1. Introduction
Multi-pedestrian tracking (MPT) serves as a foundational task within the realm of computer vision and finds applications in numerous computer vision domains [
1]. MPT involves estimating the trajectories of multiple objects of interest within video sequences, holding pivotal significance in video analytics systems for domains like surveillance security [
2], automated driving, intelligent transportation [
3], behavioral recognition [
4], human–computer interaction, and intelligent agriculture [
5,
6]. While extensive research has been conducted in this field, a definitive method that can consistently perform exceptionally well in addressing the challenges posed by complex scenes with frequent occlusions in surveillance videos remains elusive [
7]. The current focus for enhancing the accuracy of multi-pedestrian tracking primarily involves optimizing pedestrian detector performance, refining the extraction of representative pedestrian features, and improving data association matching algorithms [
8].
For the optimization of pedestrian detector performance, Zhang [
9], in his study, introduced a small-target pedestrian inspection model incorporating residual networks and feature pyramids, which dispenses with unnecessary, redundant computations in the model and solves the gradient problem in a neural network by using residual blocks with a discarded layer instead of the standard residual block, thus significantly improving the accuracy and anti-jamming ability of small-target pedestrian detection. Liu [
10] introduced an enhanced detection-and-tracking framework with a semantic matching strategy based on deep learning. Integrating scene-aware affinity detection, this framework proves to be highly effective in alleviating challenges related to occlusion and similar appearances. Zhang [
11] introduced an innovative approach, FairMOT, which combines CenterNet and directly embeds the Re-ID module, whose training process utilizes the cross-entropy loss function, aiding in obtaining more accurate target features. This amalgamation achieves higher precision in capturing target features, all while considering the trade-off between speed and accuracy in the multi-target tracking model. Zhang et al. [
12] proposed a multi-pedestrian tracking algorithm using the Tracking-by-Detection framework. It addresses the diversity of human postures, appearance similarities, and occlusion in real-time road traffic scenes. The algorithm effectively leverages both pedestrian depth appearance features and motion features to establish correlations among the tracking targets, thus realizing the multi-objective target tracking of pedestrians. Zhou et al. [
13] proposed an improved MOT approach for occlusion scenarios, combining attention mechanisms and occlusion sensing as a solution. Jia [
14] designed and developed a network for learning separate representations for processing occlusion re-identification guided by semantic preference object queries in a converter without strict character image alignment or any additional supervision. To better eliminate occlusion interference, they devised a Contrast Feature Learning approach to better separate hidden features from recognition features. Bewley et al. [
15] proposed the Simple Online Real-Time Tracking (SORT) method, which fuses positional and motion information in a similarity matrix for target ID association and achieved good results in short-range matching. Bewley et al. [
16] proposed DeepSORT based on SORT, which adds an offline pedestrian re-identification network and achieves better results in long-distance matching by merging appearance and motion information. Zhang [
17] proposed the BYTE data association method, which introduces low-confidence detection frames into data association matching and utilizes these low-confidence similarities between the detection frames and the tracking trajectories to mine out heavily occluded targets, thus maintaining the continuity of the tracking trajectories.
While significant progress has been made in enhancing detector performance, extracting more representative features, and improving data association and matching algorithms, most tracking tasks still face common challenges in complex scenarios, such as occlusion, omissions, and distractions [
18]. As a result, the robustness of existing methods is in need of improvement [
19].
Based on the above problems, in order to solve complex surveillance video scenes with multiple targets tracked simultaneously, we propose a method for the simultaneous tracking of multiple pedestrians based on KC-YOLO detection and an identity validity discrimination module (IVDM). We have made improvements in both the detector and the tracker. The Convolution Block Attention Module (CBAM) [
20] is introduced into the detector, utilizing attention weights to allow for a more focused and refined representation of the target features, which improves the ability of the detector to capture the effective feature information of the target, which has been decisive in improving the overall precision and accuracy of the test procedure. In the tracking process, to address the issue of tracking failure due to the short-term occlusion of the target, this method constructs an IVDM after cascade matching. The target occlusion coefficient
k is calculated to discriminate whether the target identity in the low-scoring detection frame after target detection and cascade matching is valid or not and to decide whether to update its appearance features so as not to generate redundant identity data, thereby ensuring the purity of the tracked pedestrian’s identity and improving the overall performance of the tracking task.
To summarize, this paper’s primary contributions can be outlined as follows:
An efficient, robust, and practical multi-pedestrian tracking method based on KC-YOLO deep detection and identity validity discrimination is proposed. This method provides an effective solution for multi-pedestrian tracking tasks in complex surveillance videos. Experimental results demonstrate its high utility, making it suitable for the long-term tracking of critical targets in various scenarios, such as public safety and firefighting.
