


Gait Recognition Based on Gait Optical Flow Network with Inherent Feature Pyramid


Abstract
:1. Introduction
2. Related Work
2.1. Gait Representation
2.2. Unordered Set
2.3. Instantaneous Motion Description
3. Proposed Approach
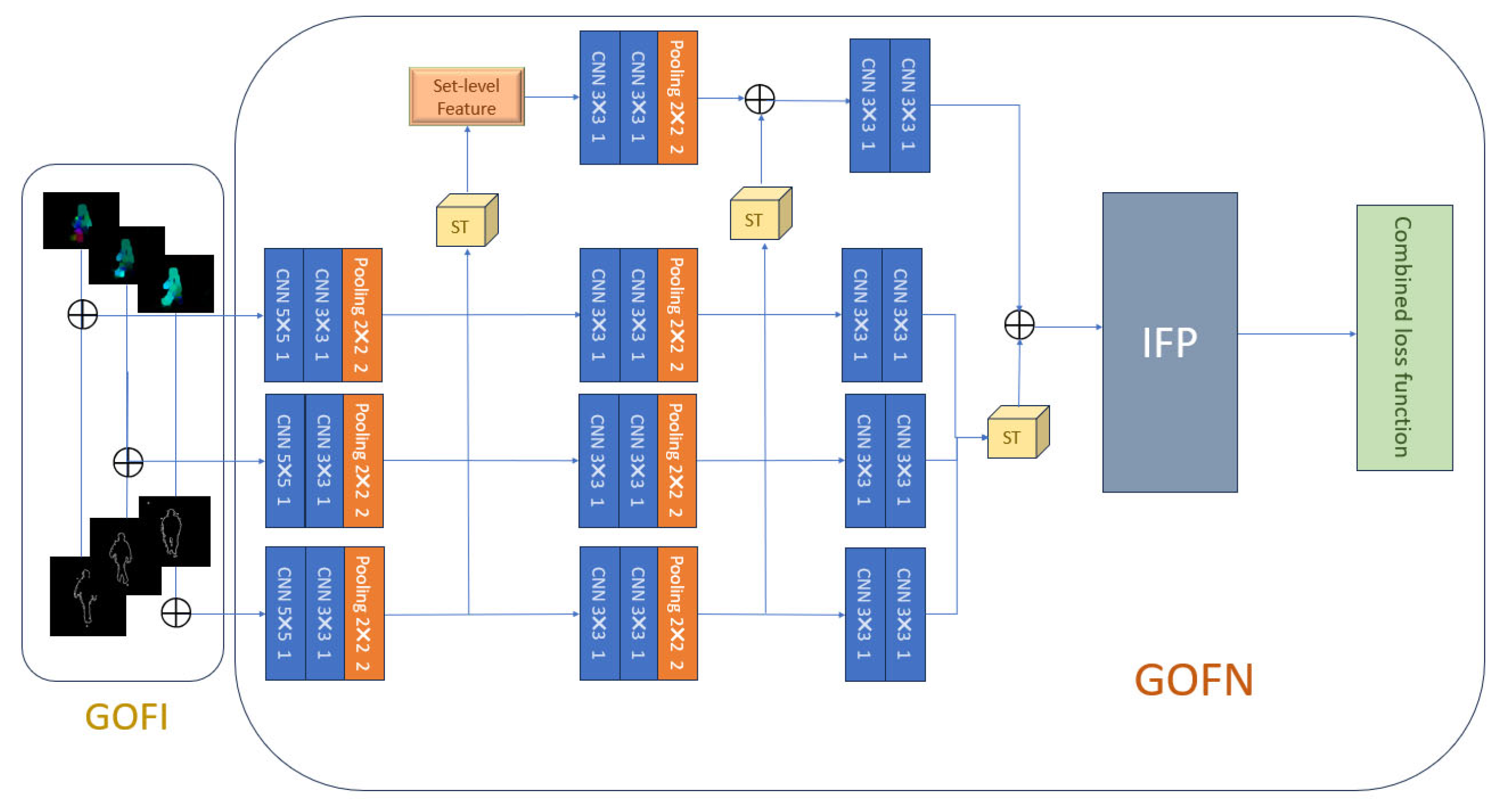
3.1. Gait Optical Flow Image Extraction
3.2. Set-Level Feature from Unordered Set
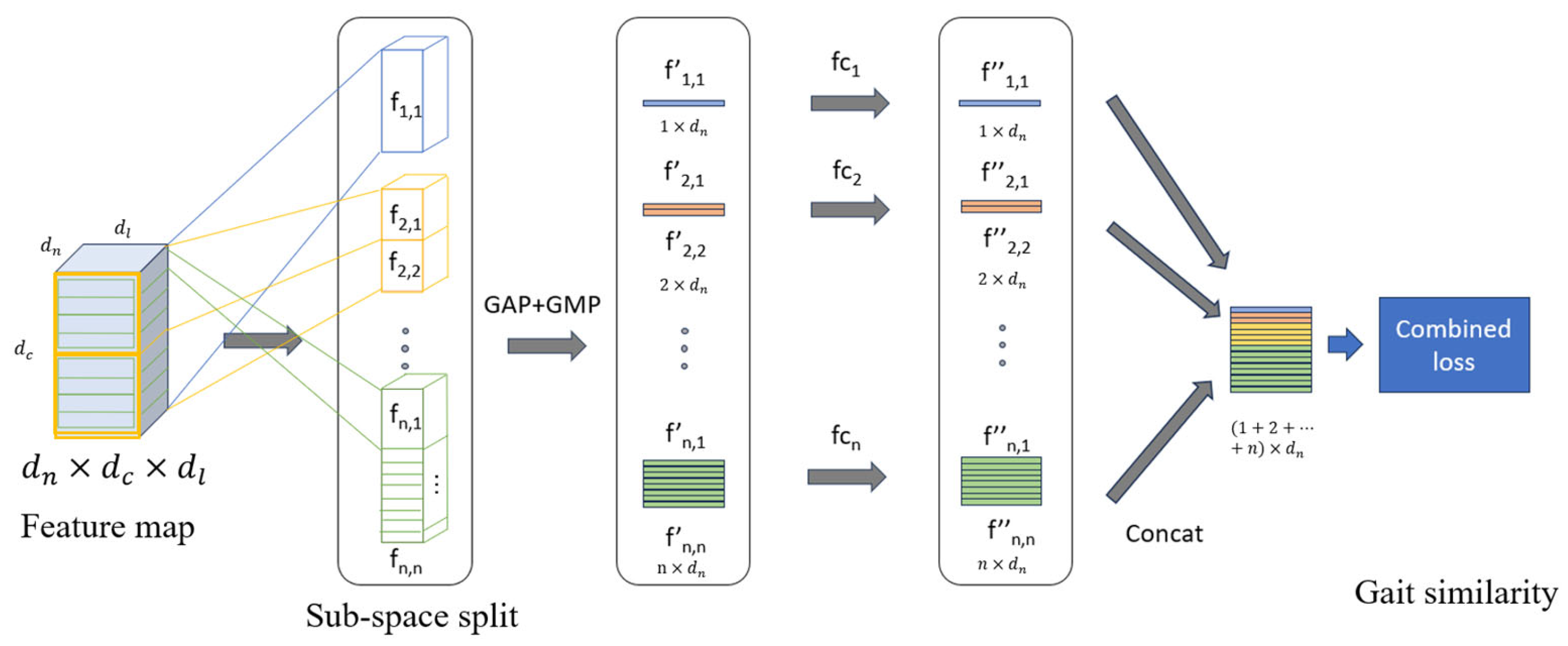
3.3. Inherent Feature Pyramid
3.4. Framework of GOFN
4. Experiments
4.1. Datasets
4.2. Comparisons with Other Methods
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, T.K.; Belkhatir, M.; Sanei, S. A Comprehensive Review of Past and Present Vision-Based Techniques for Gait Recognition. Multimed. Tools Appl. 2014, 72, 2833–2869. [Google Scholar] [CrossRef]
- Han, J.; Bhanu, B. Individual Recognition Using Gait Energy Image. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zheng, N. Gait History Image: A Novel Temporal Template for Gait Recognition. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 663–666. [Google Scholar]
- Chen, C.; Liang, J.; Zhao, H.; Hu, H.; Tian, J. Frame Difference Energy Image for Gait Recognition with Incomplete Silhouettes. Pattern Recognit. Lett. 2009, 30, 977–984. [Google Scholar] [CrossRef]
- Zhang, E.; Zhao, Y.; Xiong, W. Active Energy Image plus 2DLPP for Gait Recognition. Signal Process. 2010, 90, 2295–2302. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Wolf, T.; Babaee, M.; Rigoll, G. Multi-View Gait Recognition Using 3D Convolutional Neural Networks. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4165–4169. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Chao, H.; He, Y.; Zhang, J.; Feng, J. GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8126–8133. [Google Scholar]
- Bashir, K.; Xiang, T.; Gong, S. Gait Recognition Using Gait Entropy Image. In Proceedings of the 3rd International Conference on Imaging for Crime Detection and Prevention (ICDP 2009), London, UK, 3 December 2009; p. P2. [Google Scholar]
