
Estimating Organic Matter Content in Hyperspectral Wetland Soil Using Marine-Predators-Algorithm-Based Random Forest and Multiple Differential Transformations


Abstract
:1. Introduction
2. Materials and Methods
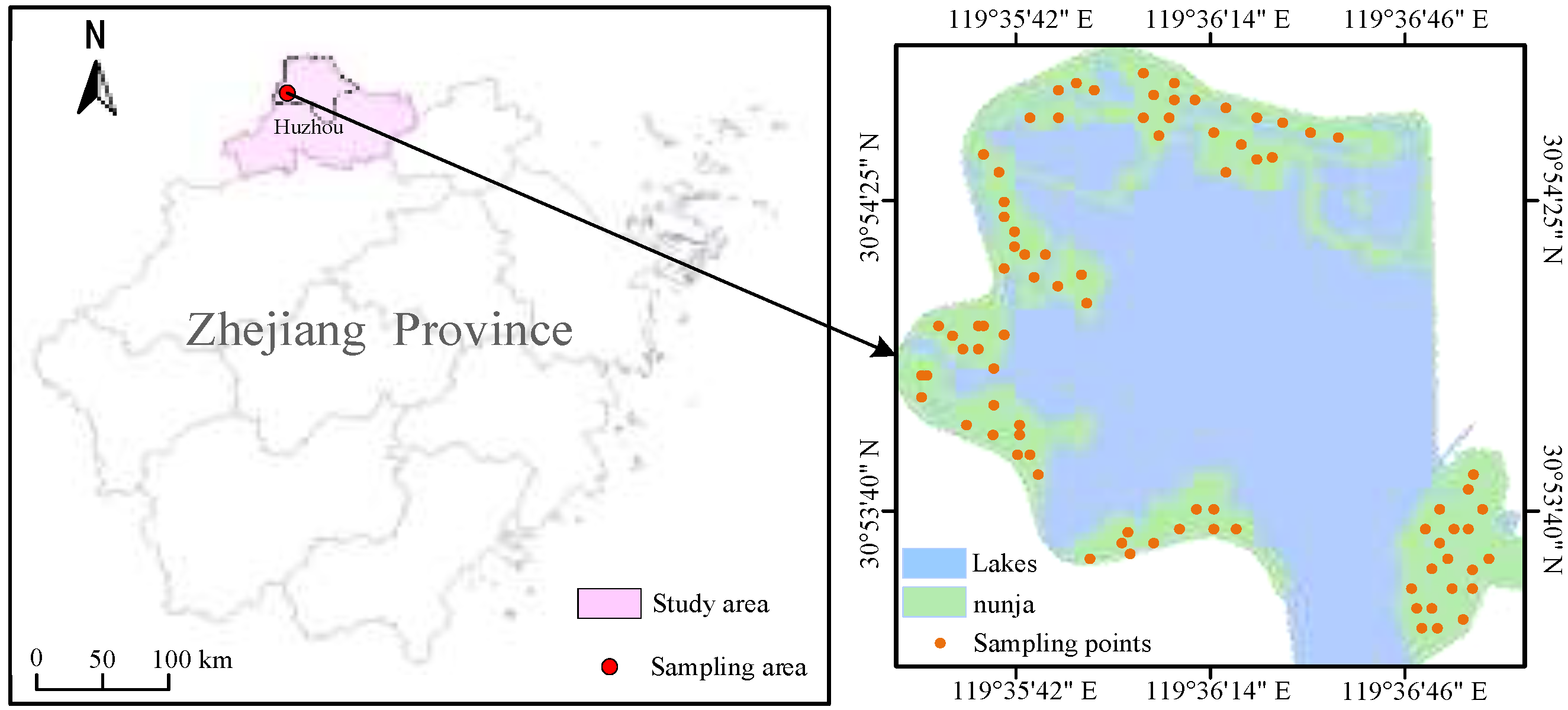
2.1. Collection and Testing of Soil Samples
2.2. Spectral Data PreProcessing Methods for Soils
2.3. Spectral Data Feature Band Selection
3. Models Overview
3.1. Traditional Machine Learning Model
3.1.1. Multiple Linear Regression (MLR)
3.1.2. Partial Least Squares Regression (PLSR)
3.1.3. Support Vector Regression (SVR)
3.1.4. Random Forest (RF)
3.2. Marine-Predators-Algorithm-Based Random Forest
3.3. Model Evaluation
3.4. Research Route
4. Results
4.1. Statistical Analysis of Soil Organic Matter Content
4.2. Soil Spectral Profile Characterization
4.3. Correlation Analysis of Organic Matter Content with Different Spectral Transformation Forms
4.4. Extraction of Feature Bands Using SCARS Algorithm
4.5. Comparative Analysis of Soil Organic Matter Content Inversion Model Accuracy
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Murphy, B. Key soil functional properties affected by soil organic matter-evidence from published literature. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Bendigo, VIC, Australia, 24–27 March 2014. [Google Scholar]
- Angelopoulou, T.; Balafoutis, A.; Zalidis, G.; Bochtis, D. From Laboratory to Proximal Sensing Spectroscopy for Soil Organic Carbon Estimation—A Review. Sustainability 2020, 12, 443. [Google Scholar] [CrossRef]
- Shang, T.; Mao, H.; Zhang, J.; Cheng, R.; Wang, F.; Jia, K. Hyperspectral estimation of soil organic matter content in Yinchuan plain, China based on PCA sensitive band screening and SVM modeling. Chin. J. Ecol. 2021, 40, 4128–4136, (In Chinese with English Abstract). [Google Scholar]
- Wang, S.; Zhuang, Q.; Jin, X.; Yang, Z.; Liu, H. Predicting Soil Organic Carbon and Soil Nitrogen Stocks in Topsoil of Forest Ecosystems in Northeastern China Using Remote Sensing Data. Remote Sens. 2020, 12, 1115. [Google Scholar] [CrossRef]
- Huang, X.; Wang, X.; Baishan, K.; An, B. Hyperspectral Estimation of Soil Organic Carbon Content Based on Continuous Wavelet Transform and Successive Projection Algorithm in Arid Area of Xinjiang, China. Sustainability 2023, 15, 2587. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Wang, Y.; Xu, X.; Han, C.; Wang, Q. A Hyperspectral prediction model for organic matter content in soil developed from Loess-like parent material in Liaoning Province. Chin. J. Soil. Sci. 2022, 53, 1320–1330, (In Chinese with English Abstract). [Google Scholar]
