
Deep Representation of EEG Signals Using Spatio-Spectral Feature Images



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Dataset
3. Methods
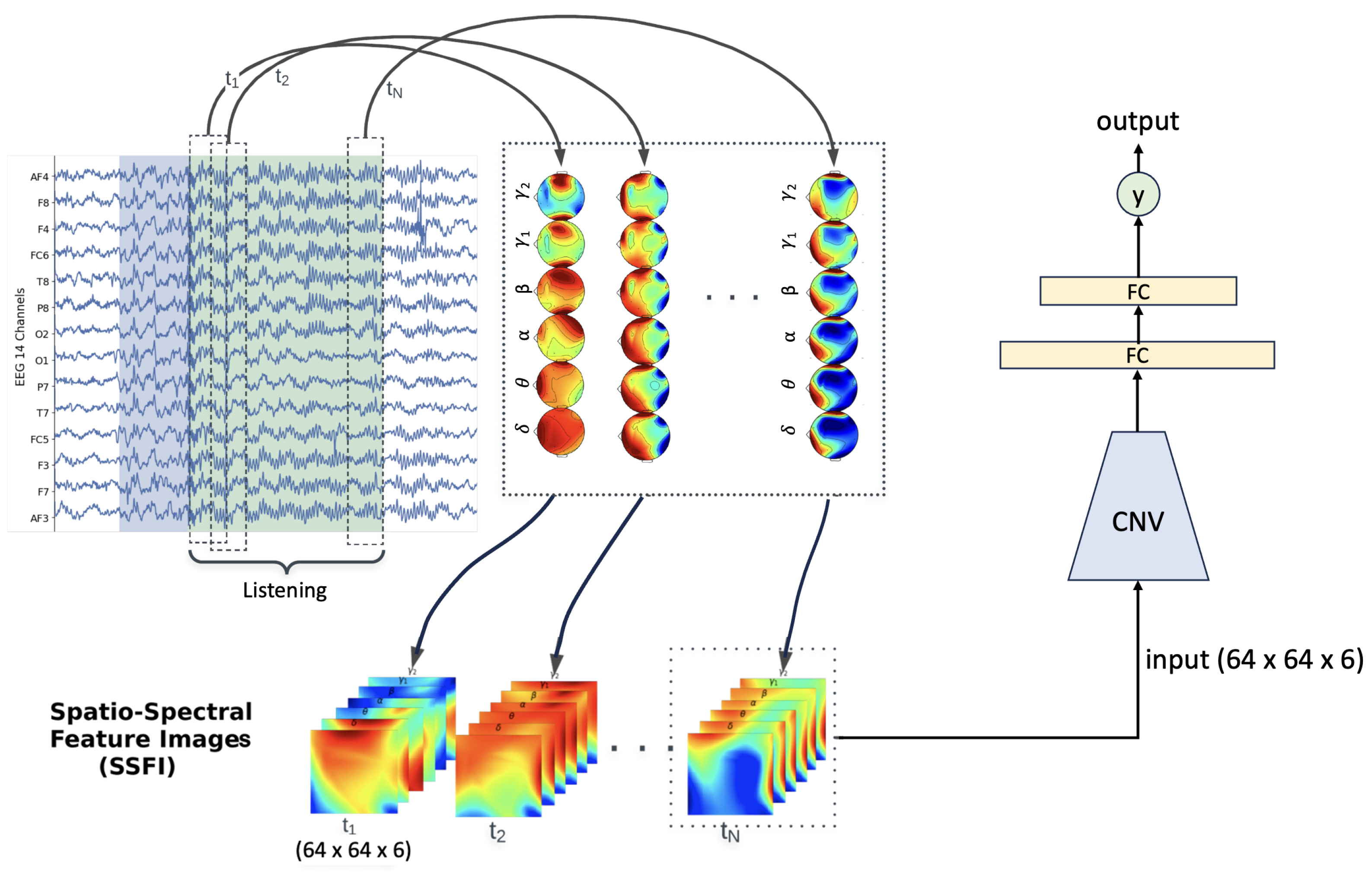
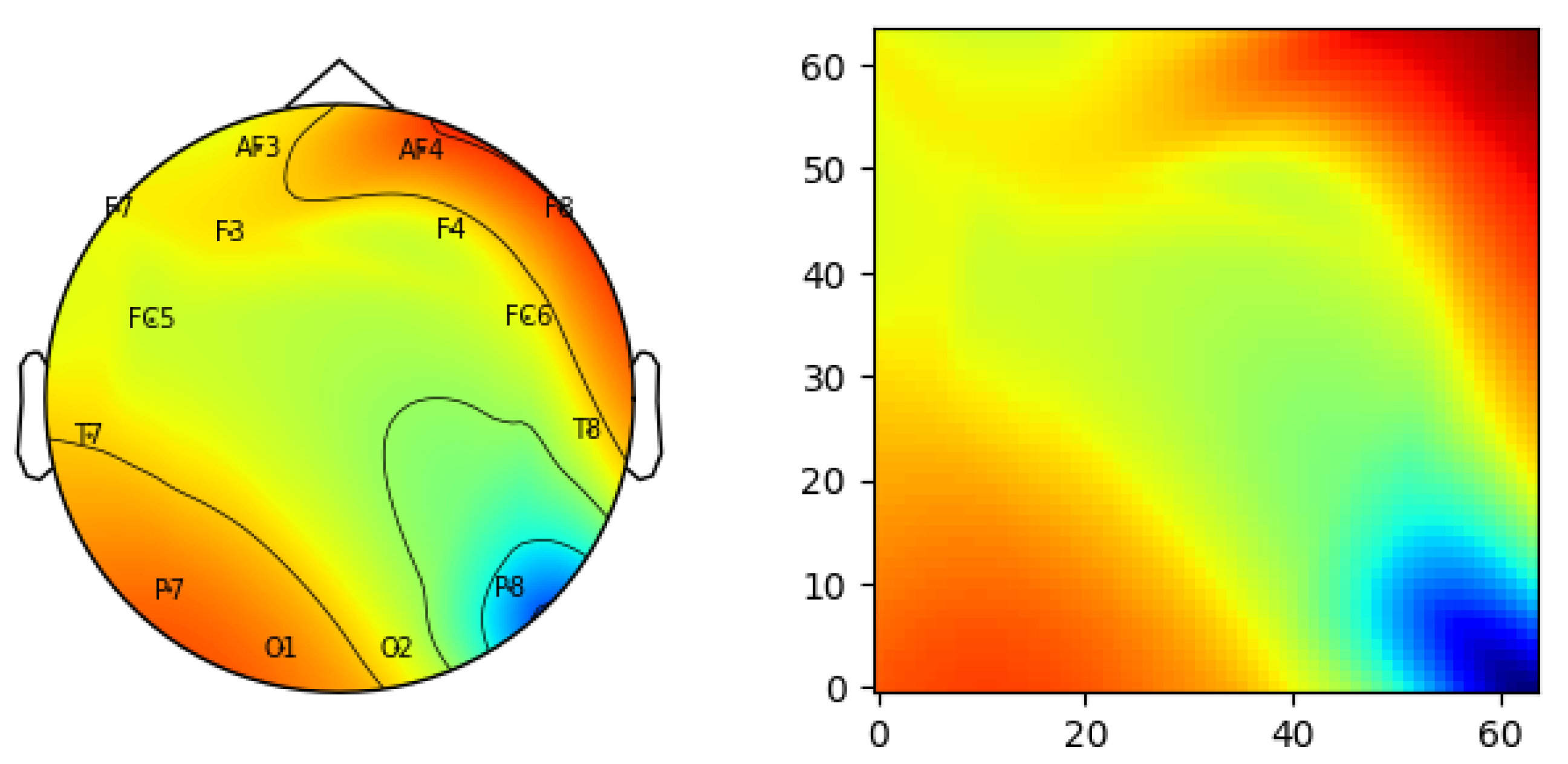
3.1. Spatio-Spectral Feature Image Definition and Generation
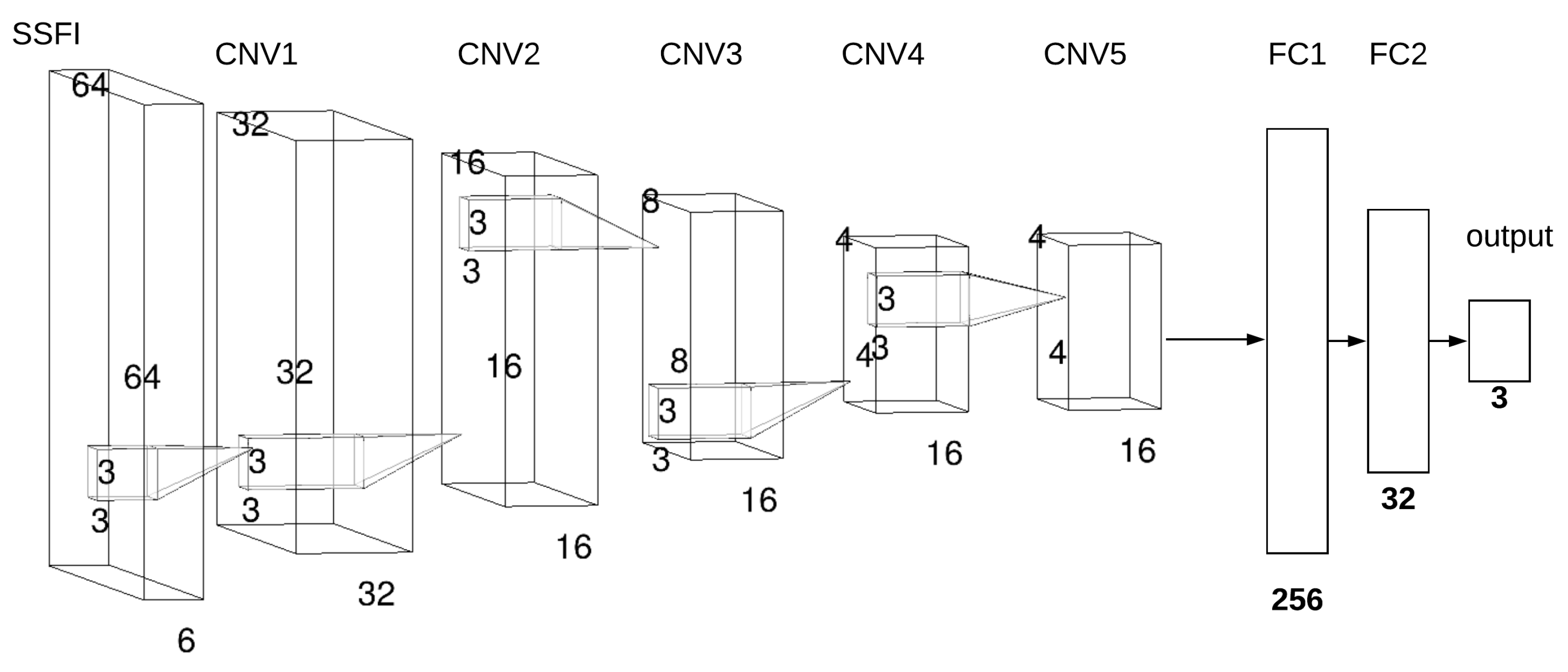
3.2. Neural Network Architecture, Training, and Test
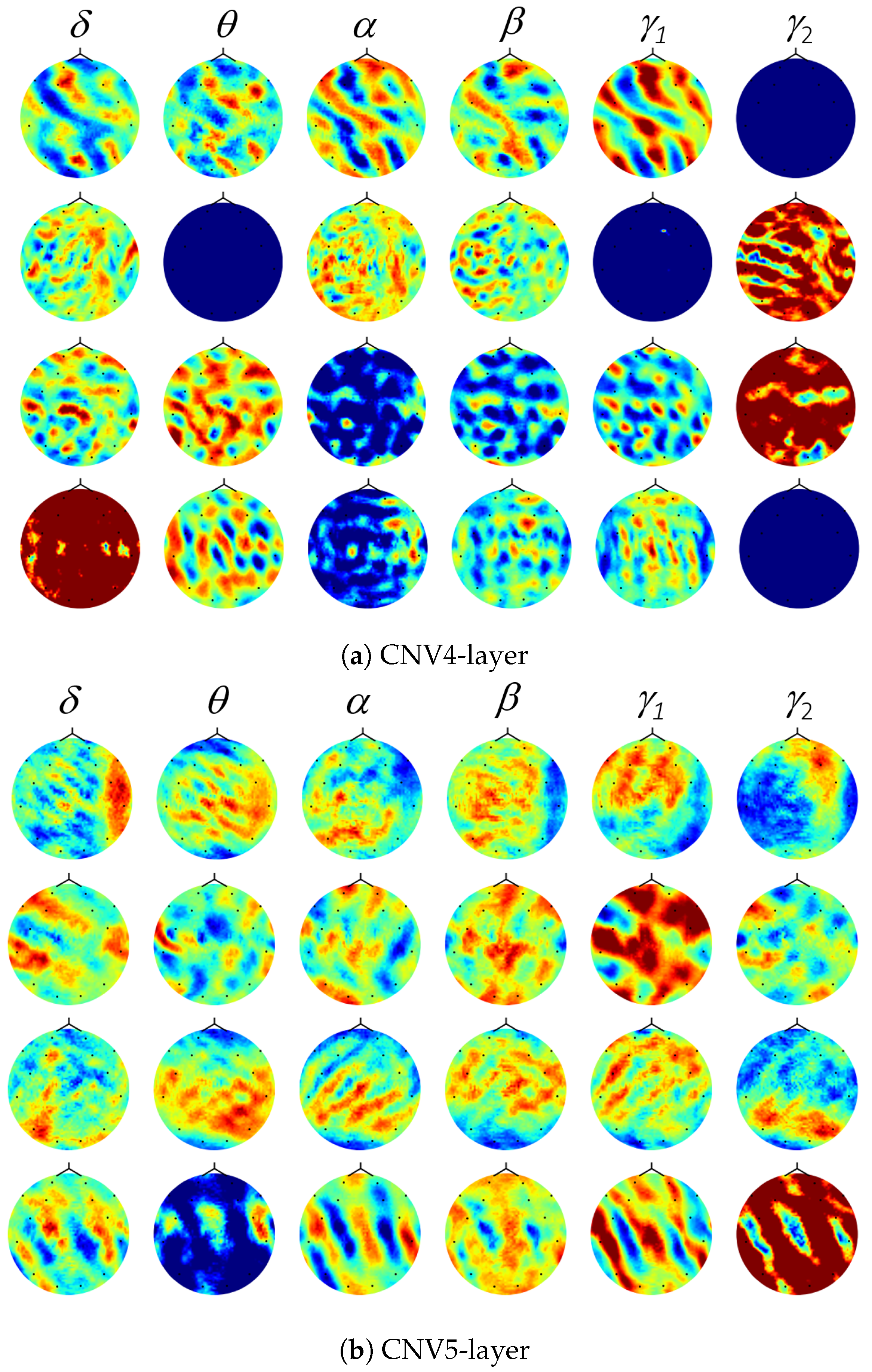
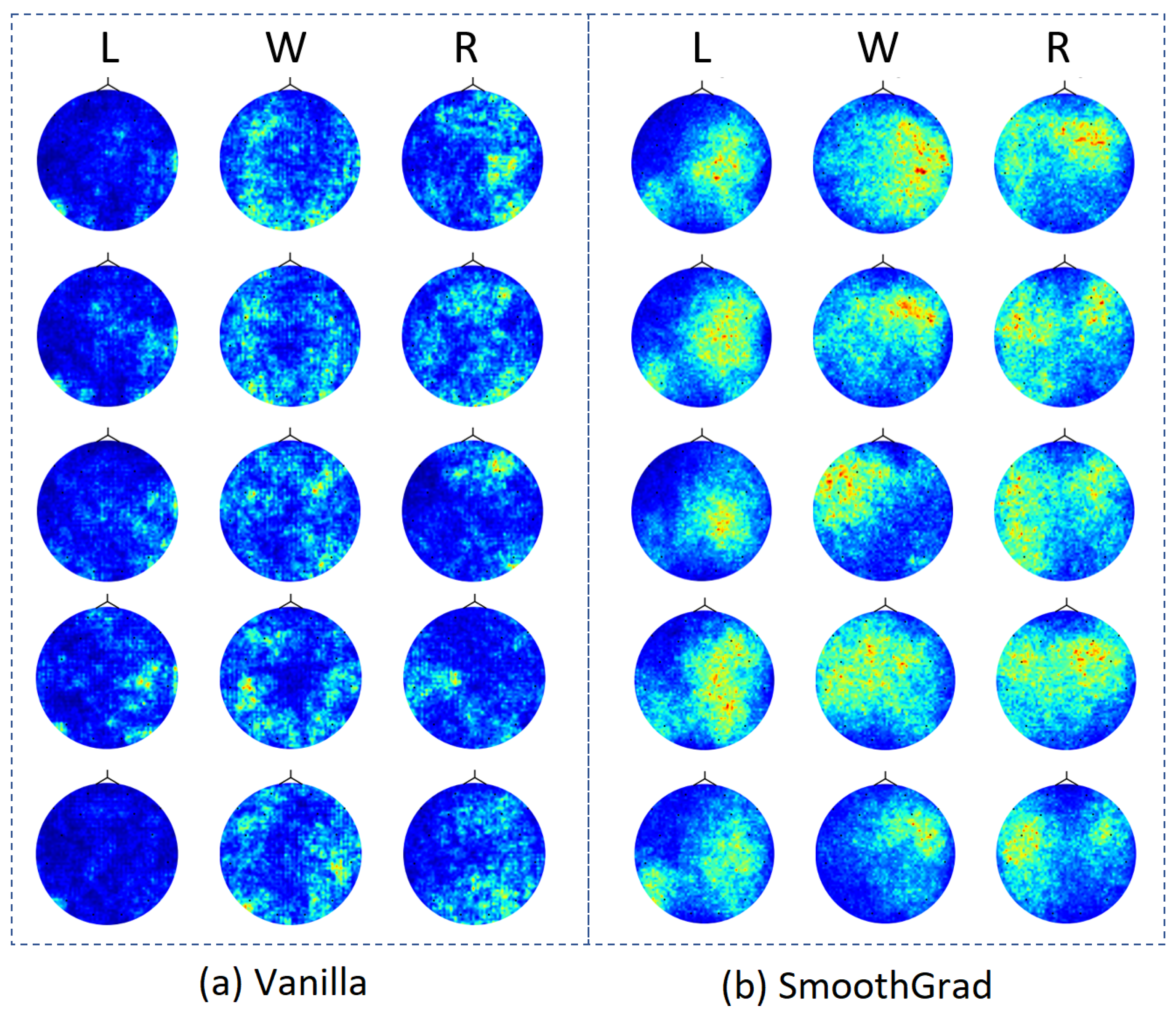
3.3. Deep Representation Analysis
4. Results
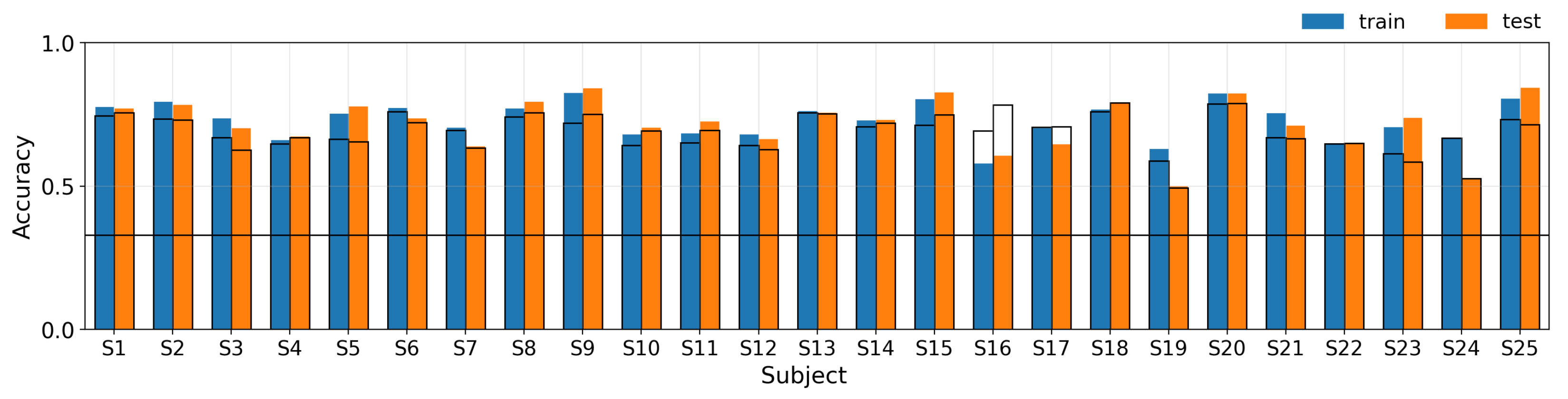
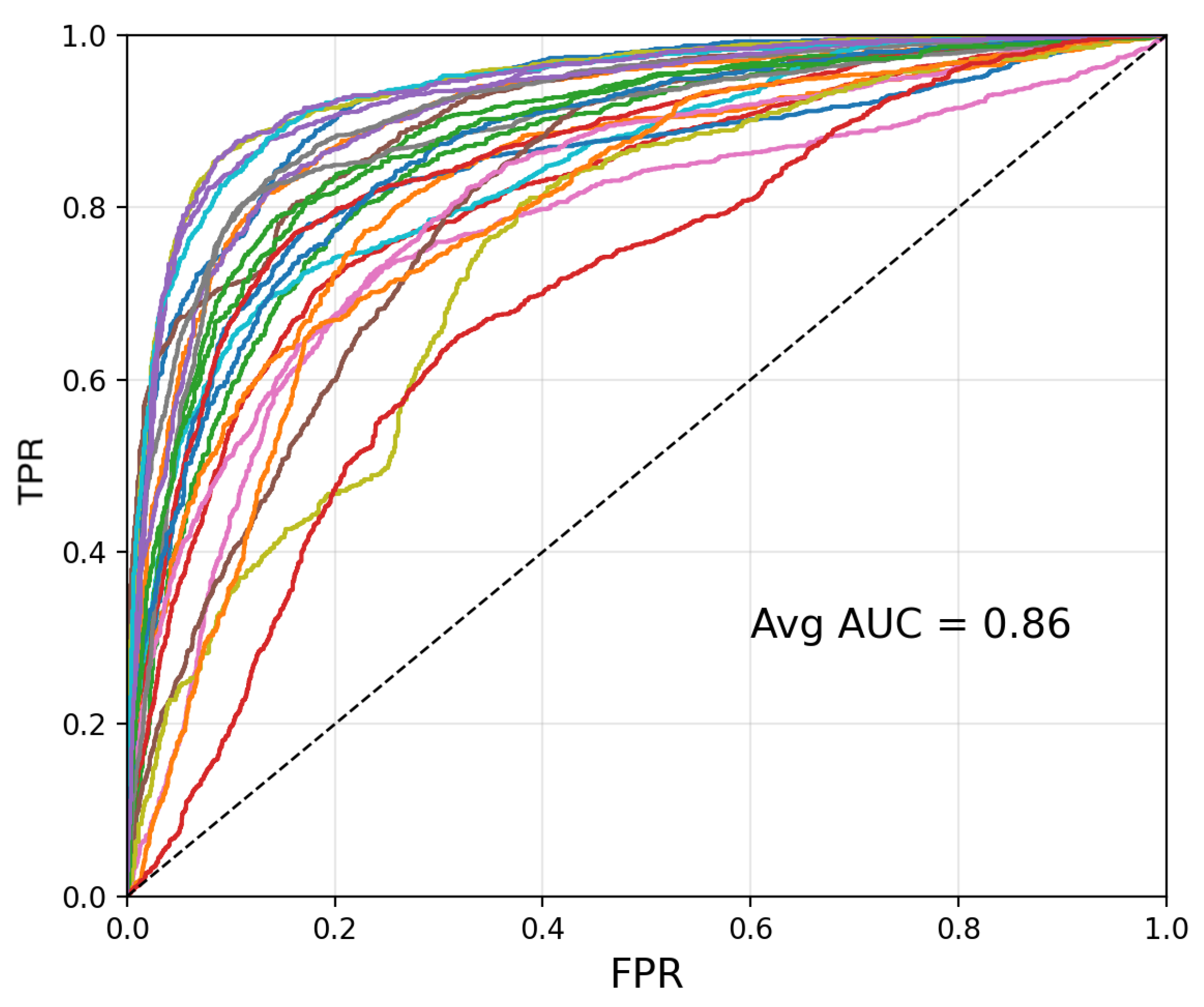
4.1. Individual Subject Model
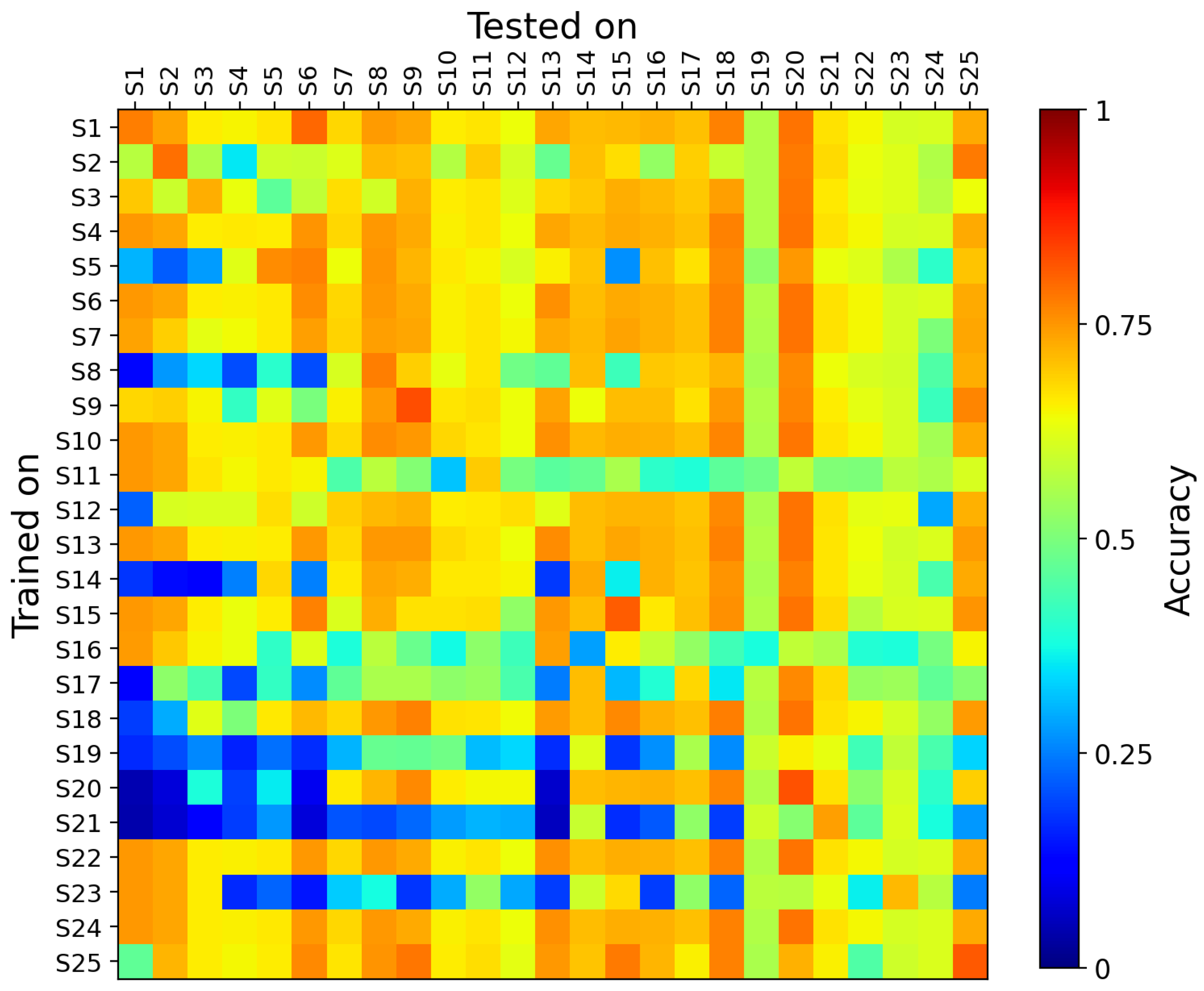
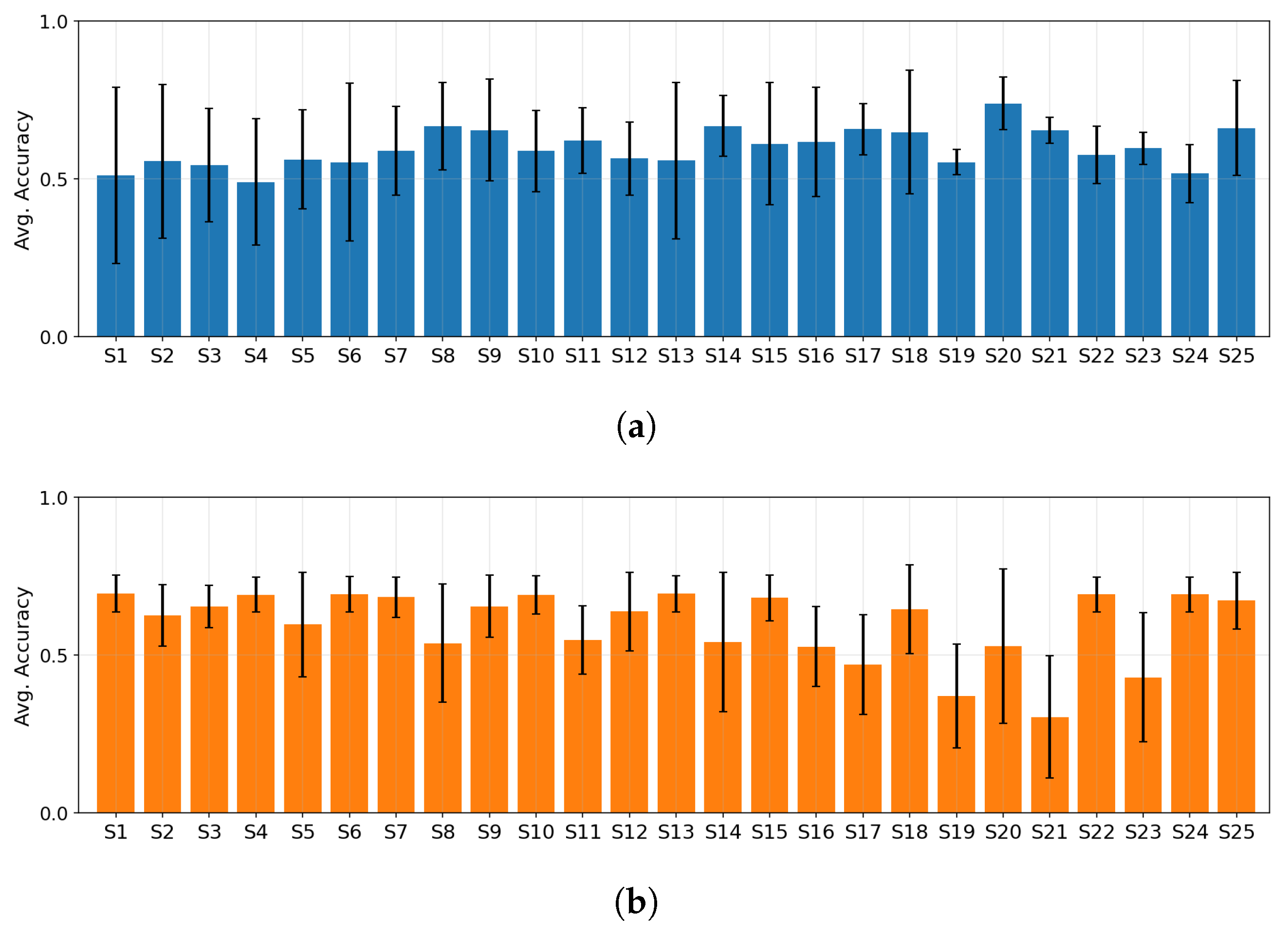
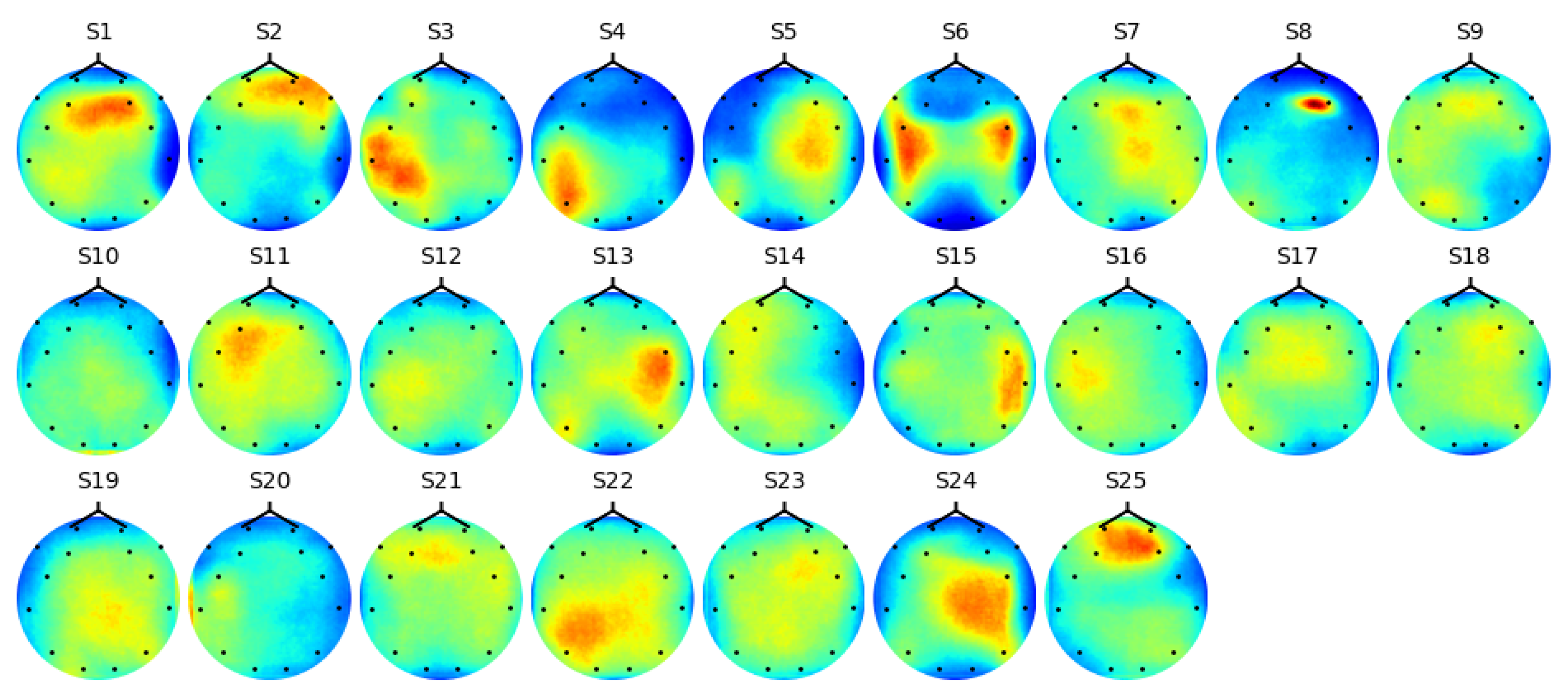
4.2. Inter-Subject Dependency Analysis
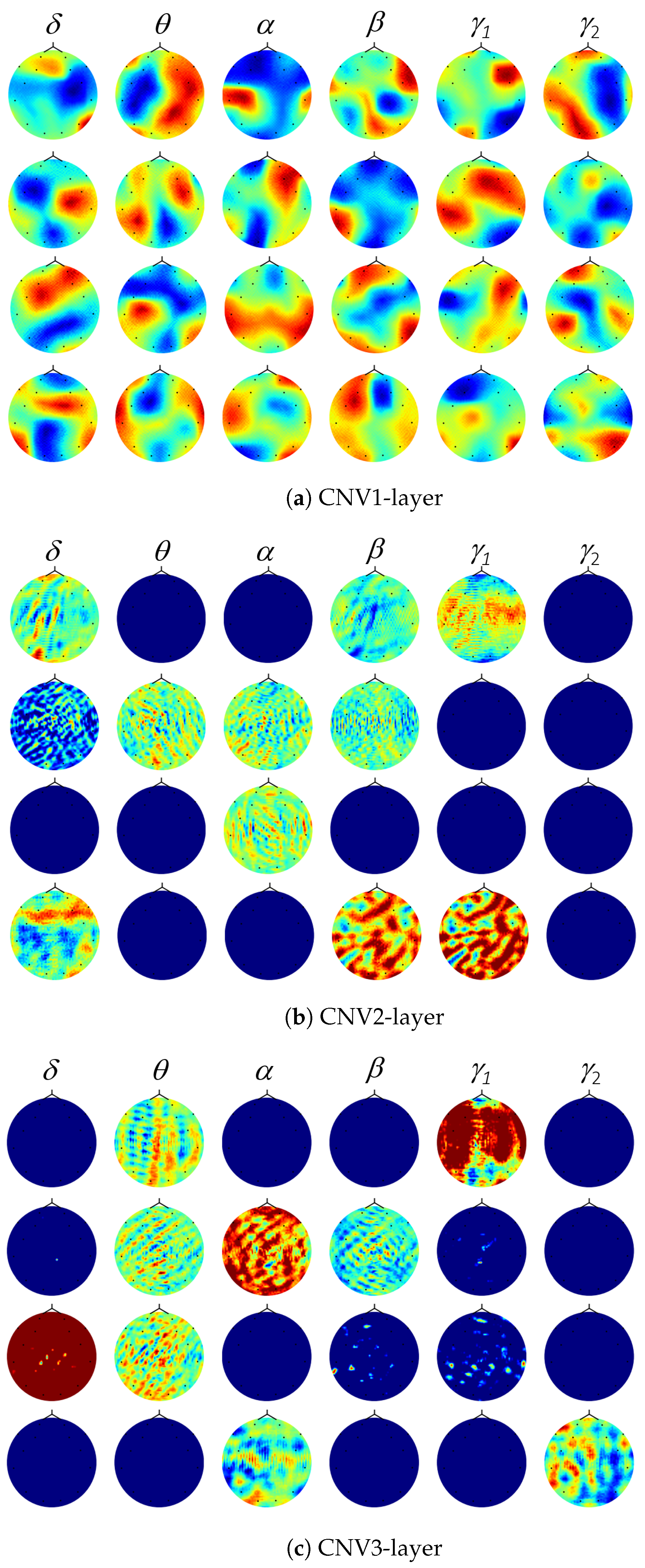
4.3. Deep Representation
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain–Computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef] [PubMed]
- Bellotti, F.; Kapralos, B.; Lee, K.; Moreno-Ger, P.; Berta, R. Assessment in and of serious games: An overview. Adv. Hum. Comput. Interact. 2013, 2013, 136864. [Google Scholar] [CrossRef]
