
Taxi Demand and Fare Prediction with Hybrid Models: Enhancing Efficiency and User Experience in City Transportation

 , , ,
, , ,  , , , and
, , , and
Abstract
:1. Introduction
- Development of a hybrid model intertwining LSTM-RNN with MDN to predict high-demand zones for customers across various time intervals, thereby optimizing taxi drivers’ efficiency and income potential.
- Creation of an ensemble model amalgamating LR, RR, and MLP to estimate taxi fares for point-to-point trips, while also identifying the nearest taxi pickup locations.
- Establishment of a user-friendly interface facilitating seamless interaction between end users and the platform, enabling clear and effective visualization of the predicted outcomes.
2. Methodology
2.1. Dataset
2.2. Demand Prediction Model
2.3. Fare Prediction Model
2.4. Web Application
3. Result And Discussion
3.1. Predictive Models
3.1.1. Evaluation Metric
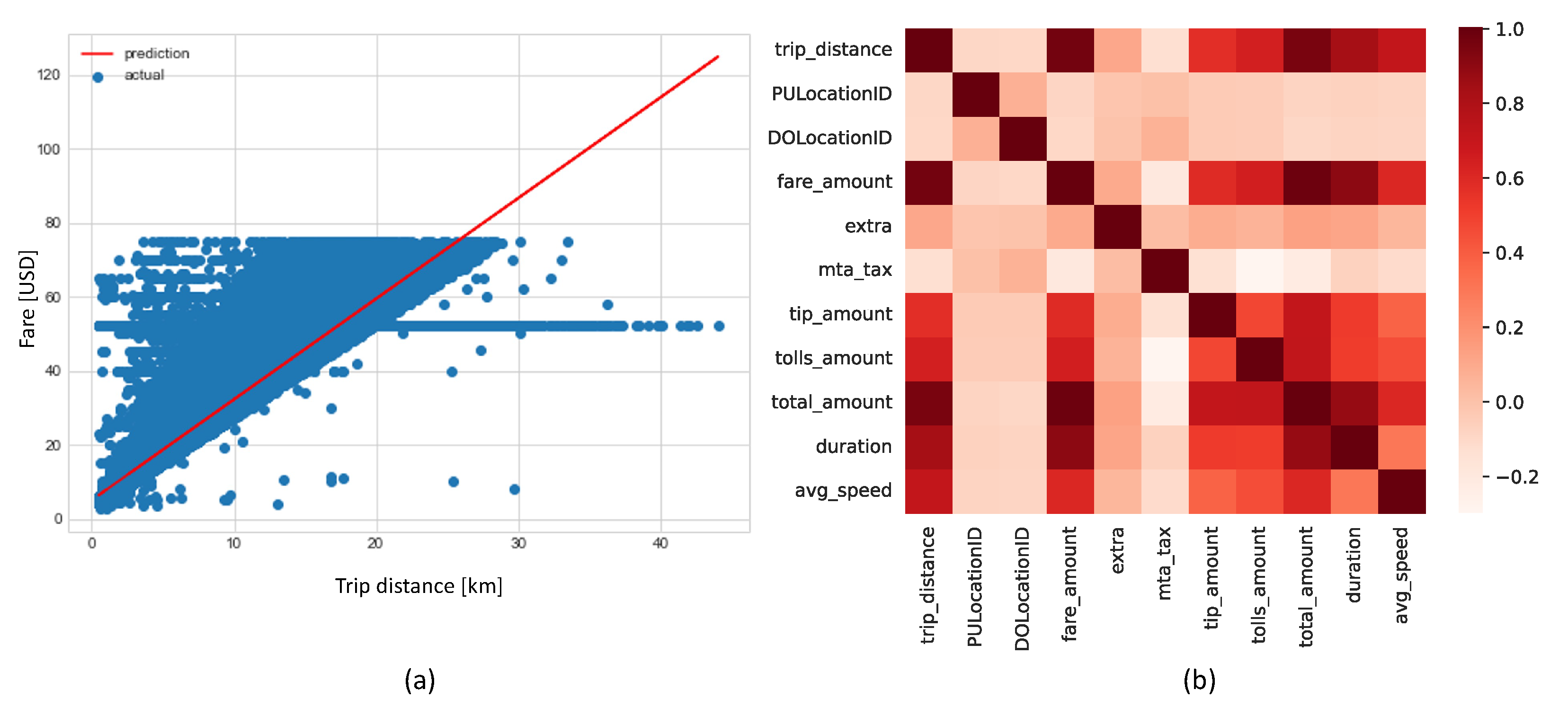
3.1.2. Fare Prediction
3.1.3. Demand Prediction
3.2. Interface and Use Cases
- Simply using a heatmap, point to the neighboring zone with the highest demand in the upcoming timestep. By moving in the direction of greater need, this situation is regarded as one of the quickest methods to gain a new client.
