1. Introduction
Text classification [
1,
2] is a fundamental and crucial part of the NLP community. With the growth of deep neural networks, researchers have begun to focus on how to extend good classification performance to scenarios with only a small amount of labeled data.
Inspired by the advances of few-shot learning in CV [
3,
4], many studies [
5,
6] have leveraged the meta-learning based framework to tackle few-shot text classification (FSTC). Ohashi et al. [
7] proposed a self-attention based encoder and a mutual information based loss function to obtain high-quality prototype representation. Sun et al. [
8] proposed a data augmentation algorithm, which randomly generates instances within the smallest enclosing ball, to promote meta-learning methods. Unlike methods that learn directly from words, Bao et al. [
9] proposed DS-FSL, which learns word importance via distributional signatures of texts. Distributional signatures mean characteristics of text distribution. A well-known instance of using these signatures is TF-IDF, which models the weights of words by their frequencies—a kind of explicit distributional signatures. These characteristics of text distribution imply underlying semantic knowledge, and their behaviors are consistent across classes. Bao et al. [
9] suggest that learning from distributional signature is much more effective to generalize across different classes than directly learning from words.
However, the above approaches follow the in-domain setting. This setting assumes that the meta-training and meta-testing data are in the same data distribution, which is not feasible in real-world applications. Consequently, some researchers have begun to extend FSTC to a cross-domain setting. Zhang et al. [
10] presented cross-domain few-shot text classification (CD-FSTC). In CD-FSTC, meta-training is conducted on one dataset in a single domain, and meta-testing on another in a different domain. Wang et al. [
11] supposed that a meta-training dataset with only a single domain in CD-FSTC limits the generalization ability of the model, and proposed domain-generalized few-shot text classification (DG-FSTC). DG-FSTC replaces the single-domain dataset with a multi-domain dataset as the base dataset for meta-training. The meta-learning framework enables models to learn how to learn across different domains. Compared with conventional FSTC and CD-FSTC, DG-FSTC effectively improves the domain adaptability of the model, and is much closer to real application scenarios.
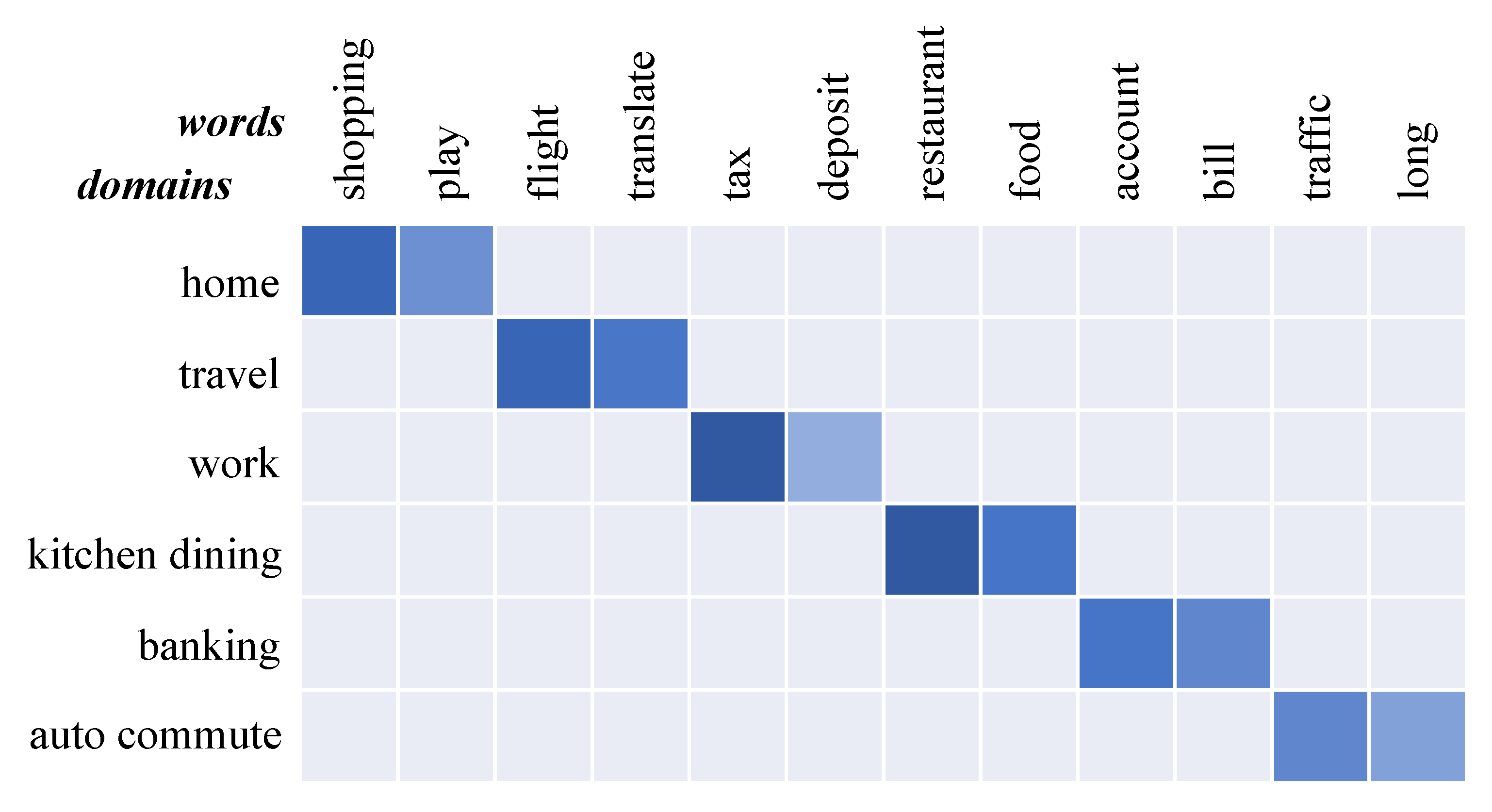
Currently, the DG-FSTC problem is still challenging for previous FSTC methods. Directly applying the FSTC methods to DG-FSTC will inevitably suffer from performance degradation. This is because the feature distribution changes significantly as the domain varies. The distribution variation makes those methods that learn directly from words struggle to capture discriminative features in specific domains under a domain shift. Therefore, we attempt to enhance the domain adaptability of the model by utilizing features that reflect specific domain information, such as distributional signatures. We find that in multi-domain data, the distributional signatures of different domains are highly domain-related. As shown in
