
Deep Reinforcement Learning-Based Approach for Video Streaming: Dynamic Adaptive Video Streaming over HTTP


Abstract
:1. Introduction
- Optimizing QoE: One significant challenge lies in how DRL effectively manages the trade-off between delivering high-quality video and ensuring a seamless streaming experience.
- Adaptation to Dynamic Network Conditions: DASH operates in environments characterized by constantly changing network parameters, such as bandwidth and latency. It is essential to explore how DRL models adapt to these dynamic fluctuations and make real-time decisions to maintain optimal streaming quality.
- Segmentation and Quality Switching: The process of segmenting video content and determining when and how to switch between different quality levels is intricate. Discussing these intricacies sheds light on the challenges involved in ensuring a smooth transition between video segments.
- Reward Function Design: Designing a reward function that accurately reflects the quality of the streaming experience and encourages optimal decision making is a complex task. Elaborating on this complexity can provide insights into the inner workings of DRL models.
- Training Complexity: Training DRL models for video streaming poses computational challenges. This includes the need for substantial datasets and considerable computational resources. Exploring these training complexities highlights the practical considerations involved in implementing DRL for video streaming applications.
- Formulation and design model: We introduce a new deep reinforcement learning approach for DASH video streaming that focuses on controlling the quality distance between consecutive segments. By doing so, we effectively manage the perceptual quality switch. We formulate the DASH video streaming process within a learning model called the Markov Decision Process, enabling the determination of optimal solutions through reinforcement learning.
- Optimizing QoE: To optimize the QoE, we define the QoE function that relies on three key parameters: the quality of each segment, the perceptual change in quality, and playback interruptions.
- Reward Function Design: We have designed and formulated a reward function that takes into account the rate of perceived quality change, occurrences of rebuffering events, and the quality of each video segment.
- Analysis and implementation: We classify the available qualities (bitrates) into three classes: Qhigh, Qmedium, and Qpoor. To evaluate our approach, we conducted experiments using the animation video sequence “Big Buck Bunny” in the DASH.js environment over a wireless network. The experiments involved playing video sequences on different devices under various network conditions. We monitored the performance of the experiments throughout the streaming sessions, specifically observing the perceptible quality switch. Based on the observed quality switches, we classified the bitrates into three distinct classes.
- Training process: To tackle the training challenge of DRL and achieve enhanced performance, we leveraged a comprehensive and diverse dataset, and we traines the DRL agent using a two-step training process.
- Simulation and comparison: We simulated and compared our proposed approach with existing studies. The results demonstrated a significant improvement in QoE, providing highly stable video quality. Our scheme successfully minimized the distance factor, ensuring a smooth streaming session.
2. Related Work
- Traditional ABR-based approaches: This category encompasses methods that rely on bandwidth measurements, buffer occupancy, or a combination of both to guide streaming decisions. These approaches typically use fixed rules for adaptation throughout the streaming process. While they have found widespread use and implementation, their efficacy may be constrained, particularly in highly dynamic and diverse network conditions.
- Deep-learning-based approaches: Within this category, deep learning techniques, specifically neural network models, play a pivotal role. By training these models on extensive datasets, they can discern intricate patterns and make informed decisions regarding adaptation. Deep-learning-based approaches have demonstrated enhanced performance in adapting to a range of network conditions and user preferences. However, they often necessitate substantial amounts of training data and computational resources for effective model training.
- Reinforcement-learning-based approaches: In this category, adaptation decisions are orchestrated by an agent within an interactive environment, refining its choices through trial and error, guided by rewards. Reinforcement learning empowers the agent to learn and optimize its decisions based on the feedback received. These approaches offer the advantage of adaptability and the capability to navigate dynamic and uncertain network conditions. However, it is worth nothing that training reinforcement learning models can be a time-consuming process, and their performance heavily depends on the design of rewards and exploration strategies.
- Deep-reinforcement-learning-based approaches: This category harnesses the synergy of deep neural networks and reinforcement learning techniques. Deep reinforcement learning approaches utilize deep neural networks to approximate various elements of the reinforcement learning process, equipping them to handle intricate streaming environments and make sound adaptation decisions. By leveraging the representation learning capabilities of deep neural networks, these approaches have exhibited promising results in delivering high-quality video streaming experiences.
