
A Few-Shot Automatic Modulation Classification Method Based on Temporal Singular Spectrum Graph and Meta-Learning


Abstract
:1. Introduction
1.1. Motivations
- When the raw and unprocessed signal is directly inputted, the model primarily conducts feature extraction on the original signal. However, the features derived through this approach often encapsulate only a fraction of the original signal’s characteristics, lacking a comprehensive and efficient capability for fulfilling the AMC task.
- Traditional machine learning relies heavily on data-driven pattern recognition and feature extraction, necessitating a substantial pool of well-labeled signal samples. Insufficient training samples can subsequently hamper the model’s generalization performance. In practical application, the intricate and varied nature of communication signals makes accumulating and labeling a substantial number of samples more complex. Frequently, only a limited number of samples are available, engendering a scenario where the model’s utilization of traditional machine learning-based methods might yield predictions with low confidence when it persists in conducting the AMC task under these constraints.
1.2. Related Works
1.2.1. Signal Transformation
1.2.2. Meta-Learning
- The support set, a small example collection, trains the model on the same classes it will be tested on. The model derives insights from this set to update its parameters and apply them to the query set.
- The query set, used for evaluation, tests the model using knowledge acquired from the support set. It guides the model’s training process.
1.3. Contributions
- We propose a novel approach that combines time-series signal visualization with meta-learning to tackle the small sample problem. We transform communication signals into images and employ a metric-based meta-learning method for feature extraction and classification.
- In the signal representation stage, we employ Singular Spectrum Analysis (SSA) to reduce noise and eliminate redundant information in the signals. Subsequently, the signal sequences are transformed into two-dimensional images. This method enhances the exploration of signal content through signal decomposition and reconstruction. In contrast to traditional sequential signal processing methods that only extract features between adjacent time steps, this approach can capture the correlations between any two time points.
- In the classification stage, we adopt a metric-based relation network. The feature embedding module converts samples into high-dimensional feature representations Then, the relation metric module measures the distances between samples. Ultimately, this approach achieves AMC under the small sample condition.
- We conduct simulations on the publicly available RadioML.2018.01a dataset to validate the advantages of the proposed method. Compared to the direct application of traditional machine learning methods for AMC, the method proposed in this paper attains higher recognition accuracy while employing a smaller number of samples. Furthermore, it demonstrates superior recognition capability when contrasted with the conventional approach of representing sequences.
1.4. Organization
2. Data Processing and Network Description
2.1. Signal Model
2.2. Temporal Singular Spectrum Graph
- Preprocessing. For a sequence with length , the sequence is first standardized by the following formula:
- Constructing trajectory matrix. For the given sequence, a sliding window is defined with a window length of , satisfying . Simultaneously, is defined as , which is used to construct the trajectory matrix. The first column of the matrix represents to , the second column represents to , etc., until the -th column represents to . The resulting trajectory matrix is as follows:
- Matrix Reconstruction: Based on the magnitude of the singular values , the number of principal components in the sequence is determined. The left singular vectors corresponding to the largest singular values (i.e., the first columns of matrix ) are selected to construct matrix . Simultaneously, the right singular vectors corresponding to the largest singular values (i.e., the first columns of matrix ) are selected to construct matrix . Then, the reconstruction matrix is obtained.
- Sequence Reconstruction. The reconstructed sequence is obtained by performing anti-diagonal averaging reconstruction on the reconstructed submatrix . Here, . Let and . The reconstruction of sequence can be calculated using the following formula:
- Visualization. The reconstructed sequence is copied times along the column direction, and then the transpose of is obtained as a column vector. This process generates two matrices: one where each row is equal to , and another where each column is equal to . By subtracting these two matrices, a matrix is obtained, representing the Euclidean distance between every pair of points. Similar to a recursive graph, each row and column of matrix contains information about the entire sequence. Finally, the matrix is transformed into a grayscale image using max-min normalization, resulting in the desired image.
2.3. Relation Network
2.3.1. Network Structure
2.3.2. Feature Embedding Module
- The Squeeze part reduces the dimensionality of the input feature maps through global average pooling, transforming them into a fixed-size vector. This vector can be regarded as the global statistical information of the entire feature map, encompassing the overall characteristics of each channel. Specifically, for an input feature map with a size of H × W × C (height × width × number of channels), the Squeeze operation produces a feature map of size 1 × 1 × C.