- Zhou, W.; Li, H.; Wen, S.; Xie, L.; Wang, T.; Tian, Y.; Yu, W. Simulation of Soil Organic Carbon Content Based on Laboratory Spectrum in the Three-Rivers Source Region of China. Remote Sens. 2022, 14, 1521. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, J.; Wang, J. Spectral Characteristics of Oasis Soil in Arid Area Based on Harmonic Analysis Algorithm. Acta Opt. Sin. 2019, 39, 0228003. [Google Scholar] [CrossRef]
- Chen, C.; Dai, H.; Feng, Y.; Yang, Z.; Yang, J. Setinel-2A based inversion of the organic matter content of soil the Sunwu area. Geophys. Geochem. Explor. 2022, 46, 1141–1148. [Google Scholar]
- Liu, T.; Zhu, X.; Bai, X.; Peng, Y.; Li, M.; Tian, Z.; Jiang, Y.; Yang, G. Hyperspectral estimation model construction and accuracy comparison of soil organic matter content. Smart Agric. 2020, 2, 129–138. [Google Scholar]
- Choudhury, B.U.; Divyanth, L.G.; Chakraborty, S. Land use/land cover classification using hyperspectral soil reflectance features in the Eastern Himalayas. India. Catena. 2023, 229, 107200. [Google Scholar] [CrossRef]
- Chang, N.; Jing, X.; Zeng, W.; Zhang, Y.; Li, Z. Soil Organic Carbon Prediction Based on Different Combinations of Hyperspectral Feature Selection and Regression Algorithms. Agronomy 2023, 13, 1806. [Google Scholar] [CrossRef]
- Claesen, M.; De Moor, B. Hyperparameter search in machine learning. arXiv 2015, arXiv:1502.02127. [Google Scholar]
- Walkley, A.; Black, I.A. An examination of the Degtjareff method for determining soil organic matter, and a proposed modification of the chromic acid titration method. Soil Sci. 1934, 37, 29–38. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, S.; Li, S.; Yi, J.; Fu, P. Prediction and map-making of soil organic matter of soil profile based on imaging spectroscopy: A case in Hubei China. In Proceedings of the 2011 19th International Conference on Geoinformatics, Shanghai, China, 24–26 June 2011; pp. 1–5. [Google Scholar]
