
Attitude Control of Stabilized Platform Based on Deep Deterministic Policy Gradient with Disturbance Observer

Abstract
:1. Introduction
- A rotary steering drilling stabilized platform model is established, and a LuGre friction model is constructed to provide a basis for the attitude control strategy.
- A DDPG-based deep reinforcement learning attitude control system for the stabilized platform is developed. This involves the selection of the state vector, the design of the reward function, and the construction of the Actor–Critic network structure.
- A Disturbance-Observer-Based Deep Deterministic Policy Gradient is proposed, which is aimed at effectively suppressing frictional disturbances and enhancing the control performance and robustness of the system.
2. Model
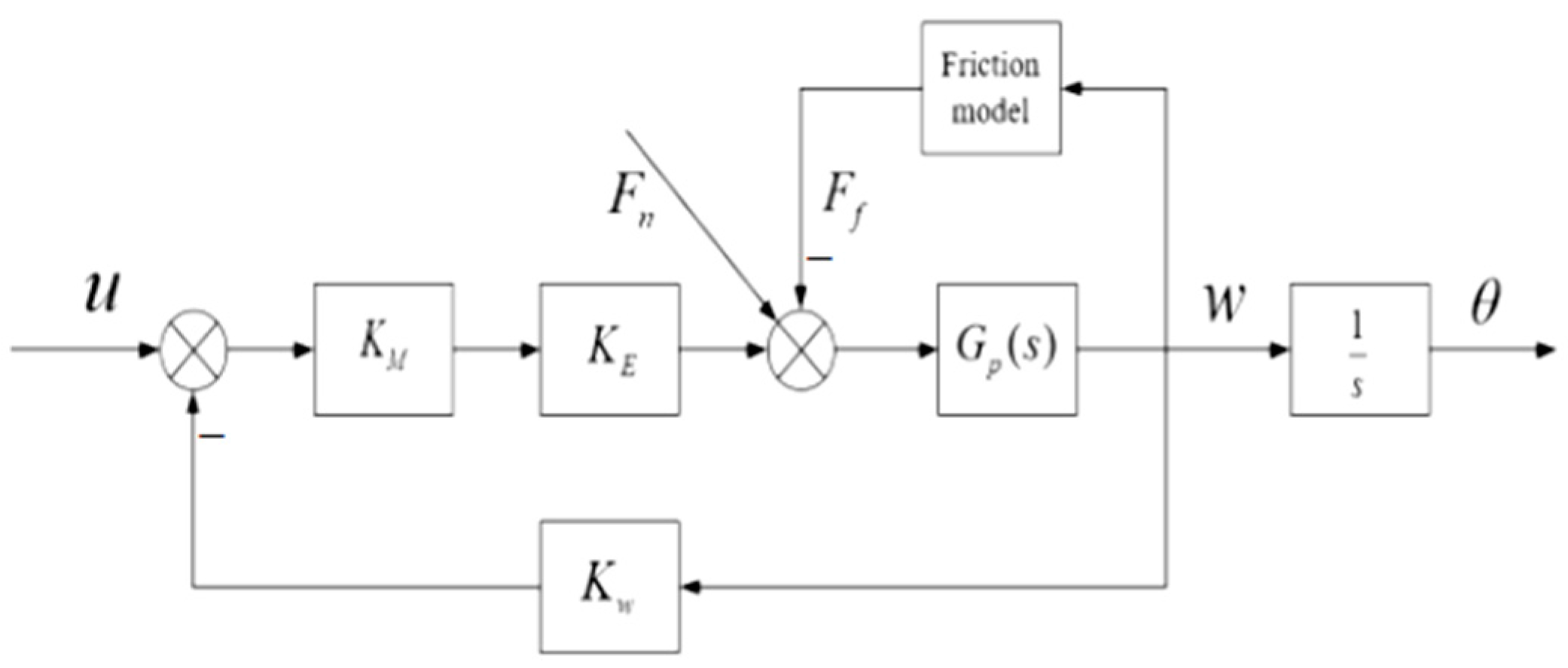
2.1. Stabilized Platform Model
2.2. Friction Characteristic Model
3. Design of Deep Reinforcement Learning Controller Based on DDPG_DOB