- Paranthaman, P.K.; Bajaj, N.; Solovey, N.; Jennings, D. Comparative evaluation of the EEG performance metrics and player ratings on the virtual reality games. In Proceedings of the 2021 IEEE Conference on Games (CoG), Copenhagen, Denmark, 17–20 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Lazar, N.A.; Luna, B.; Sweeney, J.A.; Eddy, W.F. Combining brains: A survey of methods for statistical pooling of information. Neuroimage 2002, 16, 538–550. [Google Scholar] [CrossRef]
- Tu, W.; Sun, S. A subject transfer framework for EEG classification. Neurocomputing 2012, 82, 109–116. [Google Scholar] [CrossRef]
- Sun, S.; Zhou, J. A review of adaptive feature extraction and classification methods for EEG-based brain-computer interfaces. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; IEEE: Piscataway, NJ, USA, 2014; pp. 1746–1753. [Google Scholar]
- Zhang, Y.Q.; Zheng, W.L.; Lu, B.L. Transfer components between subjects for EEG-based driving fatigue detection. In Proceedings of the International Conference on Neural Information Processing, Istanbul, Turkey, 9–12 November 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 61–68. [Google Scholar]
- Kang, H.; Nam, Y.; Choi, S. Composite common spatial pattern for subject-to-subject transfer. IEEE Signal Process. Lett. 2009, 16, 683–686. [Google Scholar] [CrossRef]
