The specific implementation details for registration and authentication are as follows. The framework of the identity registration model based on the blockchain is shown in
Figure 6. The client filters the optimal combination
. The fuzzy extractor receives the biometric vector
and generates the user’s random key
and public information
using a random character generation algorithm. It returns the random key
to the APP client. In the identity chain, each service provider acts as a node. The client inputs the hash-processed user biological key
and document information to the service node that has write access. Then, the service node writes the user’s random key
to the IPFS, which returns the hash address of the file upon successful deposit. The service node stores the user ID, hash of document information, and hash address in the blockchain. The service and public key will be returned to the client if the message is successfully uploaded.
When the user requests the service again, the authentication operation needs to be completed. The framework of the multistage authentication model based on blockchain technology is shown in
Figure 7. The client packages the data firstly and sends the data to the server provider. In the first stage of authentication, the system retrieves the user’s information in the blockchain based on the user’s name. The strategy compares the user’s document information and returns the hash address of the file if it matches. Successful authentication in the first stage indicates that the user’s document information is verified. In the second stage of authentication, the user’s random key
is searched in the IPFS based on the preoutput of the first stage. This step compares whether the random key in the IPFS is consistent with the key generated at the time of input. If it is identical, it means the user’s biometric information is authenticated successfully in the second stage.
4.2.1. Gait Key Extraction Scheme
The authentication process based on gait characteristics is shown in
Figure 8. The black lines in the figure indicate the overall flow of the authentication model. Firstly, the gait data are collected through the built-in accelerometer and gyroscope sensors of the smart devices. The gait data acquisition program is written by instruction code that can run in the background of devices. The data are recorded in real time when relevant activities are detected. The acquired data need to be preprocessed, including the removal of outliers, noise filtering, and gait cycle segmentation. Afterward, the processed gait feature data are extracted to generate a user’s gait feature template. The feature template is stored in the database, and the authentication result can be judged according to the consistency of the template in the authentication stage.
In this paper, body activity data were collected using a smartphone equipped with the Android operating system. The smartphone device has a triaxial accelerometer and a triaxial gyroscope. The acceleration sensor returns the three-axis acceleration applied to the device by the user, and it is measured in m/s. The gyroscope measures the rotation rate of the device, i.e., the rate of rotation of the device around each axis. It is measured in rad/s.
- (1)
Gait data collection
The dataset used in this paper was collected by a self-developed Android program. The data folder is automatically uploaded to the cloud after being collected. The dataset consists of 21 users. Each person collects 10 sample files. Each file contains the X axis, Y axis, and Z axis gait data of the accelerometer and gyroscope sensors.
Table 3 shows the 3D acceleration and gyroscope data for one user. Notably, the gait signals collected by the proposed authentication scheme will not violate the privacy of the user. Our system will display a prompt message before the actual collection of gait information, and it will proceed to the next step only after obtaining the user’s consent.
We can simulate three-dimensional data from an experimenter’s walking acceleration sensor and gyroscope sensor.
Figure 9 is the waveform obtained for the X axis of the accelerometer. However, due to multiple factors such as different acquisition performance outcomes of the built-in sensors and unconscious jitter from the user’s grip on the phone, the acquired signal is subject to noise fluctuations. There will be a large amount of anomalous data in the initial phase of the data collection. Therefore, we needed to preprocess the data.
- (2)
Data Preprocessing Processes
- A.
Signal denoising
The noise generated by built-in sensors is high-frequency random noise, while the gait signal belongs to a low communication signal. Walking frequency is usually below 20 Hz, and most of the energy of the signal is mainly concentrated in the frequency range of 1–5 Hz. Therefore, a Butterworth filter with maximum flatness was chosen in this paper to allow the low-frequency signal in the signal to pass through, while filtering or suppressing the high-frequency signal, thus retaining the appropriate step signal. The principle is as follows: the amplitude frequency mode-squared characteristic
of a Butterworth low-pass filter is given in Equation (2).
where
N is the order of the filter, and
is the cut-off frequency of the low-pass filter. In this paper, the cut-off frequency of the 3rd-order Butterworth filter was set to 5 Hz.
Figure 10 shows a comparison of the waveforms before and after denoising.
- B.
Signal segmentation
The gait signal in the human body is periodic. The segmentation of the gait signal into sequence units facilitates the extraction of information about human gait characteristics. A gait cycle is defined as the time interval between two adjacent touches of the same foot to the ground. Using the gait cycle as a segmentation unit is a more feasible approach than dividing the gait signal based on a fixed length. It is also known that the acceleration signal reaches its maximum value when one foot touches the ground. Therefore, this paper used the maximum signal from the accelerometer as the starting point of the gait cycle.
