
A Survey of Detection and Mitigation for Fake Images on Social Media Platforms

 , ,
, ,  ,
,  and
and 
Abstract
:1. Introduction
1.1. Motivation
1.2. Related Study
1.3. Contribution and Organization
- -
- Comprehensive Coverage: This paper thoroughly examines the fake image detection process, leaving no stone unturned. It explores image tampering techniques, including Generative Adversarial Networks (GANs). It covers various detection methods, encompassing handcrafted forensic features, semantic features, statistical features, web retrievals, neural networks, and multi-modal approaches;
- -
- Performance Comparison: It goes beyond describing these methods by summarizing and comparing their results within each detection category. This performance evaluation aids researchers in selecting the most suitable approach for their specific needs;
- -
- Deep Learning Emphasis: This paper underscores the superiority of deep learning methods for detecting fake images over social media platforms, backed by evidence and comparative analysis. This emphasis provides clear guidance to researchers and practitioners;
- -
- Challenges and Future Scope: It does not shy away from highlighting the current challenges and limitations in the field, shedding light on areas where further research is needed. This forward-looking perspective enhances its value for the research community;
- -
- Dataset and Evaluation Parameters: This paper also provides valuable information on fake image datasets and evaluation parameters, facilitating the replication of experiments and benchmarking new detection methods.
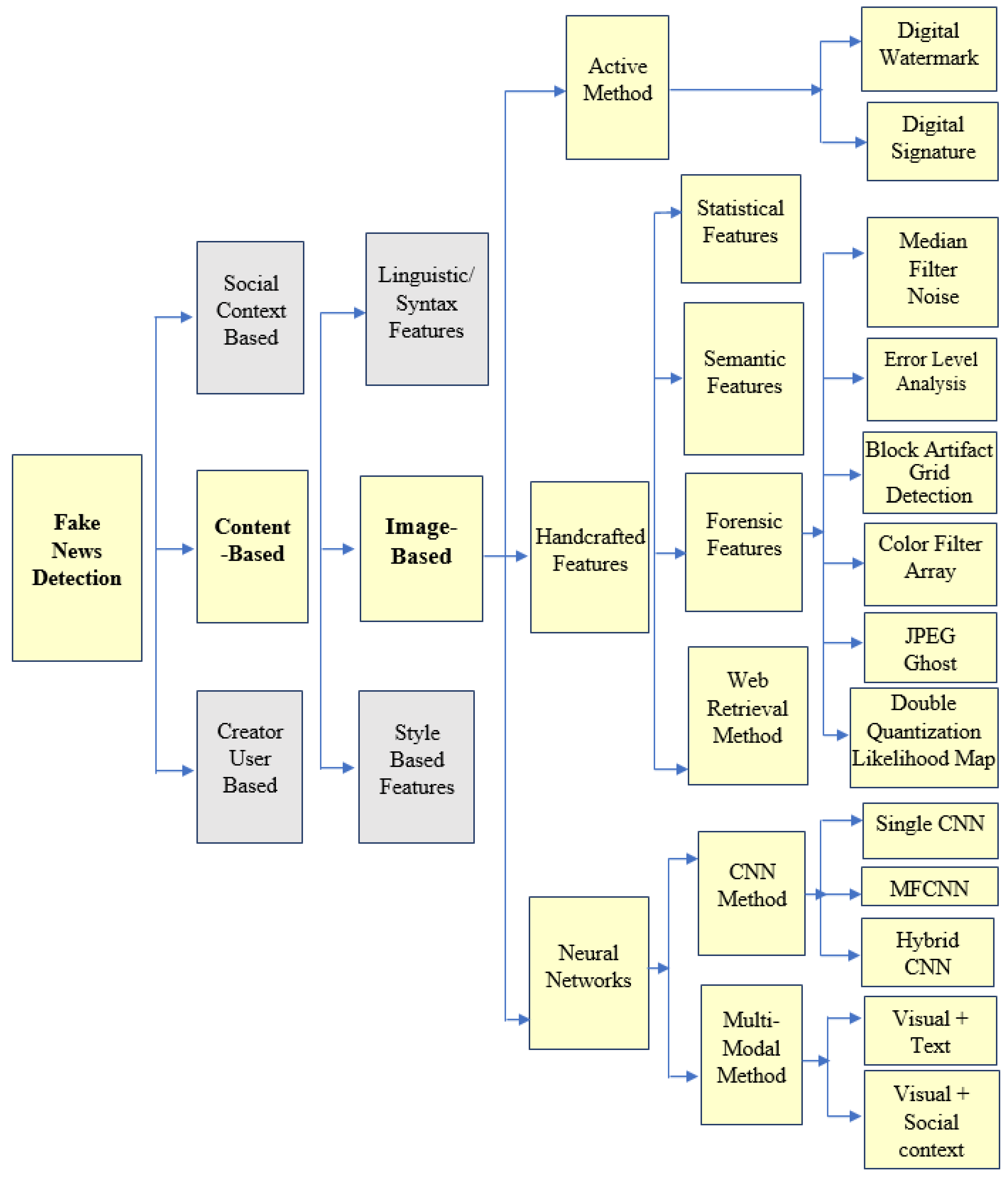
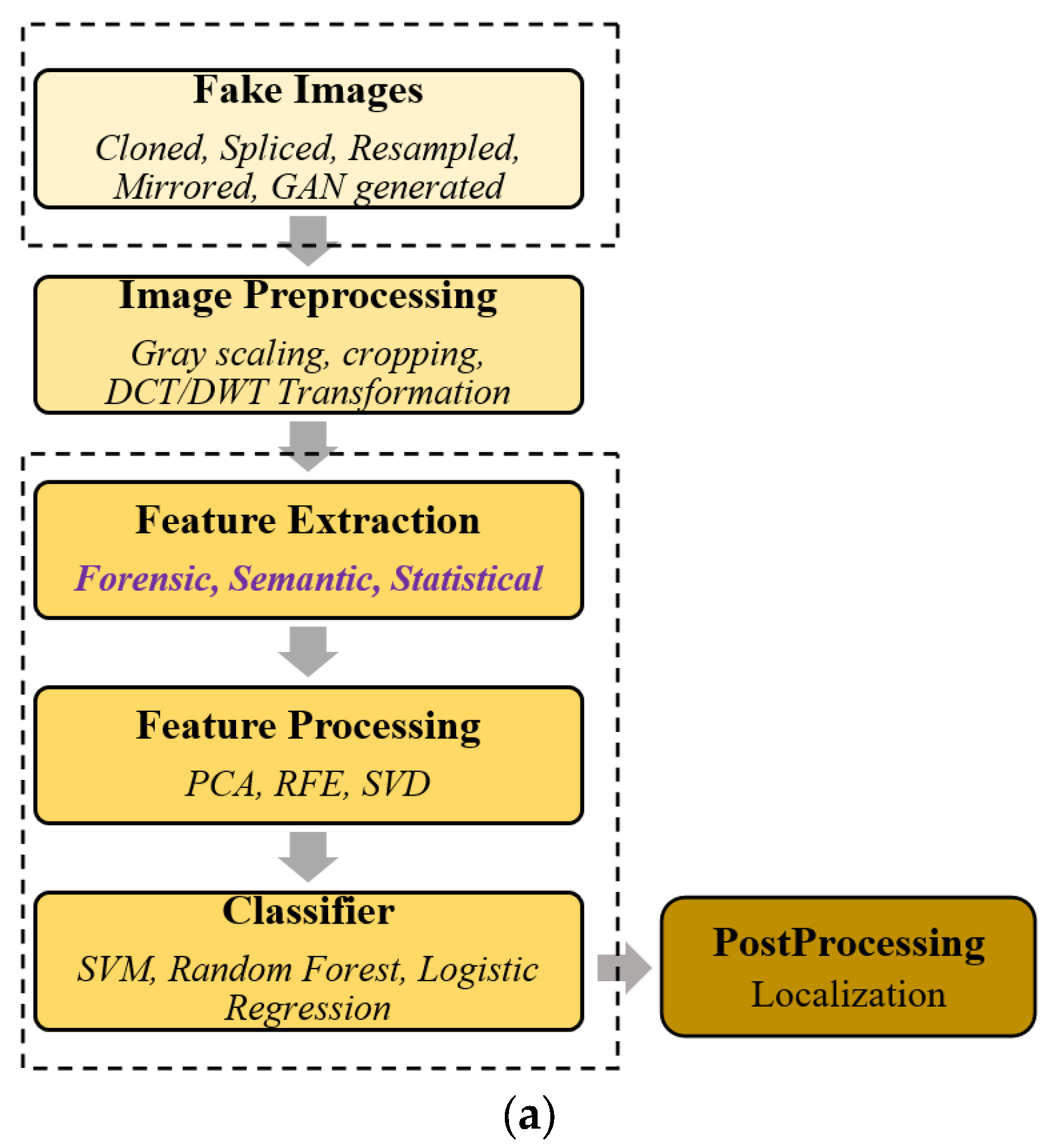
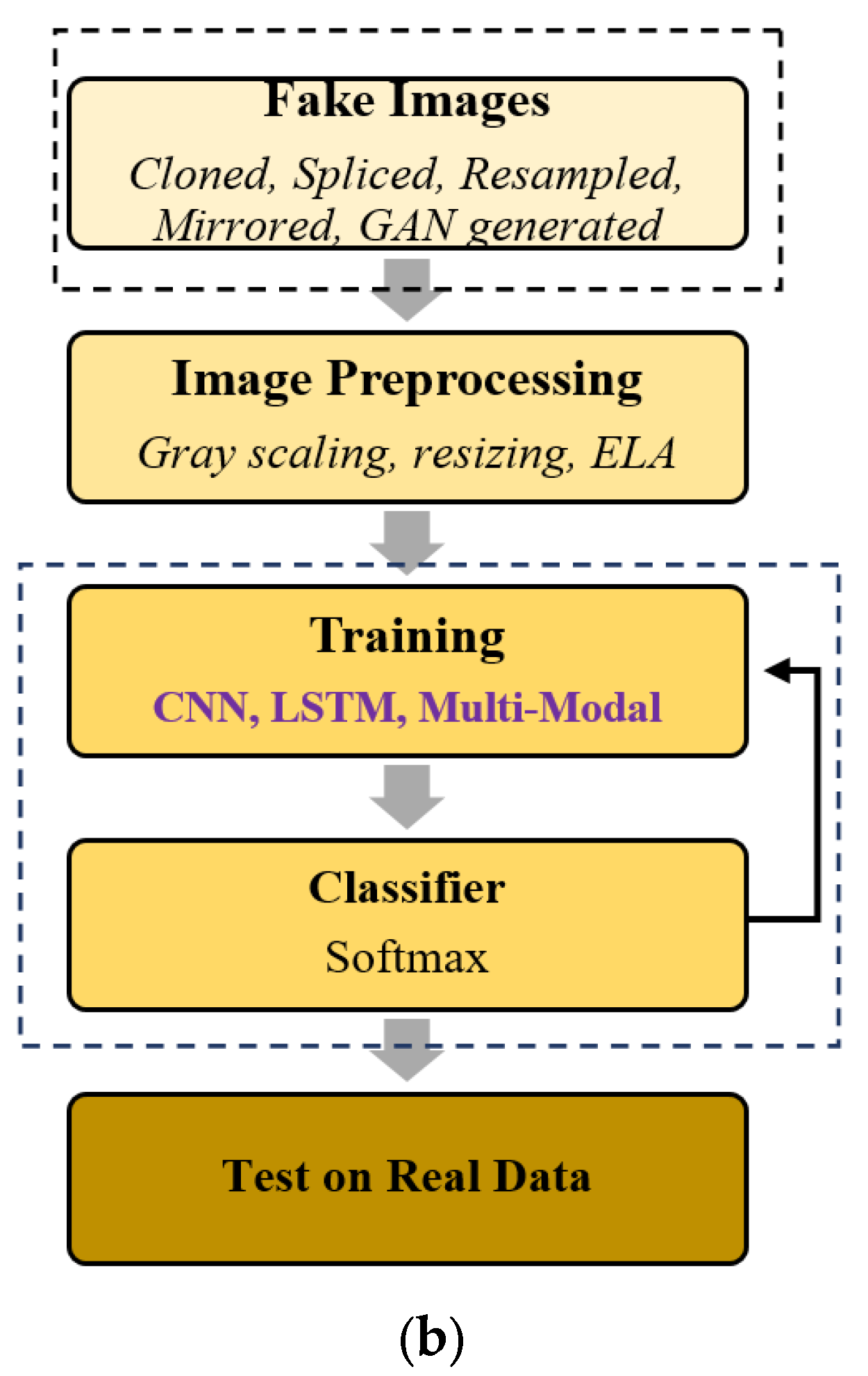
2. Fake Image Detection Process
3. Image Tampering Techniques
3.1. Mirroring
3.2. Resampling
3.3. Move/Cloning
3.4. Image Splicing
3.5. Generative Adversarial Networks

4. Fake Image Detection Methods—Using Handcrafted Feature Set
4.1. Forensic Features Based
4.1.1. Copy-and-Move/Cloning
4.1.2. Image Splicing
4.1.3. Resampling
4.1.4. JPEG Compression
4.1.5. GAN-Generated Images
4.1.6. Problems—Forensic Method
- Specialization: Non-specialized examples as they undergo multiple manipulations;
- Proper resolution: Social Images are deficient in quality due to size constraints over the platforms;
- Compression: They are highly compressed images and have multiple compressions at times;
- Visual Features: Noise addition through the blur and edge removal techniques; thus, features are lost;
- Cropping: Much cropping is carried out to hide the details and highlight emotional content;
- Regions: Images can have large manipulated areas or tiny tampered patches. Figure 12 shows one such example, where a real tree shoot is marked as tampered (last right shoot);
- Source: Sources can be different, like digital cameras, computer-generated, and GAN;
- Formats: Platforms support multiple formats like JPEG, TIFF, GIF, BMP, PNG, and PSB.
4.2. Semantic Features
4.3. Image Retrieval/Web Search
- Not all images can be searched over the reverse web search;
- Images/news not gathering enough highlights will not be ranked in the initial few pages;
- Reverse image searches will also bring images from fake websites wherein such fake images are spread;
- It requires time for the fake image to spread; searching before it becomes viral will not fetch any relevant information;
- Searching fake videos over the web is a tight task and requires effort and time.
4.4. Statistical Features
- Count: The presence of images in fake news. For example, how many images are present?
- Popularity: How popular is the event image over social media, such as comments and re-tweets?
- Dimension: What image size is gaining popularity compared to other images?
- The study suggested specific patterns in these statistical ratios, which are then used to classify the event as real or fake;
- Issues with statistical methods:
- Statistical methods need to be researched further. Similar statistical observations can be observed with real news, too;
- Also, it does not accurately identify fake images. It only gives a diligent prediction pointing toward fake image probability.
5. Fake Image Detection Method—Using Neural Networks
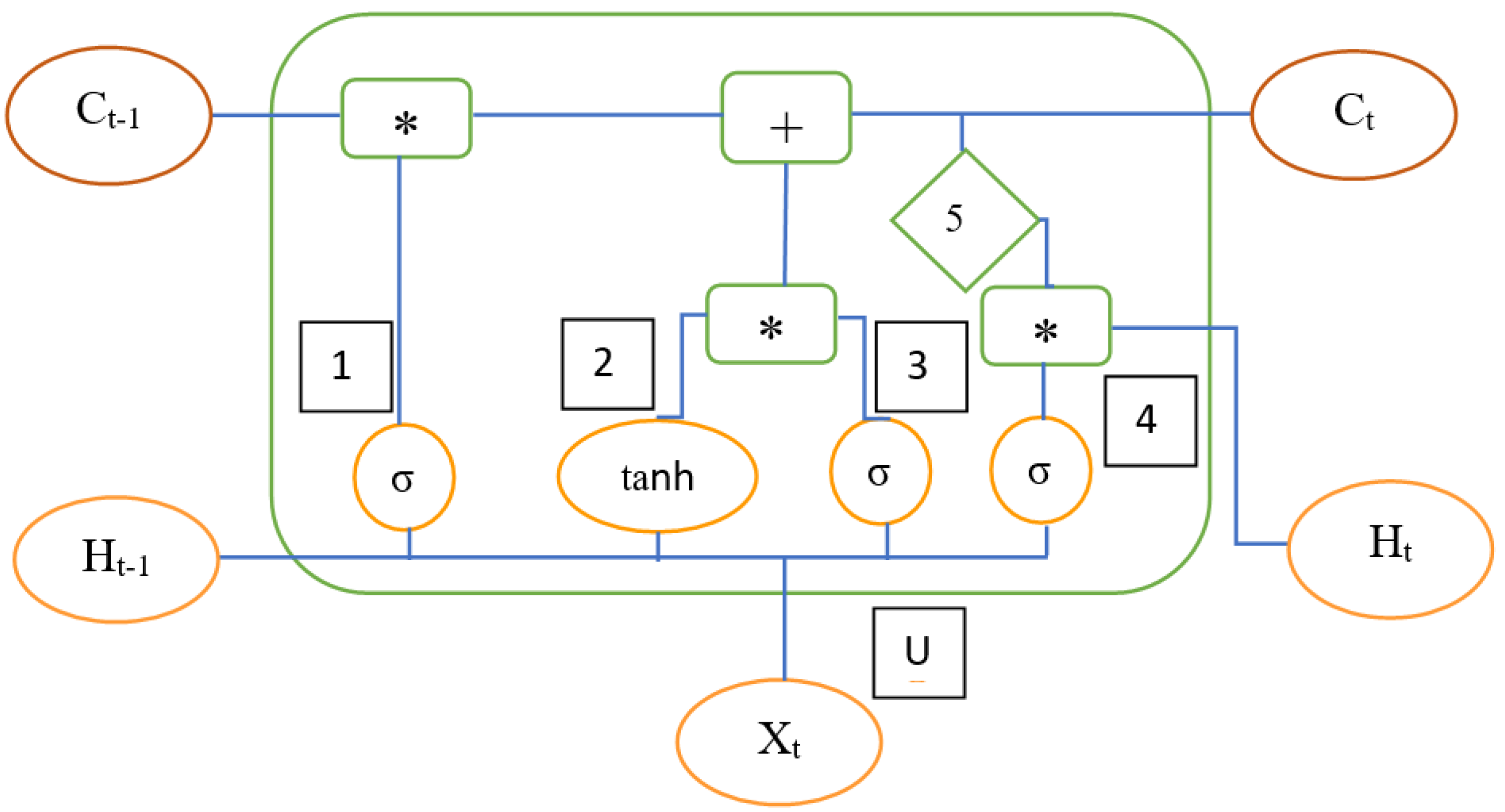
5.1. Convolutional Neural Network—Image Specific
- Feature Vectors/Intrinsic characteristics of fake images are learned by themselves. It does not need a feature set;
- It can detect images having multiple manipulations;
- Can detect images having Pre/Post-processing after tampering is applied over the images;
- It can use pre-trained state-of-the-art DNN models, which saves time;
- Provide higher results and better accuracy;
- It can work well on unstructured images/data from various sources and formats;
- ViT’s based models work well on deepfakes (GAN) images and videos.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Framework | Columbia | CASIA 1.0 | CASIA 2.0 | NIST 16 |
|---|---|---|---|---|---|
| Bappy et al. [91] | CNN + LSTM | - | - | - | 0.764 |
| Salloum et al. [90] | MFCN | 0.611 | 0.541 | - | 0.571 |
| Zhou et al. [92] | FRCNN (RBG N) | 0.697 | 0.408 | - | 0.722 |
| Xiao et al. [94] | C-CNN + R-CNN (C2RNet) | 0.695 | - | 0.675 | - |
| Noise Net [92] | FRNN + SRM Filter | 0.705 | 0.283 | - | - |
| Late Fusion [92] | Fusion FRNN | 0.681 | 0.397 | - | - |
| Wu et al. [95] | Buster Net | - | - | 0.759 | - |
| Bi et al. [96] | RRU-Net | 0.915 | - | 0.841 | - |
| Biach et al. [119] | False-Unet | - | 0.736 | 0.695 | 0.638 |
| Hao et al. [122] | Vision Transformer | - | - | 0.620 | - |
5.2. Multi-Modal Approach
6. Evaluation Parameters and Datasets
6.1. Evaluation Parameters
6.2. Datasets
