1. Introduction
The intelligent maintenance of railway equipment has garnered increasing attention as a way to enhance sustainable transportation and manufacturing [
1,
2]. As an essential topic in prognostics and health management (PHM), fault diagnosis can help reduce the workload for inspectors and enhance the efficiency of traditional regular inspections [
3,
4]. Intelligent fault diagnosis technology applications can concurrently enhance the reliability and transportation efficiency of rail systems. With the timely and accurate diagnosis and repair of faults, railway transportation can better meet the demands of industrial supply chains, ensuring the safety and timely delivery of goods.
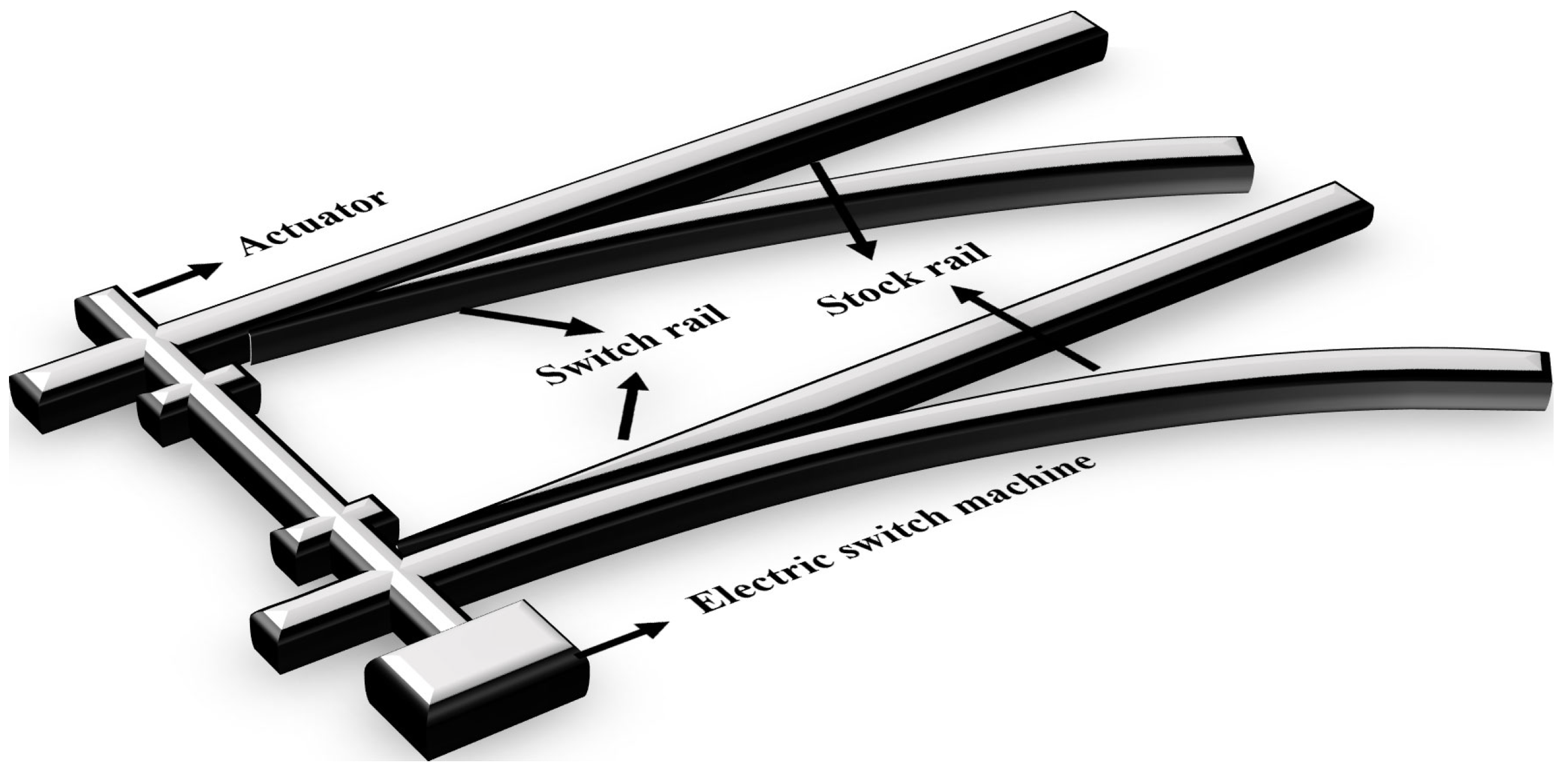
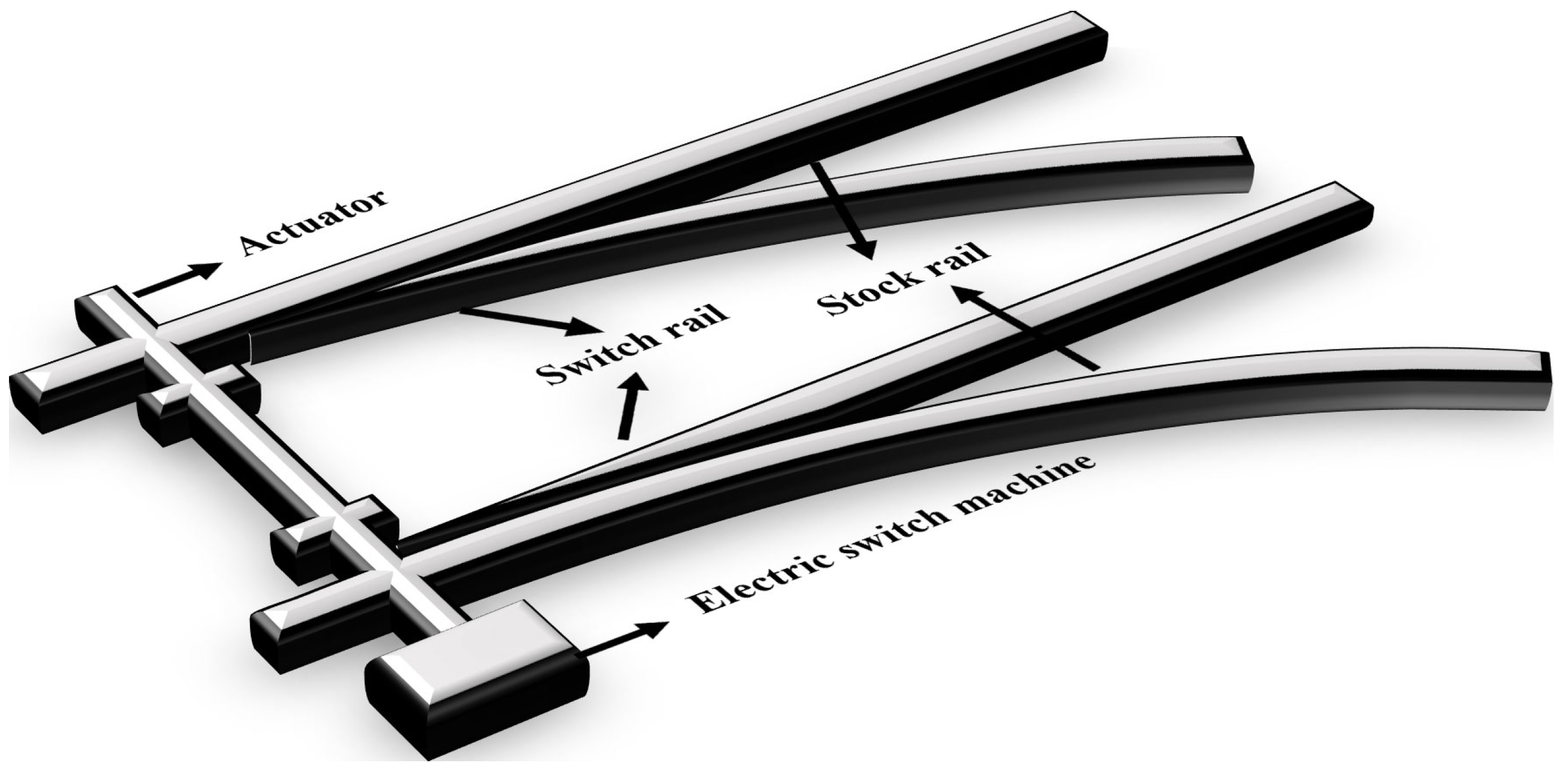
The traffic planning of railways primarily relies on controlling turnouts. Turnouts are essential elements of railway systems because they allow track switching and enable trains to travel on different routes [
5,
6]. The turnout switch machine system comprises stock rails, switch rails, and switch machines [
7,
8], as shown in
Figure 1. However, these turnouts may encounter failures due to various factors, disrupting the transportation process. Therefore, the proper functioning of turnouts is crucial to maintaining the safety and efficient operation of trains, as well as to enhancing transportation efficiency.