- Devlaminck, D.; Wyns, B.; Grosse-Wentrup, M.; Otte, G.; Santens, P. Multisubject learning for common spatial patterns in motor-imagery BCI. Comput. Intell. Neurosci. 2011, 2011, 8. [Google Scholar] [CrossRef] [PubMed]
- Samek, W.; Meinecke, F.C.; Müller, K.R. Transferring subspaces between subjects in brain–computer interfacing. IEEE Trans. Biomed. Eng. 2013, 60, 2289–2298. [Google Scholar] [CrossRef] [PubMed]
- Lotte, F.; Guan, C. Learning from other subjects helps reducing brain-computer interface calibration time. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 614–617. [Google Scholar]
- Yuan, P.; Chen, X.; Wang, Y.; Gao, X.; Gao, S. Enhancing performances of SSVEP-based brain–computer interfaces via exploiting inter-subject information. J. Neural Eng. 2015, 12, 046006. [Google Scholar] [CrossRef]
- Völker, M.; Schirrmeister, R.T.; Fiederer, L.D.; Burgard, W.; Ball, T. Deep transfer learning for error decoding from non-invasive EEG. In Proceedings of the 2018 6th International Conference on Brain-Computer Interface (BCI), Gangwon, Republic of Korea, 15–17 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Dalhoumi, S.; Dray, G.; Montmain, J. Knowledge transfer for reducing calibration time in brain-computer