- BuzzFeed: This source contains data and analysis supporting the BuzzFeed News article, “These Are 50 of the Biggest Fake News Hits on Facebook in 2017”, published on 28 December 2017;
- CASIA: Natural color image repository with realistic tampering operations, available for the public for research;
- CelebA: It contains ten thousand celebrity identities, each with twenty images. There are two hundred thousand images in total;
- COCO: The Irnia Holidays—Copydays dataset contains a set of photos that are collected explicitly from personal holidays. Each photo has suffered three kinds of artificial attacks, JPEG, cropping, and “strong”;
- Columbia: The original images in this dataset consist of 312 images from the CalPhotos collection and 10 captured using a digital camera. The data set consists of 1845 images;
- CoMoFod: This database contains a total of 13,520 forged images. These images are a set of 260 manipulated images. Of 260 images, 200 images are in a small category, and the rest are in a large category;
- FakeNewsNet: This repository contains fake news articles while traversing the fact-check websites PolitiFact and GossipCop. These articles are then explored over the web pages. The PolitiFact section has 447 real and 336 fake news articles with images, while the GossipCop section contains 16,767 real and 1650 fake articles;
- Fakkedit: The Fakeddit is the latest and largest multi-modal dataset from the real-world social networking website Reddit. It contains over 1 million fake textual news data and over 4 lakh multi-modal samples. The multi-modal samples have text and images. It has both two-way and six-way labeling. Two-way labeling is fake and real. As Reddit collects data from micro-sites like Twitter, Facebook, Instagram, and WhatsApp, this dataset has the largest diversified dataset. In the experiment, we have selected a two-way labeling of fake vs. real. As the images are from multiple platforms, it tests the framework’s robustness;
- FNC: Kaggle fake news detection challenge dataset. It has content from 244 websites and includes 12,999 news stories collected from these websites;
- MediaEval: Comprises a total of 413 images, of which 193 cases are of real images, 218 cases are of fake images, and two cases are of altered videos. These images are associated with 9404 fake and 6225 real tweets posted by 9025 and 5895 unique users, respectively;
- NIST Nimble: The Nimble 16 dataset has approximately 10,000 images with various types of tampering, including the images where anti-forensic algorithms were used to hide minor alterations;
- PGGAN: Consisting of 100K GAN-generated fake celebrity images at 1024 × 1024 resolution;
- PHEME: The rumors and hard facts made on Twitter amid breaking news are collected in this dataset. It contains rumors related to nine events; each is annotated with its veracity value, true, false, or unverified.
- Weibo: Comprises Sina Weibo data collected between 2012 and 2016 from the web and mobile platforms. The collection has domestic and international news.
7. Limitations and Challenges
7.1. Labeled Dataset
7.2. Cross-Platform Training
7.3. Satire vs. Fake
7.4. Interpretability
7.5. Audio Splicing
7.6. Multi-Modal Detection
7.7. Deepfakes
7.8. Active Methods
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barthel, M.; Mitchell, A.; Holcomb, J. Many Americans Believe Fake News Is Sowing Confusion. Available online: https://www.journalism.org/2016/12/15/many-americans-believe-fake-news-is-sowing-confusion/ (accessed on 2 May 2020).
- CIGI-Ipsos Global Survey on Internet Security and Trust. 2019. Available online: https://www.cigionline.org/internet-survey-2019 (accessed on 15 January 2021).
- Silverman, C. This Analysis Shows How Viral Fake Election News Stories Outperformed Real News on Facebook. Available online: https://www.buzzfeednews.com/article/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook#.emA15rzd0 (accessed on 2 May 2020).
- Gowen, A. As Mob Lynchings Fueled by Whatsapp Messages Sweep India, Authorities Struggle to Combat Fake News. Available online: https://www.washingtonpost.com/world/asia_pacific/as-mob-lynchings-fueled-by-whatsapp-sweep-india-authorities-struggle-to-combat-fake-news/2018/07/02/683a1578-7bba-11e8-ac4e-421ef7165923_story.html (accessed on 2 May 2020).
- Kudrati, M. This Picture of Donald Trump Endorsing PM Modi Is a Hoax. Available online: https://www.boomlive.in/this-picture-of-donald-trump-endorsing-pm-modi-is-a-hoax/ (accessed on 10 July 2020).
- Baynes, C. Coronavirus: Patients Refusing Treatment Because of Fake News on Social Media, NHS Staff Warn. Available online: https://www.independent.co.uk/news/uk/home-news/coronavirus-fake-news-conspiracy-theories-antivax-5g-facebook-twitter-a9549831.html (accessed on 15 July 2020).
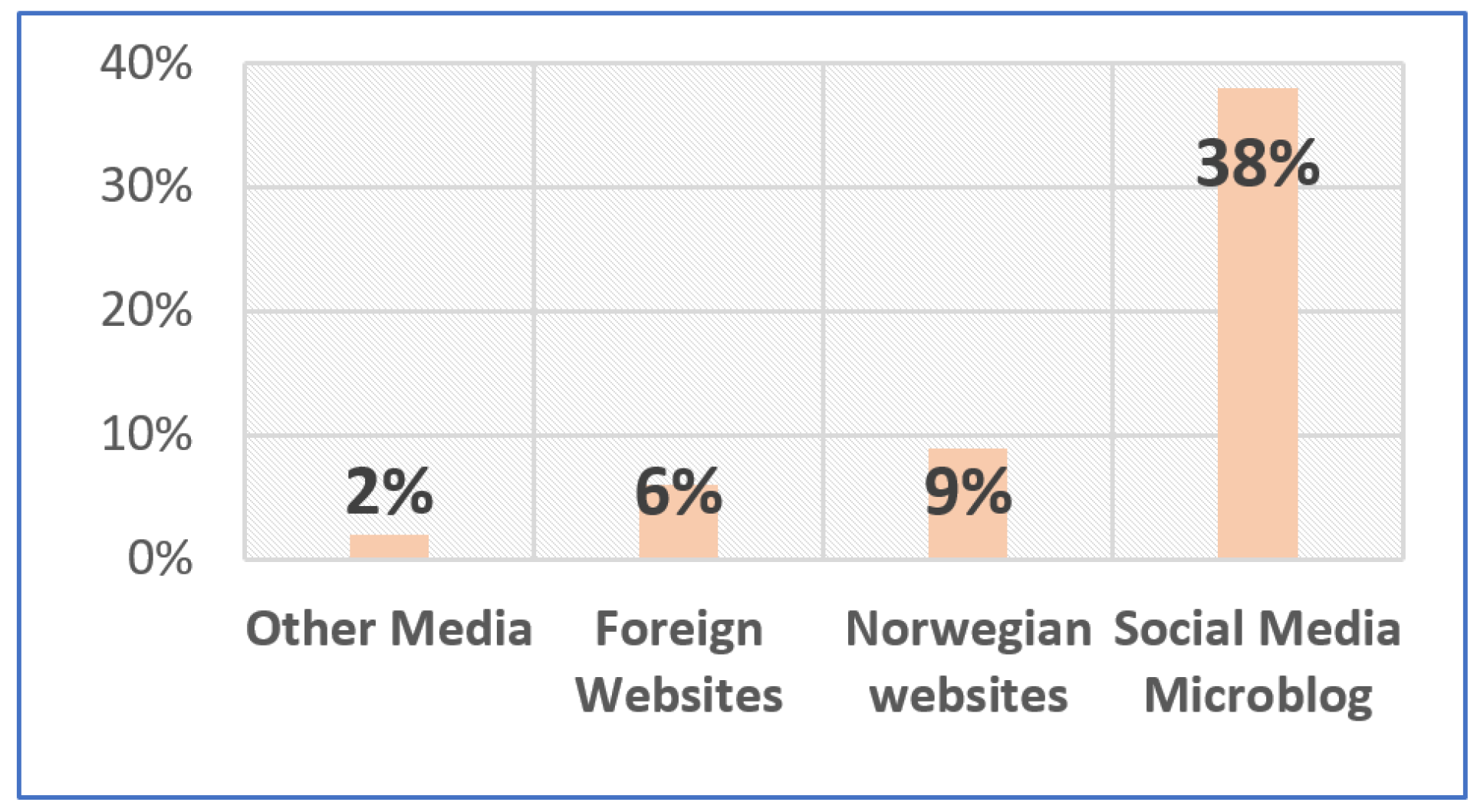
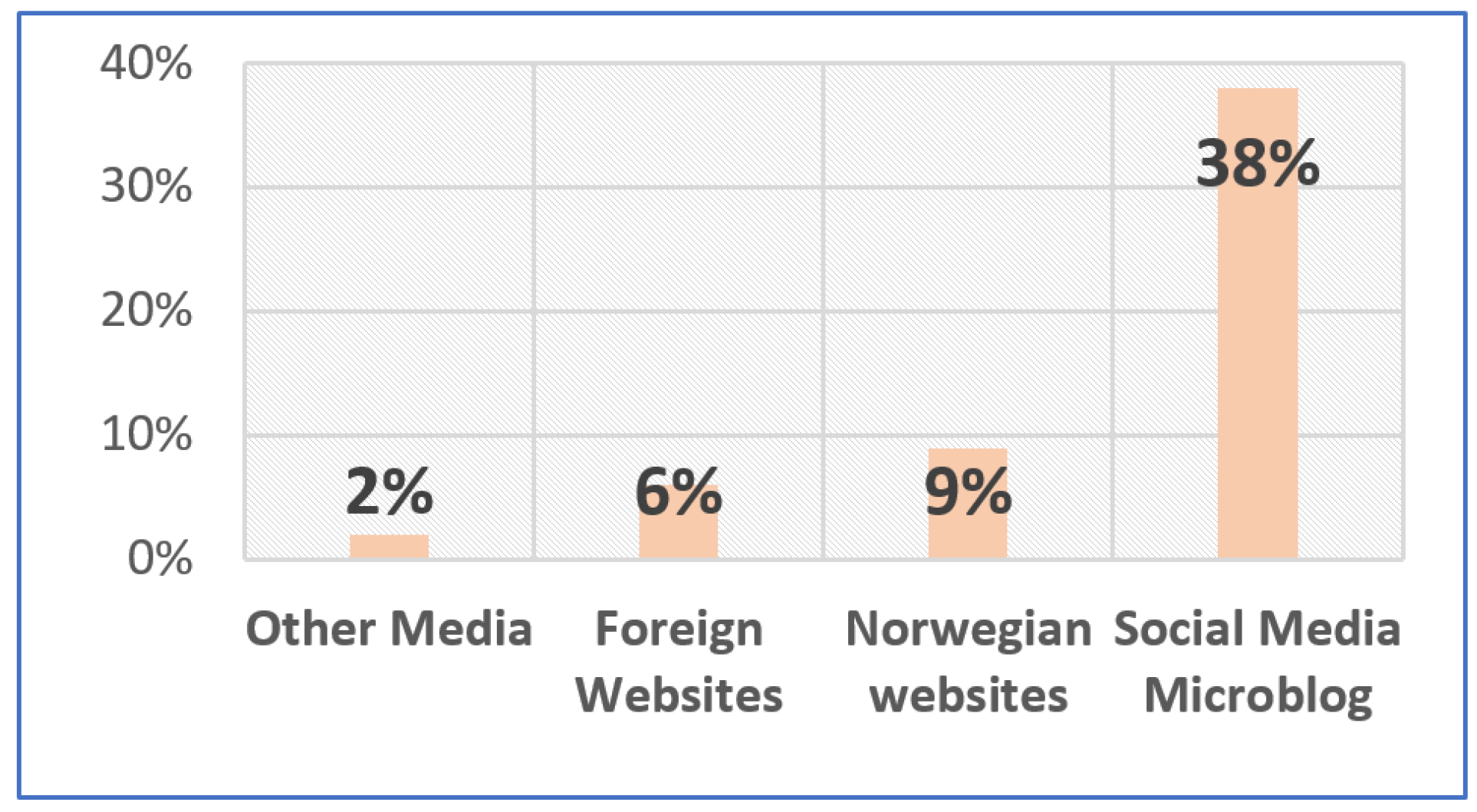
- Stoll, J. Reading Fake News about the Coronavirus in Norway 2020, by Source. Available online: https://www.statista.com/statistics/1108710/reading-fake-news-about-the-coronavirus-in-norway-by-source/ (accessed on 2 May 2020).
- Unnikrishnan, D. Photo of PM Narendra Modi Bowing to Xi Jinping Is Morphed. Available online: https://www.boomlive.in/fake-news/photo-of-pm-narendra-modi-bowing-to-xi-jinping-is-morphed-8579 (accessed on 10 July 2020).
- Amsberry, C. Alteration of Photos Raise Host of Legal, Ethical Issues. Wall Str. J. 1989, 1, 26–89. [Google Scholar]
- Jaffe, J. Dubya, Willya Turn the Book Over. Available online: https://www.wired.com/2002/11/dubya-willya-turn-the-book-over/ (accessed on 10 July 2020).
- Mishra, M.; Adhikary, M.C. Digital Image Tamper Detection Techniques—A Comprehensive Study. arXiv 2013, arXiv:1306.6737. [Google Scholar]
- Mandankandy, A.A. Image forgery and its detection: A survey. In Proceedings of the International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 17–18 March 2017. [Google Scholar] [CrossRef]
