
Deep Learning-Enabled Heterogeneous Transfer Learning for Improved Network Attack Detection in Internal Networks


Abstract
:Featured Application
Abstract
1. Introduction
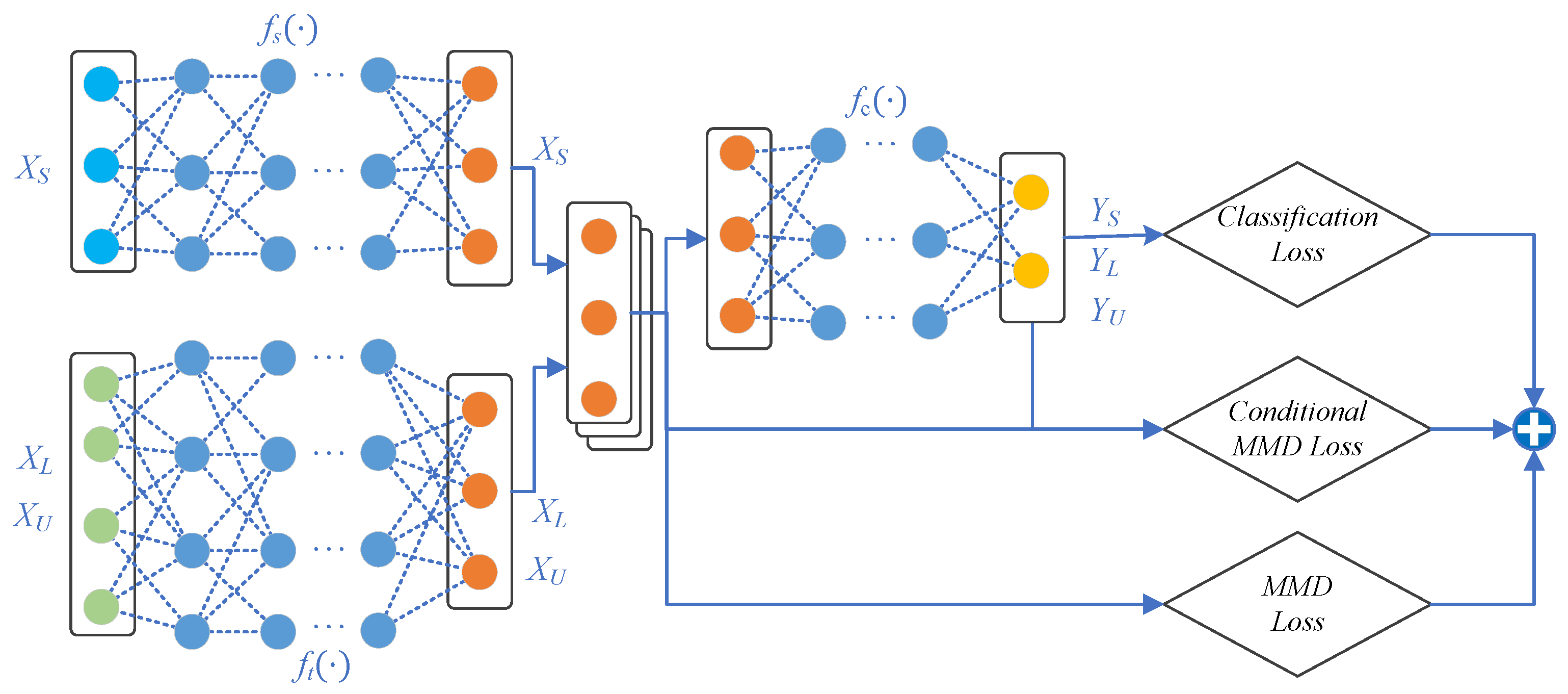
- Two feature projection networks are built for the source and target domains, transforming heterogeneous feature data into a shared, unified feature space. By learning domain-specific representations, our model effectively mitigates feature space heterogeneity and establishes a foundation for seamless knowledge transfer.
