1. Introduction
Relation extraction (RE) aims to extract structured knowledge from unstructured text and is widely used in various downstream tasks such as knowledge base construction and question answering [
1]. Although most existing RE systems focus on sentence-level RE and have achieved promising results on several benchmark datasets [
2,
3], they are limited in their representation ability to extract relational facts from multiple sentences [
4]. The capability only to capture intra-sentence relational facts cannot cover numerous relational facts that appear across multiple sentences in a document or with more than one speaker in a dialogue, and understanding inter-sentence and intra-document information is more significant in practical scenarios [
5,
6]. Therefore, several studies have shifted their focus toward more challenging but practical RE tasks that require extracting relational information from more extended and complicated contexts, such as documents and dialogues [
7,
8].
The dialogue-based relation extraction (DialogRE) task aims to predict the relation(s) between two entities that appear in an entire dialogue and requires the cross-sentence RE technique in the conversational setting with multi-speakers and multi-utterances [
9]. Due to the multi-occurrences of speakers and utterances in a dialogue, meaningful information that supports the relational facts is spread over the entire dialogue, resulting in low relational information density. To effectively capture and understand the scattered relational information in a dialogue, it is essential to directly exploit the pre-trained language model (PLM) knowledge by appropriately guiding the model on which information is significant in the conversation [
10]. Therefore, to leverage the knowledge inherent in PLM and guide it to identify important information in conversations, we adopt a prompt-based fine-tuning approach along with a trigger generation method in the DialogRE task.
Concerning the direct exploitation of the knowledge of PLM first, a prompt-based learning approach has been proposed and is advantageous in consistency in learning. Unlike the conventional fine-tuning approach, which utilizes the representation of a special classification token
[CLS] from an additional classifier, the prompt-based learning approach directly exploits the learned knowledge of a pre-trained language model by alleviating discrepancy [
11]. In particular, a prompt-based approach using PLMs such as Bidirectional Encoder Representations from Transformers (BERT) [
12] solves downstream tasks by regarding them as a cloze task using the
[MASK] token as a direct predictor, resulting in bridging the gap of learning objectives between pre-training phase and downstream task.
Moreover, providing appropriate guidance on which contextual representation is remarkable for the model in the DialogRE system helps to alleviate the challenge of dialogue relation extraction due to the low relational information density. The trigger, which can be described as a potential explanatory element, is defined as “the smallest span of continuous text that clearly indicates the existence of a given relation” and plays an essential role in understanding contextual features in the dialogue [
9].
Table 1 shows a dialogue example that contains multiple entity pairs and triggers. For example, the first relation (R1) can be easily predicted when the word “mom” is accurately captured and predicted by the model, but there are no triggers aidful for the prediction in the cases of the relation types R3 and R4. As the amount of annotated triggers in the dataset is limited, this scarcity of triggers leads to the difficulty in providing guidance on which information is significant to the model for predicting relations between a given entity pair.
To these ends, we explore a prompt-based learner with trigger generation for dialogue relation extraction to take advantage of the inherent knowledge in PLMs and guide them to identify crucial information in dialogues. Specifically, the DialogRE downstream task is solved with the prompt-based masked-language modeling (MLM) objective, and also the effectiveness of utilization and manual initialization of prompt tokens is analyzed. In addition, the potential of the generated triggers by utilizing the generative approach is explored.
The contributions of this study are summarized in three parts. (1) We present a prompt-based fine-tuning approach with a trigger generation method that alleviates the challenges of dialogue relation extraction. (2) We demonstrate that the prompt-based method, including the manual initialization method in our approach, significantly improves performance on the DialogRE task compared to the baseline model. (3) Moreover, we explore the effectiveness of extracted triggers by a generative approach and analyze their limitation with analytical experiments. By exploring these trigger-generation- and prompt-based approaches, our research aims to capture potential ways to directly leverage the model’s implicit knowledge and guide the model to meaningful clues for dialogue relation extraction.
The remaining parts of this manuscript are organized into the following sections. In
Section 2, previous works related to dialogue relation extraction (
Section 2.1), prompt-based learning (
Section 2.2) and trigger generation (
Section 2.3) are introduced.