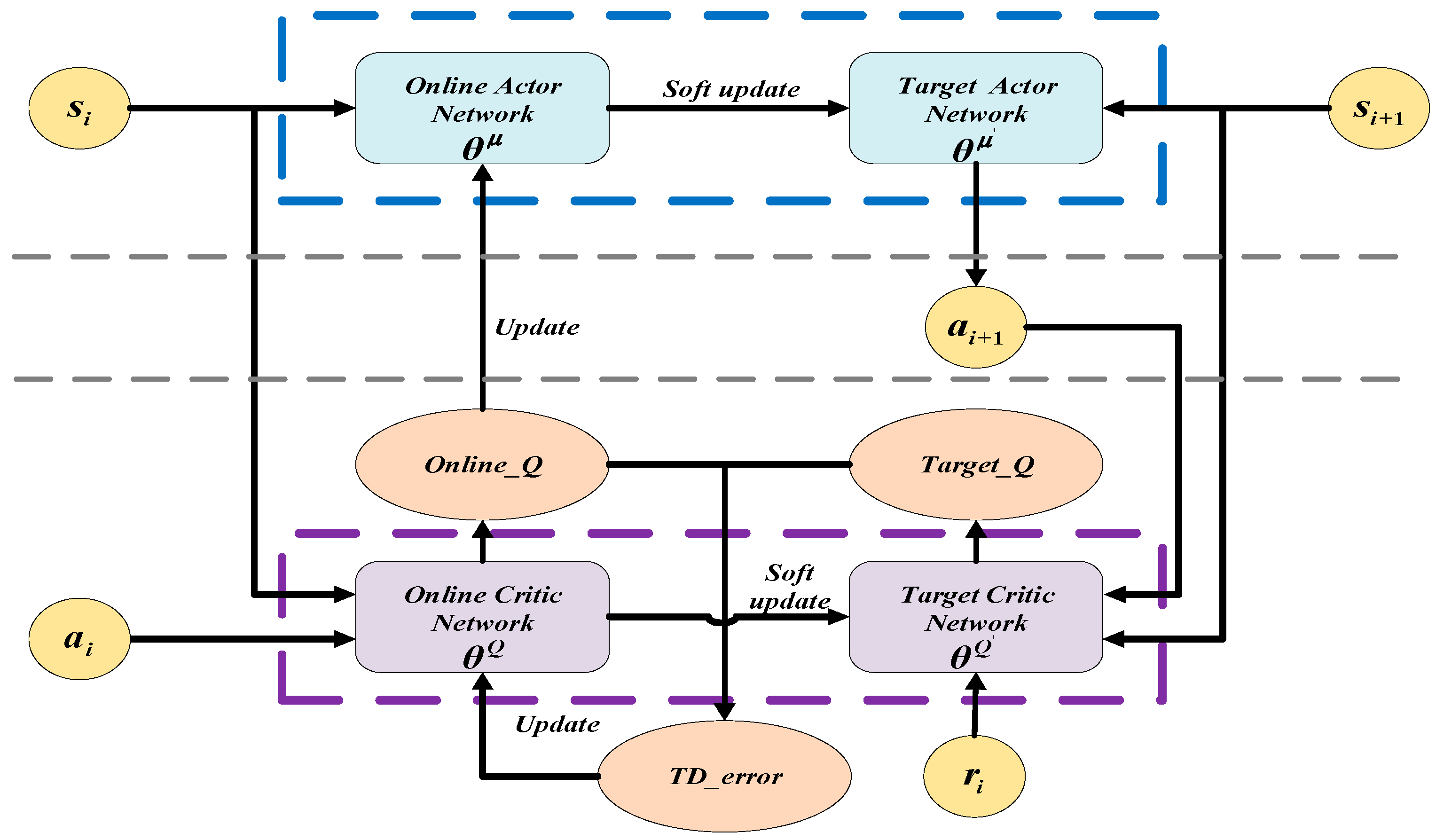
3.1. DDPG Algorithm
3.2. Parameters Updating of DDPG Algorithm
4. Design of Deep Reinforcement Learning Controller for Stabilized Platform
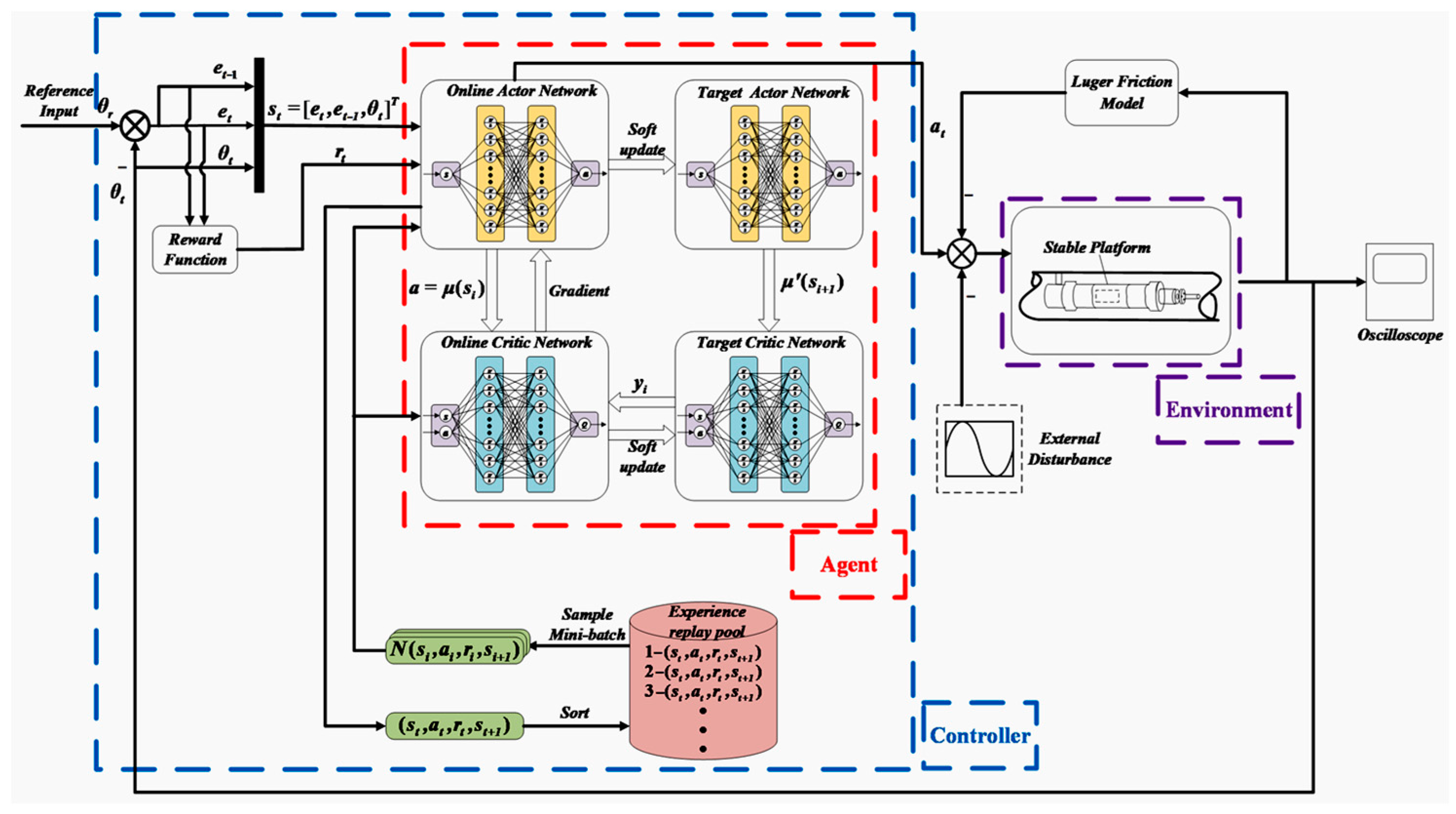
4.1. Overview of the Control System Framework
4.2. Selecting State Vectors
4.3. Designing the Reward Function
