Abstract
Virtual 3D fashion fitting, commonly referred to as 2D virtual try-on, has garnered significant attention due to its potential to revolutionize the way consumers interact with fashion items online. This paper presents a novel approach to virtual try-on utilizing a deep learning framework built upon the concept of appearance flow. Our proposed method improves the existing state-of-the-art techniques by seamlessly integrating natural cloth folds, shadows, and intricate textures, such as letters and comic characters, into the synthesized virtual try-on images. Building upon the advancements of previous research, our approach introduces a multi-faceted transformation strategy that operates at both the pixel and image patch levels. Our method’s effectiveness is demonstrated through extensive experiments and comparisons with existing virtual try-on techniques. The results showcase a substantial improvement in the synthesis of virtual try-on images with natural-looking cloth folds, realistic shadows, and intricate textures.
1. Introduction
Virtual try-on technology, which generates images of people wearing desired clothing items, has become a key application in online shopping. Broadly, the virtual try-on problem can be divided into two sub-problems: warping the target clothing item (the “warping process”) and integrating it onto a human body (the “try-on process”). The warping process adjusts the clothing item based on pose information to align it with the human figure. The try-on process then merges this warped clothing item onto an image of the person to produce the final output.
Typically, pixelwise warping techniques, such as Thin-Plate Spline (TPS) warping and appearance flow, are used in the warping process [1,2,3,4,5,6,7,8]. These techniques focus on pixelwise mapping to the original clothing image, making them robust for preserving details like logos. However, they often fail to maintain contextual features such as shadows or fabric folds, mainly because the original clothing images usually lack the color range to represent these features.
The try-on process integrates the warped cloth onto the person image. Simultaneously, this process also refines the warped cloth to retain the contextual features. However, since this process commonly adopts conditional generative models [9,10], we found that this generative process tends to compromise the detail of logos.
Additionally, this process typically necessitates a cloth-agnostic person image, meaning that the clothing part is removed. This requirement arises due to constraints in data collection. In practical scenarios, collecting paired images of the same person in different outfits, but with exactly identical poses is difficult. Therefore, the available data often consist of paired images of a cloth and a person wearing that cloth. This limitation forces the use of cloth-agnostic person images to ensure that the model is not provided with ground truth person images already wearing the clothing during the training phase. While the use of this cloth-agnostic image is highly practical, it prevents layering an outer clothing item over an inner one.
In this work, we aimed to address the preservation of both logos and contextual features by reversing the traditional try-on process: we used a generative model for warping and an appearance-flow-based method to refine logos. Specifically, for the warping process, we propose to utilize the appearance-flow-based feature transformation at multiple levels for accurately aligning clothes with the person’s pose. Since this generative process often blurs the logos, we complemented it by substituting the blurred logos with their counterparts from the warped clothes at the pixel level.
Another important issue we focused on is enabling the layering of clothes. To achieve this, we need to exclude the use of cloth-agnostic images in the generative process. However, this exclusion might lead to a decrease in the quality of contextual features, as the cloth-agnostic image can provide a rich context. To relieve the loss of the contextual information, we propose to utilize a cloth segmentation map instead of just a cloth mask. Our cloth segmentation map involves segmentation masks for each part of a cloth (e.g., left, right arms, and torso for the upper clothing case), which offer more information for generating the contextual features.
We assessed the effectiveness of our approach both qualitatively and quantitatively, comparing it to state-of-the-art methods such as HR-VITON [8] and Flow-Style VTON [6]. Our experiments indicated that our approach can produce more-realistic outcomes and achieves superior performance to other baseline methods. Furthermore, we argue that the Zalando dataset [1], frequently used in virtual try-on research, is well-curated, lacking practical applicability in real-world scenarios. Hence, we utilized the more-realistic dataset, the Korean fashion dataset from AIHub [11], thereby strengthening the practical relevance of our work.
Our contributions can be organized as follows:
- We propose to warp clothing items using a generative approach and refine them using pixel-level appearance flow. In contrast to previous works, this approach is more robust in preserving the intricate details of clothing, such as logos, textures, and realistic shadows.
- In warping clothing items, we propose using feature-level appearance flow at multiple levels. This is a coarse-to-fine approach, where it warps the clothes at a lower resolution and, then, refines them at a higher resolution.
- Since our method preserves contextual features during the warping process, we can exclude cloth-agnostic person images for refining the warped clothes. This capability makes layering clothes possible.