- Zhao, A.; Tang, X.; Zhang, Z.; Liu, J. The parameters optimization selection of Savitzky-Golay filter and its application in smoothing pretreatment for FTIR spectra. In Proceedings of the 2014 9th IEEE Conference on Industrial Electronics and Applications, Hangzhou, China, 9–11 June 2014; pp. 516–521. [Google Scholar]
- Yun, Y.H.; Li, H.D.; Deng, B.C.; Cao, D.S. An overview of variable selection methods in multivariate analysis of near-infrared spectra. Trends Anal. Chem. 2019, 113, 102–115. [Google Scholar] [CrossRef]
- Zheng, K.; Li, Q.; Wang, J.; Geng, J.; Cao, P.; Sui, T.; Wang, X.; Du, Y. Stability competitive adaptive reweighted sampling (SCARS) and its applications to multivariate calibration of NIR spectra. Chemom. Intell. Lab. Syst. 2012, 112, 48–54. [Google Scholar] [CrossRef]
- Zare, S.; Shamsi, S.R.; Abtahi, S.M. Weakly-coupled geostatistical mapping of soil salinity to Stepwise Multiple Linear Regression of MODIS spectral image products. J. Afr. Earth Sci. 2019, 152, 101–114. [Google Scholar] [CrossRef]
- Cheng, J.H.; Sun, D.W. Partial least squares regression (PLSR) applied to NIR and HSI spectral data modeling to predict chemical properties of fish muscle. Food Eng. Rev. 2017, 9, 36–49. [Google Scholar] [CrossRef]
- Xu, S.; Lu, B.; Baldea, M.; Edgar, T.F.; Nixon, M. An improved variable selection method for support vector regression in NIR spectral modeling. J. Process Control. 2018, 67, 83–93. [Google Scholar] [CrossRef]
- Bao, Y.; Meng, X.; Ustin, S.; Wang, X.; Zhang, X.; Liu, H.; Tang, H. Estimation of soil organic matter content based on CARS algorithm coupled with random forest. Spectrochim. Acta Part. A Mol. Biomol. Spectrosc. 2021, 258, 119823. [Google Scholar]
- Faramarzi, A.; Heidarinejad, M.; Mirjalili, S.; Gandomi, A.H. Marine Predators Algorithm: A nature-inspired metaheuristic. Expert Syst. Appl. 2020, 152, 113377. [Google Scholar] [CrossRef]
- Kawamura, K.; Tsujimoto, Y.; Nishigaki, T.; Andriamananjara, A.; Rabenarivo, M.; Asai, H.; Rakotoson, T.; Razafimbelo, T. Laboratory Visible and Near-Infrared Spectroscopy with Genetic Algorithm-Based Partial Least Squares Regression for Assessing the Soil Phosphorus Content of Upland and Lowland Rice Fields in Madagascar. Remote Sens. 2019, 11, 506. [Google Scholar] [CrossRef]
- Zhao, H.L.; Gan, S.; Yuan, X.P.; Hu, L.; Liu, S.; Wang, J. Inversion of soil iron oxide based on multi-scale continuous wavelet decomposition. Chin. J. Acta Opt. Sin. 2022, 42, 2230003. [Google Scholar]