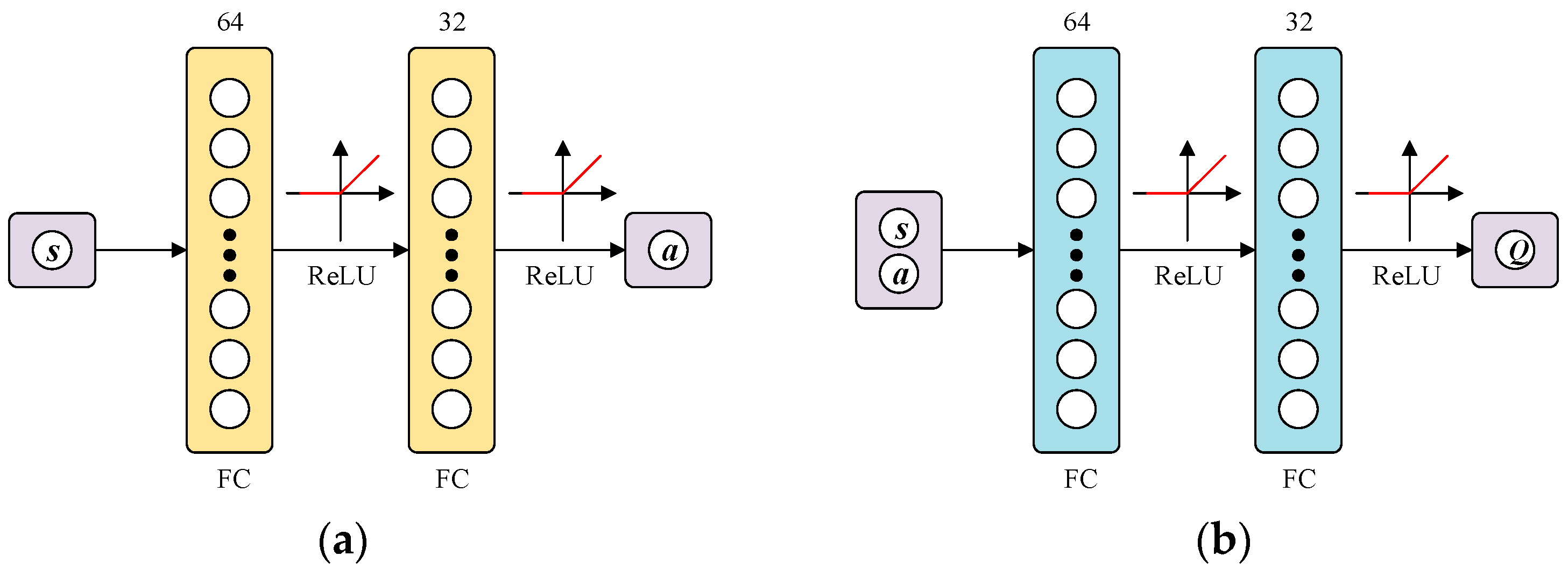
4.4. Network Structure Design
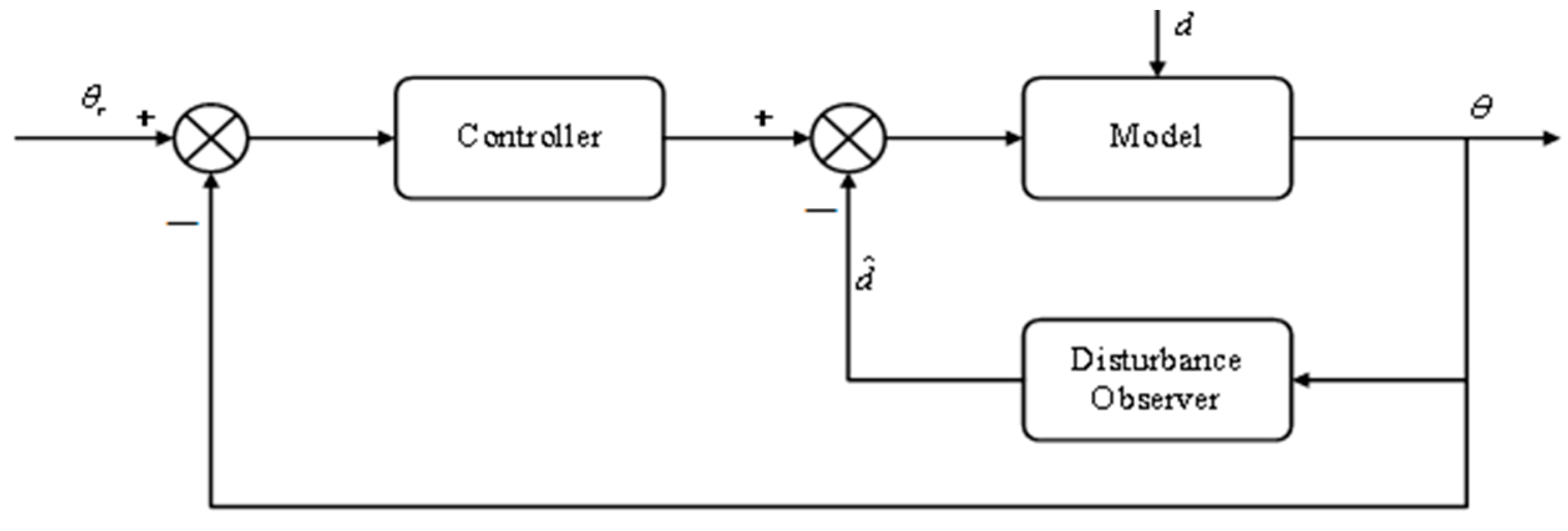
4.5. Design of DDPG_DOB
5. Simulation
5.1. Parameter Description
5.2. Simulation Results and Analysis
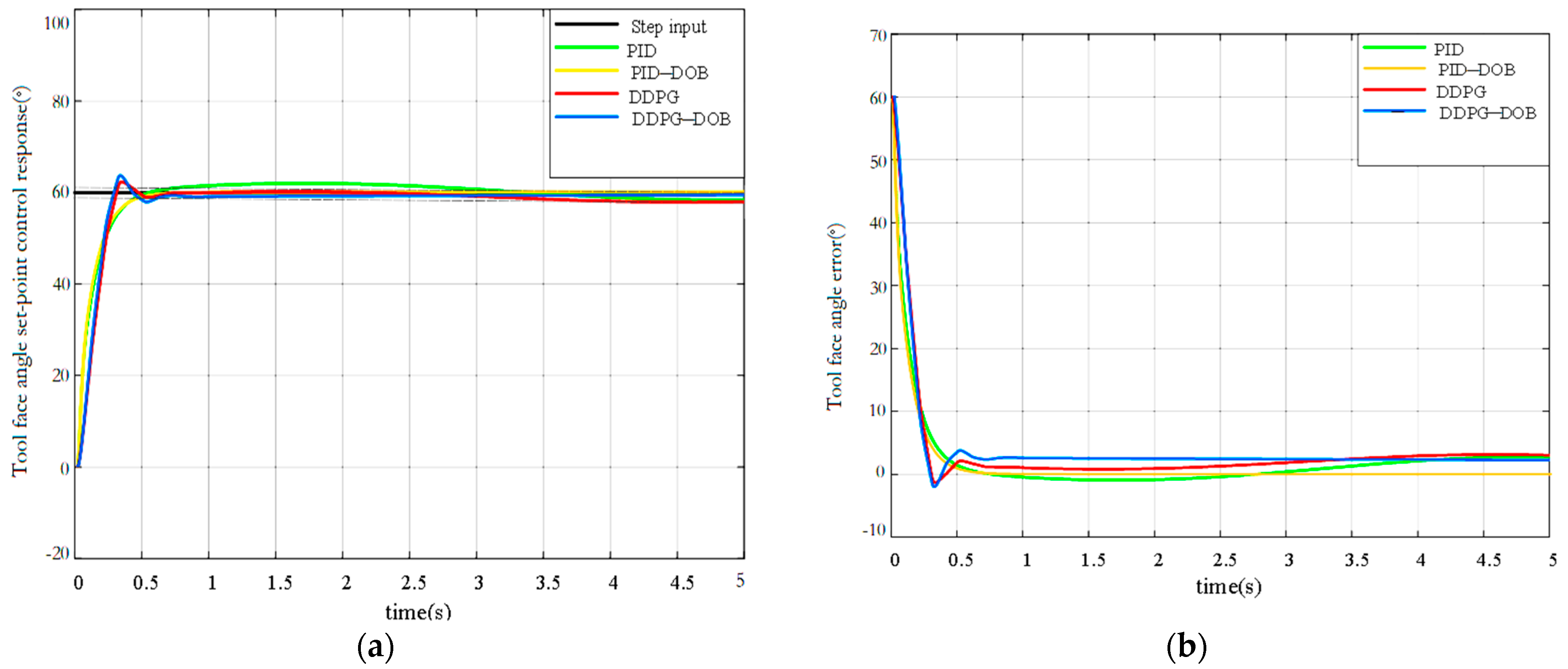
5.2.1. Tool Face Angle Step Simulation with Friction
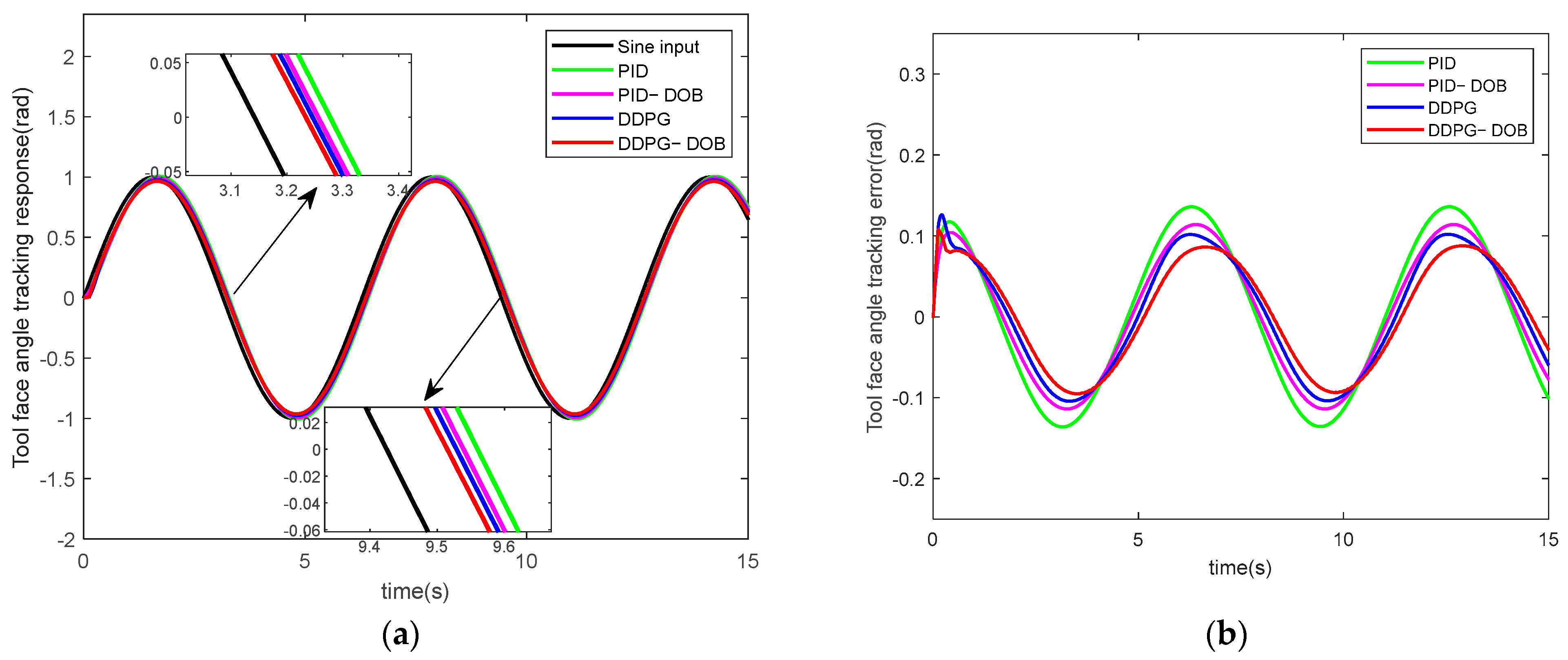