Section 3 first explains the overall structure of our approach (
Section 3.1), and the following sections consist of the descriptions of the trigger generation method (
Section 3.2), the construction process of inputs including prompts (
Section 3.3) and the deliberate initialization method of inserted prompts (
Section 3.4). Afterward,
Section 4 covers experimental results and findings, and
Section 5 presents various analyses on the effectiveness of trigger- and prompt-based approaches. Finally,
Section 6 concludes by summarizing the purpose and findings of this study.
3. Materials and Method
We explore an approach to enhance the capturing capability of pre-trained language models (PLMs) by exploiting a prompt-based learning approach and to guide on the crucial information, i.e., generated triggers for the dialogue relation extraction. In the DialogeRE task, each example X consists of a dialogue D = {:, :, …, :}, subject entity , and object entity , where is the n-th speaker and is the corresponding utterance. Please note that the following parts denote the entity pair (, ) as E. When X = {} is given, the dialogue-based relation extraction (DialogRE) task aims to predict an appropriate relation from the set of pre-defined relations R between entities and by understanding D and capturing the scattered helpful information in it.
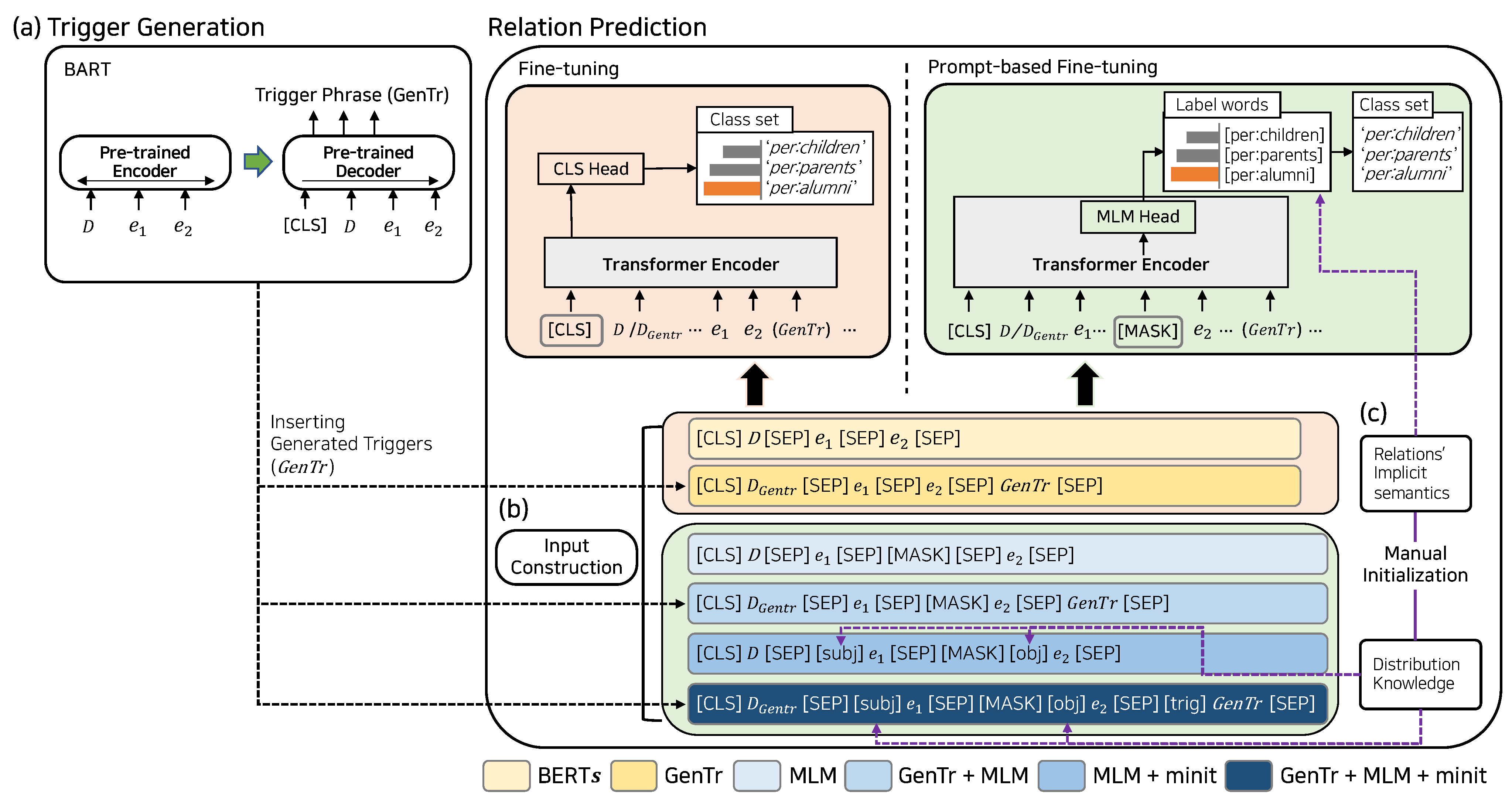
3.1. Prompt Language Learner with Trigger Generation
Figure 1 illustrates the model overview of our approach. Given an input text
X, triggers regarded as informative in the dialogue are generated based on the dialogue
D. Subsequently, these triggers are utilized to construct a prompt-based format for the input text using pre-defined prompt templates, which will be explained in detail in
Section 3.3. The input with the prompt template is then fed into an appropriate model with a different learning objective, i.e., fine-tuning or prompt-based fine-tuning, depending on the type of the constructed input. When employing prompt-based fine-tuning, the model is trained to fill
[MASK] token with a virtual relational token for each relation label. To that end, we add relational tokens to the model’s vocabulary, which correspond to specific relation classes, such as
[per:friends] for the ‘