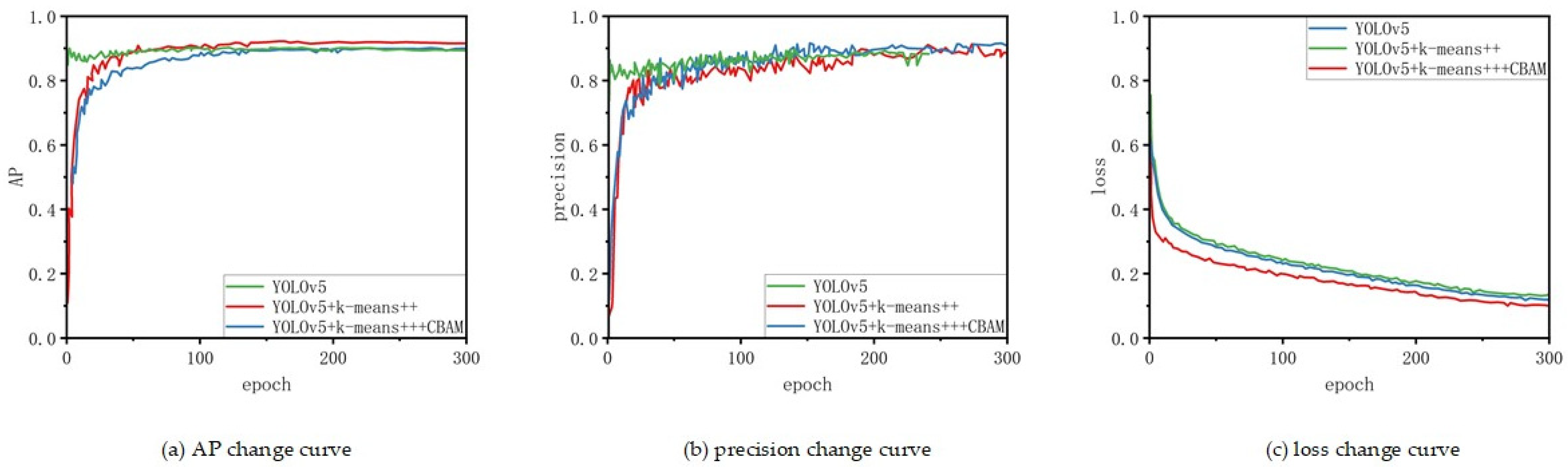
An improved pedestrian object detector based on YOLOv5, tailored for complex environments, has been designed. This detector employs the K-means++ clustering method to select optimal detection frames and introduces the CBAM for adaptive feature refinement. The KC-YOLO network is introduced for extracting target depth features.
A pedestrian identity validity model has been developed. To address challenges such as targets reappearing after occlusion and rapid identity switches, this model assesses the identity validity of newly generated targets. Different processing strategies are applied to targets with identity validity, enhancing the tracking accuracy while ensuring the purity of pedestrian target identities.
This paper is structured such that
Section 2 introduces the summary of the work related to the proposed method in this study. The multi-Pedestrian Tracking Method Based on IVDM is discussed in
Section 3. The experimental data and analyses the experimental results are highlighted in
Section 4, and in
Section 5 we summarize this study. Lastly, we discuss this study and provide an outlook for future research in
Section 6.
3. Multi-Pedestrian Tracking Method Based on IVDM
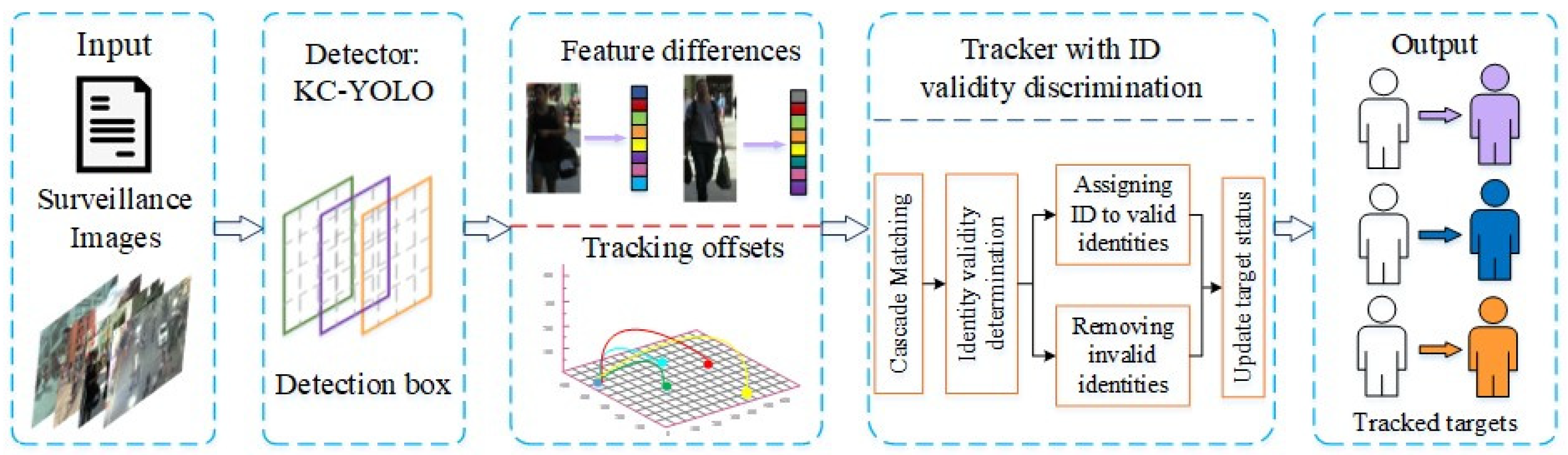
In the context of multi-pedestrian tracking, detection and tracking tasks are both independent and closely related to each other [
29]. We adopt the KC-YOLO detection model to detect pedestrians in complex traffic environments, where the apparent information may be incomplete and unclear. Then, we introduce the IVDM as part of the improved approach to realizing the tracking of multiple pedestrian targets. The integrated detector–tracker structure is shown in
Figure 1.
We utilize the KC-YOLO network as our detector to extract the adaptive deep features of the targets. We combine this with trajectory matching based on Kalman filtering predictions. For tracking, we employ DeepSORT, which incorporates pedestrian identity validity discrimination. This combination allows us to perform accurate and efficient multi-pedestrian tracking.
3.1. Construction of KC⁃YOLO Detection Model
We propose a model called KC-YOLO, which is applied to complex scenes in surveillance video and uses the YOLOv5 [
30] detection model as the base algorithm.
The core steps of the KC-YOLO model are as follows:
Determine the optimal anchor frame that is compatible with the input pedestrian image;
Extract the deep features of the pedestrian image through the KC-YOLO network. Use the attention mechanism to highlight its salient information and achieve adaptive feature refinement.