- In our experiments, we confirmed that our method yields more-realistic outcomes than established state-of-the-art techniques like Flow-Style VTON and HR-VITON. Moreover, our approach outperformed other baseline methods in quantitative performance.
2. Related Works
In this section, we will briefly discuss the research trends in 2D image-based virtual try-on, which can be distinguished into three main categories depending on the method of warping clothes: the TPS-based approaches, the appearance-flow-based approaches, and the GAN-based approaches, respectively.
2.1. Thin-Plate Spline-Based Virtual Try-On
VITON [1] is a pioneering research study addressing the virtual try-on problem using TPS warping and a deep generative model. CP-VITON [2], a subsequent work to VITON, aimed at reconstructing the characteristics of clothing items by removing the coarse-to-fine strategy. CP-VITON+ [3] improved CP-VITON by refining the dataset, network structures, and loss functions. Furthermore, Reference [12] addressed the issue of missing body parts in generated images by utilizing human parsing to maintain consistency between the original images and the generated images. ACGPN [13] regarded the virtual try-on problem as an inpainting task, where they first warped clothing items using TPS warping and subsequently inpainted the masked person images. Other studies that used the TPS for warping clothes include LM-VTON [14] and PG-VTON [15]. They utilized additional guidance, such as clothing landmarks or predicted parsing maps, to achieve more-accurate warping. While [16] also utilized landmarks as the guidance, it additionally addressed the warping of multi-category clothing items. However, their generated images were limited to a resolution of . VITON-HD [7] proposed a high-resolution virtual try-on network, which can generate images up to a resolution of .
2.2. Appearance-Flow-Based Virtual Try-On
Appearance-flow-based virtual try-on methods such as [4,5,6,8] aim to warp clothing images according to the target human pose. This process involves utilizing 2D coordinates from the source image to facilitate the accurate transformation. While ClothFlow [5] was proposed to solve the pose transfer problem, which adjusts a person image into a specific pose while preserving his (or her) clothes, they demonstrated that their method can be applicable to the virtual try-on task. They used appearance flow to deform the clothes of a person. PF-AFN [4] first trained the parser-based try-on network, denoted as PB-AFN, which utilizes parsing maps and pose information to generate the try-on image. Subsequently, they distilled the knowledge of PB-AFN into PF-AFN, which only takes a person and a clothing item. Consequently, during the inference phase, they only required a pair of images, a clothing image and a person image. Flow-Style VTON [6] proposed using StyleGAN [17,18] for estimating the flow fields to utilize global style information. HR-VITON [8] is another research work that adopted the appearance flow for warping clothes. They estimated the flow fields and segmentation mask simultaneously, motivated by the idea that flow field estimation and the segmentation prediction should share a substantial amount of information.
2.3. GAN-Based Virtual Try-On
Poly-GAN [19] utilizes a fully generative approach from the warping of clothes to the refinement phase. The main characteristic of this work is its use of the same architecture for warping clothes, stitching, and refining them to align them onto human bodies. DCTON [20] incorporated cycle consistency [21] for training their model. Reference [22] extended other works to fit bottom clothes, as well as upper clothes. TryOnGAN [23] proposed a latent interpolation-based try-on method, which generates the try-on images by interpolating the StyleGAN style vectors of the input images.
3. Background
3.1. Appearance Flow
Appearance flow [24] was initially introduced for synthesizing novel views by warping an image using a flow field. The flow field refers to vectors that map the spatial coordinates from one view to another. The flow fields are often learned through machine learning techniques, allowing for more-accurate and -flexible view generation.
Let and be different views of one object and be a warping operator using a flow field . To estimate , which maps from to , we can minimize the distance between the target view and the warped view as follows:
Virtual try-on can be considered a specific application of novel view synthesis, where the goal is to generate new perspectives of a cloth image. For this reason, many studies [4,5,6,8] have utilized appearance flow to warp a clothing item to align it with the target pose. However, in virtual try-on, additional factors such as cloth folds or human pose should be taken into account, making the problem more challenging.
3.2. Generative Adversarial Network
A Generative Adversarial Network (GAN) [10] is a generative model for synthesizing artificial images. GAN consists of two key components: a generator and a discriminator. The generator learns to generate fake images by fooling the discriminator, while the discriminator learns to distinguish them from real images. The objective of GAN can be written as follows:
where D and G represent the discriminator and the generator, respectively. x is real data, and is a generated image using Gaussian noise z.