- Kusakunniran, W.; Wu, Q.; Zhang, J.; Ma, Y.; Li, H. A New View-Invariant Feature for Cross-View Gait Recognition. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1642–1653. [Google Scholar] [CrossRef]
- Makihara, Y.; Sagawa, R.; Mukaigawa, Y.; Echigo, T.; Yagi, Y. Gait Recognition Using a View Transformation Model in the Frequency Domain. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Volume 3953, pp. 151–163. [Google Scholar]
- Wang, C.; Zhang, J.; Wang, L.; Pu, J.; Yuan, X. Human Identification Using Temporal Information Preserving Gait Template. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2164–2176. [Google Scholar] [CrossRef] [PubMed]
- Fan, C.; Peng, Y.; Cao, C.; Liu, X.; Hou, S.; Chi, J.; Huang, Y.; Li, Q.; He, Z. GaitPart: Temporal Part-based Model for Gait Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14213–14221. [Google Scholar]
- Lin, B.; Zhang, S.; Yu, X. Gait recognition via effective global-local feature representation and local temporal aggregation. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 14648–14656. [Google Scholar]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Ren, M. Gait Recognition via Semi-supervised Disentangled Representation Learning to Identity and Covariate Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13306–13316. [Google Scholar]
- Fan, C.; Liang, J.; Shen, C.; Hou, S.; Huang, Y.; Yu, S. OpenGait: Revisiting Gait Recognition Toward Better Practicality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Ariyanto, G.; Nixon, M.S. Model-Based 3D Gait Biometrics. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–7. [Google Scholar]
- Bodor, R.; Drenner, A.; Fehr, D.; Masoud, O.; Papanikolopoulos, N. View-Independent Human Motion Classification Using Image-Based Reconstruction. Image Vis. Comput. 2009, 27, 1194–1206. [Google Scholar] [CrossRef]
- Kusakunniran, W.; Wu, Q.; Li, H.; Zhang, J. Multiple Views Gait Recognition Using View Transformation Model Based on Optimized Gait Energy Image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1058–1064. [Google Scholar]