2.1. Traditional ABR-Based Approaches
2.2. Deep-Learning-Based Approaches
2.3. Reinforcement-Learning-Based Approaches
2.4. Deep-Reinforcement-Learning-Based Approaches
3. Materials and Methods
3.1. Problem Formulation
3.2. System Model
3.3. Reward Function
3.3.1. Perceived Quality Change
3.3.2. Rebuffering
3.3.3. Segment Quality
3.3.4. QoE Function
3.4. Markov Decision Process (MDP)
3.5. Deep Neural Network Architecture
3.5.1. Agent Design
3.5.2. Agent Training
- represents the policy function, where is the policy, ‘s’ is the state, and ‘a’ is the action. This function calculates the probability of taking action ‘a’ in state ‘s’ according to the policy parameterized by .
- indicates the probability of taking action ‘a’ given the state ‘s’ under the policy .
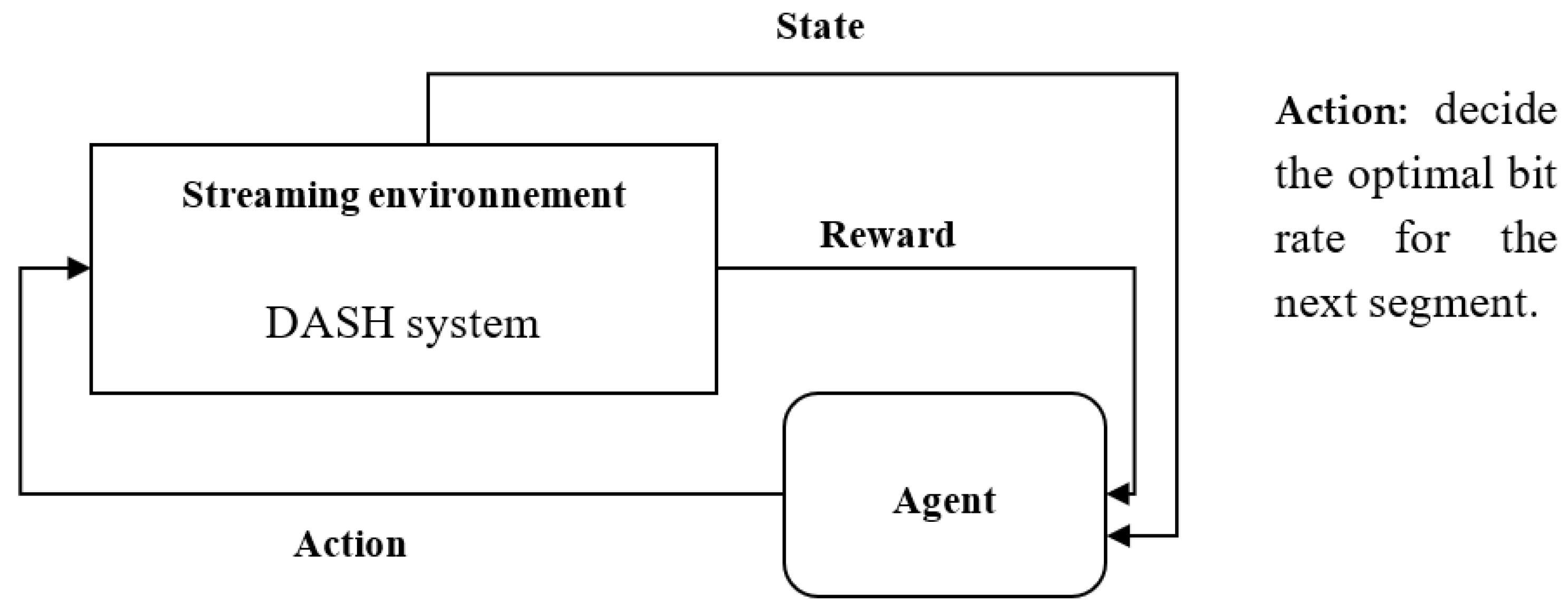
3.6. Overall Functionality Block Diagram of the Proposed Method
- Agent: The reinforcement learning agent, which uses the current state (bandwidth, buffer state, and quality of the previously downloaded segment) to select the next action to take (next video segment to download).
