3.1. Preliminaries
Capsule Network: In the context of CapsNets, the fundamental idea is to introduce capsules that encapsulate pose information along with other instantiation parameters, such as color and texture, for different parts or fragments of an object. This structure is characterized by being deep in width rather than height, resembling a parse tree [
13] where each active capsule selects a parent capsule in the next layer. The underlying principle is that as the viewpoint of an object changes, the corresponding pose matrices should be coordinated to maintain the voting agreement.
A CapsNet typically consists of three key components: a stack of convolutional layers responsible for extracting features, a primary capsule layer that transforms these features into capsule representations, and a stack of capsule layers that incorporate the routing mechanism. In CapsNets, capsules in a lower layer
(children) are routed to capsules in a higher layer
(parents), creating a connection between the two layers. In every layer, there are multiple capsules, each characterized by an instantiation parameter pose vector
[
14] or matrix
, and an activation probability
[
28]. The pose in each capsule encodes the relationship of an entity to the viewer, while the activation probability represents its presence. Using its pose matrix,
, each lower-level capsule contributes a vote to determine the pose of a higher-level capsule. This is achieved by multiplying the pose with a trainable viewpoint-invariant transformation weight matrix.
In essence, the trainable weights, enable the capsules to learn affine transformations, allowing them to capture and represent the part–whole relations within the data.
Routing Methods: Routing-by-agreement is a dynamic information flow through the network by determining connections between successive layers of capsules at runtime. Unlike traditional neural networks, where cross-layer connections are determined solely by network parameters, routing enables the adjustment of magnitudes and relevance from lower capsules to higher capsules, ensuring the activation of relevant higher-level counterparts and effective transmission of pattern information. The concept of routing can be likened to clustering logic [
28,
49] where higher-level parent capsules receive votes from multiple lower-level child capsules within their receptive fields. However, capsule routing differs from regular clustering as each cluster has its own learnable viewpoint-invariant transformation matrix, enabling a unique perspective on the data and facilitating faster convergence by breaking symmetry. Different approaches to routing have been explored in CapsNets [
16,
21,
22,
32,
49,
50,
54].
The pre-activation of a capsule,
, is computed as the sum of the association coefficients,
multiplied by the predictions,
of the lower-level capsules
.
These association coefficients are determined through iterative routings, with examples outlined below.
Dynamic routing [
14]: The agreement is measured by cosine similarity, and the coupling coefficients are updated as follows:
- 2.
EM routing [
28]: This refers to using an EM algorithm to determine the coupling as a mixture coefficient with cluster assumption that the votes are distributed around a parent capsule.
Activation of a parent capsule, , occurs when there is a substantial consensus among the votes with the parent capsule. This consensus leads to the formation of a compact cluster () in the -dimensional space.
- 3.
Max–min routing [
50]: Instead of using SoftMax, which limits the range of routing coefficients and results in mostly uniform probabilities, this study proposes the utilization of max–min normalization. Max–min normalization ensures a scale-invariant approach to normalize the logits.
- 4.
Fuzzy routing [
21]: To address the computational complexity of EM routing, Vu et al. introduce a routing method based on fuzzy clustering, where the coupling between capsules is represented by fuzzy coefficients. This approach offers a more efficient alternative to EM routing, reducing the computational demands, while still enabling effective information flow between capsules.
In the Fuzzy C-means algorithm, the parameter controls the degree of fuzziness in the clustering process. Larger values of lead to fuzzier clusters, where the membership values can approach either 0 or 1. When is set to 2, the objective of Fuzzy C-means aligns with that of the traditional K-means algorithm.
Routing in CapsNets filters out contributions from submodules with noisy information, suppresses output capsules with high variance predictions, and promotes consensus among capsules. However, the assumption of spherical or normal distribution of prediction vectors may not hold in real-world data with variability and noise. It also has inherent weaknesses, the unsupervised clustering nature of routing requires repeated computations, increasing computational complexity compared to one-pass feed-forward CNNs.
