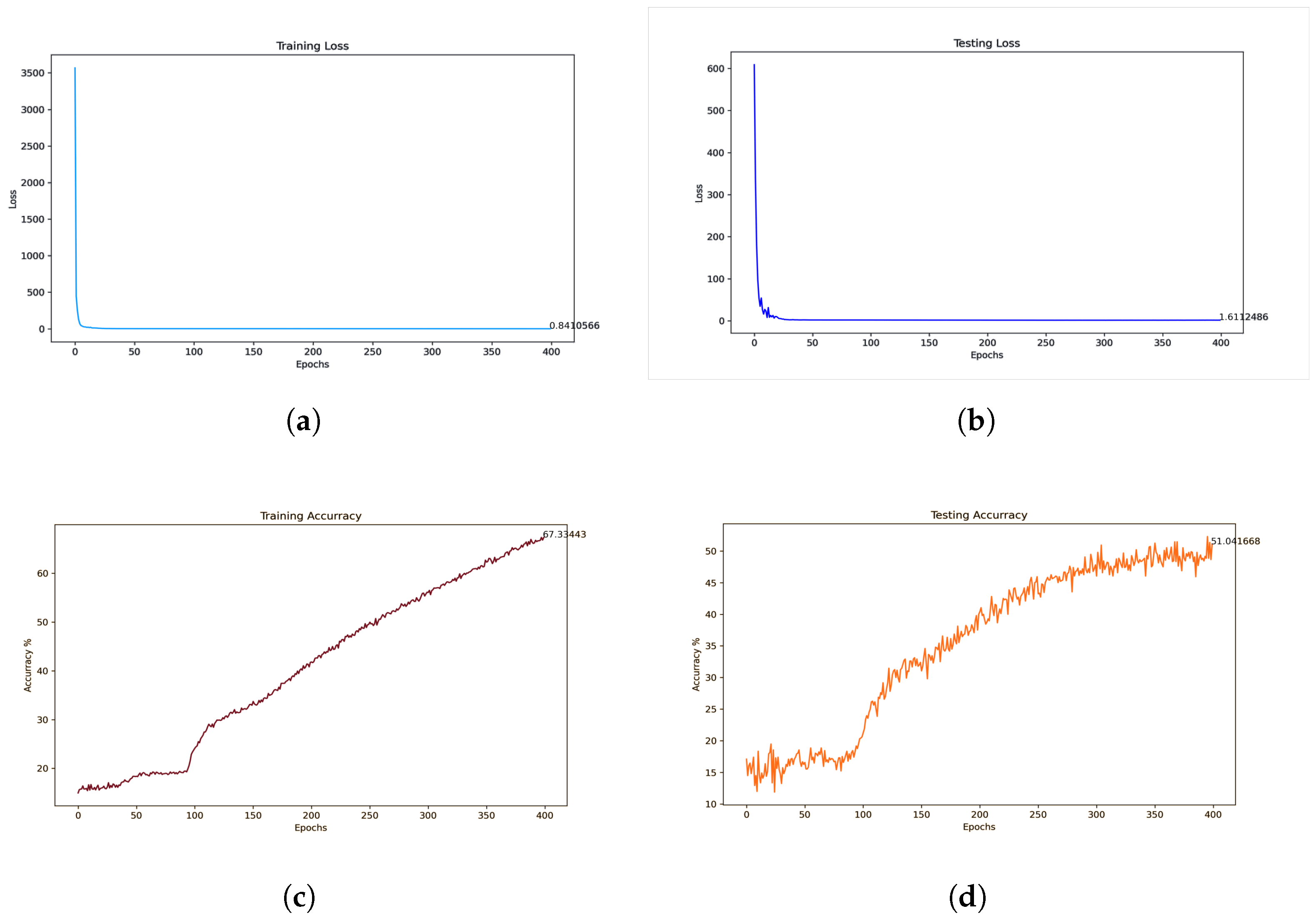
4.2. Supervised Model
- Hyperparameters: This includes fine-tuning parameters such as the activation function, optimizer settings, learning rate, batch size, and kernel size.
- Architecture: The overall structure and design of the model must be carefully considered and refined.
- Regularization techniques: Various techniques, such as normalization or dropout, may be applied to enhance the model’s generalization and prevent overfitting.
Style7 Architecture
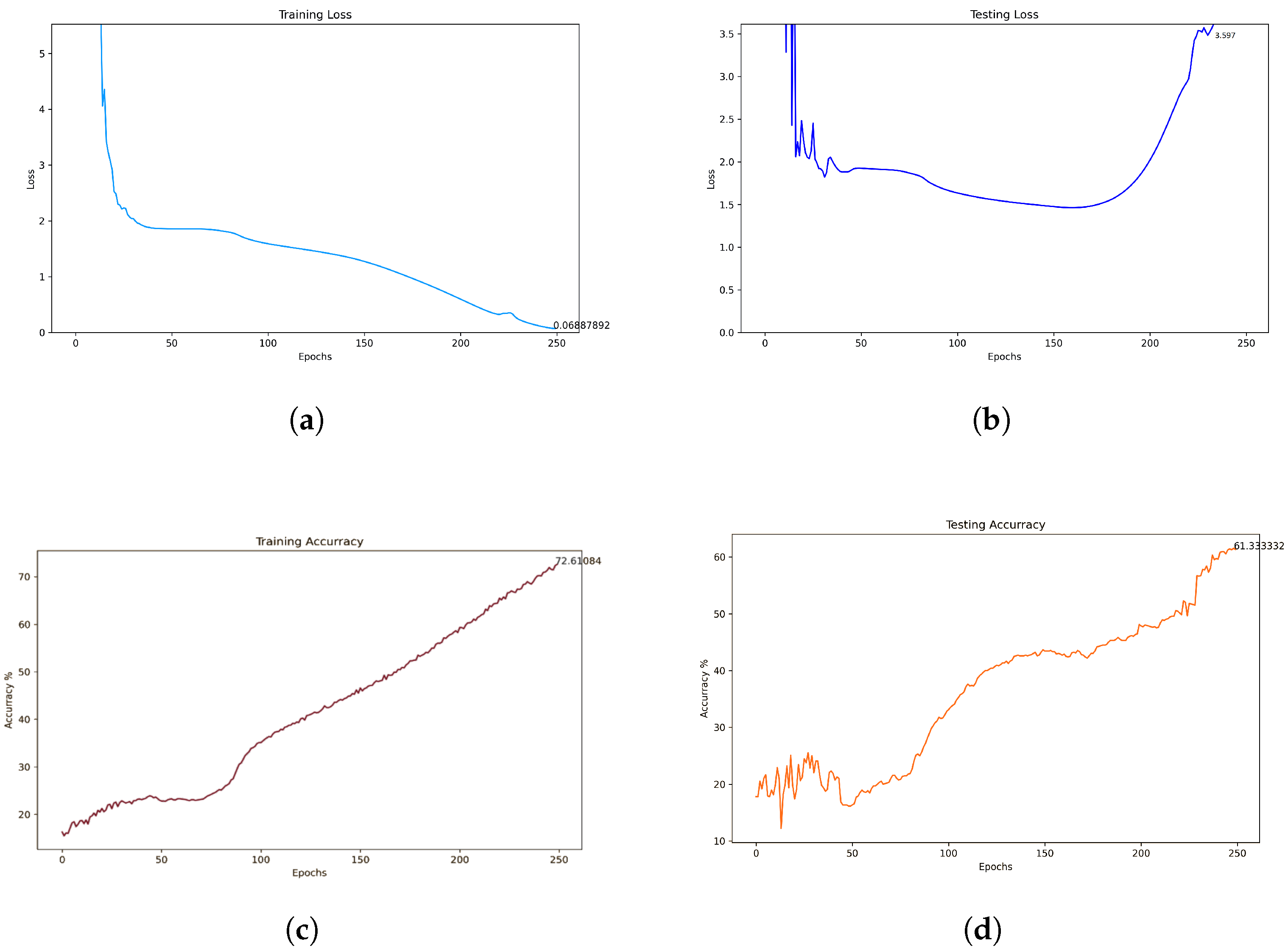
4.3. Semi-Supervised Model
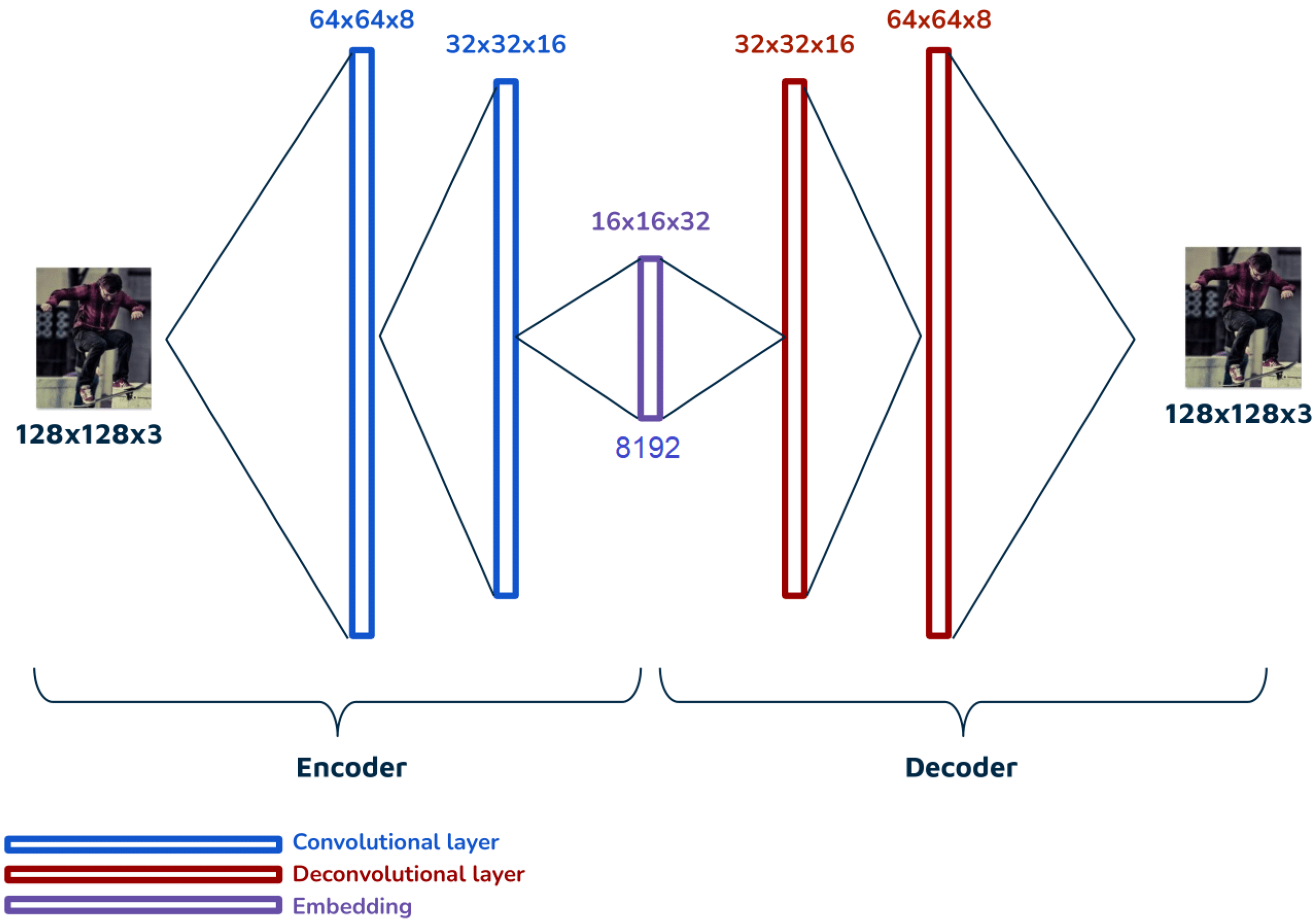
4.3.1. LIP Autoencoder Architecture
4.3.2. ClassEmbedding2048 Architecture
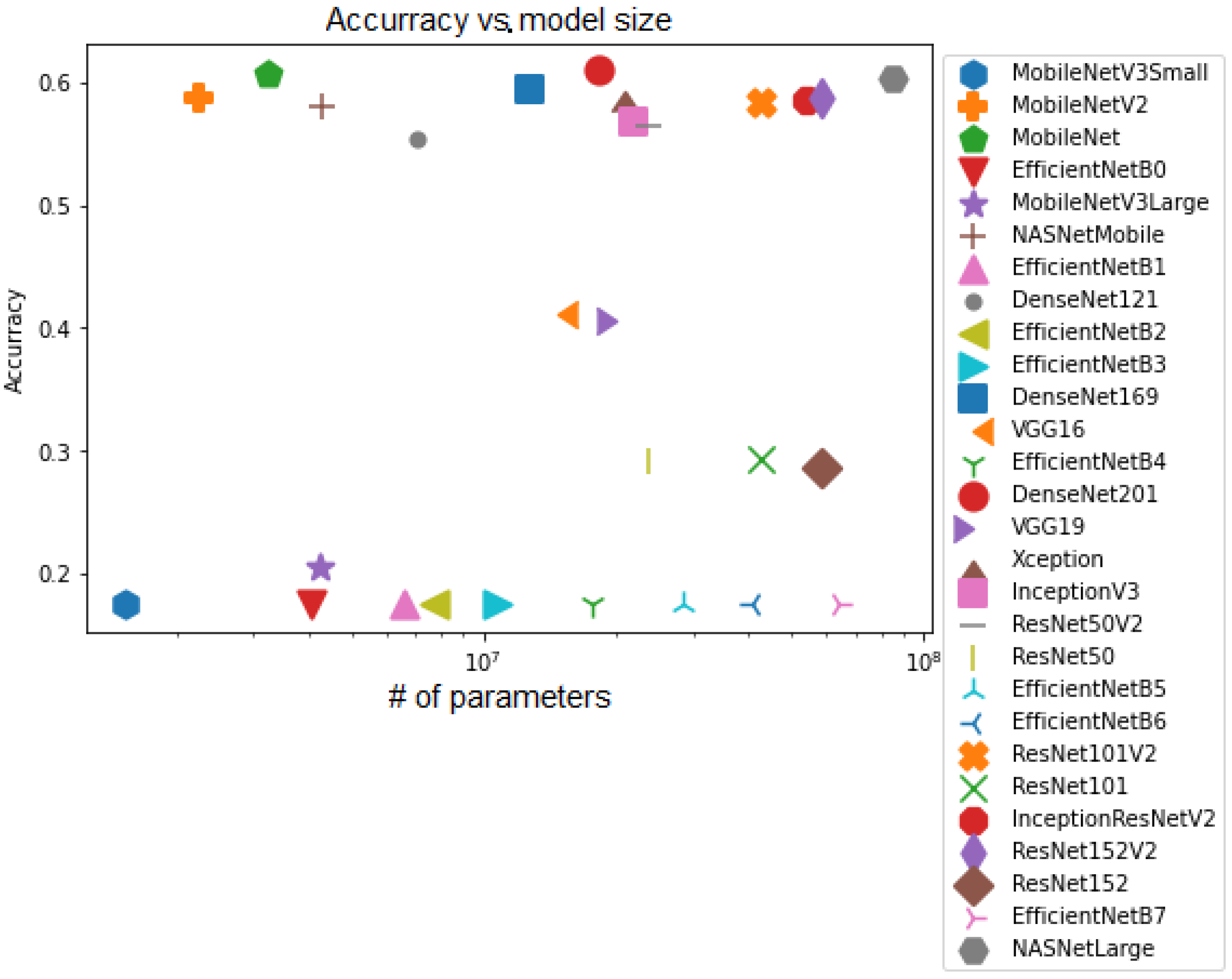
4.4. Transfer Learning Model
4.5. 7Styles Ad Generator
- Design of chromatic rules: In the design of the chromatic rules, we employed the color theory of Sherwin-Williams (SW) [56,57]. We assigned an SW color palette to each of the seven styles, as depicted in Figure 8. To determine the appropriate color palette for a given style, we measured the distance between the SW palette and the corresponding palette in Figure 1 and selected the closest hues. This process enabled us to establish a chromatic base consisting of seven colors for the personalized ad;
- Design of geometric rules: The design of the geometric rules involved determining the appropriate shapes and patterns for each style. This was achieved through a combination of visual analysis and expert judgment. By examining the characteristic shapes and patterns associated with each style, as described in Figure 1, we established rules that align with the visual representation of the style. These geometric rules served as guidelines for incorporating appropriate shapes and patterns into the personalized ad;