- We employ the maximum mean discrepancy (MMD) technique [24] along with the classification loss as the optimization objective for the model so that it forces the alignment of probability distributions between domains during model training. One notable advantage of our proposed model is that MMD computation can leverage the samples’ unconditional distribution by utilizing the vast number of unlabeled samples in the target domain, which is common for collected datasets in internal networks.
- Additionally, we apply soft classification to the unlabeled data, using the classification sub-network to compute MMD over classes, thereby aiming to align conditional distributions between domains more effectively [20].
- To validate the effectiveness and generalizability of our approach, we conduct multiple transfer learning tasks between diverse datasets, including the widely used NSL-KDD, UNSW-NB15, and CIC-IDS2017 datasets [25].
2. Related Work
2.1. Machine Learning for Network Attack Detection
2.2. Transfer Learning
2.3. Deep Learning for Transfer Learning
2.4. Transfer Learning in Network Attack Detection
3. System Design and Methods
3.1. Network Architecture Design
3.1.1. Feature Projection Networks
3.1.2. Classification Network
3.1.3. Distribution Alignment
3.1.4. The Optimization Objective of the Transfer Learning Network
4. Performance Evaluation
4.1. Datasets
- 1.
- NSL-KDD (NSL-KDD Cup’99 Dataset) is a widely used dataset in the field of network intrusion detection and security. It is an improved version of the original KDD Cup ’99 datasets, designed to address some shortcomings in the latter, such as redundancy and unrealistic traffic patterns. NSL-KDD contains a large collection of network traffic data, including both normal and various types of malicious activities (i.e., DoS, Probe, R2L, and U2R attacks), making it a valuable resource for training and evaluating intrusion detection systems.
- 2.
- UNSW-NB15 (University of New South Wales Network-Based 15) consists of network traffic data captured in a controlled environment, simulating a real network. This dataset includes a diverse range of attack types (contains nine types of attacks, including Brute Force, DoS, and Web Attacks, etc.) and normal traffic, providing a realistic representation of network security challenges for developing and testing intrusion detection systems.
- 3.
- CIC-IDS2017 (Canadian Institute for Cybersecurity Intrusion Detection Evaluation Dataset 2017) is a comprehensive dataset that includes various attack scenarios, such as DoS, DDoS, and Port Scans. It offers a wide variety of network traffic scenarios, including both benign and malicious traffic, across different network protocols. This dataset is particularly valuable for researchers and practitioners working on cybersecurity, as it helps in the development and assessment of effective intrusion detection and prevention mechanisms.
4.2. Transfer Learning Tasks
4.2.1. UNSW-NB15 to CIC-IDS2017 Transfer Learning
4.2.2. NSL-KDD to UNSW-NB15 Transfer Learning
- (a)
- The hemap method, which employs linear projection to transform the diverse source and target feature space into a shared latent space, concurrently minimizing projection errors and sample distances across different domains.
- (b)
- (c)
- The base approach, which entails the direct training of the source domain while subsequently applying predictions to target domain data. This is accomplished by orchestrating the transformation of both source and target data into a shared feature space through principal component analysis (PCA).
