


High Performing Facial Skin Problem Diagnosis with Enhanced Mask R-CNN and Super Resolution GAN

Abstract
:1. Introduction
- Detecting small-sized skin problems such as pores, moles, and acne
- Handling the high complexity of detecting about 20 different facial skin problem types
- Handling appearance variability of the same facial skin problem type among people
- Handling appearance similarity of different facial skin problem types
- Handling false segmentations on non-facial areas
2. Related Works
3. Technical Challenges in Diagnosing Facial Skin Problems
3.1. Challenge #1: Detecting Small-Sized Skin Problems Such as Pores, Moles, and Acne
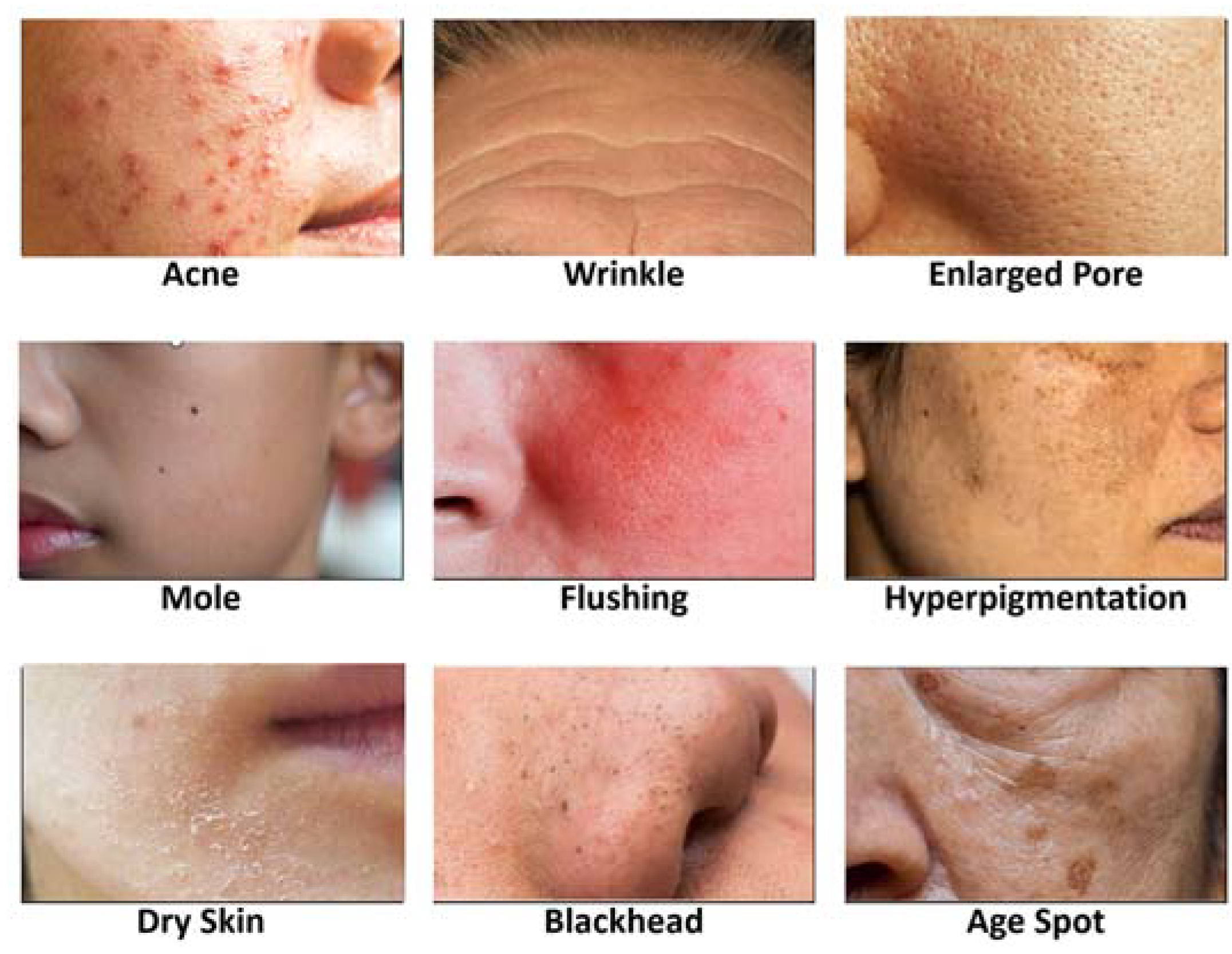
3.2. Challenge #2: Detecting about 20 Different Types of Facial Skin Problems
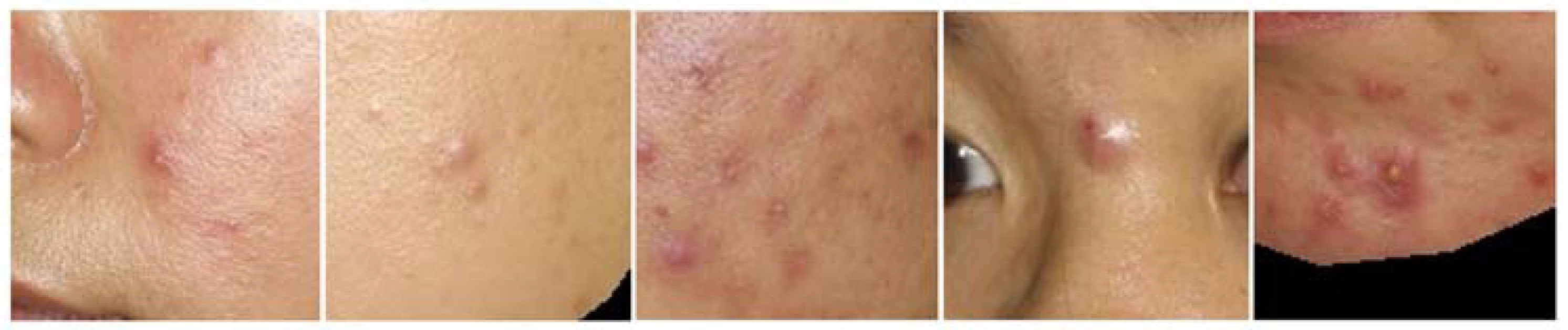
3.3. Challenge #3: Variability on Appearances of Same Facial Skin Problem Type
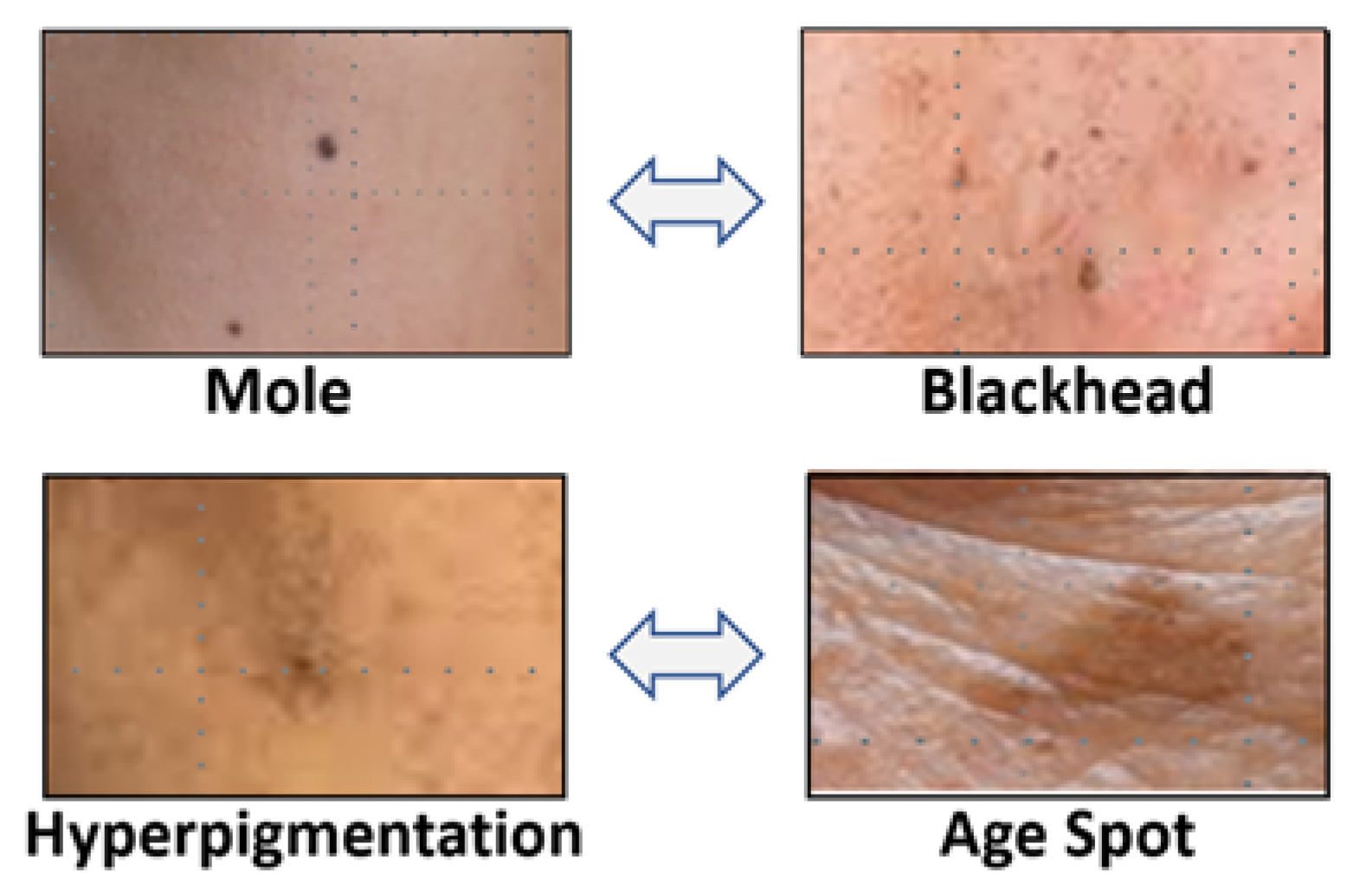
3.4. Challenge #4: Similarity on Appearances of Different Facial Skin Problem Types
3.5. Challenge #5: False Segmentations on Non-Facial Areas
4. Design of Tactics for Remedying the Technical Challenges
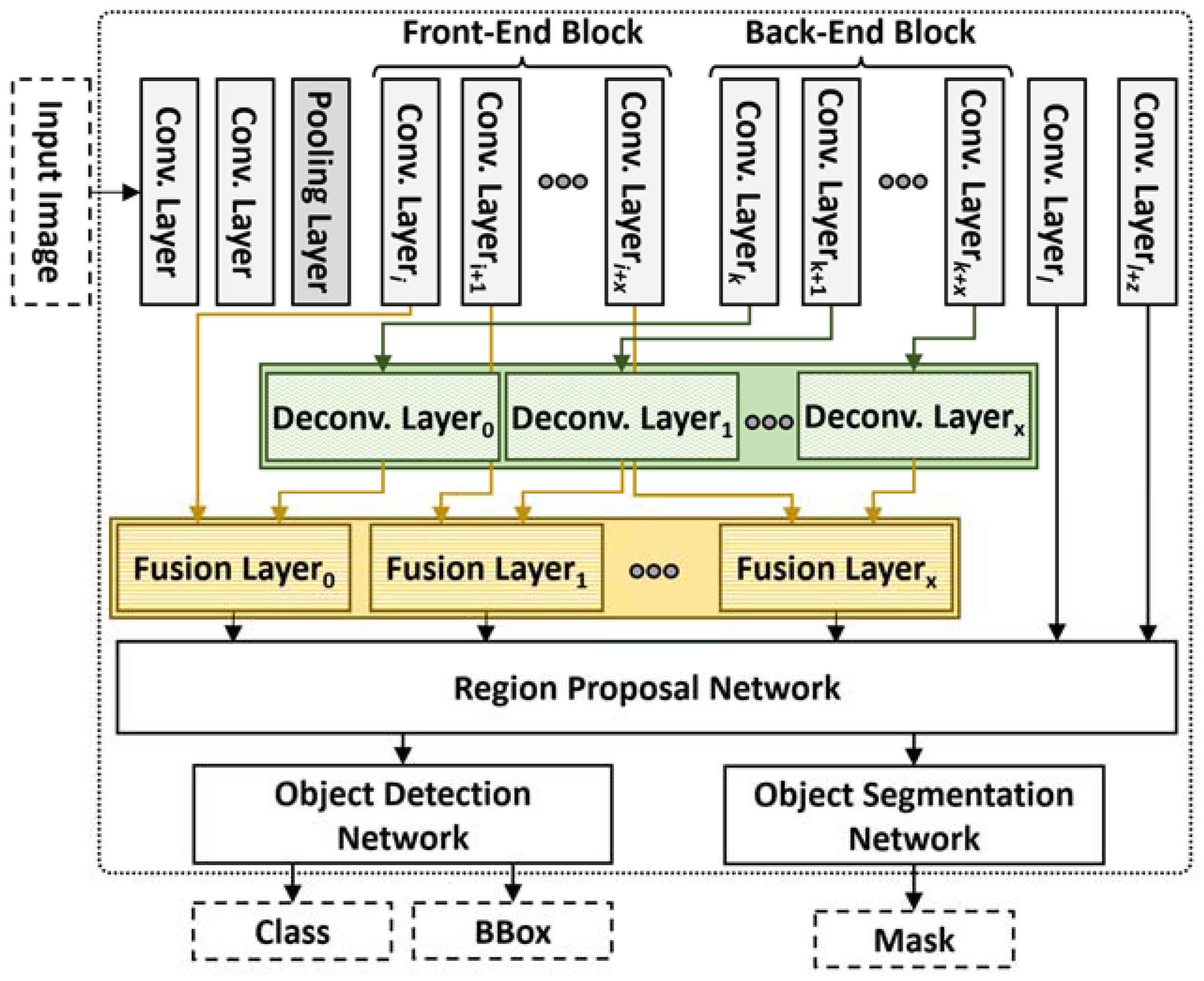
4.1. Design of Tactic #1: Refining Mask R-CNN Network with Fusion and Deconvolution Layers
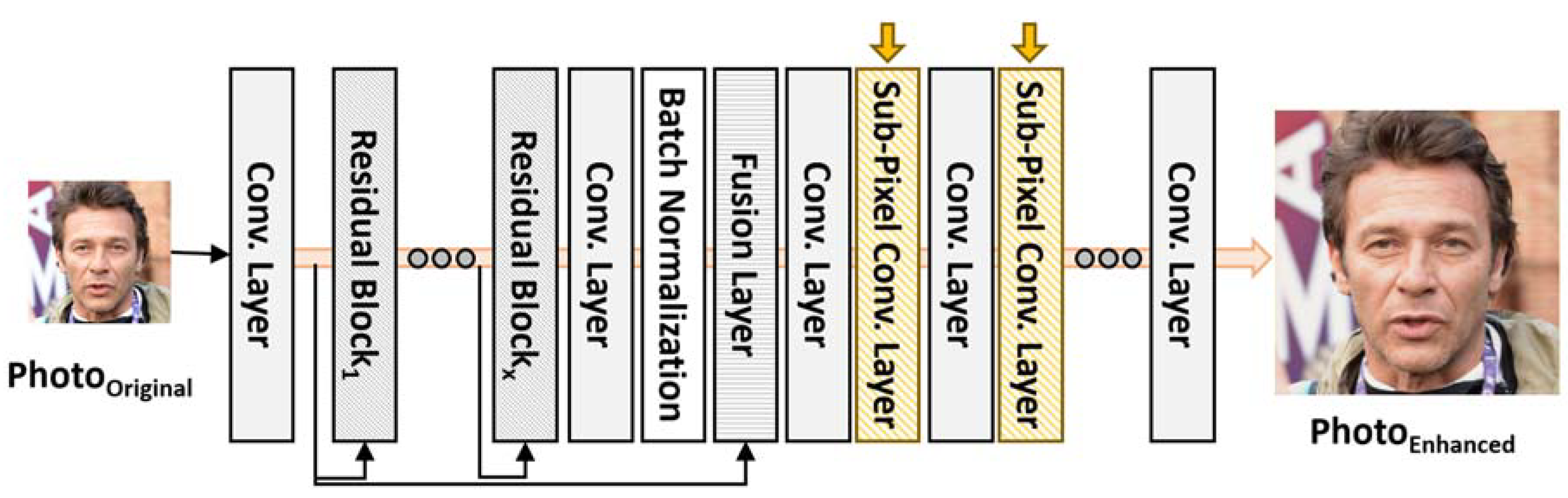
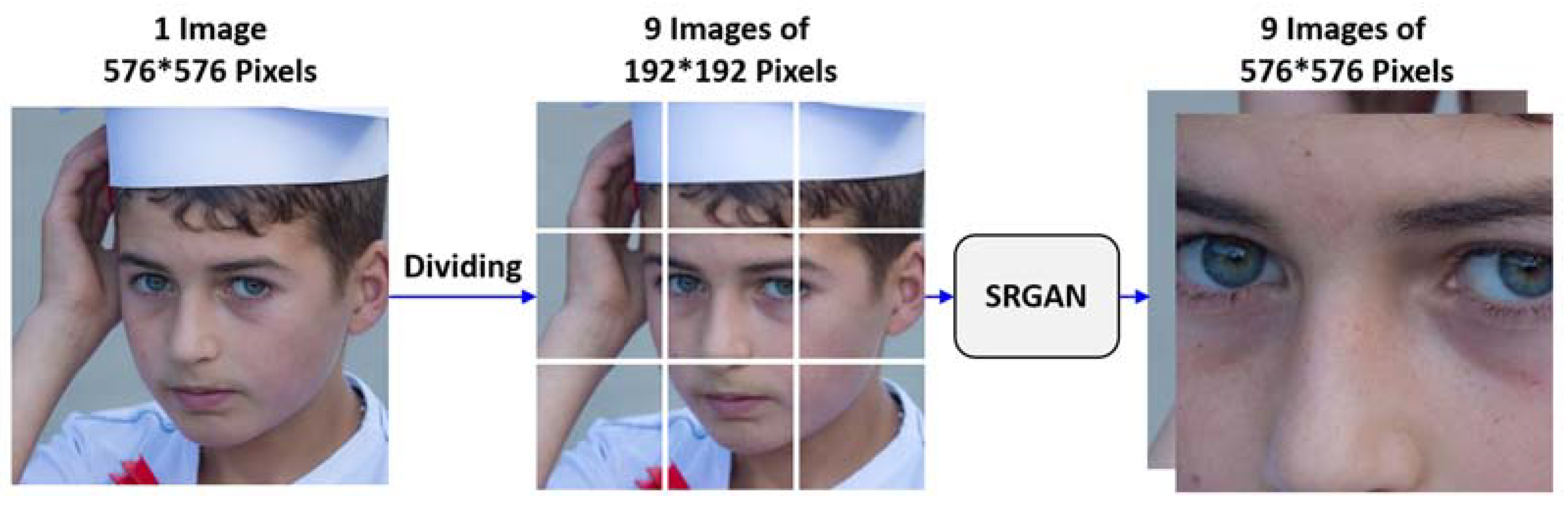
4.2. Design of Tactic #2: Super Resolution Generative Adversarial Network (GAN) for Small-sized and Blurry Images
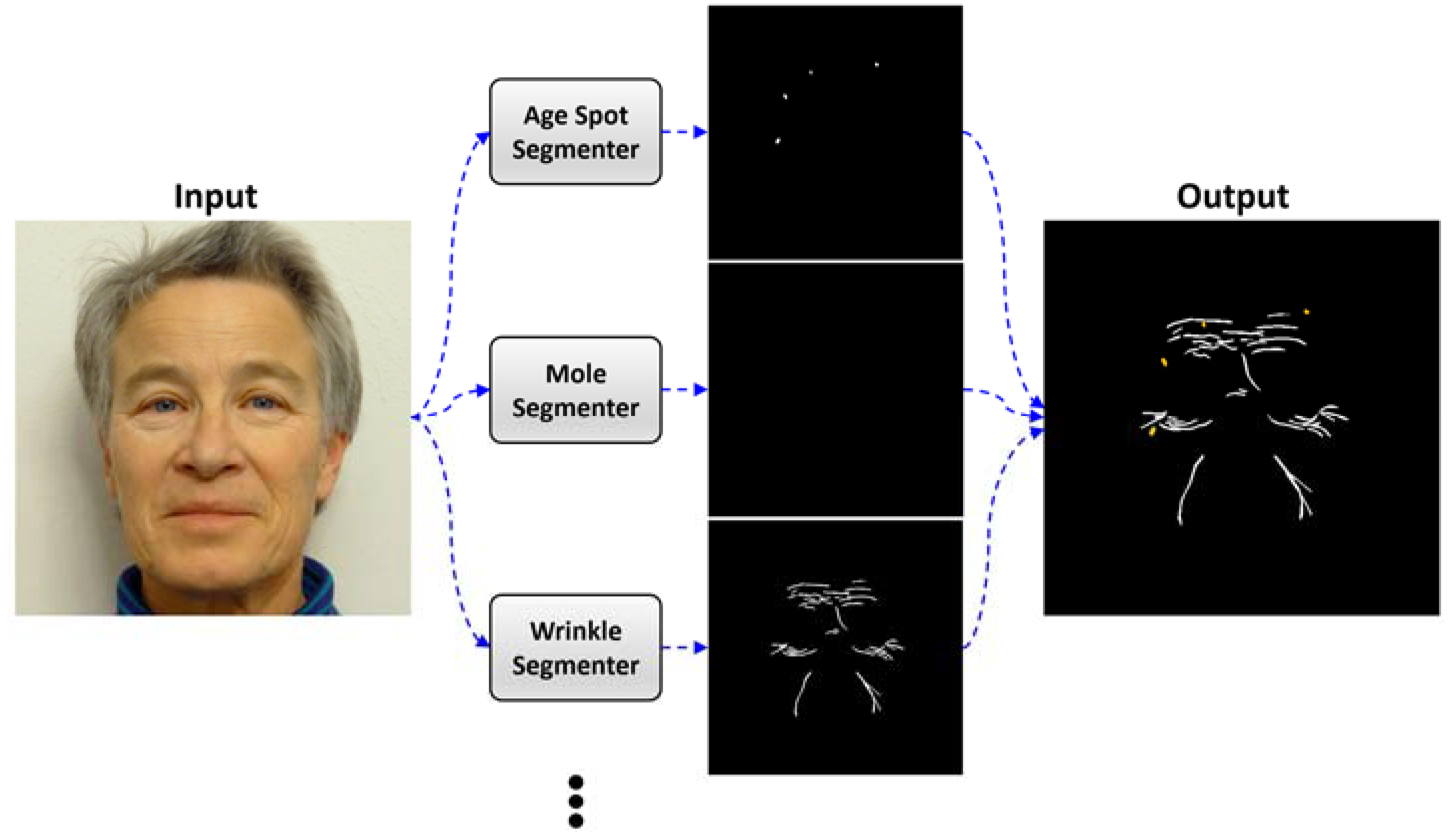
4.3. Design of Tactic #3: Training Facial Skin Problem-Specific Segmentation Models
4.4. Design of Tactic #4: Training Face Direction-Specific Segmentation Models
4.5. Design of Tactic #5: Discarding Segmentations on Non-Facial Areas Using Facial Landmark Model
4.6. Design of the Main Control Flow