As an extension of GAN, the conditional generative adversarial network (cGAN) [9] generates images based on specific conditions, such as semantic segmentation maps or other references. Unlike vanilla GAN, cGAN can generate more-realistic and -varied images. The loss function for cGAN is very similar to that of vanilla GAN, with the main difference being the addition of conditional inputs to both the generator and the discriminator.
where c is the conditional input. In many real-world scenarios, including virtual try-on, cGAN is frequently utilized to synthesize images meeting their conditions or references.
4. Approach
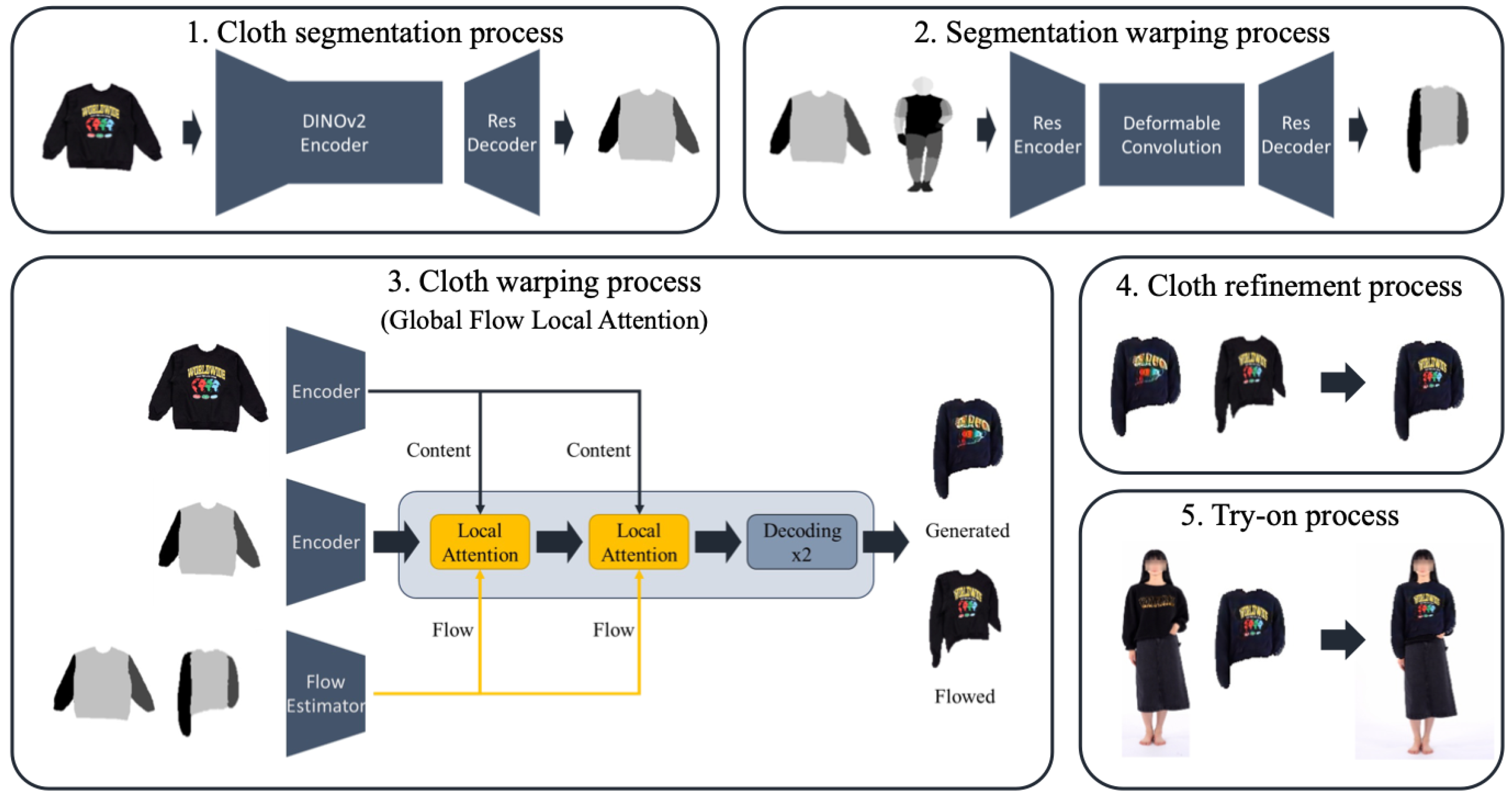
Let be an image of a person p wearing a clothing item . Given the person image and another clothing item (a target cloth), our approach aims to generate an image of the person p wearing . To achieve this, we divided the virtual try-on process into five sub-processes: (1) cloth segmentation process, (2) segmentation warping process, (3) cloth warping process, (4) cloth refinement process, and finally, (5) try-on process. Figure 1 showcases an overview of our approach.