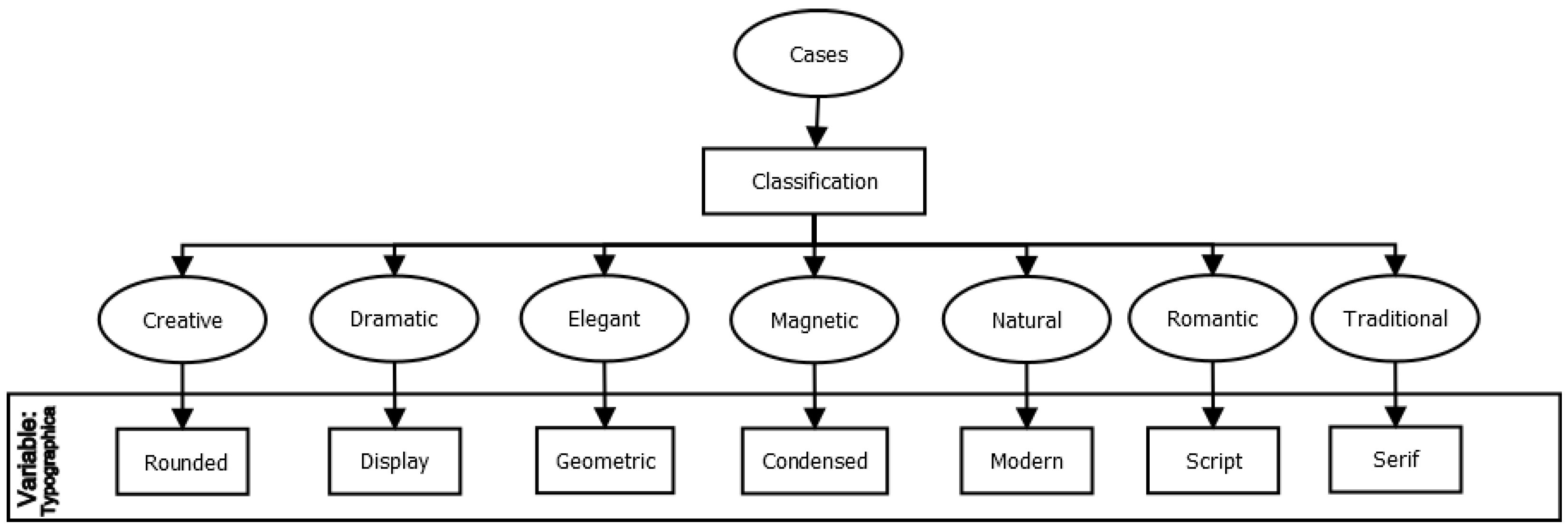
- Derivation of typographic rules: The typographic rules were derived based on the theories proposed by Li [58] and Shaikh [59], complemented by the typeface classification presented by Perez in [60]. These authors establish connections between the psychological traits associated with specific font families and typographic styles. The summarized relationships between psychological traits and typographies are outlined in Table 2. By incorporating these typographic rules, we ensured that the typography used in the personalized ad aligned with the psychological traits associated with the predicted style of the individual. The selection of the case was based on the correspondence between the features presented in Figure 2 and those shown in Figure 1. Additionally, instances where the description of the geometric basis in the style corresponds to specific graphic traits of the typeface family were also considered. The relationships between the styles and typographic characteristics are outlined in Table 3. Using this information, we constructed a decision tree for each style, as illustrated in Figure 9. These decision trees serve as a guide for selecting the appropriate typographic style for each predicted style in the generation of personalized ads;
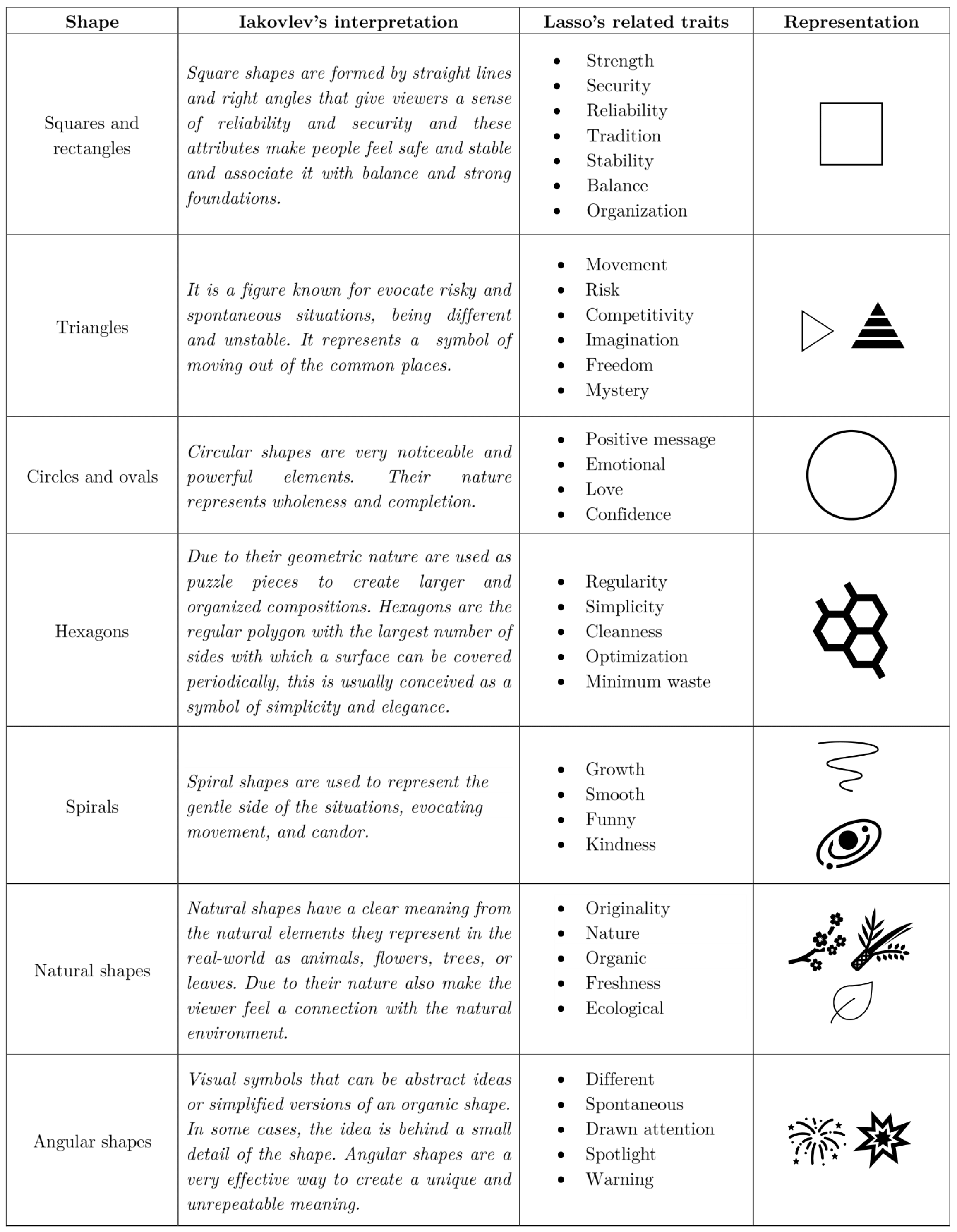
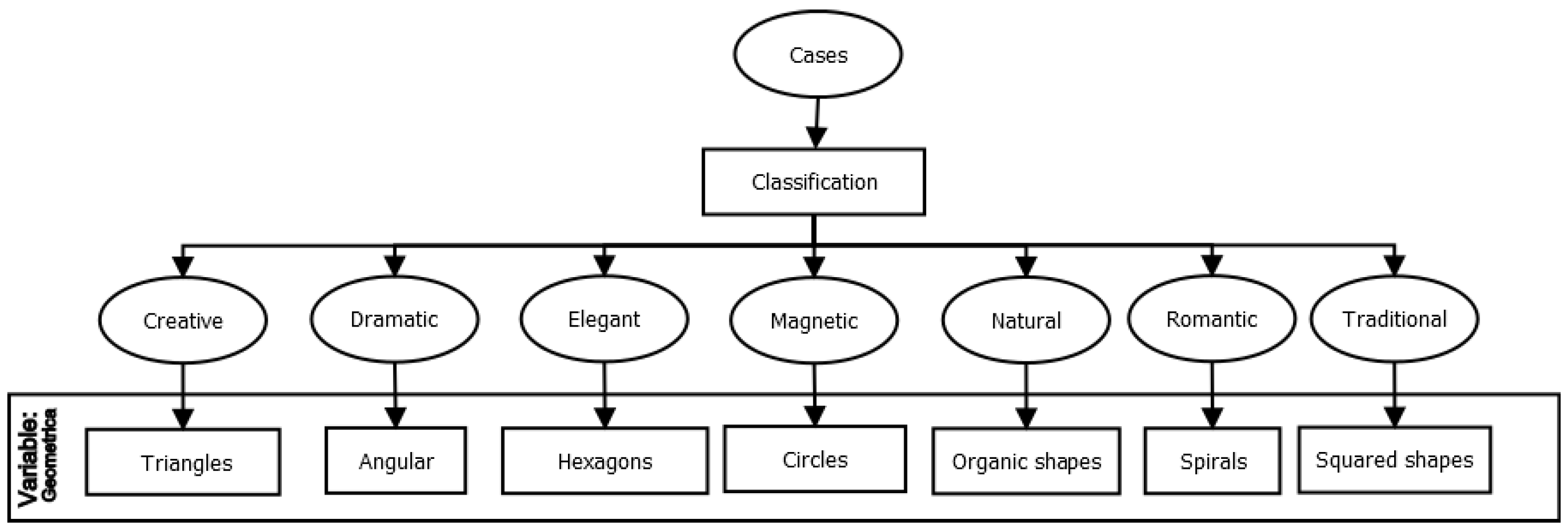