- (d)
- The hemmd method [41], which is similar to hemap but minimizes cross-domain distribution distance with measurement of MMD.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CIC-IDS2017 | Canadian Institute for Cybersecurity Intrusion Detection System 2017 dataset |
| CNN | Convolutional Neural Network |
| DANN | Domain Adversarial Neural Network |
| DDoS | Distributed Denial of Service |
| DoS | Denial of Service |
| GNN | Graph Neural Network |
| IDS | Intrusion Detection Systems |
| LDA | Linear Discriminant Analysis |
| LSTM | Long Short-Term Memory |
| MMD | Maximum Mean Discrepancy |
| NSL-KDD | NSL-KDD Cup’99 Dataset |
| PCA | Principal Component Analysis |
| R2L | Root to Local attacks |
| ReLU | Rectified Linear Activation Function |
| RKHS | Reproducing Kernel Hilbert Space |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machine |
| TCA | Transfer Component Analysis |
| UNSW-NB15 | University of New South Wales Network-Based 15 dataset |
| U2R | User to Root attack |
References
- Cisco. Cisco Annual Internet Report (2018–2023) White Paper; Techreport; Cisco Systems: San Jose, CA, USA, 2020. [Google Scholar]
- Homoliak, I.; Toffalini, F.; Guarnizo, J.; Elovici, Y.; Ochoa, M. Insight into insiders and IT: A survey of insider threat taxonomies, analysis, modeling, and countermeasures. ACM Comput. Surv. (CSUR) 2019, 52, 1–40. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Liu, L.; De Vel, O.; Han, Q.L.; Zhang, J.; Xiang, Y. Detecting and preventing cyber insider threats: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 1397–1417. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 20. [Google Scholar] [CrossRef]
- Erlacher, F.; Dressler, F. FIXIDS: A high-speed signature-based flow intrusion detection system. In Proceedings of the NOMS 2018–2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–8. [Google Scholar]
- Asharf, J.; Moustafa, N.; Khurshid, H.; Debie, E.; Haider, W.; Wahab, A. A review of intrusion detection systems using machine and deep learning in internet of things: Challenges, solutions and future directions. Electronics 2020, 9, 1177. [Google Scholar] [CrossRef]
- Kim, H.A.; Karp, B. Autograph: Toward Automated, Distributed Worm Signature Detection. In Proceedings of the USENIX Security Symposium, San Diego, CA, USA, 9–13 August 2004; Volume 286. [Google Scholar]
- Sommer, R.; Paxson, V. Outside the closed world: On using machine learning for network intrusion detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 16–19 May 2010; pp. 305–316. [Google Scholar]
- Kim, G.; Lee, S.; Kim, S. A Novel Hybrid Intrusion Detection Method Integrating Anomaly Detection with Misuse Detection. Expert Syst. Appl. 2014, 41, 1690–1700. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Zhou, C.; Paffenroth, R.C. Anomaly detection with robust deep autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, USA, 13–17 August 2017; pp. 665–674. [Google Scholar]