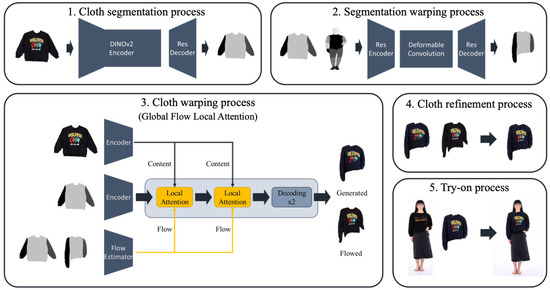
Figure 1.
Overview of our approach, involving five sub-processes: (1) the cloth segmentation process, (2) the cloth segmentation warping process, (3) the cloth warping process, (4) the cloth refinement process, and (5) the try-on process.
Before proceeding to the description of each procedure, we briefly explain the dataset used for training our approach. The training dataset can be represented as a set of tuples, each consisting of six items: , where , , and denote the DensePose [25] representation of the person p, a cloth segmentation map for , and a warped cloth segmentation map aligned with the person’s pose, respectively. corresponds to the category of the clothing item , determining it as one of four categories, outer, inner, pants, and skirt. All items, except for , were included in the dataset we used. For the DensePose representation, we used the DensePose implementation [26] to estimate it. In the training phase, we utilized a cloth image and a person image wearing that clothing item, as well as the segmentation masks and the category information. In the inference phase, however, only pairs of images, , are required, with not necessarily being the same as . The other items, , , , and , are estimated through our try-on processes. We will explain these processes step-by-step in the subsequent sub-sections.
4.1. Cloth Segmentation Process
This process is responsible for estimating a cloth segmentation map of a clothing item and determining its category . We implemented a cloth segmentation network, which is composed of two components, the DINOv2 encoder [27] and the residual decoder, as depicted in Figure 1. This cloth segmentation network is trained using the following loss function:
where CE represents the cross-entropy loss function, corresponds to the model’s predictions for the clothing category of , is the estimated cloth segmentation map, and denotes the discriminator, respectively. As indicated in the loss function, we also employed the Least Squares adversarial loss [10,28].
4.2. Cloth Segmentation Warping Process
Given the cloth segmentation map for the clothing item , this procedure calculates the warped cloth segmentation map, which is aligned to the person’s pose. The cloth segmentation warping network is composed of three primary components: (1) the segmentation map encoder, (2) the deformable convolutional layer [29,30], and (3) the segmentation decoder. Both the encoder and the decoder are traditional convolutional networks, which consist of strided convolutional layers, normalization layers, and activation functions. The key component in this model is the deformable convolutional layer, which warps the segmentation feature to align with the target pose. We employed Deformable Convolution v2 [30] for this layer. The loss function used to train these modules can be represented as follows:
where is the estimated warped cloth segmentation map aligned to the person’s pose and denotes a discriminator for adversarial training.
4.3. Cloth Warping Process
Given the three inputs, , this process generates a warped cloth image. In contrast to warping cloth segmentation maps, warping actual clothes presents a greater challenge due to the need to capture the distinct characteristics of clothing items. To ensure high-quality warping, we propose to utilize a multilevel feature transformation that warps clothes in a coarse-to-fine manner at the feature level. For the implementation of this module, we employed Global Flow Local Attention (GFLA) [31], originally designed for pose transfer. While the original GFLA relies on OpenPose [32] for image alignment, we instead used cloth segmentation maps to align the clothing item .
Following [31], the loss function for this module is formulated as follows:
where and are the sampling correctness and affine regularization loss, represents the reconstruction loss, denotes the adversarial loss, and and denote the perceptual and style loss [33], respectively. s are hyperparameters for adjusting the effects of each loss term, and we followed the default values set by [31], where , , , , , and .
4.4. Cloth Refinement Process
While our cloth warping process effectively generates warped clothes with rich contextual features, such as cloth folding, we observed a loss in the detail of logos or textures. To address this, we appended the cloth refinement process to the end of the cloth warping process. Unlike most previous works [4,6,7,8], which use generative models to reconstruct the contextual features, our refinement step specifically focuses on restoring the logos.
