
A Person Re-Identification Method Based on Multi-Branch Feature Fusion




Abstract
:1. Introduction
2. Related Work
2.1. Transformer in Vision
2.2. Attention Mechanism
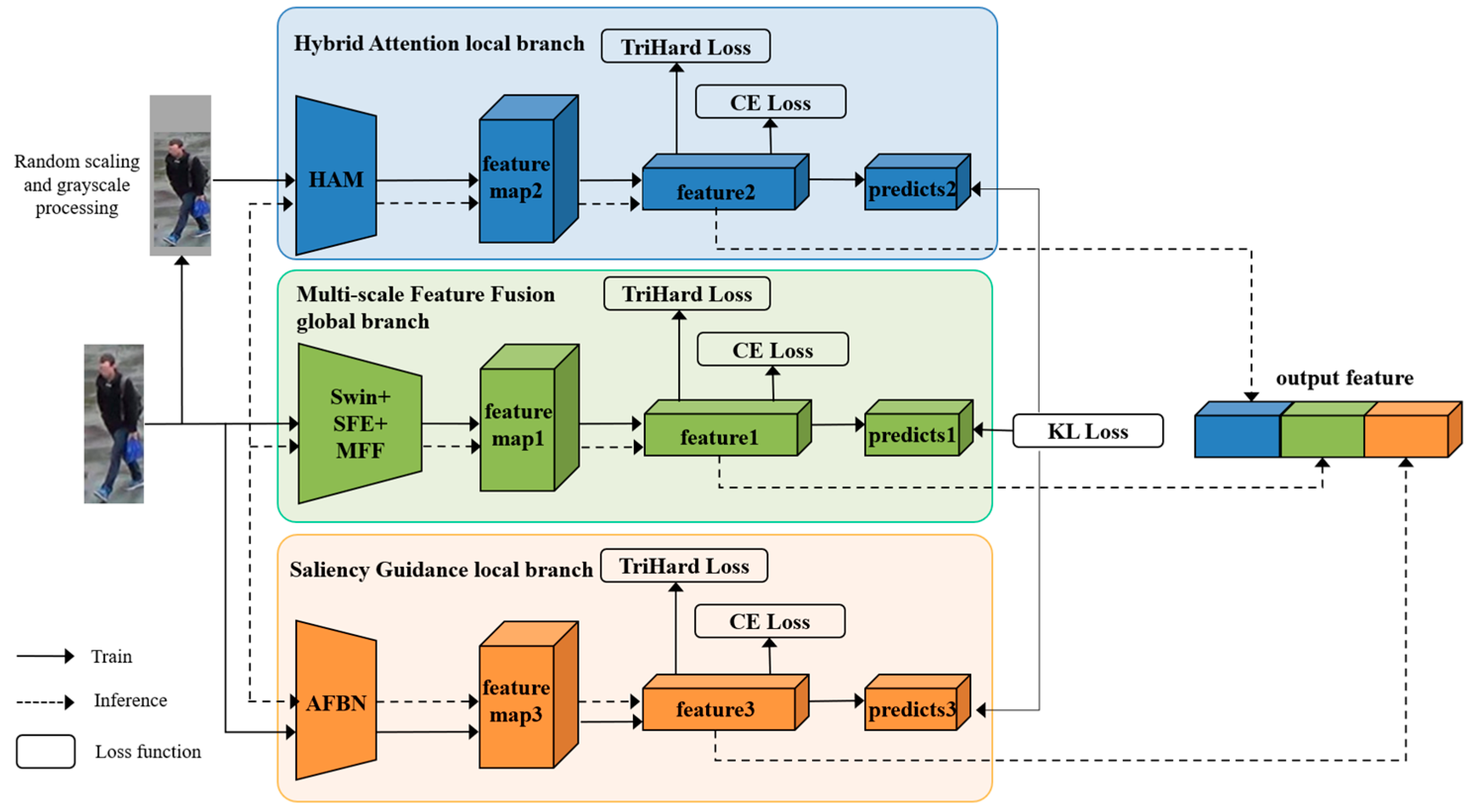
3. Multi-Branch Feature Fusion Network
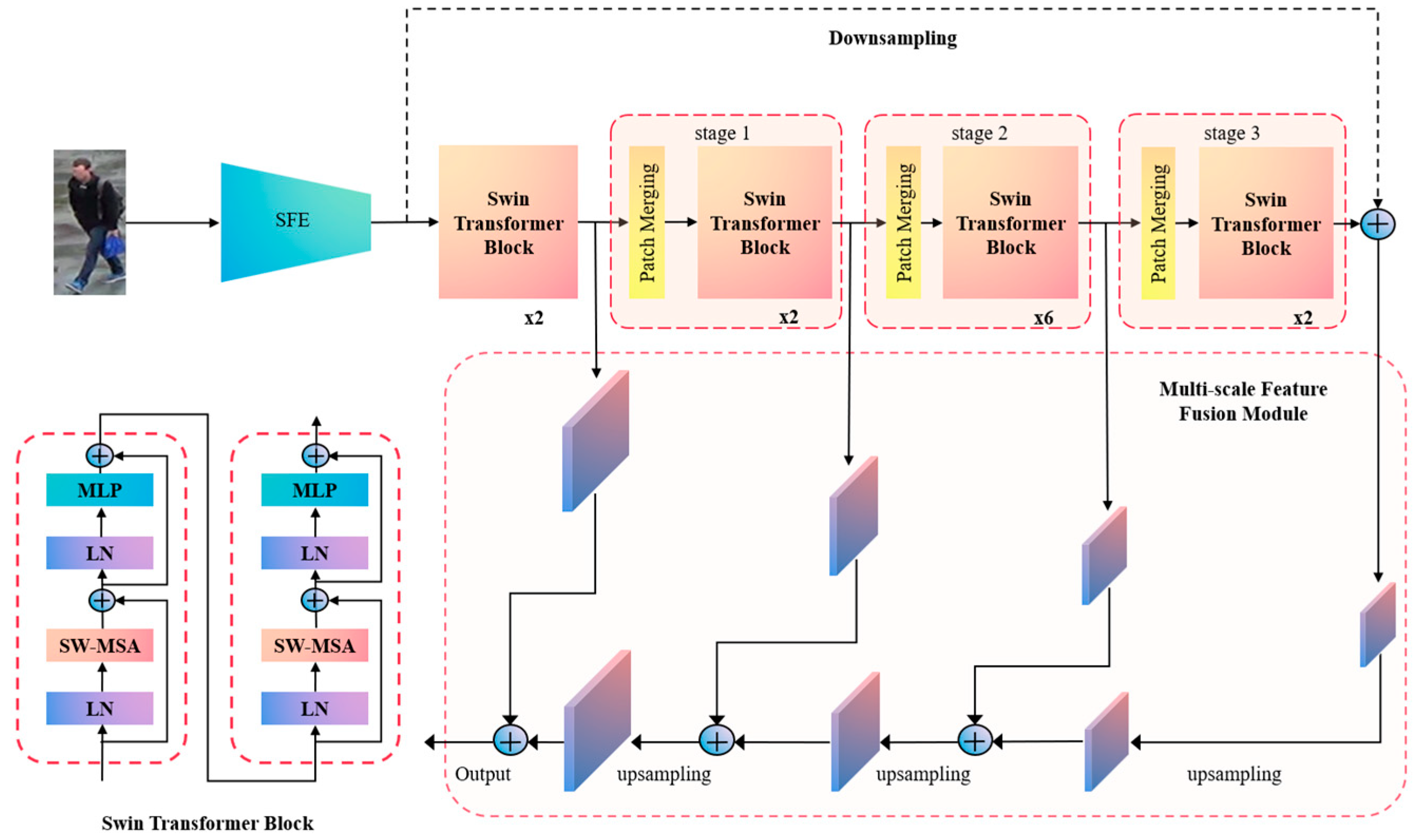
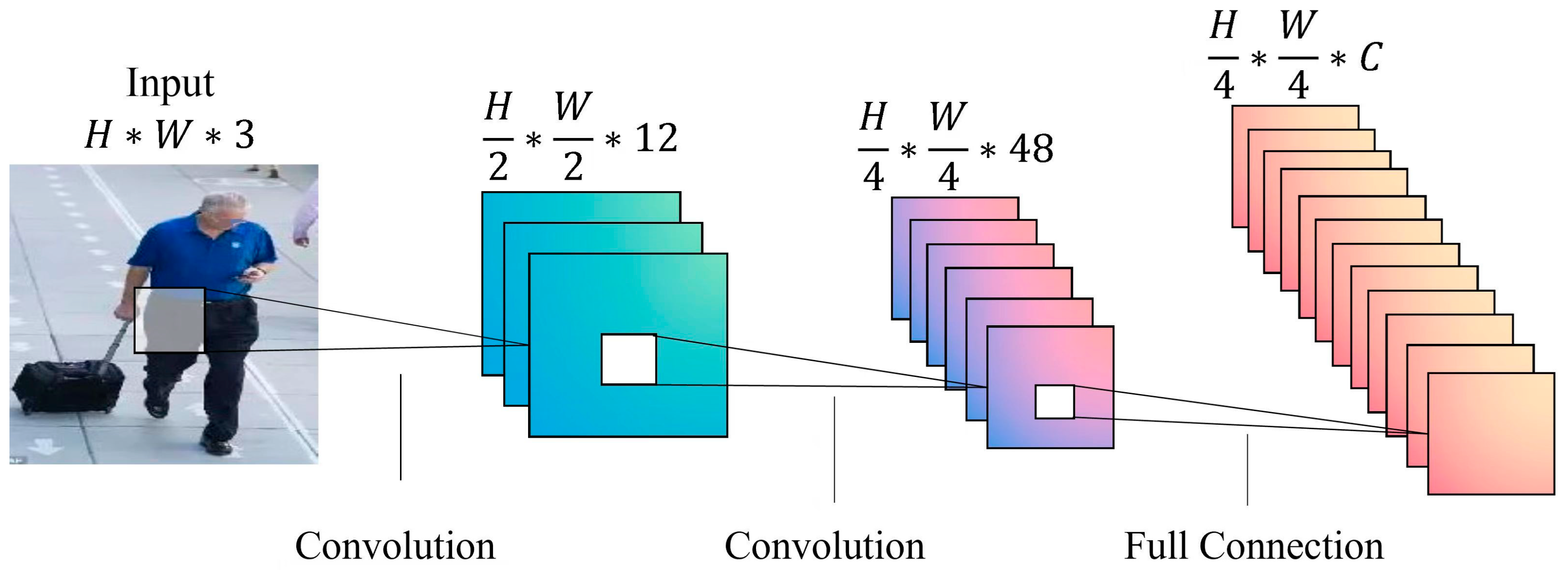
3.1. Multi-Scale Feature Fusion Global Branch
- (1)
- (2)
- Multi-scale Feature Fusion (MFF). The backbone network employs a layer-by-layer abstraction approach to extract the target features, progressively expanding the field of view of the feature map through convolution and downsampling algorithms. Incorporating the concept of a feature pyramid [42], we introduce a multi-scale fusion module to enhance feature representations at various levels, capturing both local fine-grained features and global feature information of pedestrians. Additionally, this module is compatible with different scales of the Swin Transformer models.