per:friends’ relation label.
Our approach is composed of the following three parts; (i) trigger generation, (ii) prompt-based fine-tuning method and (iii) the manual initialization of prompt tokens. The methods are applied to the basic dialogue relation extraction model BERT
[
9]. With regard to the type of utilized methods, the relation prediction models are categorized into five types; (a)
, (b)
, (c)
, (d)
, (e)
. BERT
and
follow the previous fine-tuning approach, and
and
follow the prompt-based fine-tuning approach.
3.2. Trigger Generation
Since triggers are absent in a significant number of examples in the dataset, we intend to consider the critical information in predicting an appropriate relation by directly generating it. Unlike the explicit span extraction method, the generative approach is expected to produce implicit answers. The purpose of the generated triggers is to enhance the relation prediction capability by feeding them as one of the input features of the model. In contrast to previous trigger-related studies, our approach employs a generative model with an encoder-decoder architecture, considering both the given entity pair and the given dialogue D.
Our trigger generation module is illustrated in part (a) in
Figure 1. This module generates
(generated triggers) considering the given context and entity pair, thereby identifying the relation
r using
D and entity pair
E, i.e.,
. A single entity pair can include multiple relations in this process. As shown in the left part of
Figure 1, the trigger generation module consists of encoder-decoder architecture by adopting the pre-trained BART [
38] model. The input in fine-tuning step is constructed as “
<s> D </s> E </s>”. The module is taught to identify optimal triggers by defining the triggers of some examples where triggers exist as labels among the examples in the DialogRE dataset, and to generate triggers using the decoder of BART model. The number of generated triggers may be one or several, and the triggers generated in this way are also used as input features to the relation prediction module in the later step. Specifically, for given
, the trigger generator is trained as follows:
where
is the ground-truth trigger sequence to generate and
is the parameter set of the trigger generation module.
