


HierTTS: Expressive End-to-End Text-to-Waveform Using a Multi-Scale Hierarchical Variational Auto-Encoder


Abstract
:1. Introduction
- A highly expressive TTS model which deeply couples the hierarchical properties of speech with hierarchical VAE.
- A staged KL-weighted annealing strategy that helps eliminating posterior collapse in hierarchical VAE.
2. Background
Hierarchical Variational Auto-Encoder
3. Method
3.1. Overview
3.2. Reconstruction Losses
3.3. Adversrial Training
3.4. Staged KL Weighted Annealing
3.5. Component of HierTTS
3.5.1. HAE
3.5.2. HAD
3.5.3. HCE
4. Experimental and Results
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Training Setting
4.2. Baselines
4.3. Expressiveness
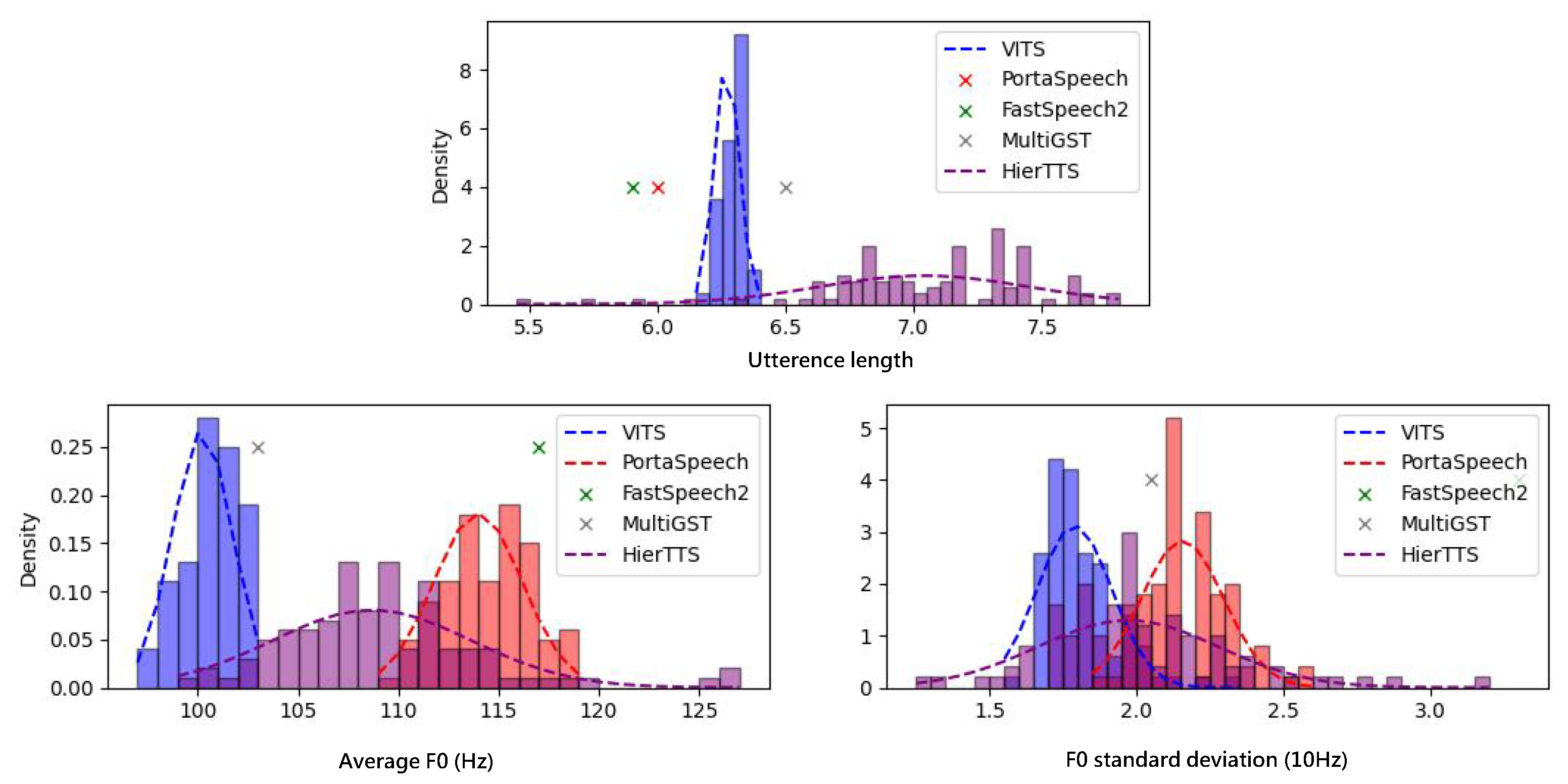
4.4. Diversity Analysis
4.5. Ablation Experiments and Methodological Analysis
4.5.1. Ablation Study
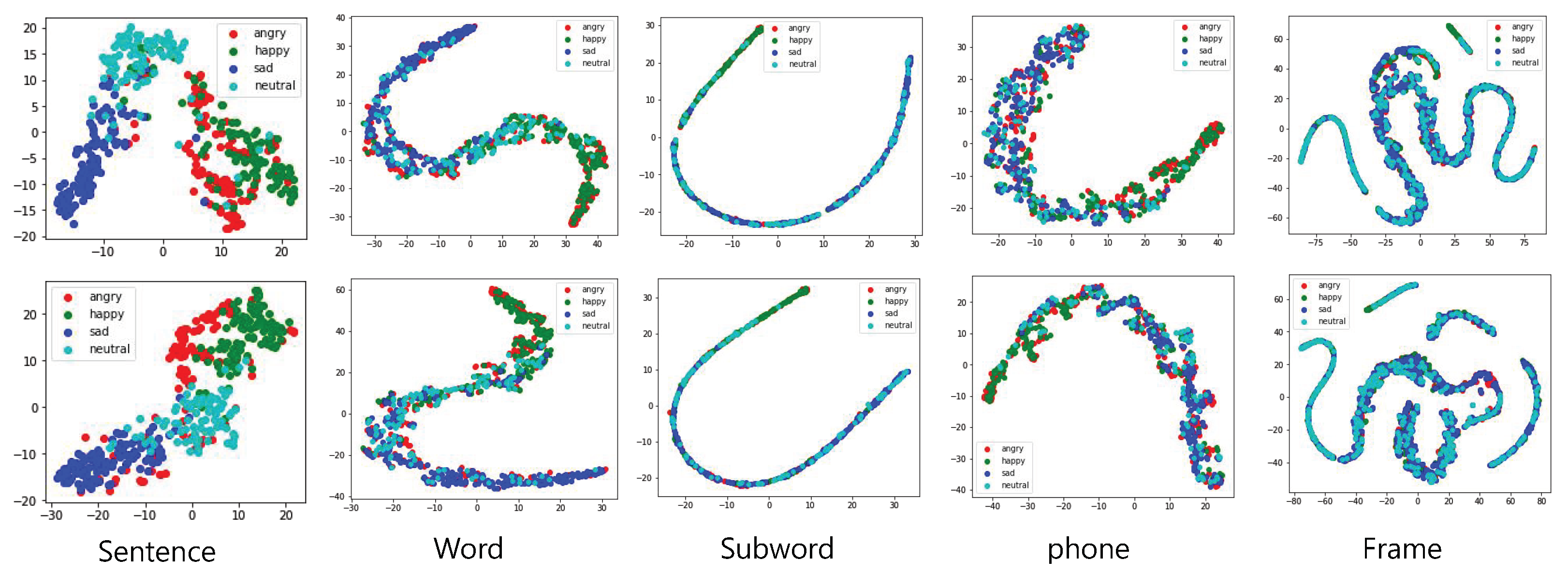
4.5.2. Visualization of Latent Space
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Xing, X.; Xu, X.; Pang, J.; Du, L. SpeechFormer: A Hierarchical Efficient Framework Incorporating the Characteristics of Speech. In Proceedings of the International Conference on Machine Learning, Boca Raton, FL, USA, 16–19 December 2019; pp. 3331–3340. [Google Scholar]
- Kenter, T.; Wan, V.; Chan, C.A.; Clark, R.; Vit, J. CHiVE: Varying prosody in speech synthesis with a linguistically driven dynamic hierarchical conditional variational network. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3331–3340. [Google Scholar]
- Sun, G.; Zhang, Y.; Weiss, R.J.; Cao, Y.; Zen, H.; Wu, Y. Fully-hierarchical fine-grained prosody modeling for interpretable speech synthesis. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6264–6268. [Google Scholar]
- Bae, J.S.; Yang, J.; Bak, T.J.; Joo, Y.S. Hierarchical and Multi-Scale Variational Autoencoder for Diverse and Natural Non-Autoregressive Text-to-Speech. arXiv 2022, arXiv:2204.04004. [Google Scholar]
- Lei, Y.; Yang, S.; Wang, X.; Xie, L. MsEmoTTS: Multi-scale emotion transfer, prediction, and control for emotional speech synthesis. IEEE/ACM Trans. Audio Speech, Lang. Process. 2022, 30, 853–864. [Google Scholar] [CrossRef]
- Lei, S.; Zhou, Y.; Chen, L.; Hu, J.; Wu, Z.; Kang, S.; Meng, H. Towards Multi-Scale Speaking Style Modelling with Hierarchical Context Information for Mandarin Speech Synthesis. arXiv 2022, arXiv:2204.02743. [Google Scholar]