- Parikh, S.B.; Atrey, P.K. Media-Rich Fake News Detection: A Survey. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 436–441. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A Survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Wang, X.-Y.; Wang, C.; Wang, L.; Yang, H.-Y.; Niu, P.-P. Robust and effective multiple copy-move forgeries detection and localization. Pattern Anal. Appl. 2021, 24, 1025–1046. [Google Scholar] [CrossRef]
- Alamro, L.; Nooraini, Y. Copy-move forgery detection using integrated DWT and SURF. J. Telecommun. Electron. Comput. Eng. (JTEC) 2017, 9, 67–71. [Google Scholar]
- Jwaid, M.F.; Baraskar, T.N. Study and analysis of copy-move & splicing image forgery detection techniques. In Proceedings of the 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 697–702. [Google Scholar] [CrossRef]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting Fake News: Image Splice Detection via Learned Self-Consistency. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 106–124. [Google Scholar] [CrossRef]
- Vadsola, M. The Math behind GANs (Generative Adversarial Networks). Available online: https://towardsdatascience.com/the-math-behind-gans-generative-adversarial-networks-3828f3469d9c (accessed on 10 May 2020).
- Vincent, J. Facebook’s Problems Moderating Deepfakes Will Only Get Worse in 2020. Available online: https://www.theverge.com/2020/1/15/21067220/deepfake-moderation-apps-tools-2020-facebook-reddit-social-media (accessed on 10 July 2020).
- Warif, N.B.A.; Idris, M.Y.I.; Wahab, A.W.A.; Ismail, N.-S.N.; Salleh, R. A comprehensive evaluation procedure for copy-move forgery detection methods: Results from a systematic review. Multimed. Tools Appl. 2022, 81, 15171–15203. [Google Scholar] [CrossRef]
- Fridrich, J.; Soukal, D.; Lukas, J. Detection of copy-move forgery in digital images. In Proceedings of the Digital Forensic Research Workshop, Cleveland, OH, USA, 6–8 August 2003; pp. 55–61. [Google Scholar]
- Popescu, A.C.; Farid, H. Exposing Digital Forgeries by Detecting Duplicated Image Regions; Technical Report TR2004-515; Department of Computer Science, Dartmouth College: Hanover, NH, USA, 2004. [Google Scholar]
- Li, G.; Wu, Q.; Tu, D.; Sun, S. A Sorted Neighborhood Approach for Detecting Duplicated Regions in Image Forgeries Based on DWT and SVD. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 1750–1753. [Google Scholar] [CrossRef]
- Bayram, S.; Sencar, H.T.; Memon, N. An efficient and robust method for detecting copy-move forgery. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1053–1056. [Google Scholar] [CrossRef]
- Gul, G.; Avcibas, I.; Kurugollu, F. SVD based image manipulation detection. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1765–1768. [Google Scholar] [CrossRef]
- Huang, Y.; Lu, W.; Sun, W.; Long, D. Improved DCT-based detection of copy-move forgery in images. Forensic Sci. Int. 2011, 206, 178–184. [Google Scholar] [CrossRef]
- Li, L.; Li, S.; Zhu, H.; Chu, S.-C.; Roddick, J.F.; Pan, J.-S. An efficient scheme for detecting copy-move forged images by local binary patterns. J. Inf. Hiding Multimed. Signal Process. 2013, 4, 46–56. [Google Scholar]
- Lee, J.-C.; Chang, C.-P.; Chen, W.-K. Detection of copy–move image forgery using histogram of orientated gradients. Inf. Sci. 2015, 321, 250–262. [Google Scholar] [CrossRef]
- Hussain, M.; Qasem, S.; Bebis, G.; Muhammad, G.; Aboalsamh, H.; Mathkour, H. Evaluation of Image Forgery Detection Using Multi-Scale Weber Local Descriptors. Int. J. Artif. Intell. Tools 2015, 24, 1540016. [Google Scholar] [CrossRef]
- Mahmood, T.; Nawaz, T.; Irtaza, A.; Ashraf, R.; Shah, M.; Mahmood, M.T. Copy-Move Forgery Detection Technique for Forensic Analysis in Digital Images. Math. Probl. Eng. 2016, 2016, 8713202. [Google Scholar] [CrossRef]
- Chen, B.; Yu, M.; Su, Q.; Shim, H.J.; Shi, Y.-Q. Fractional Quaternion Zernike Moments for Robust Color Image Copy-Move Forgery Detection. IEEE Access 2018, 6, 56637–56646. [Google Scholar] [CrossRef]
- Dixit, A.; Bag, S. A fast technique to detect copy-move image forgery with reflection and non-affine transformation attacks. Expert Syst. Appl. 2021, 182, 115282. [Google Scholar] [CrossRef]
- Rani, A.; Jain, A.; Kumar, M. Identification of copy-move and splicing based forgeries using advanced SURF and revised template matching. Multimed. Tools Appl. 2021, 80, 23877–23898. [Google Scholar] [CrossRef]
- Tanaka, M.; Shiota, S.; Kiya, H. A Detection Method of Operated Fake-Images Using Robust Hashing. J. Imaging 2021, 7, 134. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Liang, Z.; Gan, Y.; Zhong, J. A novel copy-move forgery detection algorithm via two-stage filtering. Digit. Signal Process. 2021, 113, 103032. [Google Scholar] [CrossRef]
- Tahaoglu, G.; Ulutas, G.; Ustubioglu, B.; Ulutas, M.; Nabiyev, V.V. Ciratefi based copy move forgery detection on digital images. Multimed. Tools Appl. 2022, 81, 22867–22902. [Google Scholar] [CrossRef]
- Uma, S.; Sathya, P.D. Copy-move forgery detection of digital images using football game optimization. Aust. J. Forensic Sci. 2020, 54, 258–279. [Google Scholar] [CrossRef]
- Gan, Y.; Zhong, J.; Vong, C. A Novel Copy-Move Forgery Detection Algorithm via Feature Label Matching and Hierarchical Segmentation Filtering. Inf. Process. Manag. 2021, 59, 102783. [Google Scholar] [CrossRef]
- Ng, T.; Chang, S. A model for image splicing. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Singapore, 24–27 October 2004; pp. 1169–1172. [Google Scholar]
- Popescu, A.; Farid, H. Exposing digital forgeries in color filter array interpolated images. IEEE Trans. Signal Process. 2005, 53, 3948–3959. [Google Scholar] [CrossRef]
