

Generating Synthetic Dataset for ML-Based IDS Using CTGAN and Feature Selection to Protect Smart IoT Environments


Abstract
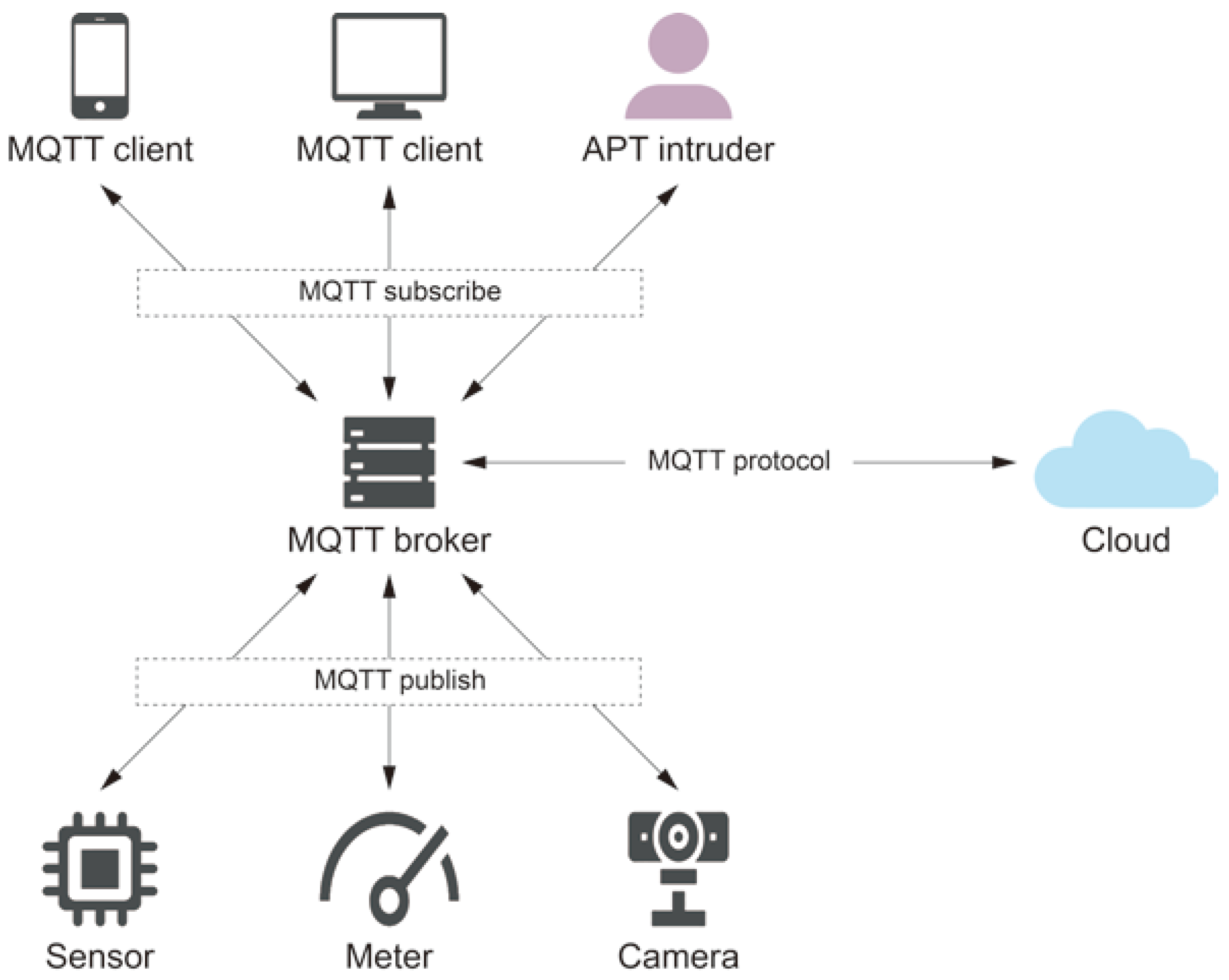
:1. Introduction
1.1. Research Contribution and Scope
1.2. Research Structure
2. Literature Review
2.1. ML-Based IDS Studies
2.2. ML-Based IDS Using GAN Methods
2.3. Literature Review Summary
3. Generating a Lightweight IoT Dataset
3.1. Dataset Generation
3.2. Machine Learning Classification
4. Results and Discussion
4.1. Data Generation Performance Testing
| Algorithm 1. The proposed dataset generation and validation methodology. DR is the real data, and DG is the generated data. |
|
4.2. Machine Learning Efficiency Metrics
5. Conclusions and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jeong, J.; Lim, J.Y.; Son, Y. A data type inference method based on long short-term memory by improved feature for weakness analysis in binary code. Future Gener. Comput. Syst. 2019, 100, 1044–1052. [Google Scholar] [CrossRef]
- Son, Y.; Jeong, J.; Lee, Y. An Adaptive Offloading Method for an IoT-Cloud Converged Virtual Machine System Using a Hybrid Deep Neural Network. Sustainability 2018, 10, 3955. [Google Scholar] [CrossRef]
- Jeong, J.; Joo, J.W.J.; Lee, Y.; Son, Y. Secure Cloud Storage Service Using Bloom Filters for the Internet of Things. Access 2019, 7, 60897–60907. [Google Scholar] [CrossRef]
- Chen, W.; Helu, X.; Jin, C.; Zhang, M.; Lu, H.; Sun, Y.; Tian, Z. Advanced persistent threat organization identification based on software gene of malware. Eur. Trans. Telecommun. 2020, 31, e3884. [Google Scholar] [CrossRef]
- Cheng, X.; Luo, Q.; Pan, Y.; Li, Z.; Zhang, J.; Chen, B. Predicting the APT for Cyber Situation Comprehension in 5G-Enabled IoT Scenarios Based on Differentially Private Federated Learning. Secur. Commun. Netw. 2021, 2021, 8814068. [Google Scholar] [CrossRef]
- Tankard, C. Advanced Persistent threats and how to monitor and deter them. Netw. Secur. 2011, 2011, 16–19. [Google Scholar] [CrossRef]
- Malhotra, H.; Sharma, P. Intrusion Detection using Machine Learning and Feature Selection. Int. J. Comput. Netw. Inf. Secur. 2019, 11, 43–52. [Google Scholar] [CrossRef]
- Binbusayyis, A.; Vaiyapuri, T. Comprehensive analysis and recommendation of feature evaluation measures for intrusion detection. Heliyon 2020, 6, e04262. [Google Scholar] [CrossRef]