3.3. Input Construction
This phase is depicted in part (b) in
Figure 1. To explore the effectiveness of the relation prediction based on how to construct the input structure, we distinguish the input structure construction approach into two objectives; fine-tuning and prompt-based fine-tuning. Following the widely used fine-tuning approach, we investigate the efficacy of the generated triggers. For the prompt-based fine-tuning approach, we explore the specific structure of a prompt template as it significantly impacts overall model performance. Thus, we systematically investigated the impact of different prompt design choices on the quality of extracted relations. In other words, the input design is constructed as six types depending on whether the generated triggers or prompt tokens are included, and the prompts are manually initialized. The set of input construction types is denoted as
, i.e., {
,
,
,
,
}, and a template function,
, is defined to map each example
X to
. Our input construction is employed to the input structure of BERT
[
9] model, the baseline model for verifying the impact of our presented methods, and the input of BERT
is defined as “
[CLS] D [SEP] [SEP] [SEP]”
To utilize the generated triggers when a dialogue
D is given, we define
as the dialogue where the phrases or words identical to the generated triggers are marked with trigger marker
[trig]. Afterwards, the input, which consists of
and an entity pair (
,
), is constructed by employing the template function
as follows and is fed into the fine-tuning model:
To leverage the parametric capability of PLM into the DialogRE task using the prompt-based fine-tuning approach, we regard the downstream task as an MLM problem. The
input type
is constructed by adding
[MASK] token to the input structure of BERT
model, and the generated triggers are added on it to compose the
input type with the generated triggers
as follows:
Finally, as additional information such as entity type or distributional information can be employed as a guiding indicator for the model in the prompt-based approach, we construct input designs
and
by inserting additional prompt tokens based on the template function T
and injecting the additional knowledge. Specifically, the prompt tokens
[subj] and
[obj] are inserted in front of each entity, and additional information (i.e., entity type information) is injected into the prompt tokens by initializing them deliberately. The detailed formulation of this prompt initialization method is described in the following
Section 3.4. Therefore, the input structures for the manual initialization of prompt tokens are designed as follows:
3.4. Prompt Manual Initialization
As described in the previous
Section 3.3, the prompt tokens
[subj] and
[obj] inserted in the input are initialized with the prior distributions of entity types for the entities resulting in the learning of distributional knowledge for the model. In other words, the injection of distributional information is expected to help predict the relation(s) between an entity pair when they effectively learn the distribution of entity types. Specifically, inspired by previous studies on the manual initialization of prompts [
39,
40], we define the entity types as
{
"Person", "Organization", "Geographical entity", "Value", "String"}, exploiting the pre-defined types in the DialogRE dataset. For a given prompt token
corresponding to each entity
and
, we estimate the prior distributions of the entity types
by calculating frequency in the dataset over
as follows:
where
is the embedding from the PLM and
is the initialized embedding of the prompt tokens.
Additionally, each relation representation is deliberately initialized by appending the set of virtual relational tokens
V corresponding to the relation classes into the model’s vocabulary and initializing them with the implicit semantics of the relations as aforementioned in
Section 3.1. Suppose that the
i-th semantic words set corresponding to the
i-th component of
V, i.e., the
i-th virtual relational token
, is denoted as
. Specifically,
is computed by obtaining the average embedding of the semantic words set
. For instance, when the corresponding relational token of the relation label ‘
per:place_of_residence’ is
[per:place_of_residence], we initialize the token by aggregating the embeddings of the semantic words in the set, i.e., {“person”, “place”, “of”, “residence”}. To be elaborated formally, the representation of
is calculated as follows:
where
is the initialized embedding of the relation representation and
is the
j-th component of
. These deliberate initialization processes are shown in part (c) in
Figure 1.
5. Discussion
In this section, we analyze several findings based on the main results presented above (
Table 2 and
Table 3) and additional experimental results.