Figure 1, we utilize word frequency, an explicit distributional signature, to estimate word importance. The results show that, in a specific domain, the most informative words are highly domain-related. For instance, in travel domain, ‘flight’ and ‘translate’ are two of the most informative words. In a nutshell, the distributional signatures of texts are solid and annotation-free to reflect the word importance in specific domains.
Consequently, this study introduces the distributional signature to solve DG-FSTC problem and propose a model based on Multi-level Distributional Signatures, namely MultiDS. MultiDS utilizes hierarchical distributional signatures to generate knowledge from three aspects, which are domain-agnostic, domain-specific, and class-specific, to improve the classification performance of the model under domain shift. Firstly, we argue that even textual representations of different domains have a kind of general and domain-agnostic features. Inspired by pretrained language models, we compute distributional signatures on a large news dataset containing information from multiple domains. The computed distributional signatures are used as the domain-agnostic features. Secondly, since the distributional signatures of different domains indicate specific domain information, we compute distributional signatures from texts of the same domain in each episode. These distributional signatures are treated as the domain-specific features. Thirdly, distributional signatures of different categories also show class-level differences, which can be used to model class-level word importance. In each episode, we calculate the distributional signatures of each class as class-specific features. After obtaining multi-level distributional signatures, we apply neural networks to translate them into word-level attention weights, which is able to help the model focus on informative features in different domains. In addition to utilizing distributional signatures to generate word importance, information indicated by distributional signatures are also beneficial in correcting feature distributions of different domains. Concretely, we think that domain-specific distributional signatures are also beneficial for neural networks to fit the feature distribution of specific domains. Therefore, we fuse domain-specific distributional signatures and word embeddings to generate instance-level calibration vectors. These calibration vectors effectively enable the model to adapt to different feature distributions. MultiDS thus obtains strong domain adaptability based on multi-level distributional signatures.