interfacing. In Proceedings of the 2014 IEEE 26th International Conference on Tools with Artificial Intelligence, Limassol, Cyprus, 10–12 November 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 634–639. [Google Scholar]
- Wan, Z.; Yang, R.; Huang, M.; Zeng, N.; Liu, X. A review on transfer learning in EEG signal analysis. Neurocomputing 2021, 421, 1–14. [Google Scholar] [CrossRef]
- Sanei, S.; Chambers, J.A. EEG Signal Processing; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Lemm, S.; Blankertz, B.; Curio, G.; Muller, K.R. Spatio-spectral filters for improving the classification of single trial EEG. IEEE Trans. Biomed. Eng. 2005, 52, 1541–1548. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef] [PubMed]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2023, 35, 14681–14722. [Google Scholar] [CrossRef]
- Al-Saegh, A.; Dawwd, S.A.; Abdul-Jabbar, J.M. Deep learning for motor imagery EEG-based classification: A review. Biomed. Signal Process. Control. 2021, 63, 102172. [Google Scholar] [CrossRef]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef]
- Zhang, D.; Yao, L.; Zhang, X.; Wang, S.; Chen, W.; Boots, R. EEG-based intention recognition from spatio-temporal representations via cascade and parallel convolutional recurrent neural networks. arXiv 2017, arXiv:1708.06578. [Google Scholar]