- Derivation of geometric rules: The selection criteria for the geometric variables for the seven cases were based on the expert rules derived from the theories presented by Lasso [61] and Iakovlev [62]. These theories establish connections between psychological traits and certain shapes, which are summarized in Figure 10. By applying these expert rules, we can determine the appropriate shapes for each style in the generation of personalized ads. Continuing, we examined the correlations between the columns showing the geometric basis and psychological traits in Figure 1 and Figure 10, which were derived from the relationships presented in Table 4. By doing so, we obtained the decision tree illustrated in Figure 11. This decision tree serves as a reference for selecting the appropriate geometric variables for each predicted style in the generation of personalized ads.
5. Experiments
5.1. Data Preprocessing
5.2. Supervised Model
5.3. Custom Semi-Supervised Model
LIP Autoencoder Results
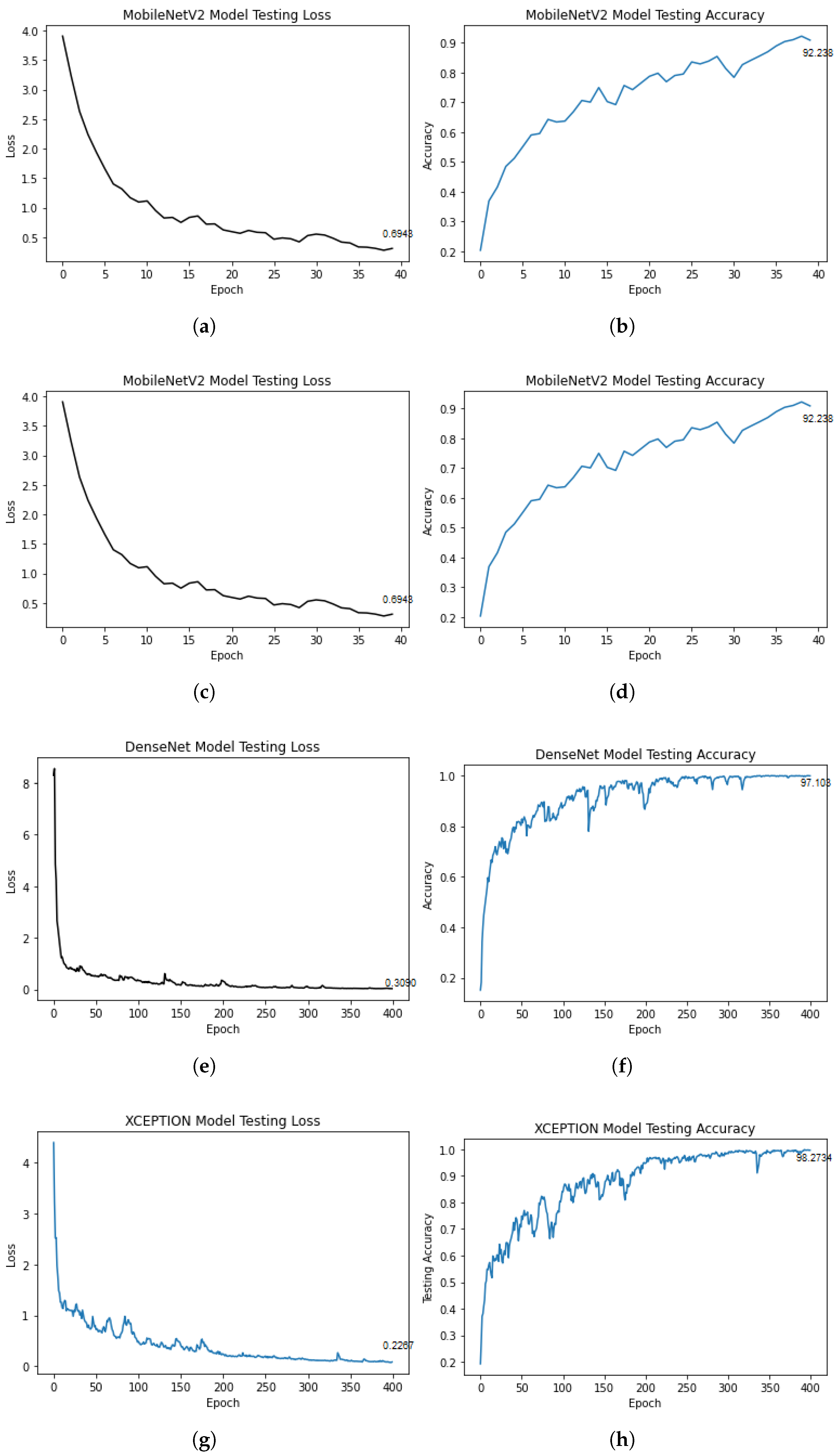
5.4. Transfer Learning Architectures
5.4.1. Discussion of Style Characterizer Results
5.4.2. Comparison with the State of the Art
5.5. 7Styles Ad Generator
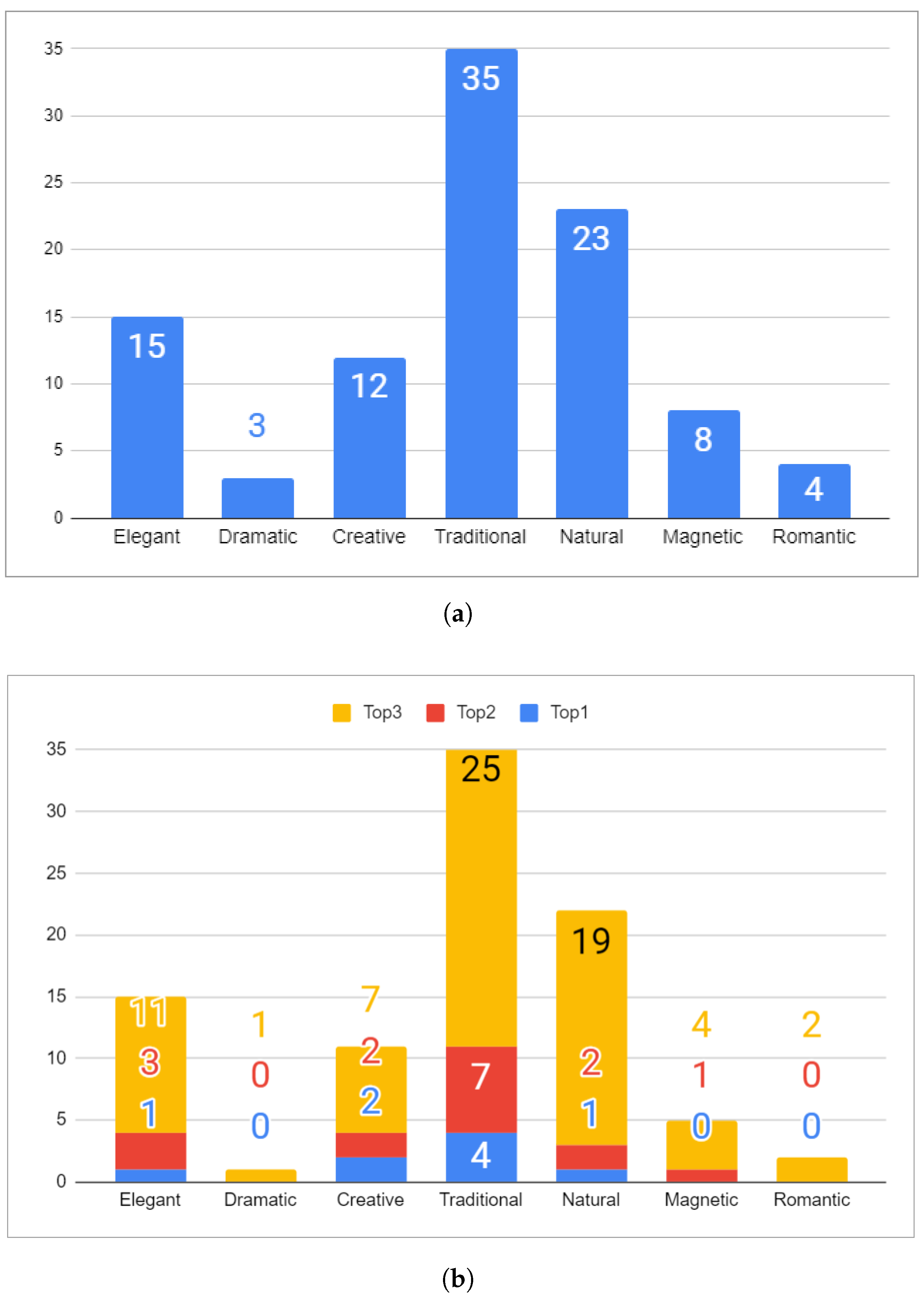
- We asked each participant to provide a full-body photo;
- The participant’s dress style was determined using the seven-style model. Figure 18a shows the number of participants for each class;
- We generated seven custom ads based on the participants’ predicted dress style;
6. Final Discussion
- This study presents a model capable of evaluating the apparent style from a photograph, demonstrating that this process can be carried out by computational means. Certain methodologies make it possible to obtain information that can be important for industrial or commercial purposes based solely on the individual’s appearance;