- When neighboring zones have comparable demand, the top five demand zones are listed along with a payment analysis for the higher-income zone. Extending from above, a taxi driver could choose to travel to the area with the highest revenue while the other regions have a comparable demand. Consequently, integrating the heatmap, top zones list, and payment analysis can result in superior decision support with historical income for taxi drivers.
- With a thorough evaluation of the demand heatmap, payment analysis, and trip summary for the maximum zone. Suppose there was a demand scenario on a Sunday between 8 and 8:30 p.m. Penn Station/Madison Sq West is the highest demand zone, and it has the information (designated in Figure 6A) of the average journey distance, speed, and duration. On Monday, the zone’s average speed was around 10 miles per hour higher than typical. Combining the demand line chart (labeled as B in Figure 6), which displays the decreasing trend in the number of pickups and the higher trend in the number of dropoffs, provides proof that the taxi service is over-served. Label C denotes the highest earning zone, suggesting that drivers could be able to earn more money during the over-served hour.
- By comparing the trip information in various timesteps, it is possible to estimate traffic jams using historical data (label A in Figure 6). The area’s typical speed is revealed by the high average speed at night. There is presumed traffic congestion when the average speed of the trips in a particular zone is low and the average length is high.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhan, X.; Qian, X.; Ukkusuri, S. A Graph-Based Approach to Measuring the Efficiency of an Urban Taxi Service System. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2479–2489. [Google Scholar] [CrossRef]
- Yang, H.; Fung, C.C.; Wong, K.F.; Wong, S.K. Nonlinear pricing of taxi services. Transp. Res. Part A Policy Pract. 2010, 44, 337–348. [Google Scholar] [CrossRef]
- Zhang, R.; Ghanem, R. Demand, Supply, and Performance of Street-Hail Taxi. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4123–4132. [Google Scholar] [CrossRef]
- Chelliah, B.J.; Singh, J.; Chaturvedi, D.; Singh, A.K. Taxi fare prediction system using key feature extraction in artificial intelligence. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 3803–3808. [Google Scholar]
- Santi, P.; Resta, G.; Szell, M.; Sobolevsky, S.; Strogatz, S.; Ratti, C. Quantifying the benefits of vehicle pooling with shareability networks. Proc. Natl. Acad. Sci. USA 2014, 111, 13290–13294. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Qiu, Z.; Li, G.; Wang, Q.; Ouyang, W.; Lin, L. Contextualized Spatial–Temporal Network for Taxi Origin-Destination Demand Prediction. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3875–3887. [Google Scholar] [CrossRef]
- Yamaki, S. Study on Taxi Demand Prediction Using Context and Spatio-Tamporal Data. 2020. Available online: https://core.ac.uk/download/pdf/288814152.pdf (accessed on 30 March 2021).
- Grinberg, J.; Jain, A.; Choksi, V. Predicting Taxi Pickups in New York City. 2014. Available online: http://www.vivekchoksi.com/papers/taxi_pickups.pdf (accessed on 5 August 2023).