- Onik, A.; Haq, N.; Alam, L.; Mamun, T. An Analytical Comparison on Filter Feature Extraction Method in Data Mining using J48 Classifier. Int. J. Comput. Appl. 2015, 124, 1–8. [Google Scholar] [CrossRef]
- Hindy, H.; Bayne, E.; Bures, M.; Atkinson, R.; Tachtatzis, C.; Bellekens, X. Machine Learning Based IoT Intrusion Detection System: An MQTT Case Study (MQTT-IoT-IDS2020 Dataset). In Selected Papers from the 12th International Networking Conference; Springer International Publishing: Cham, Switzerland, 2021; pp. 73–84. [Google Scholar]
- Hussain, F.; Abbas, S.G.; Fayyaz, U.U.; Shah, G.A.; Toqeer, A.; Ali, A. Towards a Universal Features Set for IoT Botnet Attacks Detection. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020; pp. 1–6. [Google Scholar]
- Chen, Z.; Liu, J.; Shen, Y.; Simsek, M.; Kantarci, B.; Mouftah, H.T.; Djukic, P. Machine Learning-Enabled IoT Security: Open Issues and Challenges Under Advanced Persistent Threats. ACM Comput. Surv. 2022, 55, 37. [Google Scholar] [CrossRef]
- Bourou, S.; El Saer, A.; Velivassaki, T.; Voulkidis, A.; Zahariadis, T. A Review of Tabular Data Synthesis Using GANs on an IDS Dataset. Inf. (Basel) 2021, 12, 375. [Google Scholar] [CrossRef]
- Appenzeller, A.; Leitner, M.; Philipp, P.; Krempel, E.; Beyerer, J. Privacy and Utility of Private Synthetic Data for Medical Data Analyses. Appl. Sci. 2022, 12, 12320. [Google Scholar] [CrossRef]
- Soe, Y.N.; Feng, Y.; Santosa, P.I.; Hartanto, R.; Sakurai, K. Towards a Lightweight Detection System for Cyber Attacks in the IoT Environment Using Corresponding Features. Electronics 2020, 9, 144. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, G.; Jiang, S.; Dai, M. Building an efficient intrusion detection system based on feature selection and ensemble classifier. Comput. Netw. 2020, 174, 107247. [Google Scholar] [CrossRef]
- Rahman, M.A.; Asyhari, A.T.; Leong, L.S.; Satrya, G.B.; Hai Tao, M.; Zolkipli, M.F. Scalable machine learning-based intrusion detection system for IoT-enabled smart cities. Sustain. Cities Soc. 2020, 61, 102324. [Google Scholar] [CrossRef]