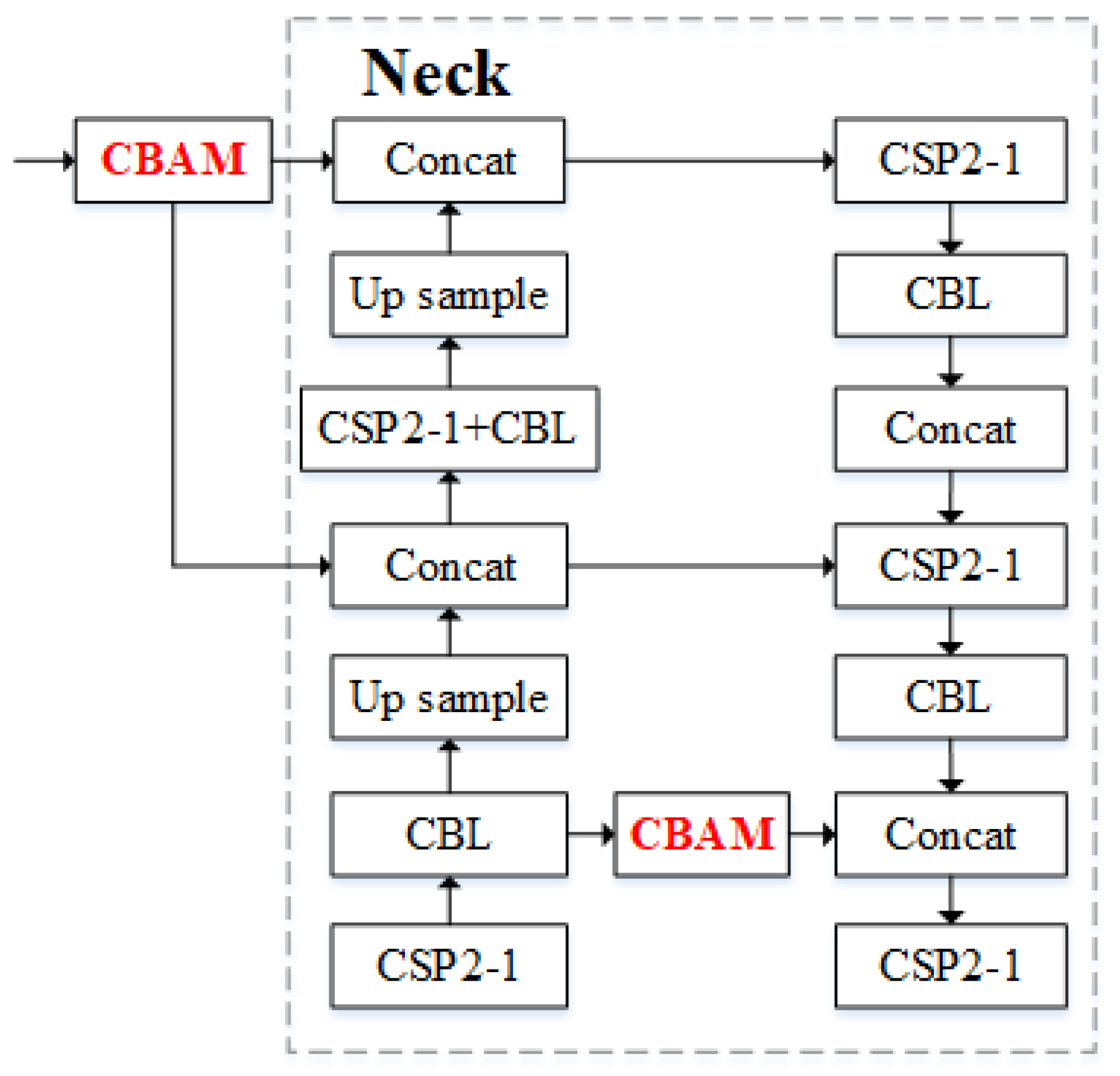
We introduce the CBAM into the backbone and neck parts of the detection network for the following reasons: the backbone part is the key part for extracting pedestrian features, while the neck part fuses the features and sends them to the head for prediction, and the introduction of the CBAM here can improve the feature extraction ability of the network more effectively. The structure of the improved KC-YOLO network is shown in
Figure 2.
Concat is primarily responsible for combining addition and residual convolution operations. Through feature fusion, it allows the detection network to simultaneously utilize the extracted shallow and deep features. The main purpose of the upsample structure is to perform upsampling operations; CBL is a convolutional block. Within CSP2_1, the input feature map is divided into two parts. One part is processed through a subnetwork, while the other part undergoes further processing directly. These two sets of feature maps are then concatenated and used as input for the next layer. By combining the features processed by the subnetwork with those processed directly, a series of convolution operations are performed. This approach effectively integrates low-level detail features with high-level abstract features, thereby improving the feature extraction efficiency.
3.1.1. Optimal Pedestrian Detection Frame Determination
In the context of pedestrian detection, YOLOv5 defaults to using k-means clustering to generate anchor frames. However, before performing k-means clustering, it is crucial to initialize
k cluster centers, as the convergence can be significantly affected by uninitialized cluster centers. To address this issue, we employ the k-means++ clustering method [
31]. Here is how it works:
Initially, a random sample point is selected from the dataset as the first initial cluster center.
Then, the shortest distance between each sample point and the currently existing cluster centers is calculated.
Finally, each sample point is chosen as the next cluster center with a probability proportional to the shortest distance. The sample point with the highest probability is selected as the next cluster center.
This approach provides a more reliable initialization method, improving the stability and convergence of the clustering process, which, in turn, optimizes the selection of detection frames. The formula for the calculation is as follows:
where
Ci represents the first initial cluster center;
D(X) denotes the shortest distance between each sample point and the currently existing cluster centers; and
P(X) represents the probability of each sample point being selected as the next cluster center.