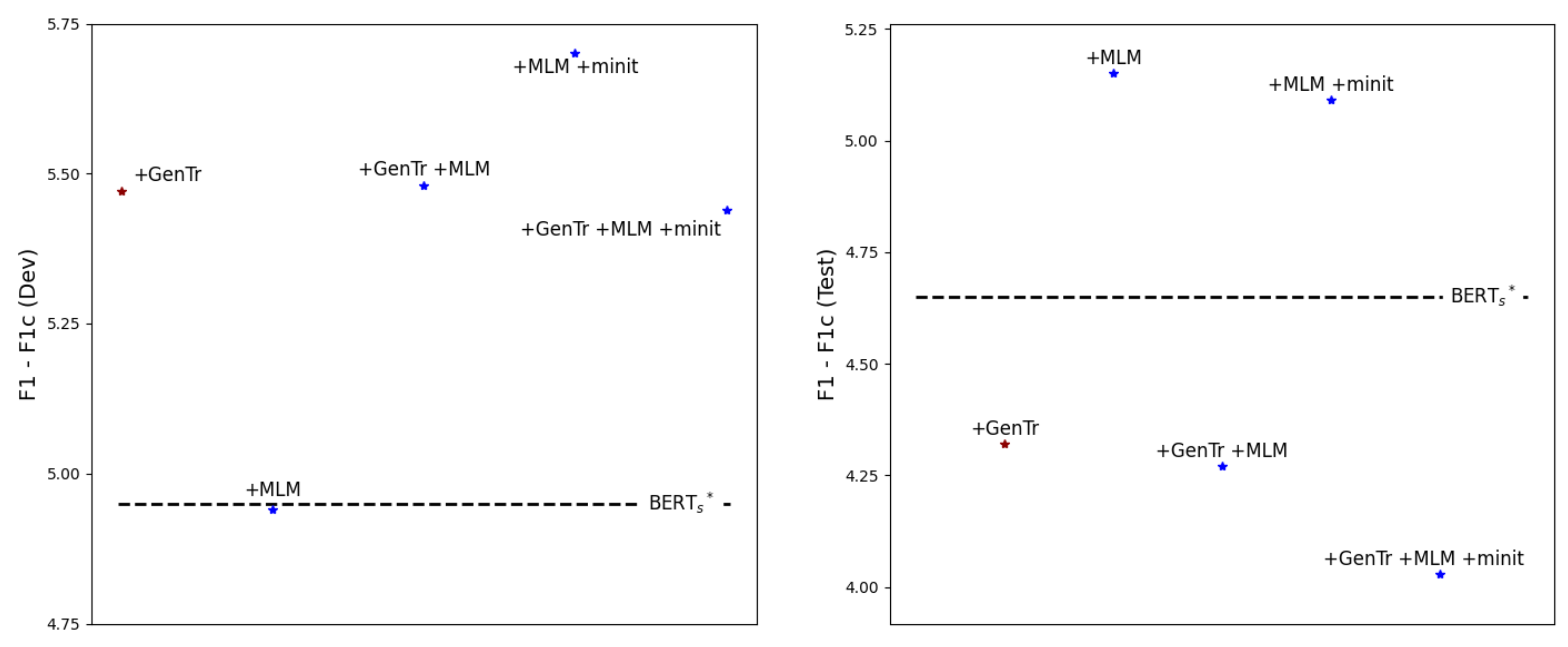
5.1. Learning Distributional Knowledge with Prompt Manual Initialization Is Advantageous
According to
Table 2 and
Table 3, the model with the overall highest performances in both full-shot and few-shot settings is the
model. Moreover, the performance gap between the
model and the
model is considerable, showing at least 1.48%p of improvement both at F1 and F1
in the full-shot setting. We assume that as the
model does not contain prompt tokens for an entity pair, i.e.,
[subj] and [obj], and its relation representation is randomly initialized, the model has difficulty learning the distribution of the training dataset, compared to the
model. Therefore, it is confirmed that injecting the knowledge on the entity type distribution and the semantic information from relation classes is effective, as presented in the previous study [
40].
