
Clover Dry Matter Predictor Based on Semantic Segmentation Network and Random Forest



Abstract
:1. Introduction
- It obtains the rich feature representation of clover images through semantic segmentation network, and then combines it with RF regression to construct a dry matter prediction model of clover images to realize the function of predictive analysis of dry matter content.
- It uses the DeepLabv3+ network with MobileNetv2 as the backbone as the feature extraction network and uses the SE attention mechanism to improve the ASPP, which, compared with the FCN-8s model used by the producer of the open-source dataset, has an improvement of up to 18% in the mIoU collinearity for the semantic segmentation task of the GressClovers dataset. has an improvement of up to 18.5%.
- It obtains the pixel-level features of the species in the image through semantic segmentation to understand the semantic information of the various classes in the image, which is used to obtain the deep information linking the distribution of the species in the image to the dry matter by constructing a RF regression model.
- Provides a new, low-cost and efficient solution for the prediction of dry matter in clover.
2. Methods
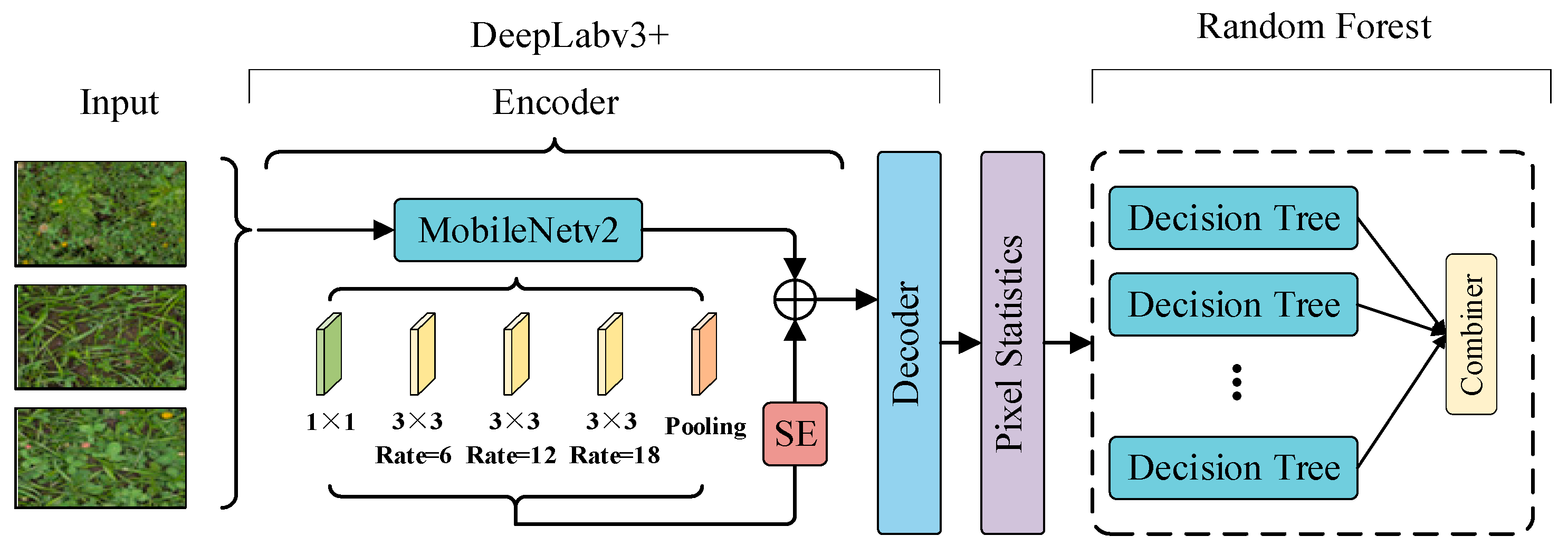
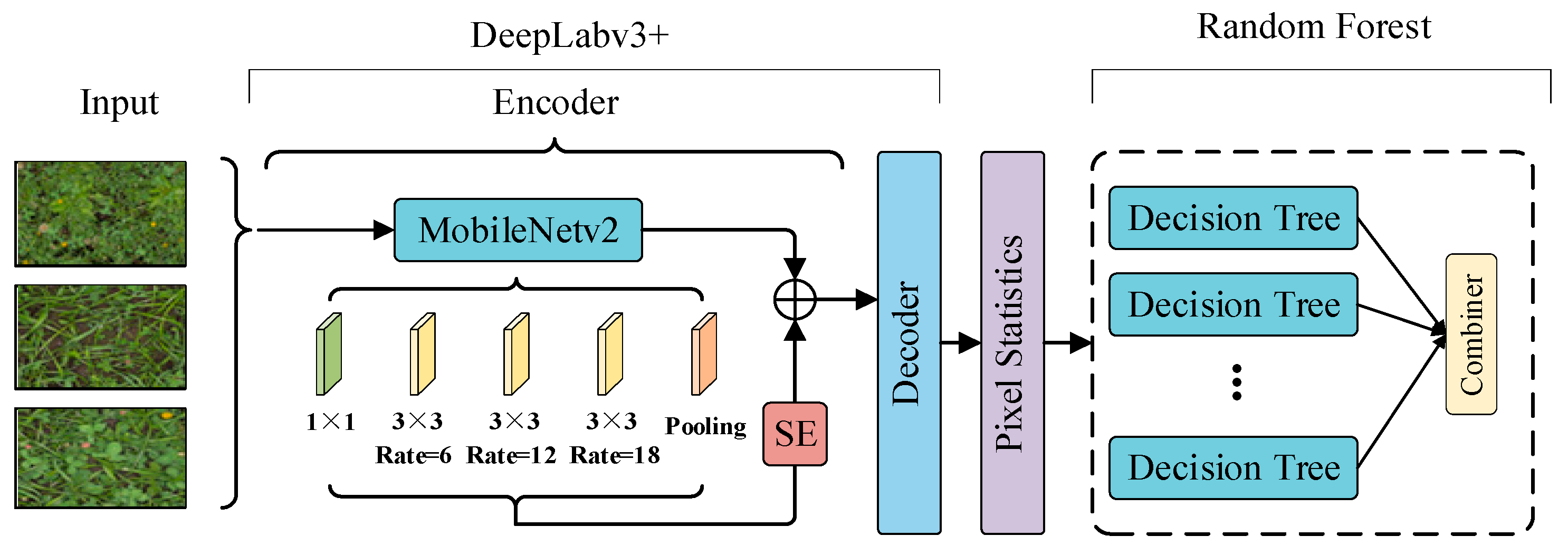
2.1. Model Overall Architecture
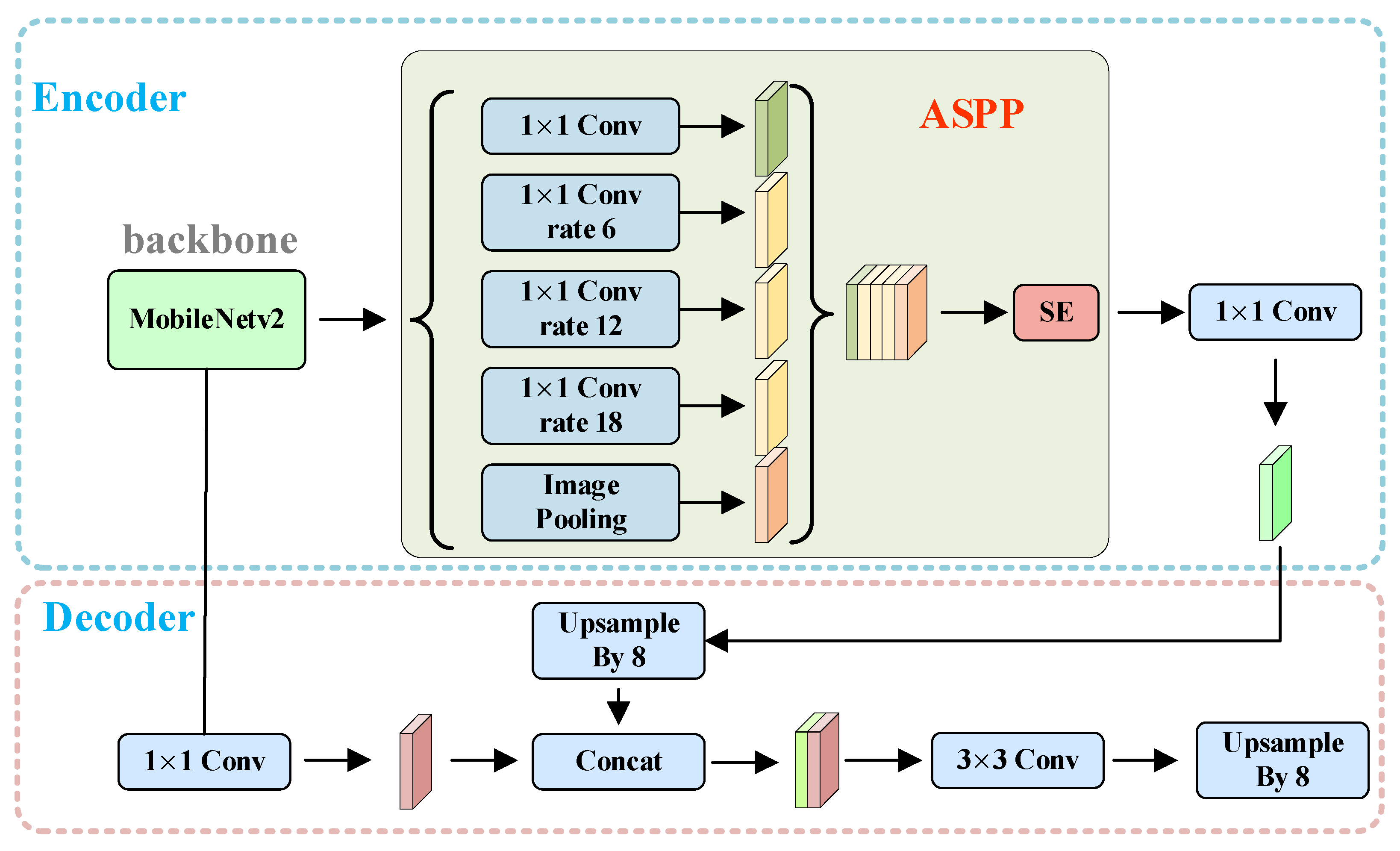
2.2. DeepLabv3+
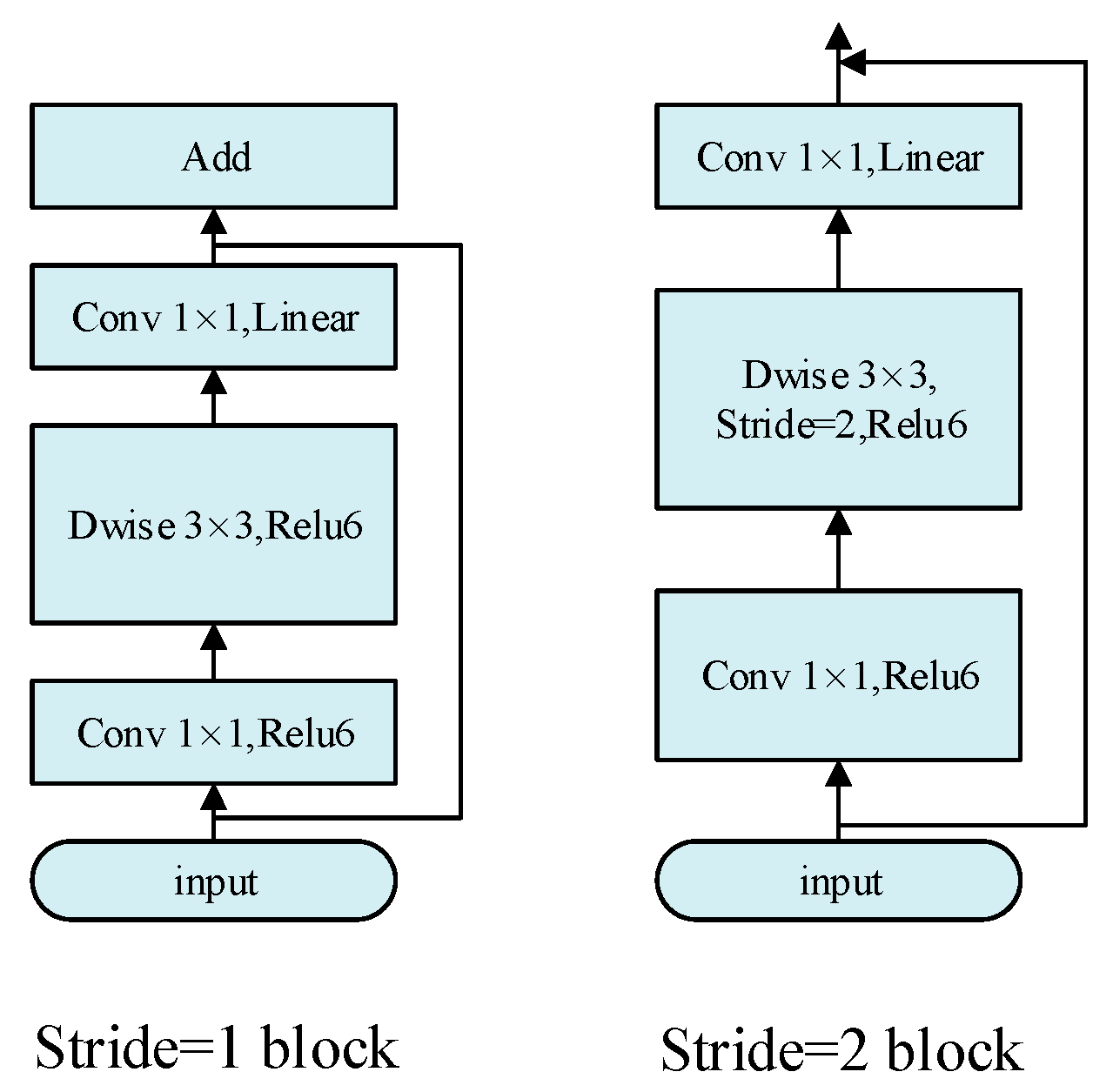
2.2.1. MobileNetv2
2.2.2. ASPP Based on Squeeze and Extraction Networks
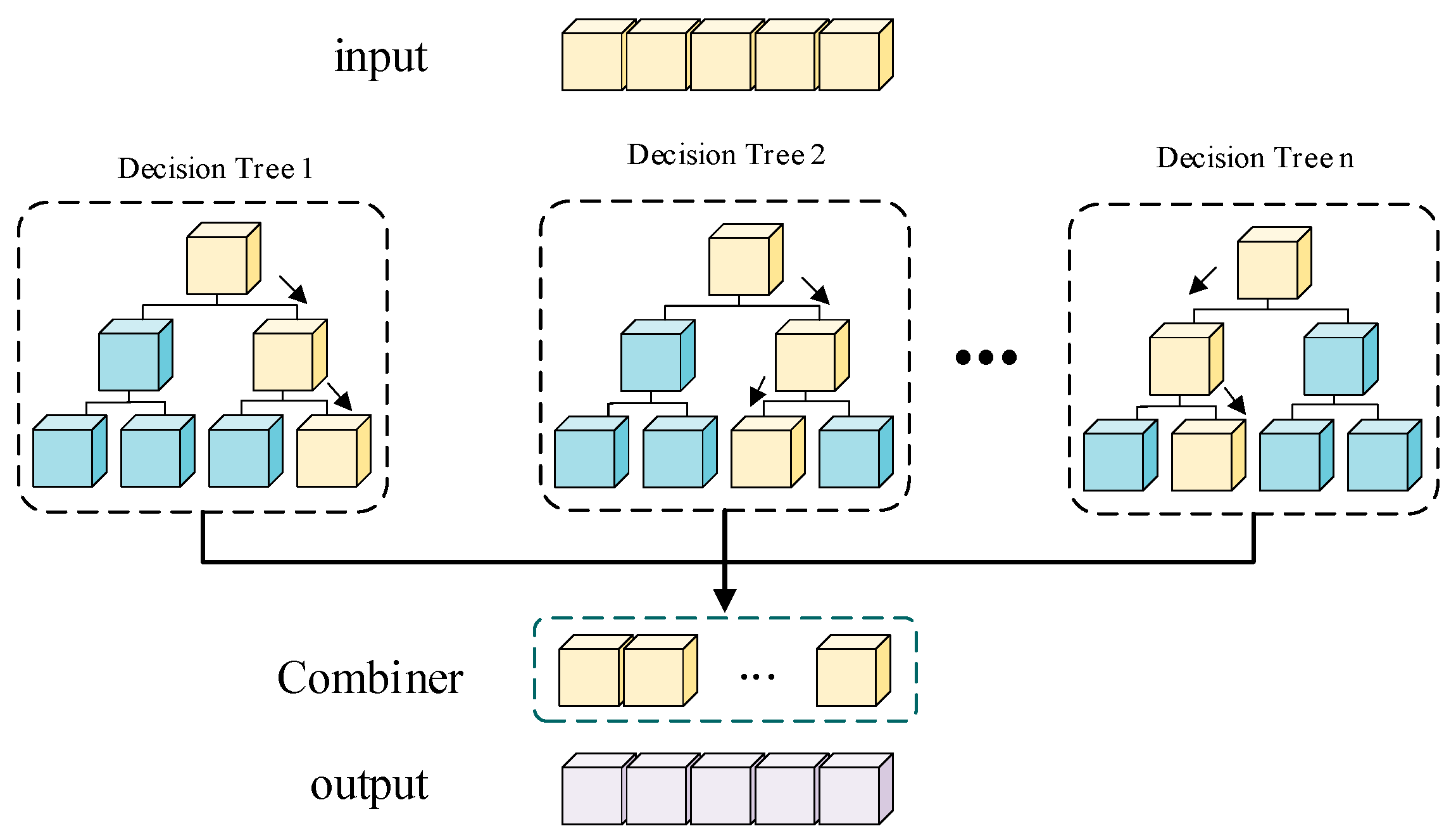
2.3. Dry Matter Prediction
2.4. Experimental Workflow
| Algorithm 1: Dry matter predictor based on DeepLabv3+ and random forests |