- Liu, T.; Wu, W.; Zhu, Y.; Tong, W. Predicting taxi demands via an attention-based convolutional recurrent neural network. Knowl. Based Syst. 2020, 206, 106294. [Google Scholar] [CrossRef]
- Miao, F.; Han, S.; Lin, S.; Stankovic, J.; Zhang, D.; Munir, S. Taxi Dispatch with Real-Time Sensing Data in Metropolitan Areas: A Receding Horizon Control Approach. IEEE Trans. Autom. Sci. Eng. 2016, 13, 463–478. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Predicting Taxi–Passenger Demand Using Streaming Data. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1393–1402. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Zhang, L.; Xie, X.; Sun, G. Where to find my next passenger. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011. [Google Scholar]
- Zhang, C.; Zhu, F.; Wang, X.; Sun, L.; Tang, H.; Lv, Y. Taxi Demand Prediction Using Parallel Multi-Task Learning Model. IEEE Trans. Intell. Transp. Syst. 2022, 23, 794–803. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. MLRNN: Taxi Demand Prediction Based on Multi-Level Deep Learning and Regional Heterogeneity Analysis. IEEE Trans. Intell. Transp. Syst. 2022, 23, 8412–8422. [Google Scholar] [CrossRef]
- Xu, J.; Rahmatizadeh, R.; Boloni, L.; Turgut, D. Real-Time Prediction of Taxi Demand Using Recurrent Neural Networks. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2572–2581. [Google Scholar] [CrossRef]
- Wu, C.H.; Ho, J.W.; Lee, D.H. Travel-Time Prediction with Support Vector Regression. IEEE Trans. Intell. Transp. Syst. 2004, 5, 276–281. [Google Scholar] [CrossRef]
- Yang, H.; Ye, M.; Tang, W.H.; Wong, S. Regulating taxi services in the presence of congestion externality. Transp. Res. Part A Policy Pract. 2005, 39, 17–40. [Google Scholar] [CrossRef]
- Antoniades, C.; Fadavi, D.; Foba Amon, A., Jr. Fare and Duration Prediction: A Study of New York City Taxi Rides. 2016. Available online: http://cs229.stanford.edu/proj2016/report/AntoniadesFadaviFobaAmonJuniorNewYorkCityCabPricing-report.pdf (accessed on 5 August 2023).
- Rossi, A.; Barlacchi, G.; Bianchini, M.; Lepri, B. Modelling Taxi Drivers’ Behaviour for the Next Destination Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 2980–2989. [Google Scholar] [CrossRef]
- Upadhyay, R.; Lui, S. Taxi Fare Rate Classification Using Deep Networks. 2017. Available online: https://www.researchgate.net/publication/324706525_Taxi_Fare_Rate_Classification_Using_Deep_Networks (accessed on 5 August 2023).
- Ferreira, N.; Poco, J.; Vo, H.; Freire, J.; Silva, C. Visual Exploration of Big Spatio-Temporal Urban Data: A Study of New York City Taxi Trips. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2149–2158. [Google Scholar] [CrossRef]
- TLC Trip Record Data. Available online: https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page (accessed on 10 August 2023).
- Zhao, K.; Khryashchev, D.; Vo, H. Predicting Taxi and Uber Demand in Cities: Approaching the Limit of Predictability. IEEE Trans. Knowl. Data Eng. 2021, 33, 2723–2736. [Google Scholar] [CrossRef]
- Shu, P.; Sun, Y.; Zhao, Y.; Xu, G. Spatial-temporal taxi demand prediction using LSTM-CNN. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1226–1230. [Google Scholar]
- Guo, X. Prediction of taxi demand based on CNN-BiLSTM-attention neural network. In Proceedings of the Neural Information Processing: 27th International Conference, ICONIP 2020, Bangkok, Thailand, 23–27 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 331–342. [Google Scholar]
- Duan, Z.T.; Kai, Z.; Yun, Y.; Ni, Y.Y.; Bajgain, S. Taxi demand prediction based on CNN-LSTM-ResNet hybrid depth learning model. J. Transp. Syst. Eng. Inf. Technol. 2018, 18, 215. [Google Scholar]
- Cao, D.; Zeng, K.; Wang, J.; Sharma, P.K.; Ma, X.; Liu, Y.; Zhou, S. BERT-Based Deep Spatial-Temporal Network for Taxi Demand Prediction. IEEE Trans. Intell. Transp. Syst. 2022, 23, 9442–9454. [Google Scholar] [CrossRef]
- Li, Y.; Moura, J.M. Forecaster: A graph transformer for forecasting spatial and time-dependent data. arXiv 2019, arXiv:1909.04019. [Google Scholar]
- Kim, T.; Sharda, S.; Zhou, X.; Pendyala, R.M. A stepwise interpretable machine learning framework using linear regression (LR) and long short-term memory (LSTM): City-wide demand-side prediction of yellow taxi and for-hire vehicle (FHV) service. Transp. Res. Part C Emerg. Technol. 2020, 120, 102786. [Google Scholar] [CrossRef]
- Django. The Web Framework for Perfectionists with Deadlines. 2019. Available online: https://www.djangoproject.com/ (accessed on 5 August 2023).