- Environment: The environment in which the agent operates, which includes the video stream and the network conditions.
- Reward: The reward that the agent receives for taking a particular action.
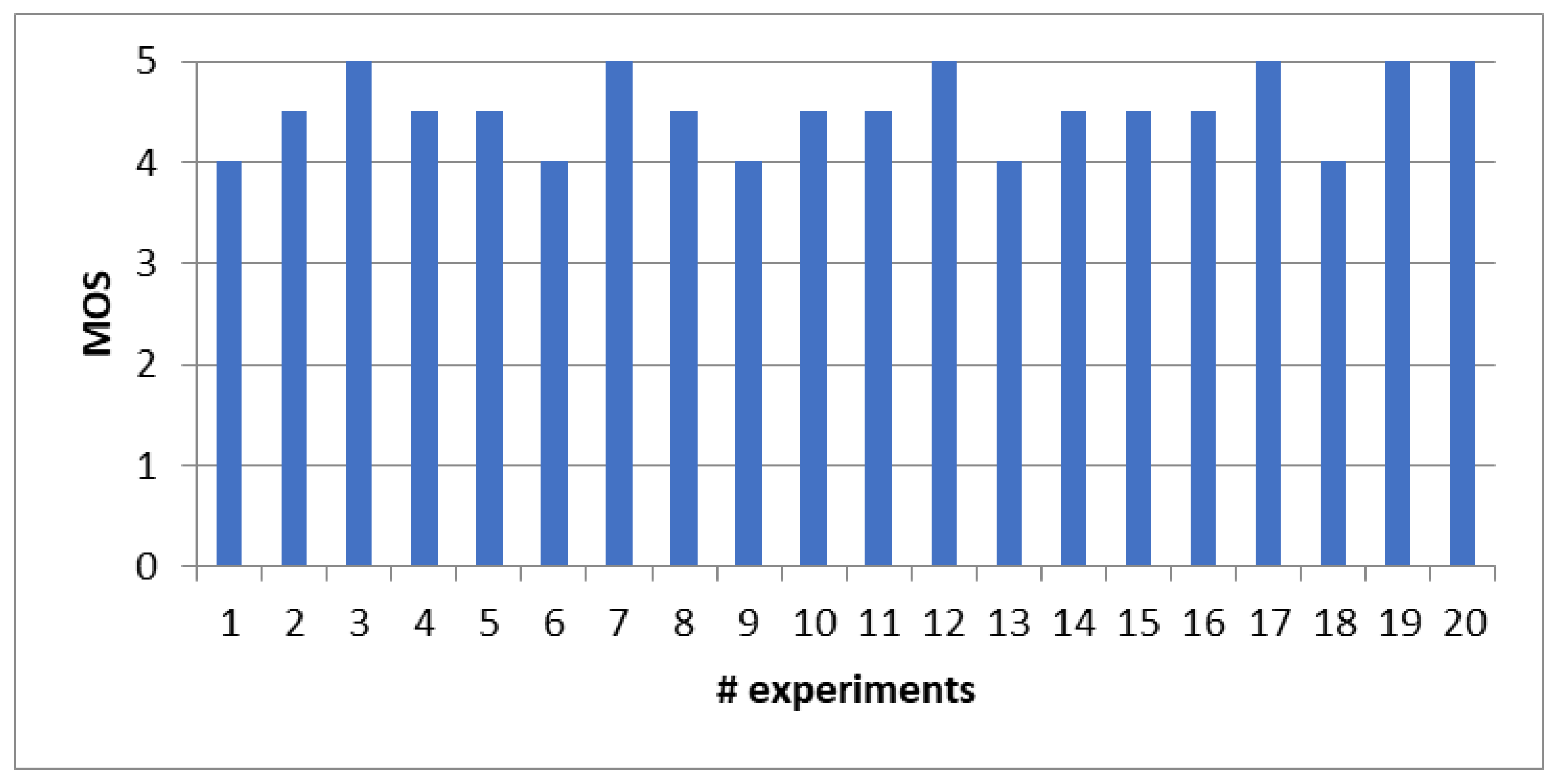
4. Performance Evaluation
- Network Dataset: This dataset is used to simulate network conditions, such as bandwidth, latency, and other network-related parameters. It contains data about network performance.
