
Multi-View Masked Autoencoder for General Image Representation


Abstract
:1. Introduction
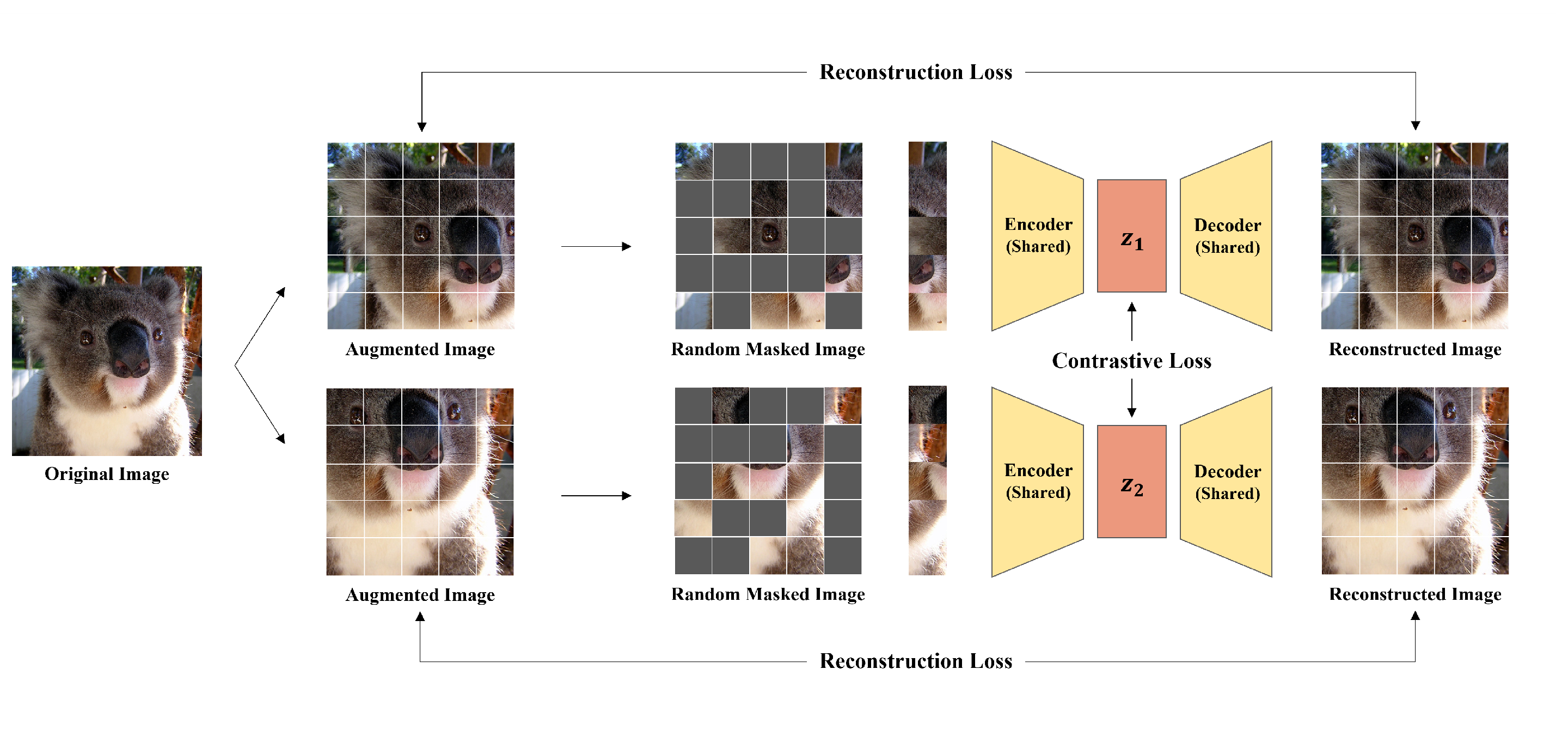
- We propose a simple framework exploiting contrastive learning for MIM to learn rich and holistic representations. The model learns discriminative representation by contrasting two augmented views while reconstructing original signals from the corrupted ones.
- A high masking ratio works as strong augmentation. Without additional augmentation like color distortion, blur, etc., our model shows better performance than previous CL-based methods by only using masking and random cropping.
- Experimental results prove that our work is effective, thus outperforming previous MIM methods in ImageNet-1K classification, linear probing, and other downstream tasks like object detection and instance segmentation.
