
EduChat: An AI-Based Chatbot for University-Related Information Using a Hybrid Approach


Abstract
:1. Introduction
- 1.
- What effective method to build a chatbot to support a specific domain such as issues related to universities?
- 2.
- For languages with limited resources such as Vietnamese, does the combination of various methods without relying on deep learning bring effectiveness?The main contributions of this paper are as follows:
- With only a small dataset in the low-resource Vietnamese language, we have proposed an efficient hybrid method to construct a robust chatbot system for the field of education.
- Within EduChat, for managing dialogues within the specialized domain, we have established an effective set of rules using DCG and introduced the improved random forest algorithm to enhance text classification accuracy.
- The model presented in this paper can be applied to various systems, across different contexts and languages.
2. Related Work
2.1. Rule-Based Chatbots
2.2. Artificial Intelligence-Driven Chatbots
3. The Proposed Model
- 1.
- Start: EduChat initiates the conversation with a welcoming message.
- 2.
- User Input: Users send messages, which can be either questions (queries) or statements.
- 3.
- Understanding and Message Classification: EduChat comprehends the intent and context of the messages as follows:
- ○
- If the user’s input falls within the context of the application:
- ■
- EduChat provides relevant responses by using predefined answers or accessing information from the knowledge base.
- ○
- If the user’s input indicates a request beyond the scope of the application:
- ■
- EduChat acknowledges the request and forwards it to ChatGPT to address such queries.
- 4.
- Conclusion: When user questions have been resolved or when users indicate they have completed their interaction, EduChat concludes the conversation. EduChat bids farewell or provides concluding information.
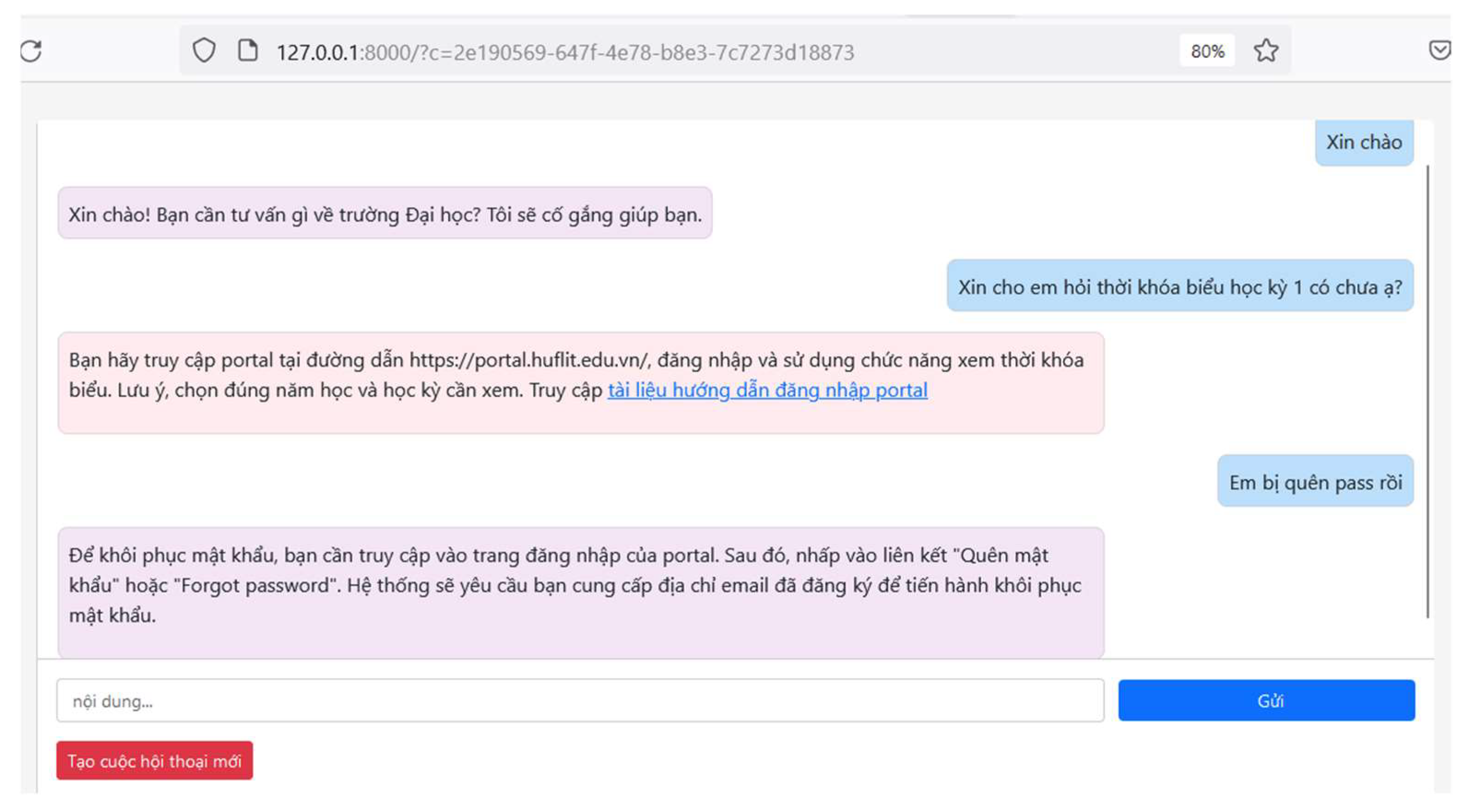
- User Interface: A web-based chat window serving as the user interface.
- Conversation Management: Manages the flow of the conversation. This ensures that EduChat responds appropriately to user input, adheres to the context, and maintains a smooth conversation.
- Knowledge Base: Contains information that EduChat can use to answer user queries. The knowledge base includes frequently asked questions, help guides, and other university-related information.
- Natural Language Processing (NLP) Module: This module allows EduChat to understand and process human language. Its role involves parsing the syntax and semantics of text messages.
- Machine Learning Module: EduChat is equipped with machine learning and artificial intelligence approaches to comprehend and respond to messages that the NLP module cannot handle.