- Video Streaming Dataset: This dataset is used in a server-side component for video streaming, where video content is requested and streamed to users. It contains data about video files, user requests, and streaming performance.
- The SJTU HDR video sequences dataset consists of 15 ultra-high-definition (UHD) video sequences with a resolution of 4K (2160 p). Each video sequence is divided into segments of 2 s each. A buffer size of 30 s is maintained during playback. The video sequences are encoded using the high-efficiency video coding (HEVC) format and have a frame rate of 30 frames per second (fps).
- Network Dataset Norway contains network traces collected from Telenor’s 3G/HSDPA mobile wireless network in Norway. It accurately replicates real-world network conditions, capturing variations and characteristics commonly found in mobile networks.
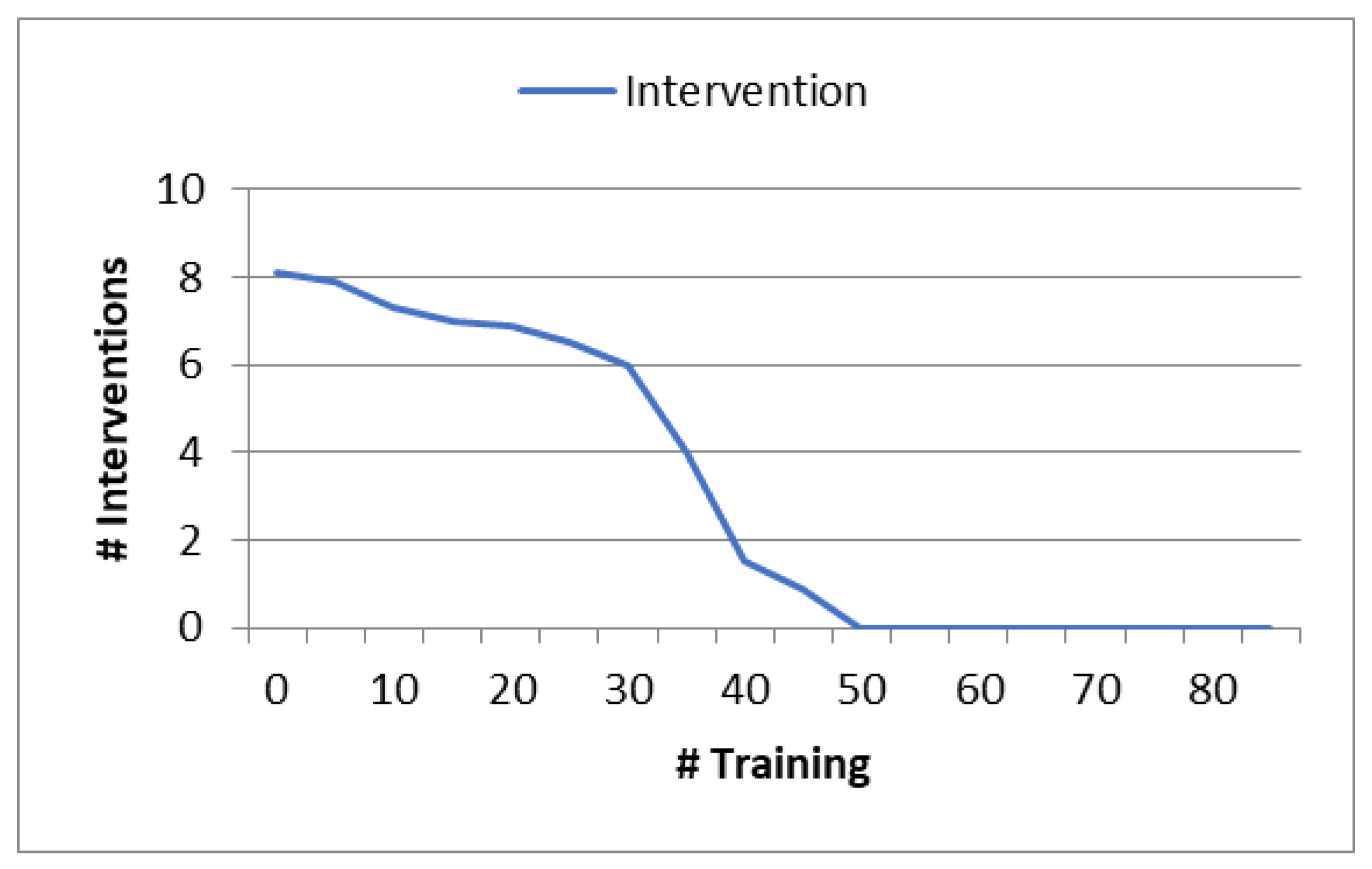
- Step 1—Individual Agent Training (Offline Mode): In this initial phase, the agent is trained alone using deep reinforcement learning (DRL). For this training phase, the datasets are randomly divided, with 70% of the video sequences from the video streaming dataset/Network Dataset Norway used for agent training, while the remaining 30% are reserved for testing the model’s performance. This phase equips the agent with the ability to learn and make decisions based on the training data.