| Algorithm 1. Main control flow of ‘Facial Skin Problem Diagnosis’ system. | |
| Input: photos: A list of 3 face photos (per person) Output: FSPResults: A list of detected facial skin problem instances | |
| 1: | Main() { |
| 2: | FSPResults = []; |
| 3: | SRGAN = // SR-GAN Model for upscaling and improving quality of Images |
| 4: | FaceLandmarkDetector = // Model for Face Landmark Detector |
| 5: | upscalingRatio = // Ratio of upscaling image by SRGAN |
| 6: | segmenters = // set of segmentation models for face direction and face skin problems |
| 7: | |
| 8: | for (photo in photos){ |
| 9: | // Step 1. Identify Face Directions (regarding the tactic #4) |
| 10: | landmarks = FaceLandmarkDetector.identify(photo); |
| 11: | locMouth = // Location of Mouth from detected Landmarks |
| 12: | locNose = // Location of Nose from Detected Landmarks |
| 13: | locRt = // Location of right side of face in detected landmarks |
| 14: | locLt = // Location of Left side of face in detected landmarks |
| 15: | if ((|locMouth-locLT| < |locMouth-locRT|) & (|locNose-locLT| < |locNose-locRT|)) |
| 16: | curDirection = LEFT; |
| 17: | else if ((|locMouth-locLT| > |locMouth-locRT|) & (|locNose-locLT| > |locNose- |
| 18: | locRT|)) |
| 19: | curDirection = RIGHT; |
| 20: | else curDirection = FRONTAL; |
| 21: | |
| 22: | // Step 2. Invoke Facial Skin Problem-specific Segmenters (regarding the tactic #3) |
| 23: | listFSPs = []; |
| 24: | for (segmenter_type in segmenters[curDirection]){ |
| 25: | SEGRef_type = // Segmenter based on Refined mask R-CNN from segmenter_type |
| 26: | SEGOrg_type = // Segmenter based on Original mask R-CNN from segmenter_type |
| 27: | // Step 3. Applying Refined mask R-CNN (regarding the tactic #1) |
| 28: | resultRef = SegRef_type.segment(photo); |
| 29: | |