- Chen, W.; Shi, Y.Q.; Su, W. Image splicing detection using 2-D phase congruency and statistical moments of characteristic function. In Security, Steganography, and Watermarking of Multimedia Contents IX; SPIE: Bellingham, WA, USA, 2007; Volume 6505, pp. 281–288. [Google Scholar] [CrossRef]
- Wang, W.; Dong, J.; Tan, T. Effective image splicing detection based on image chroma. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1257–1260. [Google Scholar] [CrossRef]
- Zhao, X.; Li, J.; Li, S.; Wang, S. Detecting Digital Image Splicing in Chroma Spaces. In Proceedings of the Digital Watermarking: 9th International Workshop, IWDW 2010, Seoul, Republic of Korea, 1–3 October 2010; pp. 12–22. [Google Scholar] [CrossRef]
- Liu, Q.; Cao, X.; Deng, C.; Guo, X. Identifying Image Composites Through Shadow Matte Consistency. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1111–1122. [Google Scholar] [CrossRef]
- Ferrara, P.; Bianchi, T.; De Rosa, A.; Piva, A. Image Forgery Localization via Fine-Grained Analysis of CFA Artifacts. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1566–1577. [Google Scholar] [CrossRef]
- He, Z.; Lu, W.; Sun, W.; Huang, J. Digital image splicing detection based on Markov features in DCT and DWT domain. Pattern Recognit. 2012, 45, 4292–4299. [Google Scholar] [CrossRef]
- Mazumdar, A.; Bora, P.K. Exposing splicing forgeries in digital images through dichromatic plane histogram discrepancies. In Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing, Guwahati, India, 18–22 December 2016; Volume 62, pp. 1–8. [Google Scholar] [CrossRef]
- Moghaddasi, Z.; Jalab, H.A.; Noor, R.M. Image splicing detection using singular value decomposition. In Proceedings of the Second International Conference on Internet of things, Data and Cloud Computing, Cambridge, UK, 22–23 March 2017; Volume 140, pp. 1–5. [Google Scholar] [CrossRef]
- Sheng, H.; Shen, X.; Lyu, Y.; Shi, Z.; Ma, S. Image splicing detection based on Markov features in discrete octonion cosine transform domain. IET Image Process. 2018, 12, 1815–1823. [Google Scholar] [CrossRef]
- Jaiswal, A.K.; Srivastava, R. A technique for image splicing detection using hybrid feature set. Multimed. Tools Appl. 2020, 79, 11837–11860. [Google Scholar] [CrossRef]
- Itier, V.; Strauss, O.; Morel, L.; Puech, W. Color noise correlation-based splicing detection for image forensics. Multimed. Tools Appl. 2021, 80, 13215–13233. [Google Scholar] [CrossRef]
- Monika; Bansal, D.; Passi, A. Image Forensic Investigation Using Discrete Cosine Transform-Based Approach. Wirel. Pers. Commun. 2021, 119, 3241–3253. [Google Scholar] [CrossRef]
- Niyishaka, P.; Bhagvati, C. Image splicing detection technique based on Illumination-Reflectance model and LBP. Multimed. Tools Appl. 2020, 80, 2161–2175. [Google Scholar] [CrossRef]
- Jalab, H.A.; Alqarni, M.A.; Ibrahim, R.W.; Almazroi, A.A. A novel pixel’s fractional mean-based image enhancement algorithm for better image splicing detection. J. King Saud Univ.-Sci. 2022, 34, 101805. [Google Scholar] [CrossRef]
- Agrawal, S.; Kumar, P.; Seth, S.; Parag, T.; Singh, M.; Babu, V. SISL: Self-Supervised Image Signature Learning for Splicing Detection & Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Work-Shops, New Orleans, LA, USA, 19–20 June 2022; pp. 22–32. [Google Scholar]
- Sun, Y.; Ni, R.; Zhao, Y. ET: Edge-Enhanced Transformer for Image Splicing Detection. IEEE Signal Process. Lett. 2022, 29, 1232–1236. [Google Scholar] [CrossRef]
- Popescu, A.; Farid, H. Exposing digital forgeries by detecting traces of resampling. IEEE Trans. Signal Process. 2005, 53, 758–767. [Google Scholar] [CrossRef]
- Fillion, C.; Sharma, G. Detecting content adaptive scaling of images for forensic applications. In Media Forensics and Security II; SPIE: Bellingham, WA, USA, 2010; Volume 75410. [Google Scholar] [CrossRef]
- Mahalakshmi, S.D.; Vijayalakshmi, K.; Priyadharsini, S. Digital image forgery detection and estimation by exploring basic image manipulations. Digit. Investig. 2012, 8, 215–225. [Google Scholar] [CrossRef]
- Niu, P.; Wang, C.; Chen, W.; Yang, H.; Wang, X. Fast and effective Keypoint-based image copy-move forgery detection using complex-valued moment invariants. J. Vis. Commun. Image Represent. 2021, 77, 103068. [Google Scholar] [CrossRef]
- Fan, Z.; de Queiroz, R. Identification of bitmap compression history: JPEG detection and quantizer estimation. IEEE Trans. Image Process. 2003, 12, 230–235. [Google Scholar] [CrossRef] [PubMed]
- Krawetz, N. A Picture’s Worth… Hacker Factor Solutions. 2007. Available online: https://www.hackerfactor.com/papers (accessed on 10 May 2020).
- Zhang, J.; Wang, H.; Su, Y. Detection of Double-Compression in JPEG2000 Images. In Proceedings of the 2008 Second International Symposium on Intelligent Information Technology Application, Shanghai, China, 21–22 December 2008; Volume 1, pp. 418–421. [Google Scholar] [CrossRef]
- Lin, Z.; He, J.; Tang, X.; Tang, C.-K. Fast, automatic and fine-grained tampered JPEG image detection via DCT coefficient analysis. Pattern Recognit. 2009, 42, 2492–2501. [Google Scholar] [CrossRef]
- Kwon, M.-J.; Nam, S.-H.; Yu, I.-J.; Lee, H.-K.; Kim, C. Learning JPEG Compression Artifacts for Image Manipulation Detection and Localization. Int. J. Comput. Vis. 2022, 130, 1875–1895. [Google Scholar] [CrossRef]
- McCloskey, S.; Albright, M. Detecting Gan-Generated Imagery Using Color Cues. arXiv 2018, arXiv:1812.08247. [Google Scholar]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.S.; Chandrasekaran, S.; Flenner, A.; Bappy, J.H.; Roy-Chowdhury, A. Detecting GAN generated Fake Images using Co-occurrence Matrices. Electron. Imaging 2019, 2019, 532–541. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 June 2019; pp. 83–92. [Google Scholar]