- Somwang, P.; Lilakiatsakun, W. Intrusion detection technique by using fuzzy ART on computer network security. In Proceedings of the 2012 7th IEEE Conference on Industrial Electronics and Applications (ICIEA), Singapore, 18–20 July 2012; pp. 697–702. [Google Scholar]
- Sivatha Sindhu, S.S.; Geetha, S.; Kannan, A. Decision tree based light weight intrusion detection using a wrapper approach. Expert Syst. Appl. 2012, 39, 129–141. [Google Scholar] [CrossRef]
- Setiawan, B.; Djanali, S.; Ahmad, T. Increasing accuracy and completeness of intrusion detection model using fusion of normalization, feature selection method and support vector machine. Int. J. Intell. Eng. Syst. 2019, 12, 378–389. [Google Scholar] [CrossRef]
- Rashid, M.M.; Kamruzzaman, J.; Hassan, M.M.; Imam, T.; Gordon, S. Cyberattacks Detection in IoT-Based Smart City Applications Using Machine Learning Techniques. Int. J. Environ. Res. Public Health 2020, 17, 9347. [Google Scholar] [CrossRef]
- Hassannataj Joloudari, J.; Haderbadi, M.; Mashmool, A.; Ghasemigol, M.; Band, S.S.; Mosavi, A. Early Detection of the Advanced Persistent Threat Attack Using Performance Analysis of Deep Learning. Access 2020, 8, 186125–186137. [Google Scholar] [CrossRef]
- Shang, L.; Guo, D.; Ji, Y.; Li, Q. Discovering unknown advanced persistent threat using shared features mined by neural networks. Comput. Netw. 2021, 189, 107937. [Google Scholar] [CrossRef]
- Chizoba, O.J.; Kyari, B.A. Ensemble classifiers for detection of advanced persistent threats. Glob. J. Eng. Technol. Adv. 2020, 2, 1. [Google Scholar] [CrossRef]
- Stojanović, B.; Hofer-Schmitz, K.; Kleb, U. APT datasets and attack modeling for automated detection methods: A review. Comput Secur 2020, 92, 101734. [Google Scholar] [CrossRef]
- Myneni, S.; Chowdhary, A.; Sabur, A.; Sengupta, S.; Agrawal, G.; Huang, D.; Kang, M. DAPT 2020-Constructing a Benchmark Dataset for Advanced Persistent Threats. In Deployable Machine Learning for Security Defense: First International Workshop, MLHat 2020, San Diego, CA, USA, August 24, 2020, Proceedings 1; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 138–163. [Google Scholar]
- Safa, M.; Pandian, A.; Gururaj, H.L.; Ravi, V.; Krichen, M. Real time health care big data analytics model for improved QoS in cardiac disease prediction with IoT devices. Health Technol 2023, 13, 473–483. [Google Scholar] [CrossRef]