5.2.2. Tool Face Angle Simulation with Friction
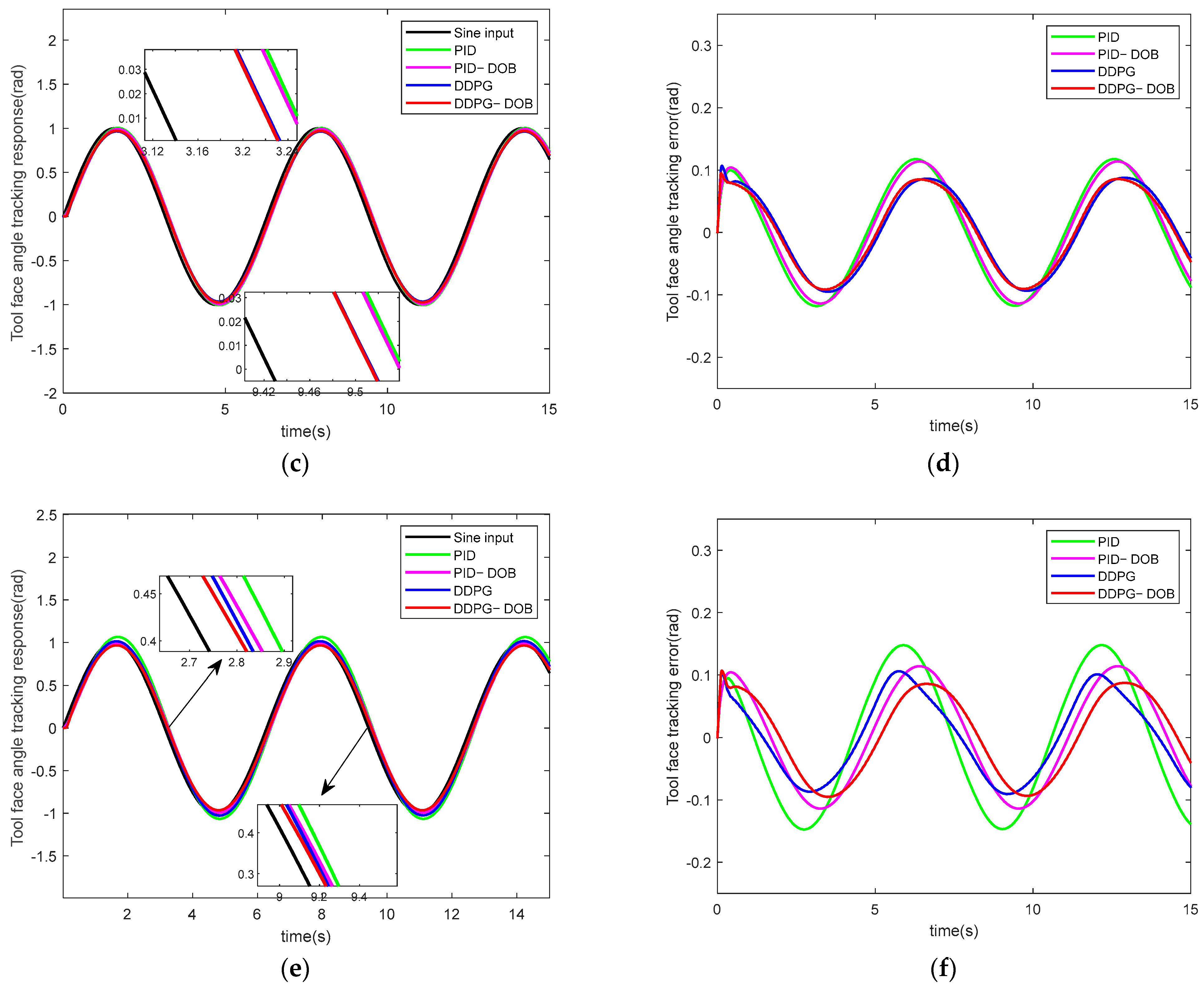
5.2.3. Robustness Experimental Research
6. Conclusions
- ▪
- DDPG_DOB achieves a tracking response error range of 8.7%, outperforming PID and DDPG in terms of control accuracy, nonlinearity, and anti-disturbance capability.