- Li, Y.; Chang, M.-C.; Lyu, S. In Ictu Oculi: Exposing AI Created Fake Videos by Detecting Eye Blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, C.; Li, Y. A Novel Counterfeit Feature Extraction Technique for Exposing Face-Swap Images Based on Deep Learning and Error Level Analysis. Entropy 2020, 22, 249. [Google Scholar] [CrossRef]
- Shang, Z.; Xie, H.; Zha, Z.; Yu, L.; Li, Y.; Zhang, Y. PRRNet: Pixel-Region relation network for face forgery detection. Pattern Recognit. 2021, 116, 107950. [Google Scholar] [CrossRef]
- Sunstein, C.R. On Rumors: How Falsehoods Spread, Why We Believe Them, and What Can Be Done; Princeton University Press: Princeton, NJ, USA, 2014. [Google Scholar]
- Jin, Z.; Cao, J.; Luo, J.; Zhang, Y. Image credibility analysis with effective domain transferred deep networks. arXiv 2016, arXiv:1611.05328. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on Social Media. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Ghanem, B.; Ponzetto, S.P.; Rosso, P. FacTweet: Profiling Fake News Twitter Accounts. In Proceedings of the International Conference on Statistical Language and Speech Processing, Cardiff, UK, 14–16 October 2020; pp. 35–45. [Google Scholar]
- Zhang, Y.; Tan, Q.; Qi, S.; Xue, M. PRNU-based Image Forgery Localization with Deep Multi-scale Fusion. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 67. [Google Scholar] [CrossRef]
- Xie, X.; Liu, Y.; de Rijke, M.; He, J.; Zhang, M.; Ma, S. Why People Search for Images using Web Search Engines. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 655–663. [Google Scholar] [CrossRef]
- Xie, X.; Mao, J.; Liu, Y.; de Rijke, M.; Shao, Y.; Ye, Z.; Zhang, M.; Ma, S. Grid-based Evaluation Metrics for Web Image Search. In Proceedings of the The World Wide Web Conference (WWW 2019), San Francisco, CA, USA, 13–17 May 2019; pp. 2103–2114. [Google Scholar] [CrossRef]
- Gaikwad, M.; Hoeber, O. An Interactive Image Retrieval Approach to Searching for Images on Social Media. In Proceedings of the Conference on Human Information Interaction and Retrieval (CHIIR, 2019), Glasgow, UK, 10–14 March 2019. [Google Scholar] [CrossRef]
- Vishwakarma, D.K.; Varshney, D.; Yadav, A. Detection and veracity analysis of fake news via scrapping and authenticating the web search. Cogn. Syst. Res. 2019, 58, 217–229. [Google Scholar] [CrossRef]
- Gupta, A.; Lamba, H.; Kumaraguru, P.; Joshi, A. Faking Sandy: Characterizing and identifying fake images on Twitter during Hurricane Sandy. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 729–736. [Google Scholar] [CrossRef]
- Huang, Q.; Zhou, C.; Wu, J.; Liu, L.; Wang, B. Deep spatial–temporal structure learning for rumor detection on Twitter. Neural Comput. Appl. 2020, 35, 12995–13005. [Google Scholar] [CrossRef]
- Chen, Y.; Retraint, F.; Qiao, T. Image splicing forgery detection using simplified generalized noise model. Signal Process. Image Commun. 2022, 107, 116785. [Google Scholar] [CrossRef]
- Jin, Z.; Cao, J.; Zhang, Y.; Zhou, J.; Tian, Q. Novel Visual and Statistical Image Features for Microblogs News Verification. IEEE Trans. Multimed. 2016, 19, 598–608. [Google Scholar] [CrossRef]
- Xu, Z.; Li, S.; Deng, W. Learning temporal features using LSTM-CNN architecture for face anti-spoofing. In Proceedings of the 3rd Asian Conference on Pattern Recognition, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 141–145. [Google Scholar]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 20–22 June 2016; pp. 5–10. [Google Scholar]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Rao, Y.; Ni, J.; Xie, H. Multi-semantic CRF-based attention model for image forgery detection and localization. Signal Process. 2021, 183, 108051. [Google Scholar] [CrossRef]
- Salloum, R.; Ren, Y.; Kuo, C.-C.J. Image Splicing Localization using a Multi-task Fully Convolutional Network (MFCN). J. Vis. Commun. Image Represent. 2018, 51, 201–209. [Google Scholar] [CrossRef]
- Bappy, J.H.; Roy-Chowdhury, A.K.; Bunk, J.; Nataraj, L.; Manjunath, B. Exploiting Spatial Structure for Localizing Manipulated Image Regions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning Rich Features for Image Manipulation Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1053–1061. [Google Scholar] [CrossRef]
- Rehman, Y.A.U.; Po, L.M.; Liu, M. LiveNet: Improving features generalization for face liveness detection using convolution neural networks. Expert Syst. Appl. 2018, 108, 159–169. [Google Scholar] [CrossRef]
- Xiao, B.; Wei, Y.; Bi, X.; Li, W.; Ma, J. Image splicing forgery detection combining coarse to refined convolutional neural network and adaptive clustering. Inf. Sci. 2019, 511, 172–191. [Google Scholar] [CrossRef]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. BusterNet: Detecting Copy-Move Image Forgery with Source/Target Localization. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; pp. 170–186. [Google Scholar] [CrossRef]
- Bi, X.; Wei, Y.; Xiao, B.; Li, W. RRU-Net: The Ringed Residual U-Net for Image Splicing Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 30–39. [Google Scholar] [CrossRef]
- Liu, B.; Pun, C.-M. Exposing splicing forgery in realistic scenes using deep fusion network. Inf. Sci. 2020, 526, 133–150. [Google Scholar] [CrossRef]
- Abhishek; Jindal, N. Copy move and splicing forgery detection using deep convolution neural network, and semantic segmentation. Multimed. Tools Appl. 2021, 80, 3571–3599. [Google Scholar] [CrossRef]
- Hosny, K.M.; Mortda, A.M.; Fouda, M.M.; Lashin, N.A. An Efficient CNN Model to Detect Copy-Move Image Forgery. IEEE Access 2022, 10, 48622–48632. [Google Scholar] [CrossRef]
- Elaskily, M.A.; Alkinani, M.H.; Sedik, A.; Dessouky, M.M. Deep learning based algorithm (ConvLSTM) for Copy Move Forgery Detection. J. Intell. Fuzzy Syst. 2021, 40, 4385–4405. [Google Scholar] [CrossRef]