- Step 2—Collaborative Agent Training (With a slave Agent): In the second step, the agent collaborates with a secondary agent, which plays a crucial role in enhancing the quality of streaming sessions. The slave agent works in collaboration with the main agent and corrects any erroneous decisions made by the latter. This collaborative approach leads to improved adaptation and decision-making processes.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Symbol | Meaning |
| V | Video set |
| Q | Set of different bitrates or qualities of a given video |
| S | Represent the user satisfaction |
| R | Reward function |
| Rt | Reward value obtained after a decision |
| Rb | Rebuffering |
| q | The quality of a segment |
| QHigh | High qualities set: Set of high qualities |
| QMedium | Medium qualities set: Set of medium qualities |
| QPoor | Poor qualities set: Set of Poor qualities |
| Bw | Bandwidth set |
| qt, Si | Quality t of segment i |
| The factor distance between qt and qt+1 | |
| Sd | Download time of segment |
| Sp | Playback time of segment |
| Avg_q | Average quality of total video segments |
| N | Total number of segments in a given video |
| QoEmax | The estimated QoE during a streaming session |
| QoE | Represents the normalized QoEmax |
| Buff_statet | Buffer state at time t |
| π | Policy |
| μ | Penalty of rebuffering |
| λ | Penalty of quality change |
References
- CISCO. Cisco Annual Internet Report (2018–2023). White Paper. 2020. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.pdf (accessed on 15 January 2022).
- ITU-T SG12; Definition of Quality of Experience (QoE); COM12–LS 62–E, TD 109rev2 (PLEN/12). ITU: Geneva, Switzerland, 2007.