- The models trained in the present work can emulate the typically human task of evaluating apparent style. This information can be used to apply advantageous strategies for those who use it in a business environment;
- We obtained results with better metric evaluations than those presented by the most similar work in the literature. Although not exactly equivalent, it provides a fair comparison due to the similarity of the tasks and presented solution approaches;
- The proposed 7Styles ad generator could produce a wide variety of ad compositions. Furthermore, 79% of the people surveyed chose the ad corresponding to their style.
7. Conclusions
- Deep learning model for style prediction: The research introduced a novel deep learning model that achieved a high accuracy of 98.27% in predicting dress styles based on full-body images. This model surpassed traditional methods of market segmentation, which often rely on less granular demographic data. By leveraging advanced deep learning techniques, this model can enable businesses to understand their customers’ style preferences more accurately and effectively;
- Personalized ad generator: The integration of the deep learning model into a personalized ad generator offers a groundbreaking approach to advertising. By generating custom ads based on each user’s predicted style, businesses can deliver highly relevant and engaging content, increasing the likelihood of positive customer responses and conversions;
- Automated market segmentation: The research showcased the automation of market segmentation by using the predicted dress styles as a segmentation variable. This automation can streamline the process of tailoring marketing campaigns to specific customer segments, saving time and resources for businesses while enhancing the precision of their targeting efforts;