- Ge, X.Y.; Ding, J.L.; Wang, J.Z. Estimation of soil moisture content based on competitive adaptive reweighted sampling algorithm coupled with machine learning. Chin. J. Acta Opt. Sin. 2018, 38, 1030001. [Google Scholar]
- Zhou, Q.Q.; Ding, J.L.; Huang, S. Hyperspectral estimation of soil organic carbon and its influencing factors in arid oasis. Chin. J. Agric. Res. Arid. Areas. 2018, 36, 200–206. [Google Scholar]
- Shen, L.; Gao, M.; Yan, J.; Li, Z.-L.; Leng, P.; Yang, Q.; Duan, S.-B. Hyperspectral Estimation of Soil Organic Matter Content using Different Spectral Preprocessing Techniques and PLSR Method. Remote Sens. 2020, 12, 1206. [Google Scholar] [CrossRef]
- Zhang, X.Q.; Li, Z.W.; Deng, D.C.; Song, H.Y.; Wang, G.L. VIS-NIR Hyperspectral Prediction of Soil Organic Matter Based on Stacking Generalization Model. Chin. J. Spectrosc. Spectr. Anal. 2023, 43, 903–910. [Google Scholar]
- Wang, Z.; Zhang, F.; Zhang, X.; Chan, N.W.; Kung, H.T.; Ariken, M.; Zhou, X.; Wang, Y. Regional Suitability Prediction of Soil Salinization Based on Remote-Sensing Derivatives and Optimal Spectral Index. Sci. Total Environ. 2021, 775, 145807. [Google Scholar] [CrossRef]
- Mohapatra, N.; Shreya, K.; Chinmay, A. Optimization of the Random Forest Algorithm. In Advances in Data Science and Management; Springer: Singapore, 2020; pp. 201–208. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Differential Transformation Method | Theoretical Formula | Differential Transformation Method | Theoretical Formula |
|---|---|---|---|
| FD | SD | ||
| LFD | LSD | ||
| RFD | RSD | ||
| LRFD | LRSD | ||
| RLFD | RLSD |
| Statistics | Number of Samples | Maximum Value | Minimum Value | Mean Value | Standard Deviation | Coefficient of Variation |
|---|---|---|---|---|---|---|
| Total sample | 85 | 19.40 | 3.68 | 9.77 | 3.80 | 38.94 |
| Training sample | 59 | 18.50 | 5.03 | 9.68 | 3.53 | 36.56 |
| Testing sample | 26 | 19.40 | 3.68 | 9.81 | 3.97 | 40.54 |
| Spectral Transformation Form | N | FD | SD | RFD | RSD | LRFD | LRSD | RLFD | RLSD |
|---|---|---|---|---|---|---|---|---|---|
| Maximum value | 0.01 | 0.55 | 0.35 | 0.38 | 0.37 | 0.24 | 0.33 | 0.43 | 0.40 |
| Minimum value | −0.10 | −0.38 | −0.33 | −0.54 | 0.42 | −0.51 | −0.30 | −0.53 | −0.39 |
| Spectral Transformation Form | Feature Band/nm |
|---|---|
| N | 946, 1034, 1038, 1045, 1055, 1199, 1214, 1344, 1375, 1428 |