- Hindy, H.; Brosset, D.; Bayne, E.; Seeam, A.K.; Tachtatzis, C.; Atkinson, R.; Bellekens, X. A Taxonomy of Network Threats and the Effect of Current Datasets on Intrusion Detection Systems. IEEE Access 2020, 8, 104650–104675. [Google Scholar] [CrossRef]
- Kheddar, H.; Himeur, Y.; Awad, A.I. Deep Transfer Learning Applications in Intrusion Detection Systems: A Comprehensive Review. arXiv 2023, arXiv:2304.10550. [Google Scholar]
- Zhao, J.; Shetty, S.; Pan, J.W.; Kamhoua, C.; Kwiat, K. Transfer learning for detecting unknown network attacks. EURASIP J. Inf. Secur. 2019, 2019, 1. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, Z.; Li, Y.; Zheng, Y.; Hou, H.; Gao, M.; Song, Y.; Xin, Y. Intrusion detection based on fusing deep neural networks and transfer learning. In Proceedings of the Digital TV and Wireless Multimedia Communication: 16th International Forum, IFTC 2019, Shanghai, China, 19–20 September 2019; pp. 212–223. [Google Scholar]
- Masum, M.; Shahriar, H. Tl-nid: Deep neural network with transfer learning for network intrusion detection. In Proceedings of the 2020 15th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 8–10 December 2020; pp. 1–7. [Google Scholar]
- Mahdavi, E.; Fanian, A.; Mirzaei, A.; Taghiyarrenani, Z. ITL-IDS: Incremental transfer learning for intrusion detection systems. Knowl.-Based Syst. 2022, 253, 109542. [Google Scholar] [CrossRef]
- Pawlicki, M.; Kozik, R.; Choraś, M. Towards Deployment Shift Inhibition Through Transfer Learning in Network Intrusion Detection. In Proceedings of the 17th International Conference on Availability, Reliability and Security, Vienna, Austria, 23–26 August 2022; pp. 1–6. [Google Scholar]
- Yao, Y.; Zhang, Y.; Li, X.; Ye, Y. Heterogeneous domain adaptation via soft transfer network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1578–1586. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Yuan, S.; Wu, X. Deep learning for insider threat detection: Review, challenges and opportunities. Comput. Secur. 2021, 104, 102221. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Ring, M.; Wunderlich, S.; Scheuring, D.; Landes, D.; Hotho, A. A survey of network-based intrusion detection data sets. Comput. Secur. 2019, 86, 147–167. [Google Scholar] [CrossRef]
- Li, J.; Qu, Y.; Chao, F.; Shum, H.P.; Ho, E.S.; Yang, L. Machine learning algorithms for network intrusion detection. AI Cybersecur. 2019, 151, 151–179. [Google Scholar]
- Belavagi, M.C.; Muniyal, B. Performance evaluation of supervised machine learning algorithms for intrusion detection. Procedia Comput. Sci. 2016, 89, 117–123. [Google Scholar] [CrossRef]
