1. Introduction
The unprecedented growth of the Internet of Things (IoT) has caused wireless sensor networks (WSNs) to receive considerable attention from the research community. WSNs consist of hundreds of limited-resource sensors connected via wireless links. The main purpose of WSN systems is to collect information about their surroundings. First, the sensor nodes gather data from the environment. Subsequently, they transfer these data to a base station (BS) or sink node for processing. Researchers worldwide have been interested in WSNs owing to their low cost and wide variety of applications. WSNs can be used in many terrains, such as land [
1], underground [
2], and underwater [
3]. They also offer great promise for a variety of applications, such as military target tracking and surveillance [
4,
5], natural disaster relief [
6,
7], and biomedical health monitoring [
8,
9].
It is difficult to monitor every sensor node because the majority of them are located in areas that are not easily accessible. Therefore, sensors may malfunction or be exposed to various factors. This leads to noise issues when the WSN operates, which significantly affects the system performance. One study [
10] shows that the WSN performance is significantly degraded when receiving and transmitting data via wireless channels that are influenced by noise. The network may experience data loss or corruption.
Many different noise-causing factors exist, and each has a different impact on the system, depending on the environment and the system itself. Therefore, studying the effects of noise is critical for increasing the effectiveness of the entire system. Various sources of noise can interfere with wireless networks. Generally, the noise is caused by internal or external events. Internal events are factors inside the WSN system that produce noise, and they occur when sensor nodes gather and measure information from their surroundings. In contrast, external events are noise-causing factors from the outside. These could include environmental changes, the sudden appearance of an obstruction between the sensor node and the base station, etc. External events mainly impact WSNs when transmitting data from the sensor nodes to the sink nodes.
Although noise reduction in WSNs is not a new research topic, very few studies have specifically investigated noise caused by external events. This motivated us to carefully consider the noise caused by harsh weather conditions, including rain, snow, and fog. These weather conditions were modeled as attenuation models. The impact of these unfavorable weather conditions was considered when data were transferred from the sensor nodes to a sink node. This noise can negatively affect the reliability of the data because it causes some data packets to be lost when transferring from the sensor nodes to the base station. The missing data packets significantly affect the completeness of the data received by the sink node.
Traditional methods to prevent missing data require the sensor to resend the packet data. However, this solution is not desirable because of energy loss, communication delay, and inefficiency. In recent years, missing data reconstruction has become the preferred approach. The process of missing data reconstruction involves the recovery or reconstruction of missing data through the utilization of previously collected data points [
11]. Many studies use algorithms for data recovery. However, most of them do not efficiently use the data from readings from the past, present, and neighborhood because the proposed algorithms are relatively simple and ineffective.
In [
12], the authors proposed a data reconstruction algorithm that replaces the missing data with the average of the data series, relying on its own data history. This is quite straightforward. An approach based on machine learning was proposed to address this problem by exploring the correlation between data in the sensors [
13]. However, traditional machine learning algorithms only calculate the relationship between data from the same sensor and ignore data from neighboring sensors. Therefore, a reconstruction approach based on a convolutional neural network (CNN) emerges as a potential approach for utilizing multiple directions of data from multiple sensors.
A CNN combined with an autoencoder (CAE) is a popular model for reconstructing missing data. This model takes advantage of the spatiotemporal correlations in sensor data; thus, its performance should be better than that of existing data recovery methods. Therefore, in this study, we employed a CAE to address the loss of data due to noise.
In a normal CAE model, before training, the convolution layer and dense layer weights are initialized randomly. However, random weight initialization may cause the optimized loss function to drop into weak local optima when the training is complete. As a result, the performance of the CAE is significantly diminished. Therefore, we proposed a stacked convolutional autoencoder (SCAE), which is more advanced. This technique pretrains the initial weights before the learning model employs them in the training process. Therefore, this method can obtain a stronger local optimum compared with a traditional CAE. Finally, we compared the performance of the SCAE with other available data reconstruction techniques in terms of error.
In addition to external noise, in this research, we also consider the impact of noise caused by internal events, specifically thermal noise. The noise corrupts the data sent to the sink node, which also decreases the data transmission reliability. The proposed SCAE not only solves the problem of losing data from external event noise but also revises data changed by internal events.
The main contributions of this study are as follows:
We analyzed the impact of noise caused by harsh weather conditions, such as rain, snow, and fog. We also considered the effect of noise due to internal factors, such as thermal noise.
We successfully adopted a stacked convolutional autoencoder (SCAE) to reconstruct the data affected by this noise.
We conducted extensive experiments to demonstrate the outstanding performance of the proposed model in terms of training and testing errors.