3.2. Hybrid-Architecture Capsule Head
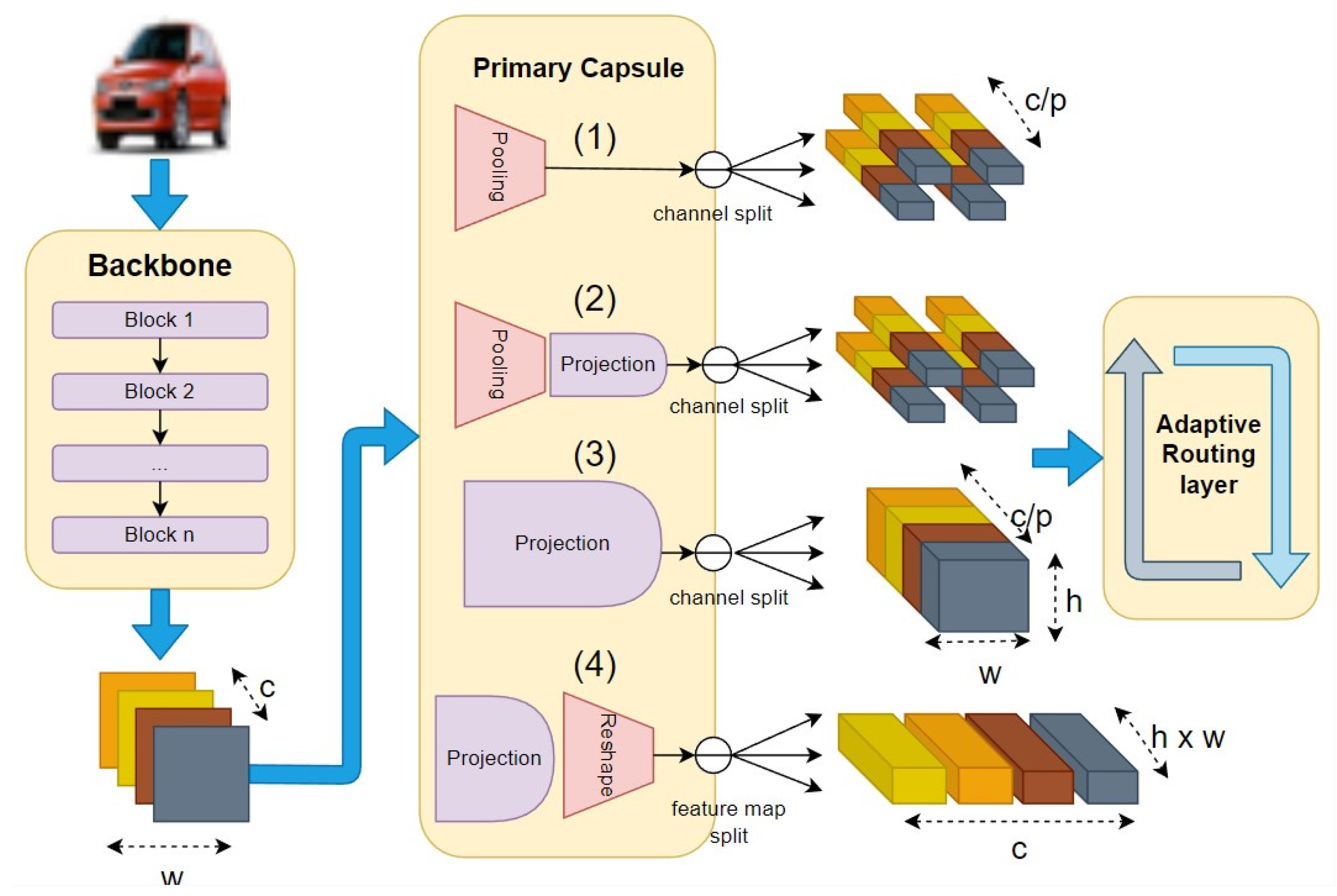
Our proposed architecture incorporates several design elements, with a focus on utilizing a backbone model and stacking a task-driven capsule head over the extracted feature maps. We present various design demonstrations, showcasing different configurations for the integration of CapsHead within the architecture, shown in
Figure 1.