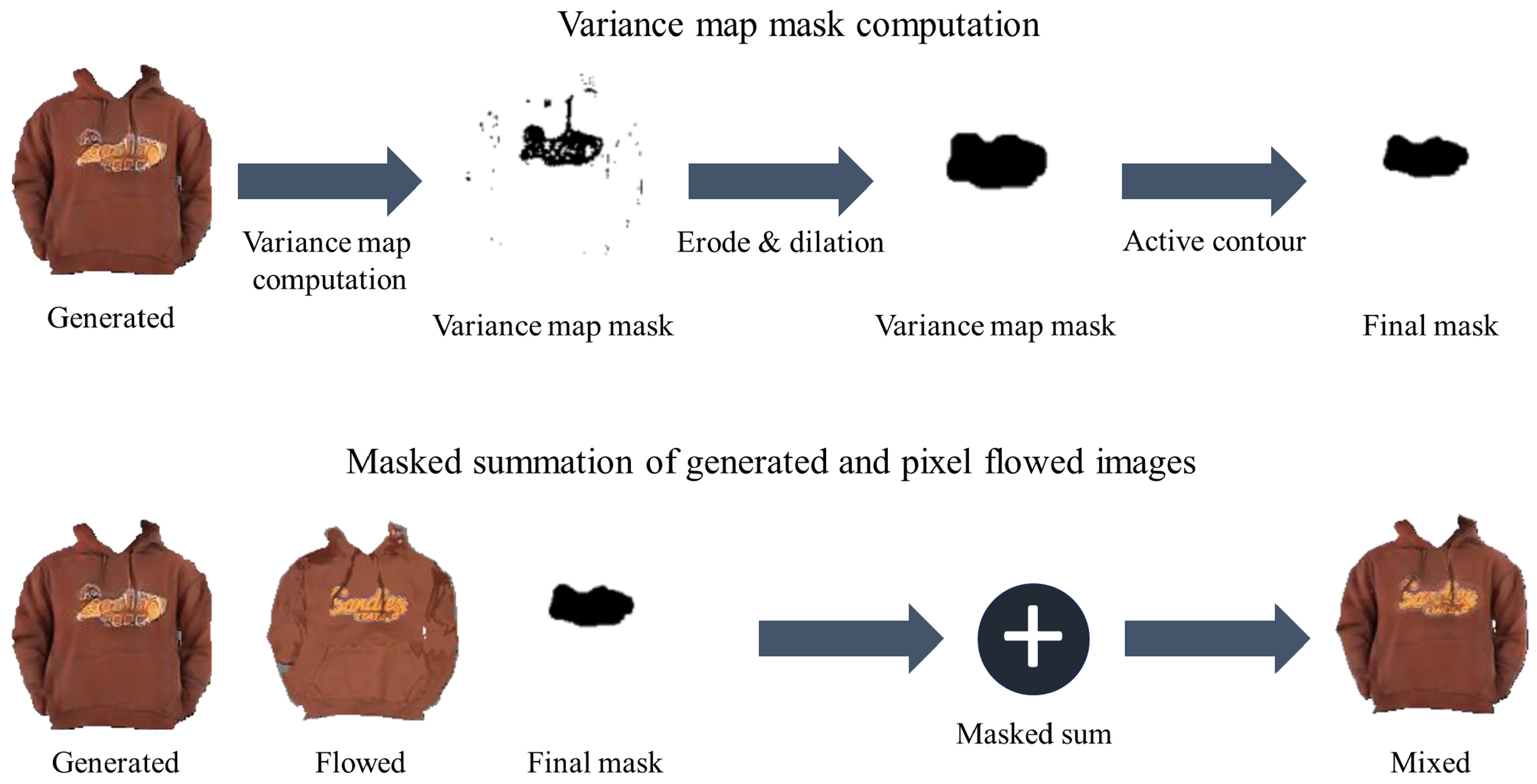
To restore logo details, we calculated the pixel-level-flowed clothes. Instead of calculating pixel-level appearance flow from scratch, we utilized the feature-level flow fields from GFLA and upscaled them to match the dimensions of the clothes. Given the warped cloth and the pixel-level-flowed cloth, we mended the logos by replacing the damaged area in the warped cloth with their counterparts from the pixel-level-flowed cloth. However, this procedure poses another challenge: How can we identify the regions containing logos?