- Koul, S.; Kumar, M.; Khurana, S.S.; Mushtaq, F.; Kumar, K. An efficient approach for copy-move image forgery detection using convolution neural network. Multimed. Tools Appl. 2022, 81, 11259–11277. [Google Scholar] [CrossRef]
- Hsu, C.-C.; Zhuang, Y.-X.; Lee, C.-Y. Deep Fake Image Detection Based on Pairwise Learning. Appl. Sci. 2020, 10, 370. [Google Scholar] [CrossRef]
- Jeon, H.; Bang, Y.; Woo, S.S. FDFtNet: Facing Off Fake Images Using Fake Detection Fine-Tuning Network. IFIP Adv. Inf. Commun. Technol. 2020, 580, 416–430. [Google Scholar] [CrossRef]
- Wang, S.-Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-Generated Images are Surprisingly Easy to Spot… for Now. arXiv 2020, arXiv:1912.11035. [Google Scholar]
- Neves, J.C.; Tolosana, R.; Vera-Rodriguez, R.; Lopes, V.; Proença, H.P.; Fierrez, J. GANprintR: Improved Fakes and Evaluation of the State of the Art in Face Manipulation Detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1038–1048. [Google Scholar] [CrossRef]
- Arora, T.; Soni, R. Arora, T.; Soni, R. A review of techniques to detect the GAN-generated fake images. In Generative Adversarial Networks for Image-to-Image Translation; Academic Press: Cambridge, MA, USA, 2021; pp. 125–159. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, S.; Li, A.; Lan, G.; Wang, H. Detecting fake images by identifying potential texture difference. Futur. Gener. Comput. Syst. 2021, 125, 127–135. [Google Scholar] [CrossRef]
- Kwon, M.-J.; Yu, I.-J.; Nam, S.-H.; Lee, H.-K. CAT-Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 375–384. [Google Scholar] [CrossRef]
- Meena, K.B.; Tyagi, V. A Deep Learning based Method for Image Splicing Detection. J. Phys. Conf. Ser. 2021, 1714, 012038. [Google Scholar] [CrossRef]
- Jaiswal, A.K.; Srivastava, R. Detection of Copy-Move Forgery in Digital Image Using Multi-scale, Multi-stage Deep Learning Model. Neural Process. Lett. 2022, 54, 75–100. [Google Scholar] [CrossRef]
- Zhuo, L.; Tan, S.; Li, B.; Huang, J. Self-Adversarial Training Incorporating Forgery Attention for Image Forgery Localization. IEEE Trans. Inf. Forensics Secur. 2022, 17, 819–834. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J.; Tian, J.; Liu, J.; Qiao, Y. Robust Image Forgery Detection Against Transmission Over Online Social Networks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 443–456. [Google Scholar] [CrossRef]
- Tyagi, S.; Yadav, D. MiniNet: A concise CNN for image forgery detection. Evol. Syst. 2022, 14, 545–556. [Google Scholar] [CrossRef]
- Ali, S.S.; Ganapathi, I.I.; Vu, N.-S.; Werghi, N. Image Forgery Localization using Image Patches and Deep Learning. In Proceedings of the 2022 IEEE 11th International Conference on Communication Systems and Network Technologies (CSNT), Indore, India, 23–24 April 2022; pp. 583–588. [Google Scholar] [CrossRef]
- Singh, B.; Sharma, D.K. SiteForge: Detecting and localizing forged images on microblogging platforms using deep convolutional neural network. Comput. Ind. Eng. 2021, 162, 107733. [Google Scholar] [CrossRef]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries with Anomalous Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9535–9544. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Z.; Jiang, Z.; Chaudhuri, S.; Yang, Z.; Nevatia, R. SPAN: Spatial Pyramid Attention Network for Image Manipulation Localization. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 312–328. [Google Scholar] [CrossRef]
- Zhuang, P.; Li, H.; Tan, S.; Li, B.; Huang, J. Image Tampering Localization Using a Dense Fully Convolutional Network. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2986–2999. [Google Scholar] [CrossRef]
- El Biach, F.Z.; Iala, I.; Laanaya, H.; Minaoui, K. Encoder-decoder based convolutional neural networks for image forgery detection. Multimed. Tools Appl. 2022, 81, 22611–22628. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Ganguly, S.; Ganguly, A.; Mohiuddin, S.; Malakar, S.; Sarkar, R. ViXNet: Vision Transformer with Xception Network for deepfakes based video and image forgery detection. Expert Syst. Appl. 2022, 210, 118423. [Google Scholar] [CrossRef]
- Hao, J.; Zhang, Z.; Yang, S.; Xie, D.; Pu, S. TransForensics: Image Forgery Localization with Dense Self-Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 15035–15044. [Google Scholar] [CrossRef]
- Arshed, M.A.; Alwadain, A.; Ali, R.F.; Mumtaz, S.; Ibrahim, M.; Muneer, A. Unmasking Deception: Empowering Deepfake Detection with Vision Transformer Network. Mathematics 2023, 11, 3710. [Google Scholar] [CrossRef]
- Heo, Y.-J.; Yeo, W.-H.; Kim, B.-G. DeepFake detection algorithm based on improved vision transformer. Appl. Intell. 2023, 53, 7512–7527. [Google Scholar] [CrossRef]
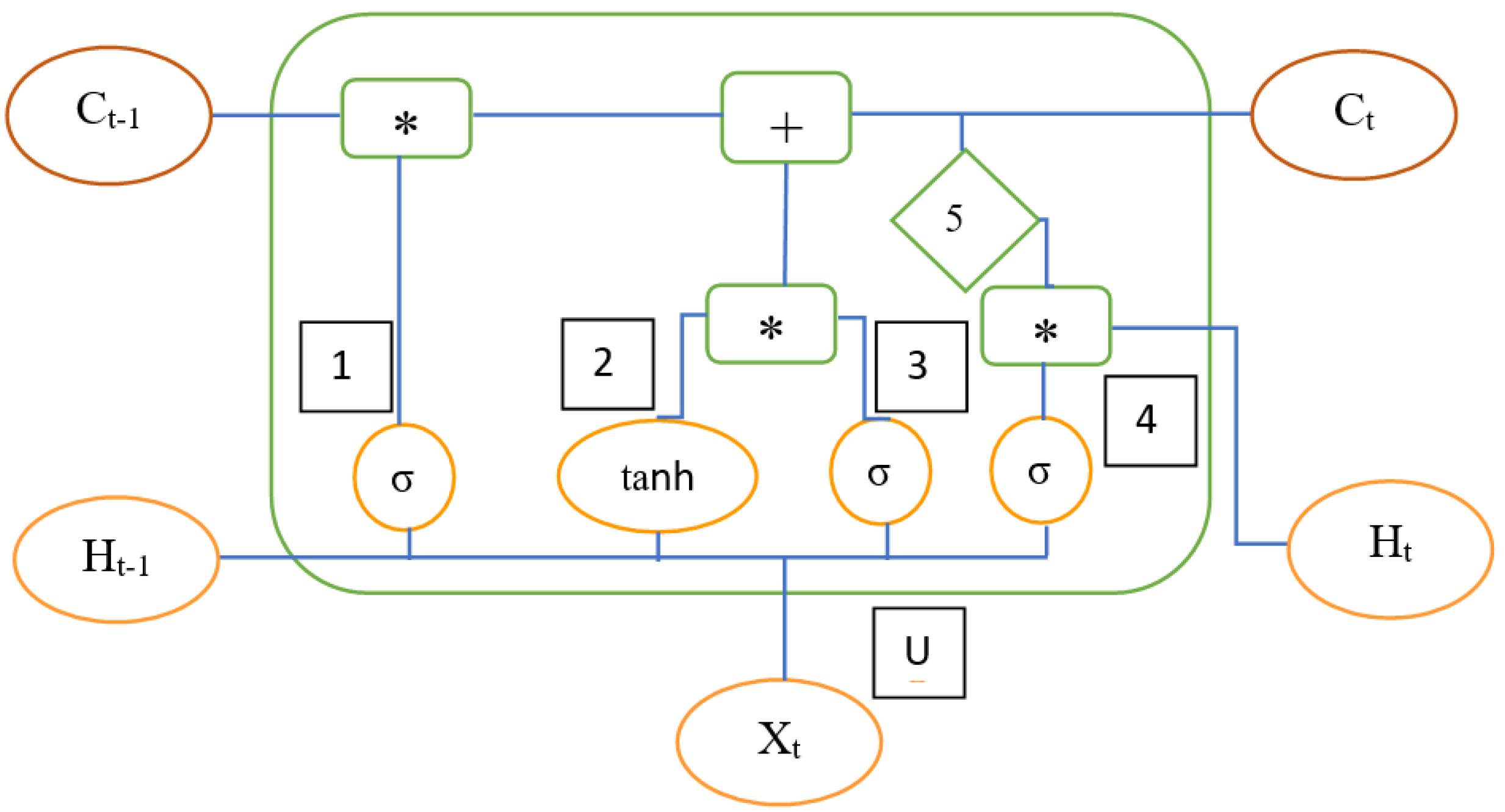
- Sanjeevi, M. Available online: https://medium.com/deep-math-machine-learning-ai/chapter-10-1-deepnlp-lstm-long-short-term-memory-networks-with-math-21477f8e4235 (accessed on 10 May 2020).
- Singh, V.K.; Ghosh, I.; Sonagara, D. Detecting fake news stories via multimodal analysis. J. Assoc. Inf. Sci. Technol. 2020, 72, 3–17. [Google Scholar] [CrossRef]
- Nakamura, K.; Levy, S.; Wang, W.Y. Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake News Detection. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC 2020), Marseille, France, 11–16 May 2020; pp. 6149–6157. Available online: https://www.aclweb.org/anthology/2020.lrec-1.755 (accessed on 18 December 2020).
- Yang, Y.; Zheng, L.; Zhang, J.; Cui, Q.; Li, Z.; Yu, P.S. TI-CNN: Convolutional Neural Networks for Fake News Detection. arXiv 2018, arXiv:1806.00749. [Google Scholar]
- Wang, Y.; Ma, F.; Jin, Z.; Yuan, Y.; Xun, G.; Jha, K.; Su, L.; Gao, J. EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD 2018), London, UK, 19–23 August 2018; pp. 849–857. [Google Scholar] [CrossRef]
