1. Introduction
Currently, air traffic management in the civil aviation sector in China primarily relies on manual control, with radio communication being used for the instructions exchanged between air traffic controllers and pilots. During the process of voice interaction, factors such as noise, accents, speaking rate, intonation, and timbre can affect the transmission of speech information and auditory perception. However, clear and accurate voice communication between controllers and pilots is a crucial factor in ensuring flight safety. Therefore, the evaluation of the quality of air traffic control speech is of utmost importance.
Speech quality assessment can be broadly categorized into two categories: subjective methods and objective methods. Subjective evaluation, which takes into account the perceptual characteristics of the human auditory system, is widely adopted due to its high credibility and reliability. This method requires professionals to reference the pristine clean version of the speech signal to estimate the quality of the distorted speech signal, typically using a rating scale ranging from 1 to 5 [
1], as shown in
Table 1. The average of all ratings is referred to as the mean opinion score (MOS) [
2]. During the evaluation process, professionals consider various aspects, including noise, distortion, speech clarity, the naturalness of sound, and alignment with specific application scenarios, which allows for a relatively objective assessment of speech quality.
However, subjective evaluation methods exhibit limitations, encompassing rater subjectivity and variability, as well as the time-consuming, costly, and non-repeatable nature of the evaluation process [
3]. To address these challenges, researchers have begun proposing objective evaluation methods. Objective evaluation methods aim to quantify and measure speech quality by using computer algorithms or automation techniques, thus reducing the influence of subjective factors [
4]. These methods can be based on acoustic features, waveform analysis, signal processing, and other techniques, using mathematical models and algorithms to assess speech quality. Compared to subjective evaluation methods, objective evaluation methods offer better repeatability and consistency, as well as higher efficiency and lower costs.
Objective evaluation methods can be classified into intrusive and non-intrusive types. Intrusive models also require the pristine clean version of the speech signal as a reference to estimate the quality of distorted speech signals, such as the PESQ model proposed in ITU-T Recommendation P.862 [
5,
6]. In contrast, non-intrusive models solely rely on the output signal of the transmission system to estimate the MOS, such as the P.563 model introduced by ITU-T [
7,
8]. Obtaining the pristine clean version of the speech signal can be challenging in practical communication scenarios. Therefore, non-intrusive objective evaluation has become a hot topic in domestic and international research to ensure real-time and convenience. Non-intrusive models can directly assess distorted speech signals, offering greater flexibility to adapt to different application scenarios and reducing the complexity of the evaluation process [
9]. This method holds significant importance for a wide range of speech quality assessment tasks.
With the continuous development of technologies like deep learning, researchers are exploring and improving non-intrusive objective evaluation methods to enhance their accuracy and reliability. These methods leverage models such as neural networks to automatically learn speech features and patterns, enabling more precise speech quality assessment. Future research will continue to focus on the advancement of non-intrusive objective evaluation, further driving its application in practical scenarios.
Related Work
Various non-intrusive speech quality assessment methods are available in the literature. A non-intrusive speech quality assessment method under complex environments is proposed in [
10,
11]. The method [
10] employs Bayesian non-negative matrix factorization (BNMF) to calculate the fundamental spectro-temporal matrixes of the target speech, integrating the resulting matrix, as a separate layer, into the deep neural network (DNN) model. Subsequently, a deep neural network is trained to learn the complex mapping between the target source and the mixture signal, reconstructing the magnitude spectrogram of the quasi-clean speech. Finally, the reconstructed speech is regarded as the reference of the modified PESQ to estimate the MOS of the tested speech sample. The method [
11] learns an overcomplete dictionary of the clean speech power spectrum through K-singular value decomposition. Then, during the sparse representation stage, it adaptively obtains the stopping residue based on the estimated cross-correlation and noise spectrum, adjusted by an a posteriori SNR-weighted factor. It utilizes orthogonal matching pursuit to reconstruct clean speech spectra from noisy speech. By using the quasi-clean speech as a reference, it estimates the degraded speech’s MOS using the modified PESQ. Both of these methods entail constructing reference signals, leading to high computational costs.