- Slaney, M. Precision-Recall is Wrong for Multimedia. IEEE MultiMedia 2011, 18, 4–7. [Google Scholar] [CrossRef]
- Petrangeli, S.; Hooft, J.V.D.; Wauters, T.; Turck, F.D. Quality of experience-centric management of adaptive video streaming services: Status and challenges. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–29. [Google Scholar] [CrossRef]
- Akay, M.F.; Zayid, E.I.M.; Aktürk, E.; George, J.D. Artificial neural network-based model for predicting VO2max from a submaximal exercise test. Expert Syst. Appl. 2011, 38, 2007–2010. [Google Scholar] [CrossRef]
- Zhang, Y. Applications of Artificial Neural Networks (ANNs) in Several Different Materials Research Fields. Ph.D. Thesis, Queen Mary University of London, London, UK, 2010. [Google Scholar]
- Kerdvibulvech, C.; Saito, H. Vision-based detection of guitar players’ fingertips without markers. In Proceedings of the Computer Graphics, Imaging and Visualisation, Bangkok, Thailand, 14–17 August 2007; pp. 419–428. [Google Scholar] [CrossRef]
- Jung, E.; Kim, J.; Kim, M.; Jung, D.H.; Rhee, H.; Shin, J.-M.; Choi, K.; Kang, S.-K.; Kim, M.-K.; Yun, C.-H.; et al. Artificial neural network models for prediction of intestinal permeability of oligopeptides. BMC Bioinform. 2007, 8, 245. [Google Scholar] [CrossRef]
- Liu, C.-C.; Lin, C.-C.; Li, K.-C.; Chen, W.-S.E.; Chen, J.-C.; Yang, M.-T.; Yang, P.-C.; Chang, P.-C.; Chen, J.J. Genome-wide identification of specific oligonucleotides using artificial neural network and computational genomic analysis. BMC Bioinform. 2007, 8, 164. [Google Scholar] [CrossRef] [PubMed]
- Huang, T.Y.; Johari, R.; McKeown, N.; Trunnell, M.; Watson, M. A buffer-based approach to rate adaptation: Evidence from a large video streaming service. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; pp. 187–198. [Google Scholar] [CrossRef]
- Spiteri, K.; Urgaonkar, R.; Sitaraman, R.K. BOLA: Near-Optimal Bitrate Adaptation for Online Videos. IEEE/ACM Trans. Netw. 2020, 28, 1698–1711. [Google Scholar] [CrossRef]
- De Cicco, L.; Caldaralo, V.; Palmisano, V.; Mascolo, S. ELASTIC: A client-side controller for dynamic adaptive streaming over HTTP (DASH). In Proceedings of the 2013 20th International Packet Video Workshop, San Jose, CA, USA, 12–13 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Yin, X.; Jindal, A.; Sekar, V.; Sinopoli, B. A control-theoretic approach for dynamic adaptive video streaming over HTTP. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, London, UK, 17–21 August 2015; pp. 325–338. [Google Scholar] [CrossRef]
- Beben, A.; Wiśniewski, P.; Batalla, J.M.; Krawiec, P. ABMA+ is a lightweight and efficient algorithm for HTTP adaptive streaming. In Proceedings of the 7th International Conference on Multimedia Systems, Klagenfurt, Austria, 10–13 May 2016; pp. 1–11. [Google Scholar]
- Jiang, J.; Sekar, V.; Zhang, H. Improving fairness, efficiency, and stability in HTTP-based adaptive video streaming with festive. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies, Paris, France, 10–13 December 2012; pp. 97–108. [Google Scholar]
- Li, Z.; Zhu, X.; Gahm, J.; Pan, R.; Hu, H.; Begen, A.C.; Oran, D. Probe and Adapt: Rate Adaptation for HTTP Video Streaming At Scale. IEEE J. Sel. Areas Commun. 2014, 32, 719–733. [Google Scholar] [CrossRef]
- Mao, H.; Netravali, R.; Alizadeh, M. Neural Adaptive Video Streaming with Pensieve. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM 17), Los Angeles, CA, USA, 21–25 August 2017; pp. 197–210. [Google Scholar] [CrossRef]
- De Cicco, L.; Cilli, G.; Mascolo, S. Erudite: A deep neural network for optimal tuning of adaptive video streaming controllers. In Proceedings of the 10th ACM Multimedia Systems Conference, Amherst, MA, USA, 18–21 June 2019; pp. 13–24. [Google Scholar]