- Cui, L.; Wang, S.; Lee, D. SAME: Sentiment-Aware Multi-Modal Embedding for Detecting Fake News. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM, 2019), Vancouver, BC, Canada, 27–30 August 2019. [Google Scholar] [CrossRef]
- Singhal, S.; Shah, R.R.; Chakraborty, T.; Kumaraguru, P.; Satoh, S. SpotFake: A Multi-modal Framework for Fake News Detection. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 39–47. [Google Scholar]
- Khattar, D.; Goud, J.S.; Gupta, M.; Varma, V. MVAE: Multimodal Variational Autoencoder for Fake News Detection. In Proceedings of the The World Wide Web Conference (2019), San Francisco, CA, USA, 13–17 May 2019; pp. 2915–2921. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, J.; Zafarani, R. SAFE: Similarity-Aware Multi-Modal Fake News Detection. Adv. Knowl. Discov. Data Min. 2020, 12085, 354–367. [Google Scholar] [CrossRef]
- Chen, H.; Chang, C.; Shi, Z.; Lyu, Y. Hybrid features and semantic reinforcement network for image forgery detection. Multimed. Syst. 2022, 28, 363–374. [Google Scholar] [CrossRef]
- Singh, B.; Sharma, D.K. Predicting image credibility in fake news over social media using multi-modal approach. Neural Comput. Appl. 2021, 34, 21503–21517. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Chen, B.-C.; Han, X.; Najibi, M.; Shrivastava, A.; Lim, S.-N.; Davis, L. Generate, Segment, and Refine: Towards Generic Manipulation Segmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13058–13065. [Google Scholar] [CrossRef]
- Sharma, D.K.; Singh, B.; Agarwal, S.; Kim, H.; Sharma, R. Sarcasm Detection over Social Media Platforms Using Hybrid Auto-Encoder-Based Model. Electronics 2022, 11, 2844. [Google Scholar] [CrossRef]
- Salim, M.Z.; Abboud, A.J.; Yildirim, R. A Visual Cryptography-Based Watermarking Approach for the Detection and Localization of Image Forgery. Electronics 2022, 11, 136. [Google Scholar] [CrossRef]











| Methods | Feature Length | Feature |
|---|---|---|
| Fridrich et al. [22] | 64 | DCT |
| Popescu and Farid [23] | 32 | PCA |
| Li et al. [24] | 8 | DWT + SVD |
| Bayram, et al. [25] | 45 | FMT |
| Huang et al. [27] | 16 | Improved DCT |
| Mahmood et al. [31] | 10 | DCT and KPCA |
| S. No | Author | Detection Techniques | Dataset | Results | Pros | Cons |
|---|---|---|---|---|---|---|
| 1 | Li et al. [24] | DWT + SVD | Self-created Image set | Not provided | Can handle JPEG compression | Fails after 70 factors |
| 2 | Gul et al. [26] | SVD | 200 Images | 86% | Can handle scaling, rotation, and blurring | JPEG compression and contrast/brightness have low results |
| 3 | Li et al. [28] | Local Binary Pattern | 200 images from the Internet | Correct detection Ration ~0.9 | Can handle rotation, blurring, compression | Images rotated at general angles |
| 4 | Lee et al. [29] | Histogram of Oriented Gradients | CoMoFod | FC factor > 90% | Can handle small rotation, blurring, and contrast | High scaling and high rotation |
| 5 | Hussain et al. [30] | Multiscale Weber’s Law Descriptor MWLD | CASIA 1.0 CASIA 2.0 Columbia | Accuracy 92.08 95.70 94.17 | Can handle rotation, compression, noise | Cannot tell localization of tampered image |
| 6 | Alamro and Nooraini [16] | DWT + SURF | 50 Images from MICC-F2000 | 95% Accuracy | Good with geometric transformation | Not verified with compression and AWGN noise |
| 7 | Chen et al. [32] | FrQZMs | FAU and GRIP | F-Measure of 0.9533 over GRIP and 0.9392 over FAU | Can handle scaling and noise processing | Low results with rotation angles and JPEG compression |
| 8 | Tanaka et al. [35] | Robust Hashing | UADFV, CycleGan, StarGan | 0.83, 0.97, and 0.99 F-score | Can handle noise, compression, and resizing | Not verified on social media images |
| 9 | Gan, Zhang, Vong, [39] | SIFT with HSF algorithm | CMH and GRIP | F-Score 91.50 on CMH. 92.11 on GRIP | Work well on geometrical attacks and post-processing disturbances | Not verified on social media images |
| Methods | Feature Length | Feature |
|---|---|---|
| Wang et al. [43] | 100 | GLCM + BFS |
| Zhao et al. [44] | 60 | RLRN |
| He et al. [47] | 100 | SVM + RFE |
| Moghaddasi et al. [49] | 50 | SVD + DCT |
| Sheng et al. [50] | 972 | DOCT + Markov |
| Niyishaka and Bhagvati [54] | 768 | Illumination–Reflectance and LBP |
| S. No | Author | Detection Techniques | Dataset | Results | Pros | Cons |
|---|---|---|---|---|---|---|
| 1 | Zhao et al. [44] | Run-length run number (RLRN) | CASIA 1.0 Columbia | Accuracy 94.7% 85% | Works well in color and grayscale images | Not verified for any pre/post-processing over images |
| 2 | He et al. [47] | Markov features in the DWT and DCT domain | CASIA 1.0 Columbia | Accuracy 89.76% 93.55% | Works well for color and grayscale. | Gives lower accuracy over real-world images, more realistic images |
| 3 | Mazumdar and Bora [48] | Illumination-signature using DRM | DSO-1 DSI-1 | AUC 91.2% | Good performance for images with faces | Fails on images having sharp contrast skin-tones |
| 4 | Moghaddasi et al. [49] | SVD + DCT + PCA | Columbia | Accuracy 80.79% (No PCA) 98.78% (PCA) | Have excellent performance over grayscale images | Not verified for color images. Not verified with Pre/Post-processing |
| 5 | Sheng et al. [50] | Markov features of DOCT domain | CASIA 1.0 CASIA 2.0 | Accuracy 98.77% 97.59% | Can handle Gaussian blur and white Gaussian noise | Fails over small-size images |
| 6 | Jaiswal and Srivastava [51] | Machine learning—logistic regression | CASIA 1.0 CASIA 2.0 Columbia | Accuracy 98.3% 99.5% 98.8% | Can handle pre/post-processing alterations | Fails when images are highly down-sampled |
| 7 | Niyishaka and Bhagvati [54] | Illumination reflectance and LBP | CASIA 2.0 | Accuracy 94.59% | Can handle down-sampling and resizing | Fails over small size images and images with blurred background |