- Shahriar, M.H.; Haque, N.I.; Rahman, M.A.; Alonso, M. G-IDS: Generative Adversarial Networks Assisted Intrusion Detection System. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 376–385. [Google Scholar]
- Liu, X.; Li, T.; Zhang, R.; Wu, D.; Liu, Y.; Yang, Z. A GAN and Feature Selection-Based Oversampling Technique for Intrusion Detection. Secur. Commun. Netw. 2021, 2021, 9947059. [Google Scholar] [CrossRef]
- Lin, Z.; Shi, Y.; Xue, Z. IDSGAN: Generative Adversarial Networks for Attack Generation Against Intrusion Detection. In Advances in Knowledge Discovery and Data Mining; Springer International Publishing: Cham, Switzerland, 2022; pp. 79–91. [Google Scholar]
- Kumar, V.; Sinha, D. Synthetic attack data generation model applying generative adversarial network for intrusion detection. Comput. Secur. 2023, 125, 103054. [Google Scholar] [CrossRef]
- Strickland, C.; Saha, C.; Zakar, M.; Nejad, S.; Tasnim, N.; Lizotte, D.; Haque, A. DRL-GAN: A Hybrid Approach for Binary and Multiclass Network Intrusion Detection. arXiv 2023, arXiv:2301.03368. [Google Scholar] [CrossRef]
- Vaccari, I.; Chiola, G.; Aiello, M.; Mongelli, M.; Cambiaso, E. MQTTset, a New Dataset for Machine Learning Techniques on MQTT. Sensors 2020, 20, 6578. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular data using Conditional GAN. Adv. Neural Inf. Process. Syst. 2019, 32, 1–15. [Google Scholar]
- Scikit-Learn: Machine Learning in Python—Scikit-Learn 1.1.1 Documentation. Available online: https://scikit-learn.org/stable/ (accessed on 6 March 2022).
- CTGAN Model—SDV 0.13.1 Documentation. Available online: https://sdv.dev/SDV/user_guides/single_table/ctgan.html (accessed on 6 March 2022).
- Single Table Metrics—SDV 0.13.1 Documentation. Available online: https://sdv.dev/SDV/user_guides/evaluation/single_table_metrics.html (accessed on 6 March 2022).
- Alsaedi, A.; Moustafa, N.; Tari, Z.; Mahmood, A.; Anwar, A. TON_IoT Telemetry Dataset: A New Generation Dataset of IoT and IIoT for Data-Driven Intrusion Detection Systems. IEEE Access 2020, 8, 165130–165150. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Future Gener. Comput Syst 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Tshark(1) Manual Page. Available online: https://www.wireshark.org/docs/man-pages/tshark.html (accessed on 6 March 2022).