The gait signals selected for this paper are an array of six channels, including the X, Y, and Z axis signals from the accelerometer and gyroscope sensors. As the experimenter holds the smart device in his hand and swings his arm naturally during data acquisition, his Z axis direction coincides with the direction of the user’s acceleration. And the Z axis direction is most sensitive to the perception of gait data. Therefore, the Z axis signal from the accelerometer sensor was used to complete the gait cycle detection in this paper.
As shown in
Figure 11 below, this paper used a sliding window segmentation technique. The length of the human gait cycle sequence is in the range of 120–140, and there are slight differences between the individual gait signals collected in this paper. In order to ensure that the sliding time window contained the entire gait cycle, this paper used a sliding window of 150 in length to segment the collected gait data into a period. The cycles are indicated by red frames in the gait signal.
- (3)
Feature point extraction
As the raw data from both the accelerometer and gyroscope sensors are high-dimensional, we needed to perform an effective feature extraction process for the data in this paper. In this paper, we extracted features from high-dimensional time series in the time domain. Common time domain features include maximum, minimum, mean, variance, and peak-to-peak. These time domain features all possess magnitudes and are therefore referred to as dimensioned eigenvalues. In addition, dimensionless features such as skewness, peak factor, and cliff factor can also be used. Appropriate feature selection not only improves the accuracy of authentication, but also increases the efficiency of identification and speeds up the process of identification and authentication. Therefore, in this paper, the five features of mean, kurtosis, standard deviation, peak factor, and skewness were finally selected as the basis for authentication. The sample format of the gait data feature extraction is shown in
Figure 12, and the 30-dimensional data features will be used in the subsequent authentication.
- (4)
Gait secret key
According to the fuzzy extractor and behavioral feature extraction scheme introduced above, the key extraction process based on the gait is shown in
Figure 13. In the registration phase, the user performs gait data collection and feature extraction. Then, we input the extracted features
into the fuzzy extractor and generate a random key
R and a public string
P according to the Gen algorithm. The random key
R is hashed and stored in the IPFS as the gait key, while the public information
P is stored on the chain. When the user is authenticated, the user’s gait characteristics
are collected again, and
P is extracted from the blockchain. If the biometric error of the two inputs is satisfied within a given range, i.e.,
, then the random key
can be recovered from
and
P. We hash the random key
and extract the original hash (R) stored in the IPFS. If
is satisfied, then the biometric verification is successful.
4.2.2. IdentiChain
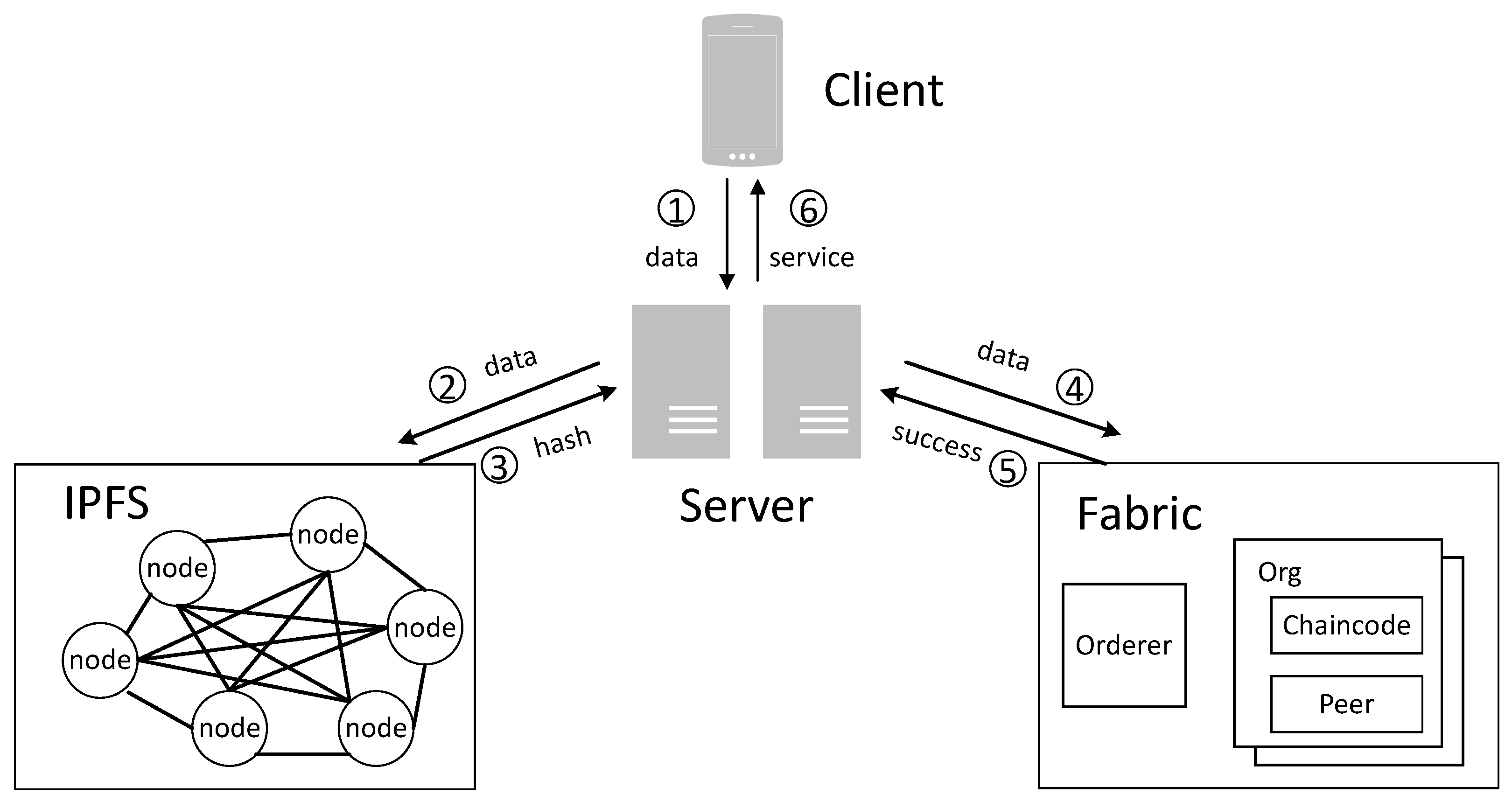