- (1)
In the first design, we add adaptive average pooling to reduce the feature maps’ dimension and a fully connected capsule layer. This configuration enables the transformation of backbone features into capsules through the primary caps layer, followed by routing through the FCCaps layer.
- (2)
In the second design, we again employ average pooling after the backbone feature extraction, followed by a projection operation to enhance the capacity of the embedding space. Then, we split by channel dimension to aggregate the capsules. Subsequently, routing is applied to these capsules to get the next-layer capsules.
- (3)
In the third design, we remove the average pooling, but keep the projection and channel splitting. By adopting these modifications, the routing layer can effectively capture spatial information, making it well-suited for segmentation tasks. However, for classification tasks, we extend the functionality by incorporating capsule pooling, which allows us to reduce the number of class capsules to the desired target.
- (4)
Lastly, the fourth design directly explores the splitting of feature maps, followed by projection and adaptive capsule routing. This configuration enables a more adaptive and flexible routing mechanism based on the spatial characteristics of the feature maps.
These design demonstrations illustrate the versatility and flexibility of our proposed architecture, showcasing different configurations for integrating CapsHead within the backbone model. Each design offers unique advantages and possibilities for improving the performance and capabilities of capsules in various vision tasks.
Our designed architectures are developed based on three key criteria which allow us to tailor the CapsNets to a specific task and size of dataset.
- -
Firstly, we consider whether the feature maps extracted from the backbone model are before or after the pooling layer. For one-dimensional feature maps, after the pooling layer, which represent high-level features condensed into a single vector, they can be directly used for linear evaluation and analysis. On the other hand, two-dimensional feature maps, before the pooling layer, capture rich contextual information, particularly beneficial for interpreting the entire model or visualizing the learned features.
- -
The second criterion pertains to the interpretation of capsules. Capsules can be seen as encapsulating either channels or feature maps. In the channel-based interpretation, a capsule represents a pose vector constructed at a specific 1-pixel location, with the channel dimension serving as the capsule pose. The total number of capsules is determined by the number of pixel locations. Alternatively, in the feature map-based interpretation, each feature map constitutes a capsule, and we utilize average adaptive pooling to obtain the desired dimension of the capsule pose. In this case, the channel size corresponds to the number of capsules.
- -
Lastly, we consider the mapping of feature vectors to the primary capsule space. We provide the flexibility of either directly using the feature space spanned by the backbone model or incorporating a non-linear projection head to map the feature vectors to the primary capsule space. This allows for a more tailored and optimized representation of capsules. In this study, we craft the projection head using a multi-layer perceptron with two-to-three layers, incorporating non-linear activation functions like ReLU.
In our proposed architecture, we introduce an adaptive routing layer that facilitates the routing of capsules to class-level capsules, regardless of the size of the feature maps. This idea is inspired by the concept of capsule pooling introduced in [
16,
52]. If the size of the feature maps is different from
, we first perform routing to capture the spatial relationships, and then apply capsule pooling to achieve the desired output size, which is typically
, and flatten its capsule activations which are used for the classification task.
The proposed architecture combines a backbone model with CapsHeads to leverage their respective strengths and enhance the overall performance. The backbone model [
1,
2,
3,
4,
11], which can be a pre-trained deep neural network, serves as a feature extractor, capturing high-level features from the input data. These features are then fed into the CapsHead, which introduce capsule layers to capture spatial relationships and enable richer representations. The combination of the backbone model and CapsHead offers several advantages. Firstly, the backbone model provides a strong foundation of feature extraction, leveraging its ability to learn complex patterns and representations from large-scale datasets. This allows our model to benefit from the informative features extracted by the backbone model, enhancing their discriminative power. Additionally, capsules encapsulate pose information and activation, allowing them to capture spatial relationships between features. This makes them well-suited for tasks requiring the understanding of object orientation, pose, and spatial arrangements.







{kind=link}
{kind=link}
{kind=link}
{kind=link}