
Prediction of Particulate Matter 2.5 Concentration Using a Deep Learning Model with Time-Frequency Domain Information


Abstract
:1. Introduction
- (1)
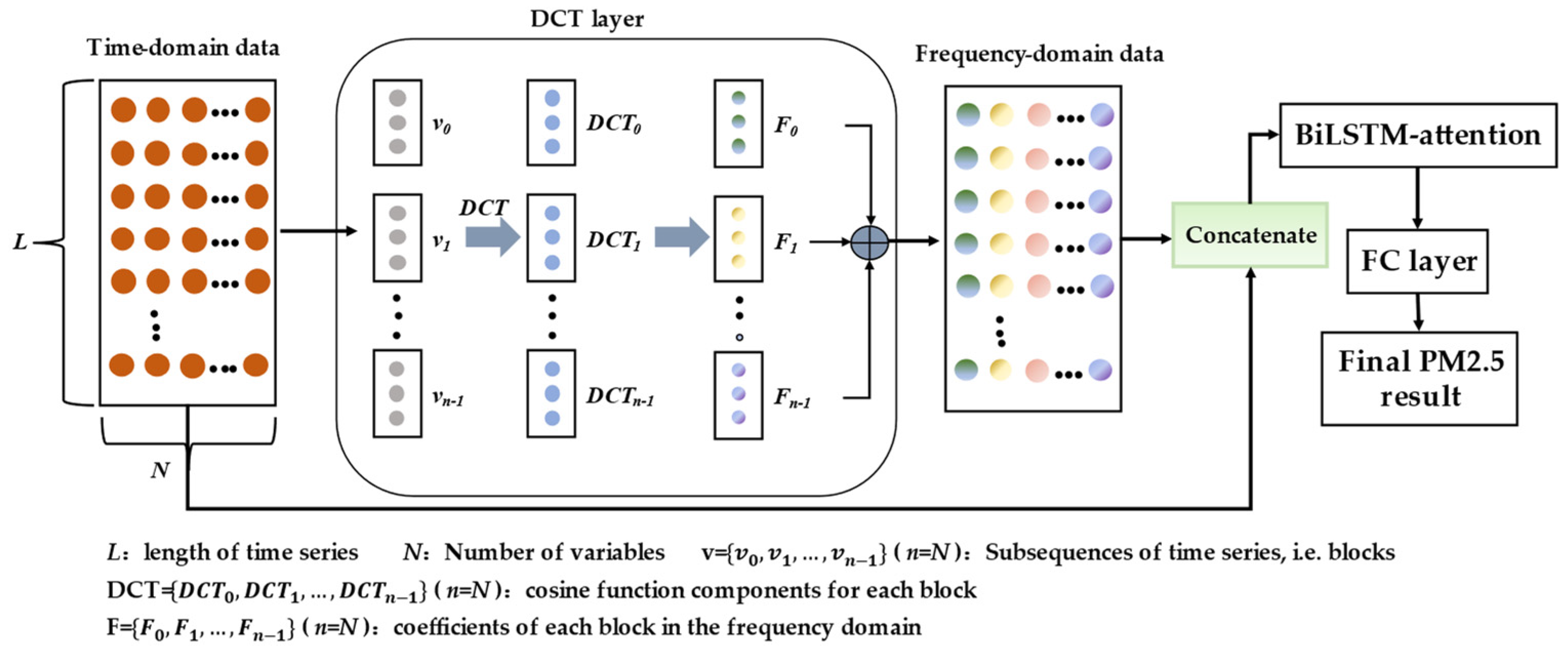
- First, it uses DCT to transform the input data from the time domain to the frequency domain. Next, the amalgamation of the time domain dataset with the frequency domain dataset is executed to generate an integrated dataset. This unified dataset is designated as the model’s input, enabling optimal utilization of frequency information while encompassing essential time domain information.
