
Lane Line Type Recognition Based on Improved YOLOv5

Abstract
:1. Introduction
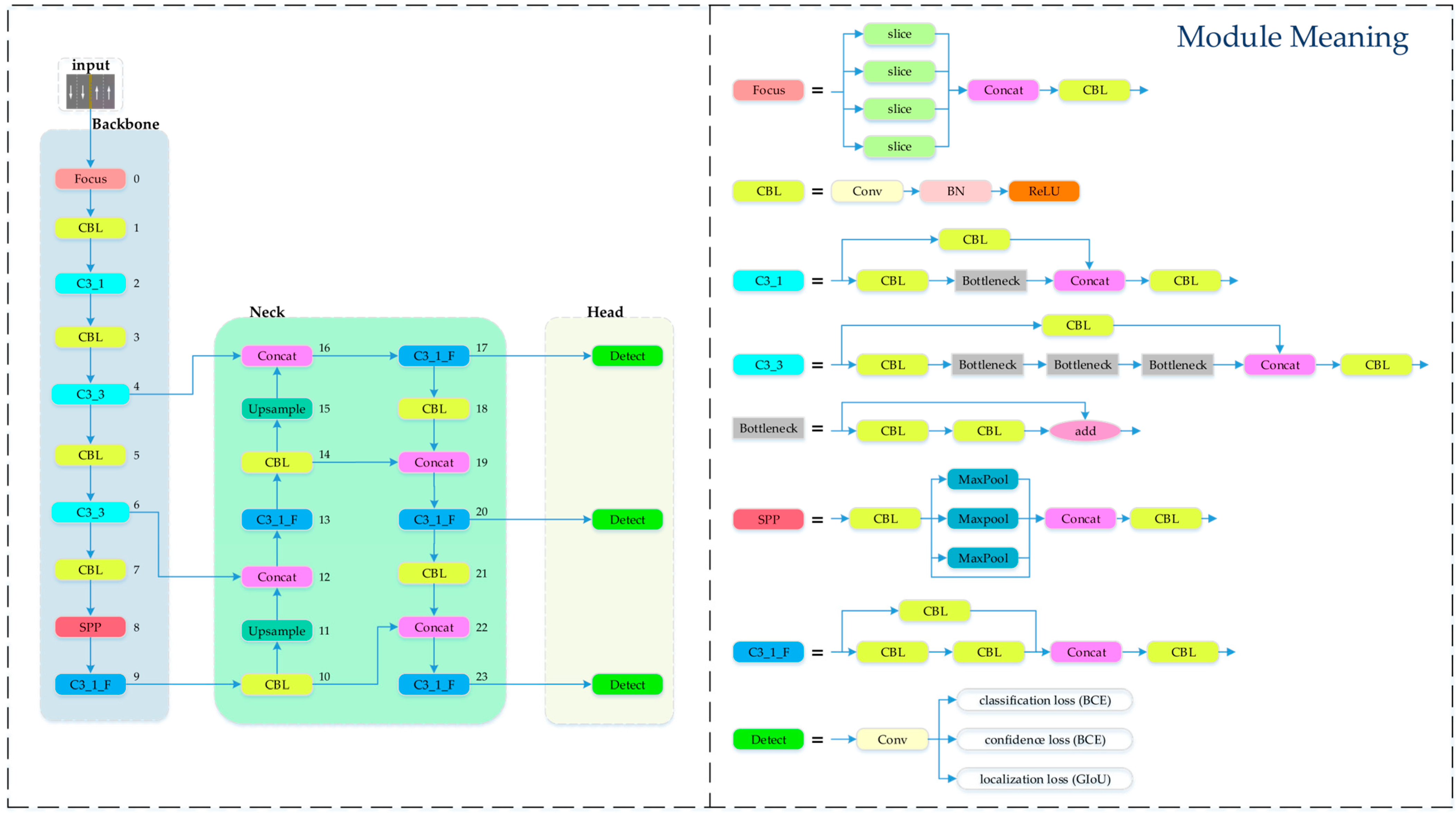
2. Method
2.1. Basic Principles of the YOLOv5 Algorithm
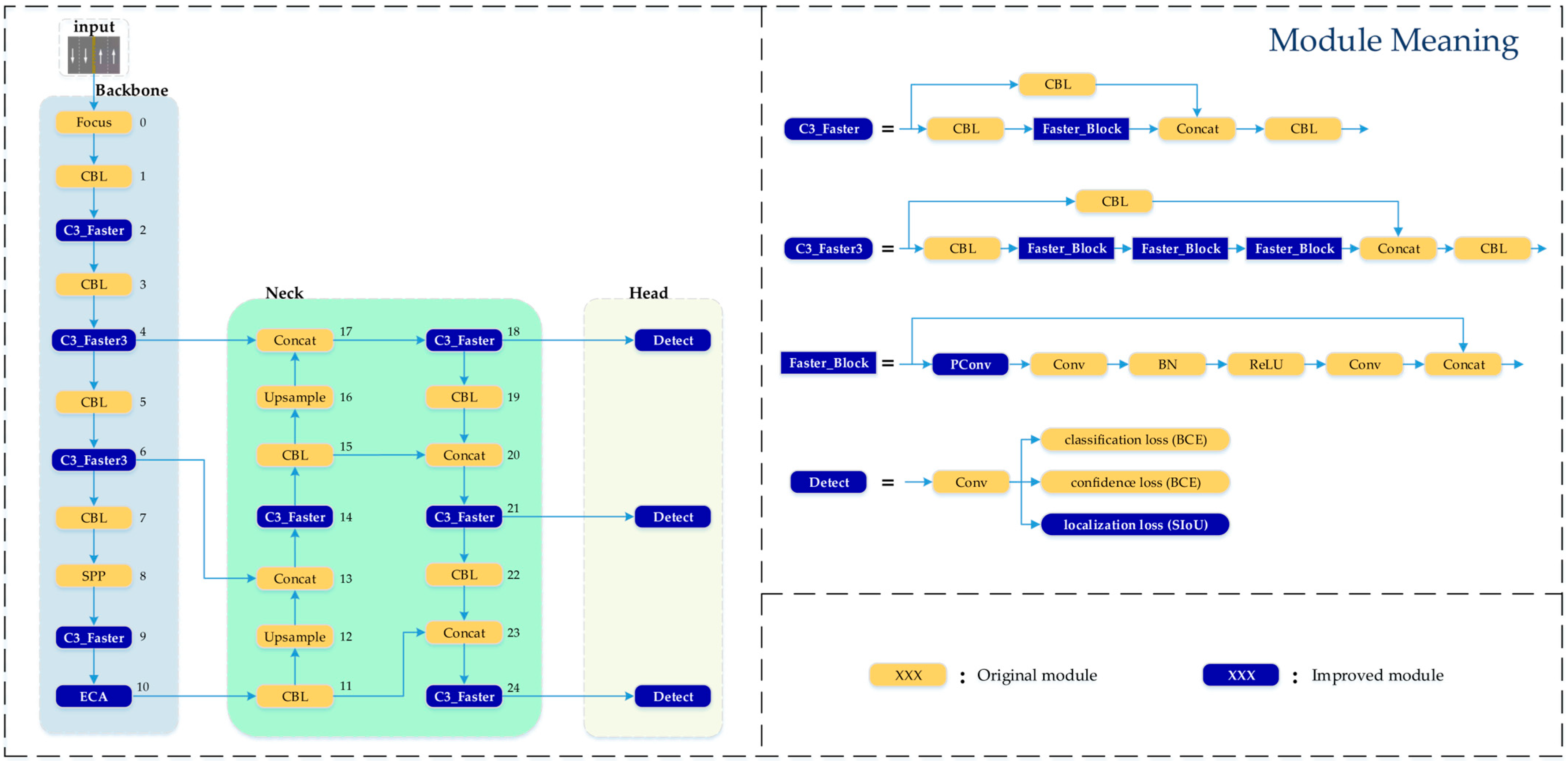
2.2. Improved YOLOv5 Algorithm
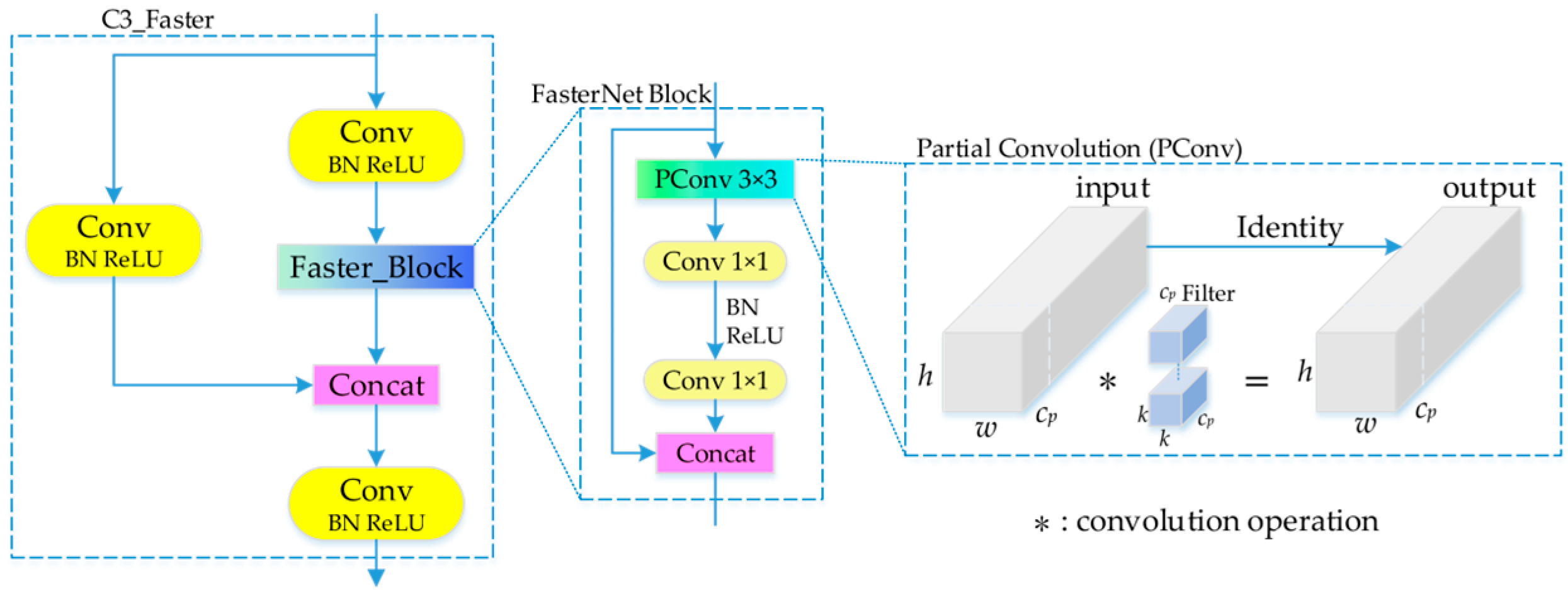
- In the C3 module of the backbone network and neck network, the FasterNet lightweight network is introduced to form the C3_Faster module. This effectively reduces redundant computations and memory access, reducing the model size and accelerating the inference speed.