- Teepe, T.; Khan, A.; Gilg, J.; Herzog, F.; Hörmann, S.; Rigoll, G. Gaitgraph: Graph Convolutional Network for Skeleton-Based Gait Recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2314–2318. [Google Scholar]
- Hou, S.; Cao, C.; Liu, X.; Huang, Y. Gait Lateral Network: Learning Discriminative and Compact Representations for Gait Recognition. In Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Lecture Notes in Computer Science. Volume 12354, pp. 382–398. [Google Scholar]
- Sepas-Moghaddam, A.; Etemad, A. View-Invariant Gait Recognition With Attentive Recurrent Learning of Partial Representations. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 124–137. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the IJCAI’81: 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Farnebäck, G. Two-Frame Motion Estimation Based on Polynomial Expansion. In Image Analysis: Proceedings of the 13th Scandinavian Conference, SCIA 2003, Halmstad, Sweden, 29 June–2 July 2003; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2749, pp. 363–370. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Luo, Z.; Yang, T.; Liu, Y. Gait Optical Flow Image Decomposition for Human Recognition. In Proceedings of the 2016 IEEE Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 20–22 May 2016; pp. 581–586. [Google Scholar]
- Yu, S.; Tan, D.; Tan, T. A Framework for Evaluating the Effect of View Angle, Clothing and Carrying Condition on Gait Recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 441–444. [Google Scholar]
- Tan, D.; Huang, K.; Yu, S.; Tan, T. Efficient Night Gait Recognition Based on Template Matching. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 1000–1003. [Google Scholar]
- Yu, S.; Chen, H.; Wang, Q.; Shen, L.; Huang, Y. Invariant Feature Extraction for Gait Recognition Using Only One Uniform Model. Neurocomputing 2017, 239, 81–93. [Google Scholar] [CrossRef]
- He, Y.; Zhang, J.; Shan, H.; Wang, L. Multi-Task GANs for View-Specific Feature Learning in Gait Recognition. IEEE Trans. Inf. Forensics Secur. 2019, 14, 102–113. [Google Scholar] [CrossRef]
