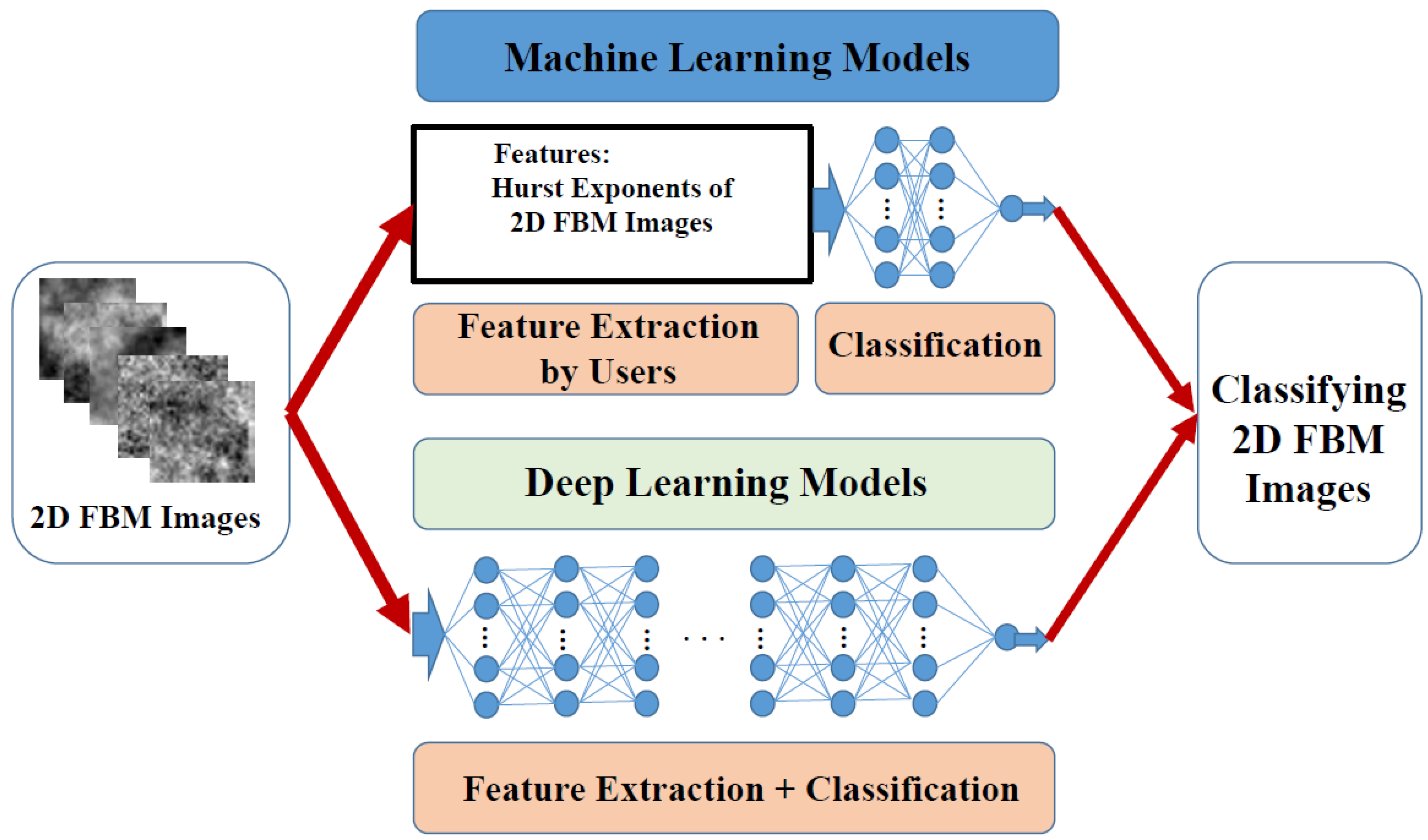
In the paper, we investigate the resolution of the Hurst exponent through machine learning and deep learning. For machine learning, we first estimate two kinds of data of Hurst exponents—fractional Brownian surfaces (FBSs; true data) and 2D FBM images (surfaces saved as images, thereby losing some details) or simply called fractional Brownian images (FBIs), and then classify these numeric estimates by four machine learning models. For deep learning, we directly classify these images by four deep learning models without feature selection and extraction performed by users.
3.3. Results and Discussion of Deep Learning Models
The MLE, as we know, is the best estimator for 2D FBM—it is an unbiased estimator and has the lowest mean-squared error. Even so, when its estimates are used to differentiate between the classes of the Hurst exponent or fractal dimension, the classification rate of the SVM classifier on these estimates is only 83.9% for FBSs and 81.4% for FBIs under the resolution of 1/11, and only 56.0% for FBSs and 53.2% for FBIs under the resolution of 1/21.