Currently, there is a growing focus on data-driven intelligent fault diagnosis research in railway turnout. The primary approach to diagnosing faults in railway equipment relies on the use of train monitoring data [
9]. Turnout fault diagnosis methods generally involve data acquisition, feature extraction, and pattern recognition [
10,
11]. From a feature construction perspective, these methods can be divided into three categories: pattern recognition, distance measurement, and deep learning methods. Pattern recognition methods generally rely on statistical or signal-processing-based indicators [
12]. Ji et al. [
3] developed a fault diagnosis model for rail transit turnouts by extracting statistical features through curve segmentation. Sun et al. [
13] introduced fractional calculus into wavelet packet decomposition energy entropy to represent switch fault characteristics. Chen et al. [
14] proposed an energy-based threshold wavelet method for turnout fault diagnosis. Although these methods achieve a satisfactory performance, the extracted features lack interpretability, which affects their application in practical engineering. The method employed for the on-site detection of railway equipment involves the interpretation of monitoring data curves through the visual inspection of corresponding images. Images are better suited for processing curve data because they contain more detailed structural information, thereby aligning with real-world scenarios. However, the aforementioned methods reshape their structures into vectors to fit the model, disregarding the spatial structure of the original time-domain signal, resulting in information loss. By contrast, the distance measurement methods aim to identify the fault by evaluating the distance between the test and standard curves [
15]. Zheng et al. [
16] used the Hausdorff distance to calculate the similarity of an action power curve and built a fault-detection model. Huang et al. [
17] adopted the Fréchet distance to measure the similarity of the current action curve to identify normal versus abnormal data. These methods facilitate fault diagnosis by assessing distances between curves, demonstrating notable interpretability. However, a marked dependence on standard curves renders these methods infeasible for broad generalization.
Deep learning with automatic features has experienced rapid development in recent years [
5,
18,
19,
20]. Guo et al. [
21] developed an unsupervised railway turnout fault detection method using a deep autoencoder. Li et al. [
22] proposed an autoencoder-based fault diagnosis method for railway turnout. Lao et al. [
23] proposed a dual-scale neural network-based fault diagnosis method to solve the data scarcity problem in labeled fault data. The method used a one-dimensional vibration signal as the input. These methods effectively mitigate the limitations associated with expert experience. However, the data processing or model in these studies ignores the structural information of the time series data, resulting in the loss of spatial structure-related information and subsequently impacting the method’s performance [
24,
25].
In recent years, matrix-based machine learning has gained attention as a pattern recognition method that utilizes matrix data as inputs [
26]. Relative to vector-based pattern recognition and deep learning methods for railway turnout fault diagnosis, matrix-based machine learning can preserve the structural information of the time series data. Additionally, unlike distance measurement methods that heavily rely on standard curves, this approach is not constrained by predefined curves, enhancing its adaptability to diverse datasets. Luo et al. [
27] introduced a support matrix machine (SMM) that employs the hinge loss, Frobenius norm, and kernel norm to integrate the structural information of the input matrix. Support vector machine (SVM) is designed for vector inputs. However, when dealing with matrix data, it is necessary to reshape the matrix into a vector, which may result in the loss of structural information. In contrast, SMM operates directly on matrix data, preserving the inherent structural information. SMM extends the concept of SVM to matrices and utilizes the hinge loss, Frobenius norm, and kernel norm to integrate the structural information of the input matrix. This enables SMM to capture the dependencies and relationships between different elements of the matrix. Subsequently, many improved SMMs have been developed to enhance performance in various classification scenarios. Li et al. [
28] presented a least squares interactive SMM to improve computational efficiency and address the SMM problem in multi-quadratic programming. Zheng et al. [
29] built upon the objective function that combines multiclass hinge loss and regularization terms. However, these models tend to be sensitive to noise, which is attributed to the integration of hinge loss functions. Fault diagnosis is a multiclassification problem. Datasets for industrial scenarios generally contain a lot of noise. To solve the limitation in noise-sensitivity and enhance the performance of MSMM for fault diagnosis problems, we design a pinball loss function-based [
30] MSMM called the PL-MSMM. We then employ PL-MSMM to diagnose turnout faults. The main contributions of this study can be summarized as follows:
A multiclass classifier with a pinball loss function is designed, namely PL-MSMM. Industrial datasets often contain noise. This classifier is better equipped to handle noisy data, making it well-suited for real-world industrial scenarios.