The remaining sections of this paper are structured as follows: In
Section 2, we discuss the recent data reconstruction investigations. Internal and external noise models are introduced in
Section 3. The proposed framework for data reconstruction is presented in
Section 4. The experiment conducted to evaluate the proposed model is described in
Section 5. The analysis of the contributions of this study is presented in
Section 6. The paper concludes in
Section 7.
4. Methodology
As shown in
Figure 3, our architecture consists of two main phases, namely, data processing and data reconstruction. During the data preprocessing phase, the input data obtained from several sensors will be collected and combined into a two-dimensional form. This procedure facilitates the incorporation of temporal attributes and the interconnection of sensors within the incoming data. During the data reconstruction phase, the processed data serve as the primary reference. The proposed model is used for the purpose of extracting intrinsic features while efficiently eliminating both internal and external noise.
4.1. Data Preprocessing
The input data play an important role in the CAE architecture for data reconstruction. To efficiently use the CAE, we propose to format the input data as a combination of data from multiple sensors in the WSN system. We thereby utilize a temporal data structure that combines a historical record and the relationship between neighboring sensors. At each sample time, the sensor measures the data from the environment and transmits it to the central sensor via a wireless channel.
We set
N as the number of samples used to build the data for the training process. By employing sequential data, we can utilize historical records to explore the relationship between data in contiguous time samples in the same sample interval for the training process. Thus, the data of the
i-th sensor
can be expressed as follows:
where
denotes the received data of sensor
at the
n-th sample time. We set
M as the number of sensors required to obtain data from the environment.
Obviously, in addition to considering the relationship between data on the same sensor, the relationship between sensors also needs to be considered. Therefore, it motivates us to combine the data of
M sensors by formatting them as a two-dimensional (2D) array for the input data. Therefore, input data
A, formatted for the CAE networks, is illustrated in
Figure 4 and expressed as
Therefore, a CAE architecture was utilized to exploit the input data as a 2D array for the training process. The CAE architecture for reconstruction is presented in detail in the following subsection.
4.2. Convolutional Autoencoder for Data Reconstruction
A reconstruction method called an autoencoder (AE) [
30] attempts to learn an approximation to the identity function, that is,
, where
x is the input and
is the output. The bottleneck layer contains fewer nodes than the previous layers to obtain a representation of the input. The bottleneck layer encodes the underlying data structure (typically in compressed form). Subsequently, the encoder layers compress the data, and the decoder layers decompress it.
Unlike artificial neural networks, the AE does not use information from the area around the input data. In contrast to other neural network designs that employ stacking, the convolution process takes advantage of the spatial and temporal data structures to find correlations more quickly. Two ideas, convolution and autoencoding, are combined [
31] to find underlying features in the data while retaining the neighborhood relationships between the pixels. They begin with convolutional layers that extract features, followed by bottleneck layers that employ feature maps to compress the data. The decoder, which completes the reconstruction, follows. Owing to the preservation of the 2D input data structure and the fact that each feature does not need to be connected to the global scale, a CNN-based AE (CAE) is far more resilient than AE and can rebuild images using small patches rather than requiring complete image information [