3.1.2. Deep Feature Extraction
Deep features extracted by convolutional neural networks can provide an effective description of the high-level semantic information of an image, and the CBAM is an attention mechanism module used to enhance the performance of convolutional neural networks with significant results. In order to improve the feature extraction capability of the detection network [
32], we introduce the CBAM [
20] into the detection model.
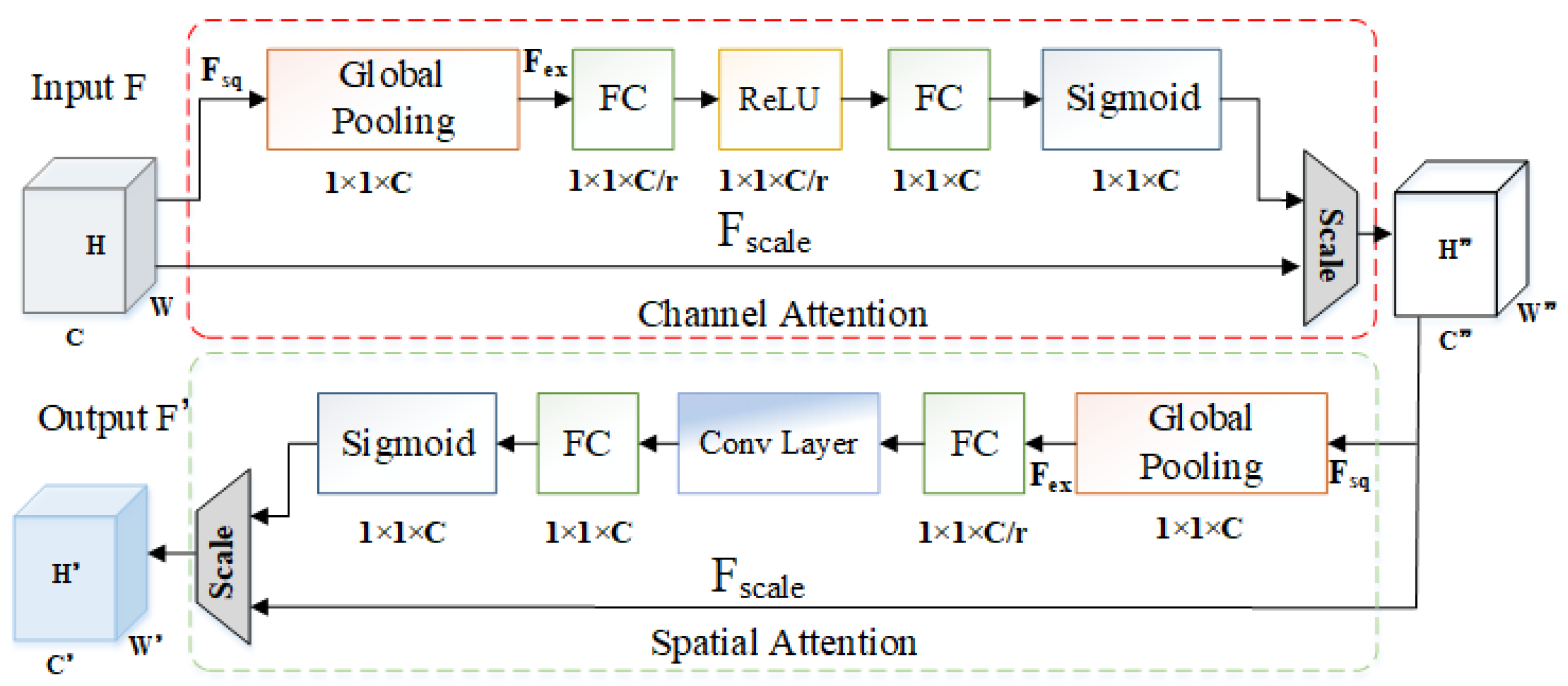
The CBAM depicted in
Figure 3 comprises both the Channel Attention Module (CAM) and the Spatial Attention Module (SAM). The CAM is employed to enhance the weights of important features while reducing the weights of irrelevant features. It begins by subjecting the input feature map to max pooling and average pooling along the channel dimension. The output results are then fused through an MLP network, and subsequently, weight coefficients are obtained by applying the Sigmoid activation function.
where
is the Sigmoid activation function;
and
are the weights, and
r is the contraction rate;
MLP stands for a neural network;
is obtained by performing element-wise summation and applying the Sigmoid activation operation on the shared fully connected layer; and
and
are the two features obtained by pooling the extracted features.
The SAM focuses on the intrinsic relationships within the spatial dimensions of the input feature map. It takes the output from the CAM and performs max pooling and average pooling along the channel direction. The results obtained are then processed through a convolutional layer with a kernel size of 7 × 7. Finally, the SAM’s feature map is obtained by applying the Sigmoid activation function. The calculation is performed with the following equation:
where
f 7×7 denotes the convolution kernel size;
is obtained by the logistic activation function.