- Hong, D.; Baik, C. Generating and Validating Synthetic Training Data for Predicting Bankruptcy of Individual Businesses. J. Inf. Commun. Converg. Eng. 2021, 19, 228–233. [Google Scholar]
- Zingo, P.; Novocin, A. Can GAN-Generated Network Traffic be used to Train Traffic Anomaly Classifiers? In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; p. 540. [Google Scholar]
- Alabdulwahab, S.; Moon, B. Feature Selection Methods Simultaneously Improve the Detection Accuracy and Model Building Time of Machine Learning Classifiers. Symmetry 2020, 12, 1424. [Google Scholar] [CrossRef]
- Hall, M.A.; Holmes, G. Benchmarking attribute selection techniques for discrete class data mining. TKDE 2003, 15, 1437–1447. [Google Scholar] [CrossRef]
- Alabrah, A. A Novel Study: GAN-Based Minority Class Balancing and Machine-Learning-Based Network Intruder Detection Using Chi-Square Feature Selection. Appl. Sci. 2022, 12, 11662. [Google Scholar] [CrossRef]
- Arvanitis, T.N.; White, S.; Harrison, S.; Chaplin, R.; Despotou, G. A method for machine learning generation of realistic synthetic datasets for validating healthcare applications. Health Inform. J. 2022, 28, 14604582221077000. [Google Scholar] [CrossRef] [PubMed]
- Brenninkmeijer, B.; de Vries, A.; Marchiori, E.; Hille, Y. On the Generation and Evaluation of Tabular Data Using GANs; Radboud University: Nijmegen, The Netherlands, 2019. [Google Scholar]
- Neves, D.T.; Alves, J.; Naik, M.G.; Proença, A.J.; Prasser, F. From Missing Data Imputation to Data Generation. J. Comput. Sci. 2022, 61, 101640. [Google Scholar] [CrossRef]
- Ashraf, H.; Jeong, Y.; Lee, C.H. Underwater Ambient-Noise Removing GAN Based on Magnitude and Phase Spectra. IEEE Access 2021, 9, 24513–24530. [Google Scholar] [CrossRef]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs. arXiv 2017, arXiv:1706.02633. [Google Scholar] [CrossRef]
- Sasirekha, G.V.K.; Bangari, A.; Rao, M.; Bapat, J.; Das, D. Das Synthesis of IoT Sensor Telemetry Data for Smart Home Edge-IDS Evaluation. In Proceedings of the 2023 International Conference on Computer Science, Information Technology and Engineering (ICCoSITE), Jakarta, Indonesia, 16 February 2023; pp. 562–567. [Google Scholar]
- Dina, A.S.; Siddique, A.B.; Manivannan, D. Effect of Balancing Data Using Synthetic Data on the Performance of Machine Learning Classifiers for Intrusion Detection in Computer Networks. IEEE Access 2022, 10, 96731–96747. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Applied ML Algorithms | Datasets | Accuracy | Training/ Testing Time (Seconds) | ||
|---|---|---|---|---|---|---|
| Preprocessing | Feature Selection | Classification | ||||
| Rahman et al. [17] | Normalization, balancing, and numerical transforming | IG | Multi-layer perceptron (MLP) | AWID | 0.97 | 73.52/n/a |
| Zhou et al. [16] | Normalization, balancing, and filtration | CFS-BA-ensemble | Forest PA-ensemble | NSL-KDD | 0.99 | 36.28/n/a |
| AWID | 0.99 | 92.62/n/a | ||||
| CIC-IDS2017 | 0.99 | 98.42/n/a | ||||
| Soe et al. [15] | n/a | CST-GR | J48 | Bot-IoT | 0.99 (TPR) | 8.61/0.81 |
| Setiawan et al. [20] | Nominal to numerical, log normalization | Modified rank-based IG | SVM | NSL-KDD | 0.99 | 56.603/2.094 |