- Kim, J.; Kong, J.; Son, J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5530–5540. [Google Scholar]
- Tan, X.; Chen, J.; Liu, H.; Cong, J.; Zhang, C.; Liu, Y.; Wang, X.; Leng, Y.; Yi, Y.; He, L.; et al. NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality. arXiv 2022, arXiv:2205.04421. [Google Scholar]
- Wu, J.; Hu, C.; Wang, Y.; Hu, X.; Zhu, J. A hierarchical recurrent neural network for symbolic melody generation. IEEE Trans. Cybern. 2019, 50, 2749–2757. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Sønderby, C.K.; Raiko, T.; Maaløe, L.; Sønderby, S.K.; Winther, O. Ladder variational autoencoders. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS 2016), Spain, Barcelona, 5–10 December 2016. [Google Scholar]
- Vahdat, A.; Kautz, J. NVAE: A deep hierarchical variational autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- Lee, Y.; Shin, J.; Jung, K. Bidirectional variational inference for non-autoregressive text-to-speech. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Liu, P.; Cao, Y.; Liu, S.; Hu, N.; Li, G.; Weng, C.; Su, D. Vara-tts: Non-autoregressive text-to-speech synthesis based on very deep vae with residual attention. arXiv 2021, arXiv:2102.06431. [Google Scholar]
- Yamamoto, R.; Song, E.; Kim, J.M. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6199–6203. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.Y. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Jang, W.; Lim, D.; Yoon, J.; Kim, B.; Kim, J. UnivNet: A neural vocoder with multi-resolution spectrogram discriminators for high-fidelity waveform generation. arXiv 2021, arXiv:2106.07889. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Pervez, A.; Gavves, E. Spectral smoothing unveils phase transitions in hierarchical variational autoencoders. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8536–8545. [Google Scholar]
- Pervez, A.; Gavves, E. Variance Reduction in Hierarchical Variational Autoencoders. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Prenger, R.; Valle, R.; Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3617–3621. [Google Scholar]
- Kim, J.; Kim, S.; Kong, J.; Yoon, S. Glow-tts: A generative flow for text-to-speech via monotonic alignment search. Adv. Neural Inf. Process. Syst. 2020, 33, 8067–8077. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, H.; Huang, Z.; Shang, Z.; Zhang, P.; Yan, Y. LinearSpeech: Parallel Text-to-Speech with Linear Complexity. In Proceedings of the Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 4129–4133. [Google Scholar]