Generally, logo regions exhibit significant changes in pixels. Leveraging this observation, we computed the variance map in the warped clothing image to identify potential logo regions, as demonstrated in the second image of the first row in Figure 2. The variance map comprises the variance calculated for every pixel, resulting in a map with identical dimensions to the clothing image. To calculate variance for the i-th pixel, we define a window, , centered on the pixel. The variance of this pixel is then computed as follows:
where is the variance of the i-th pixel and represents a pixel value in position i. If the variance of the pixel exceeds , where and denote the mean and the standard deviation values in the variance map for one image I, we consider it a candidate pixel for logo regions. Through this procedure, we can obtain the variance map mask containing potential logo pixels. We set the threshold to empirically.
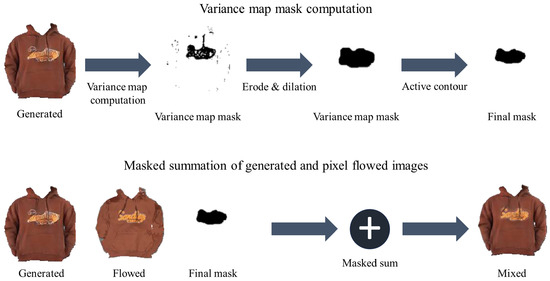
Figure 2.
The cloth refinement process. The first row of this figure represents the procedure of computing the logo regions’ mask using the variance map and the active contour. The second row indicates the logo substitution process using the mask.
Subsequently, we performed several rounds of erosion, followed by a few steps of dilation on the variance map mask to filter out false candidates, as illustrated in the third image of the first row in Figure 2. Since these masks often encompass areas larger than the actual logo regions, we employed the Active Contour algorithm [34], a morphological segmentation algorithm that identifies a segmentation contour by adjusting an initial contour. This algorithm is applied to the mask to determine the final logo regions, as depicted in Figure 2. Leveraging this final mask, damaged logos in the warped cloth are replaced with flowed logos, as illustrated in the second row in Figure 2.
4.5. Try-On Process
In prior works, the try-on process is often incorporated within the refinement process as this process not only refines the warped cloth, but also integrates it with a person image. Conversely, our approach refines the cloth without merging it with the human, making a separate try-on process essential. Unlike earlier works, we did not utilize any generative methods for the try-on process. Instead, we simply superimposed the warped cloth onto the human image. Even though this approach produces natural-looking images, it could be enhanced using algorithmic techniques or generative models, which we consider a direction for future research.
5. Experiments
5.1. Dataset
Instead of using the Zalando dataset [1], we selected the Korean fashion dataset maintained by AIHub [11] for our research, as we believe it better aligns with real-world scenarios. We observed that clothing items within the Zalando dataset are pre-processed and include volumetric effects. Conversely, most retail platforms have images of flattened clothes. This distinction implies that models trained on the Zalando dataset might not be practical for real-world applications. In contrast, the Korean fashion dataset presents images of flattened clothes, as illustrated in Figure 3, which are more closely related to real-world conditions.

Figure 3.
Demonstration of the Korean fashion dataset. As illustrated, the clothing items are presented in a flattened manner, lacking cloth folding details.
The dataset was divided into two subsets, one for training and another for validation. The training set included 33,170 clothing items and 94,089 individuals wearing those items in various poses. In our experiment, we restricted our focus to images where the individuals were facing nearly straight ahead, amounting to 16,399 images. The validation set comprised 7978 clothing items and 12,374 person images. Similar to the training set, we only utilized 2036 person images facing forward.
Each item in the dataset comes with cloth segmentation maps. For upper-body clothing, segmentation maps involve masks for the left and right arms, as well as a mask for the torso. For pants, the segmentation maps include left and right leg masks and a hip mask. Skirt segmentation maps have a single mask encapsulating the entire skirt region. Additionally, human parsing maps are also available for each data item. By leveraging these parsing maps, we extracted the warped cloth segmentation maps, which were utilized as ground truth maps during the training of the segmentation warping process. All the images, initially with dimensions of , were resized to after cropping out white spaces.
5.2. Baselines
We evaluated our approach by comparing it with three recent baseline methods, ACGPN [13], Flow Style VTON [6], and HR-VITON [8]. In this subsection, we briefly introduce these models. In all experiments, we trained them from scratch using their default settings:
- ACGPN: This research regards the virtual try-on problem as an inpainting task, where the masked person image is filled using the warped clothing item. The target cloth is transformed using TPS warping, and its parameters are estimated by a Spatial Transformer Network (STN) [35]. Given the warped clothing item, it is integrated with the body image to generate the final image.