In summary, the main contributions of this study are as follows:
We propose a simple yet powerful method based on multi-level distributional signatures to produce high-quality word-level attention values under domain shift. A large news corpus is firstly used to calculate domain-agnostic distributional signatures. Secondly, we compute domain-specific and class-specific distributional signatures from texts of the same domain and category, respectively. As a result, domain-adaptive word-level attentions are derived by translating multi-level distributional signatures using deep neural networks;
We propose a domain calibration method based on domain-specific distributional signatures. By modeling the domain information indicated by domain-specific distributional signatures, the calibration method generates instance-level calibration vectors that are used to help the model fit the feature distributions of specific domains;
We conduct extensive experiments on four datasets. The experimental results illustrate that our method outperforms the state-of-the-art method in DG-FSTC by 1.41% on average. Our method achieves the best average performance compared to five competitive baseline methods. Compared with DS-FSL [
9], our method achieves an average improvement of 4.79%.
3. Problem Definition
In this work, we focus on the DG-FSTC setting to solve few-shot problems. In DG-FSTC, models are meta-trained on a multi-domain dataset
.
A is the numbers of domains. In each episode during meta-training, an N-way-K-shot task is sampled from a random domain. Each sampled task
contains data from
N classes and each class contains
sentences, Then
t is divided into support set
and query set
. The goal in each episode is to classify the unlabeled query set using the labeled support set. The model is updated by minimizing the following objective, as shown in Equation (
1),
where
is the parameter of the model;
denotes the probability of query set sample
belonging to label
and
is the cross entropy loss. After meta-training, models are meta-tested on the dataset
with single or multiple domains. DG-FSTC expects that the models can learn transferable meta-knowledge on multi-domain datasets, then generalize to emerging classes from unseen domains. The notations in this study are listed in
Table 1.
4. MultiDS Model
The main idea of this study is to empower DG-FSTC by introducing multi-level distributional signatures, which indicate rich and hierarchical information. To take full advantage of the power of distributional signatures, in our method, we mainly propose the following two modules.
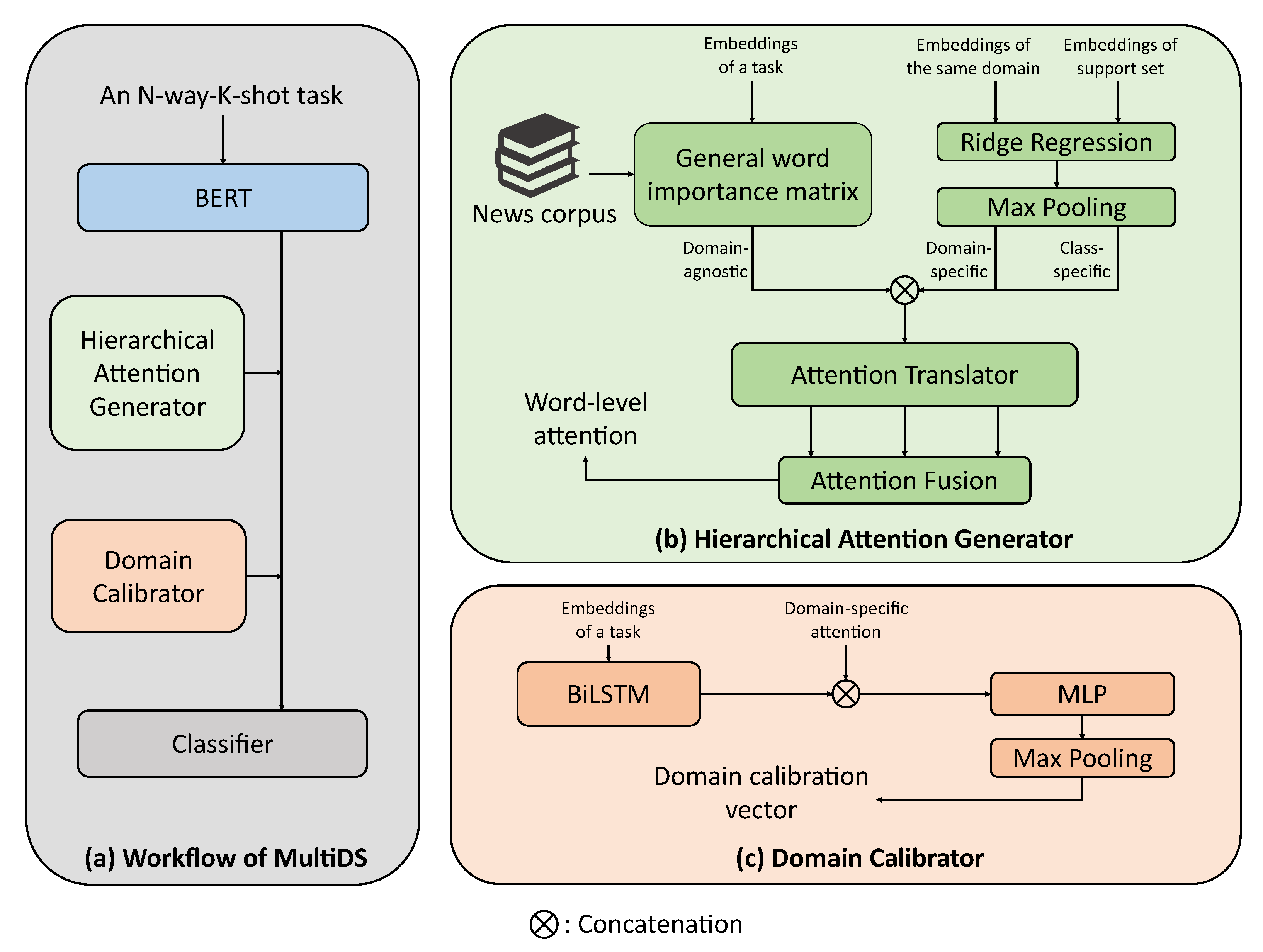
Hierarchical attention generator via multi-level distributional signatures (