The types of blockchain are divided into public blockchain, consortium blockchain, and private blockchain. In the public blockchain represented by Bitcoin, all nodes can be accessed at any time to read data, download the complete blockchain ledger, and send confirmed transactions. Users can compete for mining rewards by engaging in mining, which essentially involves solving puzzles by expending arithmetic power to compete for bookkeeping rights. As a result, users are rewarded with virtual tokens by the system. Although this consensus model ensures maximum decentralization, it is not only wasteful, but also inefficient. It is obviously not suitable for the immediate response needed in this paper. Moreover, there is no need to use virtual tokens in this system, so it is not possible to reward miners with tokens for mining. Fabric functions as a federated blockchain, thereby providing access to nodes through a public key infrastructure (PKI), which allows authorized nodes to participate in the federated chain network. Members participating in the blockchain network need to have previously registered with the blockchain to obtain a registration certificate that can be generated based on the type of entity. Fabric identifies users by issuing digital certificates, each of which corresponds to its membership service provider number on a one-to-one basis. In addition, Fabric uses a gRPC-based gossip protocol to ensure consistent messaging between nodes. The gossip protocol involves a randomly selected node that broadcasts messages and thus can improve network load performance and reduce the likelihood of malicious attacks. The greatest strength of Hyperledger Fabric is its pluggable modules such as consensus mechanisms, rights management, and ledger mechanisms. It is designed to optimize privacy and performance through privileged access, thus enabling enterprises to limit the mobility and visibility of information to legitimate users.
In Fabric blockchain networks, nodes are the main communication bodies. Multiple nodes of different types can be deployed on different servers to form a blockchain network, or they can run on the same physical server by using docker containers. In Hyperledger Fabric, there are different types of nodes: client nodes, peer nodes, orderer nodes, and CA nodes. The Fabric network architecture used in this paper is shown in
Figure 14.
Smart contracts in the Hyperledger Fabric are called chain codes, and their main function is to execute transactions and provide access to data on the chain. The chain code is the only way to interact with the blockchain storage, and all business logic implementation needs to be done through the chain code. During the development of the chain code, the init initialization function and the invoke call function of the chain code interface need to be implemented first. The init function is used to initialize the chain code parameters. The invoke function usually contains several functions, such as a query function for the data on the chain and a function to modify the data on the chain. In order to reduce development costs and ease of use, this article has been written in Node.js for chain code and developed using the VS Code editor.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}