- (2)
- Adding the attention mechanism after the BiLSTM layer can improve the role of important time steps in BiLSTM, which can in turn improve the prediction effect of the model. Finally, using time frequency domain information, BiLSTM, and attention, it develops the TF-BILSTM-attention model to predict PM2.5 concentration.
- (3)
- For the multivariate model, the input variables consist solely of the PM2.5 concentration at the site itself and at the remaining 11 sites within the study area, without considering the effects of other pollutant factors and meteorological factors. Empirical findings demonstrate that the multivariate model with these variables added has a good prediction effect.
2. Materials and Methods
2.1. Study Area and Materials
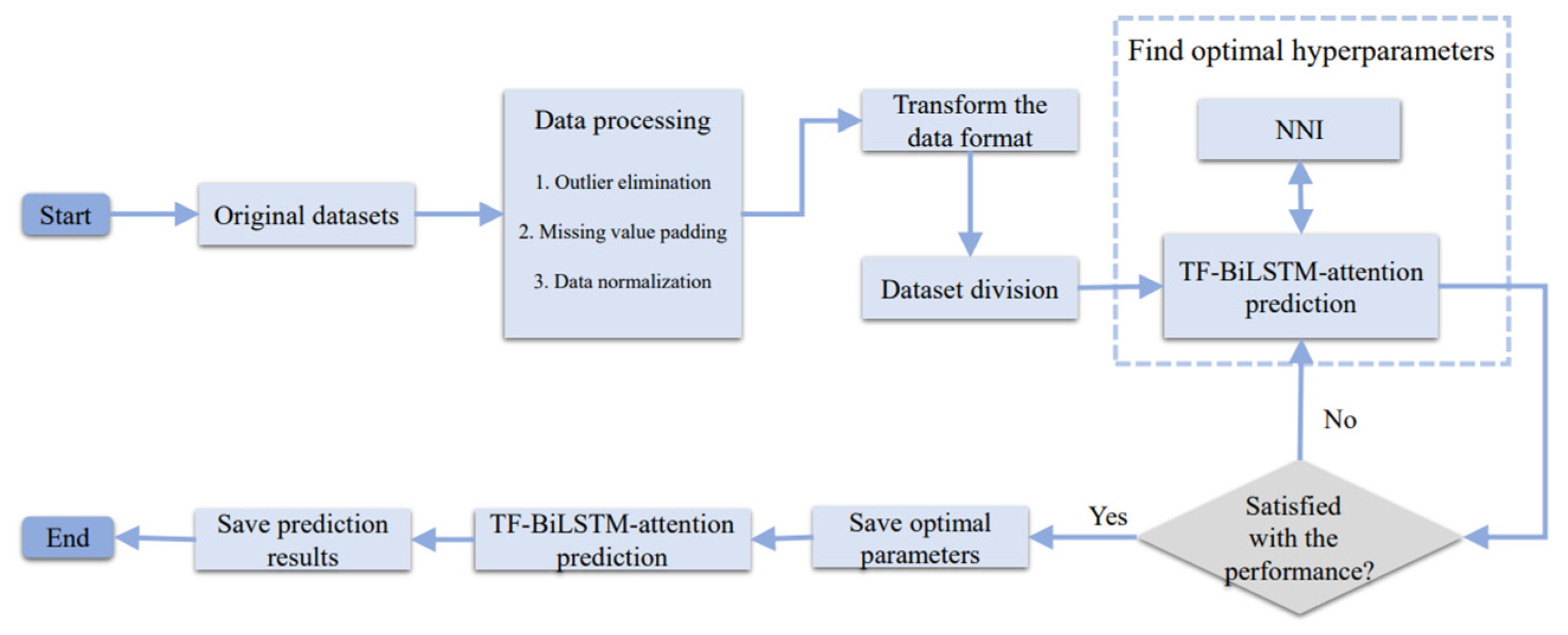
2.2. Methodology Framework
2.2.1. Discrete Cosine Transform
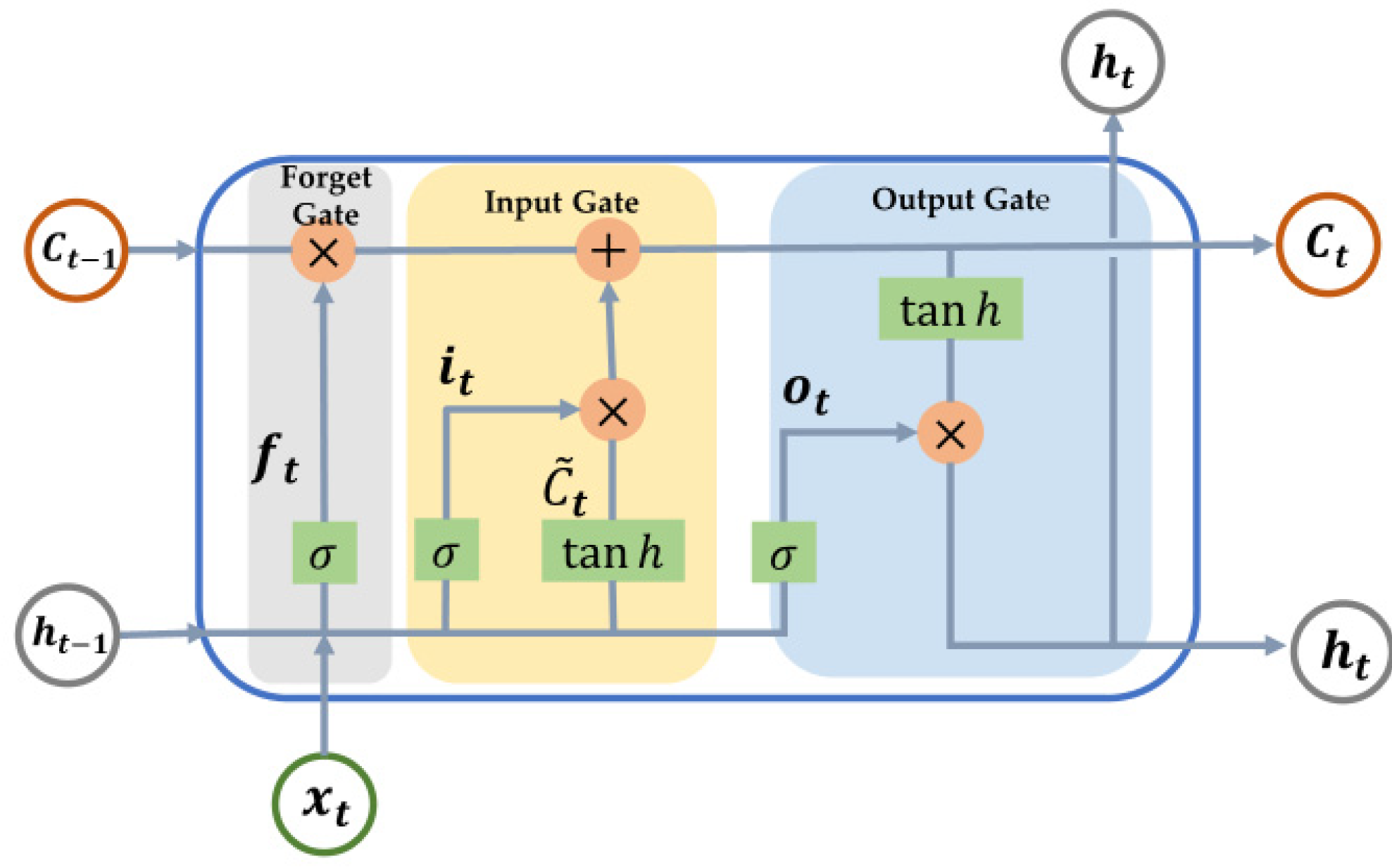
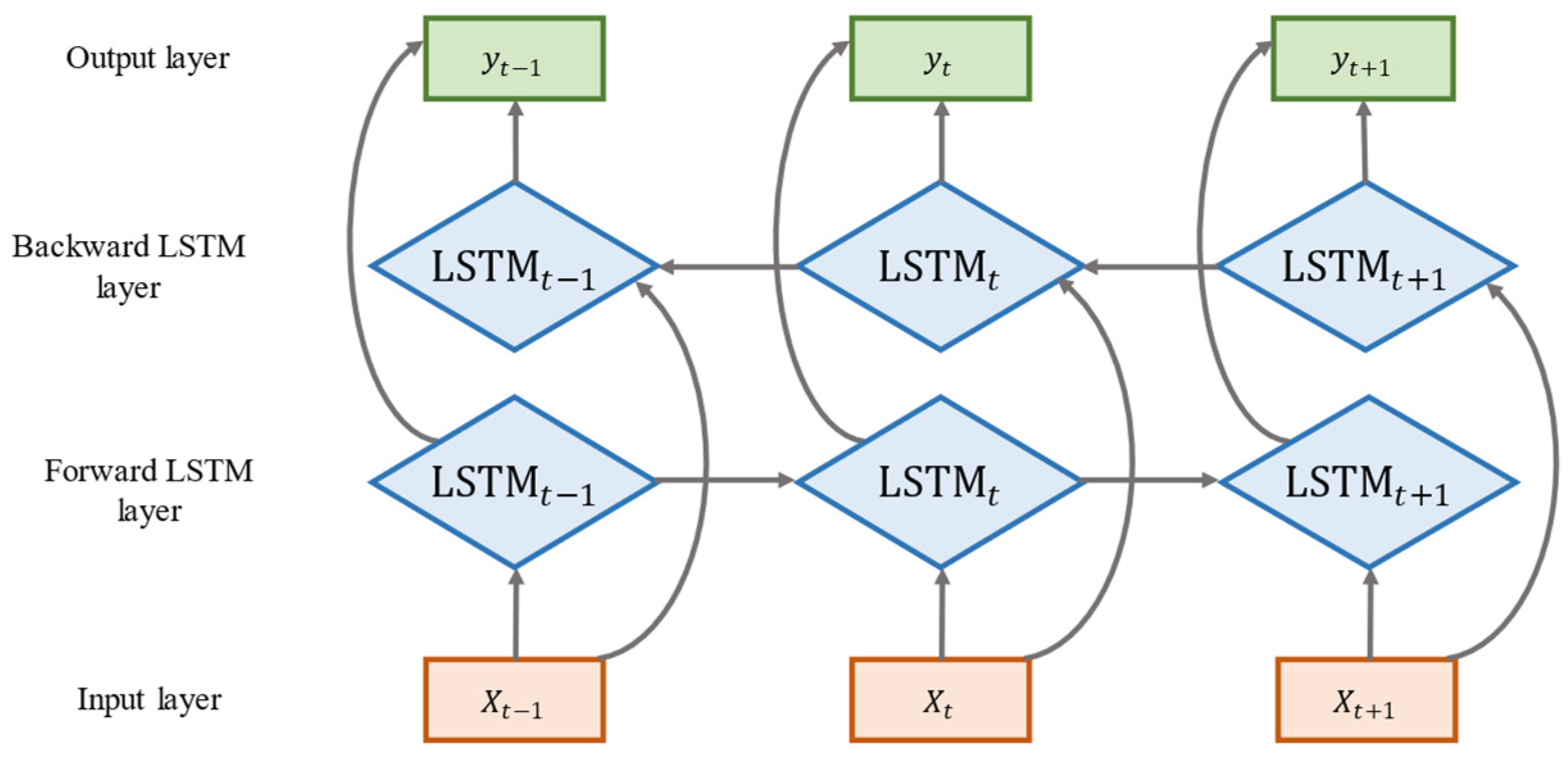
2.2.2. Bidirectional Long Short-Term Memory Neural Network
Long Short-Term Memory Neural Network
Bidirectional Long Short-Term Memory Neural Network
2.2.3. Attention Mechanism