| 30: | // Step 4. Enhance the Quality of Facial Images with SR-GAN model (regarding |
| 31: | the tactic #2) |
| 32: | sections = {SECi| SEC in photo, ∀SEC = photo}; // Divide Photos |
| 33: | resultOrg = []; |
| 34: | for (SEC ∈ sections){ |
| 35: | enlargedSEC = SRGAN.enlarge(SEC); |
| 36: | result = SEGOrg_type.segment(enlargedSEC); |
| 37: | resultOrg ← ( result // After Decreasing size of result to (1/upscalingRatio) |
| 38: | } |
| 39: | // Determine the facial skin problem |
| 40: | // (1) Select a result from step 3 and Step 4 |
| 41: | if(size(resultOrg) < thInstanceSize) |
| 42: | result = resultRef; |
| 43: | else |
| 44: | result = resultOrg; |
| 45: | // (2) Check whether the segmented instances classified by different FSP |
| 46: | for (fsp in listFSPs){ |
| 47: | if (size(fsp∧result)/max(size(fsp), size(result)) > thSize){ |
| 48: | if ((confidence score of fsp) > (confidence score of result)) |
| 49: | // Remain fsp |
| 50: | else{ |
| 51: | // discard fsp from listFSPs and add result |
| 52: | } |
| 53: | } |
| 54: | } |
| 55: | } |
| 56: | // Step 5. Discard false segmentations on non-facial skin area (regarding the tactic |
| 57: | #5) |
| 58: | faceArea = // Mask for face skin area excepting eyes, nostrils, and mouth. |
| 59: | segResult = FSPArea ∧ faceArea; // Overlay both segmented area |
| 60: | FSPResults ← ( (curDirection, segResult); |
| } | |
| return FSPResults; | |
| } | |
5. Experiments and Assessment
5.1. Datasets for Training Models
- A minimal set of essential facial skin problem types is needed; performing experiments with photos of all 20 different facial skin problem types requires a dataset of more than 10,000 photo images and annotating the facial skin problem areas on each photo manually by researchers would require an effort of more than 30 person-months.