A railway turnouts fault diagnosis method with monitoring signal images and the designed PL-MSMM is proposed. It does not rely on the standard curve and takes into account the spatial structure of the time series monitoring signal, giving it better generalizability and performance.
The proposed method is validated using a real-field current dataset. The experimental results demonstrate its efficiency as a turnout fault diagnosis framework in practical scenarios.
The remainder of this paper is structured as follows. The proposed classifier is presented in
Section 2. The proposed diagnostic method is described in
Section 3. The testing of the proposed method using field data is discussed in
Section 4. Finally,
Section 5 concludes the paper and provides recommendations for future work.
4. Experimental Results and Discussion
4.1. Data Description
In this study, a current signal obtained from a subway ZDJ9 turnout was utilized as the dataset. Because the turnout was an electronic actuator, its movement could be reflected by the current signal. Accordingly, Casco Corporation collected and provided the field data used in this study. The data were collected and tested on the Shanghai Metro Line 13.
The current curve includes three-phase currents—A, B, and C—under a 380-V AC power supply. Compared with the B- and C-phase current curves, the A-phase current curve can provide more comprehensive information about the turnout action [
33]. Therefore, in this study, the A-phase current curve was used to monitor the turnout status. The state transition of the turnout machine could be divided into two cases—that is, from the locked position to the reverse position, and from the reverse position back to the locked position. The waveforms and trends of the A-phase currents in these two cases were identical. Consequently, the normal operation of a turnout machine could be divided into the following four stages: unlocking, transition, locking, and release. The representative current waveforms of the four stages are shown in
Figure 4. The sampling frequency of the ZDJ9 AC electric point machine for the rotating turnout was 25 Hz, and the time required to complete one state transition was 7–9 s. Because of the different fault phenomena resulting in different action times, the number of points collected was inconsistent. Therefore, unifying the number of points was necessary to ensure a consistent data input format. In this study, zero padding was adopted to uniformly pad each data group to 250 points.
By analyzing the microcomputer monitoring turnout current field data and combining the experience of relevant experts in the field of turnout fault diagnosis, the current turnout curve could be divided into normal data and eight types of fault data, resulting in a total of nine types of curves, as shown in
Table 1 and
Figure 5. Due to the limited number of fault samples in certain categories in the dataset, the SMOTE method, implemented using MATLAB functions, was employed to expand the experimental sample set and balance the category data [
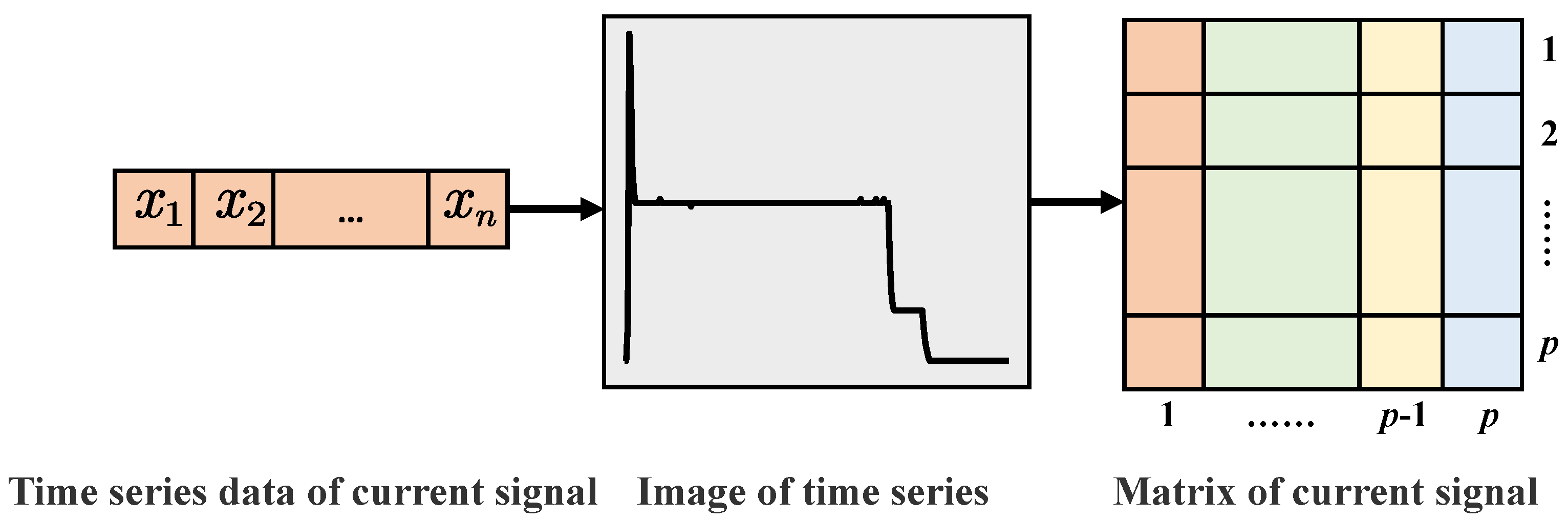
34]. Information on the action current curve was concentrated in the curved part, which could then be transformed into a binary image by converting the curve-sequence data. Each image was of size
. This processing method not only standardized the input format in the data preprocessing stage but also did not require complex signal-processing calculations or destroy the spatial structure of the current curve.