- Kheibari, B.; Sayıt, M. Quality estimation for DASH clients by using Deep Recurrent Neural Networks. In Proceedings of the 2020 16th International Conference on Network and Service Management (CNSM), Virtual, 2–6 November 2020; pp. 1–8. [Google Scholar]
- Du, L.; Zhuo, L.; Li, J.; Zhang, J.; Li, X.; Zhang, H. Video Quality of Experience Metric for Dynamic Adaptive Streaming Services Using DASH Standard and Deep Spatial-Temporal Representation of Video. Appl. Sci. 2020, 10, 1793. [Google Scholar] [CrossRef]
- Mao, H.; Chen, S.; Dimmery, D.; Singh, S.; Blaisdell, D.; Tian, Y.; Alizadeh, M.; Bakshy, E. Real-World Video Adaptation with Reinforcement Learning. arXiv 2020, arXiv:2008.12858. [Google Scholar]
- Fu, J.; Chen, X.; Zhang, Z.; Wu, S.; Chen, Z. 360SRL: A sequential reinforcement learning approach for ABR tile-based 360 video streaming. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 290–295. [Google Scholar] [CrossRef]
- Lekharu, A.; Moulii, K.Y.; Sur, A.; Sarkar, A. Deep learning-based prediction model for adaptive video streaming. In Proceedings of the 2020 International Conference on COMmunication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2020; pp. 152–159. [Google Scholar]
- Liu, L.; Hu, H.; Luo, Y.; Wen, Y. When Wireless Video Streaming Meets AI: A Deep Learning Approach. IEEE Wirel. Commun. 2019, 27, 127–133. [Google Scholar] [CrossRef]
- Liu, D.; Zhao, J.; Yang, C.; Hanzo, L. Accelerating Deep Reinforcement Learning With the Aid of Partial Model: Energy-Efficient Predictive Video Streaming. IEEE Trans. Wirel. Commun. 2021, 20, 3734–3748. [Google Scholar] [CrossRef]
- Gadaleta, M.; Chiariotti, F.; Rossi, M.; Zanella, A. D-DASH: A Deep Q-Learning Framework for DASH Video Streaming. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 703–718. [Google Scholar] [CrossRef]
- Huang, T.; Zhang, R.X.; Zhou, C.; Sun, L. QARC: Video quality aware rate control for real-time video streaming based on deep reinforcement learning. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1208–1216. [Google Scholar]
- Tian, Z.; Zhao, L.; Nie, L.; Chen, P.; Chen, S. Deeplive: QoE optimization for live video streaming through deep rein-forcement learning. In Proceedings of the 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 4–6 December 2019; pp. 827–831. [Google Scholar]
- Xiao, G.; Wu, M.; Shi, Q.; Zhou, Z.; Chen, X. DeepVR: Deep Reinforcement Learning for Predictive Panoramic Video Streaming. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1167–1177. [Google Scholar] [CrossRef]
- Lu, L.; Xiao, J.; Ni, W.; Du, H.; Zhang, D. Deep-Reinforcement-Learning-based User-Preference-Aware Rate Adaptation for Video Streaming. In Proceedings of the 2022 IEEE 23rd International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Belfast, UK, 14–17 June 2022; pp. 416–424. [Google Scholar] [CrossRef]
- Houidi, O.; Zeghlache, D.; Perrier, V.; Quang, P.T.A.; Huin, N.; Leguay, J.; Medagliani, P. Constrained Deep Reinforcement Learning for Smart Load Balancing. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), Virtual, 8–11 January 2022; pp. 207–215. [Google Scholar] [CrossRef]
- Ozcelik, I.M.; Ersoy, C. ALVS: Adaptive Live Video Streaming using deep reinforcement learning. J. Netw. Comput. Appl. 2022, 205, 103451. [Google Scholar] [CrossRef]
- Turkkan, B.O.; Dai, T.; Raman, A.; Kosar, T.; Chen, C.; Bulut, M.F.; Zola, J.; Sow, D. GreenABR: Energy-aware adaptive bitrate streaming with deep reinforcement learning. In Proceedings of the 13th ACM Multimedia Systems Conference, Athlone, Ireland, 14–17 June 2022; pp. 150–163. [Google Scholar] [CrossRef]
- Henrique, M.; Júnia, P.; Daniel, S.; Daniel, M.; Marcos, A.M.V. Improved Video Qoe in Wireless Networks Using Deep Reinforcement Learning. Available online: https://ssrn.com/abstract=4356698 (accessed on 10 April 2023).