| Input: The target sample at the clover image X[x,y]; Output: Predicted dry matter of clover M; Segmented image of clover; for each t ranging from 1 to the last clover image N 1. Image preprocessing, standardization, resize; 2. Implementing encoder feature extraction on the basis of the upper part of Figure 2; 3. Introduction of feature extraction network for SE 4. Implementing a featured decoder based on the bottom half of Figure 2; 5. Implementing pixel-level segmentation of clover images, counting the number of pixels; 6. Number of pixels combined with real dry matter to construct random forest models; 7. Constructing a Random Forest Regression Model 8. Construct a random forest regression based on Figure 5; 9. Predict dry matter in target image; end for |
3. Experiments
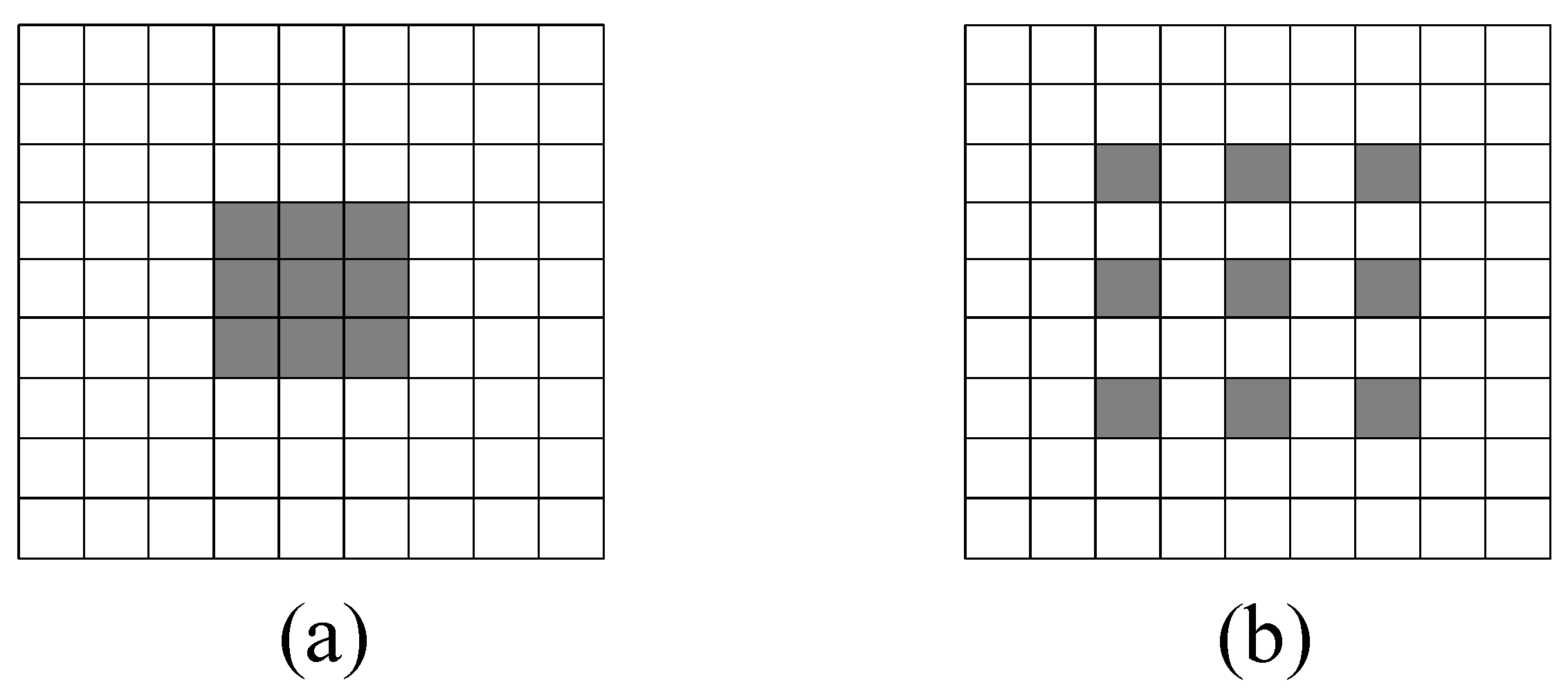
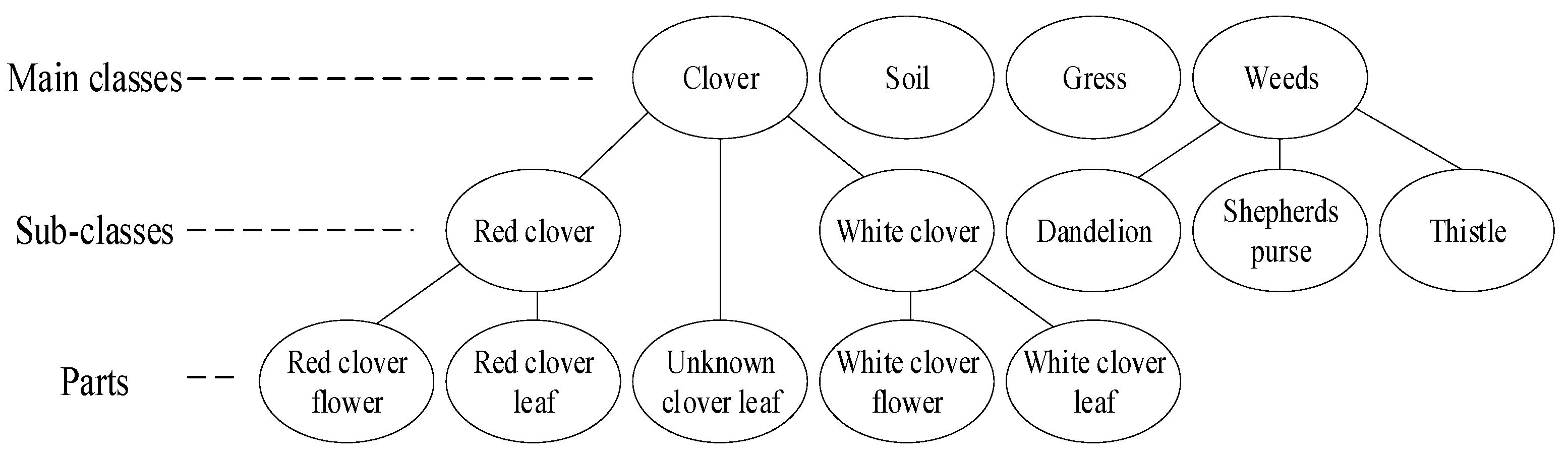
3.1. GrassClover Image Dataset
3.1.1. Semantic Segmentation Dataset
3.1.2. Dry Matter Prediction Dataset
- A canopy image of a defined 0.5 m by 0.5 m of grass clover preceding the cut.
- A composition of the harvested biomass with stems located in the square.