Another approach to non-intrusive speech quality assessment involves extracting intrinsic features from the speech signal and then mapping these features to MOS. Compared to reconstructing clean speech, this method has lower computational costs. Fu et al. [
12] proposed an end-to-end non-intrusive speech quality evaluation model based on Bidirectional Long Short-Term Memory (BiLSTM) for predicting speech PESQ scores. However, this model faces difficulties in evaluating enhanced speech with low PESQ scores compared to noisy speech. Chen et al. [
13] studied several neural network architectures for evaluating speech conversion quality, including Convolutional Neural Network (CNN), BiLSTM, and CNN–BiLSTM. However, this model is only applied to speech conversion systems and has limited generalization ability. Donald et al. [
14] used a pyramid BiLSTM with an attention mechanism to predict MOS, and the proposed model achieved scores close to human judgment. However, the encoder of this model, composed of a stacked pyramid BiLSTM, significantly increases the overall computational complexity, making it less suitable for low-resource speech evaluation tasks. Cauchi et al. [
15] combined modulation energy features with a recurrent neural network using Long Short-Term Memory to propose a non-intrusive speech quality evaluation method suitable for evaluating speech enhancement algorithms under various acoustic conditions. Shen et al. [
16] proposed a reference-free speech quality evaluation method based on ResNet and BiLSTM. They utilized an attention mechanism [
17] to obtain weights and scored based on the BiLSTM output, resulting in scores closer to human ratings. However, this model mostly predicts MOS scores between 1.5 and 4.5, and it cannot effectively predict speech quality with low or high MOS scores.
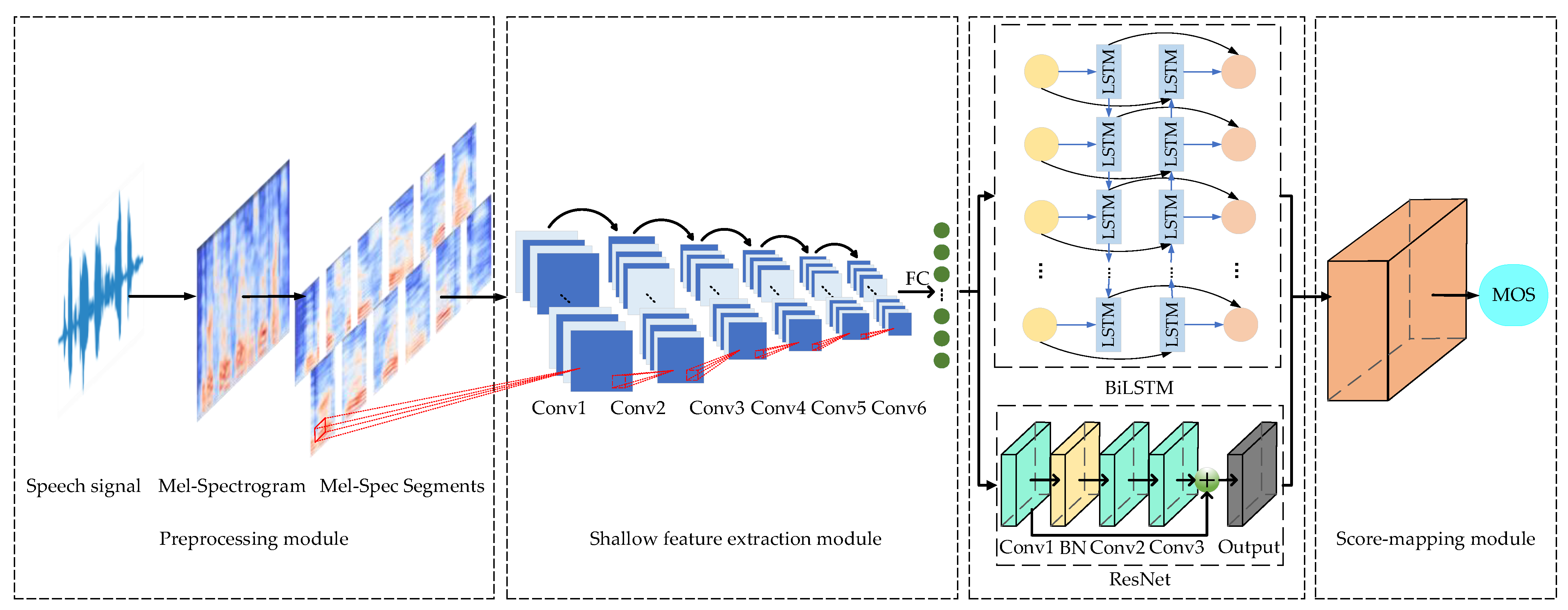
Most of the aforementioned methods available in the literature show promising results, but, to the best of our knowledge, there is no method available for evaluating the quality of air traffic control speech. This work, inspired by the combined advantages of CNN and RNN and the powerful local feature extraction capabilities of ResNet and BiLSTM, proposes a new air traffic control speech quality assessment method based on ResNet and BiLSTM. This paper considers the importance of air traffic control speech details during the communication process, such as call signs, command types, and command content. Through extensive analysis of experimental data, it retains more air traffic control speech details from three aspects. Firstly, the mel-spectrogram is introduced [
18] to capture dense features in the speech, and the mel-spectrogram is segmented for frame-level analysis of speech quality. Secondly, a preceding feature extractor composed of convolutional and pooling layers is employed to compute shallow features suitable for speech quality prediction from mel-spectrogram segments. Lastly, ResNet is utilized to extract spatial features from the shallow features, and BiLSTM is used to extract temporal features from the shallow features [