- Hafez, N.A.; Hassan, M.S.; Landolsi, T. Reinforcement learning-based rate adaptation in dynamic video streaming. Telecommun. Syst. 2023, 83, 395–407. [Google Scholar] [CrossRef]
- Naresh, M.; Saxena, P.; Gupta, M. PPO-ABR: Proximal Policy Optimization based Deep Reinforcement Learning for Adaptive BitRate streaming. arXiv 2023, arXiv:2305.08114. [Google Scholar]
- Big Buck Bunny Movie. Available online: http://www.bigbuckbunny.org (accessed on 2 May 2021).
- Kang, J.; Chung, K. HTTP Adaptive Streaming Framework with Online Reinforcement Learning. Appl. Sci. 2022, 12, 7423. [Google Scholar] [CrossRef]
- Ismail, A.A.; Wood, T.; Bravo, H.C. Improving Long-Horizon Forecasts with Expectation-Biased LSTM Networks; Cornell University Library: Ithaca, NY, USA, 2018. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. Adv. Neural Inf. Process. Syst. 1992, 12, 2–5. [Google Scholar]
- Keras Documentation. Available online: https://keras.io (accessed on 26 December 2018).
- SJTU HDR Video Sequences. Available online: https://medialab.sjtu.edu.cn/files/SJTU%20HDR%20Video%20Sequences/ (accessed on 3 July 2023).
- Riiser, H.; Vigmostad, P.; Griwodz, C.; Halvorsen, P. Commute path bandwidth traces from 3G networks: Analysis and applications. In Proceedings of the 4th ACM Multimedia Systems Conference, Oslo, Norway, 28 February–1 March 2013; pp. 114–118. [Google Scholar]
- Recommendation ITU-T P.800.1. Series P: Terminals and Subjective and Objective Assessment Methods: Methods for Objective and Subjective Assessment of Speech and Video Quality, Mean Opinion Score (MOS) Terminology; ITU: Geneva, Switzerland, 2016. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quality | High Quality | Medium Quality | Poor Quality |
|---|---|---|---|
| High quality | 0 | −1 | −2 |
| Medium quality | 1 | 0 | −1 |
| Poor quality | 2 | 1 | 0 |
| St = S | R (St = S) | |
|---|---|---|
| (qt, qt−1) ϵ Q | //qt and qt−1 are in the same quality set | 1 |
| (qt) ϵ Qhigh | //qt is in the high-quality set | 0.75 |
| (qt) ϵ Qmeduim | //qt is in the medium-quality set | 0.50 |
| (qt) ϵ Qpoor | //qt is in the poor-quality set | −1 |
| Rbt = 0 | //No rebuffering | 1 |
| Rbt > 0 | //rebuffering event occurs | −1 |
| (qt, qt−1) ∉ Q | //qt and qt−1 are not in the same quality set | −1 |
| Simulation Parameter | Description | Value |
|---|---|---|
| Discount factor | 0.99 | |
| λ | Penalty of the rebuffering | −1 |
| μ | Penalties of the change of quality | −1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Souane, N.; Bourenane, M.; Douga, Y. Deep Reinforcement Learning-Based Approach for Video Streaming: Dynamic Adaptive Video Streaming over HTTP. Appl. Sci. 2023, 13, 11697. https://doi.org/10.3390/app132111697
Souane N, Bourenane M, Douga Y. Deep Reinforcement Learning-Based Approach for Video Streaming: Dynamic Adaptive Video Streaming over HTTP. Applied Sciences. 2023; 13(21):11697. https://doi.org/10.3390/app132111697
Chicago/Turabian StyleSouane, Naima, Malika Bourenane, and Yassine Douga. 2023. "Deep Reinforcement Learning-Based Approach for Video Streaming: Dynamic Adaptive Video Streaming over HTTP" Applied Sciences 13, no. 21: 11697. https://doi.org/10.3390/app132111697
APA StyleSouane, N., Bourenane, M., & Douga, Y. (2023). Deep Reinforcement Learning-Based Approach for Video Streaming: Dynamic Adaptive Video Streaming over HTTP. Applied Sciences, 13(21), 11697. https://doi.org/10.3390/app132111697