- Su, J.; Lu, Y.; Pan, S.; Wen, B.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. arXiv 2021, arXiv:2104.09864. [Google Scholar]
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 498–502. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for Natural Language Understanding. In Proceedings of the Findings of the Association for Computational Linguistics, Online, 16–20 November 2020; pp. 4163–4174. [Google Scholar]
- Luo, R.; Xu, J.; Zhang, Y.; Ren, X.; Sun, X. Pkuseg: A toolkit for multi-domain chinese word segmentation. arXiv 2019, arXiv:1906.11455. [Google Scholar]
- Kong, J.; Kim, J.; Bae, J. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Adv. Neural Inf. Process. Syst. 2020, 33, 17022–17033. [Google Scholar]
- Ren, Y.; Liu, J.; Zhao, Z. Portaspeech: Portable and high-quality generative text-to-speech. Adv. Neural Inf. Process. Syst. 2021, 34, 13963–13974. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | MOS |
|---|---|
| FastSpeech2 + HiFiGAN | |
| MultiGST + HiFiGAN | |
| PortaSpeech + HiFiGAN | |
| VITS | |
| HierTTS | |
| GroundTruth |
| System | CMOS |
|---|---|
| -HVAE | |
| -Sentence level | |
| -Word level | |
| -Subword level | |
| -Staged weight annealing | |
| HierTTS | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, Z.; Shi, P.; Zhang, P.; Wang, L.; Zhao, G. HierTTS: Expressive End-to-End Text-to-Waveform Using a Multi-Scale Hierarchical Variational Auto-Encoder. Appl. Sci. 2023, 13, 868. https://doi.org/10.3390/app13020868
Shang Z, Shi P, Zhang P, Wang L, Zhao G. HierTTS: Expressive End-to-End Text-to-Waveform Using a Multi-Scale Hierarchical Variational Auto-Encoder. Applied Sciences. 2023; 13(2):868. https://doi.org/10.3390/app13020868
Chicago/Turabian StyleShang, Zengqiang, Peiyang Shi, Pengyuan Zhang, Li Wang, and Guangying Zhao. 2023. "HierTTS: Expressive End-to-End Text-to-Waveform Using a Multi-Scale Hierarchical Variational Auto-Encoder" Applied Sciences 13, no. 2: 868. https://doi.org/10.3390/app13020868
APA StyleShang, Z., Shi, P., Zhang, P., Wang, L., & Zhao, G. (2023). HierTTS: Expressive End-to-End Text-to-Waveform Using a Multi-Scale Hierarchical Variational Auto-Encoder. Applied Sciences, 13(2), 868. https://doi.org/10.3390/app13020868