4.2. Experimental Setup
As mentioned previously, the proposed method was validated using actual turnout data from a subway. Comparative experiments were conducted to analyze the proposed method. All models were implemented on a computer with an NVIDIA RTX 3050 GPU and an Intel i5-12500H CPU. The proposed PL-MSMM hyperparameters included C, , and p. We conducted a detailed hyperparameter tuning process and determined the optimal combination of hyperparameter values by conducting experiments with different parameter combinations. Specifically, we chose C from and manually adjusted for each C, selecting p from
To thoroughly evaluate the classifier’s classification performance, we chose three evaluation metrics—that is, accuracy, precision, and F1-score. The F1-score can be calculated by precision and recall. Because the precision, recall, and F1-score are binary metrics, we adopted a macro-averaging approach to average the same measurements computed for each individual class. These evaluation metrics can be expressed as follows:
where
,
,
, and
denote true positives, false positives, false negatives, and true negatives, respectively.
4.3. Comparison with Existing Methods
The proposed method was compared with existing fault diagnosis models to evaluate its performance. The compared models included the convolutional autoencoder (CAE) [
35], CNN [
36], and MSMM [
29] models. Details of the methods and their parameter adjustments can be summarized as follows:
- •
CAE: The input image size was . The encoder contained two convolutional layers. The first and second convolutional layers had 20 kernels of size and one kernel of size , respectively. A pooling layer was added after each layer. The decoder included two deconvolutional layers with the same convolutional kernel size. The network used the Adam optimizer and rectified linear unit (ReLU) activation function, with an initial learning rate of 0.001 and a maximum iteration number of 100.
- •
CNN: The input image size was . The model structure included convolutional, batch normalization, ReLU activation function, max pooling, fully connected, and SoftMax layers. The convolutional layers had 20 kernels of dimensions . Network training used a stochastic gradient descent with momentum (SGDM) optimizer. The initial learning rate was 0.001 and the number of iterations was 100.
- •
MSMM: The training and testing datasets input to the model were two-dimensional images of size . This model was applied to the fault diagnosis problem of turnouts based on current signals. The feature matrix obtained from the data preprocessing was used as the input to train the classifier. All the hyperparameters involved were selected through cross-validation.
The details of the hyperparameter settings and tune ranges in the models are listed in
Table 2. The learning rate, batch size, and number of epochs are represented as
r,
b, and
e, respectively. The MSMM parameters are
C and
.
The model was applied to the problem of current signal-based turnout fault diagnosis, and the image matrix features obtained from data preprocessing were used as inputs to train the classifier. To evaluate the performance of these methods, a ten-fold cross-validation method was adopted. Cross-validation is a widely used model evaluation method in machine learning. In k-fold cross-validation, the dataset is divided into k random subsets, with one subset chosen as the testing set and the remaining subsets used as the training set in each iteration [
37]. This process helps mitigate the adverse effects caused by imbalanced data partitioning in a single split, leading to a more reliable and accurate assessment of the model’s performance. By averaging the results of multiple evaluations, cross-validation provides a more comprehensive and robust estimation of the model’s effectiveness [
38]. The advantages of cross-validation are particularly evident in small-scale datasets, where the impact of imbalanced partitioning is more pronounced. For each class of samples, we randomly selected 500 to form the dataset. The accuracy, precision, and F1-score of the different methods were compared and analyzed using 10-fold cross-validation. The results are shown in
Table 3 and
Figure 6.