3.2. Hybrid Attention Local Branch
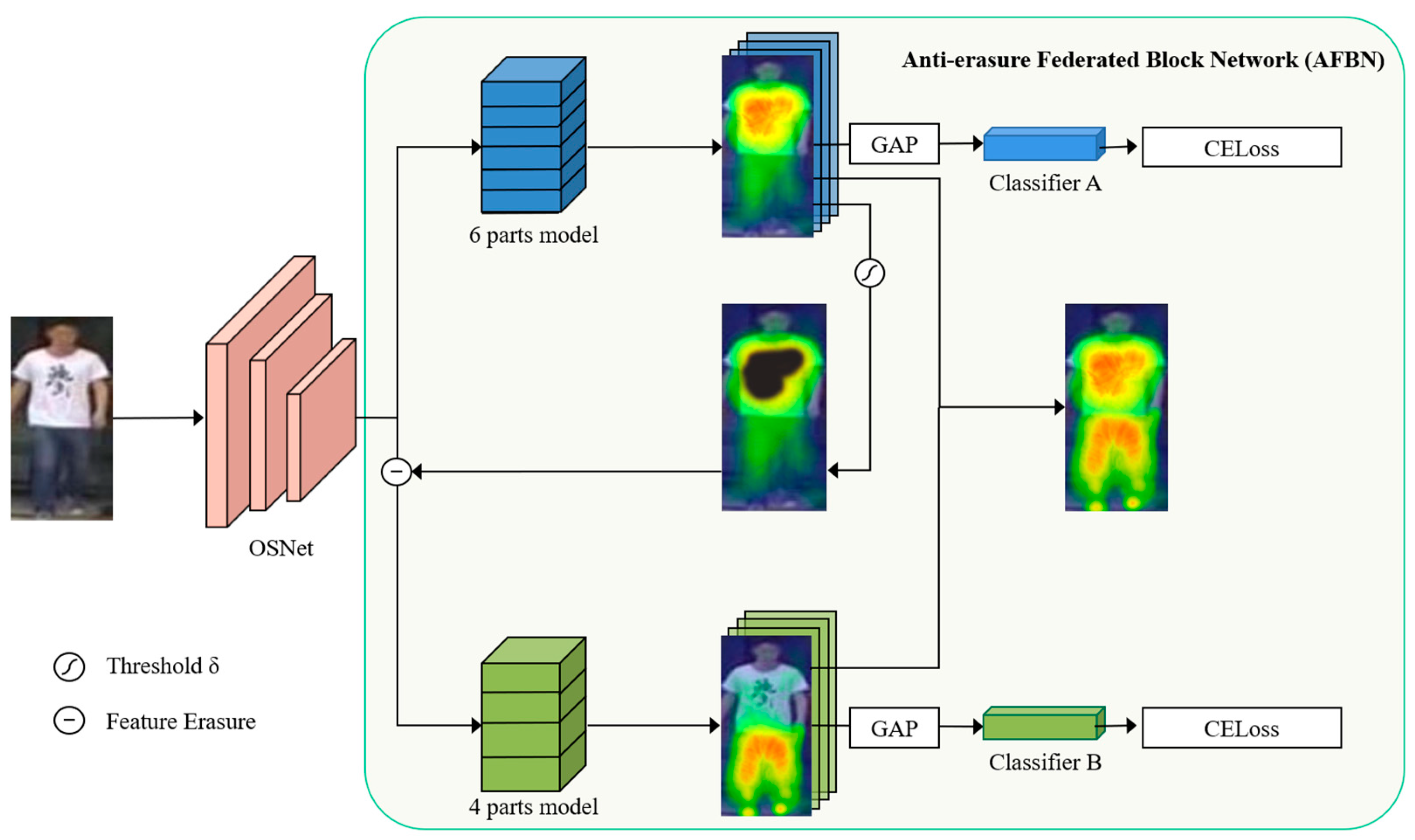
3.3. Saliency Guidance Local Branch
| Algorithm 1: AFBN |
| Input: Training data , threshold |
| 1: while training does not converge do |
| 2: ⊳ Extract initial features |
| 3: ⊳ Extract features |
| 4: : ⊳ Obtain high discriminative regions |
| 5: ⊳ Obtain erased features |
| 6: ⊳ Extract features |
| 7: ⊳ Obtain fusion feature |
| 8: end while |
| Output: |
3.4. Multiple Loss
4. Experiments
4.1. Datasets
4.2. Experimental Parameters
4.3. Experimental Results
4.4. Ablation Studies
4.5. Discussions
5. Conclusions and Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qian, X.; Fu, Y.; Jiang, Y.-G.; Xiang, T.; Xue, X. Multi-scale deep learning architectures for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, F.; Zuo, W.; Lin, L.; Zhang, D.; Zhang, L. Joint learning of single-image and cross-image representations for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Wu, L.; Shen, C.; Hengel, A.v.d. Personnet: Person re-identification with deep convolutional neural networks. arXiv 2016, arXiv:1601.07255. [Google Scholar]
- Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Yao, Z.; Huang, T. Horizontal pyramid matching for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Miao, J.; Wu, Y.; Liu, P.; Ding, Y.; Yang, Y. Pose-guided feature alignment for occluded person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liao, K.; Wang, K.; Zheng, Y.; Lin, G.; Cao, C. Multi-scale saliency features fusion model for person re-identification. Multimed. Tools Appl. 2023, 1–16. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Ren, Z.; Wang, Z. Abd-net: Attentive but diverse person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Jia, M.; Sun, Y.; Zhai, Y.; Cheng, X.; Yang, Y.; Li, Y. Semi-attention Partition for Occluded Person Re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Ning, X.; Gong, K.; Li, W.; Zhang, L. JWSAA: Joint weak saliency and attention aware for person re-identification. Neurocomputing 2021, 453, 801–811. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, H.; Liu, S. Person re-identification using heterogeneous local graph attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, X.; Fu, C.; Zhao, Y.; Zheng, F.; Song, J.; Ji, R.; Yang, Y. Salience-guided cascaded suppression network for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020. [Google Scholar]
- Yao, H.; Zhang, S.; Hong, R.; Zhang, Y.; Xu, C.; Tian, Q. Deep representation learning with part loss for person re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Chen, C.; Chen, Y.; Zhang, H.; Zheng, Y. Transformer-based global-local feature learning model for occluded person re-identification. J. Vis. Commun. Image Represent. 2023, 95, 103898. [Google Scholar] [CrossRef]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018. [Google Scholar]
- Ming, Z.; Yang, Y.; Wei, X.; Yan, J.; Wang, X.; Wang, F.; Zhu, M. Global-local dynamic feature alignment network for person re-identification. arXiv 2021, arXiv:2109.05759. [Google Scholar]
- Li, X.; Zheng, W.-S.; Wang, X.; Xiang, T.; Gong, S. Multi-scale learning for low-resolution person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Wang, Y.; Wang, L.; You, Y.; Zou, X.; Chen, V.; Li, S.; Huang, G.; Hariharan, B.; Weinberger, K.Q. Resource aware person re-identification across multiple resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Huang, Y.; Zha, Z.-J.; Fu, X.; Zhang, W. Illumination-invariant person re-identification. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Zhang, G.; Luo, Z.; Chen, Y.; Zheng, Y.; Lin, W. Illumination unification for person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6766–6777. [Google Scholar] [CrossRef]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Vrstc: Occlusion-free video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Huang, H.; Li, D.; Zhang, Z.; Chen, X.; Huang, K. Adversarially occluded samples for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Z.; Zhu, F.; Tang, S.; Zhao, R.; He, L.; Song, J. Feature erasing and diffusion network for occluded person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Chen, B.; Deng, W.; Hu, J. Mixed high-order attention network for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, J.; Jiang, X.; Wang, F.; Zhang, J.; Zheng, F.; Sun, X.; Zheng, W.-S. Learning 3D shape feature for texture-insensitive person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Jin, X.; Lan, C.; Zeng, W.; Chen, Z.; Zhang, L. Style normalization and restitution for generalizable person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020. [Google Scholar]
- Li, H.; Wu, G.; Zheng, W.-S. Combined depth space based architecture search for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Quan, R.; Dong, X.; Wu, Y.; Zhu, L.; Yang, Y. Auto-reid: Searching for a part-aware convnet for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. Svdnet for pedestrian retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, P.; Zhao, Z.; Su, F.; Zu, X.; Boulgouris, N.V. HOReID: Deep high-order mapping enhances pose alignment for person re-identification. IEEE Trans. Image Process. 2021, 30, 2908–2922. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Zou, W. Fusion pose guidance and transformer feature enhancement for person re-identification. Multimed. Tools Appl. 2023, 1–19. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Bu, J.; Tian, Q. Person re-identification meets image search. arXiv 2015, arXiv:1502.02171. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 26–27 June 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
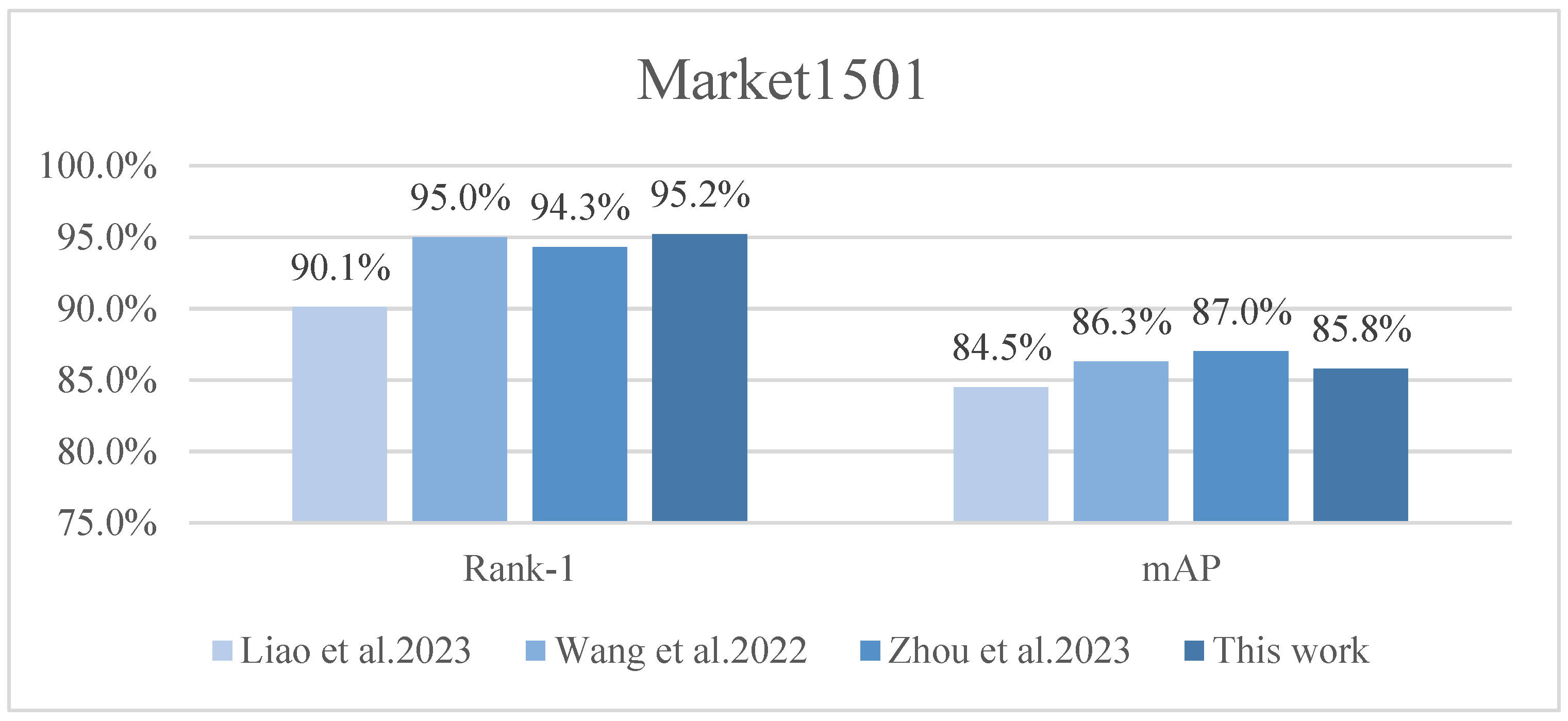
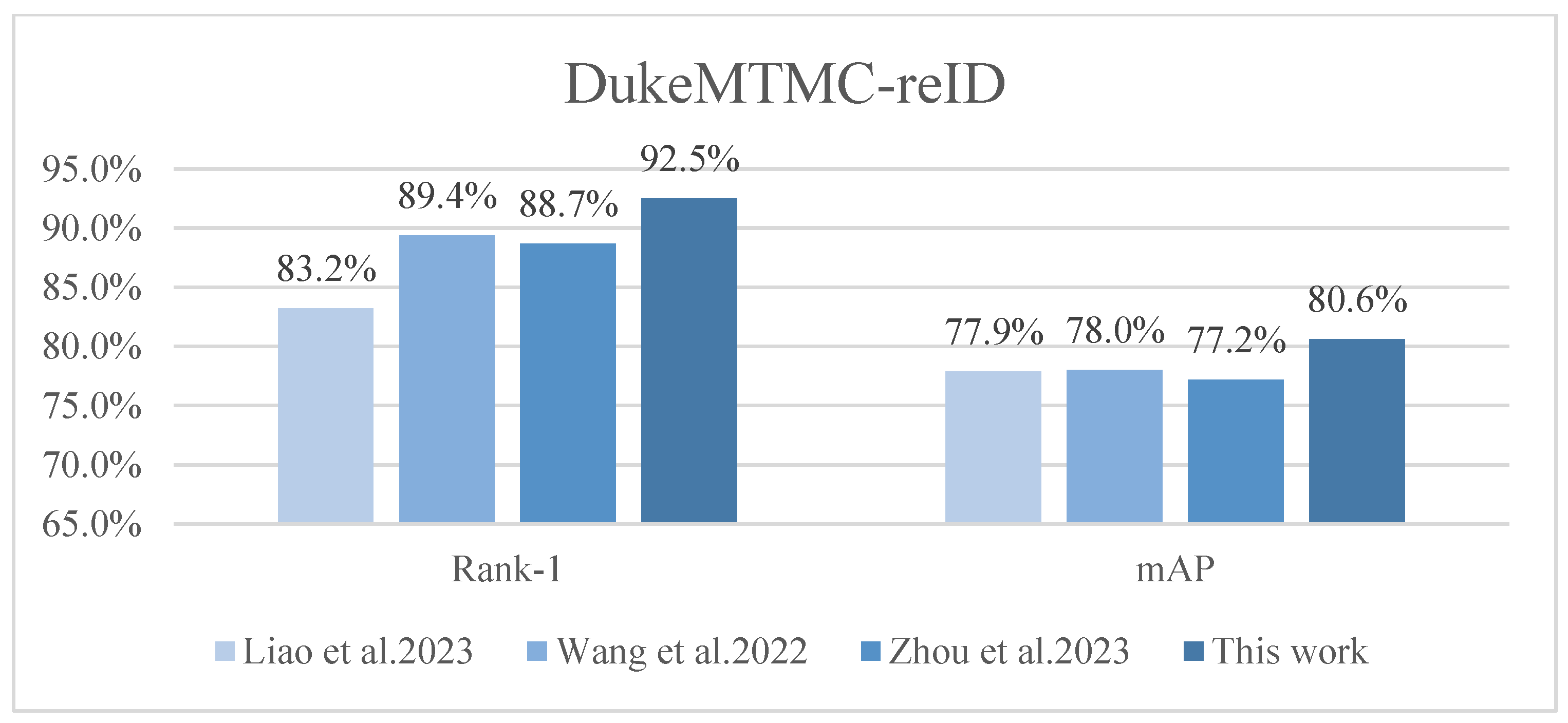
| Method | Venue | Market-1501 | DukeMTMC-reID | MSMT17 | |||
|---|---|---|---|---|---|---|---|
| Rank-1/% | mAP/% | Rank-1/% | mAP/% | Rank-1/% | mAP/% | ||
| SVDNet [31] | ICCV 17 | 82.3 | 62.1 | 76.7 | 56.8 | - | - |
| PCB [32] | ECCV18 | 92.3 | 77.4 | 81.7 | 66.1 | - | - |
| PCB+RPP [32] | ECCV18 | 93.8 | 81.6 | 83.3 | 69.2 | - | - |
| MHN [26] | CVPR19 | 95.1 | 85.0 | 89.1 | 77.2 | - | - |
| Auto-ReID [30] | ICCV19 | 94.5 | 85.1 | 88.5 | 75.1 | 78.2 | 52.5 |
| OSNet [8] | ICCV19 | 94.8 | 84.9 | 88.6 | 73.5 | 78.7 | 52.9 |
| HOReID [33] | CVPR20 | 94.2 | 84.9 | 86.9 | 75.6 | 78.4 | 54.8 |
| SNR [28] | CVPR20 | 94.4 | 84.7 | 84.4 | 72.9 | - | - |
| CDNet [29] | CVPR21 | 95.1 | 86.0 | 88.6 | 76.8 | 78.9 | 54.7 |
| L3DS [27] | CVPR21 | 95.0 | 87.3 | 88.2 | 76.1 | - | - |
| FED [25] | CVPR22 | 95.0 | 86.3 | 89.4 | 78.0 | - | - |
| IER+MTOR [22] | IEEE22 | 90.2 | 75.5 | 82.6 | 66.4 | - | - |
| FPTE [34] | Springer23 | 94.3 | 87.0 | 88.7 | 77.2 | - | - |
| MFFNet | This work | 95.2 | 85.8 | 92.5 | 80.6 | 80.2 | 56.6 |
| Model | Standard Scene | Occlusion Scene | The Scene with Illumination Difference and Scale Change |
|---|---|---|---|
| Input |  |  |  |
| ResNet50 [48] |  |  | 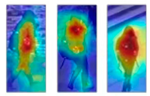 |
| Swin Transformer [37] |  |  | 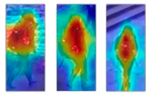 |
| MFFNet |  |  |  |
| Branch | Rank-1/% | mAP/% |
|---|---|---|