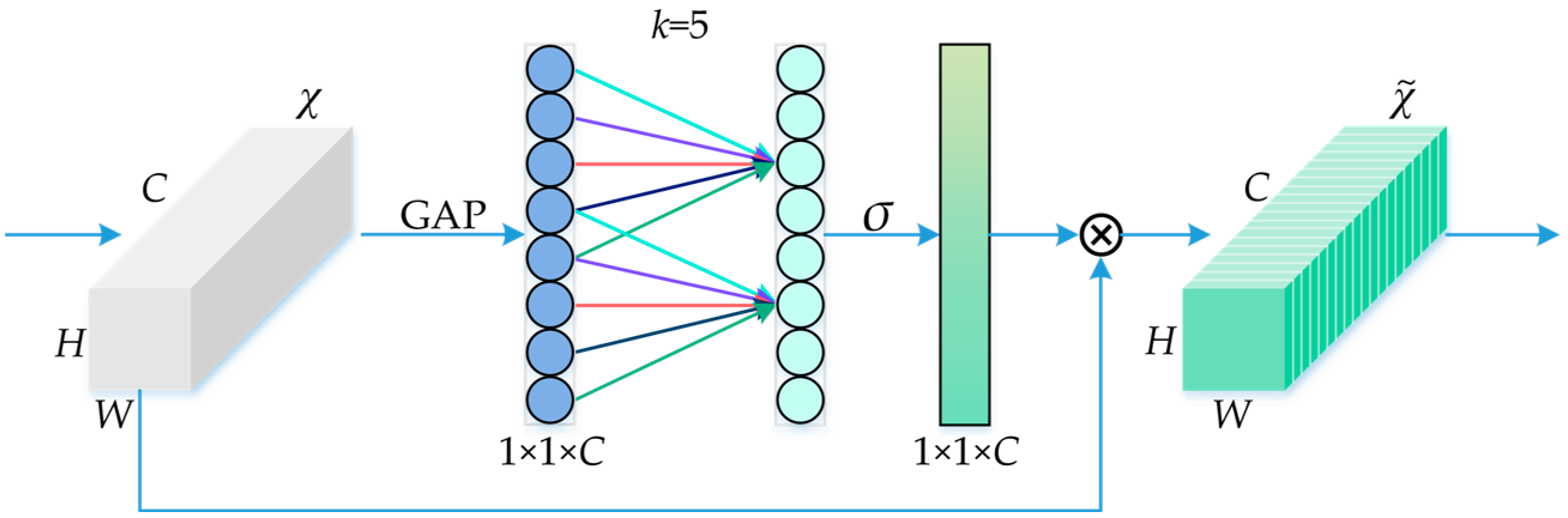
- The ECA mechanism is introduced at the end of the backbone, which incorporates attention on both channel and spatial dimensions. This significantly enhances the model’s feature extraction capability.