- A dataset including facial skin problem types that are relatively large in size and also small in size is needed. Hence, photos showing wrinkles and rosacea are selected for the large-sized types and acne, mole, and age spots are selected for the small-sized types.
- A dataset including different facial skin problem types but having some similarities in their appearances is needed. Hence, photos showing acne, age spots, and moles are selected.
- A dataset including blurry boundaries between the problem-free skin areas and facial skin problem areas is needed. Hence, photos showing acne, rosacea, and wrinkles are selected.
5.2. Proof-of-Concept Implementation
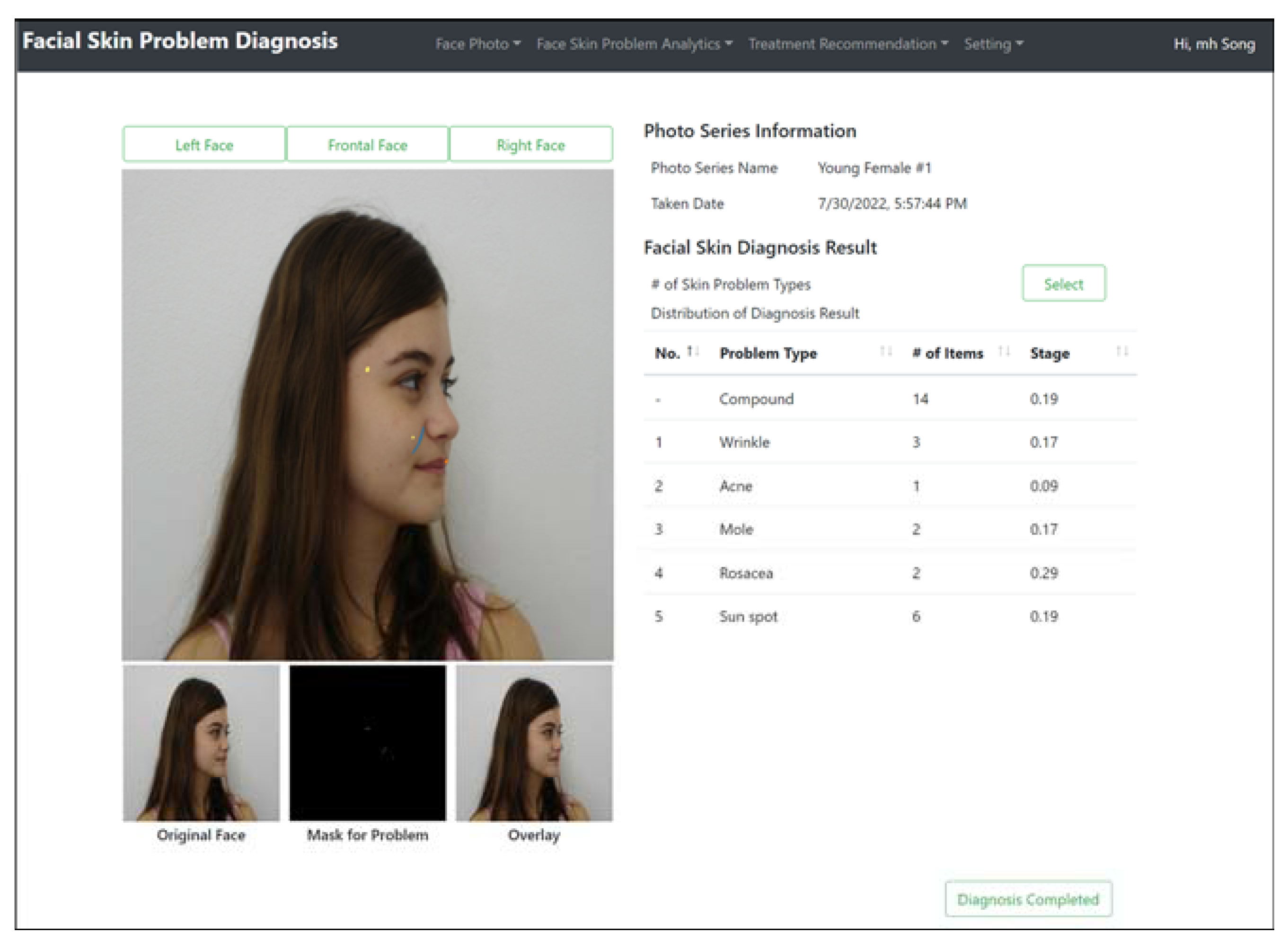
5.3. Performance Metric for Facial Skin Problem Diagnosis
5.4. Experiment Scenarios and Results
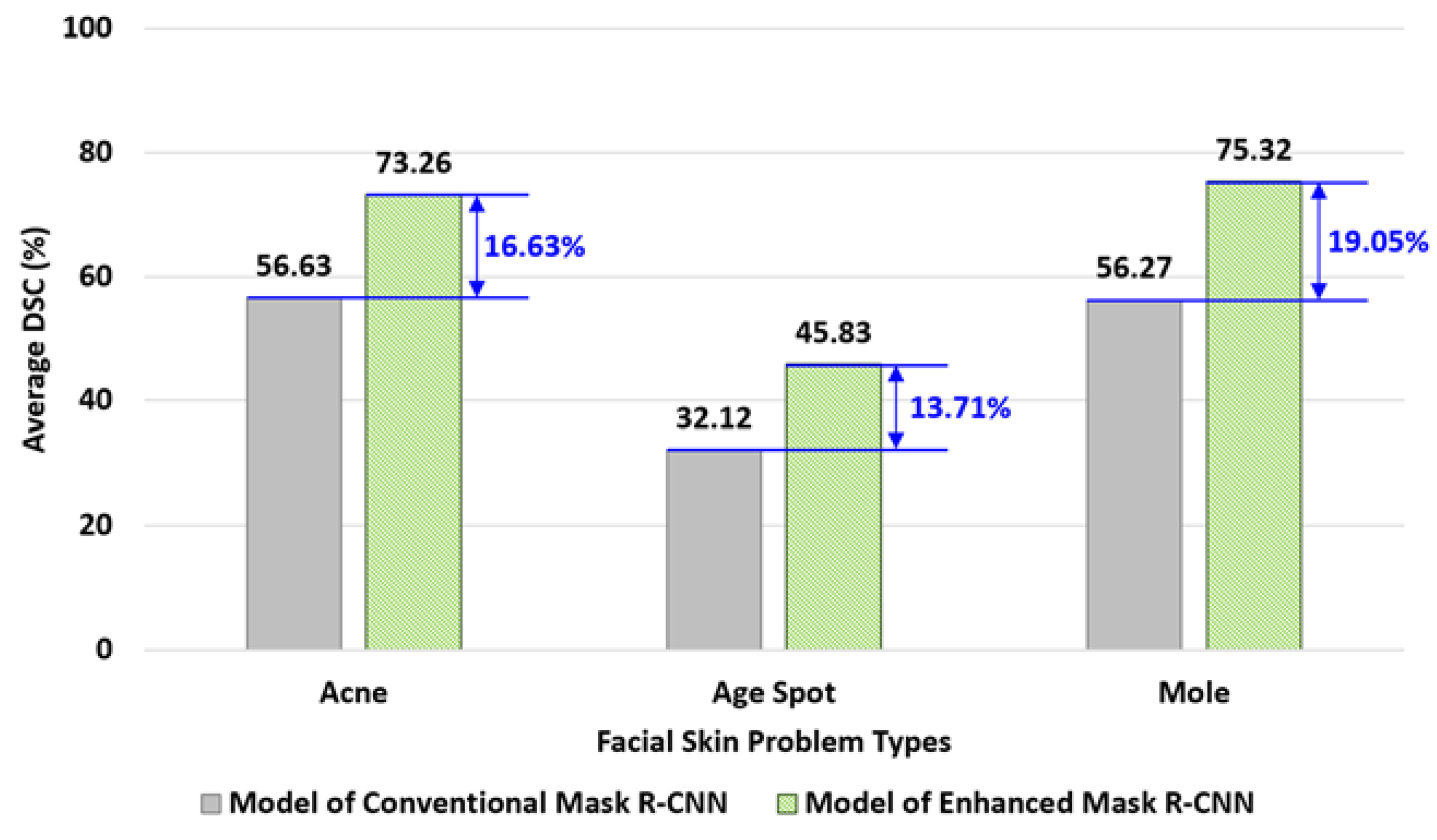
5.4.1. Experiment for Tactic #1: Refined Mask R-CNN Segmentation Models
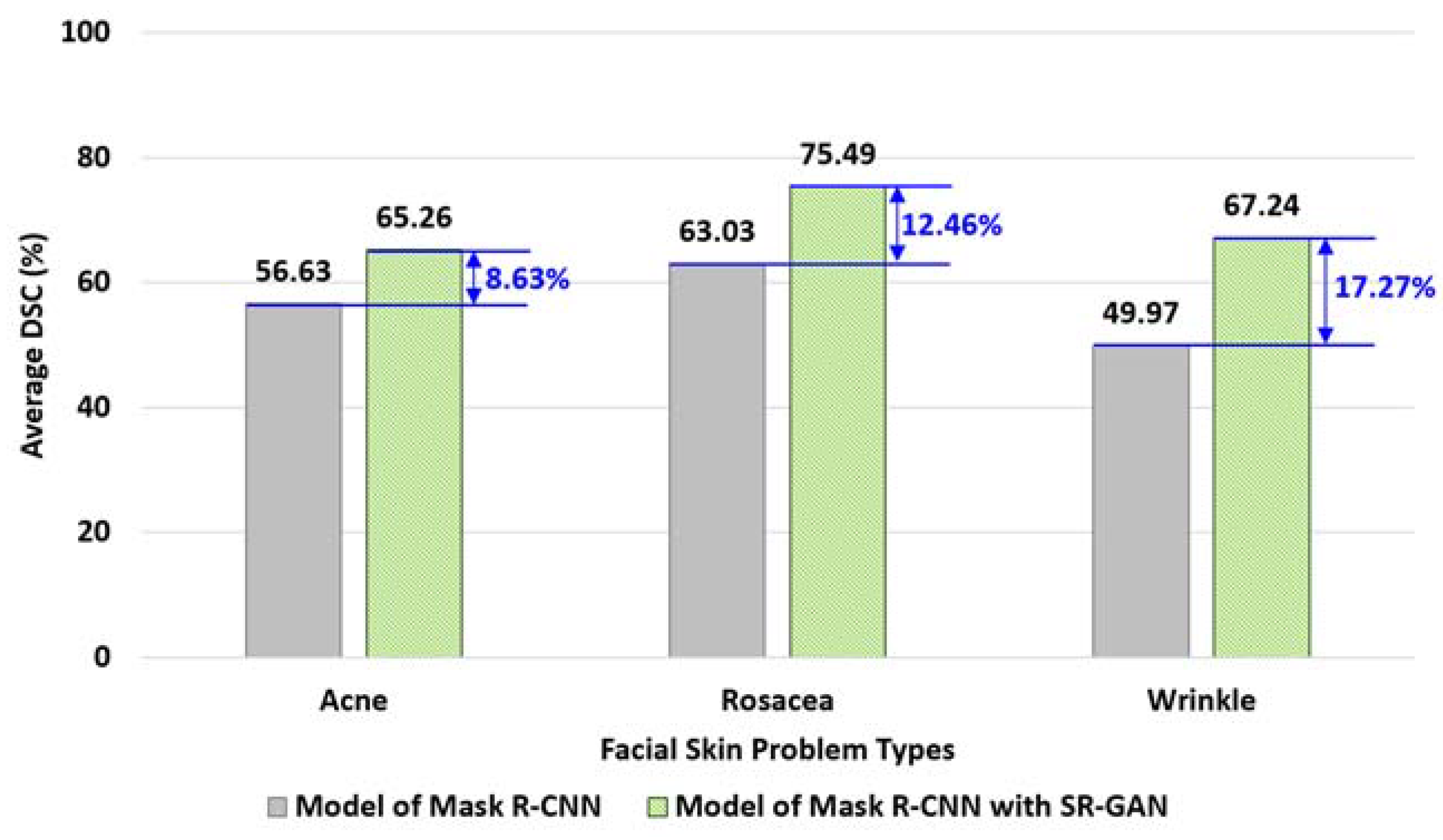
5.4.2. Experiment for Tactic #2: Super Resolution GAN Model
5.4.3. Experiment for Tactic #3: Facial Skin Problem-Specific Models
5.4.4. Experiment for Tactic #4: Face Direction-Specific Models
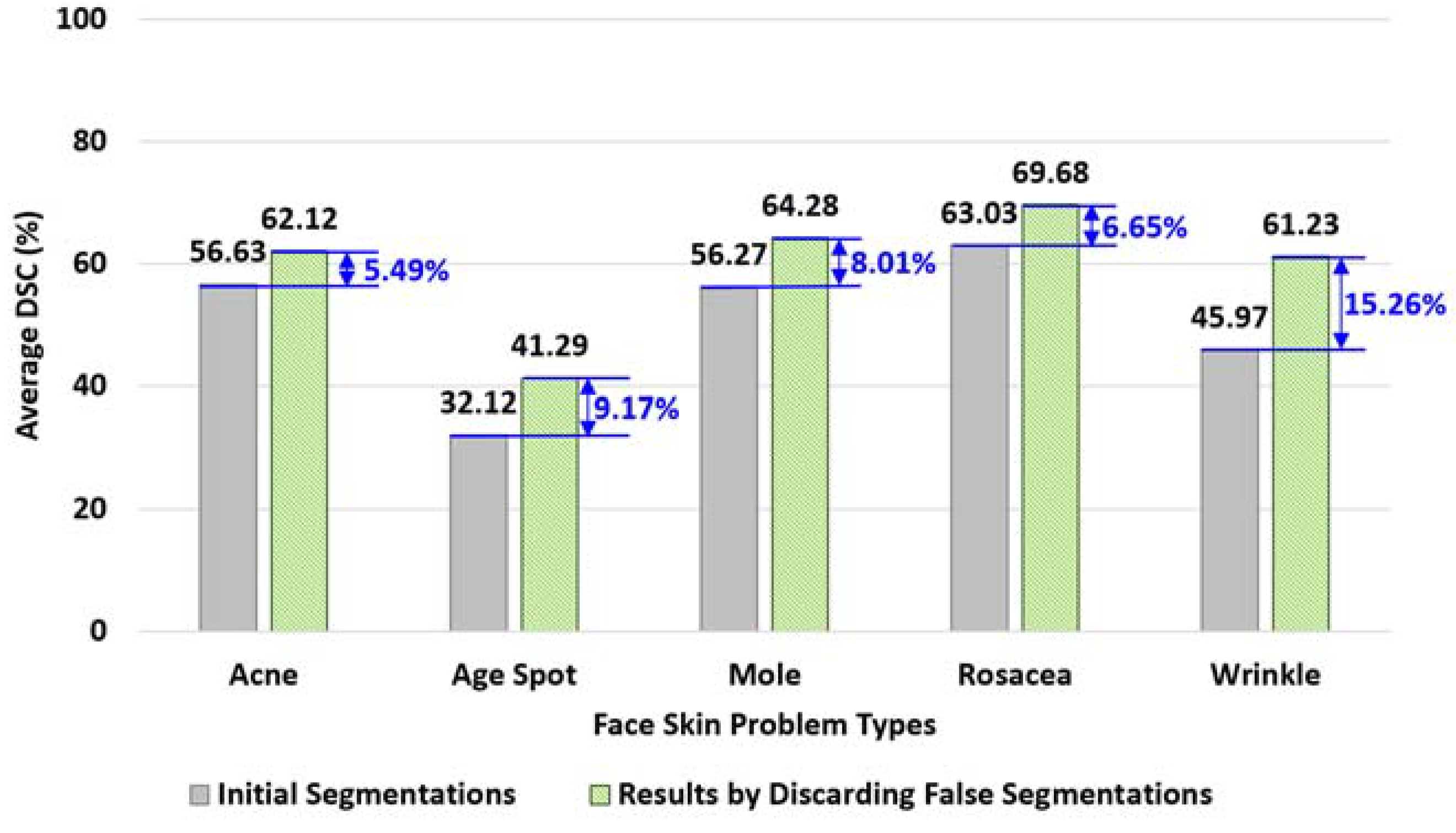
5.4.5. Experiment for Tactic #5: Discarding False Segmentations
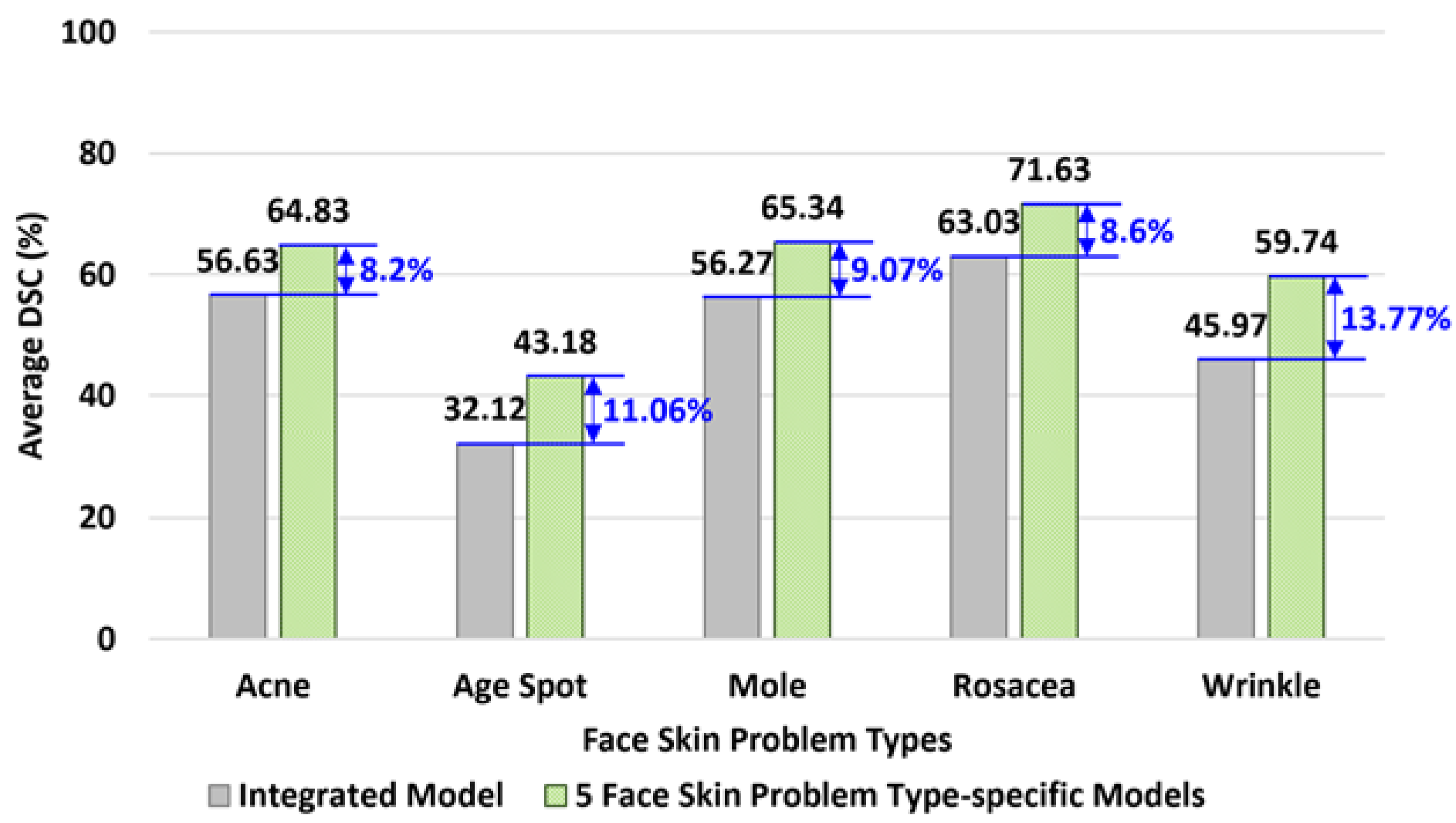
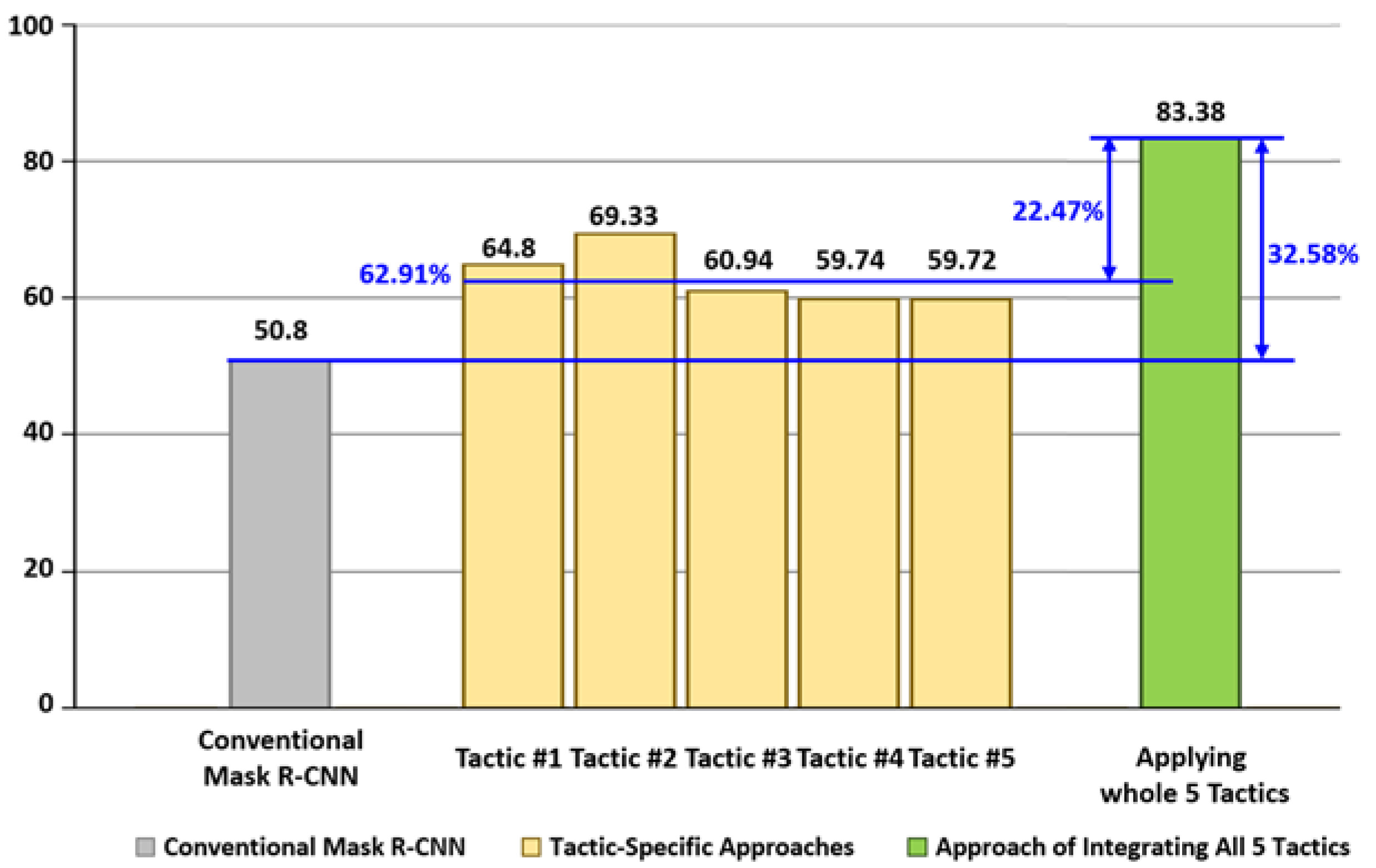
5.4.6. Experiment for Integrating all 5 Tactics
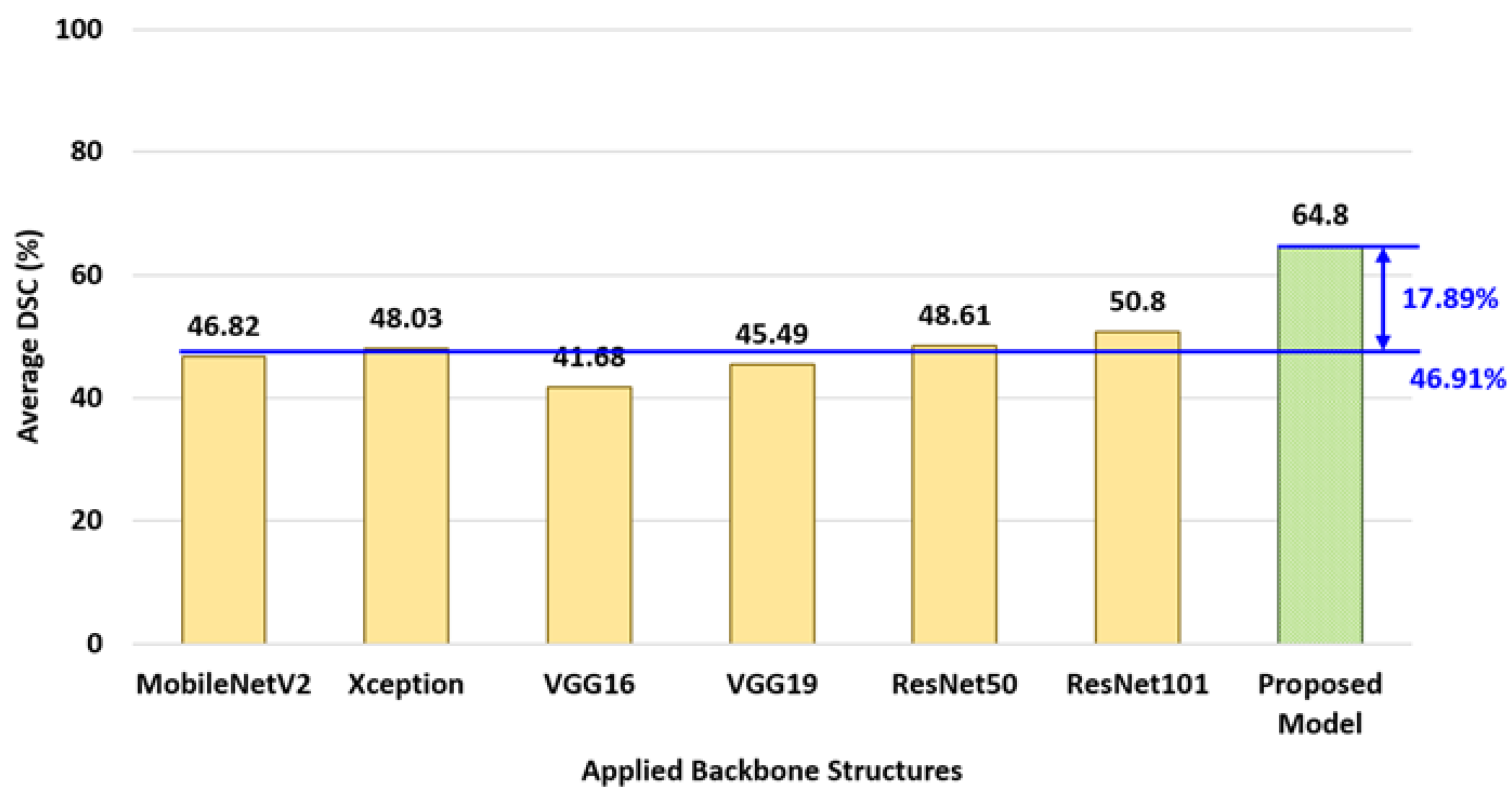
5.4.7. Experiment for Comparing with Other Backbone Networks
6. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, X.; Zhang, J.; Yan, C.; Zhou, H. An Automatic Diagnosis Method of Facial Acne Vulgaris Based on Convolutional Neural Network. Sci. Rep. 2018, 8, 5839. [Google Scholar] [CrossRef] [Green Version]
- Quattrini, A.; Boër, C.; Leidi, T.; Paydar, R. A Deep Learning-Based Facial Acne Classification System. Clin. Cosmet. Investig. Dermatol. 2022, 15, 851–857. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Wu, C.-M.; Zhang, S.; He, F.; Liu, F.; Wang, B.; Huang, Y.; Shi, W.; Jian, D.; Xie, H.; et al. A Novel Convolutional Neural Network for the Diagnosis and Classification of Rosacea: Usability Study. JMIR Public Health Surveill. 2021, 9, e23415. [Google Scholar] [CrossRef]
- Liu, S.; Chen, Z.; Zhou, H.; He, K.; Duan, M.; Zheng, Q.; Xiong, P.; Huang, L.; Yu, Q.; Su, G.; et al. DiaMole: Mole Detection and Segmentation Software for Mobile Phone Skin Images. J. Health Eng. 2021, 2021, 6698176. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Yin, H.; Chen, H.; Sun, M.; Liu, X.; Yu, Y.; Tang, Y.; Long, H.; Zhang, B.; Zhang, J.; et al. A deep learning, image based approach for automated diagnosis for inflammatory skin diseases. Ann. Transl. Med. 2020, 8, 581. [Google Scholar] [CrossRef]
- Gerges, F.; Shih, F.; Azar, D. Automated Diagnosis of Acne and Rosacea using Convolution Neural Networks. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Pattern Recognition (AIPR 2021), Xiamen, China, 24–26 September 2021. [Google Scholar] [CrossRef]
- Yadav, N.; Alfayeed, S.M.; Khamparia, A.; Pandey, B.; Thanh, D.N.H.; Pande, S. HSV model-based segmentation driven facial acne detection using deep learning. Expert Syst. 2021, 39, e12760. [Google Scholar] [CrossRef]
- Junayed, M.S.; Islam, B.; Jeny, A.A.; Sadeghzadeh, A.; Biswas, T.; Shah, A.F.M.S. ScarNet: Development and Validation of a Novel Deep CNN Model for Acne Scar Classification With a New Dataset. IEEE Access 2021, 10, 1245–1258. [Google Scholar] [CrossRef]