3.2. Multi-Pedestrian Tracking Methods Based on IVDM
Pedestrian tracking not only provides trajectory information but also provides valuable information for behavioral analysis. However, in crowded scenes, a large number of targets may be occluded, resulting in missing and blurred features, which seriously affects the function of detection-based tracking methods [
16]. When the video surveillance fields of view do not overlap and the pedestrians are heavily occluded, the “1-n” pedestrian identity phenomenon results. Existing tracking algorithms still lack a flexible approach to dealing with heavily occluded targets and thus perform poorly in complex scenarios where heavy occlusion occurs frequently [
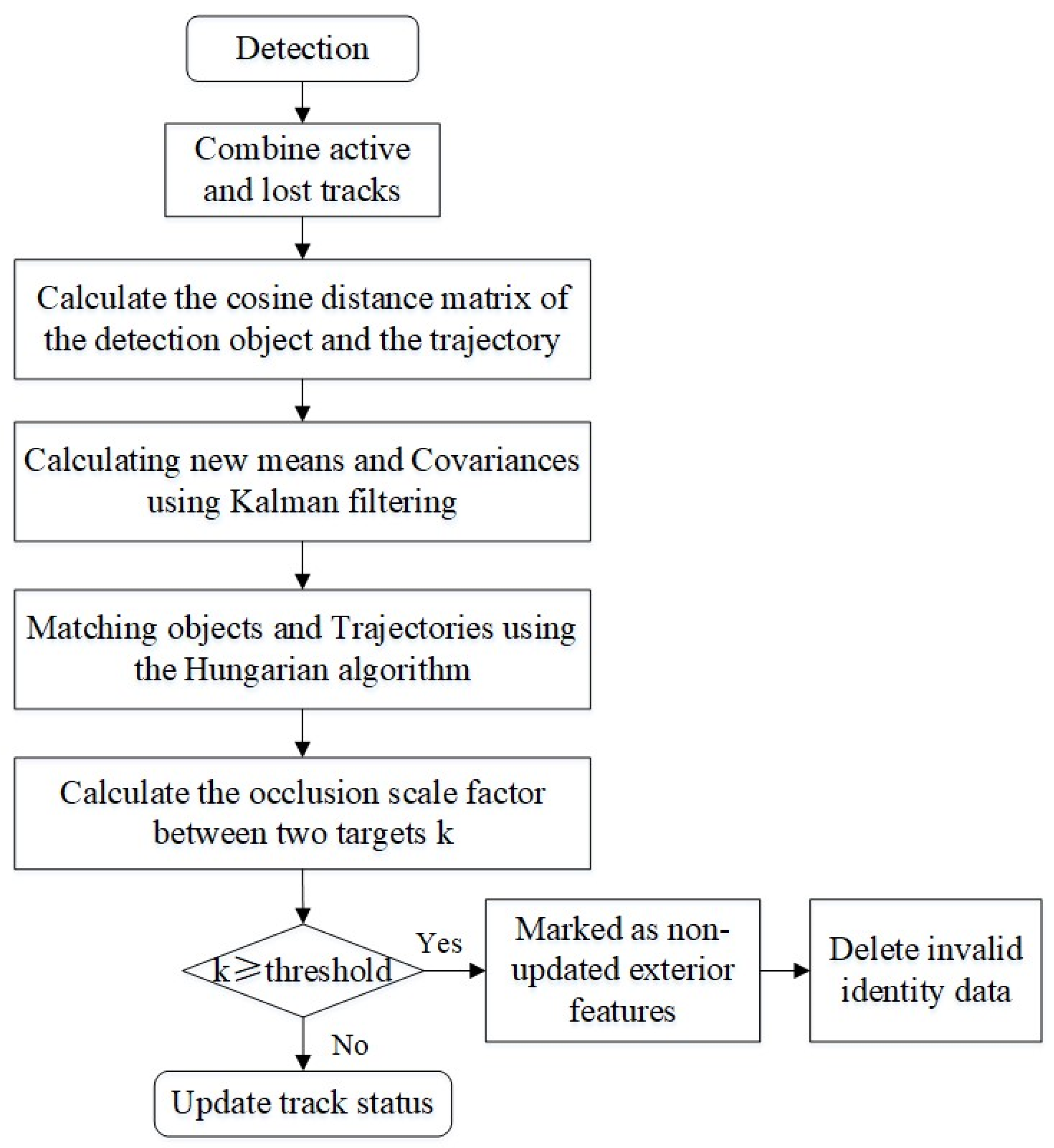
33]. To address the above situation, based on the improved detection method in the previous section, we introduce pedestrian identity validity judgment into the pedestrian tracking process, which performs “occlusion perception-occlusion ratio
k calculation-pedestrian identity validity discrimination” on unmatched targets between different frames (
Figure 4).