2. Related Work
2.1. Contrastive Learning
2.2. Masked Language Modeling
2.3. Masked Image Modeling
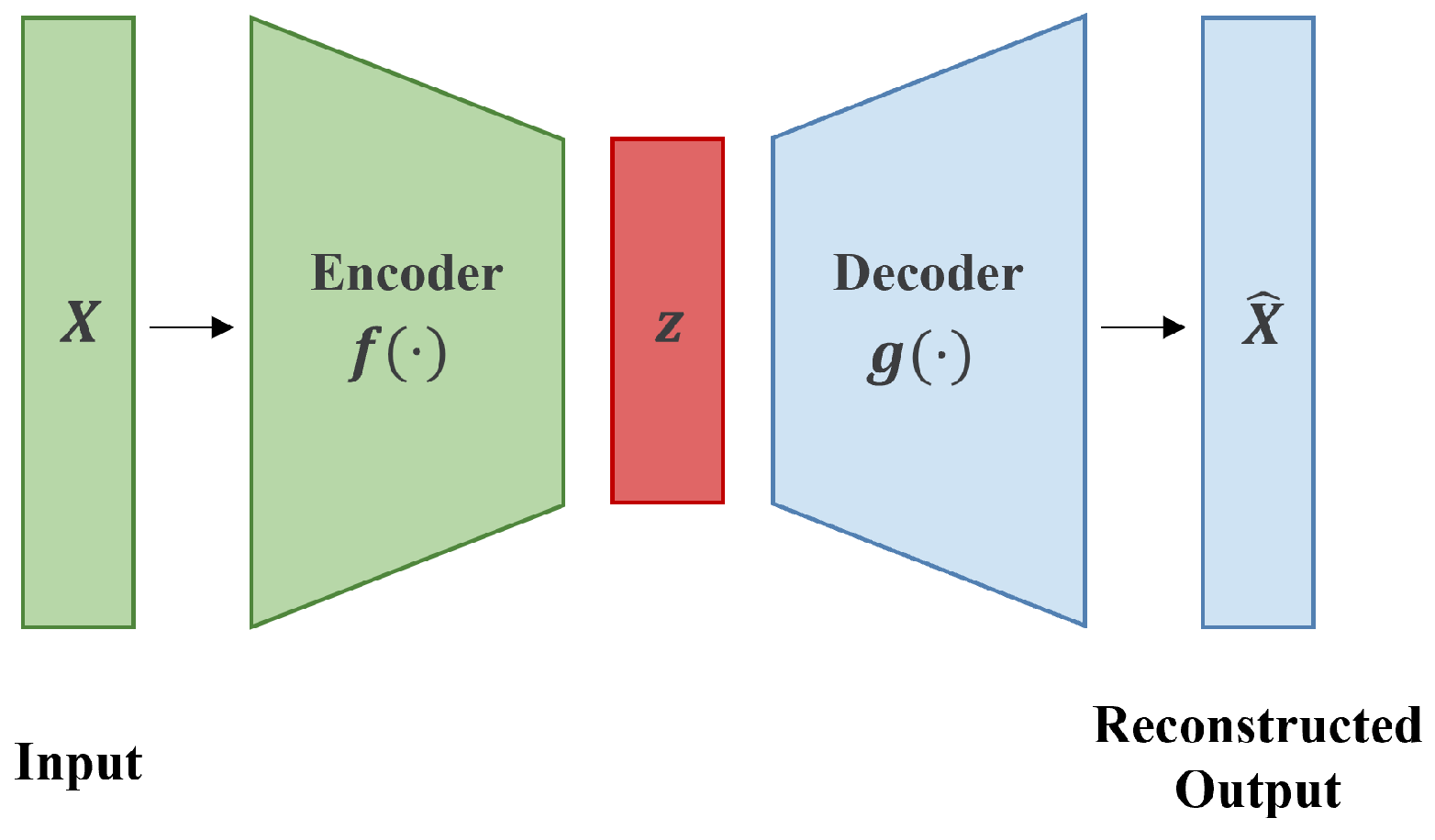
3. Method
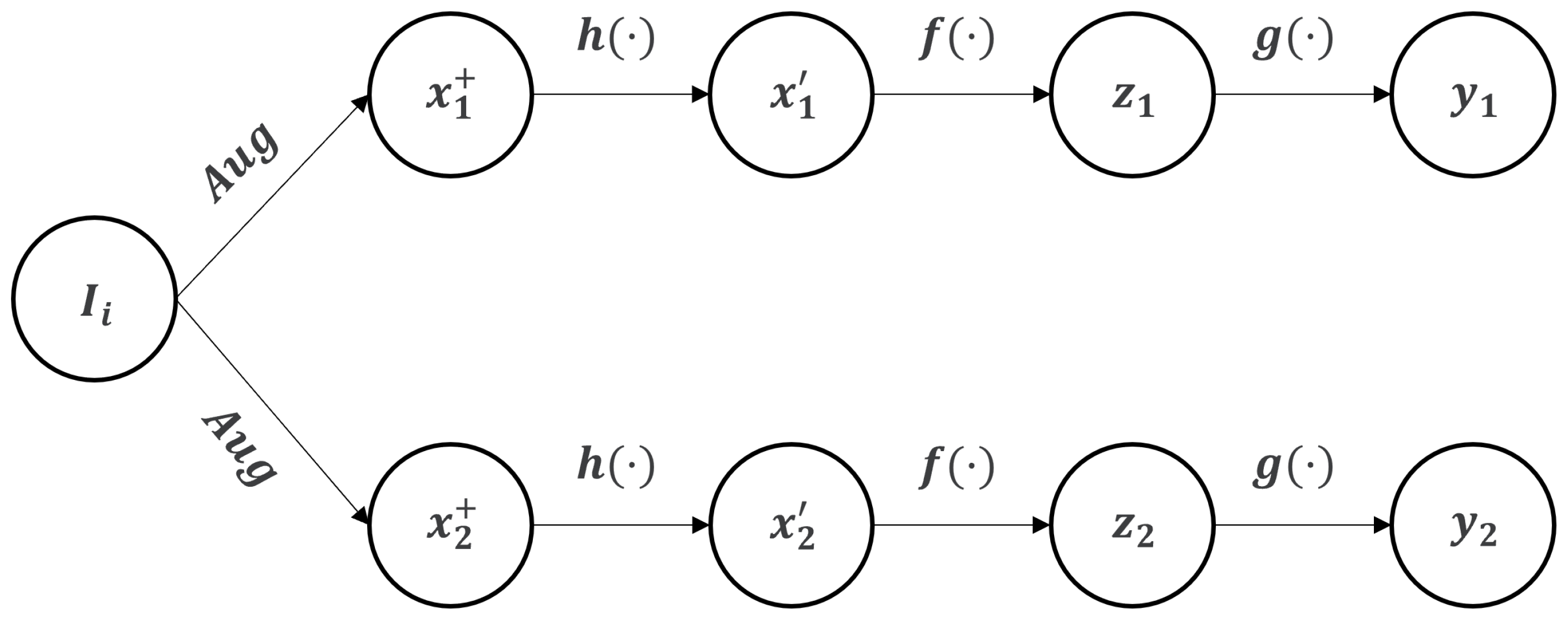
3.1. Framework
3.1.1. Input and Target Views
3.1.2. Patchify and Masking Strategy
3.1.3. Encoder
3.1.4. Decoder
3.2. Training Objectives
3.2.1. Reconstruction Loss
3.2.2. Contrastive Loss
4. Experiments
4.1. Implementation Details
4.1.1. Pre-Training
4.1.2. Fine-Tuning
4.1.3. Linear Probing
4.2. Experimental Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP | AP |
|---|---|---|
| MoCo-v3 [32] | 47.9 | 42.7 |
| BeiT [2] | 49.8 | 44.4 |
| CAE [37] | 50.0 | 44.0 |
| SimMIM [36] | 52.3 | - |
| MAE [23] | 50.3 | 44.9 |
| Ours | 51.3 | 45.6 |
| Method | mIOU |
|---|---|
| MoCo-v3 [32] | 47.3 |
| BeiT [2] | 47.1 |
| CAE [37] | 50.2 |
| SimMIM [36] | 52.8 |
| MAE [23] | 48.1 |
| Ours | 50.2 |
4.2.1. Architecture Analysis
4.3. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Liu, Y.; Sangineto, E.; Bi, W.; Sebe, N.; Lepri, B.; Nadai, M. Efficient training of visual transformers with small datasets. Adv. Neural Inf. Process. Syst. 2021, 34, 23818–23830. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Hendrycks, D.; Mazeika, M.; Kadavath, S.; Song, D. Using self-supervised learning can improve model robustness and uncertainty. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1476–1485. [Google Scholar]
- Zhang, C.; Zhang, C.; Song, J.; Yi, J.S.K.; Zhang, K.; Kweon, I.S. A survey on masked autoencoder for self-supervised learning in vision and beyond. arXiv 2022, arXiv:2208.00173. [Google Scholar]
- Ng, A. Sparse Autoencoder. CS294A Lecture Notes 2011; Volume 72, pp. 1–19. Available online: https://web.stanford.edu/class/cs294a/sparseAutoencoder.pdf (accessed on 3 October 2023).