- ▪
- The DDPG_DOB method showcases distinct advantages over PID, PID_DOB, and DDPG; reduces steady-state errors by 0.023°, 0.012°, and 0.014°; and the settling time and rise time are the shortest. These improvements underscore its efficacy in enhancing response speed and accuracy.
- ▪
- The DDPG_DOB-stabilized platform control system shows the effective suppression of the effects of rotational inertia, armature resistance ingestion, and external disturbance amplitude varieties on the system. This system exhibits good adaptive ability and strong robustness under complex and continuous working conditions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.-H. New progress and development direction of modern steering drilling techniques. Acta Pet. Sin. 2003, 24, 82–85, 89. [Google Scholar]
- Su, Y.-N.; Dou, X.-R.; Wang, J.-J. Function, characteristics and typical structure of rotary steering drilling system. Oil Drill. Prod. Technol. 2003, 25, 5–7. [Google Scholar]
- Li, T. Discussion on research status and development trend of rotary steering drilling technology. Petrochem. Ind. Technol. 2016, 18, 165–171. [Google Scholar]
- Xiao, S.-H.; Liang, Z. Development status and prospect of rotary steering drilling technology. China Pet. Mach. 2006, 34, 66–70. [Google Scholar]
- Wang, W.; Geng, Y.; Wang, N. Toolface Control Method for a Dynamic Point-the-Bit Rotary Steerable Drilling System. Energies 2019, 12, 1831. [Google Scholar] [CrossRef]
- Cui, Q.-L.; Zhang, S.-H.; Liu, Y.-X. Study on Controlling System for Variable Structure of Stabilized Platform in Rotary Steering Drilling System. Acta Pet. Sin. 2007, 28, 120–123. [Google Scholar]
- Yan, W.-H.; Peng, Y.; Zhang, S.-H. Mechanism of Rotary Steering Drilling tool. Acta Pet. Sin. 2005, 26, 98–101. [Google Scholar]
- Song, H.-X.; Zeng, Y.-J.; Zhang, W. Current Situation and Key Technology Analysis of Rotary Steering System. Sci. Technol. Eng. 2021, 21, 2123–2131. [Google Scholar]
- Li, Y.-D.; Cheng, W.-B.; Tang, N. The Intelligent PID Control of the Rotary Navigational Drilling Tool. China Pet. Mach. 2010, 38, 13–16. [Google Scholar]
- Huo, A.-Q.; He, Y.-Y.; Wang, Y.-L. Study of Fuzzy Adaptive Sliding Mode Control for Rotary Steering Drilling Stable Platform. Compute. Simul. 2010, 27, 152–155. [Google Scholar]
- Wang, Y.-L.; Wang, H.-J.; Kang, S.-M. Output Feedback Linearization of Servo Platform for Rotary Steering Drilling System. Acta Pet. Sin. 2014, 35, 952–957. [Google Scholar]
- Modares, H.; Lewis, F.-L.; Kang, W. Optimal synchronization of heterogeneous nonlinear systems with unknown dynamics. IEEE Trans. Autom. Control 2018, 63, 117–131. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, W.; Lewis, F.-L. Attitude synchronization for multiple quadrotors using reinforcement learning. In Proceedings of the Chinese Control Conference, Guangzhou, China, 27–30 July 2019; pp. 2480–2483. [Google Scholar]
- Wang, Y. Nonlinear Control Method for Rotary Steering Drilling Servo Platform. Ph.D. Thesis, Northwestern Polytechnical University, Xi’an, China, 2012. [Google Scholar]
- Zhang, Z.; Li, X.; An, J. Model-free optimal attitude control of spacecraft with external disturbance and input saturation based on DRL. In Proceedings of the IEEE 10th Joint International Information Technology and Artificial Intelligent Conference, Chongqing, China, 17–19 June 2022; pp. 100–112. [Google Scholar]
- Tang, N.; Huo, A.-Q.; Wang, Y.-L. Experimental Study on Control Function of Stabilized Platform for Rotary Steerable Drilling Tool. Acta Pet. Sin. 2008, 29, 284–287. [Google Scholar]
- Wang, Y.-L.; Fei, W.-H.; Huo, A.-Q. Electromagnetic Torque Feed Forward Control of the Turbine Alternator for Rotary Steerable Drilling Tools. Acta Pet. Sin. 2014, 35, 141–145. [Google Scholar]
- Tang, N.; Mu, X.-Y. Study on the Platform Stabilizing Control Mechanism of Modulating Rotary Steerable Drilling Tool. Oil Drill. Prod. Technol. 2003, 25, 9–12, 81. [Google Scholar]