- Bekmirzaev, S.; Oh, S.; Yo, S. RethNet: Object-by-Object Learning for Detecting Facial Skin Problems. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Gessert, N.; Sentker, T.; Madesta, F.; Schmitz, R.; Kniep, H.; Baltruschat, I.; Werner, R.; Schlaefer, A. Skin Lesion Classification Using CNNs With Patch-Based Attention and Diagnosis-Guided Loss Weighting. IEEE Trans. Biomed. Eng. 2019, 67, 495–503. [Google Scholar] [CrossRef]
- Gulzar, Y.; Khan, S.A. Skin Lesion Segmentation Based on Vision Transformers and Convolutional Neural Networks—A Comparative Study. Appl. Sci. 2022, 12, 5990. [Google Scholar] [CrossRef]
- Li, H.; Pan, Y.; Zhao, J.; Zhang, L. Skin disease diagnosis with deep learning: A review. Neurocomputing 2021, 464, 364–393. [Google Scholar] [CrossRef]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale deconvolutional single shot detector for small objects. Sci. China Inf. Sci. 2020, 63, 120113. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Yeoh, J.K.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention Mask R-CNN for Ship Detection and Segmentation From Remote Sensing Images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seo, H.; Huang, C.; Bassenne, M.; Xiao, R.; Xing, L. Modified U-Net (mU-Net) with Incorporation of Object-Dependent High Level Features for Improved Liver and Liver-Tumor Segmentation in CT Images. IEEE Trans. Med. Imaging 2019, 39, 1316–1325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, C.; Zhang, Y.; Zheng, J.; Li, B.; Shen, J.; Li, M.; Liu, L.; Qiu, B.; Chen, D.Z. IMIIN: An Inter-modality Information Interaction Network for 3D Multi-modal Breast Tumor Segmentation. Comput. Med. Imaging Graph. 2021, 95, 102021. [Google Scholar] [CrossRef]
- Tian, G.; Liu, J.; Zhao, H.; Yang, W. Small object detection via dual inspection mechanism for UAV visual images. Appl. Intell. 2021, 52, 4244–4257. [Google Scholar] [CrossRef]
- Chen, C.; Zhong, J.; Tan, Y. Multiple-Oriented and Small Object Detection with Convolutional Neural Networks for Aerial Image. Remote Sens. 2019, 11, 2176. [Google Scholar] [CrossRef]
- Amudhan, A.N.; Sudheer, A.P. Lightweight and computationally faster Hypermetropic Convolutional Neural Network for small size object detection. Image Vis. Comput. 2022, 119, 104396. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, G.; Zhang, G. Collaborative Network for Super-Resolution and Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 21546971. [Google Scholar] [CrossRef]
- Da Wang, Y.; Blunt, M.J.; Armstrong, R.T.; Mostaghimi, P. Deep learning in pore scale imaging and modeling. Earth-Sci. Rev. 2021, 215, 103555. [Google Scholar] [CrossRef]
- Guo, Z.; Wu, G.; Song, X.; Yuan, W.; Chen, Q.; Zhang, H.; Shi, X.; Xu, M.; Xu, Y.; Shibasaki, R.; et al. Super-Resolution Integrated Building Semantic Segmentation for Multi-Source Remote Sensing Imagery. IEEE Access 2019, 7, 99381–99397. [Google Scholar] [CrossRef]
- Aboobacker, S.; Verma, A.; Vijayasenan, D.; Suresh, P.K.; Sreeram, S. Semantic Segmentation on Low Resolution Cytology Images of Pleural and Peritoneal Effusion. In Proceedings of the 2022 National Conference on Communications (NCC 2022), Mumbai, India, 24–27 May 2022. [Google Scholar] [CrossRef]
- Fromm, M.; Berrendorf, M.; Faerman, E.; Chen, Y.; Schüss, B.; Schubert, M. XD-STOD: Cross-Domain Super resolution for Tiny Object Detection. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW 2019), Beijing, China, 8–11 November 2019. [Google Scholar]