- The Excitation part is the core component of SENet, which processes the output of the Squeeze operation through a fully connected layer and an activation function. The output size of the fully connected layer is C × r (where r is a tunable scaling factor typically chosen to be small), followed by a ReLU activation function for non-linear mapping. Finally, another fully connected layer restores the size of the feature map to C. This process can be seen as a re-calibration of the feature channels, allowing for the learning of weights for each channel.
2.3.3. Relation Metric Module
3. Simulation Experiments and Analysis
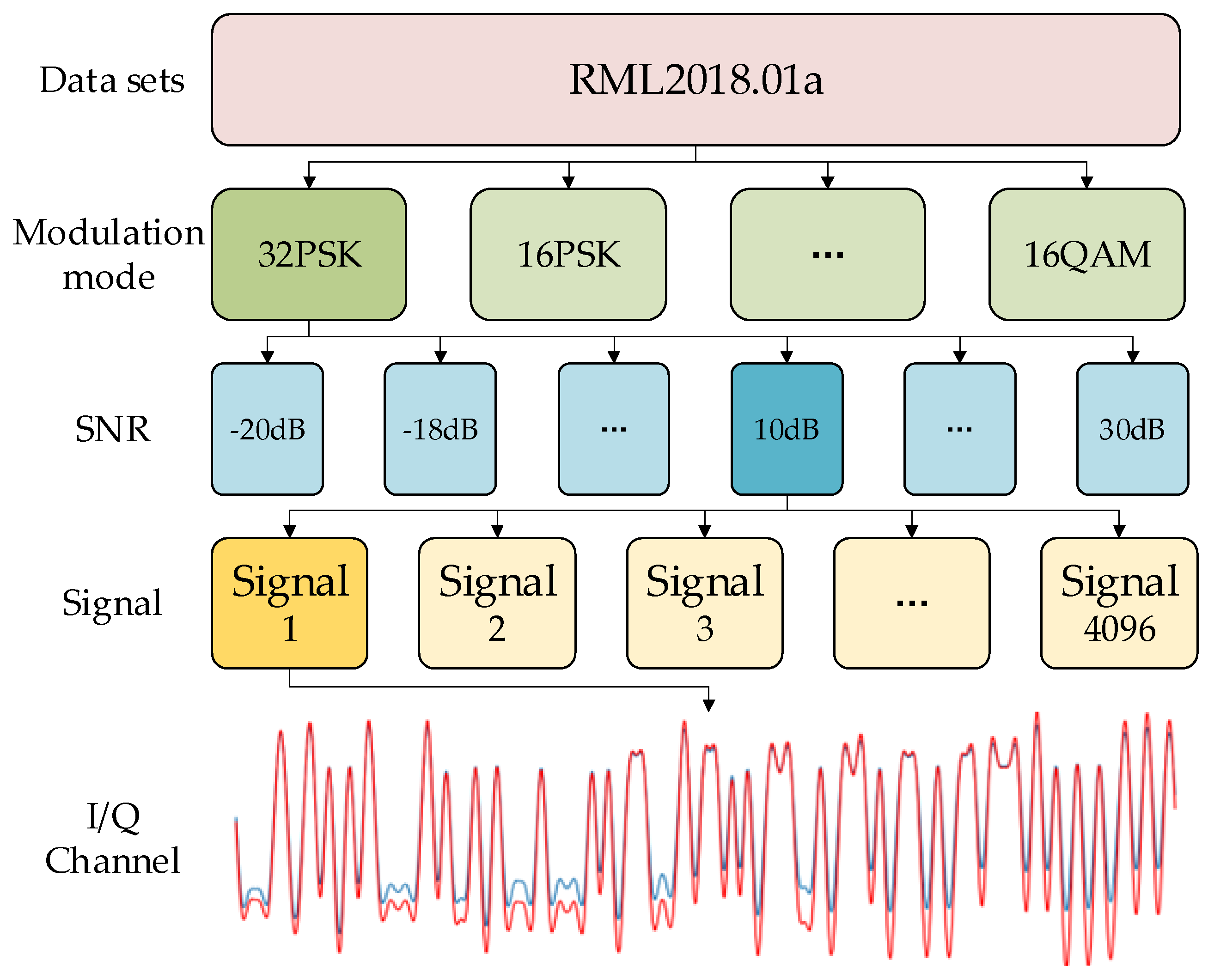
3.1. Simulation Experiment
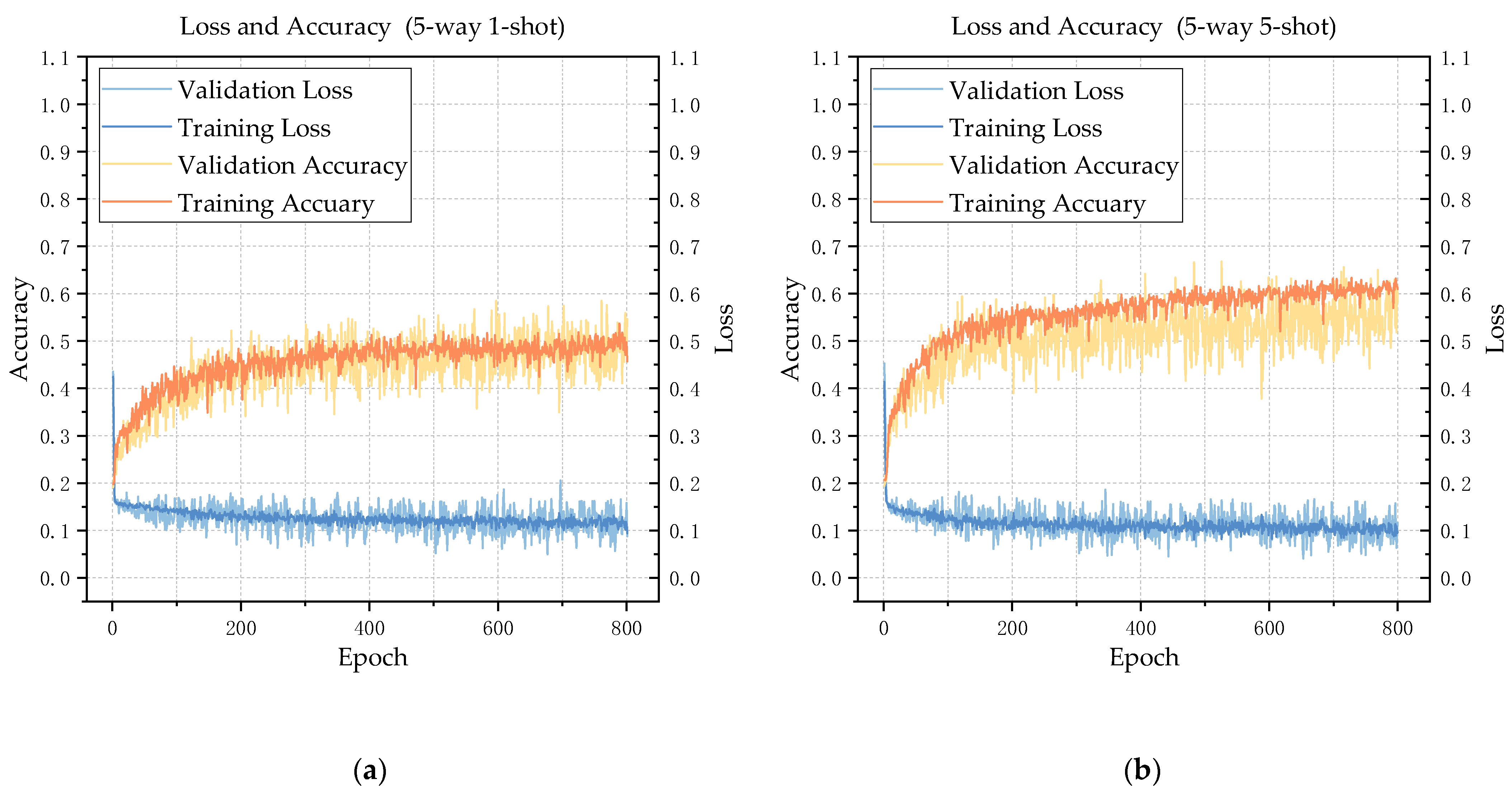
3.2. Model Performance Analysis
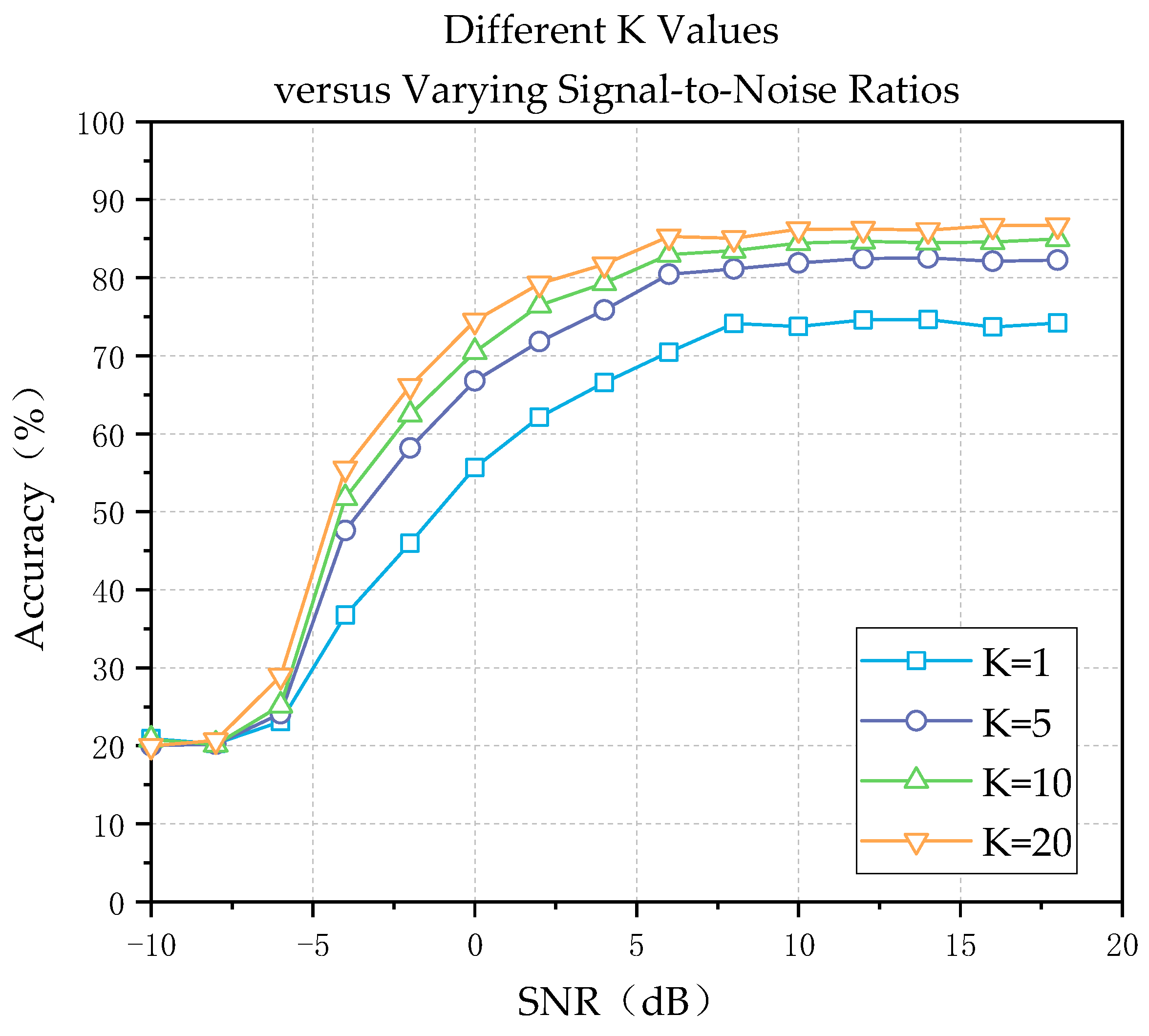
3.3. Performance Comparison with Different Values of K
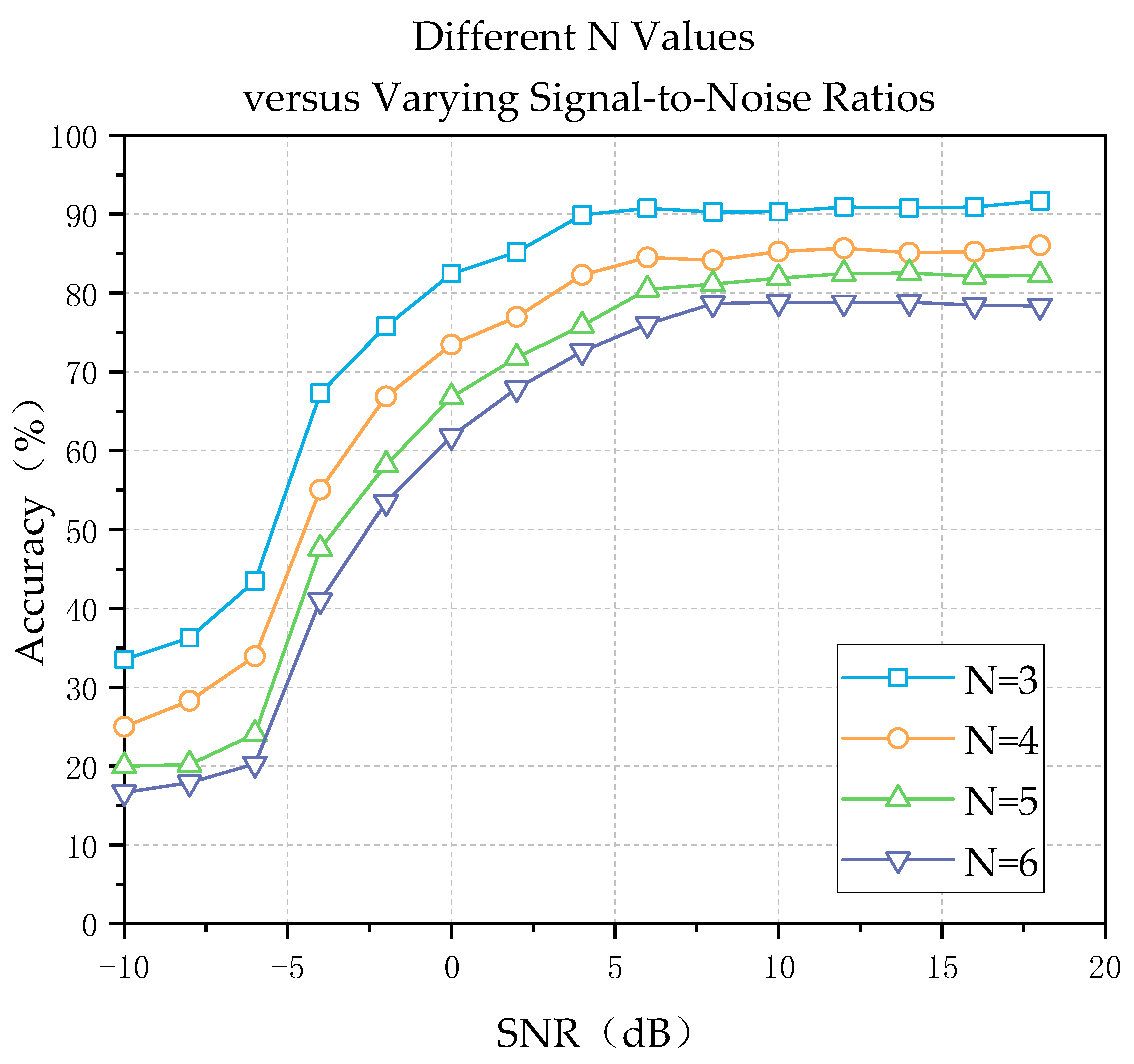
3.4. Performance Comparison for Different Values of N
3.5. Performance Analysis with Traditional Methods
3.6. Comparative Experiment with Other Visualization Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shafi, M.; Molisch, A.F.; Smith, P.J.; Haustein, T.; Zhu, P.; De Silva, P.; Tufvesson, F.; Benjebbour, A.; Wunder, G. 5g: A tutorial overview of standards, trials, challenges, deployment, and practice. IEEE J. Sel. Areas Commun. 2017, 35, 1201–1221. [Google Scholar] [CrossRef]
- Qin, Z.; Zhou, X.; Zhang, L.; Gao, Y.; Liang, Y.C.; Li, G.Y. 20 Years of Evolution from Cognitive to Intelligent Communications. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 6–20. [Google Scholar] [CrossRef]