- Flow Style VTON: The work in [6] was a StyleGAN-based [17,18] virtual try-on method. Motivated by the intuition that it is essential to use global style vectors to preserve a global context, this method leverages StyleGAN to determine flow fields using global style vectors extracted from both the person and the clothing images. After the clothing image has been warped using a StyleGAN-based flow estimator, a generator further refines the warped cloth and integrates it into the person image.
- HR-VITON: One of the key ideas of the work in [8] is that the flow field estimation and segmentation prediction should share information between each other. Motivated by this, they simultaneously estimated warped cloth masks and flow fields. Furthermore, they introduced a condition-aligning method to eliminate misaligned regions. Using the estimated flow fields, they computed the flowed cloth and employed a generative model to recover contextual features and generate a high-resolution result.
5.3. Qualitative Results
Figure 4 presents a qualitative comparison with three baseline methods. While existing methods successfully reconstructed the contextual features, such as cloth folding, they often struggled to preserve the logo details. Among them, Flow-Style VTON stood out by restoring the logos most accurately. In contrast, our method preserved both the contextual features and the logo details. More examples can be found in Figure A1 in Appendix A.

Figure 4.
Qualitative comparison with baselines.
Layering Results
We also present layering examples in Figure 5. These examples were produced by warping clothing items through our warping and refinement process and subsequently superimposing them onto the person images. Even though our method does not utilize cloth-agnostic person images during refinement, the generated images still appear natural.

Figure 5.
Layering examples using our approach.
However, one limitation is that simply superimposing clothing items pixelwise onto the person images can sometimes yield unrealistic results, especially when the inner clothes are larger. Addressing the influence of inner clothing size on layering outcomes will be a focus of our future research.
5.4. Quantitative Results
In addition to qualitative comparisons, we also conducted quantitative experiments to demonstrate the superiority of our approach. We computed the Fréchet Inception Distance (FID) [36], Inception Score (IS) [37], Learned Perceptual Image Patch Similarity (LPIPS) [38], and Structural Similarity Index Measure (SSIM) [39] for our approach and compared these with the results from other works, as detailed in Table 1. As it shows, our approach outperformed previous works on most metrics, with the exception of the Inception Score.

Table 1.
Quantitative comparison with baselines.
5.5. Ablation Study
Next, to demonstrate the effectiveness of our refinement, we evaluated the quantitative metrics for our method both with and without the refinement, as presented in Table 2. Our findings suggested that our approach, when including refinement, yielded better FID and IS results. Although the LPIPS and SSIM were slightly worse with refinement, the differences were not statistically significant. We also offer a qualitative comparison in Figure 6, demonstrating that the final images produced with refinement appear more natural.
Table 2.
Quantitative comparison of our method with and without the refinement process.

Figure 6.
Qualitative comparison of our method with and without the refinement process.
6. Conclusions
In contrast to previous works, we employed a generative approach to warp clothing items, followed by refinement using a pixel-level flow. This design enhances the preservation of both contextual features and logos. Specifically, in the warping process, our method can capture contextual features, such as cloth folding, by utilizing multilevel feature transformation based on appearance flow. Furthermore, our method allows for the generation of layering outcomes, as it does not rely on cloth-agnostic person images during the try-on process. In the experiment section, we provide both qualitative and quantitative results, suggesting that our method outperformed others in the practical setting where the clothing images contain limited contextual information. Nonetheless, our method has a limitation in layering, where we simply superimpose the warped clothes onto the human images. This layering approach needs to be refined in our future work to generate the final images more elegantly. We anticipate that our approach will inspire further advancements in this field.
Author Contributions
J.L. and M.L. contributed to the conceptualization, methodology, software development and testing, and writing of the manuscript. Y.K. oversaw the supervision, project administration, funding acquisition, and proofreading. All authors have read and approved the final version of the manuscript for publication.
Funding
This work was supported by the Technology development Program (S3295790) funded by the Ministry of SMEs and Startups (MSS, Republic of Korea).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All datasets used in this research are publicly available online. The AIHUB data can be accessed from https://www.aihub.or.kr/ (accessed on 4 July 2022), and the VTON dataset can be downloaded from https://github.com/xthan/VITON.
Conflicts of Interest
The authors declare that they have no conflicts of interest. Additionally, the funders played no role in the study’s design, data collection, analysis, or interpretation, the writing of the manuscript, nor the decision to publish the results.