3.2. Experimental Environment
3.3. Experimental Results of DeepLabv3+ Network
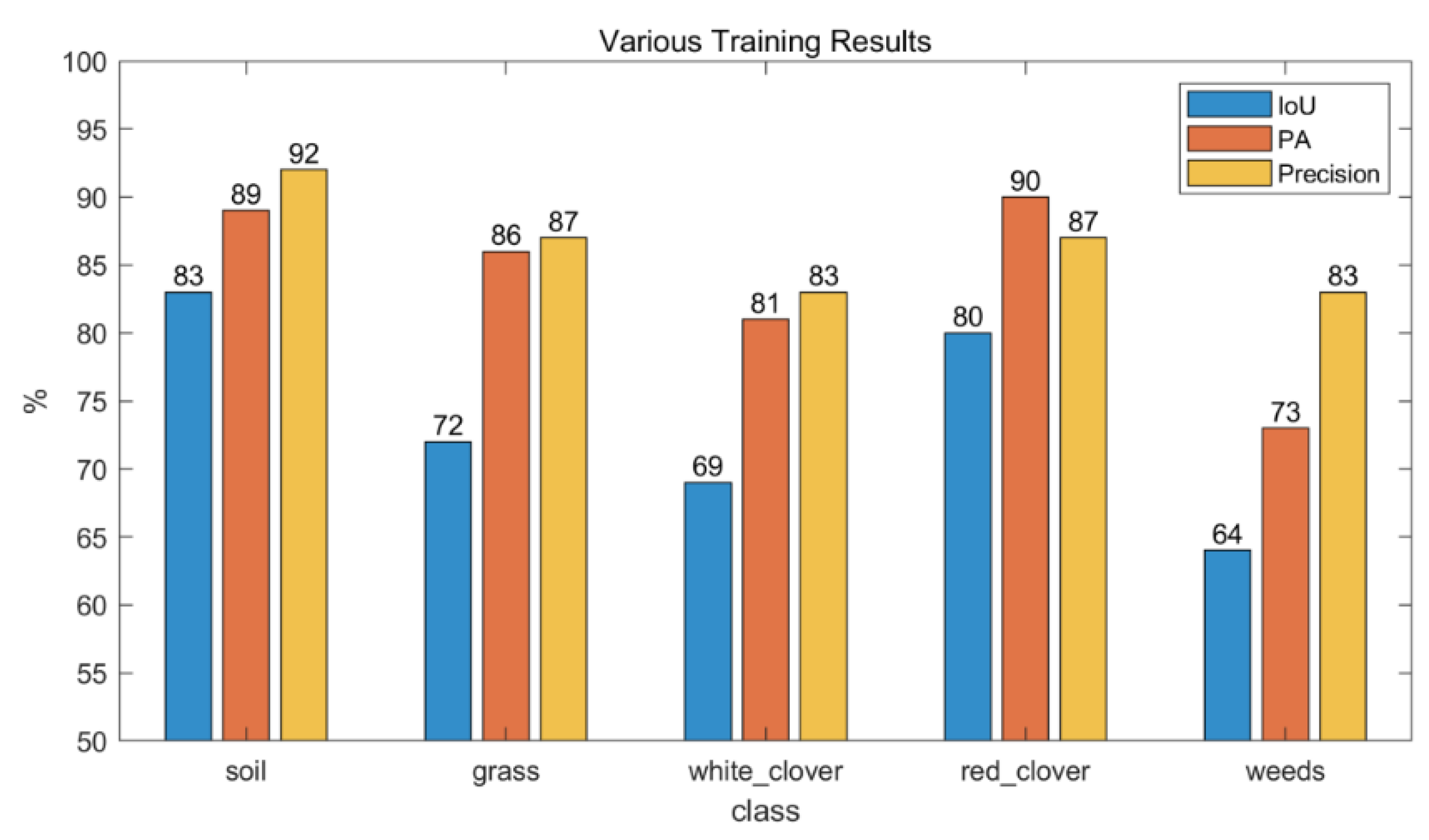
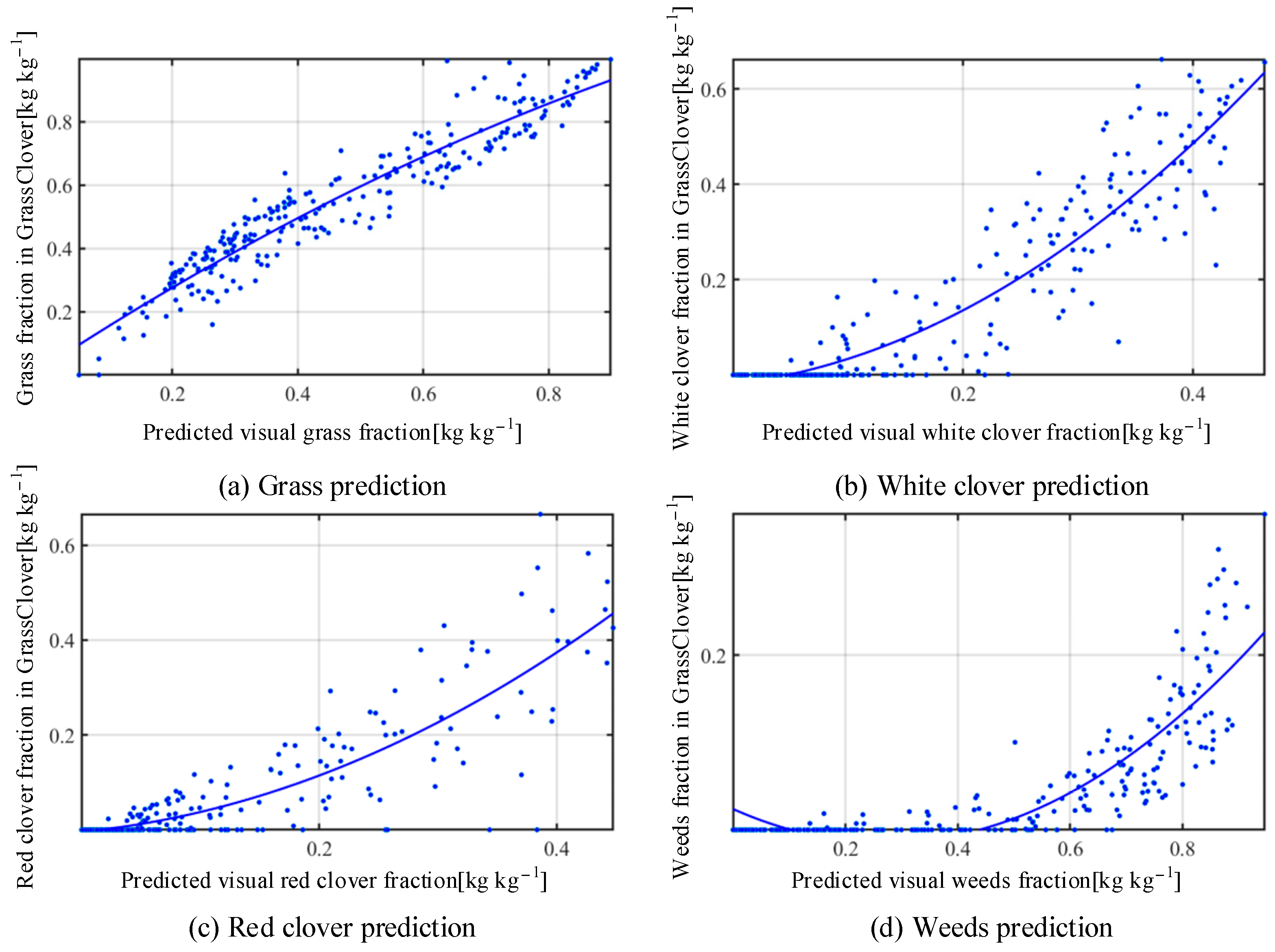
3.4. Experimental Results of Dry Matter Prediction
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pupo, M.; Wallau, M.; Ferraretto, L. Effects of season, variety type, and trait on dry matter yield, nutrient composition, and predicted intake and milk yield of whole-plant sorghum forage. J. Dairy Sci. 2022, 105, 5776–5785. [Google Scholar] [CrossRef] [PubMed]
- Tucak, M.; Ravlić, M.; Horvat, D.; Čupić, T. Improvement of forage nutritive quality of alfalfa and red clover through plant breeding. Agronomy 2021, 11, 2176. [Google Scholar] [CrossRef]
- Sousa, D.O.; Hansen, H.H.; Hallin, O.; Nussio, L.G.; Nadeau, E. A two-year comparison on nutritive value and yield of eight lucerne cultivars and one red clover cultivar. Grass Forage Sci. 2019, 75, 76–85. [Google Scholar] [CrossRef]
- Kandil, A.A.; Salama, A.M.; El-Moursy, S.A.; Abido, W.A. Productivity of Egyptian clover as affected by seeding rates and cutting schedules II-Chemical dry matter analysis. Pak. J. Biol. Sci. 2005, 8, 1766–1770. [Google Scholar]
- Zhou, Z.; Morel, J.; Parsons, D.; Kucheryavskiy, S.V.; Gustavsson, A.-M. Estimation of yield and quality of legume and grass mixtures using partial least squares and support vector machine analysis of spectral data. Comput. Electron. Agric. 2019, 162, 246–253. [Google Scholar] [CrossRef]
- Kartal, S. Comparison of semantic segmentation algorithms for the estimation of botanical composition of clover-grass pastures from RGB images. Ecol. Inform. 2021, 66, 101467. [Google Scholar] [CrossRef]
- Skovsen, S.K.; Laursen, M.S.; Kristensen, R.K.; Rasmussen, J.; Dyrmann, M.; Eriksen, J.; Gislum, R.; Jørgensen, R.N.; Karstoft, H. Robust species distribution mapping of crop mixtures using color images and convolutional neural networks. Sensors 2020, 21, 175. [Google Scholar] [CrossRef]
- Han, D.; Tian, M.; Gong, C.; Zhang, S.; Ji, Y.; Du, X.; Wei, Y.; Chen, L. Image classification of forage grasses on Etuoke Banner using edge autoencoder network. PLoS ONE 2022, 17, e0259783. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C. Tree, shrub, and grass classification using only RGB images. Remote. Sens. 2020, 12, 1333. [Google Scholar] [CrossRef]
- Skovsen, S.; Dyrmann, M.; Mortensen, A.K.; Steen, K.A.; Green, O.; Eriksen, J.; Gislum, R.; Jørgensen, R.N.; Karstoft, H. Estimation of the botanical composition of clover-grass leys from RGB images using data simulation and fully convolutional neural networks. Sensors 2017, 17, 2930. [Google Scholar] [CrossRef]