- Wei, S.; Zeng, X.; Zhang, H.; Zhou, Z.; Shi, J.; Zhang, X. LFG-Net: Low-Level Feature Guided Network for Precise Ship Instance Segmentation in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 21865424. [Google Scholar] [CrossRef]
- Wei, J.; Xia, Y.; Zhang, Y. M3Net: A multi-model, multi-size, and multi-view deep neural network for brain magnetic resonance image segmentation. Pattern Recognit. 2019, 91, 366–378. [Google Scholar] [CrossRef]
- Zhou, X.; Takayama, R.; Wang, S.; Hara, T.; Fujita, H. Deep learning of the sectional appearances of 3D CT images for anatomical structure segmentation based on an FCN voting method. Med. Phys. 2017, 44, 5221–5233. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Kwak, H.-S.; Oh, I.-S. Cerebrovascular Segmentation Model Based on Spatial Attention-Guided 3D Inception U-Net with Multi-Directional MIPs. Appl. Sci. 2022, 12, 2288. [Google Scholar] [CrossRef]
- Sander, J.; de Vos, B.D.; Išgum, I. Automatic segmentation with detection of local segmentation failures in cardiac MRI. Sci. Rep. 2020, 10, 21769. [Google Scholar] [CrossRef] [PubMed]
- Scherr, T.; Löffler, K.; Böhland, M.; Mikut, R. Cell segmentation and tracking using CNN-based distance predictions and a graph-based matching strategy. PLoS ONE 2020, 15, e0243219. [Google Scholar] [CrossRef]
- Larrazabal, A.J.; Martinez, C.; Ferrante, E. Anatomical Priors for Image Segmentation via Post-processing with Denoising Autoencoders. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2019), Shenzhen, China, 13–17 October 2019. [Google Scholar] [CrossRef] [Green Version]
- Chan, R.; Rottmann, M.; Gottschalk, H. Entropy Maximization and Meta Classification for Out-of-Distribution Detection in Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 1–17 October 2021; pp. 5128–5137. [Google Scholar] [CrossRef]
- Shuvo, B.; Ahommed, R.; Reza, S.; Hashem, M. CNL-UNet: A novel lightweight deep learning architecture for multimodal biomedical image segmentation with false output suppression. Biomed. Signal Process. Control. 2021, 70, 102959. [Google Scholar] [CrossRef]
- Khan, S.A.; Gulzar, Y.; Turaev, S.; Peng, Y.S. A Modified HSIFT Descriptor for Medical Image Classification of Anatomy Objects. Symmetry 2021, 13, 1987. [Google Scholar] [CrossRef]
- Hamid, Y.; Elyassami, S.; Gulzar, Y.; Balasaraswathi, V.R.; Habuza, T.; Wani, S. An improvised CNN model for fake image detection. Int. J. Inf. Technol. 2022, 2022. [Google Scholar] [CrossRef]
- Zhang, W.; Itoh, K.; Tanida, J.; Ichioka, Y. Parallel distributed processing model with local space-invariant interconnections and its optical architecture. Appl. Opt. 1990, 29, 4790–4797. [Google Scholar] [CrossRef]
- Nguyen, N.-D.; Do, T.; Ngo, T.D.; Le, D.-D. An Evaluation of Deep Learning Methods for Small Object Detection. J. Electr. Comput. Eng. 2020, 2020, 3189691. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Sun, C.; Ai, Y.; Wang, S.; Zhang, W. Mask-guided SSD for small-object detection. Appl. Intell. 2020, 51, 3311–3322. [Google Scholar] [CrossRef]