- Nurse, E.S.; Karoly, P.J.; Grayden, D.B.; Freestone, D.R. A generalizable brain-computer interface (BCI) using machine learning for feature discovery. PLoS ONE 2015, 10, e0131328. [Google Scholar] [CrossRef]
- Nurse, E.; Mashford, B.S.; Yepes, A.J.; Kiral-Kornek, I.; Harrer, S.; Freestone, D.R. Decoding EEG and LFP signals using deep learning: Heading TrueNorth. In Proceedings of the ACM International Conference on Computing Frontiers, New York, NY, USA, 16–19 May 2016; ACM: New York, NY, USA, 2016; pp. 259–266. [Google Scholar]
- Stober, S.; Sternin, A.; Owen, A.M.; Grahn, J.A. Deep feature learning for EEG recordings. arXiv 2015, arXiv:1511.04306. [Google Scholar]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Chambon, S.; Galtier, M.N.; Arnal, P.J.; Wainrib, G.; Gramfort, A. A deep learning architecture for temporal sleep stage classification using multivariate and multimodal time series. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 758–769. [Google Scholar] [CrossRef] [PubMed]
- Sors, A.; Bonnet, S.; Mirek, S.; Vercueil, L.; Payen, J.F. A convolutional neural network for sleep stage scoring from raw single-channel EEG. Biomed. Signal Process. Control. 2018, 42, 107–114. [Google Scholar] [CrossRef]
