
A Real-Time Dynamic Gesture Variability Recognition Method Based on Convolutional Neural Networks

 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Purpose and Summary of the Work
- (1)
- Is it possible in practice to use technologies that integrate hand, body, and head movements to improve sign language recognition?
- (2)
- Is it possible to group gestures for a more accurate and reliable interpretation of sign language?
- (3)
- Is it possible to create preprocessing software that allows for gesture properties to be automatically collected from video files or in real time from a video camera system?
- (4)
- Is the created architecture of the real-time dynamic gesture variability recognition system based on CNNs effective for different data sets?
3. Materials and Methods
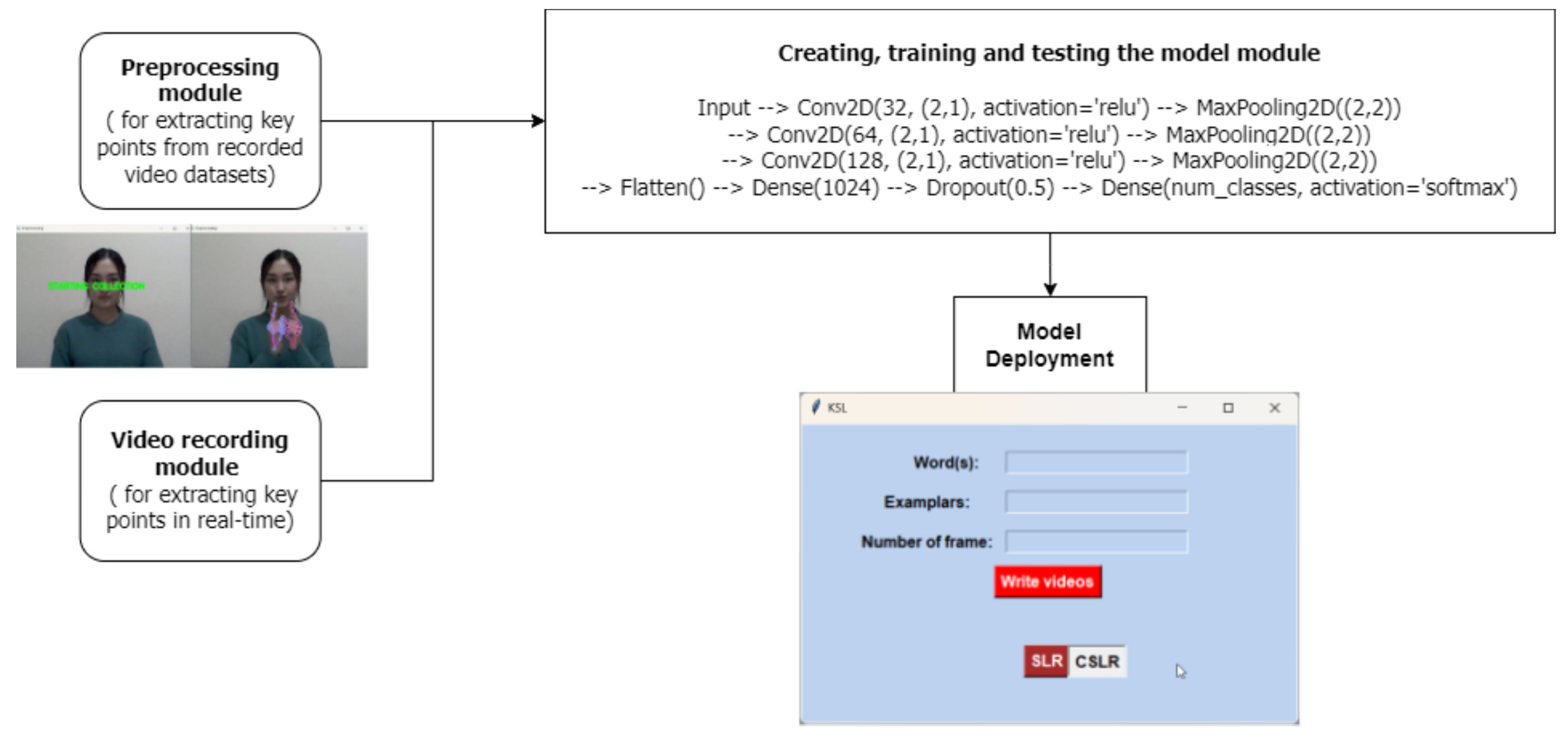
3.1. Preprocessing Module
- Palm orientation:
- Palms facing the camera—gestures in which the palm faces the camera, and the fingers are visible to the viewer; for example, pointing or greeting.