32].
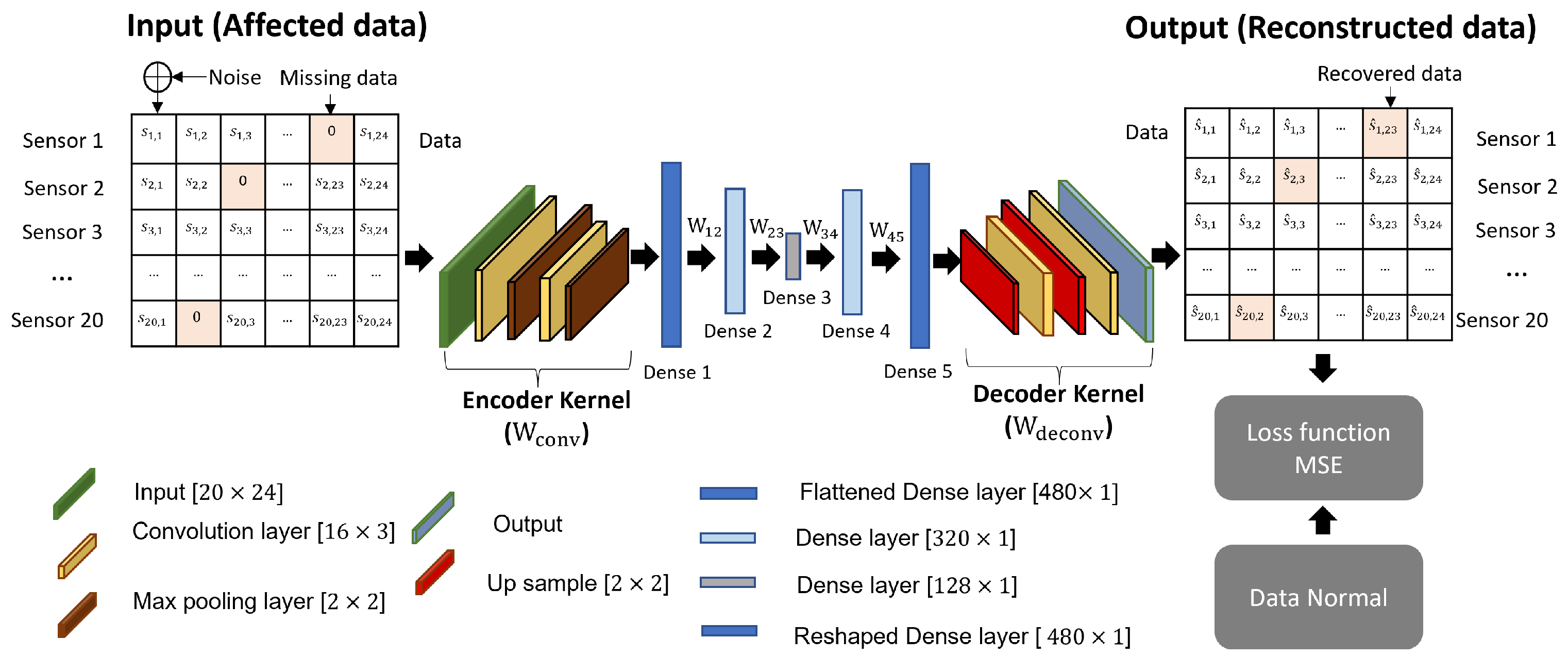
A CAE model, which is a powerful tool for compressing and reconstructing data, is described in
Figure 5. The model is made up of two main kernel networks, the encoder and decoder, which work together to encode and decode data, respectively. Convolution layers are used in both the encoder and decoder kernels to extract the necessary information from the input data and reconstruct it using the bottleneck layer.
To further improve the performance of the AE model, dense layers are employed between the AE and decoder kernels. These layers serve to enhance the encoding and decoding processes, thereby improving the overall performance of the network for data reconstruction. In this study, careful consideration was given to the number of dense layers used in the model. After evaluating performance, it was determined that five dense layers provided optimal results. Notably, a symmetric dense layer network is used for encoding and decoding purposes, ensuring that the number of nodes in dense layers 1 and 5 is equal, and layers 2 and 4 are equal. By carefully considering the structure of the CAE model, including the use of convolution and dense layers, this study has successfully developed a powerful tool for data reconstruction. As seen in
Figure 5, the affected data from 20 sensors
are composed of the missing data due to the extreme weather conditions and noise due to internal events. After the training process, the affected data are reconstructed to become the data
as close to the data
as possible.
In the training process, the loss function of the mean squared error (MSE) is used and minimized by the CAE network model to make the output data
approximate the ground truth
Y as closely as possible. This can be expressed as follows:
where
denotes the number of training data points in each batch.
Backpropagation is used to update the weights of the layers using the gradient descent method, as follows:
where
denotes the learning rate of the training process. In addition,
and
denote the weights of the convolutional layers in the encoder and decoder kernels, respectively. Furthermore,
,
, and
correspond to the weights between dense layers
, and
, respectively.
4.3. Proposed Stacked Convolutional Autoencoder for Data Reconstruction
To train a conventional CAE, the weights of the convolution and dense layers must be randomly initialized before training. However, randomly initializing the weights leads to an optimized loss function that is prone to falling into weak local optima after finishing training. Consequently, the performance of the CAE is significantly degraded.
To address this problem, we propose an SCAE model for efficiently reconstructing problems caused by external and internal events. Specifically, our proposed model is composed of two AE subnets, such as subnets AE 1 and AE 2, which are trained to obtain the optimal weights. After each subnet is trained, the complete initial AE network uses alternative weights from the AE subnets for the training process. The architecture of the proposed model is illustrated in
Figure 6.
The structure of subnet AE 1 is composed of the encoder and decoder kernels from the initial CAE network; they contain weights and , respectively. The structure of subnet AE 2 is composed of the dense layers of the initial CAE network, which contain weights , , and , respectively. Based on the stacked AE framework, the first step is to train subnet AE 1 to obtain the weights and . Subsequently, subnet AE 2 is trained using the trained subnet AE 1 to obtain , and . Finally, the entire SCAE network is trained using the pretrained weights as the initial weights. The training process is presented in detail below.