In
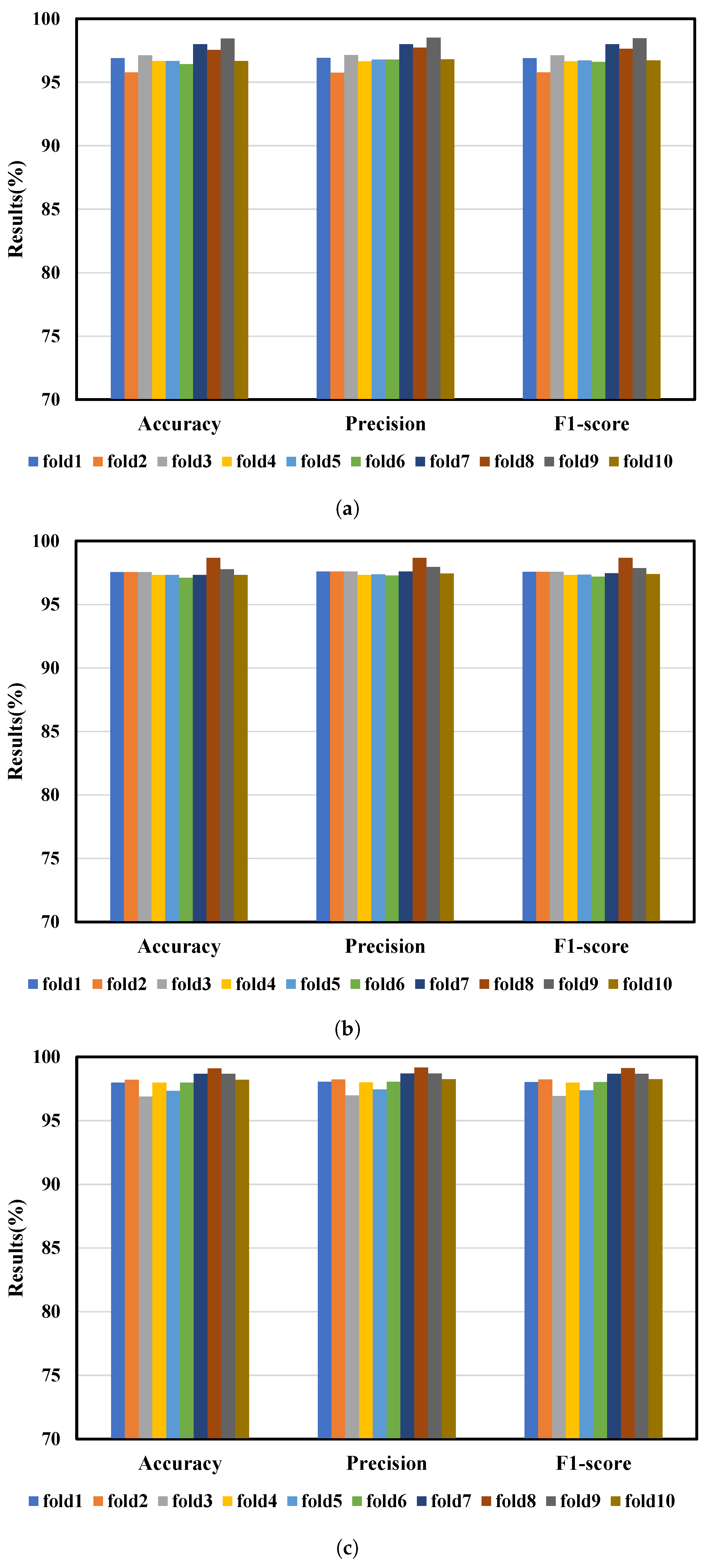
Table 3, the average testing and training accuracy, precision, and F1-score of the four models are presented. The results show that the proposed PL-MSMM method outperforms the other methods in terms of accuracy, precision, and F1-score. The comparative results between matrix learning models (MSMM and PL-MSMM) and non-matrix learning models (CAE and CNN) indicate that the inclusion of structural information from 2D images significantly enhances diagnostic performance. Matrix learning models, which consider the structural information of the input data, have demonstrated superior results.