- Mendis, G.J.; Wei, J.; Madanayake, A. Deep learning-based automated modulation classification for cognitive radio. In Proceedings of the 2016 IEEE International Conference on Communication Systems (ICCS), Shenzhen, China, 14–16 December 2016; IEEE: Shenzhen, China, 2016; pp. 1–6. [Google Scholar]
- Grajal, J.; Yeste-Ojeda, O.; Sanchez, M.A.; Garrido, M.; López-Vallejo, M. Real-time FPGA implementation of an automatic modulation classifier for electronic warfare applications. In Proceedings of the 2011 19th European Signal Processing Conference, Barcelona, Spain, 29 August–2 September 2011; IEEE: Barcelona, Spain, 2011; pp. 1514–1518. [Google Scholar]
- Liao, K.; Zhao, Y.; Gu, J.; Zhang, Y.; Zhong, Y. Sequential convolutional recurrent neural networks for fast automatic modulation classification. IEEE Access 2021, 9, 27182–27188. [Google Scholar] [CrossRef]
- European Centre for Disease Prevention and Control (ECDC); European Food Safety Authority (EFSA); European Medicines Agency (EMA). Ecdc/efsa/ema second joint report on the integrated analysis of the consumption of antimicrobial agents and occurrence of antimicrobial resistance in bacteria from humans and food-producing animals: Joint interagency antimicrobial consumption and resistance analysis (jiacra) report. EFSA J. 2017, 15, e04872. [Google Scholar]
- Zhang, K.; Xu, E.L.; Feng, Z.; Zhang, P. A Dictionary Learning Based Automatic Modulation Classification Method. IEEE Access 2018, 6, 5607–5617. [Google Scholar] [CrossRef]