4.3.1. Step 1: Recursive Pretraining of the Weights
(1) Training subnet AE 1. The loss function of the MSE is used and minimized by the subnet AE 1 network model to make the output data
approximate the ground truth
Y as closely as possible, as follows:
where
is the number of training data samples in each batch of subnet AE 1.
Backpropagation is used to update the weights of the convolution layers using the gradient descent method, as follows:
(2) Training subnet AE 2. We set
Q as the output data of the encoder kernel in subnet AE 1 after completing the training process in Step 1. Subnet AE 2 uses output data
Q as its input. Moreover, the subnet AE 2 network model also minimizes the loss function of the MSE to approximate the output data
as closely as possible to the output of subnet AE 1’s encoder kernel. The loss function
of subnet AE 2 is expressed as
where
denotes the number of training data samples in each batch.
Backpropagation is used to update the weights of the dense layers using the gradient descent method, as follows:
4.3.2. Step 2: Use the Preinitialized Weights from Step 1 to Train the Entire SCAE Network
After weights , , , , , and are pretrained, they serve as the starting points for training the entire network. Step 2 uses a training procedure similar to that of the CAE model presented above.
6. Discussion
The effectiveness of the proposed SCAE model in recovering noise-affected data is shown via experimental analysis.
Table 5 presents the performance comparison results for PLSR, RNN, and SCAE. While the training error of PLSR is more than three times that of the SCAE, that of RNN is more than two times greater. Similarly, PLSR, RNN, and SCAE have testing errors of
,
, and
, respectively. It is evident that the SCAE demonstrates superior performance compared with currently available data reconstruction approaches. This is the result of using the data of multiple sensors simultaneously, which not only preserves the temporal component of the data of each sensor but also reveals the relationship between the sensors. In addition, the use of a convolutional autoencoder architecture enhances the efficacy of data extraction, particularly when dealing with two-dimensional data. The improvement in the ability to identify and analyze data patterns leads to increased efficiency in the recovery of affected data.
Furthermore, the comparison between the SCAE and CAE is conducted in different scenarios. The experimental results indicate that, despite their shared use of a hybrid CNN and AE framework, the SCAE exhibits superior performance than the CAE across all evaluated comparisons. In the context of using the PM 2.5 dataset, it was observed that the training error of the CAE reached
, while that of the SCAE was shown as
.
Table 5 displays the testing errors of the CAE and SCAE, which are
and
, respectively. Moreover, the employing of additional actual datasets, such as temperature, AQI, O3, or PM10, demonstrates that the SCAE exhibits enhanced efficacy in the reconstruction of data. In investigations with varying Gaussian noise variances, training and testing errors are substantially reduced. When the variance of the noise increases from
to 1, there is an observed increase in the gap between the testing error of the CAE and the SCAE. Specifically, the difference in testing error between the two models rises from
to
, as clearly shown in
Figure 9.
The enhanced performance shown by the SCAE in comparison with the CAE may be attributed to enhancements in both the initialization of model weights and the underlying model architecture. The utilization of a more complex structure may give rise to the issue of vanished gradients in the backpropagation process. The use of random weight initialization might also contribute to the possibility of vanishing gradients, hence restricting the model to learn effectively. Furthermore, the presence of inadequately initialized weights might lead to the model getting stuck in local optimum situations. The SCAE employs a stacked fashion, which serves the dual purpose of reducing the size of subnets and optimizing the weight initialization process via the use of a weight sharing mechanism. The efficiency of this approach has been clearly proven through intensive experiments with real-world data.
7. Conclusions
In this study, we addressed the problem of recovering data from noise-affected WSN systems. In contrast with previous investigations that only focused on internal noise, our study incorporates a consideration of external influences, which enhances the feasibility of our research findings in real-world scenarios. The noise that impacts the WSN system is categorized into two main sources: internal noise, such as thermal noise, and external noise, which encompasses adverse weather conditions. The use of data from multiple sensors concurrently is suggested in order to maintain the temporal characteristics of the data and the interdependencies among the sensors. Moreover, the SCAE model, as described, demonstrates efficiency in effectively extracting data characteristics while also addressing the limitations of the original CAE in terms of network structure and weight initialization. Thorough experiments were conducted using both WSN simulations and real-world sensor data. The experimental findings demonstrate that the SCAE has superior performance compared with existing models in noise-affected data reconstruction.
In the future, we intend to expand the performance evaluation of the proposed model to WSN systems implementing additional protocols and real-world datasets. Additionally, we also desire to fine-tune the hyperparameters in order to enhance the performance of the model.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}