- Huo, A.-Q.; Qiu, L.; Wang, Y.-L. Sliding Mode Variable Structure Control of Stabilized Platform in Rotary Steering Drilling System Based on RBF Neural Network. J. Xi’an Shiyou Univ. 2016, 31, 103–108. [Google Scholar]
- Canudas de Wit, C.; Olsson, H.; Astrom, K.J. A New Model for Control of Systems with Friction. IEEE Trans. Autom. Control 1995, 40, 419–425. [Google Scholar] [CrossRef]
- Mashayekhi, A.; Behbahani, S.; Nahvi, A.; Keshmiri, M.; Shakeri, M. Analytical describing function of LuGre friction model. Int. J. Intell. Robot. Appl. 2022, 6, 437–448. [Google Scholar] [CrossRef]
- Park, K.-W.; Kim, M.; Kim, J.-S.; Park, J.-H. Path Planning for Multi-Arm Manipulators Using Soft Actor-Critic Algorithm with Position Prediction of Moving Obstacles via LSTM. Appl. Sci. 2022, 12, 9837. [Google Scholar] [CrossRef]
- Zhao, J.; Zhu, T.; Gao, Z.-Q. Actor-Critic for Multi-Agent Reinforcement Learning with Self-Attention. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2252014. [Google Scholar] [CrossRef]
- Syavasya, C.V.S.R.; Muddana, A.L. Optimization of autonomous vehicle speed control mechanisms using hybrid DDPG-SHAP-DRL-stochastic algorithm. Adv. Eng. Softw. 2022, 173, 103245. [Google Scholar]
- Wu, L.; Wang, C.; Zhang, P. Deep Reinforcement Learning with Corrective Feedback for Autonomous UAV Landing on a Mobile Platform. Drones 2022, 6, 238. [Google Scholar] [CrossRef]
- Huo, A.-Q. Mode Identification and Control Method of Stabilized Platform in Rotary Steerable Drilling. Ph.D. Thesis, Northwestern Polytechnical University, Xi’an, China, 2012. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Numerical Value |
|---|---|
| PWM to MOS tube ratio | 3.440 |
| Gyroscope conversion coefficient | 5.74 |
| Turbine electromagnetic torque to current ratio | 0.22 |
| Rotational inertia | 0.03 |
| Armature resistance | 12.50 |
| Viscous friction coefficient | 0.270 |
| Motor torque coefficient | 3.820 |
| Counterelectromotive force coefficient | 0.44 |
| Parameter Name | Numerical Value |
|---|---|
| Friction torque | 0.5991 |
| Coulomb friction | 2.440 |
| Tool face angular velocity | 0.0103 |
| Stiffness coefficient | 0.4766 |
| Viscous damping coefficient | 0.2701 |
| Viscous friction coefficient | 0.0049 |
| Parameter Name | Numerical Value |
|---|---|
| Discount factor | 0.995 |
| Actor learning rate | |
| Critic learning rate | |
| Maximum return combined number | 5000 |
| Per round number of steps | 200 |
| Soft update parameters | |
| Experience pool capacity | |
| Number of samples per training | 64 |
| Control Method | PID | PID_DOB | DDPG | DDPG_DOB |
|---|---|---|---|---|
| Overshoot (%) | 0 | 0 | 4.762 | 7.143 |
| Settling time (, s) | 3.181 | 2.454 | 0.727 | 0.636 |
| Steady-state error () | −0.047 | 0.036 | −0.038 | 0.024 |
| Rise time (s) | 0.545 | 0.509 | 0.295 | 0.236 |
| PID | PID_DOB | DDPG | DDPG_DOB | |||
|---|---|---|---|---|---|---|
| --- | --- | --- | 0.126 | 0.113 | 0.093 | 0.085 |
| 1.5 J | 1.5 Ra | --- | 0.135 | 0.113 | 0.101 | 0.086 |
| 1.5 J | 0.5 Ra | --- | 0.117 | 0.114 | 0.088 | 0.084 |
| --- | --- | 4 Fn | 0.147 | 0.114 | 0.101 | 0.086 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huo, A.; Jiang, X.; Zhang, S. Attitude Control of Stabilized Platform Based on Deep Deterministic Policy Gradient with Disturbance Observer. Appl. Sci. 2023, 13, 12022. https://doi.org/10.3390/app132112022
Huo A, Jiang X, Zhang S. Attitude Control of Stabilized Platform Based on Deep Deterministic Policy Gradient with Disturbance Observer. Applied Sciences. 2023; 13(21):12022. https://doi.org/10.3390/app132112022
Chicago/Turabian StyleHuo, Aiqing, Xue Jiang, and Shuhan Zhang. 2023. "Attitude Control of Stabilized Platform Based on Deep Deterministic Policy Gradient with Disturbance Observer" Applied Sciences 13, no. 21: 12022. https://doi.org/10.3390/app132112022
APA StyleHuo, A., Jiang, X., & Zhang, S. (2023). Attitude Control of Stabilized Platform Based on Deep Deterministic Policy Gradient with Disturbance Observer. Applied Sciences, 13(21), 12022. https://doi.org/10.3390/app132112022