Appendix A. More Try-On Examples Using Our Approach

Figure A1.
More try-on examples using our approach.
Figure A1.
More try-on examples using our approach.

References
- Han, X.; Wu, Z.; Wu, Z.; Yu, R.; Davis, L.S. Viton: An image-based virtual try-on network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7543–7552. [Google Scholar]
- Wang, B.; Zheng, H.; Liang, X.; Chen, Y.; Lin, L.; Yang, M. Toward characteristic-preserving image-based virtual try-on network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 589–604. [Google Scholar]
- Minar, M.R.; Tuan, T.T.; Ahn, H.; Rosin, P.; Lai, Y.K. Cp-vton+: Clothing shape and texture preserving image-based virtual try-on. In Proceedings of the CVPR Workshops, Online, 14–19 June 2020; Volume 3, pp. 10–14. [Google Scholar]
- Ge, Y.; Song, Y.; Zhang, R.; Ge, C.; Liu, W.; Luo, P. Parser-free virtual try-on via distilling appearance flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8485–8493. [Google Scholar]
- Han, X.; Hu, X.; Huang, W.; Scott, M.R. Clothflow: A flow-based model for clothed person generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 27 October–2 November 2019; pp. 10471–10480. [Google Scholar]
- He, S.; Song, Y.Z.; Xiang, T. Style-based global appearance flow for virtual try-on. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3470–3479. [Google Scholar]
- Choi, S.; Park, S.; Lee, M.; Choo, J. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14131–14140. [Google Scholar]
- Lee, S.; Gu, G.; Park, S.; Choi, S.; Choo, J. High-resolution virtual try-on with misalignment and occlusion-handled conditions. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 204–219. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- AIHub Korean Fashion Dataset. Available online: https://www.aihub.or.kr (accessed on 4 July 2022).
- Sun, F.; Guo, J.; Su, Z.; Gao, C. Image-based virtual try-on network with structural coherence. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 519–523. [Google Scholar]
- Yang, H.; Zhang, R.; Guo, X.; Liu, W.; Zuo, W.; Luo, P. Towards photo-realistic virtual try-on by adaptively generating-preserving image content. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7850–7859. [Google Scholar]
- Liu, G.; Song, D.; Tong, R.; Tang, M. Toward realistic virtual try-on through landmark guided shape matching. Proc. Aaai Conf. Artif. Intell. 2021, 35, 2118–2126. [Google Scholar] [CrossRef]
- Fang, N.; Qiu, L.; Zhang, S.; Wang, Z.; Hu, K. PG-VTON: A Novel Image-Based Virtual Try-On Method via Progressive Inference Paradigm. arXiv 2023, arXiv:2304.08956. [Google Scholar]
- Fang, N.; Qiu, L.; Zhang, S.; Wang, Z.; Hu, K.; Li, H. Toward multi-category garments virtual try-on method by coarse to fine TPS deformation. Neural Comput. Appl. 2022, 34, 12947–12965. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Pandey, N.; Savakis, A. Poly-GAN: Multi-conditioned GAN for fashion synthesis. Neurocomputing 2020, 414, 356–364. [Google Scholar] [CrossRef]
- Ge, C.; Song, Y.; Ge, Y.; Yang, H.; Liu, W.; Luo, P. Disentangled cycle consistency for highly-realistic virtual try-on. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16928–16937. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Neuberger, A.; Borenstein, E.; Hilleli, B.; Oks, E.; Alpert, S. Image based virtual try-on network from unpaired data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5184–5193. [Google Scholar]
- Lewis, K.M.; Varadharajan, S.; Kemelmacher-Shlizerman, I. Tryongan: Body-aware try-on via layered interpolation. ACM Trans. Graph. (TOG) 2021, 40, 1–10. [Google Scholar] [CrossRef]
- Zhou, T.; Tulsiani, S.; Sun, W.; Malik, J.; Efros, A.A. View synthesis by appearance flow. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 286–301. [Google Scholar]
- Güler, R.A.; Neverova, N.; Kokkinos, I. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7297–7306. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 9 November 2022).
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. Dinov2: Learning Robust Visual Features without Supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Ren, Y.; Yu, X.; Chen, J.; Li, T.H.; Li, G. Deep image spatial transformation for person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7690–7699. [Google Scholar]
- Cao, Z.; Hidalgo Martinez, G.; Simon, T.; Wei, S.; Sheikh, Y.A. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. arXiv 2017, arXiv:1706.08500. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).