For images of size 32 × 32 × 1, the resolution is not very high, especially under the resolution of 1/21. Therefore, the first purpose of the paper is to investigate whether or not we can design a simple sequential network to achieve a higher classification rate, as well as whether some pretrained deep learning models can obtain higher classification rates. If so, the second purpose is to use these deep learning models to replace the role of the MLE for 2D FBM in order to efficiently and effectively recognize the classes of images—or equivalently estimate the Hurst exponent or its corresponding fractal dimension of images.
First, we designed a simple sequential network model and chose three pretrained models—AlexNet, GoogleNet, and Xception—as our compared subjects. Except for the AlexNet model, each model contains two types of modalities: one uses the size of the original images—32 × 32 × 1—as the size of the input layer, and hence no augmented operation is necessary; the other uses the size of the original model—for example, 227 × 227 × 3 for the AlexNet model—as the size of the input layer, and hence an augmented operation is needed. We call the first modality Type 1 and the second Type 2 and simply express them as AlexNet 1 and AlexNet 2, GoogleNet 1 and GoogleNet 2, as well as Xception1 and Xception 2.
Since the AlexNet model contains three pooling layers, making the size smaller and smaller, AlexNet 1 was not suitable for the size of our images. Therefore, the following four tables will not list their corresponding results. Totally, six models were considered and performed. All six models were run on the same FBIs or 2D FBM images and under five-fold cross-validation. The size of our images is 32 × 32 × 1.
In the case of Type 1, since our image size is different from those of the three pretrained models—227 × 227 × 3 for the AlexNet model (25 layers), 224 × 224 × 3 for the GoogleNet model (144 layers), and 299 × 299 × 3 for the Xception model (170 layers)—and the number of the output classes (11 or 21) is different from 1000 for three models, we adjusted the input layer, fully connected layer, and an output layer of the three pretrained models in order to run these models correctly. For convenience, when we refer to these adjusted models, we call them the adjusted AlexNet model, the adjusted GoogleNet model, and the adjusted Xception model, respectively, or simply AlexNet 1, GoogleNet 1, and Xception 1, respectively.
In the case of Type 2, we used an augmenter to make the image size (32 × 32 × 1) match the sizes (227 × 227 × 3, 224 × 224 × 3, or 299 × 299 × 3) of three pretrained models, and modified the corresponding fully-connected layer and output layer to meet the number of our classes, 11 or 21. We simply call them AlexNet 2, GoogleNet 2, and Xception 2, respectively. The augmenter was introduced only for resizing the original images to the corresponding sizes of three pretrained models.
For a fair comparison, all six models were performed in the same computing environment. (1) Hardware: a computer of Intel® Xeon(R) W-2235 CPU @ 3.80 GHz with 48.0 GB RAM (47.7 GB available), together with a GPU processor (NVIDIA RTX A4000); (2) operating system: Windows 11 Professional Workstation, version 21 H2; (3) programming software: MATLAB R2022a; (4) training options: the solver was stochastic gradient descent with momentum (SGDM); the mini-batch size was 128; the initial learning rate was 0.001; the learning rate schedule was piecewise; the learning rate drop factor was 0.1; the learning rate drop period was 20; the shuffle was for every epoch; the validation frequency was 30; the number of epochs was 30; and the other options were set to default.
Since the mini-batch size was 128 and five-fold was performed, the number of iterations per epoch was 68 (11,000 × 0.8/128 = 68.75) for 11 Hurst exponents, 2040 iterations in total; the number of iterations per epoch was 131 (21,000 × 0.8/128 = 131.25) for 21 Hurst exponents, 3930 iterations in total.
Our proposed model is a 29-layer sequential network composed of an image input layer, five groups of a convolutional layer, a batch normalization layer, a ReLU layer, and a maximum pooling layer (in total, 20 layers), one group of a convolutional layer, a batch normalization layer, and a ReLU layer (in total, three layers), one group of a fully connected layer and a ReLU layer (in total, two layers), as well as the final group of a fully connected layer, a softmax layer, and a classification layer (in total, three layers).