- Palms facing away from the camera—gestures in which the back of the palm faces the camera, and the fingers are not visible, for example, a demonstration of refusal or disapproval.
- Localization:
- Upper body—gestures involving movements of the arms and hands above the waist; for example, waving, clapping, or stretching the hand.
- Lower body—gestures related to the movements of the legs and feet; for example, walking, running, or jumping.
- Trajectory of movement:
- Parallel to the camera—gestures in which the hand moves in the same plane as the camera; for example, waving or gesticulating horizontally.
- Perpendicular to the camera—gestures in which the hand moves towards or away from the camera; for example, points or stretches.
3.2. Video Recording Module
3.3. Creating, Training, and Testing the Model Module
3.4. Model Demployment Module
4. Results
5. Discussion
6. Conclusions
7. Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. List of Words Used in This Research

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Kazakh Sign Word in Latin | Kazakh Sign Word in Cyrillic | Translation |
|---|---|---|---|
| 1. | bayandau | Баяндау | Narrative |
| 2. | jangbyr | Жаңбыр | Rain |
| 3. | jaryk | Жарық | Light |
| 4. | jyrtu | Жырту | Plow |
| 5. | kezdesu | Кездесу | The meeting |
| 6. | khauyn | Қауын | Melon |
| 7. | kholghap | Қoлғап | Gloves |
| 8. | kobelek | Көбелек | Butterfly |
| 9. | korpe | Көрпе | Blanket |
| 10. | shainek | Шәйнек | Kettle |
| 11. | akylsyz | Ақылсыз | Crazy |
| 12. | demalu | Демалу | Rest |
| 13. | grimm | Гримм | Grimm |
| 14. | khasyk | Қасық | Spoon |
| 15. | khuany | Қуану | Rejoice |
| 16. | kuieu jigit | Күйеу жігіт | The groom |
| 17. | paidaly | Пайдалы | Useful |
| 18. | shattanu | Шаттану | Delight |
| 19. | tate | Тәте | Aunt |
| 20. | unaidy | Ұнайды | Like |
| 21. | aiau | Аяу | Pity |
| 22. | alup kely | Алып келу | Bring |
| 23. | aparu | Апару | Drag |
| 24. | aser etu | Әсер ету | Influence |
| 25. | beldemshe | Белдемше | Skirt |
| 26. | jalgasu | Жалғасу | Continuation |
| 27. | jien | Жиен | Nephew |
| 28. | keshiru | Кешіру | Forgive |
| 29. | kuieu | Күйеу | Husband |
| 30. | oktau | Оқтау | Loading |
| 31. | akelu | Әкелу | Bring |
| 32. | ana | Ана | Mother |
| 33. | apa | Апа | Sister |
| 34. | auru | Ауру | Disease |
| 35. | balalar | Балалар | Children |
| 36. | dari | Дәрі | Medicine |
| 37. | et | Ет | Meat |
| 38. | korshi | Көрші | Neighbor |
| 39. | shakyru | Шақыру | The invitation |
| 40. | tanysu | Танысу | Dating |
References
- Abdullahi, S.B.; Chamnongthai, K. American Sign Language Words Recognition Using Spatio-Temporal Prosodic and Angle Features: A Sequential Learning Approach. IEEE Access 2022, 10, 15911–15923. [Google Scholar] [CrossRef]
- Sincan, O.M.; Keles, H.Y. Using Motion History Images With 3D Convolutional Networks in Isolated Sign Language Recognition. IEEE Access 2022, 10, 18608–18618. [Google Scholar] [CrossRef]
- Deafness and Hearing Loss. Available online: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (accessed on 22 July 2023).
- Sahoo, J.P.; Prakash, A.J.; Pławiak, P.; Samantray, S. Real-Time Hand Gesture Recognition Using Fine-Tuned Convolutional Neural Network. Sensors 2022, 22, 706. [Google Scholar] [CrossRef]
- Bird, J.J.; Ekárt, A.; Faria, D.R. British Sign Language Recognition via Late Fusion of Computer Vision and Leap Motion with Transfer Learning to American Sign Language. Sensors 2020, 20, 5151. [Google Scholar] [CrossRef]
- Amangeldy, N.; Kudubayeva, S.; Razakhova, B.; Mukanova, A.; Tursynova, N. Comparative analysis of classification methods of the dactyl alphabet of the Kazakh language. J. Theor. Appl. Inf. Technol. 2022, 100, 5506–5523. Available online: http://www.jatit.org/volumes/Vol100No19/9Vol100No19.pdf (accessed on 18 April 2023).