- Flament, F.; Francois, G.; Qiu, H.; Ye, C.; Hanaya, T.; Batisse, D.; Cointereau-Chardon, S.; Seixas, M.D.G.; Belo, S.E.D.; Bazin, R. Facial skin pores: A multiethnic study. Clin. Cosmet. Investig. Dermatol. 2015, 8, 85–93. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- National Cancer Institute. Common Moles, Dysplastic Nevi, and Risk of Melanoma. Available online: https://www.cancer.gov/types/skin/moles-fact-sheet (accessed on 4 January 2023).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Indolia, S.; Goswami, A.K.; Mishra, S.; Asopa, P. Conceptual Understanding of Convolutional Neural Network- A Deep Learning Approach. Procedia Comput. Sci. 2018, 132, 679–688. [Google Scholar] [CrossRef]
- Luo, C.; Li, X.; Wang, L.; He, J.; Li, D.; Zhou, J. How Does the Data set Affect CNN-based Image Classification Performance? In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI 2018), Nanjing, China, 10–12 November 2018. [CrossRef]
- Zheng, X.; Qi, L.; Ren, Y.; Lu, X. Fine-Grained Visual Categorization by Localizing Object Parts With Single Image. IEEE Trans. Multimedia 2020, 23, 1187–1199. [Google Scholar] [CrossRef]
- Avianto, D.; Harjoko, A. Afiahayati CNN-Based Classification for Highly Similar Vehicle Model Using Multi-Task Learning. J. Imaging 2022, 8, 293. [Google Scholar] [CrossRef]
- Ju, M.; Moon, S.; Yoo, C.D. Object Detection for Similar Appearance Objects Based on Entropy. In Proceedings of the 2019 7th International Conference on Robot Intelligence Technology and Applications (RiTA 2019), Daejeon, Republic of Korea, 1–3 November 2019. [Google Scholar] [CrossRef]
- Jang, W.; Lee, E.C. Multi-Class Parrot Image Classification Including Subspecies with Similar Appearance. Biology 2021, 10, 1140. [Google Scholar] [CrossRef] [PubMed]
- Facial Landmarks Shape Predictor. Available online: https://github.com/codeniko/shape_predictor_81_face_landmarks (accessed on 4 January 2023).
- Wu, X.; Wen, N.; Liang, J.; Lai, Y.K.; She, D.; Cheng, M.; Yang, J. Joint Acne Image Grading and Counting via Label Distribution Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV 2019), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4217–4228. [Google Scholar] [CrossRef] [PubMed]
- Wu, X. Pytorch Implementation of Joint Acne Image Grading and Counting via Label Distribution Learning. Available online: https://github.com/xpwu95/LDL (accessed on 4 January 2023).
- NVDIA Research Lab. FFHQ Datase. Available online: https://github.com/NVlabs/ffhq-dataset (accessed on 4 January 2023).
- Thomaz, C.E. FEI Face Database. Available online: https://fei.edu.br/~cet/facedatabase.html (accessed on 4 January 2023).
- COCO Annotator. Available online: https://github.com/jsbroks/coco-annotator (accessed on 4 January 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Input Image | Functionality | Enhanced Section |
|---|---|---|---|
| Liu [14] | Ground-Penetrating Radar Image | To detect signals for cracks in asphalt pavement | Applied two feature pyramid networks as backbone networks in Mask R-CNN. |
| Nie [15] | Remote Sensing Images | To detect and segment ships | Added bottom-up structure to the feature pyramid networks in Mask R-CNN. |
| Liu [16] | Captured images by Unmanned aerial vehicle (UAV) | To detect objects in UAV perspective | Modified backbone network in YOLO to increase receptive fields. |
| Seo [17] | Medical Image | To segment liver and liver tumor | Added a residual path with deconvolution and activation operations to the skip connection of the U-Net. |
| Peng [18] | 3D Magnetic Resonance Imaging Image | To segment breast tumor in 3D image | Proposed a segmentation structure consisting of localization and segmentation by two Pseudo-Siamese networks (PSN). |