Section 4.2): We utilize three levels of distributional signatures, which are domain-agnostic, domain-specific, and class-specific, to approximate hierarchical word importance. To denoise distributional signatures and get more accurate attentions, this generator is devised to translate different levels of distributional signatures into word-level attention weights;
Domain calibrator via domain-specific information (
Section 4.3): In addition to accessing word importance, a domain calibrator is applied to calibrate sentence-level feature representations. By generating calibration vectors using domain-related information, this calibrator guides the model to adapt to specific domain distributions.
Overview: As illustrated in
Figure 2, our method is divided into following steps: (1) we construct word embeddings by pretrained language model, BERT, in
Section 4.1; (2) we calculate multi-level distributional signatures, and convert them to word-level attentions by hierarchical attention generator in
Section 4.2; (3) we calibrate the feature representations by generating calibration vectors from domain-specific distributional signatures in
Section 4.3; (4) we apply a ridge regressor as the classifier to categorize query samples in
Section 4.4.
4.1. Text Encoder
In our work, we choose BERT [
22] as the text encoder for its formidable semantic representation. Due to pre-training on massive data, BERT excels at expressing and understanding textual information. Given an input sequence
, the word embedding is derived according to Equation (
2),
where
l denotes the length of the sequence and
is the dimension of BERT embedding.
4.2. Hierarchical Attention Generator via Multi-Level Distributional Signatures
In order to facilitate model’s adaptation to various domains, we propose to utilize multi-level distributional signatures to generate hierarchical and domain-adaptive attentions. We find that different levels of distributional signatures exhibit hierarchical characteristics. A well-known point in recent years is that there are some general semantic features that can also be used to process other data, such as applying a pretrained model to downstream tasks. Consequently, we propose domain-agnostic attention, which can be transferred to various domains. Besides, distributional signatures in the same domain or category also contain rich semantic information. A good example is the phenomenon that the word frequency of data in the same domain shows unique characteristics that are relevant to that domain information. Similarly, data from the same category shows characteristics specific to that category. Based on the above phenomenons, we propose domain-specific attention and class-specific attention to help the model understand discriminative information at the domain- and class-level. In addition, to fuse three different levels of attentions and reduce informative redundancy, an attention fusion module is devised.