- Kim, K.; Polydoros, A. Digital modulation classification: The BPSK versus QPSK case. In Proceedings of the MILCOM 88, 21st Century Military Communications—What’s Possible?’. Conference Record. Military Communications Conference, Piscataway, NJ, USA, 23–26 October 1988; IEEE: Piscataway, NJ, USA, 1988; pp. 431–436. [Google Scholar]
- Lay, N.E.; Polydoros, A. Modulation classification of signals in unknown ISI environments. In Proceedings of the MILCOM ’95, Piscataway, NJ, USA, 5–8 November 1995; IEEE: Piscataway, NJ, USA, 1995; pp. 170–174. [Google Scholar]
- Panagiotou, P.; Anastasopoulos, A.; Polydoros, A. Likelihood ratio tests for modulation classification. In MILCOM 2000 Proceedings. 21st Century Military Communications. Architectures and Technologies for Information Superiority (Cat. No.00CH37155); IEEE: Piscataway, NJ, USA, 2000; pp. 670–674. [Google Scholar]
- Zhang, J.; Wang, B.; Wang, Y.; Liu, M. An Algorithm for OFDM Signal Modulation Recognition and Parameter Estimation under α-Stable Noise. J. Electron. 2018, 46, 1390–1396. [Google Scholar]
- Yan, X.; Feng, G.; Wu, H.C.; Xiang, W.; Wang, Q. Innovative robust modulation classification using graph-based cyclic-spectrum analysis. IEEE Commun. Lett. 2017, 21, 16–19. [Google Scholar] [CrossRef]