| Multi-scale Fusion global branch | 78.3 | 52.7 |
| Multi-scale Fusion global branch + Hybrid Attention local branch | 79.1 | 53.8 |
| Multi-scale Fusion global branch + Saliency Guidance local branch | 79.5 | 55.3 |
| Multi-scale Fusion global branch + Hybrid Attention local branch + Saliency Guidance local branch | 80.2 | 56.6 |
| Method | Rank-1/% | mAP/% |
|---|---|---|
| Swin Transformer | 77.0 | 51.5 |
| Swin Transformer + SFE | 77.2 | 51.8 |
| Swin Transformer + MFF | 78.1 | 52.3 |
| Swin Transformer + SFE + MFF | 78.3 | 52.7 |
| Method | Rank-1/% | mAP/% |
|---|---|---|
| OSNet | 78.3 | 52.8 |
| OSNet + Standard Fusion Attention Module | 78.9 | 53.6 |
| OSNet + HAM | 79.1 | 53.8 |
| Method | Rank-1/% | mAP/% |
|---|---|---|
| OSNet | 78.3 | 52.8 |
| Random Erasing | 78.5 | 52.8 |
| Adversarial Erasing | 78.8 | 53.9 |
| Random Erasing + partitioned network | 79.0 | 54.3 |
| Adversarial Erasing + partitioned network (AFBN) | 79.5 | 55.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Hu, X.; Liu, P.; Tang, R. A Person Re-Identification Method Based on Multi-Branch Feature Fusion. Appl. Sci. 2023, 13, 11707. https://doi.org/10.3390/app132111707
Wang X, Hu X, Liu P, Tang R. A Person Re-Identification Method Based on Multi-Branch Feature Fusion. Applied Sciences. 2023; 13(21):11707. https://doi.org/10.3390/app132111707
Chicago/Turabian StyleWang, Xuefang, Xintong Hu, Peishun Liu, and Ruichun Tang. 2023. "A Person Re-Identification Method Based on Multi-Branch Feature Fusion" Applied Sciences 13, no. 21: 11707. https://doi.org/10.3390/app132111707
APA StyleWang, X., Hu, X., Liu, P., & Tang, R. (2023). A Person Re-Identification Method Based on Multi-Branch Feature Fusion. Applied Sciences, 13(21), 11707. https://doi.org/10.3390/app132111707