The module performs a series of calculation and discrimination operations on unmatched targets between different frames, such as “occlusion perception-calculation of occlusion ratio
k-pedestrian identity validity discrimination”, which determines the degree of occlusion of pedestrians detected by the surveillance video based on the magnitude of the coefficient k of the proportion of occlusion of pedestrians in the frame and categorizes the occluded pedestrians into valid ID
Y and invalid ID
N through
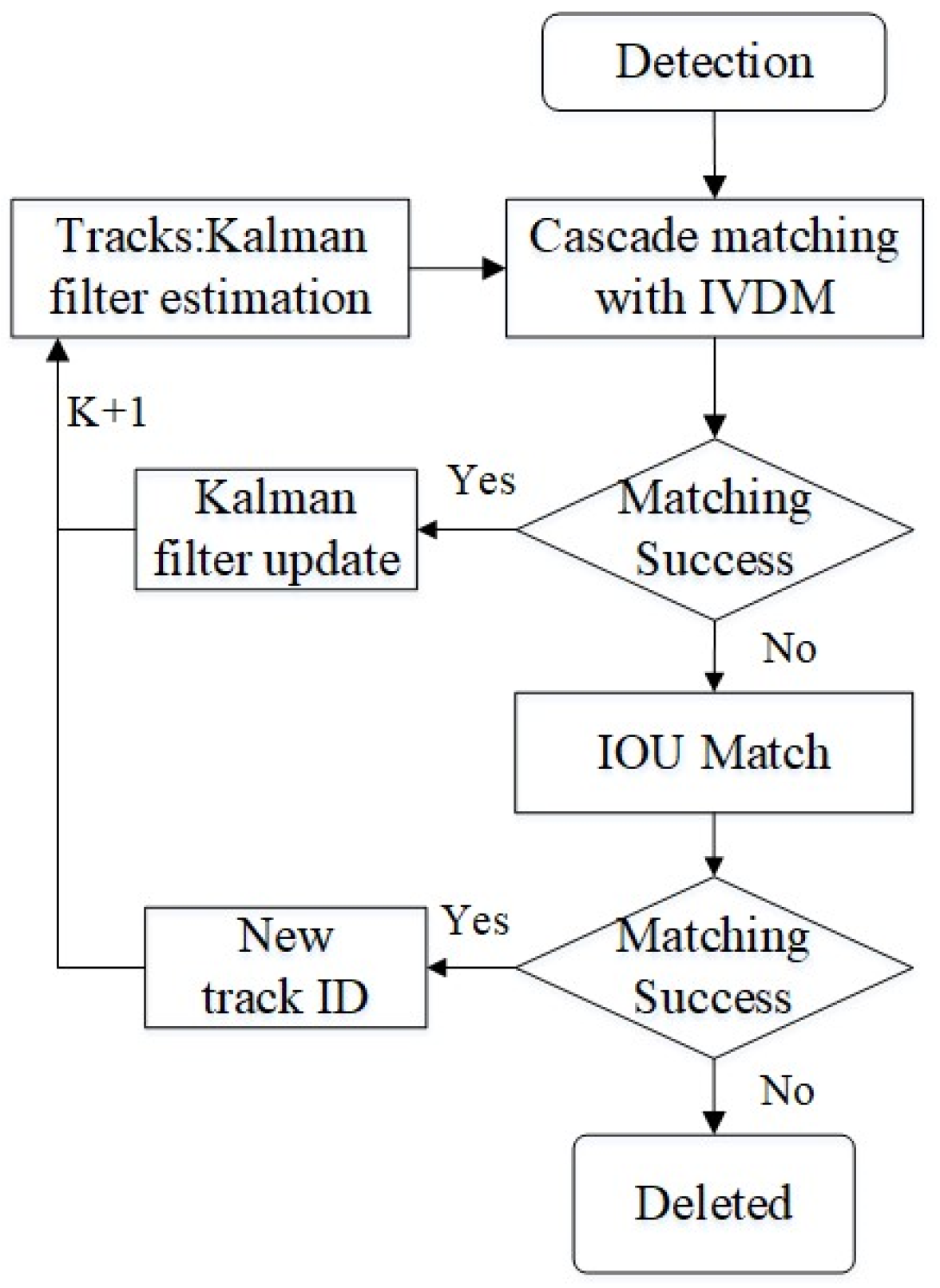
k. In essence, the above process is used to discern whether or not the identity of the detected pedestrian has validity. The most successful associations in pedestrian tracking often occur in the cascade matching section. Therefore, we have incorporated the IVDM into the cascade matching process, as depicted in
Figure 5.
3.2.1. Occlusion-Aware Detection
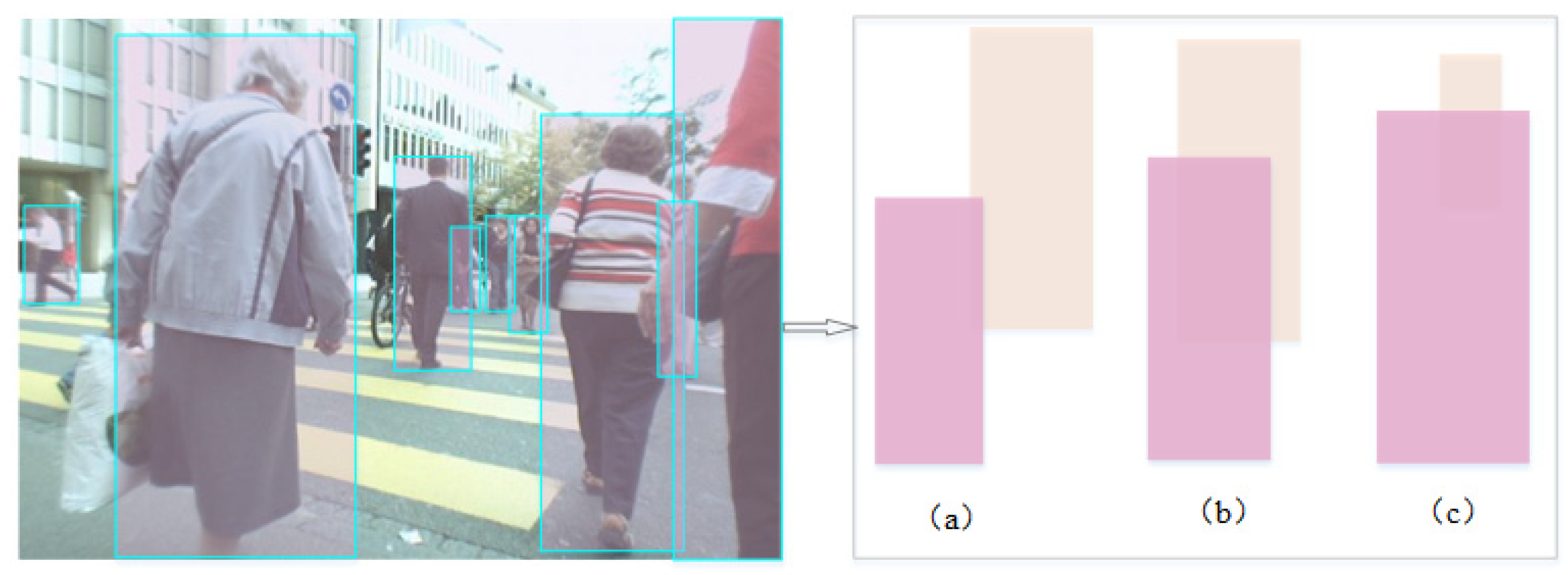
For occlusion-aware detection, traditional Intersection Over Union (IOU) cross-ratio algorithms calculate the overlap ratio and filter targets that satisfy the requirements by setting a threshold [
23].