- Majhi, S.; Gupta, R.; Xiang, W.; Glisic, S. Hierarchical hypothesis and feature-based blind modulation classification for linearly modulated signals. IEEE Trans. Veh. Technol. 2017, 66, 11057–11069. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional radio modulation recognition networks. In Proceedings of the Engineering Applications of Neural Networks: 17th International Conference, EANN 2016, Aberdeen, UK, 2–5 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 213–226. [Google Scholar]
- Huynh-The, T.; Hua, C.-H.; Pham, Q.-V.; Kim, D.-S. MCNet: An efficient CNN architecture for robust automatic modulation classification. IEEE Commun. Lett. 2020, 24, 811–815. [Google Scholar] [CrossRef]
- Perenda, E.; Rajendran, S.; Pollin, S. Automatic modulation classification using parallel fusion of convolutional neural networks. In Proceedings of the BalkanCom’ 19, Skopje, North Macedonia, 10–12 June 2019. [Google Scholar]
- Peng, C.; Cheng, W.; Song, Z.; Dong, R. A noise-robust modulation signal classification method based on continuous wavelet transform. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 745–750. [Google Scholar]
- Wang, Z.; Oates, T. Imaging Time-Series to Improve Classification and Imputation. arXiv 2015, arXiv:1506.00327. [Google Scholar]
- Hatami, N.; Gavet, Y.; Debayle, J. Classification of Time-Series Images Using Deep Convolutional Neural Networks. In Proceedings of the 10th International Conference on Machine Vision (ICMV 2017), Vienna, Austria, 13–15 November 2017. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25 (NIPS 2012); Neural Information Processing Systems Foundation: San Diego, CA, USA, 2012. [Google Scholar]