- Data-driven insights for marketing strategies: By utilizing data to estimate consumer preferences and style traits, the research demonstrated the power of data-driven insights in enhancing marketing strategies. Businesses could make more informed decisions by understanding their customers’ psychological traits through observable appearance components, leading to improved customer engagement and satisfaction.
- The deep learning model and its high accuracy in predicting dress styles can contribute to the advancement of machine learning techniques in the domain of fashion and style analysis;
- The study provides a foundation for further research in automating market segmentation and generating personalized marketing content using advanced deep learning methodologies;
- The personalized ad generator offers a valuable tool for businesses seeking to optimize their marketing efforts and create targeted campaigns that resonate with individual customers;
- The research demonstrates the potential of data-driven insights in enhancing marketing strategies, encouraging businesses to adopt more personalized and effective approaches to advertising.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Socio-Demographic Survey Results

References
- Faggella, D. Artificial Intelligence in Marketing and Advertising—5 Examples of Real Traction. 2018. Available online: https://www.techemergence.com/artificial-intelligence-in-marketing-and-advertising-5-examples-of-real-traction/ (accessed on 18 August 2023).
- Burrage, A. Targeted Marketing vs. Mass Marketing. 2020. Available online: https://www.wearetrident.co.uk/targeted-marketing-vs-mass-marketing/ (accessed on 16 August 2023).