| Rashid et al. [21] | Cleaning, visualization, feature engineering, and vectorization | IG | Stacking ensemble | UNSW-NB15 | 0.96 | 25.6/5.70 |
| CIC-IDS2017 | 0.99 | 27.09/4.19 | ||||
| CTGAN Parameters | Values |
|---|---|
| Epochs | 50 to 100 |
| Generator learning rate | 0.0002 |
| Discriminator learning rate | 0.0002 |
| Generator dimension | (256, 256) |
| Discriminator dimension | (256, 256) |
| # | Feature | Data Type |
|---|---|---|
| 1 | Protocol | Text |
| 2 | ip.id | Unsigned integer |
| 3 | ip.flags | Unsigned integer |
| 4 | ip.flags.df | Binary |
| 5 | ttl | Unsigned integer |
| 6 | ip.proto | Unsigned integer |
| 7 | ip.checksum | Unsigned integer |
| 8 | ip.len | Unsigned integer |
| 9 | tcp.srcport | Unsigned integer |
| 10 | tcp.dstport | Unsigned integer |
| 11 | tcp.seq | Unsigned integer |
| 12 | tcp.ack | Unsigned integer |
| 13 | tcp.stream | Unsigned integer |
| 14 | tcp.len | Unsigned integer |
| 15 | tcp.hdr_len | Unsigned integer |
| 16 | tcp.analysis.ack_rtt | Time offset |
| 17 | tcp.flags.fin | Boolean |
| 18 | tcp.flags.syn | Boolean |
| 19 | tcp.flags.push | Boolean |
| 20 | tcp.flags.ack | Boolean |
| 21 | tcp.window_size | Unsigned integer |
| 22 | tcp.checksum | Unsigned integer |
| 23 | frame.time_relative | Time offset |
| 24 | frame.time_delta | Time offset |
| 25 | tcp.time_relative | Time offset |
| 26 | tcp.time_delta | Time offset |
| 27 | label | Text |
| 28 | Category | Text |
| Category | Count | Percentage (%) |
|---|---|---|
| DDOS | 17,923 | 5.35 |
| DOS | 17,204 | 5.13 |
| injection | 17,708 | 5.28 |
| keylogging | 135 | 0.04 |
| password | 17,587 | 5.25 |
| mqtt_bruteforce | 16,820 | 5.02 |
| scan_A | 16,009 | 4.78 |
| ransomware | 15,734 | 4.69 |
| backdoor | 16,464 | 4.91 |
| XSS | 15,766 | 4.70 |
| Sparta | 17,148 | 5.12 |
| theft | 423 | 0.13 |
| normal | 166,249 | 49.60 |
| Total | 335,170 | 100.00 |
| Category | Count | Percentage (%) |
|---|---|---|
| DDOS | 13,282 | 3.96 |
| DOS | 12,047 | 3.59 |
| injection | 13,933 | 4.16 |
| keylogging | 12,026 | 3.59 |
| password | 12,852 | 3.83 |
| mqtt_bruteforce | 21,686 | 6.47 |
| scan_A | 14,203 | 4.24 |
| ransomware | 21,358 | 6.37 |
| backdoor | 14,849 | 4.43 |
| XSS | 11,986 | 3.58 |
| Sparta | 12,612 | 3.76 |
| theft | 8087 | 2.41 |
| normal | 166,249 | 49.60 |
| Total | 335,170 | 100.00 |
| Epochs | 50 | 60 | 70 | 80 | 90 | 100 |
|---|---|---|---|---|---|---|
| KS test | 0.80 | 0.82 | 0.83 | 0.82 | 0.82 | 0.82 |
| RMSE | 0.13 | 0.12 | 0.11 | 0.11 | 0.12 | 0.12 |
| MAE | 0.09 | 0.08 | 0.08 | 0.08 | 0.08 | 0.08 |
| Classifier | 50 Epochs | 60 Epochs | 70 Epochs | 80 Epochs | 90 Epochs | 100 Epochs | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | |
| Decision Tree | 0.39 | 0.39 | 0.54 | 0.54 | 0.88 | 0.88 | 0.74 | 0.74 | 0.60 | 0.60 | 0.43 | 0.43 |
| Naïve Bayes | 0.75 | 0.75 | 0.75 | 0.75 | 0.72 | 0.72 | 0.77 | 0.77 | 0.77 | 0.77 | 0.75 | 0.75 |
| RF | 0.93 | 0.93 | 0.97 | 0.97 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.96 | 0.96 |
| MLP | 0.80 | 0.80 | 0.76 | 0.76 | 0.81 | 0.81 | 0.81 | 0.81 | 0.80 | 0.80 | 0.86 | 0.86 |
| Gradient Boost | 0.41 | 0.41 | 0.54 | 0.54 | 0.87 | 0.87 | 0.74 | 0.74 | 0.60 | 0.60 | 0.43 | 0.43 |