- Cha, X.; Peng, H.; Qin, X. Modulation Recognition Method Based on Multi-Branch Convolutional Neural Networks. J. Commun. 2019, 40, 30–37. (In Chinese) [Google Scholar]
- Liu, M.Q.; Zheng, S.F.; Li, B.B. MPSK Signal Modulation Recognition Based on Deep Learning. J. Natl. Univ. Def. Technol. 2019, 41, 153–158. (In Chinese) [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one-shot learning. In Advances in Neural Information Processing Systems 29 (NIPS 2016); Neural Information Processing Systems Foundation: San Diego, CA, USA, 2016. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems 30; Neural Information Processing Systems Foundation: San Diego, CA, USA, 2017. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Dai, R.; Huang, J.; Yao, Y.; Gao, Y.; Ning, F.; Feng, Z. Automatic modulation classification using gated recurrent residual network. IEEE Internet Things J. 2020, 7, 7795–7807. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Output Shape |
|---|---|---|
| Input | 3 × 84 × 84 | |
| 1 | Conv2d | 64 × 82 × 82 |
| BatchNorm2d | 64 × 82 × 82 | |
| ReLU | 64 × 82 × 82 | |
| MaxPool2d | 64 × 41 × 41 | |
| SEBlock | 64 × 41 × 41 | |
| 2 | Conv2d | 64 × 39 × 39 |
| BatchNorm2d | 64 × 39 × 39 | |
| ReLU | 64 × 39 × 39 | |
| MaxPool2d | 64 × 19 × 19 | |
| 3 | SEBlock | 64 × 19 × 19 |
| Conv2d | 64 × 19 × 19 | |
| BatchNorm2d | 64 × 19 × 19 | |
| ReLU | 64 × 19 × 19 | |
| SEBlock | 64 × 19 × 19 | |
| 4 | Conv2d | 64 × 19 × 19 |
| BatchNorm2d | 64 × 19 × 19 | |
| ReLU | 64 × 19 × 19 | |
| SEBlock | 64 × 19 × 19 |
| Layer | Type | Output Shape |
|---|---|---|