- Gao, S.; Yun, J.; Zhao, Y.; Liu, L. Gait-D: Skeleton-Based Gait Feature Decomposition for Gait Recognition. IET Comput. Vis. 2022, 16, 111–125. [Google Scholar] [CrossRef]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A Model-Based Gait Recognition Method with Body Pose and Human Prior Knowledge. Pattern Recognit. 2020, 98, 107069. [Google Scholar] [CrossRef]
- Xu, K.; Jiang, X.; Sun, T. Gait Recognition Based on Local Graphical Skeleton Descriptor With Pairwise Similarity Network. IEEE Trans. Multimed. 2022, 24, 3265–3275. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | NM#5-6 | BG#1-2 | CL#1-2 | Average |
|---|---|---|---|---|
| SPAE [31] | 59.3 | 37.2 | 24.2 | 40.2 |
| MGAN [32] | 68.1 | 54.7 | 31.5 | 51.4 |
| Gaitset [9] | 92.0 | 84.3 | 62.5 | 79.6 |
| Gait-D [33] | 91.6 | 79.0 | 72.0 | 80.9 |
| GaitPart [14] | 96.2 | 92.4 | 78.7 | 89.1 |
| GaitGL [15] | 95.9 | 92.1 | 78.2 | 88.7 |
| GaitNet [16] | 91.5 | 85.7 | 58.9 | 78.7 |
| GaitGraph [21] | 87.7 | 74.8 | 66.3 | 76.3 |
| GOFN | 96.4 | 85.5 | 66.1 | 82.7 |
| Probe | Model | 0 | 18 | 36 | 54 | 72 | 90 | 108 | 126 | 144 | 162 | 180 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NM#5-6 | SPAE [31] | 98.4 | 99.2 | 97.6 | 96.0 | 96.0 | 96.0 | 96.8 | 98.4 | 97.6 | 96.8 | 100.0 | 97.5 |
| PoseGait [34] | 96.0 | 96.8 | 96.0 | 96.8 | 96.0 | 97.6 | 97.6 | 94.4 | 96.8 | 97.6 | 97.6 | 96.6 | |
| LGSD + PSN [35] | 99.2 | 99.2 | 98.4 | 99.2 | 97.6 | 98.4 | 97.6 | 96.8 | 97.6 | 97.6 | 99.2 | 98.1 | |
| GOFN | 98.4 | 99.2 | 99.2 | 97.6 | 97.6 | 96.8 | 96.8 | 99.2 | 99.2 | 98.4 | 97.6 | 98.2 | |
| BG#1-2 | SPAE [31] | 79.8 | 81.5 | 70.2 | 66.9 | 74.2 | 65.3 | 62.1 | 75.8 | 72.6 | 68.6 | 74.2 | 71.9 |
| PoseGait [34] | 74.2 | 75.8 | 77.4 | 76.6 | 69.4 | 70.2 | 71.0 | 69.4 | 74.2 | 65.3 | 60.5 | 71.3 | |
| LGSD + PSN [35] | 86.3 | 84.7 | 83.1 | 88.7 | 90.3 | 86.3 | 90.3 | 83.9 | 84.7 | 76.6 | 80.7 | 85.0 | |
| GOFN | 84.7 | 88.7 | 92.7 | 91.1 | 85.5 | 80.7 | 87.1 | 88.7 | 91.9 | 91.1 | 79.9 | 87.5 | |
| CL#1-2 | SPAE [31] | 44.4 | 49.2 | 46.8 | 46.8 | 49.2 | 42.5 | 46.8 | 43.6 | 40.3 | 41.4 | 42.7 | 44.9 |
| PoseGait [34] | 46.8 | 48.4 | 57.3 | 61.3 | 58.1 | 56.5 | 59.7 | 54.8 | 55.7 | 58.1 | 39.5 | 54.2 | |