- Camilleri, M.A. Understanding customer needs and wants. In Tourism, Hospitality; Event Management; Springer: Berlin/Heidelberg, Germany, 2017; pp. 29–50. [Google Scholar] [CrossRef]
- Kimiagari, S.; Baei, F. Promoting e-banking actual usage: Mix of technology acceptance model and technology-organisation-environment framework. Enterp. Inf. Syst. 2022, 16, 1894356. [Google Scholar] [CrossRef]
- Malafe, N.S.A.; Kimiagari, S.; Balef, E.K. Investigating the Variables Affecting Brand Performance in the SOR Framework. In Academy of Marketing Science Annual Conference-World Marketing Congress; Springer: Berlin/Heidelberg, Germany, 2021; pp. 303–317. [Google Scholar]
- Kimiagari, S.; Balef, E.K.; Malafe, N.S.A. Study of the Factors Affecting the Intention to Adopt and Recommend Technology to Others: Based on the Unified Theory of Acceptance and Use of Technology (UTAUT). In Academy of Marketing Science Annual Conference-World Marketing Congress; Springer: Berlin/Heidelberg, Germany, 2021; pp. 321–334. [Google Scholar]
- Kimiagari, S.; Baei, F. Extending Intention to Use Electronic Services Based on the Human–Technology Interaction Approach and Social Cognition Theory: Emerging Market Case. IEEE Trans. Eng. Manag. 2022, 1–20. [Google Scholar] [CrossRef]
- Kimiagari, S.; Malafe, N.S.A. The role of cognitive and affective responses in the relationship between internal and external stimuli on online impulse buying behavior. J. Retail. Consum. Serv. 2021, 61, 102567. [Google Scholar] [CrossRef]
- Dawar, N.; Parker, P. Marketing universals: Consumers’ use of brand name, price, physical appearance, and retailer reputation as signals of product quality. J. Mark. 1994, 58, 81–95. [Google Scholar]
- Mittal, B.; Baker, J. The Services Marketing System and Customer Psychology; Wiley Subscription Services, Inc.: Hoboken, NJ, USA, 1998. [Google Scholar]
- Gustafson, S.B.; Mumford, M.D. Personal style and person-environment fit: A pattern approach. J. Vocat. Behav. 1995, 46, 163–188. [Google Scholar] [CrossRef]
- Jackson, D.N.; Messick, S. Content and style in personality assessment. Psychol. Bull. 1958, 55, 243. [Google Scholar] [CrossRef]
- Callow, M.; Schiffman, L.G. Sociocultural meanings in visually standardized print ads. Eur. J. Mark. 2004, 38, 1113–1128. [Google Scholar] [CrossRef]
- Ascarza, E.; Israeli, A. Eliminating unintended bias in personalized policies using bias-eliminating adapted trees (BEAT). Proc. Natl. Acad. Sci. USA 2022, 119, e2115293119. [Google Scholar] [CrossRef]
- Buhalis, D.; Volchek, K. Bridging marketing theory and big data analytics: The taxonomy of marketing attribution. Int. J. Inf. Manag. 2021, 56, 102253. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Korolova, A.; Sarma, A.D. Personalized social recommendations-accurate or private? arXiv 2011, arXiv:1105.4254. [Google Scholar]
- Zhu, Z.; Wang, J.; Caverlee, J. Measuring and mitigating item under-recommendation bias in personalized ranking systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 449–458. [Google Scholar]
- Theocharous, G.; Healey, J.; Mahadevan, S.; Saad, M. Personalizing with human cognitive biases. In Proceedings of the Adjunct Publication of the 27th Conference on User Modeling, Adaptation and Personalization, Larnaca, Cyprus, 9–12 June 2019; pp. 13–17. [Google Scholar]
- Martin, K.D.; Murphy, P.E. The role of data privacy in marketing. J. Acad. Mark. Sci. 2017, 45, 135–155. [Google Scholar] [CrossRef]
- Cartwright, S.; Liu, H.; Raddats, C. Strategic use of social media within business-to-business (B2B) marketing: A systematic literature review. Ind. Mark. Manag. 2021, 97, 35–58. [Google Scholar] [CrossRef]
- Eco, U. Tratado de Semiótica General, 3rd ed.; Penguin Random House: Barcelona, Spain, 2018. [Google Scholar]
- Barthes, R.; Ward, M.; Howard, R. The Fashion System; Hill and Wang: New York, NY, USA, 1983. [Google Scholar]
- Rodríguez-Jaime, J. Social cognition study: Clothing and its link as an analysis element of nonverbal communication. Vivat Acad. 2018, 157, 85. [Google Scholar] [CrossRef]
- Volli, U. Semiótica de la Publicidad; Gius Laterza and Figli Spa: Rome, Italy, 2012. [Google Scholar]
- Kaiser, S. The Social Psychology of Clothing: Symbolic Appearances in Context; Fairchild: New York, NY, USA, 1997. [Google Scholar]
- Polaino-Lorente, A.; Armentia, A.; Cabanyes, J. Fundamentos de Psicología de la Personalidad; Colección Textos del Instituto de Ciencias para la Familia; RIALP: Madrid, España, 2003. [Google Scholar]
- Parsons, A.; Parente, D.; Martin, G. Universal Style: Dress for Who You Are and What You Want; Parente & Parsons: Online, 1991. [Google Scholar]
- Aguilar, D. La Tipología del Estilo Como Herramienta Clave Para Mejorar las Relaciones Humanas a Partir los Procesos de Reclutamiento de Personal. Ph.D. Thesis, Colegio de Consultores en Imagen Pública, Mexico City, Mexico, 2015. [Google Scholar]
- Migueles, L.C.; Gordillo, P.C. El hombre vestido: Una visión sociológica, psicológica y comunicativa sobre la moda. In El Hombre Vestido: Una Visión Sociológica, Psicológica y Comunicativa Sobre la Moda; University of Granada: Granada, Spain, 2014. [Google Scholar]
- Kwon, J.; Ogawa, K.i.; Ono, E.; Miyake, Y. Detection of nonverbal synchronization through phase difference in human communication. PLoS ONE 2015, 10, e0133881. [Google Scholar] [CrossRef] [PubMed]
- Marín Dueñas, P.P. Hand up. Analysis of non-verbal communication in the campaign for the general secretary of PSOE (spanish socialist workers’ party). Encuentros 2014, 12, 91–104. [Google Scholar]
- Entwistle, J. El Cuerpo y la Moda: Una Visión Sociológica; Contextos/Context; Paidós: Barcelona, España, 2002. [Google Scholar]
- Elkan, D. The psychology of colour: Why winners wear red. New Sci. 2009, 203, 42–45. [Google Scholar] [CrossRef]
- Frank, M.; Gilovich, T. The Dark Side of Self- and Social Perception: Black Uniforms and Aggression in Professional Sports. J. Personal. Soc. Psychol. 1988, 54, 74–85. [Google Scholar] [CrossRef]
- Hill, R.A.; Barton, R.A. Red enhances human performance in contests. Nature 2005, 435, 293. [Google Scholar] [CrossRef]
- Stephen, I.D.; Oldham, F.H.; Perrett, D.I.; Barton, R.A. Redness enhances perceived aggression, dominance and attractiveness in men’s faces. Evol. Psychol. 2012, 10, 147470491201000312. [Google Scholar] [CrossRef]
- Eaves, M.H.; Leathers, D. Successful Nonverbal Communication: Principles and Applications; Routledge: Oxfordshire, UK, 2017. [Google Scholar]
- Molloy, J.T. John T. Molloy’s New Dress for Success; Warner Books: New York, NY, USA, 1988. [Google Scholar]
- Rasicot, J. Jury Selection, Body Language & the Visual Trial; AB Publications: Minneapolis, MN, USA, 1983. [Google Scholar]
- Smith, L.J.; Malandro, L.A. Courtroom Communication Strategies; Kluwer Law Book Publishers: Alphen aan den Rijn, The Netherlands, 1985. [Google Scholar]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1096–1104. [Google Scholar]
- Hadi Kiapour, M.; Han, X.; Lazebnik, S.; Berg, A.C.; Berg, T.L. Where to buy it: Matching street clothing photos in online shops. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3343–3351. [Google Scholar]
- Huang, J.; Feris, R.S.; Chen, Q.; Yan, S. Cross-domain image retrieval with a dual attribute-aware ranking network. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1062–1070. [Google Scholar]
- Chen, Q.; Huang, J.; Feris, R.; Brown, L.M.; Dong, J.; Yan, S. Deep domain adaptation for describing people based on fine-grained clothing attributes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5315–5324. [Google Scholar]
- Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from massive noisy labeled data for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2691–2699. [Google Scholar]
- Chen, J.C.; Liu, C.F. Deep net architectures for visual-based clothing image recognition on large database. Soft Comput. 2017, 21, 2923–2939. [Google Scholar] [CrossRef]
- Liu, K.H.; Chen, T.Y.; Chen, C.S. Mvc: A dataset for view-invariant clothing retrieval and attribute prediction. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; pp. 313–316. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sun, G.L.; Wu, X.; Peng, Q. Part-based clothing image annotation by visual neighbor retrieval. Neurocomputing 2016, 213, 115–124. [Google Scholar] [CrossRef]
- Takagi, M.; Simo-Serra, E.; Iizuka, S.; Ishikawa, H. What makes a style: Experimental analysis of fashion prediction. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 2247–2253. [Google Scholar]
- Gong, K.; Liang, X.; Zhang, D.; Shen, X.; Lin, L. Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 932–940. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Chollet, F.; Zhu, Q.S.; Rahman, F.; Gardener, T.; Lee, T.; Qian, C.; Marmiesse, G.; Jin, H.; Zabluda, O.; Marks, S.; et al. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 23 August 2023).