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. In Machine Learning for Data Science Handbook: Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2023; pp. 353–374. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the 2021 IEEE/CVF international Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Chen, X.; Ding, M.; Wang, X.; Xin, Y.; Mo, S.; Wang, Y.; Han, S.; Luo, P.; Zeng, G.; Wang, J. Context autoencoder for self-supervised representation learning. Int. J. Comput. Vis. 2023, 1–16. [Google Scholar] [CrossRef]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Park, N.; Kim, W.; Heo, B.; Kim, T.; Yun, S. What Do Self-Supervised Vision Transformers Learn? arXiv 2023, arXiv:2305.00729. [Google Scholar]
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 776–794. [Google Scholar]
- Zhang, C.; Zhang, K.; Zhang, C.; Pham, T.X.; Yoo, C.D.; Kweon, I.S. How does simsiam avoid collapse without negative samples? a unified understanding with self-supervised contrastive learning. arXiv 2022, arXiv:2203.16262. [Google Scholar]
- Chen, X.; Xie, S.; He, K. An Empirical Study of Training Self-Supervised Vision Transformers. arXiv 2021, arXiv:2104.02057. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. Available online: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 3 October 2023).
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the 2020 International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, Virtual, 8–24 July 2021; pp. 8821–8831. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- Fang, Y.; Dong, L.; Bao, H.; Wang, X.; Wei, F. Corrupted image modeling for self-supervised visual pre-training. arXiv 2022, arXiv:2202.03382. [Google Scholar]
- Wettig, A.; Gao, T.; Zhong, Z.; Chen, D. Should you mask 15% in masked language modeling? arXiv 2022, arXiv:2202.08005. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Li, Y.; Xie, S.; Chen, X.; Dollár, P.; He, K.; Girshick, R.B. Benchmarking Detection Transfer Learning with Vision Transformers. arXiv 2021, arXiv:2111.11429. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do better imagenet models transfer better? In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2661–2671. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Kolesnikov, A.; Zhai, X.; Beyer, L. Revisiting self-supervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1920–1929. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 6023–6032. [Google Scholar]





| Model | Approach | Training Epochs | Accuracy |
|---|---|---|---|
| SimCLR [13] | CL | 1000 | 80.4 |
| MoCo-v3 [32] | CL | 300 | 83.2 |
| DINO [14] | CL | 300 | 82.8 |
| CIM [37] | MIM | 300 | 83.3 |
| BEiT [2] | MIM | 800 | 83.2 |
| SimMIM [36] | MIM | 800 | 83.8 |
| CAE [24] | MIM | 1600 | 83.9 |
| MAE [23] | MIM | 1600 | 83.6 |
| Ours | MIM+CL | 800 | 83.2 |
| Ours | MIM+CL | 1600 | 84.3 |
| Method | Approach | Pre-Training Epochs | Accuracy |
|---|---|---|---|
| SimCLR [13] | CL | 1000 | 76.5 |
| MoCo-v3 [32] | CL | 300 | 76.7 |
| DINO [14] | CL | 300 | 78.2 |
| BEiT [2] | MIM | 800 | 56.7 |
| SimMIM [36] | MIM | 800 | 56.7 |
| CAE [24] | MIM | 1600 | 71.4 |
| MAE [23] | MIM | 1600 | 68.0 |
| Ours | MIM+CL | 1600 | 76.7 |
| Mask Ratio | Accuracy | Loss Weight | Accuracy | Decoder Depth | Accuracy |
|---|---|---|---|---|---|
| 50% | 79.22 | 0.1 | 78.10 | 1 | 74.89 |
| 75% | 79.09 | 0.5 | 78.09 | 2 | 78.56 |
| 80% | 79.25 | 1 | 78.09 | 4 | 80.03 |
| 90% | 79.23 | 1.5 | 79.31 | 8 | 80.03 |
| 95% | 78.30 | 2.0 | 79.64 | 12 | 79.11 |
| Methods | Accuracy |
|---|---|
| Ours | 79.09 |
| Ours w/o two different targets | 77.86 |
| Ours w/o contrastive loss | 74.33 |
| Baseline [23] | 76.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, S.; Han, S.; Rhee, J. Multi-View Masked Autoencoder for General Image Representation. Appl. Sci. 2023, 13, 12413. https://doi.org/10.3390/app132212413
Ji S, Han S, Rhee J. Multi-View Masked Autoencoder for General Image Representation. Applied Sciences. 2023; 13(22):12413. https://doi.org/10.3390/app132212413
Chicago/Turabian StyleJi, Seungbin, Sangkwon Han, and Jongtae Rhee. 2023. "Multi-View Masked Autoencoder for General Image Representation" Applied Sciences 13, no. 22: 12413. https://doi.org/10.3390/app132212413
APA StyleJi, S., Han, S., & Rhee, J. (2023). Multi-View Masked Autoencoder for General Image Representation. Applied Sciences, 13(22), 12413. https://doi.org/10.3390/app132212413