Figure 6a–d show the testing accuracy, precision, and F1-score when applying 10-fold cross-validation to the four models. It can be seen that the minimum accuracy of PL-MSMM is 98.22% and the maximum accuracy is 99.56%. The overall average classification accuracy can reach 98.67%. Among the 10-fold cross-validation, PL-MSMM achieves the highest accuracy. Its overall diagnostic performance is significantly superior to that of the other models under consideration. In summary, these experimental results show that the proposed PL-MSMM method performed excellently in turnout data fault diagnosis. This provides a feasible fault diagnosis method for practical applications and can achieve efficient fault diagnosis.
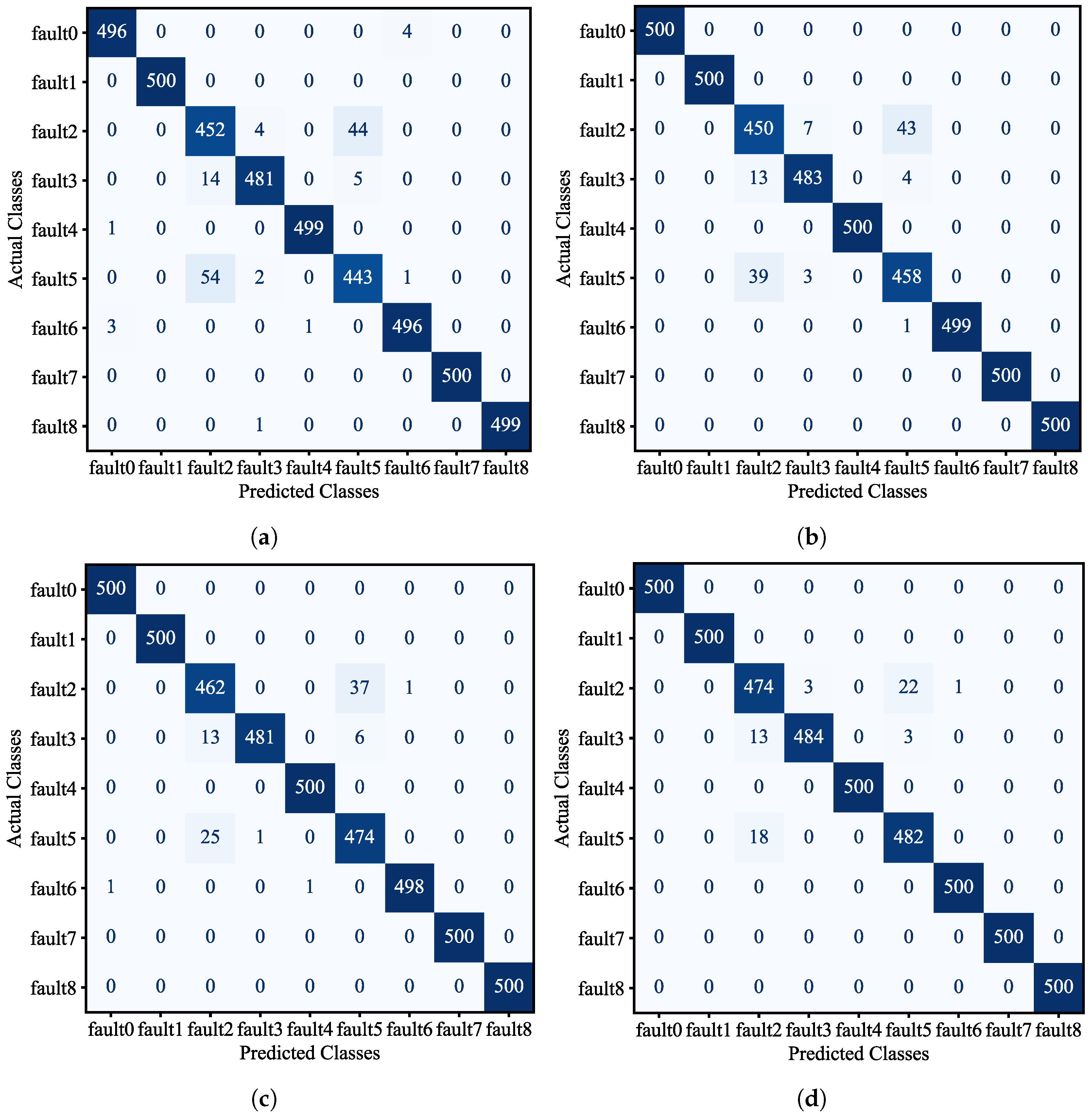
To enhance the illustration of the fault diagnosis results,
Figure 7a–d display the confusion matrix generated by four different models. The confusion matrix provides a visual representation of the relationship between the model’s predicted results and the actual labels across various categories, presented in a matrix format. In the confusion matrix, each column represents the predicted categories, while each row corresponds to the true categories of the data. The elements on the main diagonal of the matrix indicate the number of correct classifications for each respective category.