- Mortensen, A.K.; Karstoft, H.; Søegaard, K.; Gislum, R.; Jørgensen, R.N. Preliminary results of clover and grass coverage and total dry matter estimation in clover-grass crops using image analysis. J. Imaging 2017, 3, 59. [Google Scholar] [CrossRef]
- Bretas, I.L.; Valente, D.S.; Silva, F.F.; Chizzotti, M.L.; Paulino, M.F.; D’áurea, A.P.; Paciullo, D.S.; Pedreira, B.C.; Chizzotti, F.H. Prediction of aboveground biomass and dry-matter content in Brachiaria pastures by combining meteorological data and satellite imagery. Grass Forage Sci. 2021, 76, 340–352. [Google Scholar] [CrossRef]
- Murphy, D.J.; O’Brien, B.; O’Donovan, M.; Condon, T.; Murphy, M.D. A near infrared spectroscopy calibration for the prediction of fresh grass quality on Irish pastures. Inf. Process. Agric. 2022, 9, 243–253. [Google Scholar] [CrossRef]
- Sun, S.; Zuo, Z.; Yue, W.; Morel, J.; Parsons, D.; Liu, J.; Peng, J.; Cen, H.; He, Y.; Shi, J.; et al. Estimation of biomass and nutritive value of grass and clover mixtures by analyzing spectral and crop height data using chemometric methods. Comput. Electron. Agric. 2021, 192, 106571. [Google Scholar] [CrossRef]
- Albert, P.; Saadeldin, M.; Narayanan, B.; Namee, B.M.; Hennessy, D.; O’Connor, A.; O’Connor, N.; McGuinness, K. Semi-supervised dry herbage mass estimation using automatic data and synthetic images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1284–1293. [Google Scholar]
- Hjelkrem, A.-G.R.; Geipel, J.; Bakken, A.K.; Korsaeth, A. NORNE, a process-based grass growth model accounting for within-field soil variation using remote sensing for in-season corrections. Ecol. Model. 2023, 483, 110433. [Google Scholar] [CrossRef]
- Tosar, V.; Pierna, J.F.; Decruyenaere, V.; Larondelle, Y.; Baeten, V.; Froidmont, E. Application of near infrared hyperspectral imaging for identifying and quantifying red clover contained in experimental poultry refusals. Anim. Feed. Sci. Technol. 2021, 273, 114827. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation.C. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015. In Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 801–818. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentationw. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 7151–7160. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Gupta, J.; Pathak, S.; Kumar, G. Deep Learning (CNN) and Transfer Learning: A Review. J. Physics: Conf. Ser. 2022, 2273. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 7132–7141. [Google Scholar]