According to the structures and characteristics of our FBIs, we adopted a simple design concept for our proposed model; that is, the filters were regularly configured, and their corresponding sizes were increased. Therefore, our proposed model was arranged as follows. The image input layer is of size 32 × 32 × 1; the first convolutional layer contains 128 filters of size 3 × 3; the second convolutional layer contains 128 filters of size 5 × 5; the third convolutional layer contains 128 filters of size 7 × 7; the fourth convolutional layer contains 128 filters of size 9 × 9; the fifth convolutional layer contains 128 filters of size 11 × 11; the sixth convolutional layer contains 128 filters of size 13 × 13. All maximum pooling layers are of size 2 × 2 with stride two. The output size of the first fully connected layer is 10 times 11 or 21 (110 or 210); the output size of the second fully connected layer is 11 or 21, depending on the number of classes. For clarity,
Table 7 shows the architecture of our proposed model.
In the case of 11 classes,
Table 8 shows that our proposed model has the best accuracy at 0.9600, and its corresponding standard deviation is 0.0056; the second best is GoogleNet 1, with an accuracy of 0.9324 and the smallest standard deviation of 0.0026. The worst model for our FBIs is Xception 1, with an accuracy of 0.6551 and the largest standard deviation of 0.0180.
In the case of 21 classes,
Table 9 shows that our proposed model also has the best accuracy at 0.9370 and its corresponding standard deviation is 0.0063; the second best is also GoogleNet 1 with an accuracy of 0.9266 and the smallest standard deviation at 0.0046. The worst model for our FBIs is also Xception 1, with an accuracy of 0.6410 and the largest standard deviation at 0.0498. Similar to machine learning models, it is expected that the case of 21 classes is generally worse than the case of 11 classes.
Based on the same FBIs, five deep learning models (except for Xception 1) on 11 classes are better than the best accuracy of 0.814 (SVMs) from four machine learning models, where the only feature of the estimated Hurst exponents was considered. In the other case of 21 classes, six deep learning models are all better than the best accuracy of 0.56 (SVMs) from four machine learning models.
When training time is important, our proposed model is also the first choice.
Table 10 and
Table 11 shows that the training times of 11 classes and 21 classes are 1.41 and 2.71 min, respectively. In addition, these two tables also show the time ratios of other models to our model. The second efficient model is GoogleNet 1, with 4.15 and 8.54 min for 11 classes and 21 classes. The worst efficient model is Xception 2 with 664.21 and 1352.69 min for 11 classes and 21 classes.
To further analyze the distribution of the incorrectly classified classes, we show two promising models—our proposed model and GoogleNet 1—for discussion. For our proposed model, we list the confusion matrix of the first fold of five-fold cross-validation for 11 classes in
Figure 7 and the complete confusion matrix and its lower right part for clarity for 21 classes in
Figure 8a,b (when zoomed in, the figure will be easy to read). The diagonal cells show the number of cases that were correctly classified, and the off-diagonal cells show the misclassified cases.
Similar to
Table 5 for SVMs, the worst sensitivity or recall (79.5%) among 11 classes occur in the last but one class, Class 10, and the worst precision (84.1%) also occurs in the last but one class. Therefore, the worst classification rate also occurs in the last but one class. Relatively, lower Hurst exponents or rougher images are easier to differentiate; the boundary lies in the middle class, Class 6 (
H = 1/2).
The worst sensitivity or recall (49.0%) among 21 classes occurs in the last to one class, Class 20; likewise, the worst precision (58.3%) also occurs in the last but one class; therefore, the worst classification rate also occurs in the last but one class. Relatively, higher Hurst exponents or smoother images are more difficult to differentiate because their hidden features get lesser. The boundary lies about in the middle class, Class 11; that is, the classes of Hurst exponents lower than 0.5 can be correctly classified. Generally, the classification rate gets lower as the Hurst exponent gets larger.
As a comparison, we also list the confusion matrix of the first fold of the five-fold cross-validation of GoogleNet 1 for 11 classes in
Figure 9 and the complete confusion matrix and its lower right part for clarity for 21 classes in
Figure 10a,b (when zoomed in, the figure will be easy to read).
The worst sensitivity or recall (74.0%) among 11 classes occur in the last but one class, Class 10; likewise, the worst precision (76.7%) also occurs in the last but one class; therefore, the worst classification rate occurs in the last but one class. Likewise, lower Hurst exponents or rougher images are easier to differentiate; the diagonal cells show smaller numbers as the Hurst exponent gets larger.
The worst sensitivity or recall (55.0%) among 21 classes occur in the last but one class, Class 20; likewise, the worst precision (57.0%) also occurs in the last but one class; therefore, the worst classification occurs in the last but one class. Similarly, higher Hurst exponents or smoother images are more difficult to differentiate. In general, the classification rate gets lower as the Hurst exponent increases.
3.4. Comprehensive Discussion
Traditionally, when we want to estimate the fractal dimensions of images, we use an estimator to compute. If necessary, we also can further use the fractal dimensions to classify their classes or types. In the past, the box-counting method was often used to estimate because of its simplicity; however, its accuracy is considerably low, and hence it is often unreliable, thereby resulting in a low recognition rate.