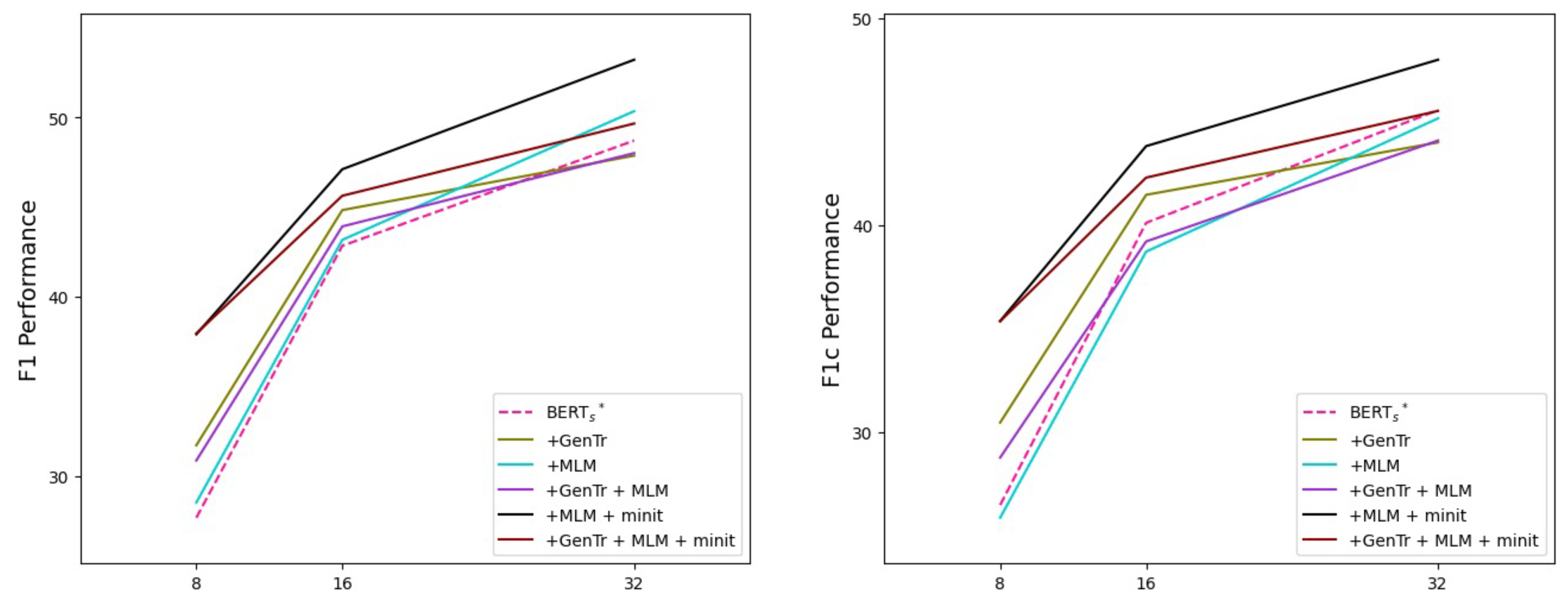
5.2. Generated Triggers Are Apt to Be Practical When Given a Small Number of Examples
As shown in
Table 2 and
Table 3, providing triggers was more effective when only a few examples were given regardless of the learning objectives, i.e., the fine-tuning and prompt-based fine-tuning approaches.
First, compared with the performance of the baseline model, the fine-tuning model with the generated triggers () showed that the full-shot performance slightly dropped by 0.14%p at F1 score in the test set, and the performance in the 32-shot setting also decreased by 0.84%p, implying inconsistent effectiveness. However, compared to the full-shot or 32-shot setting K = 32), the model in the 8- or 16-shot setting showed more significant performance gains, achieving 4.04%p and 1.99%p of improvements at the F1 score and 3.98%p and 1.35%p of increase at F1 score in the test set, respectively. This tendency of performance changes was similarly shown at the F1 score, achieving improvements of at least 1.62%p in the 8- and 16-shot settings, whereas only a minor performance increase or decrease is shown in the full-shot and 32-shot settings.
In addition, the model corresponding to the prompt-based fine-tuning approach with the generated triggers also demonstrated similar results. In the 8- and 16-shot settings of the test set, it showed higher performances at F1 and F1 scores by 2.34%p and 2.9%p (K = 8) and by 0.75%p and 0.49%p (K = 16) than the prompt-based model without the generated triggers (). In contrast, the model achieved higher performances in the 32-shot and the full-shot settings. These results are to be interpreted that the provided triggers serve as helpful clues in a setting with little data to train on, regardless of the learning objectives.