| Input | 128 × 19 × 19 | |
| 1 | Conv2d | 64 × 17 × 17 |
| BatchNorm2d | 64 × 17 × 17 | |
| ReLU | 64 × 17 × 17 | |
| MaxPool2d | 64 × 8 × 8 | |
| 2 | Conv2d | 64 × 6 × 6 |
| BatchNorm2d | 64 × 6 × 6 | |
| ReLU | 64 × 6 × 6 | |
| MaxPool2d | 64 × 3 × 3 | |
| 3 | Linear | 8 |
| 4 | Linear | 1 |
| Modulation Type | |
|---|---|
| Train Set | 16APSK FM GMSK 32APSK OQPSK 8PSK AM-SSB-SC 4ASK 64QAM 16PSK 64APSK 128QAM AM-SDB-SC AM-DSB-WC 256QAM OOK 16QAM |
| Test Set | 32PSK 32QAM 8ASK BPSK 128APSK QPSK AM-SSB-WC |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Xu, H.; Shi, Y.; Zhang, Y.; Zhao, S. A Few-Shot Automatic Modulation Classification Method Based on Temporal Singular Spectrum Graph and Meta-Learning. Appl. Sci. 2023, 13, 9858. https://doi.org/10.3390/app13179858
Yang H, Xu H, Shi Y, Zhang Y, Zhao S. A Few-Shot Automatic Modulation Classification Method Based on Temporal Singular Spectrum Graph and Meta-Learning. Applied Sciences. 2023; 13(17):9858. https://doi.org/10.3390/app13179858
Chicago/Turabian StyleYang, Hanhui, Hua Xu, Yunhao Shi, Yue Zhang, and Siyuan Zhao. 2023. "A Few-Shot Automatic Modulation Classification Method Based on Temporal Singular Spectrum Graph and Meta-Learning" Applied Sciences 13, no. 17: 9858. https://doi.org/10.3390/app13179858
APA StyleYang, H., Xu, H., Shi, Y., Zhang, Y., & Zhao, S. (2023). A Few-Shot Automatic Modulation Classification Method Based on Temporal Singular Spectrum Graph and Meta-Learning. Applied Sciences, 13(17), 9858. https://doi.org/10.3390/app13179858