4.2.1. Domain-Agnostic Attention
Inspired by the paradigm of applying pre-trained models to downstream tasks, we believe that distributional signatures computed from large amounts of data can also be transferred to specific domains as domain-independent features. Specifically, we use a document-level news dataset, 20 Newsgroups [
23], to calculate domain-agnostic distributional signatures. As shown in
Table 2, 20 Newsgroups contains news articles from 6 domains, roughly including computers, recreation, science, politics, religion, and for-sale. This multi-domain document-level dataset enables the model to obtain general distributional signatures without domain bias.
Here, we leverage explicit distributional signatures, which mean word frequency, to infer word weights. The frequency of words appearing in documents is a kind of natural and annotation-free feature that effectively implies words importance in low-resource scenarios. For instance, frequently used words such as ’the’, ’a’, etc., are often considered less important, while those that rarely appear often contain more discriminative information.
Firstly, given a word sequence
in 20 Newsgroups, our approach is to utilize an existing method [
13] to make a rough estimate of word weights via word frequency in Equation (
3),
where
is the unigram likelihood of the
i-th word over the dataset;
is a hyperparameter;
represents the noisy weight of the
i-th word.
represents a mapping from words (within vocabulary) to their corresponding weights. According to the above hypothesis, the
computed from a large document-level dataset contains generalized semantic knowledge that can be applied to the processing of other texts.
As the second step, we devise an attention translator that translates coarse word weights into fine-grained word-level attentions. Our attention translator consists of two components, a multi-layer perceptron (MLP) and a bidirectional LSTM (BiLSTM). Given an input sequence
, the MLP projects coarse word weights into a higher-dimensional space in Equation (
4). Weights with higher dimensions contain richer semantic information.
where
,
are weight and bias of the MLP;
are higher-dimensional word weights, and
means weight of the
i-th word
. Since each word weight is contextually affected, we employ a BiLSTM, which is adept at processing sequence information, to further encode these weights in Equations (
5)–(
7), so that each word weight implies the correlation between contextual information.
The bidirectional hidden states
and
are calculated by Equations (
5) and (
6) using coarse word weights, respectively. Equation (
7) concatenates two hidden states to get domain-agnostic attentions.
4.2.2. Domain-Specific Attention
In addition to domain-agnostic features, we are convinced that domain-related information is essential to guide the model in adapting to different domains. Since each N-way-K-shot task in DG-FSTC comes from a random domain, we propose to utilize the distributional signatures of each task to calculate domain-related information. However, each N-way-K-shot task contains only a small amount of data, and it is highly inaccurate to derive domain-related information using the word frequency of each small task. Consequently, we utilize a new policy to learn from distributional signatures. On the one hand, to capture more discriminative features with limited data, ridge regression is introduced, as shown in Equations (
8) and (
9), which admits a closed-form solution. On the other hand, we choose implicit distributional signatures, word embeddings, to infer word weights, which is more robust than explicit distributional signatures in low-resource scenarios. Given word sequences for an N-way-K-shot task
as well their BERT embeddings
, we derive the noisy attentions, which indicate domain information, below.
where
is a hyperparameter;
I denotes the identity matrix;
means the one-hot labels of
. In Equation (
8), domain-specific features are extracted from texts of the same domain using ridge regression. Equation (
9) derives noisy attentions by performing the multiplication of word embeddings with the weight matrix and calculating the most significant features in the product.
After that, we utilize our attention translator to produce accurate domain-specific attentions in Equations (
10) and (
11). According to Equation (
10), the MLP is employed to project noisy attentions
into higher-dimensional space.
where
denote word weights with higher-dimension. According to Equation (
11), we derive the domain-specific attentions after encoded by BiLSTM.
4.2.3. Class-Specific Attention
Apart from general semantic information and domain-specific information, class-specific information can also enhance the classification performance of models on multi-domain data. Unlike the way domain-specific information is processed, we calculate class-specific information using the support set in an N-way-K-shot task. It is considered that class-specific features extracted from the support set are applicable to the query set of the same task.