- Ahmad, I.; Ul Haq, Q.E.; Imran, M.; Alassafi, M.O.; AlGhamdi, R.A. An efficient network intrusion detection and classification system. Mathematics 2022, 10, 530. [Google Scholar] [CrossRef]
- Zainel, H.; Koçak, C. LAN intrusion detection using convolutional neural networks. Appl. Sci. 2022, 12, 6645. [Google Scholar] [CrossRef]
- Tuor, A.; Kaplan, S.; Hutchinson, B.; Nichols, N.; Robinson, S. Deep learning for unsupervised insider threat detection in structured cybersecurity data streams. arXiv 2017, arXiv:1710.00811. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Day, O.; Khoshgoftaar, T.M. A survey on heterogeneous transfer learning. J. Big Data 2017, 4, 1–42. [Google Scholar] [CrossRef]
- Dai, W.; Yang, Q.; Xue, G.R.; Yu, Y. Boosting for Transfer Learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 193–200. [Google Scholar]
- Bukhari, M.; Bajwa, K.B.; Gillani, S.; Maqsood, M.; Durrani, M.Y.; Mehmood, I.; Ugail, H.; Rho, S. An efficient gait recognition method for known and unknown covariate conditions. IEEE Access 2020, 9, 6465–6477. [Google Scholar] [CrossRef]
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer learning via dimensionality reduction. In Proceedings of the AAAI, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 677–682. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Marcelino, P. Transfer learning from pre-trained models. Towards Data Sci. 2018, 10, 23. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3723–3732. [Google Scholar]
- Shi, X.; Liu, Q.; Fan, W.; Yu, P.S. Transfer across completely different feature spaces via spectral embedding. IEEE Trans. Knowl. Data Eng. 2013, 25, 906–918. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, G.; Wang, S.; Zhan, D.; Yin, M. Cross-domain network attack detection enabled by heterogeneous transfer learning. Comput. Netw. 2023, 227, 109692. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Dataset | Attack Types | Description |
|---|---|---|
| NSL-KDD | DoS | Involves overwhelming a network or system to disrupt its services. |
| Probe | Attackers attempt to gather information about the target network without direct exploitation. | |
| U2R | Attackers exploit vulnerabilities to gain unauthorized access and escalate privileges. | |
| R2L | Attackers attempt to connect to a local system remotely without proper credentials. | |
| UNSW-NB15 | Fuzzers | aimed at testing software vulnerabilities through unexpected inputs. |
| Analysis | Techniques for gathering information about target systems. | |
| Backdoors | Unauthorized access methods left by attackers. | |
| DoS | Flooding a system to disrupt its services. | |
| Exploits | Attacks exploiting known vulnerabilities. | |
| Generic | General or unspecified attacks. | |
| Reconnaissance | Preparing for future attacks by gathering information. | |
| Shellcode | Malicious code for executing arbitrary commands. | |