| FD | 1077, 1081, 1095, 1116, 1275, 1278, 1402, 1469, 1522, 1604, 1611, 1681 |
| SD | 996, 1003, 1188, 1213, 1227, 1234, 1241, 1255, 1273, 1280, 1333, 1337, 1351, 1401, 1426, 1433, 1436, 1440, 1465, 1472, 1507, 1525, 1539, 1557, 1568, 1575, 1582, 1603, 1653, 1656, 1681, 1685 |
| RFD | 1176, 1183, 1257, 1264, 1459, 1522, 1568 |
| RSD | 971, 996, 1010, 1213, 1227, 1241, 1255, 1294, 1383, 1397, 1426, 1433, 1436, 1440, 1504, 1507, 1525, 1582, 1653 |
| LRFD | 1095, 1116, 1119, 1179, 1183, 1275, 1278, 1324, 1399, 1423, 1430, 1459, 1469, 1522, 1529, 1604, 1607, 1681 |
| LRSD | 996, 1003, 1188, 1220, 1255, 1273, 1305, 1337, 1372, 1397, 1426, 1433, 1436, 1440, 1472, 1507, 1525, 1568, 1582, 1653, 1656, 1681 |
| RLFD | 971, 1073, 1112, 1176, 1183, 1194, 1257, 1264, 1275, 1278, 1459, 1469, 1505, 1522, 1568, 1611 |
| RLSD | 996, 1213, 1241, 1255, 1266, 1397, 1426, 1433, 1436, 1440, 1472, 1525, 1568, 1582, 1653, 1681 |
| Spectral Transformation Form | Model | Training Set | Testing Set | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | RPD | R2 | RMSE | RPD | ||
| N | MLR | 0.62 | 2.16 | 1.63 | 0.51 | 3.12 | 1.43 |
| PLSR | 0.60 | 2.27 | 1.59 | 0.60 | 2.62 | 1.58 | |
| SVR | 0.53 | 2.71 | 1.45 | 0.44 | 2.57 | 1.34 | |
| RF | 0.36 | 2.95 | 1.25 | 0.27 | 3.29 | 1.17 | |
| MPARF | 0.70 | 2.02 | 1.82 | 0.65 | 2.58 | 1.77 | |
| FD | MLR | 0.76 | 1.91 | 2.05 | 0.66 | 2.56 | 1.72 |
| PLSR | 0.73 | 1.82 | 1.94 | 0.69 | 2.18 | 1.79 | |
| SVR | 0.77 | 1.65 | 2.08 | 0.63 | 2.72 | 1.64 | |
| RF | 0.85 | 1.51 | 2.61 | 0.59 | 2.26 | 1.56 | |
| MPARF | 0.88 | 1.47 | 2.80 | 0.86 | 1.55 | 2.40 | |
| SD | MLR | 0.85 | 1.40 | 2.59 | 0.61 | 2.52 | 1.60 |
| PLSR | 0.70 | 2.08 | 2.98 | 0.65 | 2.32 | 1.70 | |
| SVR | 0.54 | 2.87 | 1.48 | 0.49 | 2.96 | 1.39 | |
| RF | 0.52 | 2.71 | 1.44 | 0.39 | 2.98 | 1.28 | |
| MPARF | 0.92 | 1.27 | 3.14 | 0.90 | 1.32 | 3.02 | |
| RFD | MLR | 0.70 | 2.02 | 1.83 | 0.63 | 2.49 | 1.65 |
| PLSR | 0.75 | 2.00 | 1.98 | 0.67 | 2.20 | 1.73 | |
| SVR | 0.69 | 2.21 | 1.80 | 0.58 | 2.24 | 1.54 | |
| RF | 0.80 | 1.66 | 2.23 | 0.70 | 2.00 | 1.82 | |
| MPARF | 0.85 | 1.41 | 2.57 | 0.78 | 1.80 | 2.11 | |
| RSD | MLR | 0.63 | 2.19 | 1.65 | 0.54 | 2.54 | 1.47 |
| PLSR | 0.77 | 1.84 | 2.09 | 0.75 | 1.83 | 2.00 | |
| SVR | 0.68 | 2.28 | 1.77 | 0.75 | 1.54 | 2.02 | |
| RF | 0.61 | 2.34 | 1.60 | 0.57 | 2.50 | 1.52 | |