19]. The extracted features from both ResNet and BiLSTM are concatenated and fused, effectively improving the accuracy of air traffic control speech quality evaluation.
In summary, this paper makes the following contributions:
We created an air traffic control speech database in a real environment, annotated with speech quality scores.
We proposed a new non-intrusive speech quality evaluation method based on ResNet and BiLSTM for air traffic control speech.
We investigated the effects of varying signal-to-noise ratios and speech rates in the aerial traffic control speech dataset on the performance of the proposed method.
In the following,
Section 2 presents the proposed methodology. Subsequently,
Section 3 introduces the database and performance metrics utilized in the experimental setup and the experiments conducted in this study. Finally,
Section 4 presents the conclusion and future work.
4. Conclusions
In this study, a no-reference air traffic control speech quality assessment method was developed by optimizing the details of shallow feature extraction and improving the ResNet–BiLSTM network structure. The experimental results demonstrated that the proposed model accurately estimates the quality of the air traffic control speech and shows a high consistency with subjective evaluations. This provides a feasible solution for air traffic control speech quality assessment.
In the future, we will continue our commitment to enhancing and expanding the practicality and depth of this research. Specifically, we have planned the following initiatives: Firstly, our focus will be on expanding the real air traffic control speech database to encompass a wider range of scenarios and diverse categories of speech samples. This expansion aims to improve the robustness of our model, ensuring its exceptional performance across various contexts. Secondly, we intend to develop a rating standard tailored to air traffic control speech, following the subjective evaluation method proposed by ITU, and apply this standard to rate our speech database. Through subjective evaluations, we will achieve a more accurate quantification of speech quality and validate our model’s performance in real-world scenarios. Additionally, we will continuously refine and optimize the network structure to enhance its capability to accurately predict air traffic control speech quality scores in complex speech environments. This will involve improvements in feature extraction and deep learning architectures to better capture the critical features of speech quality. Lastly, we will conduct an in-depth analysis of the specific factors that influence air traffic control speech quality and convert them into actionable metrics. This will facilitate a deeper understanding of speech quality and further improvements in this domain.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}