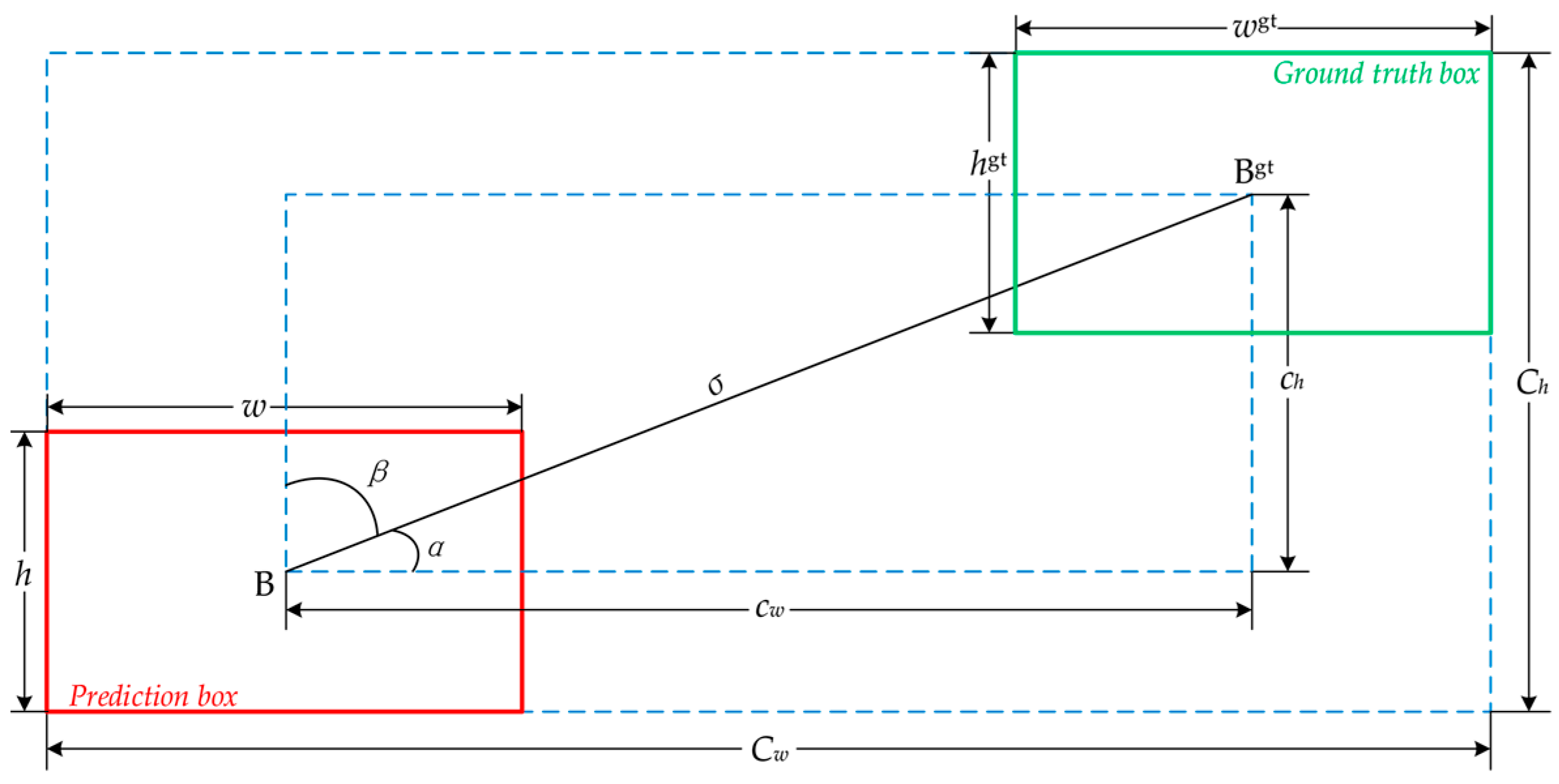
- In the localisation loss function, the SIoU is used instead of the original GIoU function. SIoU takes into account the vector angle between the ground truth box and the predicted box, redefining the penalty metric. This further improves training convergence speed and inference accuracy structure.
2.2.1. FasterNet Lightweight Network
2.2.2. ECA Mechanism
2.2.3. SIoU Loss Function