- ChatGPT API: EduChat is integrated with ChatGPT through an API to handle messages evaluated as below the threshold by the machine learning module.
| Algorithm 1. EduChat Algorithm |
| function EduChat(conversation) Input: conversation Output: response content for the user Variables: user_input: the newest user’s message prolog: an instance of the Prolog class. DCG syntax and semantics rules was loaded into this variable. model: an instance of the improved random forest (IRF) model. db: database object. gpt: an instance of ChatGPTConnector, which helps connect to ChatGPT via Open AI’s APIs. 1. user_input = encode(user_input) # user input in Vietnamese will be preprocessed, standardized and encoded. 2. task = prolog.query(user_input) # try to parse the syntax and semantics of user input 3. if task is None then 4. predicted_task, prob = model.predict_prob(user_input) # The IRF model will predict and give the probability of each class. If the maximum probability value is greater than the system’s configuration threshold, the system will accept this classification value. 5. if prob ≥ threshold then 6. task = predicted_task 7. if task is not None then 8. response = db.query(task) 9. else 10. response = gpt.post(conversation, user_input) 11. return response end function |
4. Natural Language Processing (NLP)
5. Intent Classifier Based on Improved Random Forest Algorithm (Machine Learning Module)
5.1. Data Augmentation
5.2. The Improved Random Forest (IRF) Algorithm
| Algorithm 2. IRF_1 |
| Input: S is dataset, Smin is minority class set, Smaj is majority class set, n: number of trees. Output: Weighted trees’ set, {weight(T): T is a tree} 1. Split the set S into train and test. 2. By sampling with replacement, divide train into n training sets, termed as T. 3. For i := 1 to n do (a) Split T into Tmaj and Tmin: Tmaj ⊆ Smaj, Tmin ⊆ Smin. (b) Train T with decision tree learning algorithm. (c) Compute the overall error using Equations (2) and (3) as: N = total number of samples in the tree T. (d) Compute the positive training error, using Equations (2) and (4) as p is total number of minority instances in the tree T. (e) Assign the tree Ti with weight(Ti) = 1/err_ov(Ti) Tree with lower error will obtain higher weight. (f) In case that the overall training errors of the two or more trees are the same, the weights are assigned using the formula: weight(Ti) = 1/err_pos(Ti) |
| Algorithm 3. IRF_2 |
| Input: test is the set of test samples, W = {weight(T)} is the set of weights of all trees T. Ouput: Classified test set 1. Classify test with all the trees 2. For each sample x’ in test (a) for each tree Ti in the forest obtains the outcome label as y(x’) = f(x’) from Ti (b) determine the final outcome, F(x’) by using Equation (5). |
6. Experimentation and Evaluation