| XGBoost | 0.79 | 0.79 | 0.73 | 0.73 | 0.88 | 0.88 | 0.92 | 0.92 | 0.82 | 0.82 | 0.69 | 0.69 |
| LightGBM | 0.42 | 0.42 | 0.55 | 0.55 | 0.88 | 0.88 | 0.74 | 0.74 | 0.60 | 0.60 | 0.44 | 0.44 |
| Average | 0.64 | 0.64 | 0.69 | 0.69 | 0.85 | 0.85 | 0.81 | 0.81 | 0.74 | 0.74 | 0.65 | 0.65 |
| Collected Original Dataset | Generated Dataset Before Feature Selection | Generated Dataset with 5 Best Feature Selection | Generated Dataset with 10 Best Feature Selection | Generated Dataset with 15 Best Feature Selection | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | Accuracy | F1 |
| RF | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 1 | 1 | 1 | 1 |
| Naïve Bayes | 0.73 | 0.72 | 0.76 | 0.75 | 0.96 | 0.96 | 0.97 | 0.97 | 0.97 | 0.97 |
| Decision Tree | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| MLP | 0.99 | 0.99 | 0.98 | 0.98 | 0.99 | 0.99 | 0.81 | 0.84 | 0.81 | 0.84 |
| Gradient Boost | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| XGBoost | 0.99 | 0.99 | 1 | 1 | 0.99 | 0.99 | 1 | 1 | 1 | 1 |
| LightGBM | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 1 | 1 | 1 | 1 |
| Collected Original Dataset | Generated Dataset Before Feature Selection | Generated Dataset with 5 Best Feature Selection | Generated Dataset with 10 Best Feature Selection | Generated Dataset with 15 Best Feature Selection | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | Train Time | Test Time | Train Time | Test Time | Train Time | Test Time | Train Time | Test Time | Train Time | Test Time |
| RF | 4.31 | 0.1 | 4.39 | 0.09 | 4.15 | 0.47 | 11.09 | 0.57 | 14.94 | 0.61 |
| Naïve Bayes | 0.31 | 0.06 | 0.13 | 0.04 | 0.04 | 0.006 | 0.08 | 0.01 | 0.1 | 0.02 |
| Decision Tree | 1.48 | 0.02 | 2.14 | 0.02 | 0.05 | 0.004 | 0.51 | 0.007 | 0.91 | 0.008 |
| MLP | 94.14 | 0.09 | 51.91 | 0.09 | 24.70 | 0.07 | 31.95 | 0.08 | 26.0 | 0.09 |
| Gradient Boost | 12.78 | 0.04 | 8.56 | 0.04 | 1.44 | 0.04 | 5.19 | 0.04 | 8.41 | 0.04 |
| XGBoost | 24.54 | 0.07 | 23.27 | 0.06 | 5.35 | 0.06 | 9.52 | 0.08 | 12.14 | 0.08 |
| LightGBM | 4.61 | 0.38 | 3.85 | 0.26 | 1.72 | 0.34 | 2.13 | 0.28 | 2.55 | 0.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alabdulwahab, S.; Kim, Y.-T.; Seo, A.; Son, Y. Generating Synthetic Dataset for ML-Based IDS Using CTGAN and Feature Selection to Protect Smart IoT Environments. Appl. Sci. 2023, 13, 10951. https://doi.org/10.3390/app131910951
Alabdulwahab S, Kim Y-T, Seo A, Son Y. Generating Synthetic Dataset for ML-Based IDS Using CTGAN and Feature Selection to Protect Smart IoT Environments. Applied Sciences. 2023; 13(19):10951. https://doi.org/10.3390/app131910951
Chicago/Turabian StyleAlabdulwahab, Saleh, Young-Tak Kim, Aria Seo, and Yunsik Son. 2023. "Generating Synthetic Dataset for ML-Based IDS Using CTGAN and Feature Selection to Protect Smart IoT Environments" Applied Sciences 13, no. 19: 10951. https://doi.org/10.3390/app131910951
APA StyleAlabdulwahab, S., Kim, Y.-T., Seo, A., & Son, Y. (2023). Generating Synthetic Dataset for ML-Based IDS Using CTGAN and Feature Selection to Protect Smart IoT Environments. Applied Sciences, 13(19), 10951. https://doi.org/10.3390/app131910951