3. Experimental Section
3.1. Experimental Environment and Hyperparameters
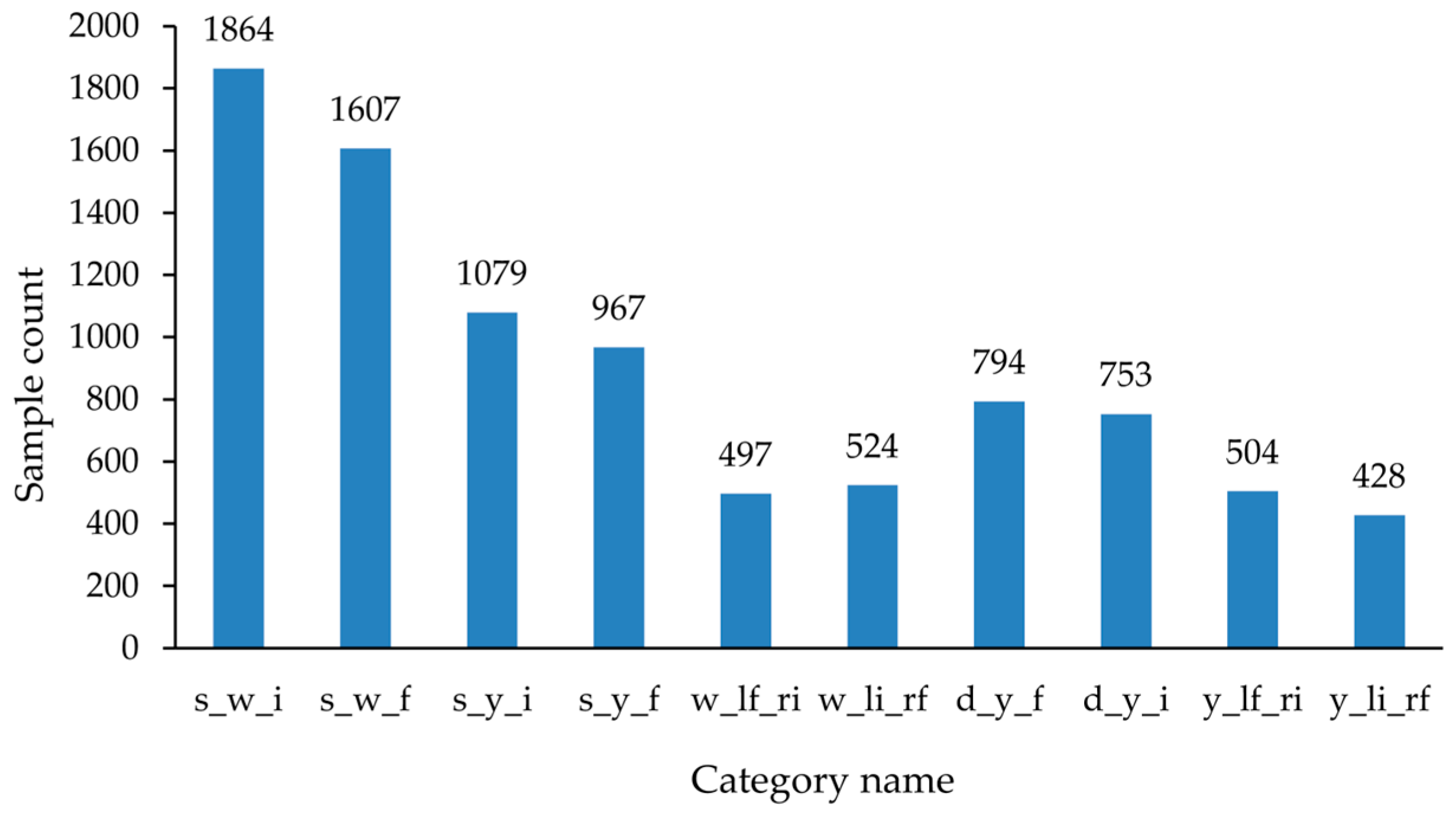
3.2. Experimental Dataset
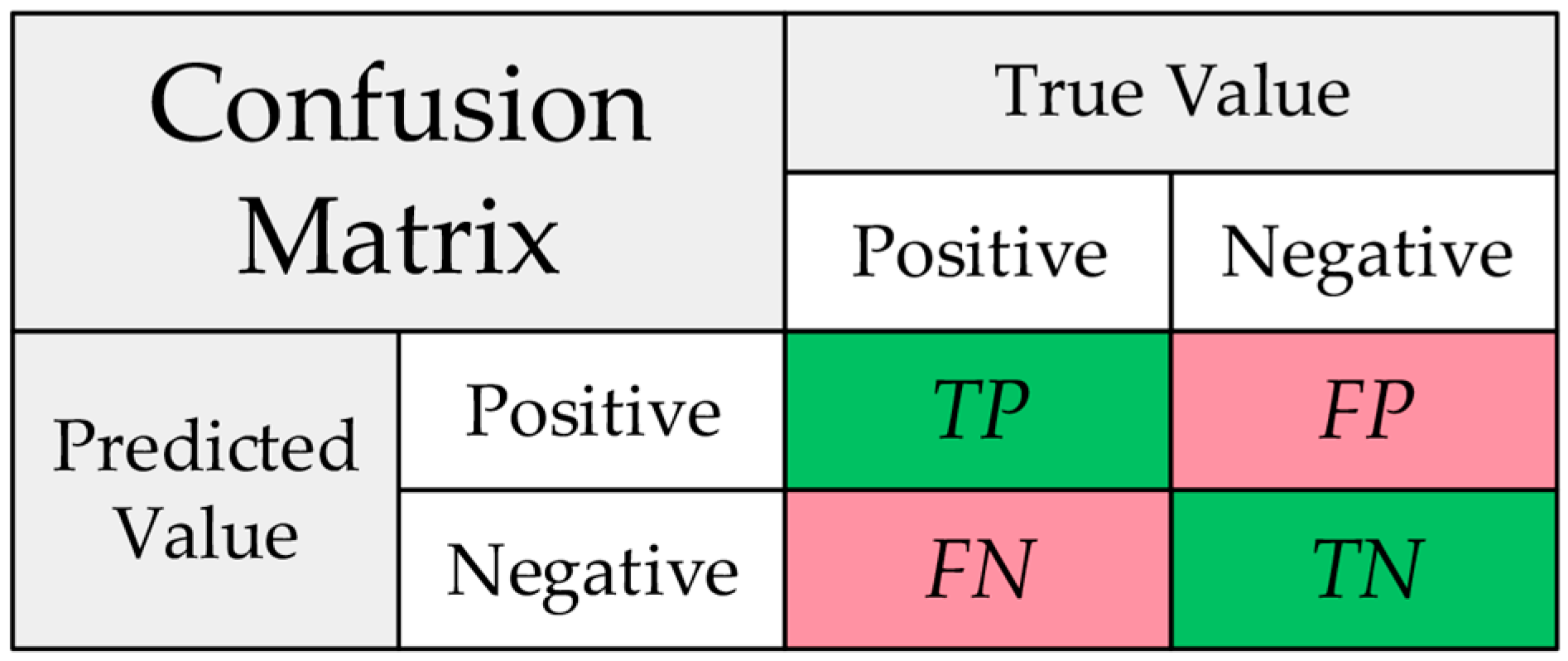
3.3. Evaluation Metrics
4. Result
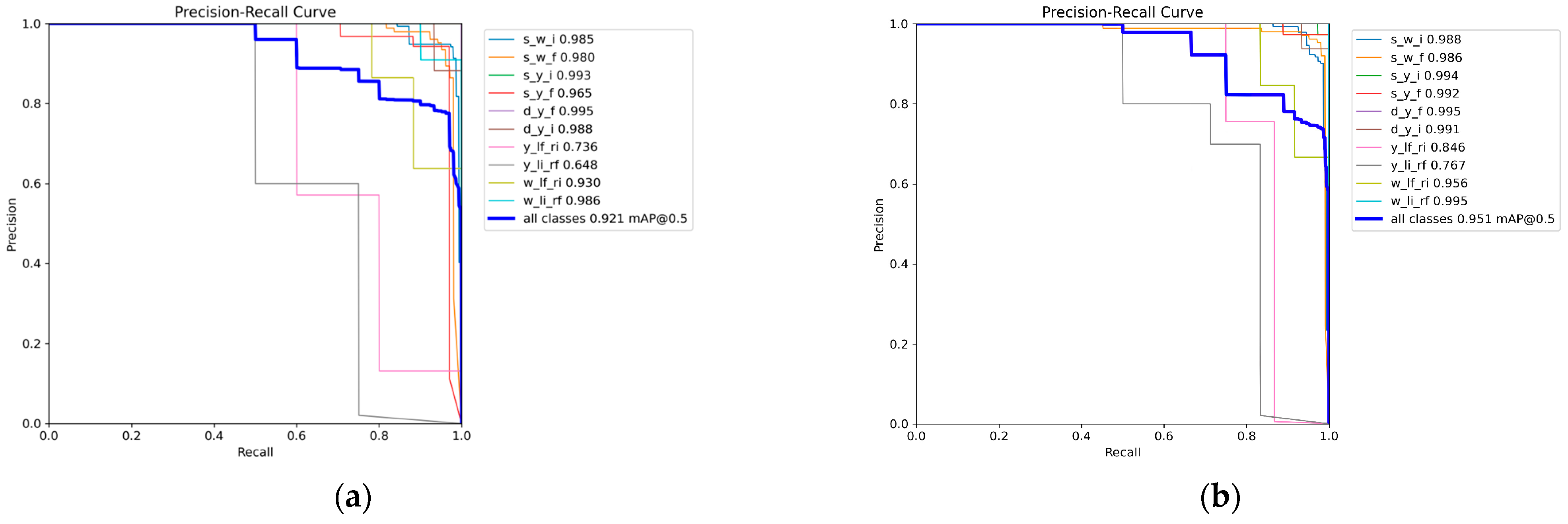
4.1. Comparative Experiment of Attentional Mechanisms
4.2. Comparison Experiment of Loss Function
4.3. Ablation Experiment
4.4. Comparative Experiment of Different Algorithms
4.5. Comparative Experiment of YOLO Series Algorithms
4.6. Analysis of Influence of Light Intensity
4.7. Analysis of the Influence of Noise
5. Conclusions
- Introducing FasterNet into the C3 module of the backbone and necking networks can speed up the inference speed of the model and reduce the calculation parameters.
- Introducing the ECA mechanism into the backbone network can significantly improve the recognition accuracy of the model.