5.3. A Critical Point Is How Appropriate Triggers Are Generated
The generative approach for the triggers did not demonstrate significant performance improvement, particularly in the 32-shot and the full-shot settings. We attribute this minor performance gain to the insufficient quality of the generated triggers, as the annotated ground-truth triggers in the dataset for training are highly scarce. Therefore, we conducted additional comparison experiments to analyze this assumption in detail by changing the type of PLM and inserting an additional input feature.
Table 4 and
Table 5 show the efficacy comparison of the generated triggers according to the type of trigger generation models. We compared two typical generative pre-trained language models (PLMs) with encoder-decoder architecture, T5 and BART [
38]. Specifically, T5-large and BART-large models are adopted for the trigger generation module, and the fine-tuned models with the generated triggers by each model are shown as
(T5) and
(BART), respectively. In the full-shot setting,
(T5) outperformed
(BART) by approximately 0.5%p both at F1 and F1
scores in the development set, but in the test set,
(BART) demonstrated approximately 0.3%p higher scores. Moreover, the
(T5) model showed higher overall performance improvements than the
(BART) in the few-shot setting except for the F1
score when
K is 32. In regard to these results, we assume that the T5 model more effectively handled the problem of lack of triggers to learn due to its large parameter size than the BART model, but we found that this was not a determinant factor.
In addition,
(w/rel) in the full-shot setting indicates a model where the triggers were generated by providing the relation class
r as an additional training input feature, and the input for this model is constructed as “
<s> D </s> E </s> r </s>”. Utilizing the triggers generated in this way led to an exponential increase in the relation prediction performances, achieving performance improvements of more than 10%p at F1 and F1
scores in both data splits. This result confirms the significance of providing appropriately generated triggers to the model as demonstrated in the previous paper [
9].
Table 6 shows an example of the comparison between the generated triggers by the three model types, i.e.,
(T5),
(BART) and
(w/rel). In the case of the first relation (R1), all three models generated “boyfriend” as a trigger, whereas only the
(w/rel) model correctly generated a trigger “love”, for the second relation (R2). In addition to the given examples in the table, there are several cases in which only the model with the triggers generated using relation classes as an additional input feature correctly predicted triggers, such as a trigger “husband” for the relation “per:spouse”. In other words, redundant phrases.
Thus, with regard to the trigger generation method, we conclude that simply providing a dialogue and an entity pair as input features for generation is insufficient to guide the generative model effectively on the critical contextual information due to the scarcity of the annotated triggers. Moreover, to play a decisive role, triggers should be generated by supplementing the input features with another complement with informational importance comparable to the relation class r. Based on this perspective, discovering the additional significant features for improving the trigger generation procedure even without relation classes will be our future work.
6. Conclusions
This paper explored simple yet effective methods in dialogue relation extraction by introducing prompt-based fine-tuning and the trigger generation approach. Also, their effectiveness is analyzed with additional experiments. In particular, unlike the previous extractive approach, we adopted the generative approach for the trigger generation module and compared the efficacy of the generated triggers between representative generative pre-trained language models (PLMs), i.e., BART and T5. The generated triggers have shown more significant effects in the few-shot setting compared to the full-shot setting, specifically when the shot K is 8. However, due to the insufficiency of ground-truth triggers for training, there still are points to improve the trigger generation module in the future. In addition, the prompt-based approach, including the prompt manual initialization method, which considers the prior distributional knowledge, demonstrated its effectiveness, showing significant performance improvements compared to the baseline model.
To summarize, this study aimed to directly exploit the model’s implicit knowledge in the dialogue relation extraction task through the utilization of a trigger-generation method and a prompt-based approach and guide the model to clues about relational facts. To this end, attempts were conducted to utilize generative models, add soft prompts, and deliberately initialize inserted prompts. Furthermore, motivated by the observations, it is expected to improve task performance by utilizing more diverse generative models for enriching the quality of generated triggers in future work.






{kind=link}
{kind=link}
{kind=link}