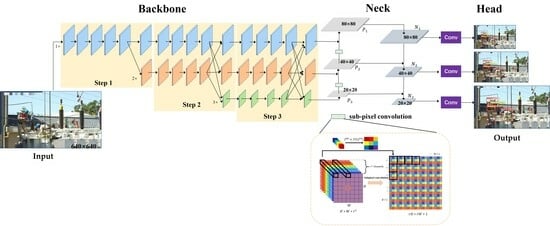
3.4.1. Model Training
The training loss is an important metric during the model training process as it reflects the optimization performance of the model. We compared the training loss curves of the HS-YOLO and the original YOLOv5, as shown in
Figure 6.
The training loss of the original YOLOv5 is depicted by the blue curve, whereas the training loss of the HS-YOLO is indicated by the orange curve. As shown in
Figure 6a, the training loss of HS-YOLO is lower than that of the unchanged YOLOv5. From
Figure 6b–d, we can observe that HS-YOLO exhibits lower losses across different categories compared to the original YOLOv5. Moreover, the losses are steadily decreasing, indicating that the model is gradually converging, and its performance is improving.
The newly added HRNet and sub-pixel convolution for small object detection offer several advantages, including enhanced spatial information and finer feature representation. These advantages aid the network in capturing object features and positions more effectively, resulting in reduced losses, accelerated convergence, and enhanced training efficiency.
3.4.2. Ablation Experiment
To assess the efficacy of the improvements introduced in the HS-YOLO algorithm for small object detection, ablation experiments were performed on each enhancement point using the created dataset of power operation scenes. The results are shown in
Table 2. In the table, Experiment ① represents the results of the original YOLOv5 model. “A” indicates the improvement of using the HRNet network as the backbone, while “B” represents the improvement of using sub-pixel convolution as the upsampling operator in the feature fusion network.
Comparing Experiment ②, Experiment ③, and Experiment ④ with the original YOLOv5 network, we can observe that using the HRNet feature extraction backbone network only sacrifices 1% of the detection accuracy while improving the detection recall by 4.1%. Introducing sub-pixel convolution in the Neck leads to a 2% increase in detection accuracy and a 3.1% increase in detection recall. When the original network is improved using HRNet and sub-pixel convolution at the same time, the detection accuracy is improved by 1%, and the detection recall is improved by 3.9%. This indicates that the algorithm can identify objects more accurately and comprehensively, reducing false detections and missed detections.
HRNet’s multi-scale features enable a more comprehensive capture of object contextual information, while sub-pixel convolution upsampling can restore finer spatial details. This aids in reducing false detections and missed detections caused by background interference or blurring. HRNet is more complex than the original backbone network, the introduction of HRNet will bring relatively high computational costs. However, we can observe that improving model detection performance only sacrifices a small amount of FPS. In high-risk power operation scenarios, detection accuracy often takes precedence over speed.
The experiments in
Table 3 show that when HRNet is used to improve the backbone network, only the AP of the Fence category decreases by 3.4%. Other objects showed slight improvements, and objects with consistently small proportions saw significant improvements in AP, with increases of 2.3%, 4.3%, and 11.8% for different objects. The mAP improved by 2.7% compared to before the improvement. After adding sub-pixel convolution to the original network, only the AP of the Human object slightly decreased, while other object categories showed varying degrees of improvement in AP. The mAP improved by 1% compared to before the improvement. When both HRNet and sub-pixel convolution were added to the network, the mAP reached 87.2%, a 3.5% improvement over the original network. There were improvements in AP for all seven object categories, with significant improvements of 4.4%, 5.8%, and 10.7% for the Safetybelt, Noneckline, and Nocuff objects, respectively. This validates that HS-YOLO can be applied to detection tasks in the context of power operation scenarios.
3.4.3. Comparative Experiments
To affirm the dependability of the HS-YOLO network as proposed, we partitioned the training process into three stages, each spanning 100 epochs. Within each stage, we randomly selected an epoch and conducted a comparative evaluation of detection performance between the baseline YOLOv5 network and the HS-YOLO network we proposed.
We selected the 100th epoch, 200th epoch, and 300th epoch for the comparative analysis of the three training stages. As shown in
Table 4, after the first stage of training, both the YOLOv5 and HS-YOLO networks achieved near-optimal levels of AP for detecting Human, Hat, Seine, and Fence in the dataset, with little difference between them. However, for the Safetybelt, Noneckline, and Nocuff classes (all of which are all small objects), the AP can be greatly improved.
In the Epoch 100 experiment, both HS-YOLO and YOLOv5 had lower maps, but HS-YOLO outperformed YOLOv5 with a 5.2% higher mAP. Specifically, Noneckline and Nocuff categories had significantly improved AP, with increases of 10.3% and 24%, respectively. By the 200th epoch, after sufficient training, both HS-YOLO and YOLOv5 achieved high mAP values. However, HS-YOLO had a higher mAP of 83.4%, surpassing YOLOv5 by 5.3%. Notably, the Safetybelt, Noneckline, and Nocuff categories exhibited improved AP, with gains of 5.2%, 10.6%, and 19.8%, respectively. In the 300th epoch, HS-YOLO maintained its superiority with a 2.8% higher mAP than YOLOv5. Moreover, the Safetybelt, Noneckline, and Nocuff categories showed AP improvements of 3.8%, 3.7%, and 9.4%, respectively. Throughout the entire training stage, our proposed HS-YOLO consistently outperformed YOLOv5 in detecting various objects in the power operation scenarios, especially small objects.
HRNet processes images using a multi-resolution approach and is able to capture multi-scale features, which helps to retain details of small objects and provide richer feature representations. Sub-pixel convolution performs finer upsampling on the feature, and aids in achieving more precise object boundary localization. This significantly enhances the precision of detection, enabling the detection model to precisely recognize and pinpoint small objects.
To further evaluate the HS-YOLO algorithm, we conducted experiments on the power operation scene dataset and compared it with other classic algorithms.
The results in
Table 5 demonstrate that our proposed HS-YOLO achieves higher AP for various object categories in the power operation scene compared to the original network and other classical networks. The mAP also shows significant improvement, with a 3.5% increase compared to the original network and a 13.5% increase compared to SSD. Particularly, there is a significant improvement in AP for small objects that are prone to be missed in the electric power operation scene, such as Safetybelt, Noneckline, and Nocuff categories. Even when compared to the latest YOLOv8, HS-YOLO exhibits similar detection accuracy on four large objects of Human, Hat, Seine, and Fence. Moreover, it shows varying degrees of improvement in the detection of three small objects of Safetybelt, Noneckline, and Nocuff, with respective increases in AP of 1.7%, 2.5%, and 4.3%. This demonstrates that our proposed HS-YOLO, when applied to the electric power operation scene, not only maintains high detection accuracy for large and medium-sized objects but also greatly improves it for small objects.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}