6.1. The NLP Module
6.2. Intent Classifier
6.3. System Testing and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS’20), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.-C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DIALOGPT: Large-Scale Generative Pre-training for Conversational Response Generation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics (ACL), Online, 5–10 July 2020; pp. 270–278. [Google Scholar] [CrossRef]
- Adiwardana, D.; Luong, M.-T.; So, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a Human-Like Open-Domain Chatbot. arXiv 2020, arXiv:2001.09977v3. [Google Scholar]
- Reddy, M.D.M.; Basha, M.S.M.; Hari, M.M.C.; Penchalaiah, M.N. Dall-e: Creating images from text. UGC Care Group I J. 2021, 8, 71–75. [Google Scholar]
- Pereira, F.C.N.; Shieber, S.N. Prolog and Natural-Language Analysis; Microtome Publishing: Brookline, MA, USA, 2005. [Google Scholar]
- Tran, T.K.; Nguyen, D.T. Semantic processing mechanism for listening and comprehension in VNSCalendar system. Int. J. Nat. Lang. Comput. (IJNLC) 2013, 2, 1–15. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Singh, J.; Joesph, M.H.; Jabbar, K.B.A. Rule-based chabot for student enquiries. J. Phys. Conf. Ser. 2019, 1228, 012060. [Google Scholar] [CrossRef]
- Rath, S.; Pattanayak, A.; Tripathy, S.; Priyadarshini, S.B.B.; Tripathy, A.; Tanvi, S. Prediction of a Novel Rule-Based Chatbot Approach (RCA) using Natural Language Processing Techniques. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 318–325. Available online: https://www.ijisae.org/index.php/IJISAE/article/view/3172 (accessed on 17 September 2023).
- Yamaguchi, H.; Mozgovoy, M.; Danielewicz-Betz, A. A Chatbot Based On AIML Rules Extracted From Twitter Dialogues. In Proceedings of the Communication Papers of the 2018 Federated Conference on Computer Science and Information Systems, PTI, Poznań, Poland, 9–12 September 2018; pp. 37–42. [Google Scholar] [CrossRef]
- Shuster, K.; Xu, J.; Komeili, M.; Ju, D.; Smith, E.M.; Roller, S.; Ung, M.; Chen, M.; Arora, K.; Lane, J.; et al. BlenderBot 3: A deployed conversational agent that continually learns to responsibly engage. arXiv 2022, arXiv:2208.03188v3. [Google Scholar]
- Slonim, N.; Bilu, Y.; Alzate, C.; Bar-Haim, R.; Bogin, B.; Bonin, F.; Choshen, L.; Cohen-Karlik, E.; Dankin, L.; Edelstein, L.; et al. An autonomous debating system. Nature 2021, 591, 379–384. [Google Scholar] [CrossRef] [PubMed]
- Solanki, R.K.; Rajawat, A.S.; Gadekar, A.R.; Patil, M.E. Building a Conversational Chatbot Using Machine Learning: Towards a More Intelligent Healthcare Application; IGI Global: Hershey, PA, USA, 2023; pp. 285–309. Available online: https://services.igi-global.com/resolvedoi/resolve.aspx?doi=10.4018/978-1-6684-7164-7.ch013 (accessed on 1 October 2023).