- Skovsen, S.; Dyrmann, M.; Mortensen, A.K.; Laursen, M.S.; Gislum, R.; Eriksen, J.; Farkhani, S.; Karstoft, H.; Jorgensen, R.N. The GrassClover image dataset for semantic and hierarchical species understanding in agriculture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | t | c | n | s |
|---|---|---|---|---|---|
| 10242 × 3 | conv2d | - | 32 | 1 | 2 |
| 5122 × 32 | bottleneck | 1 | 16 | 1 | 1 |
| 5122 × 16 | bottleneck | 6 | 24 | 2 | 2 |
| 2562 × 24 | bottleneck | 6 | 32 | 3 | 2 |
| 1282 × 32 | bottleneck | 6 | 64 | 4 | 2 |
| 642 × 64 | bottleneck | 6 | 96 | 3 | 1 |
| 642 × 96 | bottleneck | 6 | 160 | 3 | 2 |
| 322 × 160 | bottleneck | 6 | 320 | 1 | 1 |
| 322 × 320 | conv2d 1 × 1 | - | 1280 | 1 | 1 |
| 322 × 1280 | avgpool 32 × 32 | - | - | 1 | - |
| 1 × 1 × 1280 | conv2d 1 × 1 | - | k | - |
| Size | mPrecision | mIoU | mPA | |
|---|---|---|---|---|
| MobileNetV2 | 22.4 MB | 83.69% | 71.15% | 82.20% |
| Xception | 209 MB | 81.82% | 66.93% | 78.48% |
| MobileNetV3 | 15.7 MB | 79.71% | 64.92% | 77.81% |
| MobileNetV2 + SE | 23.2 MB | 85.37% | 73.50% | 83.85% |
| Method | Grass | White Clover | Red Clover | Clover | Weeds | |
|---|---|---|---|---|---|---|
| RF | RMSE [%] | 5.15 | 3.25 | 2.80 | 4.71 | 1.44 |
| MAE [%] | 3.57 | 2.37 | 1.54 | 3.37 | 0.83 | |
| First order linear [31] | RMSE [%] | 9.05 | 9.91 | 6.50 | 9.51 | 6.68 |
| MAE [%] | 6.85 | 7.82 | 4.65 | 7.62 | 4.87 |
| Grass | White Clover | Red Clover | Clover | Weeds | |
|---|---|---|---|---|---|
| RMSE [%] | 16.26 | 4.05 | 3.92 | 2.94 | 3.47 |
| MAE [%] | 10.76 | 3.00 | 2.44 | 2.11 | 2.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Y.; Fang, J.; Zhao, Y. Clover Dry Matter Predictor Based on Semantic Segmentation Network and Random Forest. Appl. Sci. 2023, 13, 11742. https://doi.org/10.3390/app132111742
Ji Y, Fang J, Zhao Y. Clover Dry Matter Predictor Based on Semantic Segmentation Network and Random Forest. Applied Sciences. 2023; 13(21):11742. https://doi.org/10.3390/app132111742
Chicago/Turabian StyleJi, Yin, Jiandong Fang, and Yudong Zhao. 2023. "Clover Dry Matter Predictor Based on Semantic Segmentation Network and Random Forest" Applied Sciences 13, no. 21: 11742. https://doi.org/10.3390/app132111742
APA StyleJi, Y., Fang, J., & Zhao, Y. (2023). Clover Dry Matter Predictor Based on Semantic Segmentation Network and Random Forest. Applied Sciences, 13(21), 11742. https://doi.org/10.3390/app132111742