| CIC-IDS2017 | DoS | Flooding the target with traffic to disrupt services. |
| PortScan | Scanning target ports to find potential vulnerabilities. | |
| DDoS | Distributed denial of service attacks from multiple sources. | |
| Patator | Brute-force attacks against SSH and FTP services. | |
| Web Attack | Attacks targeting web applications and services. | |
| Botnet | Activities related to botnets, including command and control traffic. | |
| Infiltration | Unauthorized access and data exfiltration attempts. |
| # | Source | Target | Description |
|---|---|---|---|
| 1 | Normal, Fuzzers | BENIGN, Web Attack, Brute Force, FTP-Patator, SSH-Patator | accessing target system via brute-force manner |
| 2 | Normal, DoS | BENIGN, DoS {Hulk, GoldenEye, slowloris, Slowhttptest} | denial of service attack |
| 3 | Normal, Reconn, Analysis | BENIGN, PortScan | retrieve information about target system |
| 4 | Normal, Generic | BENIGN, Bot, Web Attack XSS, Web Attack SQL Injection, Infiltration | other attack types cannot be categorized |
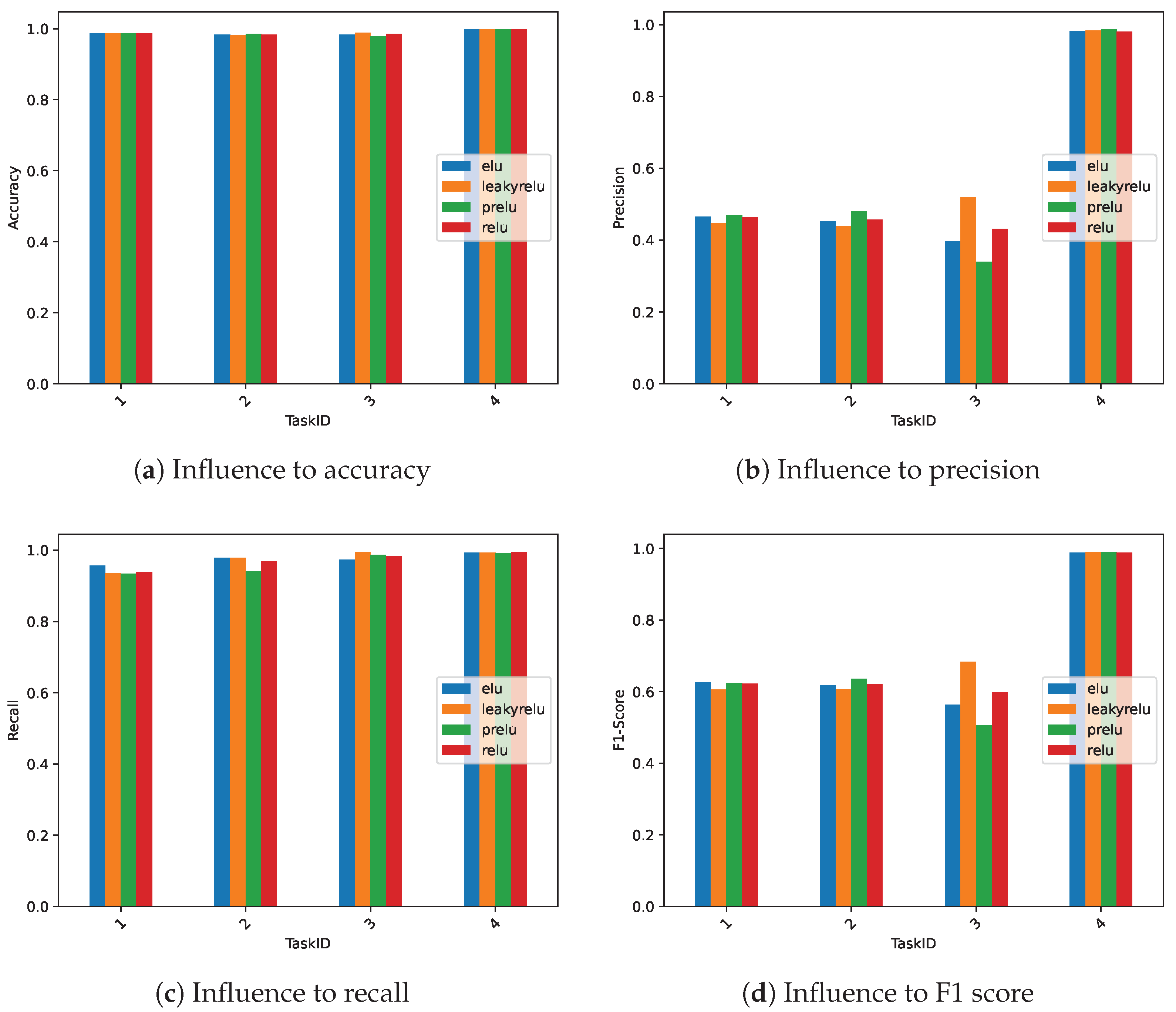
| TaskID | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 1 | 0.987 | 0.465 | 0.938 | 0.622 |
| 2 | 0.983 | 0.457 | 0.969 | 0.621 |
| 3 | 0.985 | 0.431 | 0.984 | 0.599 |
| 4 | 0.998 | 0.981 | 0.994 | 0.988 |
| Source ↓ Target | DoS ↓ DoS | DoS ↓ Fuzzers | DoS ↓ Generic | Probing ↓ Analysis | Probing ↓ Fuzzers | Probing ↓ Reconn | R2L ↓ Exploits |
|---|---|---|---|---|---|---|---|
| hemap | 0.773 | 0.757 | 0.784 | 0.744 | 0.734 | 0.720 | 0.800 |
| hetl | 0.701 | 0.693 | 0.693 | 0.699 | 0.696 | 0.700 | 0.695 |
| base | 0.846 | 0.532 | 0.914 | 0.725 | 0.585 | 0.654 | 0.617 |
| hemmd | 0.945 | 0.956 | 0.587 | 0.898 | 0.814 | 0.814 | 0.878 |
| dhetl | 0.990 | 0.989 | 0.995 | 0.995 | 0.989 | 0.989 | 0.981 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Liu, D.; Zhang, C.; Hu, T. Deep Learning-Enabled Heterogeneous Transfer Learning for Improved Network Attack Detection in Internal Networks. Appl. Sci. 2023, 13, 12033. https://doi.org/10.3390/app132112033
Wang G, Liu D, Zhang C, Hu T. Deep Learning-Enabled Heterogeneous Transfer Learning for Improved Network Attack Detection in Internal Networks. Applied Sciences. 2023; 13(21):12033. https://doi.org/10.3390/app132112033
Chicago/Turabian StyleWang, Gang, Dong Liu, Chunrui Zhang, and Teng Hu. 2023. "Deep Learning-Enabled Heterogeneous Transfer Learning for Improved Network Attack Detection in Internal Networks" Applied Sciences 13, no. 21: 12033. https://doi.org/10.3390/app132112033
APA StyleWang, G., Liu, D., Zhang, C., & Hu, T. (2023). Deep Learning-Enabled Heterogeneous Transfer Learning for Improved Network Attack Detection in Internal Networks. Applied Sciences, 13(21), 12033. https://doi.org/10.3390/app132112033