- Amangeldy, N.; Kudubayeva, S.; Kassymova, A.; Karipzhanova, A.; Razakhova, B.; Kuralov, S. Sign Language Recognition Method Based on Palm Definition Model and Multiple Classification. Sensors 2022, 22, 6621. [Google Scholar] [CrossRef] [PubMed]
- Thejowahyono, N.F.; Setiawan, M.V.; Handoyo, S.B.; Rangkuti, A.H. Hand Gesture Recognition as Signal for Help using Deep Neural Network. Int. J. Emerg. Technol. Adv. Eng. 2022, 12, 37–47. [Google Scholar] [CrossRef] [PubMed]
- Sosa-Jimenez, C.O.; Rios-Figueroa, H.V.; Rechy-Ramirez, E.J.; Marin-Hernandez, A.; Gonzalez-Cosio, A.L.S. Real-time Mexican Sign Language recognition. In Proceedings of the 2017 IEEE International Autumn Meeting on Power, Electronics and Computing, ROPEC 2017, Ixtapa, Mexico, 8–10 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Dayal, A.; Paluru, N.; Cenkeramaddi, L.R.; Soumya, J.; Yalavarthy, P.K. Design and Implementation of Deep Learning Based Contactless Authentication System Using Hand Gestures. Electronics 2021, 10, 182. [Google Scholar] [CrossRef]
- Karacı, A.; Akyol, K.; Turut, M.U. Real-Time Turkish Sign Language Recognition Using Cascade Voting Approach with Handcrafted Features. Appl. Comput. Syst. 2021, 26, 12–21. [Google Scholar] [CrossRef]
- Tateno, S.; Liu, H.; Ou, J. Development of Sign Language Motion Recognition System for Hearing-Impaired People Using Electromyography Signal. Sensors 2020, 20, 5807. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Tam, V.W.L.; Lam, E.Y. A Portable Sign Language Collection and Translation Platform with Smart Watches Using a BLSTM-Based Multi-Feature Framework. Micromachines 2022, 13, 333. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Tam, V.W.L.; Lam, E.Y. SignBERT: A BERT-Based Deep Learning Framework for Continuous Sign Language Recognition. IEEE Access 2021, 9, 161669–161682. [Google Scholar] [CrossRef]
- Kapuscinski, T.; Wysocki, M. Recognition of Signed Expressions in an Experimental System Supporting Deaf Clients in the City Office. Sensors 2020, 20, 2190. [Google Scholar] [CrossRef]
- Vaitkevičius, A.; Taroza, M.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R.; Woźniak, M. Recognition of American Sign Language Gestures in a Virtual Reality Using Leap Motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef]
- Du, Y.; Dang, N.; Wilkerson, R.; Pathak, P.; Rangwala, H.; Kosecka, J. American Sign Language Recognition Using an FMCWWireless Sensor. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Papastratis, I.; Dimitropoulos, K.; Daras, P. Continuous Sign Language Recognition through a Context-Aware Generative Adversarial Network. Sensors 2021, 21, 2437. [Google Scholar] [CrossRef]
- Papastratis, I.; Dimitropoulos, K.; Konstantinidis, D.; Daras, P. Continuous Sign Language Recognition Through Cross-Modal Alignment of Video and Text Embeddings in a Joint-Latent Space. IEEE Access 2020, 8, 91170–91180. [Google Scholar] [CrossRef]
- Zhou, H.; Zhou, W.; Zhou, Y.; Li, H. Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, AAAI 2020, New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Ahmed, M.; Zaidan, B.; Zaidan, A.; Salih, M.M.; Al-Qaysi, Z.; Alamoodi, A. Based on wearable sensory device in 3D-printed humanoid: A new real-time sign language recognition system. Measurement 2021, 168, 108431. [Google Scholar] [CrossRef]
- Alrubayi, A.; Ahmed, M.; Zaidan, A.; Albahri, A.; Zaidan, B.; Albahri, O.; Alamoodi, A.; Alazab, M. A pattern recognition model for static gestures in malaysian sign language based on machine learning techniques. Comput. Electr. Eng. 2021, 95, 107383. [Google Scholar] [CrossRef]