2.2.4. The TF-BiLSTM-Attention Model
2.2.5. Network Architecture and Hyperparameter Setting
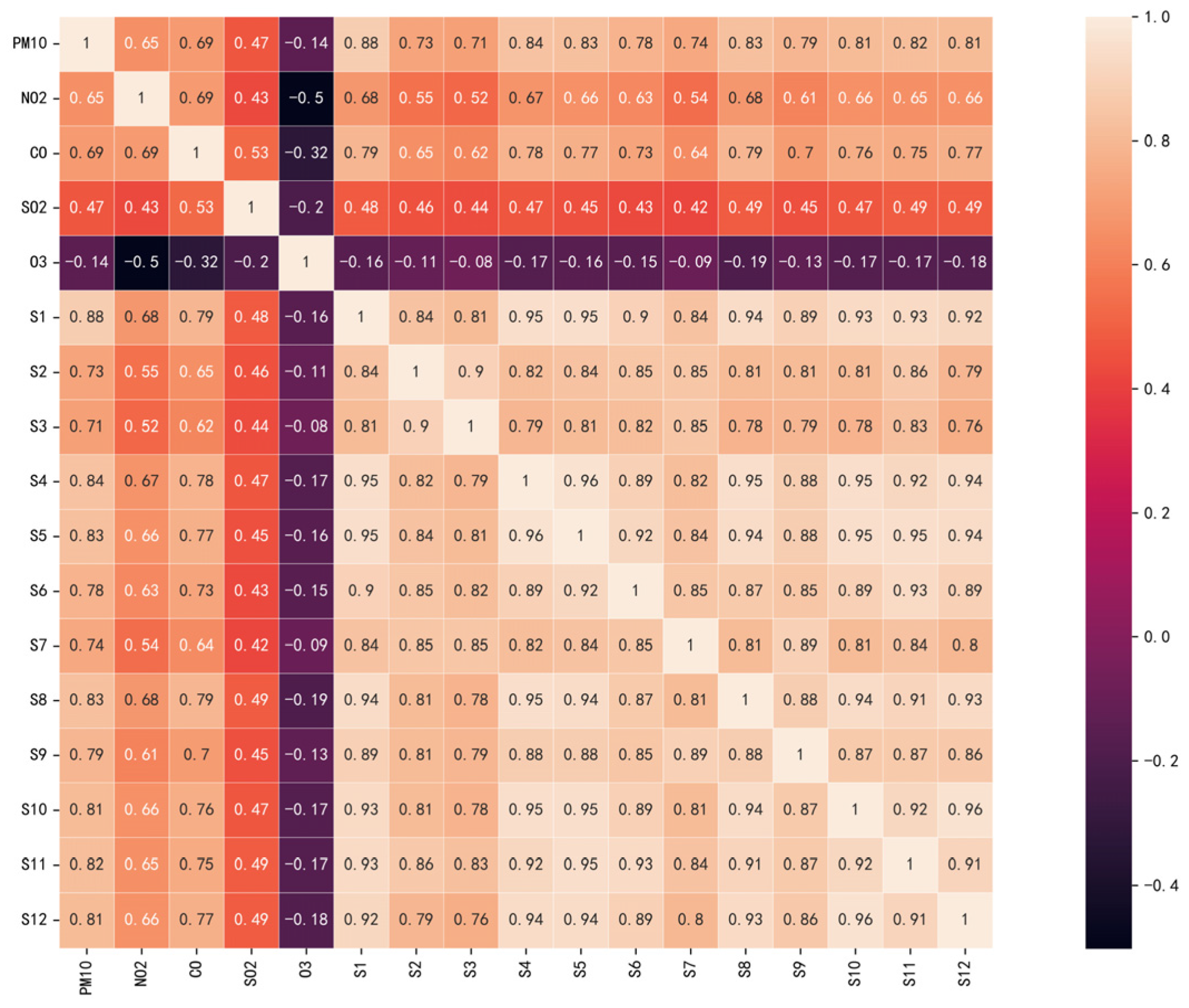
2.3. Feature Selection
2.4. Evaluation of Prediction Results
3. Results
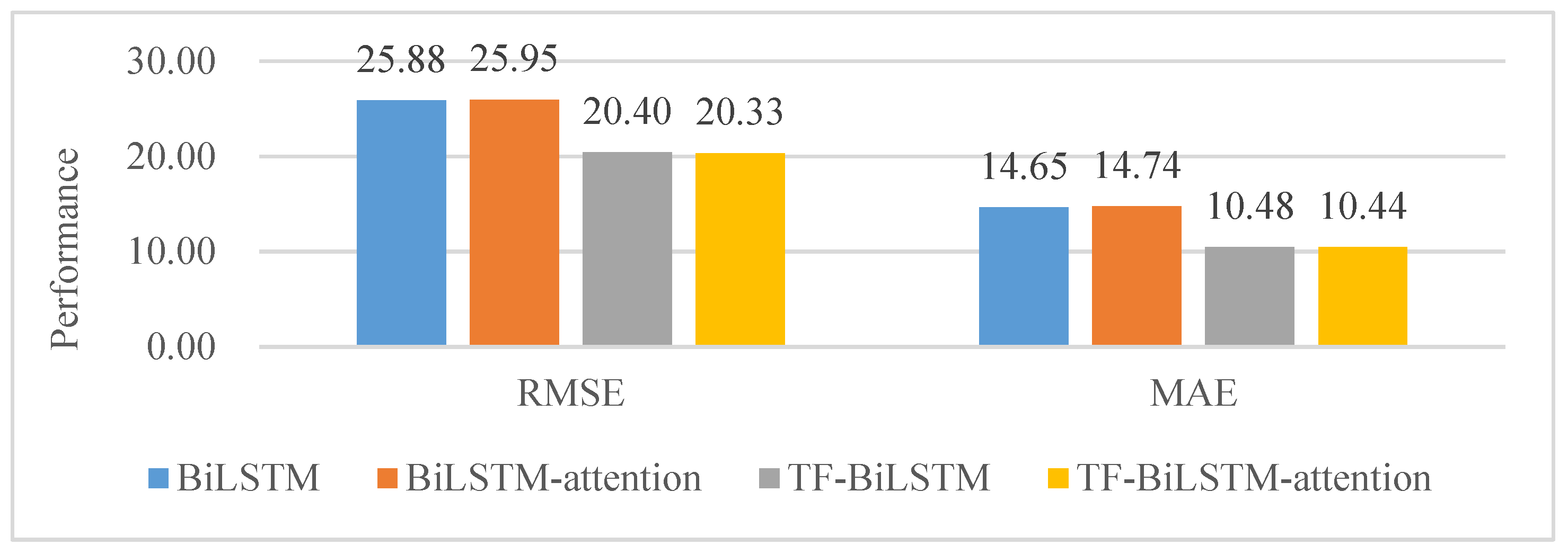
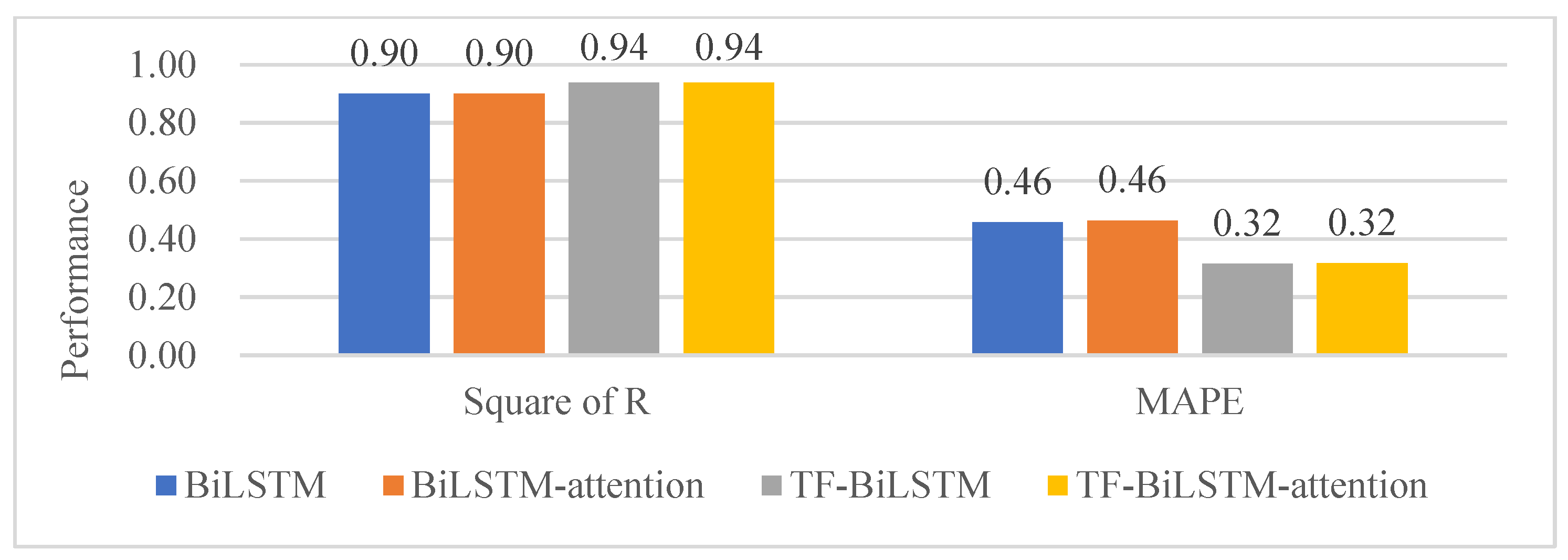
3.1. Comparison with Different Univariate Models
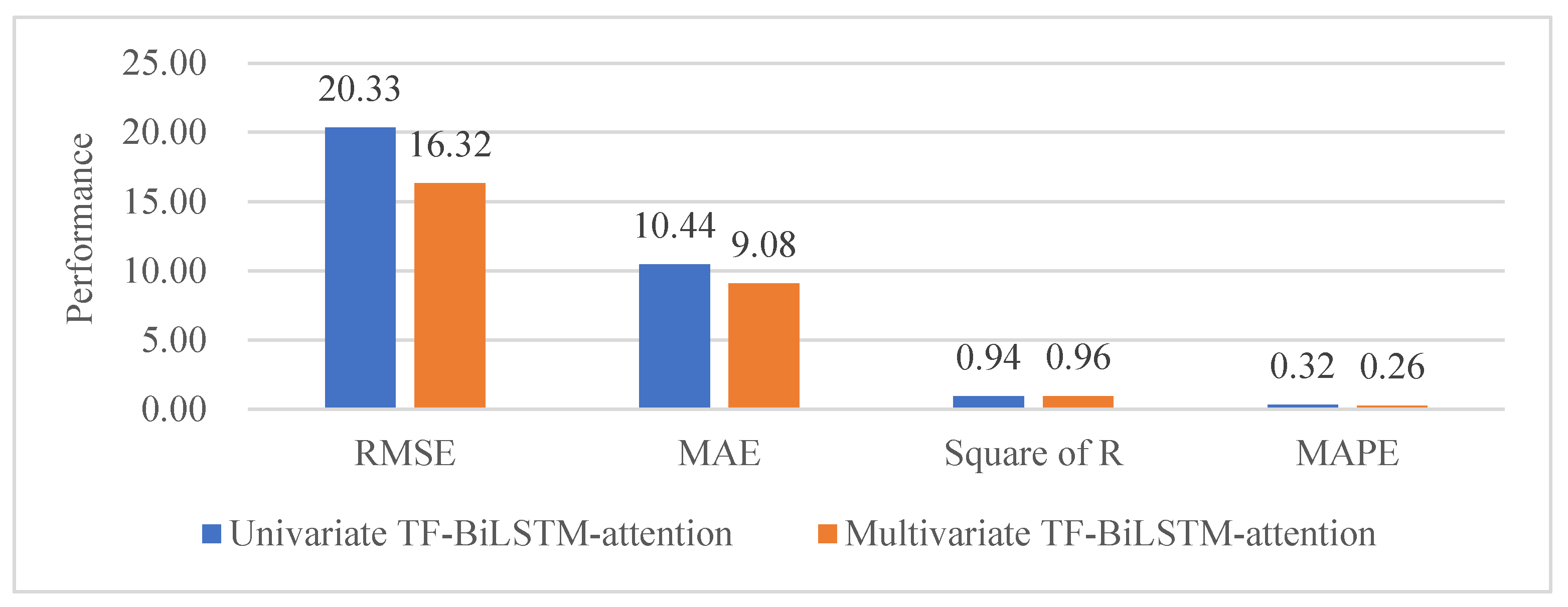
3.2. Comparison with Different Multivariate Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fan, H.; Zhao, C.; Yang, Y. A comprehensive analysis of the spatio-temporal variation of urban air pollution in China during 2014–2018. Atmos. Environ. 