| MPARF | 0.90 | 1.32 | 1.27 | 0.85 | 1.42 | 2.40 | |
| LRFD | MLR | 0.82 | 1.52 | 2.35 | 0.72 | 2.26 | 1.89 |
| PLSR | 0.74 | 1.99 | 1.98 | 0.74 | 1.79 | 1.94 | |
| SVR | 0.76 | 1.91 | 2.05 | 0.63 | 2.16 | 1.65 | |
| RF | 0.71 | 1.75 | 1.86 | 0.53 | 2.97 | 1.47 | |
| MPARF | 0.84 | 1.46 | 2.57 | 0.77 | 1.75 | 2.03 | |
| LRSD | MLR | 0.74 | 1.97 | 1.94 | 0.64 | 2.09 | 1.67 |
| PLSR | 0.77 | 1.74 | 2.08 | 0.73 | 1.98 | 1.94 | |
| SVR | 0.66 | 2.20 | 1.71 | 0.58 | 2.50 | 1.54 | |
| RF | 0.61 | 2.13 | 1.60 | 0.55 | 2.96 | 1.48 | |
| MPARF | 0.88 | 1.36 | 2.97 | 0.85 | 1.53 | 2.55 | |
| RLFD | MLR | 0.77 | 1.89 | 2.09 | 0.68 | 2.05 | 1.76 |
| PLSR | 0.83 | 1.56 | 2.39 | 0.52 | 2.71 | 1.44 | |
| SVR | 0.81 | 1.59 | 2.32 | 0.66 | 2.41 | 1.71 | |
| RF | 0.74 | 1.84 | 1.95 | 0.75 | 2.10 | 2.00 | |
| MPARF | 0.89 | 1.41 | 2.88 | 0.81 | 1.54 | 2.31 | |
| RLSD | MLR | 0.71 | 2.06 | 1.87 | 0.67 | 2.07 | 1.74 |
| PLSR | 0.81 | 1.58 | 2.31 | 0.76 | 1.87 | 2.04 | |
| SVR | 0.75 | 1.69 | 2.01 | 0.69 | 2.48 | 1.78 | |
| RF | 0.63 | 2.13 | 1.63 | 0.52 | 3.01 | 1.44 | |
| MPARF | 0.91 | 1.31 | 3.11 | 0.87 | 1.35 | 2.94 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, L.; Zu, W.; Yang, F.; Gao, L.; Gu, G.; Zhao, M. Estimating Organic Matter Content in Hyperspectral Wetland Soil Using Marine-Predators-Algorithm-Based Random Forest and Multiple Differential Transformations. Appl. Sci. 2023, 13, 10693. https://doi.org/10.3390/app131910693
Jia L, Zu W, Yang F, Gao L, Gu G, Zhao M. Estimating Organic Matter Content in Hyperspectral Wetland Soil Using Marine-Predators-Algorithm-Based Random Forest and Multiple Differential Transformations. Applied Sciences. 2023; 13(19):10693. https://doi.org/10.3390/app131910693
Chicago/Turabian StyleJia, Liangquan, Weiwei Zu, Fu Yang, Lu Gao, Guosong Gu, and Mingxing Zhao. 2023. "Estimating Organic Matter Content in Hyperspectral Wetland Soil Using Marine-Predators-Algorithm-Based Random Forest and Multiple Differential Transformations" Applied Sciences 13, no. 19: 10693. https://doi.org/10.3390/app131910693
APA StyleJia, L., Zu, W., Yang, F., Gao, L., Gu, G., & Zhao, M. (2023). Estimating Organic Matter Content in Hyperspectral Wetland Soil Using Marine-Predators-Algorithm-Based Random Forest and Multiple Differential Transformations. Applied Sciences, 13(19), 10693. https://doi.org/10.3390/app131910693