- The use of SIoU loss function can further improve the accuracy of the model and speed up the inference speed to some extent.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wippelhauser, A.; Edelmayer, A.; Bokor, L. A Declarative Application Framework for Evaluating Advanced V2X-Based ADAS Solutions. Appl. Sci. 2023, 13, 1392. [Google Scholar] [CrossRef]
- Zou, Y.; Ding, L.; Zhang, H.; Zhu, T.; Wu, L. Vehicle Acceleration Prediction Based on Machine Learning Models and Driving Behavior Analysis. Appl. Sci. 2022, 12, 5259. [Google Scholar] [CrossRef]
- Ulrich, L.; Nonis, F.; Vezzetti, E.; Moos, S.; Caruso, G.; Shi, Y.; Marcolin, F. Can ADAS Distract Driver’s Attention? An RGB-D Camera and Deep Learning-Based Analysis. Appl. Sci. 2021, 11, 11587. [Google Scholar] [CrossRef]
- Park, C.; Chung, S.; Lee, H. Vehicle-in-the-Loop in Global Coordinates for Advanced Driver Assistance System. Appl. Sci. 2020, 10, 2645. [Google Scholar] [CrossRef]
- Ma, C.; Xie, M. A Method for Lane Detection Based on Color Clustering. In Proceedings of the 2010 Third International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand, 9–10 January 2010; pp. 200–203. [Google Scholar] [CrossRef]
- Rui, R. Lane line detection technology based on machine vision. In Proceedings of the 2022 4th International Conference on Artificial Intelligence and Advanced Manufacturing (AIAM), Hamburg, Germany, 7–9 October 2022; pp. 562–566. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Xiang, J.; Shi, H.; Huang, X.; Chen, D. Improving Graphite Ore Grade Identification with a Novel FRCNN-PGR Method Based on Deep Learning. Appl. Sci. 2023, 13, 5179. [Google Scholar] [CrossRef]
- Wang, H.; Xiao, N. Underwater Object Detection Method Based on Improved Faster RCNN. Appl. Sci. 2023, 13, 2746. [Google Scholar] [CrossRef]
- Liang, B.; Wang, Z.; Si, L.; Wei, D.; Gu, J.; Dai, J. A Novel Pressure Relief Hole Recognition Method of Drilling Robot Based on SinGAN and Improved Faster R-CNN. Appl. Sci. 2023, 13, 513. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. arXiv 2020, arXiv:2011.08036. [Google Scholar]
- YOLOv5. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 10 December 2022).
- Leng, S.; Musha, Y.; Yang, Y.; Feng, G. CEMLB-YOLO: Efficient Detection Model of Maize Leaf Blight in Complex Field Environments. Appl. Sci. 2023, 13, 9285. [Google Scholar] [CrossRef]
- Singh, S.K.; Abolghasemi, V.; Anisi, M.H. Fuzzy Logic with Deep Learning for Detection of Skin Cancer. Appl. Sci. 2023, 13, 8927. [Google Scholar] [CrossRef]
- Mpouziotas, D.; Karvelis, P.; Tsoulos, I.; Stylios, C. Automated Wildlife Bird Detection from Drone Footage Using Computer Vision Techniques. Appl. Sci. 2023, 13, 7787. [Google Scholar] [CrossRef]
- González-Baldizón, Y.; Pérez-Patricio, M.; Camas-Anzueto, J.L.; Rodríguez-Elías, O.M.; Escobar-Gómez, E.N.; Vazquez-Delgado, H.D.; Guzman-Rabasa, J.A.; Fragoso-Mandujano, J.A. Lamb Behaviors Analysis Using a Predictive CNN Model and a Single Camera. Appl. Sci. 2022, 12, 4712. [Google Scholar] [CrossRef]
- He, W.; Huang, Z.; Wei, Z.; Li, C.; Guo, B. TF-YOLO: An Improved Incremental Network for Real-Time Object Detection. Appl. Sci. 2019, 9, 3225. [Google Scholar] [CrossRef]
- Farag, W.; Saleh, Z. Road Lane-Lines Detection in Real-Time for Advanced Driving Assistance Systems. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhier, Bahrain, 18–20 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7276–7283. [Google Scholar] [CrossRef]
- State General Administration of the People’s Republic of China for Quality Supervision and Inspection. Quarantine and National Standard of the People’s Republic of China. In Road Traffic Signs and Markings: Part 3, Road Traffic Markings; Standards Press of China: Beijing, China, 2009. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. arXiv 2021, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Depth Multiple | Width Multiple |