- Pandey, S.; Sharma, S.; Wazir, S. Mental healthcare chatbot based on natural language processing and deep learning approaches: Ted the therapist. Int. J. Inf. Technol. 2022, 14, 3757–3766. [Google Scholar] [CrossRef]
- Garcia-Mendez, S.; De Arriba-Perez, F.; Gonzalez-Castano, F.J.; Regueiro-Janeiro, J.A.; Gil-Castineira, F. Entertainment Chatbot for the Digital Inclusion of Elderly People without Abstraction Capabilities. IEEE Access 2021, 9, 75878–75891. [Google Scholar] [CrossRef]
- De Arriba-Pérez, F.; García-Méndez, S.; González-Castaño, F.J.; Costa-Montenegro, E. Automatic detection of cognitive impairment in elderly people using an entertainment chatbot with Natural Language Processing capabilities. J. Ambient Intell. Humaniz. Comput. 2022, 1, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Mageira, K.; Pittou, D.; Papasalouros, A.; Kotis, K.; Zangogianni, P.; Daradoumis, A. Educational AI Chatbots for Content and Language Integrated Learning. Appl. Sci. 2022, 12, 3239. [Google Scholar] [CrossRef]
- Lee, D.; Yeo, S. Developing an AI-based chatbot for practicing responsive teaching in mathematics. Comput. Educ. 2022, 191, 104646. [Google Scholar] [CrossRef]
- Görtz, M.; Baumgärtner, K.; Schmid, T.; Muschko, M.; Woessner, P.; Gerlach, A.; Byczkowski, M.; Sültmann, H.; Duensing, S.; Hohenfellner, M. An artificial intelligence-based chatbot for prostate cancer education: Design and patient evaluation study. Digit. Health 2023, 9, 20552076231173304. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Jensen, S.; Albert, L.J.; Gupta, S.; Lee, T. Artificial Intelligence (AI) Student Assistants in the Classroom: Designing Chatbots to Support Student Success. Inf. Syst. Front. 2023, 25, 161–182. [Google Scholar] [CrossRef]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6382–6388. [Google Scholar] [CrossRef]
- Khataei, M.H.; Gharehchopogh, F.S.; Majidzadeh, K.; Sangar, A.B. A New Hybrid Based on Long Short-Term Memory Network with Spotted Hyena Optimization Algorithm for Multi-Label Text Classification. Mathematics 2022, 10, 488. [Google Scholar] [CrossRef]
- Huan, H.; Guo, Z.; Cai, T.; He, Z. A text classification method based on a convolutional and bidirectional long short-term memory model. Connect. Sci. 2023, 34, 2108–2124. [Google Scholar] [CrossRef]
- Davis, F. Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| ID | Department | Topic | Example | Semantic Presentation |
|---|---|---|---|---|
| 1 | Công tác sinh viên(The Student Affairs Office) | Xác nhận sinh viên (Student confirmation letter) | Chào phòng Công tác sinh viên, em muốn làm giấy xác nhận sinh viên. (English: Hello Student Affairs Office, I would like to request a student confirmation letter.) | query (dept (ctsv), task (xacnhan)) |
| Kết quả rèn luyện(The training results) | Phòng Công tác sinh viên hướng dẫn em đánh giá kết quả rèn luyện với ạ? (English: Student Affairs Office, could you please guide me on how to evaluate my training results?) | query (dept (ctsv), task (renluyen)) | ||
| Thẻ sinh viên (Student ID card) | Phòng Công tác sinh viên cho em xin được cấp lại thẻ sinh viên ạ? (English: Student Affairs Office, could you please issue me a replacement student ID card?) | query (dept (ctsv), task (thesinhvien)) | ||
| Mùa hè xanh (“Green Summer Campaign”) | Phòng Công tác sinh viên cho em thông tin về chiến dịch mùa hè xanh năm nay ạ? (English: Student Affairs Office, could you please provide me with information about this year’s “Green Summer Campaign”?) | query (dept (ctsv), task (muahexanh)) | ||