| Tian [19] | Captured images by UAV | To detect objects in UAV perspective | Proposed a detection model consisting of two detection networks to compute low-dimensional features |
| Instances on Facial Photo | Average Number of Pixels | Occupation Ratio on Photo |
|---|---|---|
| Whole Face | 101,000 pixels | 33.06% |
| Sections of Face, i.e., Eye, Nose, Mouth, and Ear | 3690 pixels | 3.36% |
| Facial Skin Problems such as Pore, Mole, and Acne | 25 pixels | 0.02% |
| Target Objects in Different Sizes | Average of DSC Measurements |
|---|---|
| Whole Face | 95.6% |
| Mouth as a Section of the Face | 90.9% |
| Mole as a Facial Skin Problem | 31.5% |
| Subset Type | Training Set | Validation Set | Test Set | Total |
|---|---|---|---|---|
| Ratio (%) | 69.98 | 10.02 | 20.0 | 100 |
| # of Photos | 1557 | 223 | 445 | 2225 |
| Code. Implementing a Python Class for training 6 segmentation models | |
| 1: | import tensorflow as tf |
| 2: | import tensorflow.keras as keras |
| 3: | import tensorflow.keras.layers as KL |
| 4: | from .backbone import build_mobilenet, build_xception, build_vgg16, build_vgg19, build_resnet50, |
| 5: | build_resnet101, build_fusion_deconv |
| 6: | from .mrcnn import build_rpn_and_mrcnn |
| 7: | |
| 8: | class FSPSegmenter: |
| 9: | def __init__(self, backbone_type, config, p_model): |
| 10: | self.config = config |
| 11: | self.path_model = p_model |
| 12: | self.model = self.build(backbone_type) |
| 13: | |
| 14: | def build(self, backbone_type): |
| 15: | input = KL.Input(shape= self.config.img_shape) |
| 16: | # To build backbone |
| 17: | feature_maps_MobileNetV2 = self.build_mobilenet(input_img) |
| 18: | feature_maps_xception = build_xception(input_img) |
| 19: | feature_maps_vgg16 = build_vgg16(input_img) |
| 20: | feature_maps_vgg19 = build_vgg19(input_img) |
| 21: | feature_maps_resnet50 = build_resnet50(input_img) |
| 22: | feature_maps_resnet101 = build_resnet101(input_img) |
| 23: | feature_maps_fusion_deconv = build_fusion_deconv(input_img) |
| 24: | |
| 25: | # To initialize structures for region proposal networks and networks for segmentation and detection |
| 26: | self.model_mobileNetV2 = build_rpn_and_mrcnn(feature_maps_MobileNetV2) |
| 27: | self.model_xception = build_rpn_and_mrcnn(feature_maps_xception) |
| 28: | self.model_vgg16 = build_rpn_and_mrcnn(feature_maps_vgg16) |
| 29: | self.model_vgg19 = build_rpn_and_mrcnn(feature_maps_vgg19) |
| 30: | self.model_resnet50 = build_rpn_and_mrcnn(feature_maps_resnet50) |
| 31: | self.model_resnet101 = build_rpn_and_mrcnn(feature_maps_resnet101) |
| 32: | self.model_fusion_deconv = build_rpn_and_mrcnn(feature_maps_fusion_deconv) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Song, M.H. High Performing Facial Skin Problem Diagnosis with Enhanced Mask R-CNN and Super Resolution GAN. Appl. Sci. 2023, 13, 989. https://doi.org/10.3390/app13020989
Kim M, Song MH. High Performing Facial Skin Problem Diagnosis with Enhanced Mask R-CNN and Super Resolution GAN. Applied Sciences. 2023; 13(2):989. https://doi.org/10.3390/app13020989
Chicago/Turabian StyleKim, Mira, and Myeong Ho Song. 2023. "High Performing Facial Skin Problem Diagnosis with Enhanced Mask R-CNN and Super Resolution GAN" Applied Sciences 13, no. 2: 989. https://doi.org/10.3390/app13020989
APA StyleKim, M., & Song, M. H. (2023). High Performing Facial Skin Problem Diagnosis with Enhanced Mask R-CNN and Super Resolution GAN. Applied Sciences, 13(2), 989. https://doi.org/10.3390/app13020989