Given the support set in an N-way-K-shot task
and its BERT embeddings
, the class-specific features are derived utilizing the ridge regression in Equation (
12). The coarse attentions are obtained in Equation (
13) by computing the most significant information in the product of class-specific features and word embeddings.
where
is a trainable parameter and
denotes the one-hot labels of
.
Similarly, we use an MLP to project coarse attentions into higher-dimensional space and get word weights
in Equation (
14). In Equation (
15), a BiLSTM is utilized to encode word weights into class-specific attentions.
4.2.4. Attention Fusion
After obtaining hierarchical attention weights, we design a neural module to fuse different levels of attentions. Due to the informative redundancy between different levels of attentions, simply concatenating them will harm the effect of hierarchical attentions. To alleviate the informative redundancy between different levels of attentions, consequently, an MLP is firstly employed to extract discriminative features from the concatenated multi-level attentions in Equation (
16).
where
and
mean the weight and bias of the MLP.
We then use softmax function to convert attention features into word-level attention scores in Equation (
17).
Given a word sequence in an N-way-K-shot task
w as well its word embeddings
, we construct the sentence representation via word-level attentions in Equation (
18).
4.3. Domain Calibrator via Domain-Specific Information
In addition to deriving word importance from distributional signatures, we also focus on applying domain-specific distributional signatures to help the models adapt to specific feature distributions. In DG-FSTC, as each task comes from a different feature distribution, it is imperative for models to adapt effectively to various distributions. We propose to leverage features that indicate domain information, which are domain-specific distributional signatures and word embeddings, to calibrate feature distribution. Domain-specific attentions are regarded as features calculated from domain-specific distributional signatures. Besides, given a sequence in an N-way-K-shot task
w and the embeddings
e, we extract deep domain features from word embeddings of the same task by a BiLSTM in Equation (
19).
An MLP is then employed to fuse these two types of domain information, the domain features and domain-specific attentions, in Equation (
20). We choose the most significant features from the fused results as the sentence-level calibration vectors.
where
and
are the weight and bias of the MLP.
Finally, we enhance the sentence representation via the calibration vectors and derive the final representation in Equation (
21).
4.4. Ridge Regression Classifier
Here, we also use ridge regression [
24] as a classification function due to its superiority in preventing overfitting. We let the final representation of the support set and query set be
and
, which are processed by hierarchical attentions and calibration vectors.
Firstly, we train the ridge regression with the annotated support set in Equation (
22).
where
is a trainable parameter, and
represents the one-hot label of the support set.
Secondly, as shown in Equation (
23), the classifier is optimized by the following regularized squared loss.
where
denotes Frobenius norm.
Thirdly, the well-trained classifier is applied to categorize the query set samples. The classification loss based on cross entropy is derived in Equation (
24).
where
represents the cross entropy function;
and
are trainable parameters;
means the true label of the query set.
The training procedure of MultiDS is concluded in Algorithm 1.
| Algorithm 1:The training procedure of MultiDS |
- Require:
Model parameter ; Meta-training episode ; Dataset for meta-training ; Number of class N; Number of instance for each class in support set K; Number of instance for each class in query set Q; An N-way-K-shot task ; Precomputed general word importance matrix ; - Ensure:
Trained model parameter ; - 1:
Randomly initialize model parameter ; - 2:
for each do - 3:
Randomly sample an N-way-K-shot task from ; - 4:
Compute BERT embeddings of t by Equation ( 2); - 5:
Compute domain-agnostic attentions via general word importance matrix in Equations ( 4)–( 7); - 6:
Compute domain-specific attentions by Equations ( 8)–( 11); - 7:
Compute class-specific attentions by Equations ( 12)–( 15); - 8:
Fuse three kinds of attentions and derive hierarchical attentions by Equations ( 16) and ( 17); - 9:
Construct domain calibration vector via word embeddings and domain-specific attentions by Equations ( 19) and ( 20); - 10:
Train the classifier with support set , and classify query set instance by Equations ( 22)–( 24); - 11:
Update by minimizing classification loss in Equation ( 24); - 12:
end for
|
5. Experiments
In this section, we evaluate the effectiveness of our proposed method through comprehensive experiments. In
Section 5.1, we firstly detail the setup of the experiments, including the datasets we choose, the baselines for comparison, and the details of the implementation. Secondly, we present the results of our method compared to multiple baselines on several datasets, and draw conclusions based on the experimental results in
Section 5.2. Thirdly, ablation studies are conducted to explore the effectiveness and importance of key modules in our model in
Section 5.3. Fourthly, we verify the stability of our method in more N-way-K-shot settings in
Section 5.4. Finally, we present the computational overhead analysis for all methods in
Section 5.5.