| Hiến máu nhân đạo (Voluntary blood donation) | Phòng Công tác sinh viên cho em thông tin về hiến máu nhân đạo ạ? (English: Student Affairs Office, could you please provide me with information about voluntary blood donation?) | query (dept (ctsv), task (hienmau)) | ||
| Công tác xã hội (Social work) | Kính gửi Phòng Công tác sinh viên, em muốn tham gia công tác xã hội ạ. (English: Dear Student Affairs Office, I would like to participate in social work.) | query (dept (ctsv), task (hienmau)) | ||
| 2 | Đào tạo (The Department of Training) | Đăng ký môn học (Register for courses) | Phòng Đào tạo cho em hỏi cách đăng ký môn học ạ. (English: The Department of Training, could you please tell me how to register for courses?) | query (dept (daotao), task (dangkymonhoc)) |
| Thời khóa biểu (Class schedule) | Phòng Đào tạo cho em hỏi xem thời khóa biểu ở đâu ạ. (English: The Department of Education and Training, where can I check the class schedule, please?) | query (dept (daotao), task (thoikhoabieu)) | ||
| Lịch thi (Exam schedule) | Phòng Đào tạo cho em hỏi xem lịch thi ở đâu ạ. (English: The Department of Training, where can I find the exam schedule, please?) | query (dept (daotao), task (lichthi)) | ||
| Bảng điểm (Grade report) | Phòng Đào tạo cấp cho em bảng điểm ạ. (English: The Department of Training, could you please provide me with a grade report, please?) | query (dept (daotao), task (bangdiem)) | ||
| Bảo lưu (A leave of absence) | Em liên hệ với phòng Đào tạo để bảo lưu học kỳ này. (English: I contact the Department of Training to request a leave of absence for this semester.) | query (dept (daotao), task (baoluu)) | ||
| Chuyển ngành (A change in major) | Em liên hệ với phòng Đào tạo để muốn chuyển ngành. (English: I will contact the Department of Training to request a change in major.) | query (dept (daotao), task (chuyennganh)) | ||
| Tốt nghiệp (Graduation) | Xin phòng Đào tạo cho em giấy chứng nhận tốt nghiệp tạm thời ạ. (English: Please provide me with a temporary graduation certificate, thank you.) | query (dept (daotao), task (totnghiep)) | ||
| 3 | Tài vụ(The Finance Office) | Đóng học phí (Tuition fee) | Phòng Tài vụ cho em hỏi học phí học kỳ này là bao nhiêu tiền ạ. (English: The Finance Office, may I ask how much the tuition fee is for this semester, please?) | query (dept (taivu), task (tienhocphi)) |
| Học phí trễ, gia hạn học phí (tuition fee payments) | Phòng Tài vụ còn nhận đóng học phí không ạ. (English: The Finance Office, are you still accepting tuition fee payments?) | query (dept (taivu), task (hocphitre)) | ||
| 4 | Khoa chuyên môn (Faculty) | Đăng ký phúc khảo (Reevaluation) | Xin cho em thủ tục làm đơn phúc khảo môn Mạng máy tính. (English: Please provide me with the procedures for requesting a reevaluation of the Computer Networking subject.) | query (dept (khoa), task (phuckhao)) |
| Xin giấy giới thiệu (letter of introduction) | Em muốn làm giấy giới thiệu của trường để đi thực tập ạ. (English: I would like to request a letter of introduction from the school for my internship, please.) | query (dept (khoa), task (giaygioithieu)) | ||
| 5 | Tuyển sinh (Admission) | Chỉ tiêu tuyển sinh (admission quota) | Xin cho em biết chỉ tiêu tuyển sinh năm nay là bao nhiêu? (English: Could you please inform me of this year’s admission quota?) | query (dept (tuyensinh), task (chitieu)) |