- Tjepkema-Cloostermans, M.C.; de Carvalho, R.C.; van Putten, M.J. Deep learning for detection of focal epileptiform discharges from scalp EEG recordings. Clin. Neurophysiol. 2018, 129, 2191–2196. [Google Scholar] [CrossRef]
- Thodoroff, P.; Pineau, J.; Lim, A. Learning robust features using deep learning for automatic seizure detection. In Proceedings of the Machine Learning for Healthcare Conference, Los Angeles, CA, USA, 19–20 August 2016; PMLR: New York, NY, USA, 2016; pp. 178–190. [Google Scholar]
- Ruffini, G.; Ibañez, D.; Castellano, M.; Dubreuil-Vall, L.; Soria-Frisch, A.; Postuma, R.; Gagnon, J.F.; Montplaisir, J. Deep learning with EEG spectrograms in rapid eye movement behavior disorder. Front. Neurol. 2019, 10, 806. [Google Scholar] [CrossRef]
- Zhao, H.; Zheng, Q.; Ma, K.; Li, H.; Zheng, Y. Deep representation-based domain adaptation for nonstationary EEG classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 535–545. [Google Scholar] [CrossRef] [PubMed]
- Tan, C.; Sun, F.; Zhang, W. Deep transfer learning for EEG-based brain computer interface. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Srocessing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 916–920. [Google Scholar]