5.1. Experimental Setup
5.1.1. Datasets
We select the following five public datasets for the experiments.
Clinc150 [
12] is a multi-domain dataset for intent detection. It contains a total of 22,500 sentences from 10 domains. Each domain contains 150 classes;
Banking77 [
25] is a single-domain dataset with 77 fine-grained categories. These categories all belong to the banking domain;
Huffpost [
26] contains news headlines published on HuffPost from the year 2012 to 2018. These headlines cover a wide range of news varieties;
Hwu64 [
27] is also a multi-domain dataset, which contains fine-grained intents from 21 domains;
Liu57 [
27] contains 54 imbalanced categories. It brings challenges for models to reduce overfitting on major categories.
Details of the above datasets are shown in
Table 3.
In DG-FSTC, we use a multi-domain dataset, Clinc150, for meta-training. The other different types of datasets are used to evaluate model performance. For instance, Clinc→Huffpost denotes meta-training on Clinc150 and meta-testing on Huffpost.
5.1.2. Baselines
In order to demonstrate the effectiveness of MultiDS, we select five competitive approaches as baselines to compare with the proposed method.
ProtoNet [
4]: This algorithm is a strong baseline for meta-learning based methods. ProtoNet proposes to average samples of the same class to obtain class center. It classifies samples based on distances between each class center and samples in feature space;
HATT [
28]: This model improves ProtoNet by a two-step attention mechanism, which is composed by feature-level and instance-level attentions. Feature-level attention focuses on more informative features. Instance-level attention assigns different weights to instances according to their significance;
DS-FSL [
9]: This approach firstly introduces distributional signatures into few-shot learning. It proposes to utilize precomputed distributional signatures as word weights and constantly update them to fit different data;
MLADA [
29]: This method combines adversarial learning with few-shot learning to solve the cross-domain problem in few-shot learning. The core idea is to produce knowledge by a generator to enhance the domain adaptability;
DualAN [
11]: This method is an improved version of MLADA. It enhances adversarial learning by introducing high-quality and stable data. These data come from two N-way-K-shot tasks from different domains.
5.1.3. Implementation Details
Parameter settings for model training and network architecture are given in
Table 4. We choose the BERT-base-uncased version released by Hugging Face (
https://huggingface.co/ accessed on 27 December 2017) as the BERT encoder. We replace word embeddings of all baselines with BERT embedding for fair comparison. For the implementation of ProtoNet, we employ a CNN with a global max-pooling after the BERT encoder.
For the meta-learning setup, we sample 5000, 1000 random tasks for meta-training and meta-testing. During meta-training, we meta-validate the model every 100 episodes with 100 tasks randomly sampled. We implement early stopping when the accuracy of 20 consecutive meta-validations do not improve. We select Adam [
30] as the optimizer. The experiments are conducted on a single Geforce RTX 3090 GPU.
5.2. Experimental Results and Analysis
The experimental results of all methods on four dataset are shown in
Table 5. Based on the above results, we get the following four observations.
Our propose method exceeds all baseline methods in most datasets and settings. Compared to the second best methods, MultiDS achieves an average improvement of 2.69%. Compared to the five baseline methods, MultiDS outperforms them by 11.03% in Clinc→Banking, 4.38% in Clinc→Huffpost, 4.38% in Clinc→Hwu and 6.19% in Clinc→Liu on average. These above results illustrate the effectiveness and superiority of MultiDS.
Our proposed approach is able to surpass DS-FSL in all datasets and settings, improving by an average of 4.79%. This indicates that, compared to DS-FSL, the hierarchical attention generator we propose has better domain generalization and adaptability. The main reason is that MultiDS uses higher quality domain-agnostic attention and domain-specific attention that can constantly adapt to new domains.