Recently, Chang [
22] proposed an efficient MLE for 2D FBM, which is the most accurate estimator and, so far, the most efficient estimator among the MLEs. However, its computational time is still high for applications with larger image sizes and/or database sizes, and hence it is not appropriate for tasks of quick evaluation and analysis, especially for real-time systems.
Therefore, when we want to get the feature map of an original image by transforming the sub-images of the image to a matrix with the corresponding Hurst exponent as an entry or element, it is essential to find out an alternative estimation tool for a wide range of use. This is the second purpose of the paper.
In the paper, we have experimentally confirmed in the images of size 32 × 32 × 1 that the classification rates of suitably designed or chosen deep learning models can outperform those of machine learning models that receive the only feature—the estimated Hurst exponents from the efficient MLE. The computational cost of machine learning models can be neglected, but taking the only feature is terribly high.
In general, directly estimating the Hurst exponent of images is enough to analyze the differences between images; the classification is practically not necessary. Performed on the estimated Hurst exponents, machine learning models aim to compare with deep learning models as well as to further evaluate the benefits of deep learning models. If workable, we can use well-trained deep learning models to replace the role of the efficient MLE as estimation or further feature transformation.
At present, the comparison may not be considered fair because we use only one indicator as our feature for machine learning models, but deep learning models can implicitly and automatically extract or capture as more and more features as possible. However, the comparison tells us that deep learning models do work well even for the 2D FBM images from a 2D random process—various appearances coming from different realizations with the same parameter, as shown in
Figure 3,
Figure 4,
Figure 5 and
Figure 6. In the future, we can manually select other promising indicators as our features, for example, entropy and spectrum, to raise the classification rate.
Surprisingly, the chosen three pretrained networks—AlexNet, GoogleNet, and Xception—also work well for 2D FBM images (or FBIs) of size 32 × 32 × 1; in addition, the adjusted GoogleNet model is better than the adjusted AlexNet model and the adjusted Xception model in terms of the computational cost and classification rate.
These pretrained networks, as we know, were designed for 1000 common object categories, such as keyboard, mouse, pencil, and many animals. They did not see the hidden features of FBIs and were not trained with them, and hence, intuitively, they should not perform well. However, they not only work better than machine learning models with the only feature of the estimated Hurst exponents, but they also give us a promising prospect for the future, especially GoogleNet 1. As for other image sizes, further experiments are needed in order to find out the most suitable deep-learning model for different cases or situations.
In the experiments, we find that the models of Type 1—with the original images as the input images—can work better than machine learning models with the best estimates of the Hurst exponent as the only feature except Xception 1. Xception 1 cannot work well for a small image size. It is reasonable because Xception 1 cannot capture enough features for its large input size of 299 × 299 × 3 and its high layer number of 170. For the models of Type 2—with resizing the original images as the input images, they give similar results and are all better than machine learning models with the best estimates of the Hurst exponent as the only feature. However, the computational cost of model Type 2 is much higher than that of its corresponding model Type 1 because model Type 2 needs resizing and always performs on larger images.
The success of the pretrained models illustrates that 2D FBM images, even being random characteristics, can still be learned from concrete lines and/or curves to abstract patterns through low-level to high-level layers.
With the success of pretrained networks, on the other hand, we establish a regular structure of network layers according to the characteristics of 2D FBM images. It turns out that our proposed simple sequential deep learning model does work well for 11 and 21 classes under the images of size 32 × 32 × 1. In addition, our proposed model is the best in terms of the classification rate and computational cost. GoogleNet 1 is the second.
For further applications to the estimation of the Hurst exponent, we also want to know whether these promising deep learning models are still equivalently better than the MLE in terms of the mean absolute error (MAE) and mean square error (MSE) as ordinal classification metrics, especially as numerical ordinal classification metrics like our dataset.
Since our dataset is balanced and was stratified for the five-fold cross-validation, as well as all classes are equally spaced, each corresponding to a number, we simply chose the general, not weighted, MAE and MSE as our comparison metrics.
Table 12 shows the comparison among four methods—the MLE was estimated on two datasets (FBSs and FBIs)—in terms of the MAE and MSE.
It is obvious from
Table 12 that our model is also the best and the second is GoogleNet 1 in terms of the MAE and MSE. In addition, the results of 21 classes are better than those of 11 classes for our model and GoogleNet 1. Therefore, we choose our proposed model and GoogleNet 1 with 21 classes as tools for estimation or feature transformation and further compare both models with the efficient MLE in the following Applications section.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}