|---|---|---|
| YOLOv5s | 0.33 | 0.50 |
| YOLOv5m | 0.67 | 0.75 |
| YOLOv5l | 1.00 | 1.00 |
| YOLOv5x | 1.33 | 1.25 |
| Type | Parameter |
|---|---|
| CPU | Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz |
| RAM | 45 GB |
| GPU | NVIDIA RTX3090 GPU with 24 GB of VRAM |
| VRAM | 24 GB |
| Programming language | Python 3.7 |
| Deep learning framework and dependency library | Pytorch 1.10.2, CUDA 11.6, Cudnn 8.3.2, Numpy 1.19.5, tqdm 4.64.1, tensorboard 2.10.1, OpenCV-Python 4.6.0.66 |
| Hyperparameter | Value |
|---|---|
| Epochs | 300 |
| Batch size | 16 |
| Image size | 640 |
| Optimiser | SGD |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| Label Name | Lane Line Name | Legend |
|---|---|---|
| s_w_i | white dashed line |  |
| s_w_f | white solid line |  |
| s_y_i | yellow dashed line |  |
| s_y_f | yellow solid line |  |
| w_lf_ri | white dash-solid line |  |
| w_li_rf |  | |
| d_y_f | double yellow solid line |  |
| d_y_i | double yellow dashed line |  |
| y_lf_ri | yellow dash-solid line |  |
| y_li_rf |  |
| Model | mAP@0.5 (%) | Parameters (M) | FPS (frame·s−1) |
|---|---|---|---|
| YOLOv5s | 92.1 | 7.1 | 91.3 |
| YOLOv5s + CBAM | 94.1 | 7.6 | 82.6 |
| YOLOv5s + SE | 93.7 | 8.3 | 79.4 |
| YOLOv5s + ECA | 94.3 | 7.2 | 84.7 |
| Model | mAP@0.5 (%) | Parameters (M) | FPS (frame·s−1) |
|---|---|---|---|
| YOLOv5s + ECA + GIoU | 94.3 | 7.2 | 84.7 |
| YOLOv5s + ECA + CIoU | 95.0 | 7.2 | 87.7 |
| YOLOv5s + ECA + EIoU | 94.8 | 7.2 | 89.3 |
| YOLOv5s + ECA + SIoU | 95.4 | 7.2 | 85.5 |
| YOLOv5s | C3_Faster | ECA | SIoU | mAP@0.5 (%) | Parameters (M) | FPS (frame·s−1) | Volume (MB) |
|---|---|---|---|---|---|---|---|
| √ | 92.1 | 7.1 | 91.3 | 13.8 | |||
| √ | √ | 91.9 | 5.8 | 99.0 | 11.4 | ||
| √ | √ | 94.3 | 7.2 | 84.7 | 13.9 | ||
| √ | √ | 93.8 | 7.1 | 92.6 | 13.8 | ||
| √ | √ | √ | 95.4 | 7.2 | 85.5 | 13.9 | |
| √ | √ | √ | √ | 95.1 | 6.0 | 95.2 | 11.7 |
| Model | mAP@0.5 (%) | FPS (frame·s−1) | Volume (MB) |
|---|---|---|---|
| Faster R-CNN(Vgg16) | 88.1 | 13.5 | 522.1 |
| Faster R-CNN(ResNet50) | 86.0 | 6.3 | 108.5 |
| SSD(Vgg16) | 86.7 | 45.5 | 95.1 |
| SSD(ResNet50) | 82.8 | 68.9 | 49.8 |
| SSD(MobileNetv2) | 73.1 | 71.2 | 18.8 |
| RetinaNet | 85.6 | 53.3 | 139.9 |
| YOLOv5s | 92.1 | 91.3 | 13.8 |
| Oure-YOLOv5s | 95.1 | 95.2 | 11.7 |
| Model | mAP@0.5 (%) | Parameters (M) | FPS (frame·s−1) | Volume (MB) |
|---|---|---|---|---|
| YOLOv3 | 88.5 | 61.6 | 26.5 | 117.9 |
| YOLOv3-tiny | 76.8 | 8.7 | 140.8 | 16.7 |
| YOLOv4 | 89.5 | 64.4 | 24.0 | 224.6 |
| YOLOv4-tiny | 81.5 | 5.9 | 128.4 | 22.6 |
| YOLOv5s | 92.1 | 7.1 | 91.3 | 13.8 |
| YOLOv5m | 94.4 | 20.9 | 41.2 | 40.3 |
| YOLOv5l | 95.5 | 46.2 | 25.1 | 88.6 |
| YOLOv5x | 96.7 | 86.3 | 13.4 | 165.2 |
| Ours-YOLOv5s | 95.1 | 6.0 | 95.2 | 11.7 |
| Ours-YOLOv5m | 95.8 | 15.8 | 43.7 | 30.6 |
| Ours-YOLOv5l | 96.1 | 32.3 | 26.9 | 62.1 |
| Ours-YOLOv5x | 96.9 | 57.0 | 15.3 | 109.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Wang, H.; Wang, Y.; Zhou, C.; Cai, L. Lane Line Type Recognition Based on Improved YOLOv5. Appl. Sci. 2023, 13, 10537. https://doi.org/10.3390/app131810537
Liu B, Wang H, Wang Y, Zhou C, Cai L. Lane Line Type Recognition Based on Improved YOLOv5. Applied Sciences. 2023; 13(18):10537. https://doi.org/10.3390/app131810537
Chicago/Turabian StyleLiu, Boyu, Hao Wang, Yongqiang Wang, Congling Zhou, and Lei Cai. 2023. "Lane Line Type Recognition Based on Improved YOLOv5" Applied Sciences 13, no. 18: 10537. https://doi.org/10.3390/app131810537
APA StyleLiu, B., Wang, H., Wang, Y., Zhou, C., & Cai, L. (2023). Lane Line Type Recognition Based on Improved YOLOv5. Applied Sciences, 13(18), 10537. https://doi.org/10.3390/app131810537