Our proposed method outperforms adversarial learning based methods (MLADA, DualAN) in most cases, with an average lead of 2.71%. The main reason is that, in the few-shot scenario, it may be more accurate to directly use distributional signatures (such as word frequency) to derive word weights than adversarial training. A small amount of labeled data limits the effectiveness of adversarial training.
The average performance of adversarial learning based approaches (MLADA, DualAN) is superior to that of prototypical network based approaches (ProtoNet, HATT). Adversarial learning based methods are able to learn domain adaptability through adversarial training. However, when processing multi-domain data, the prototypical network based method lacks the ability to adapt to different domains, resulting in the generation of poor-quality class centers, which ultimately leads to the degradation of model performance.
5.3. Ablation Study
Here, to verify the effectiveness of each key module, we present the following variants of MultiDS.
: MultiDS without hierarchical attention;
: MultiDS without domain-agnostic attention in hierarchical attention generator;
: MultiDS without domain-specific attention in hierarchical attention generator;
: MultiDS without class-specific attention in hierarchical attention generator.
: MultiDS without domain calibration vector;
: MultiDS without domain features in domain calibrator;
: MultiDS without domain-specific attention in domain calibrator.
The experimental results are shown in
Table 6. Based on the above results, we come to the following conclusions. (1) The effect of hierarchical attention is significant. When it is removed, model performance decreases by an average of 12.27%. This proves the effectiveness of hierarchical attention. (2) By removing domain-agnostic attention, model performance decreases by an average of 3.01%. We believe the reason is that the distributional signatures calculated from 20 Newsgroups contain high-quality knowledge of general semantics. This knowledge covers multiple domains with small domain biases and is therefore beneficial for processing information in different domains. (3) Domain-specific attention and class-specific attention also improve model performance. Besides, due to the relatively small number of domain information and class information in few-shot scenarios, the power of distributional signatures is limited. (4) Domain calibration vector is beneficial to model performance, and the average improvements is 0.35%. It proves that domain calibrator can extract informative features from domain information and domain-specific attention to calibrate domain distributions.
5.4. Model Stability Verification in More Scenarios
Here we conduct extensive experiments to explore the performance and stability of models in more scenarios. The experimental results shown in
Table 7 and
Table 8 illustrate the stability of our proposed model, which outperforms DS-FSL and DualAN in most cases. In addition, we have two more discoveries. (1) When K is fixed and N increases, more categories will increase the difficulty of classification. This requires the model to extract class-specific features to distinguish them from other categories. MultiDS outperforms other methods in most cases, indicating that MultiDS has better feature extraction capabilities. (2) When N is fixed and K increases, the challenge for the models is to focus effectively on crucial category information. Our model, which learns attention from distributional signatures, is better able to generalize in the classification task than those learning from words. MultiDS outperforms other methods in all scenarios, which proves the effectiveness of our hierarchical attention.
5.5. Computational Overhead Analysis
In addition to model performance, we also focus on the computational overhead of models. As shown in
Table 9, we compare the computational time, including the time for meta-training and meta-testing, of all the methods. The results show that the total time of our method is less than that of four baseline methods, and is just a little longer than the total time of DS-FSL. Compared with DS-FSL, our method is able to significantly improve model performance with only a small increase in computational cost. This proves that our model design is reasonable and effective. Besides, our method shows a short inference time, which makes MultiDS valuable in real-world application scenarios.
7. Conclusions
In this study, we propose a multi-level distributional signatures based model, MultiDS, to solve DG-FSTC problem. Firstly, we propose a hierarchical attention generator to translate multi-level distributional signatures into high-quality word-level attentions. We utilize a large news corpus to derive domain-agnostic attention. We extract domain-specific attention and class-specific attention from domain-related and class-related information using ridge regression and attention translator. Secondly, we propose a domain calibrator that uses domain features and domain-specific attention to generate domain calibration vectors. Experimental results show that our method achieves the best average performance on four testing datasets. The effectiveness of each module is verified by ablation experiments. In model stability validation, our model can exceed the baseline method in most cases. In the future, we will try to design better ways to use distributional signatures, not just word frequency.


 ,
, 


{kind=link}
{kind=link}