| 8 | Agarwal et al. [56] | RFFT image frequency transform | Columbia | Average Precision 0.918 | Can handle down-sampling and resizing | Fails over small-size images |
| Models | Tampering Method | Detection Method | Columbia | CASIA 1.0 | CASIA 2.0 |
|---|---|---|---|---|---|
| Hussain et al. [30] | Copy-and-Move | MultiWLD | 94.17% | 94.19% | 96.61% |
| Mahmood et al. [31] | Copy-and-Move | DCT+ KPCA | - | 92.62% | 96.52% |
| Wang et al. [43] | Image Splicing | GLCM + BFS | - | 90.50% | - |
| Zhao et al. [44] | Image Splicing | RLRN | 85.00% | 94.70% | - |
| He et al. [47] | Image Splicing | SVM + RFE | 93.55% | - | 89.76% |
| Moghaddasi et al. [49] | Image Splicing | SVD + DCT | 98.78% | - | - |
| Sheng et al. [50] | Image Splicing | DOCT + Markov | - | 98.77% | 97.59% |
| Jaiswal et al. [51] | Both | DWT + HOG+ LBP + ML | 98.80% | 98.30% | 99.50% |
| Method | Framework | MediaEval | |
|---|---|---|---|
| Khattar et al. [129] | att-RNN | 66.40 | 77.90 |
| Wang et al. [129] | EANN | 71.50 | 82.70 |
| Cui et al. [130] | SAME | 77.24 | 81.58 |
| Singhal et al. [131] | SpotFake | 77.77 | 89.23 |
| Khattar et al. [132] | MVAE | 74.50 | 82.40 |
| Zhou et al. [133] | SAFE | 87.40 | 83.80 |
| Singh and Sharma [135] | EfficientNet + BERT | 85.30 | 81.20 |
| Confusion Matrix | Actual Values | ||
|---|---|---|---|
| Positive | Negative | ||
| Predicted Value | Positive | True-Positive | False-Positive |
| Negative | False-Negative | True-Negative | |
| S. No. | Parameter Name | Formula | Description |
|---|---|---|---|
| 1 | Precision (P) | P = TP/(TP + FP) | Measure shown to correct model was in classifying positives. |
| 2 | Recall (R) | R = TP/(TP + FN) | Measures how many positives are missed by model. Also called sensitivity or Total Positive Rate (TPR). |
| 3 | Accuracy (A) | A = (TP + TN)/ (TP + TN + FP + FN) | Measures how accurately model classifies correctly. |
| 4 | F1 (F1) | F1 = 2(PXR)/(P + R) | Measures the harmonic mean of Precision and Recall. |
| 5 | False-Positive Rate | FPR = FP/FP + TN | Measure how many negatives are classified as positive. Probability of false alarms. Also called Fallout. |
| 6 | False-Negative Rate | FNR = FN/TP + FN | Measures miss rate. |
| 7 | Half-Total Error Rate (HTER) | HTER = FPR + FNR/2 | Average of FPR and FNR. |
| 8 | ROC | Receiver Operating Characteristic plot is used to visualize the performance of a classifier. It is a two-dimensional curve for depicting the system’s characteristics. | |
| 9 | AUROC | The area under ROC measures the entire area under the ROC curve. It is a total measure of performance across all possible classification thresholds. | |
| 10 | mPA | Mean Average Precision is the average of AP. AP is the area under the Precision-Recall curve. | |
| S. No | Data Set | Year | Type | Source | Real Images | Fake Images | Location | Accessed on |
|---|---|---|---|---|---|---|---|---|
| 1 | Buzzfeed | 2018 | Images, Text | Buzzfeed News | 90 | 80 | https://github.com/BuzzFeedNews/2017-12-fake-news-top-50 | 19 February 2019 |
| 2 | CASIA1.0 | 2013 | Images | Self made Database | 800 | 921 | http://forensics.idealtest.org/ | 16 March 2019 |
| 3 | CASIA2.0 | 2013 | Images | Self made Database | 7200 | 5123 | http://forensics.idealtest.org/ | 16 March 2019 |
| 4 | CelebA | 2015 | Images | Self made Database | 2,00,000 | _ | https://github.com/tkarras/progressive_growing_of_gans | 6 August 2018 |
| 5 | COCO | 2008 | Images | Flickr | 500 | 229 | http://lear.inrialpes.fr/people/jegou/data.php | 14 February 2016 |
| 6 | COLUMBIA | 2004 | Images | CalPhotos | 933 | 912 | http://www.ee.columbia.edu/ln/dvmm/downloads/AuthSplicedDataSet/dlform.html | 28 April 2019 |
| 7 | CoMoFoD | 2004 | Images | Self-made Dataset (Tralic and Grgic) | 260 | 13,520 | https://www.vcl.fer.hr/comofod/comofod.html | 4 June 2020 |
| 8 | FAKENEWSNET | 2018 | Image, Text | 447 | 336 | https://github.com/KaiDMML/FakeNewsNet/tree/master/dataset | 7 September 2020 | |
| 9 | FNC | 2018 | Images, Text | Kaggle | _ | _ | https://www.kaggle.com/c/fake-news/data | 7 September 2020 |
| 10 | MediaEval 2015 | 2015 | Images, Text | 193 | 218 | https://github.com/MKLab-ITI/image-verification-corpus/tree/master/mediaeval2015 | 16 March 2019 | |
| 11 | NIST Nimble 16 | 2017 | Images | Self-made database (NIST) | _ | 10,000 | https://www.nist.gov/itl/iad/mig/media-forensics-challenge | 22 August 2019 |
| 12 | PGGAN | 2016 | Images | GAN generated | _ | 1,00,000 | https://github.com/tkarras/progressive_growing_of_gans | 6 July 2019 |
| 13 | PHEME | 2016 | Text | _ | _ | https://figshare.com/articles/PHEME_dataset_for_Rumour_DetectionandVeracityClassification/6392078 | 5 September 2019 | |
| 14 | 2016 | Images, Text | Sina Weibo | 3774 | 1363 | https://drive.google.com/file/d/14LXJ5FCEcN2QrVWHYkKEYDpzluT2XNhw/view | 26 December 2019 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, D.K.; Singh, B.; Agarwal, S.; Garg, L.; Kim, C.; Jung, K.-H. A Survey of Detection and Mitigation for Fake Images on Social Media Platforms. Appl. Sci. 2023, 13, 10980. https://doi.org/10.3390/app131910980
Sharma DK, Singh B, Agarwal S, Garg L, Kim C, Jung K-H. A Survey of Detection and Mitigation for Fake Images on Social Media Platforms. Applied Sciences. 2023; 13(19):10980. https://doi.org/10.3390/app131910980
Chicago/Turabian StyleSharma, Dilip Kumar, Bhuvanesh Singh, Saurabh Agarwal, Lalit Garg, Cheonshik Kim, and Ki-Hyun Jung. 2023. "A Survey of Detection and Mitigation for Fake Images on Social Media Platforms" Applied Sciences 13, no. 19: 10980. https://doi.org/10.3390/app131910980
APA StyleSharma, D. K., Singh, B., Agarwal, S., Garg, L., Kim, C., & Jung, K.-H. (2023). A Survey of Detection and Mitigation for Fake Images on Social Media Platforms. Applied Sciences, 13(19), 10980. https://doi.org/10.3390/app131910980