- Flask. Welcome to Flask—Flask Documentation (2.3.x). Available online: https://flask.palletsprojects.com/en/2.3.x/ (accessed on 5 August 2023).
- Google Maps Platform-Location and Mapping Solutions. Available online: https://mapsplatform.google.com/ (accessed on 5 August 2023).
- ApexCharts.js—Open Source JavaScript Charts for Your Website. Available online: https://apexcharts.com/ (accessed on 5 August 2023).
- Chart.js|Open Source HTML5 Charts for Your Website. 2019. Available online: https://www.chartjs.org/ (accessed on 5 August 2023).
- Otto, M. Bootstrap. 2022. Available online: https://sites.google.com/view/bootstrap2022/ (accessed on 5 August 2023).
- Amazon. Amazon Web Services (AWS)—Cloud Computing Services. 2023. Available online: https://pages.awscloud.com/AWS-Innovators-Amazon.html (accessed on 5 August 2023).
- Deploying a Django Application to Elastic Beanstalk. AWS Elastic Beanstalk. Available online: https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/create-deploy-python-django.html (accessed on 5 August 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Baseline | Proposed | ||
|---|---|---|---|---|
| LR | RF | MLP | Ensemble Model | |
| RMSE for 14 features | 0.32 | 0.59 | 0.25 | 0.098 |
| RMSE for 6 features | 3.61 | 3.44 | 3.33 | 3.26 |
| Method | 2-Layer LSTM without Dropout | 2-Layer LSTM with 0.1 Dropout | ||
|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | |
| 4.7018 | 0.3104 | 4.8328 | 0.3474 | |
| 3.5504 | 0.2438 | 3.4462 | 0.3359 | |
| 3.3746 | 0.2413 | 3.4227 | 0.3370 | |
| 3.3106 | 0.2305 | 3.3106 | 0.3206 | |
| 3.6732 | 0.2598 | 3.6488 | 0.3335 | |
| Method | RMSE | MAE |
|---|---|---|
| LSTM (proposed) | 3.3106 | 0.2305 |
| Multilayer perceptron | 3.4890 | 0.2962 |
| Ridge regression | 3.4224 | 0.2137 |
| Lasso | 3.4249 | 0.2164 |
| Elastic net | 3.4388 | 0.2283 |
| Method | Neg. Log-Likelihood |
|---|---|
| −3.7557 | |
| −3.7552 | |
| −3.7999 | |
| −3.7533 | |
| −3.8394 | |
| −3.7533 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chou, K.S.; Wong, K.L.; Zhang, B.; Aguiari, D.; Im, S.K.; Lam, C.T.; Tse, R.; Tang, S.-K.; Pau, G. Taxi Demand and Fare Prediction with Hybrid Models: Enhancing Efficiency and User Experience in City Transportation. Appl. Sci. 2023, 13, 10192. https://doi.org/10.3390/app131810192
Chou KS, Wong KL, Zhang B, Aguiari D, Im SK, Lam CT, Tse R, Tang S-K, Pau G. Taxi Demand and Fare Prediction with Hybrid Models: Enhancing Efficiency and User Experience in City Transportation. Applied Sciences. 2023; 13(18):10192. https://doi.org/10.3390/app131810192
Chicago/Turabian StyleChou, Ka Seng, Kei Long Wong, Boliang Zhang, Davide Aguiari, Sio Kei Im, Chan Tong Lam, Rita Tse, Su-Kit Tang, and Giovanni Pau. 2023. "Taxi Demand and Fare Prediction with Hybrid Models: Enhancing Efficiency and User Experience in City Transportation" Applied Sciences 13, no. 18: 10192. https://doi.org/10.3390/app131810192