- Al-Samarraay, M.S.; Zaidan, A.; Albahri, O.; Pamucar, D.; AlSattar, H.; Alamoodi, A.; Zaidan, B.; Albahri, A. Extension of interval-valued Pythagorean FDOSM for evaluating and benchmarking real-time SLRSs based on multidimensional criteria of hand gesture recognition and sensor glove perspectives. Appl. Soft Comput. 2021, 116, 108284. [Google Scholar] [CrossRef]
- Ahmed, M.A.; Zaidan, B.B.; Zaidan, A.A.; Alamoodi, A.H.; Albahri, O.S.; Al-Qaysi, Z.T.; Albahri, A.S.; Salih, M.M. Real-time sign language framework based on wearable device: Analysis of MSL, DataGlove, and gesture recognition. Soft Comput. 2021, 25, 11101–11122. [Google Scholar] [CrossRef]
- Tornay, S.; Razavi, M.; Magimai-Doss, M. Towards multilingual sign language recognition. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 6309–6313. [Google Scholar] [CrossRef]
- Sincan, O.M.; Keles, H.Y. AUTSL: A Large Scale Multi-Modal Turkish Sign Language Dataset and Baseline Methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Ronchetti, F.; Quiroga, F.; Estrebou, C.; Lanzarini, L.; Rosete, A. LSA64: A Dataset for Argentinian Sign Language. In Proceedings of the XXII Congreso Argentino de Ciencias de la Computación, CACIC 2016, San Luis, Argentina, 3–7 October 2016; pp. 794–803. [Google Scholar]
- Ryumin, D.; Kagirov, I.; Axyonov, A.; Pavlyuk, N.; Saveliev, A.; Kipyatkova, I.; Zelezny, M.; Mporas, I.; Karpov, A. A Multimodal User Interface for an Assistive Robotic Shopping Cart. Electronics 2020, 9, 2093. [Google Scholar] [CrossRef]
- Hand Landmarks Detection Guide. Available online: https://developers.google.com/mediapipe/solutions/vision/hand_landmarker (accessed on 8 January 2023).
- MediaPipe Holistic. Available online: https://google.github.io/mediapipe/solutions/holistic (accessed on 8 January 2023).
- Ryumin, D.; Ivanko, D.; Ryumina, E. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton Aware Multi-modal Sign Language Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 19–25 June 2012; pp. 3408–3418. [Google Scholar] [CrossRef]
- De Coster, M.; Van Herreweghe, M.; Dambre, J. Isolated Sign Recognition from RGB Video using Pose Flow and Self-Attention. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 19–25 June 2021; pp. 3436–3445. [Google Scholar] [CrossRef]







| Datasets | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| AUTSL | 0.93 | 0.93 | 0.93 | 0.93 |
| LSA64 | 1 | 1 | 1 | 1 |
| KSL | 0.98 | 0.98 | 0.98 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amangeldy, N.; Milosz, M.; Kudubayeva, S.; Kassymova, A.; Kalakova, G.; Zhetkenbay, L. A Real-Time Dynamic Gesture Variability Recognition Method Based on Convolutional Neural Networks. Appl. Sci. 2023, 13, 10799. https://doi.org/10.3390/app131910799
Amangeldy N, Milosz M, Kudubayeva S, Kassymova A, Kalakova G, Zhetkenbay L. A Real-Time Dynamic Gesture Variability Recognition Method Based on Convolutional Neural Networks. Applied Sciences. 2023; 13(19):10799. https://doi.org/10.3390/app131910799
Chicago/Turabian StyleAmangeldy, Nurzada, Marek Milosz, Saule Kudubayeva, Akmaral Kassymova, Gulsim Kalakova, and Lena Zhetkenbay. 2023. "A Real-Time Dynamic Gesture Variability Recognition Method Based on Convolutional Neural Networks" Applied Sciences 13, no. 19: 10799. https://doi.org/10.3390/app131910799
APA StyleAmangeldy, N., Milosz, M., Kudubayeva, S., Kassymova, A., Kalakova, G., & Zhetkenbay, L. (2023). A Real-Time Dynamic Gesture Variability Recognition Method Based on Convolutional Neural Networks. Applied Sciences, 13(19), 10799. https://doi.org/10.3390/app131910799