Figure 6a,b show that the IOU algorithm is effective in discriminating pedestrians when they have similar body size ratios. However, real applications mostly involve complex scenes, and the size of the pedestrian detection frame produces a very large error due to the different distances of the camera from the ground. The IOU algorithm has very little utility in this case (
Figure 6c), which is why it cannot be used as a calculation standard to show the occlusion of pedestrians and small targets in real applications [
13]. Therefore, we propose the identity validity discriminant coefficient
k, which calculates the ratio of the extent of the occluded portion of an occluded pedestrian to its detection frame and can more accurately discriminate the degree of the pedestrian’s occlusion.
3.2.2. Determination of the Shading Scale Factor k
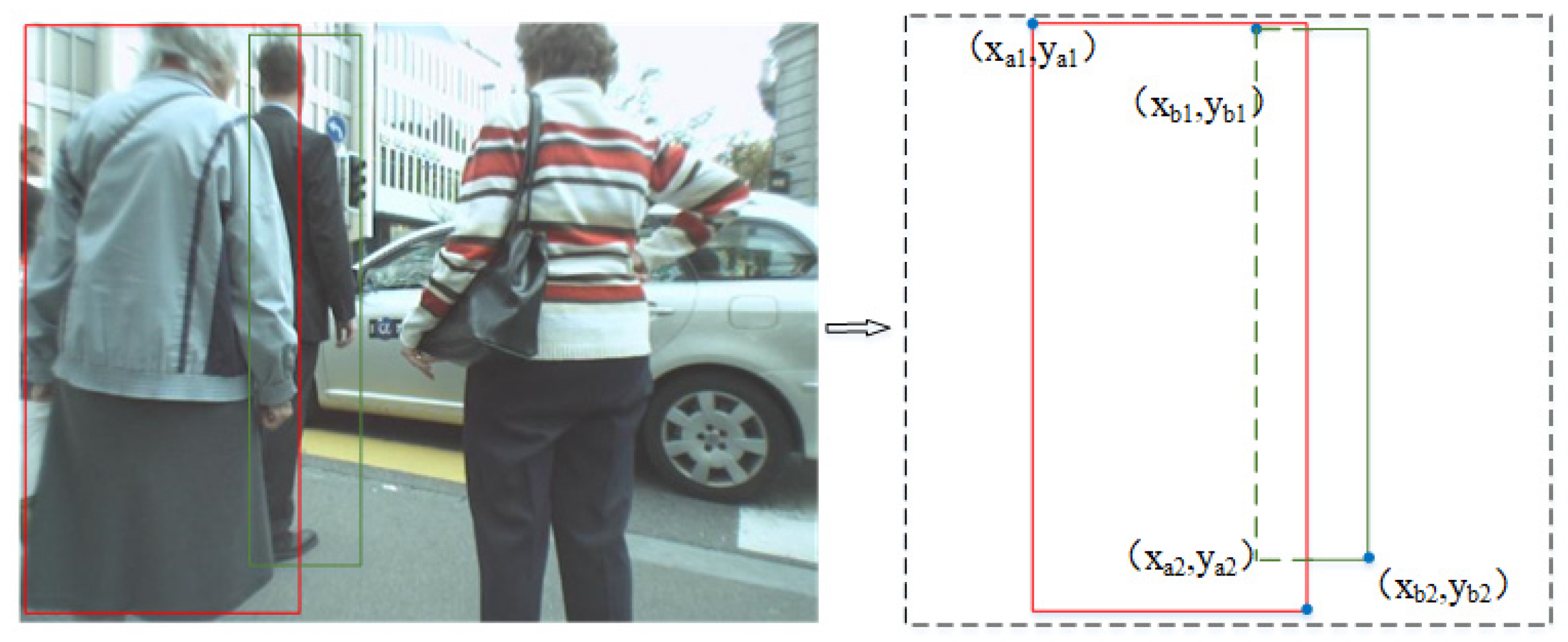
In order to express the derivation of the occlusion ratio coefficient more intuitively, we define the coordinates of the detection frame. As shown in
Figure 7,
denotes the coordinates of the upper-left corner of the blocked pedestrian detection frame;
denotes the coordinates of the upper-right corner of the blocked pedestrian detection frame;
denotes the coordinates of the upper-left corner of the blocked pedestrian detection frame;
denotes the coordinates of the upper-right corner of the blocked pedestrian detection frame;
is the upper-left corner of the blocking section; and
is the upper-right corner of the blocking section, calculated with the following equation:
S denotes the range of the occluded target frame; denotes the range of the occluded region.
Based on the obtained data for each attribute of the pedestrian detection frame, the unmatched target occlusion ratio coefficient
k after cascade matching is derived from the ratio of the occluded area range.
and the occluded target frame range
S are calculated with the following equation:
3.2.3. Identity Validity Determination Module
When two pedestrians form an occlusion, in general, if the center of mass of one target is detected within the detection frame coordinates of the other target, the identity of the pedestrian is determined to be invalid due to the effect of the occlusion, and then the identity validity = 0; otherwise, identity validity = 1. However, when occlusion is generated, the above method will not be able to accurately determine the degree of occlusion of the pedestrian if the center of mass of the pedestrian is not within the coordinates of the other pedestrian detection frames, and then the specific degree of occlusion of the pedestrian needs to be calculated. The degree of occlusion of the pedestrian is determined if the target occlusion ratio coefficient k is greater than a threshold value, and then identity validity =1; otherwise, identity validity =0.