- Bajaj, N.; Requena-Carrión, J.; Bellotti, F. PhyAAt: Physiology of Auditory Attention to Speech Dataset. arXiv 2020, arXiv:arXiv:2005.11577. [Google Scholar]
- Choi, M.; Jeong, J.J. Comparison of Selection Criteria for Model Selection of Support Vector Machine on Physiological Data with Inter-Subject Variance. Appl. Sci. 2022, 12, 1749. [Google Scholar] [CrossRef]
- Lee, P.; Hwang, S.; Lee, J.; Shin, M.; Jeon, S.; Byun, H. Inter-subject contrastive learning for subject adaptive eeg-based visual recognition. In Proceedings of the 2022 10th International Winter Conference on Brain-Computer Interface (BCI), Gangwon-do, Republic of Korea, 21–23 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Gramfort, A.; Luessi, M.; Larson, E.; Engemann, D.A.; Strohmeier, D.; Brodbeck, C.; Parkkonen, L.; Hämäläinen, M.S. MNE software for processing MEG and EEG data. Neuroimage 2014, 86, 446–460. [Google Scholar] [CrossRef]
- Bajaj, N.; Carrión, J.R.; Bellotti, F.; Berta, R.; De Gloria, A. Automatic and tunable algorithm for EEG artifact removal using wavelet decomposition with applications in predictive modeling during auditory tasks. Biomed. Signal Process. Control. 2020, 55, 101624. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.C.; Vincent, P. Visualizing Higher-Layer Features of a Deep Network; University of Montreal: Montreal, QC, Canada, 2009. [Google Scholar]
- Sau, A.; Giatti, L.; Ng, F.S.; Peters, N.; Shipley, M.; Barreto, S.; Pastika, L.; Ribeiro, A.; Sabino, E.; Ware, J.; et al. 88 Exploring the prognostic significance and important phenotypic and genotypic associations of neural network-derived electrocardiographic features. Heart 2023, 109, A96–A99. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bajaj, N.; Requena Carrión, J. Deep Representation of EEG Signals Using Spatio-Spectral Feature Images. Appl. Sci. 2023, 13, 9825. https://doi.org/10.3390/app13179825
Bajaj N, Requena Carrión J. Deep Representation of EEG Signals Using Spatio-Spectral Feature Images. Applied Sciences. 2023; 13(17):9825. https://doi.org/10.3390/app13179825
Chicago/Turabian StyleBajaj, Nikesh, and Jesús Requena Carrión. 2023. "Deep Representation of EEG Signals Using Spatio-Spectral Feature Images" Applied Sciences 13, no. 17: 9825. https://doi.org/10.3390/app13179825
APA StyleBajaj, N., & Requena Carrión, J. (2023). Deep Representation of EEG Signals Using Spatio-Spectral Feature Images. Applied Sciences, 13(17), 9825. https://doi.org/10.3390/app13179825