- Chollet, F.; Zhu, Q.S.; Rahman, F.; Gardener, T.; Lee, T.; Qian, C.; Marmiesse, G.; Jin, H.; Zabluda, O.; Marks, S.; et al. Keras Applications. 2015. Available online: https://keras.io/api/applications/ (accessed on 23 August 2023).
- Badaró, S.; Ibañez, L.J.; Agüero, M.J. Sistemas expertos: Fundamentos, metodologías y aplicaciones. Cienc. Tecnol. 2013, 349–364. Available online: https://dialnet.unirioja.es/servlet/articulo?codigo=4843871 (accessed on 23 August 2023). [CrossRef]
- Sherwin-Williams. STIR Connects Color and Cutting-Edge Design—Sherwin-Williams. 2015. Available online: https://www.sherwin-williams.com/architects-specifiers-designers/inspiration/stir (accessed on 18 August 2023).
- Sherwin-Williams. Colorsnap Color ID | Paint Color Collections | Sherwin-Williams. 2019. Available online: https://www.sherwin-williams.com/visualizer#/active/color-collections (accessed on 22 August 2023).
- Li, Y.; Suen, C.Y. Typeface personality traits and their design characteristics. In Proceedings of the 9th IAPR International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 231–238. [Google Scholar]
- Shaikh, A.D.; Chaparro, B.S.; Fox, D. Perception of fonts: Perceived personality traits and uses. In Perception of Fonts: Perceived Personality Traits and Uses; Usability News: Cardiff, UK, 2006. [Google Scholar]
- Perez, P. Las Tipografías y su Personalidad ¿Qué Transmite Cada Una? 2020. Available online: https://paoperez.com/tipografias-personalidad-transmite/ (accessed on 16 August 2023).
- Lasso, G. The Meaning Behind Shapes. 2007. Available online: https://medium.com/@glasso_14980/the-meaning-behind-shapes-10bb9db82c1b (accessed on 9 August 2023).
- Iakovlev, Y. Shape Psychology in Graphic Design. 2015. Available online: https://www.zekagraphic.com/shape-psychology-in-graphic-design/ (accessed on 14 August 2023).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Methodology | Dataset | Findings/Results |
|---|---|---|---|
| Parsons [27] | Style evaluation model based on seven distinct types | - | Framework for categorizing clothing styles based on conveyed messages |
| Various disciplines [28,29] | Thorough scrutiny of the seven universal styles | - | Widely accepted model for evaluating apparent style |
| Liu et al. [41] | Utilized FashionNet with nearly one million annotated images | Images from diverse settings | Improved performance for deep fashion tasks |
| Chen et al. [44] | Introduced a double-path deep domain adaptation network | Street webcams and surveillance video images | Enhanced performance of convolutional neural network (CNN) |
| Xiao et al. [45] | Trained CNN-like network with small dataset, expanded dataset with Internet images | Small dataset, additional Internet images | Neural network labeled up to 78% of new images |
| Chen et al. [46] | Employed transfer learning and divide-and-conquer methodology | Clothing classification dataset | Significant 18% improvement compared to previous architectures |
| Liu et al. [47] | Created dataset with different views and 264 descriptors | Dataset with different views of clothing | Achieved 80% accuracy in clothing style recognition |
| Sun et al. [49] | Proposed a methodology for clothing image annotation | Clothing images with detected poses | Significant improvement in clothing image annotation |
| Present study | Introduced deep learning model for style prediction and personalized ad generator | Images of participants in different styles | Achieved a top accuracy of 98.27% for style prediction and 80.56% acceptance rate for personalized ads |
| Typographic Family | Psychological Traits |
|---|---|
| Serif | Traditional, elegant, serious, respectable, formal, refined, and authoritative |
| Rounded | Close, imaginative, dynamic, smooth, relaxed, and unique |
| Geometric | Stable, dynamic, versatile, serious, playful, deliberate, and elegant |
| Condensed | Narrower, forceful, rigid, sophisticated, modern, and serious |
| Modern | Adaptative, modern, and professional |
| Decorative | Differentiated, transgressive and original, lacking care, and personal |
| Script | Cursive, calligraphic, and approachable |
| Style | Typographic Family | Common Psychological Traits | Common Geometric Basis |
|---|---|---|---|
| Traditional | Serif | Traditional, serious, respectable, and formal | Horizontal and vertical stripes |
| Creative | Rounded | Imaginative, relaxed, and unique | Angular shapes |
| Elegant | Geometric | Elegant, serious, deliberate, and stable | Close shapes, simple geometries |
| Magnetic | Condensed | Narrower, forceful, and sophisticated | Fitted shapes |
| Natural | Modern | Adaptive and practical | Simple lines |