4.4. Noise Sensitivity Analysis of PL-MSMM
To assess the robustness of the PL-MSMM algorithm, we added noise to the input image and compared it with the case without added noise. We chose the MSMM for comparison. For this experiment, we employed 10-fold cross-validation to evaluate the fault diagnosis accuracy of both methods.
Table 4 presents the average testing and training accuracy, precision, and F1-score of the experimental methods. It should be noted that “Clean” means using the original input image without added noise and “SPN” means using the input image with salt and pepper noise added.
It is evident that the proposed algorithm outperforms the MSMM method, indicating its effective handling of noise in the input data while maintaining high classification accuracy and robustness. In contrast, the MSMM method performs poorly when noise is added, suggesting its difficulty in coping with noisy data, which leads to a degraded classification performance. The results show that the proposed algorithm exhibits a smaller accuracy difference of 0.99 compared to the MSMM method’s difference of 1.62 when noise is present. The proposed algorithm demonstrates relatively smaller fluctuations in results when affected by noise. Furthermore, when considering the relative percentage difference (RPD) as a metric, the RPD value for the PL-MSMM method, relative to the accuracy without noise, is 1.00%. In comparison, the RPD value for the MSMM method is 1.65%. This indicates that the percentage decrease in performance when handling noisy data is smaller when using the PL-MSMM method. Owing to the noise insensitivity of the pinball loss function, the PL-MSMM achieves better results than the MSMM on noise-contaminated datasets. This shows that the PLMSMM can handle noise-containing turnout fault datasets more effectively, with robustness and reliability.
4.5. Parameter Sensitivity Analysis of the Proposed PL-MSMM
Finally, a hyperparameter sensitivity experiment was conducted for the proposed PL-MSMM. The training dataset consisted of 20 randomly selected samples from each class, and the test dataset consisted of 20 randomly selected samples. Hyperparameter
C was adjusted as follows:
. The accuracy of the PL-MSMM on the current dataset is shown in
Table 5 and
Figure 8.
The experimental results show that the performance of the PL-MSMM is sensitive to hyperparameter
C. The choice of hyperparameters depends on the performance of the model in terms of the evaluation metrics. The influence parameter
p on accuracy was also analyzed; the accuracy performance under different
p values is shown in
Table 6 and
Figure 9.
The experimental results show that hyperparameter p has an impact on the model’s performance. Consequently, we need to choose an appropriate p value to obtain the best performance based on the specific application scenario and dataset.
5. Conclusions
The fault diagnosis of railway turnouts is critical for ensuring safe and reliable railway operations. This work developed an effective data-driven approach for diagnosing turnout faults using time-series monitoring data. An intelligent fault diagnosis method for railway turnouts with the support matrix machine was proposed. We have developed a data-driven intelligent method for diagnosing railway turnout faults, which considers the unique attributes of time series monitoring data. To address the noise sensitivity limitations inherent in the multiclass support matrix machine (MSMM), we introduced the pinball loss-based multiclass support matrix machine (PL-MSMM), which is adept at handling noisy industrial data. First, the proposed method employed the original one-dimensional time-series signal to generate a two-dimensional image through data preprocessing. Subsequently, the two-dimensional image matrix was the feature matrix. Next, the proposed PL-MSMM was built by the feature matrix to realize the turnout fault diagnosis. We conducted validation experiments on the proposed method using a current real-world turnout dataset. The effectiveness of the proposed method was verified via a comparative analysis. The proposed method is useful for fault diagnosis of railway turnouts. The diagnostic capabilities developed in this work can enable the condition-based maintenance of turnouts, reducing failures and downtime. By supporting predictive analytics on railway assets, this research promotes sustainable and reliable transportation infrastructure.
Although the proposed PL-MSMM approach has demonstrated proficiency in diagnosing railway turnout system failures, its reliance on extensive labeled data is a limitation, as such data are often scarce and demand considerable domain expertise for accurate annotation. Hence, the feasibility and expense of data labeling present a clear constraint. Future endeavors will explore semi-supervised or unsupervised learning strategies to diminish the reliance on labeled datasets, aiming to further enhance the efficiency and accuracy of fault diagnosis.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}