| Ngành học (Major) | Trường tuyển sinh những ngành nào? (English: What majors is the school admitting students into?) | query (dept (tuyensinh), task (nganh)) | ||
| Điểm chuẩn (Cutoff score) | Điểm chuẩn của trường là bao nhiêu? (English: What is the school’s admission cutoff score?) | query (dept (tuyensinh), task (diemchuan)) | ||
| Phương thức xét tuyển (Admission methods) | Trường có những phương thức xét tuyển nào? (English: What admission methods does the school offer?) | query (dept (tuyensinh), task (phuongthucxettuyen)) | ||
| Khối thi (Subject groups) | Trường có những khối thi nào? (English: What subject groups does the school have for the entrance exam?) | query (dept (tuyensinh), task (khoi)) | ||
| 6 | Chung (Others) | Xin thư giới thiệu (letter of recommendation) | Em muốn xin thư giới thiệu thì liên hệ đâu ạ? (English: If you want to request a letter of recommendation, where should you contact, please?) | query (contact (thugioithieu)) |
| Cấp lại thẻ sinh viên (Student ID card) | Em muốn cấp lại thẻ sinh viên thì liên hệ phòng nào ạ? (English: If I want to request a replacement student ID card, which department should I contact?) | query (contact (thesinhvien)) | ||
| Miễn giảm học phí (Tuition fee exemption) | Em cần làm đơn miễn giảm học phí thì liên hệ với ai? (English: To apply for a tuition fee exemption or reduction, who should I contact?) | query (contact (mienhocphi)) |
| Text Messages | Results |
|---|---|
| Em muốn làm giấy xác nhận sinh viên. (English: Hello, I would like to request a student confirmation letter.) | query (dept (ctsv), task (xacnhan)) |
| Xin cho em hỏi mình xem thời khóa biểu ở đâu ạ? (English: Could you please tell me where can I check the class schedule?) | query (dept (daotao), task (thoikhoabieu)) |
| Chỉ tiêu tuyển sinh năm nay là bao nhiêu sinh viên? (English: How many students is the admission target for this year?) | query (dept (tuyensinh), task (chitieu)) |
| Xin chào Phòng Đào tạo, em muốn được cấp bảng điểm. (English: Hello Academic Affairs Office, I would like to request my exam score transcript.) | query (dept (daotao), task (bangdiem)) |
| ID | Methods | Accuracy |
|---|---|---|
| 1 | K Nearest Neighbors (KNN) | 0.8692 |
| 2 | Support vector machines (SVM) | 0.9692 |
| 3 | Decision Tree (DT) | 0.9308 |
| 4 | Improved Random Forest (IRF) | 0.9769 |
| 5 | Neural Net (ANN) | 0.9538 |
| 6 | Naive Bayes (NB) | 0.9538 |
| 7 | LSTM [22] | 0.9688 |
| 8 | BiLSTM [23] | 0.9698 |
| Very Convenient | Quite Convenient | Somewhat Convenient | Not Convenient |
|---|---|---|---|
| 40% | 45% | 10% | 5% |
| Very useful | Quite useful | Somewhat useful | Not useful |
| 42.5% | 47.5% | 5% | 5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dinh, H.; Tran, T.K. EduChat: An AI-Based Chatbot for University-Related Information Using a Hybrid Approach. Appl. Sci. 2023, 13, 12446. https://doi.org/10.3390/app132212446
Dinh H, Tran TK. EduChat: An AI-Based Chatbot for University-Related Information Using a Hybrid Approach. Applied Sciences. 2023; 13(22):12446. https://doi.org/10.3390/app132212446
Chicago/Turabian StyleDinh, Hoa, and Thien Khai Tran. 2023. "EduChat: An AI-Based Chatbot for University-Related Information Using a Hybrid Approach" Applied Sciences 13, no. 22: 12446. https://doi.org/10.3390/app132212446
APA StyleDinh, H., & Tran, T. K. (2023). EduChat: An AI-Based Chatbot for University-Related Information Using a Hybrid Approach. Applied Sciences, 13(22), 12446. https://doi.org/10.3390/app132212446