| LGSD + PSN [35] | 64.5 | 68.6 | 70.2 | 71.0 | 68.6 | 64.5 | 62.9 | 56.5 | 59.7 | 59.7 | 60.5 | 64.2 | |
| GOFN | 67.7 | 72.8 | 77.6 | 73.4 | 67.0 | 67.7 | 66.1 | 68.5 | 69.3 | 68.5 | 64.5 | 69.4 |
| Training Set | Model | FW | SW | BW | Average |
|---|---|---|---|---|---|
| 24 | LGSD + PSN [35] | 58.6 | 56.0 | 38.1 | 50.9 |
| GOFN | 64.2 | 54.3 | 39.5 | 52.7 | |
| 62 | LGSD + PSN [35] | 63.6 | 60.0 | 42.3 | 55.3 |
| GOFN | 69.3 | 58.2 | 43.5 | 57.0 | |
| 100 | LGSD + PSN [35] | 71.7 | 71.0 | 50.5 | 64.4 |
| GOFN | 76.1 | 70.5 | 51.2 | 67.9 |
| Representation | Permutation Invariant Function | IFP | Result | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GEI | GOFI | ST | Max | Mean | Median | Attention | NM | BG | CL | |
| √ | 76.4 | 64.1 | 31.8 | |||||||
| √ | √ | √ | 93.6 | 85.0 | 62.2 | |||||
| √ | √ | √ | 96.4 | 85.5 | 66.1 | |||||
| √ | √ | 94.1 | 82.3 | 64.7 | ||||||
| √ | √ | √ | 92.1 | 83.8 | 62.0 | |||||
| √ | √ | √ | 86.5 | 75.2 | 48.3 | |||||
| √ | √ | √ | 86.1 | 74.8 | 41.1 | |||||
| √ | √ | √ | 91.8 | 83.3 | 63.0 | |||||
| Loss Function | NM | BG | CL |
|---|---|---|---|
| Softmax | 31.9 | 27.9 | 11.8 |
| Triplet loss | 94.2 | 83.1 | 62.5 |
| Combined loss | 96.4 | 85.5 | 66.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, H.; Sun, T.; Xu, K. Gait Recognition Based on Gait Optical Flow Network with Inherent Feature Pyramid. Appl. Sci. 2023, 13, 10975. https://doi.org/10.3390/app131910975
Ye H, Sun T, Xu K. Gait Recognition Based on Gait Optical Flow Network with Inherent Feature Pyramid. Applied Sciences. 2023; 13(19):10975. https://doi.org/10.3390/app131910975
Chicago/Turabian StyleYe, Hongyi, Tanfeng Sun, and Ke Xu. 2023. "Gait Recognition Based on Gait Optical Flow Network with Inherent Feature Pyramid" Applied Sciences 13, no. 19: 10975. https://doi.org/10.3390/app131910975
APA StyleYe, H., Sun, T., & Xu, K. (2023). Gait Recognition Based on Gait Optical Flow Network with Inherent Feature Pyramid. Applied Sciences, 13(19), 10975. https://doi.org/10.3390/app131910975