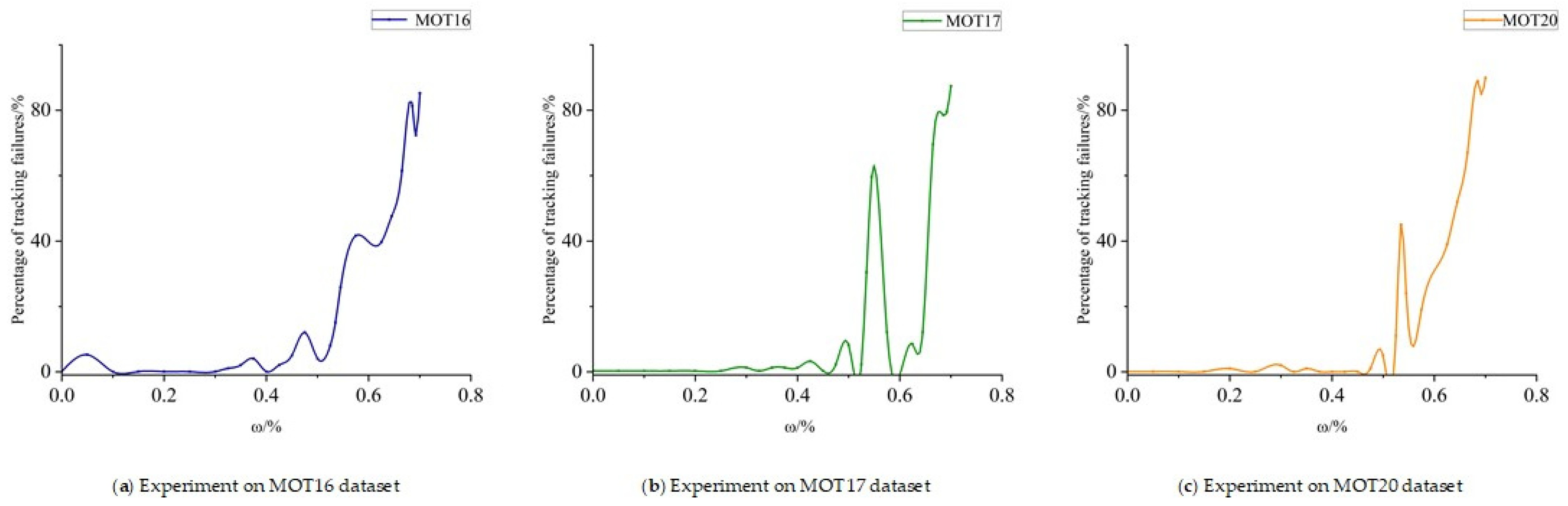
In this study, the original model was tested on consecutive frames from the MOT16, MOT17, and MOT20 datasets. Based on the experimental responses in
Figure 8, when
k > 0.535, the proportion of tracking failures due to occlusion increases significantly.
The identity validity is binarized by the occlusion ratio coefficient
k as the identity validity score of the corresponding pedestrian, where 1 indicates that the target identity is invalid and 0 indicates that the pedestrian identity is valid, and the relationship of the identity validity score calculation is calculated with the following equation:
5. Discussion
This study introduces a method for the multi-object tracking of pedestrians across multiple cameras in complex scenes, and it exhibits a higher tracking accuracy compared to existing methods in practical applications. However, like any research, our work has certain limitations that need to be considered. One major limitation is the potential influence of environmental factors on the accuracy of our model. For instance, the spacing between cameras could impact the accuracy of our tracking algorithm. Additionally, further research on the algorithm using different datasets can enhance its robustness and generalizability.
Furthermore, in order to enable rapid and accurate tracking of critical targets in applications such as public safety and fire protection systems, our next step will involve considering the design of a more lightweight model to reduce storage and computational requirements. These studies will contribute to expanding the applicability of our approach and assist in the development of more efficient and powerful pedestrian tracking algorithms.
6. Conclusions
In this research, we have developed a multi-pedestrian tracking method based on deep detection and identity validity assessment, specifically designed for complex surveillance video scenarios where issues like target occlusion are frequent.
We have constructed the KC-YOLO network as the detector, which employs the k-means++ clustering method to select the optimal target detection frames. Additionally, we have integrated a convolutional attention mechanism into the target detection algorithm, utilizing attention weights for adaptive feature refinement. This effectively suppresses secondary features to highlight crucial target characteristics, enhancing the robustness of target detection in complex scenes, where target features may become less distinct due to occlusion. The robustness of the detector has been verified through experiments.
In the target tracker, we have introduced the IVDM, which performs occlusion-aware processing on pedestrian targets after feature extraction by the detector. In cases where target identities are compromised due to occlusion-induced errors, we use the occlusion coefficient “k” to assess the validity of the identity. Based on the output of this module, we determine whether pedestrian targets possess valid identities, influencing the decision to update the appearance features of the current dynamic target.
Here are the experimental results on the MOT16 dataset: MOTA is 75.9%, and IDF1 is 74.8%. Compared to SORT, there is a 20.1% increase in MOTA and a 21.0% increase in IDF1. In comparison to CNNMTT, MOTA has improved by 10.7%, and IDF1 has seen a 12.6% improvement. When contrasted with the prototype DeepSORT method, MOTA has increased by 1.1%, and IDF1 has increased by 1.2%. The most noteworthy aspect is the substantial reduction in IDS, maintaining a high level of tracking continuity. For the MOT17 dataset, MOTA is 78.5%, and IDF1 is 77.8%. For the MOT20 dataset, the results show a MOTA of 70.1% and an IDF1 of 72.4%. When contrasted with the prototype DeepSORT method, the MOTA and IDF1 indices of our proposed method are improved by 3.3% and 4.5%. These experiments confirm that our research outperforms several advanced MOT algorithms across nearly all metrics. This study provides a stable and efficient approach to multi-pedestrian tracking in complex scenarios, significantly reducing the number of ID switches to ensure the continuity of tracking trajectories. This approach is particularly well suited for public safety and fire protection departments, enabling the continuous tracking of critical targets in crowded scenes with severe occlusion.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}