| Dramatic | Display | Differentiated, transgressive, and flamboyant | Ornamental and decorative |
| Romantic | Script | Cursive, calligraphic, and approachable | Flourishes, delicate |
| Style | Shape Family | Common Psychological Traits | Common Geometric Basis |
|---|---|---|---|
| Traditional | Squares | Tradition, organization | Horizontal and vertical stripes |
| Creative | Triangle | Risk, spontaneous, freedom, imagination | Angular shapes, sharp points |
| Elegant | Hexagons | Optimization, perfectionism | Regular designs, polygons, geometries |
| Magnetic | Circles and ovals | Positive message (fit), love | Circles and closed curves |
| Natural | Natural shapes | Organic, vital | Organic design, phytomorphic |
| Dramatic | Angular shapes | Spotlight, drawing attention | Diagonal and explosive lines |
| Romantic | Spirals | Kind, light | Delicate, open, rounded lines |
| Inputs | |||
|---|---|---|---|
| Dataset: | Style7 | Training samples: | 9161 |
| Input dimensions: | (RGB) | Testing samples: | 1000 |
| Normalized dataset: | No | Total samples: | 10,161 |
| Hyperparameters | |||
| Optimizer: | Adam | Learning rate: | 0.01 |
| Loss function: | Categorical cross-entropy | Normalized weights: | No |
| Training epochs: | 400 | Softmax at output: | No |
| Regularization: | No | Output format: | One-hot |
| Output size: | 7 | ||
| Architecture | Parameters | Depth | Training Time | Error | Accuracy |
|---|---|---|---|---|---|
| MobileNetV2 | 3,538,984 | 88 | 0:38:15 | 0.6943 | 0.9223 |
| DenseNet21 | 20,242,984 | 201 | 6:35:37 | 0.3090 | 0.9710 |
| VGG16 | 138,357,544 | 23 | 3:15:04 | 0.3943 | 0.8939 |
| XCEPTION | 22,910,180 | 126 | 3:50:49 | 0.2267 | 0.9827 |
| Aspect | Significance |
|---|---|
| Sample size | 100 participants |
| Central limit theorem | Satisfied criteria for statistical validity (p < 0.05) |
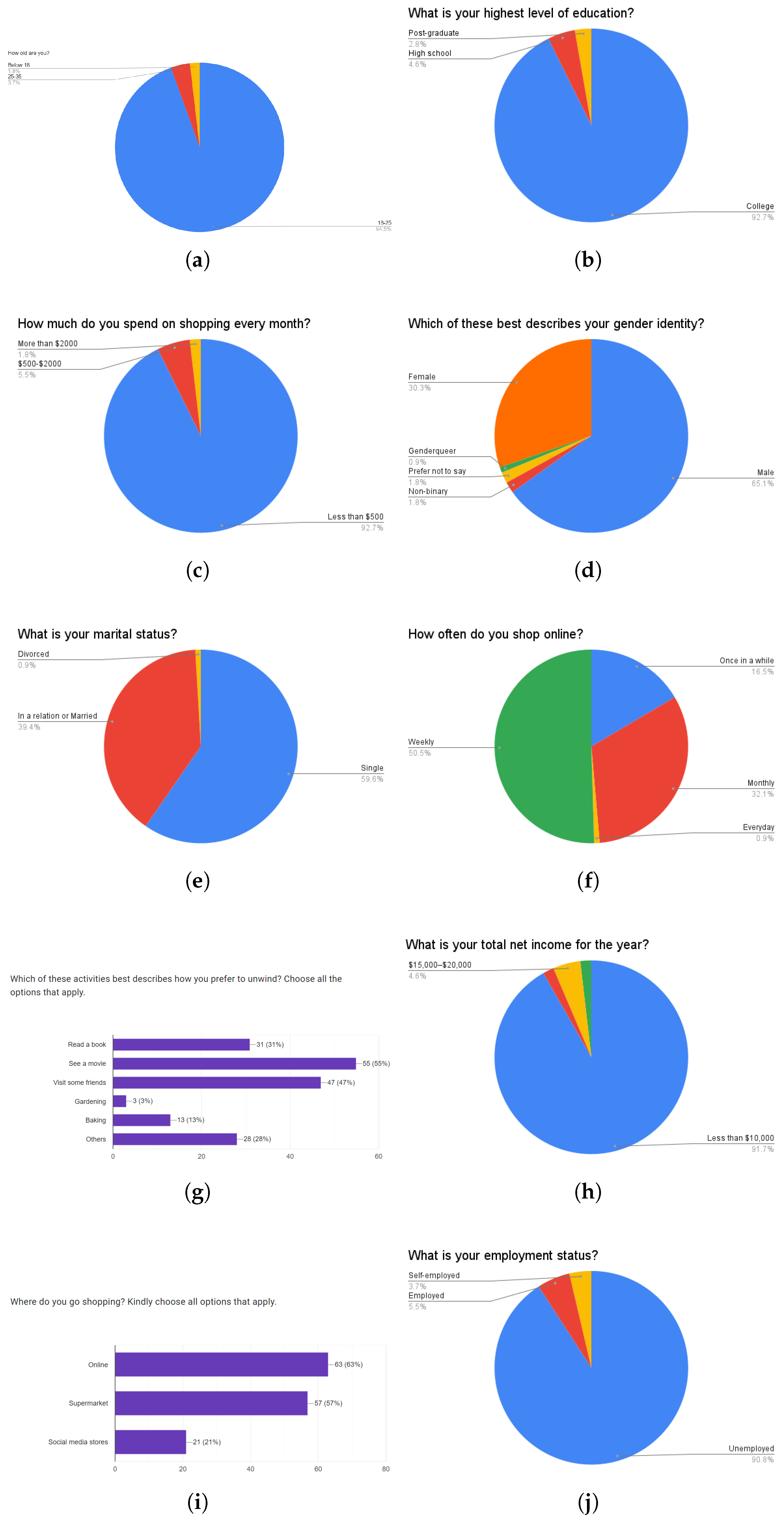
| Demographic insights | 96% aged 18–25, 92% with college education, 95% unemployed (graduate students), etc. |
| Transfer learning models | XCEPTION model achieved top accuracy of 0.9827 (p < 0.001) |
| Overall findings | Promising potential for effective personalized Ad generation |
| Predicted class | ||||||||
|---|---|---|---|---|---|---|---|---|
| Creative | Dramatic | Elegant | Magnetic | Natural | Romantic | Traditional | ||
| True class | Creative | 180 | 1 | 0 | 1 | 2 | 0 | 0 |
| Dramatic | 0 | 90 | 0 | 0 | 0 | 1 | 0 | |
| Elegant | 0 | 0 | 78 | 2 | 0 | 0 | 1 | |
| Magnetic | 0 | 0 | 0 | 60 | 0 | 0 | 0 | |
| Natural | 0 | 4 | 0 | 2 | 202 | 0 | 0 | |
| Romantic | 0 | 0 | 0 | 1 | 0 | 151 | 0 | |
| Traditional | 0 | 0 | 3 | 0 | 0 | 0 | 221 | |
| True Positive | False Positive | False Negative | True Negative | |
|---|---|---|---|---|
| Creative | 180 | 0 | 4 | 816 |
| Dramatic | 90 | 5 | 1 | 904 |
| Elegant | 78 | 3 | 3 | 916 |
| Magnetic | 60 | 6 | 0 | 934 |
| Natural | 202 | 2 | 6 | 790 |
| Romantic | 151 | 1 | 1 | 847 |
| Traditional | 221 | 1 | 3 | 775 |
| Accuracy | Precision | Recall | Specificity | F1 | Weighted F1 | |
|---|---|---|---|---|---|---|
| Creative | 0.996 | 1.000 | 0.978 | 1.000 | 0.989 | 0.982 |
| Dramatic | 0.994 | 0.947 | 0.989 | 0.994 | 0.968 | |
| Elegant | 0.994 | 0.963 | 0.963 | 0.997 | 0.963 | |
| Magnetic | 0.994 | 0.909 | 1.000 | 0.994 | 0.952 | |
| Natural | 0.992 | 0.990 | 0.971 | 0.997 | 0.981 | |
| Romantic | 0.998 | 0.993 | 0.993 | 0.999 | 0.993 | |
| Traditional | 0.996 | 0.995 | 0.987 | 0.999 | 0.991 |
| Architecture | Mean Accuracy | Weighted F1 |
|---|---|---|
| Style7 | 55.93% | 0.572 |
| ClassEmbedding2048 | 61.33% | 0.623 |
| XCEPTION | 98.27% | 0.982 |
| Study | Model | Dramatic | Elegant | Magnetic |
|---|---|---|---|---|
| M. Takagi [50] | ResNet | 0.91 | 0.72 | 0.74 |
| VGG19 | 0.79 | 0.62 | 0.50 | |
| XCEPTION | 0.79 | 0.61 | 0.50 | |
| Inception V3 | 0.73 | 0.55 | 0.39 | |
| VGG16 | 0.78 | 0.58 | 0.45 | |
| Present study | XCEPTION | 0.994 | 0.994 | 0.994 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreno-Armendáriz, M.A.; Calvo, H.; Faustinos, J.; Duchanoy, C.A. Personalized Advertising Design Based on Automatic Analysis of an Individual’s Appearance. Appl. Sci. 2023, 13, 9765. https://doi.org/10.3390/app13179765
Moreno-Armendáriz MA, Calvo H, Faustinos J, Duchanoy CA. Personalized Advertising Design Based on Automatic Analysis of an Individual’s Appearance. Applied Sciences. 2023; 13(17):9765. https://doi.org/10.3390/app13179765
Chicago/Turabian StyleMoreno-Armendáriz, Marco A., Hiram Calvo, José Faustinos, and Carlos A. Duchanoy. 2023. "Personalized Advertising Design Based on Automatic Analysis of an Individual’s Appearance" Applied Sciences 13, no. 17: 9765. https://doi.org/10.3390/app13179765