2020, 220, 117066. [Google Scholar] [CrossRef]
- Lin, Y.C.; Lee, S.J.; Ouyang, C.S.; Wu, C.H. Air quality prediction by neuro-fuzzy modeling approach. Appl. Soft Comput. 2020, 86, 105898. [Google Scholar] [CrossRef]
- Gu, K.; Zhou, Y.; Sun, H.; Zhao, L.; Liu, S. Prediction of air quality in Shenzhen based on neural network algorithm. Neural Comput. Appl. 2020, 32, 1879–1892. [Google Scholar] [CrossRef]
- Mengfan, T.; Siwei, L.; Lechao, D.; Senlin, H. Including the feature of appropriate adjacent sites improves the PM2.5 concentration prediction with long short-term memory neural network model. Sustain. Cities Soc. 2022, 76, 103427. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef] [PubMed]
- Chang-Hoi, H.; Park, I.; Oh, H.R.; Gim, H.J.; Hur, S.K.; Kim, J.; Choi, D.R. Development of a PM2.5 prediction model using a recurrent neural network algorithm for the Seoul metropolitan area, Republic of Korea. Atmos. Environ. 2021, 245, 118021. [Google Scholar] [CrossRef]
- Jiang, P.; Dong, Q.; Li, P. A novel hybrid strategy for PM2.5 concentration analysis and prediction. J. Environ. Manag. 2017, 196, 443–457. [Google Scholar] [CrossRef]
- Hua, Y.; Zhao, Z.; Li, R.; Chen, X.; Liu, Z.; Zhang, H. Deep learning with long short-term memory for time series prediction. IEEE Commun. Mag. 2019, 57, 114–119. [Google Scholar] [CrossRef]
- Prihatno, A.T.; Nurcahyanto, H.; Ahmed, M.F.; Rahman, M.H.; Alam, M.M.; Jang, Y.M. Forecasting PM2.5 concentration using a single-dense layer BiLSTM method. Electronics 2021, 10, 1808. [Google Scholar] [CrossRef]
- Li, T.; Hua, M.; Wu, X.U. A hybrid CNN-LSTM model for forecasting particulate matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, H.; Hua, L.; Sun, W.; Nazir, M.S.; Peng, T. An evolutionary deep learning model based on TVFEMD, improved sine cosine algorithm, CNN and BiLSTM for wind speed prediction. Energy 2022, 254, 124250. [Google Scholar] [CrossRef]
- Zhu, M.; Xie, J. Investigation of nearby monitoring station for hourly PM2.5 forecasting using parallel multi-input 1D-CNN-biLSTM. Expert Syst. Appl. 2023, 211, 118707. [Google Scholar] [CrossRef]
- Jiang, M.; Zeng, P.; Wang, K.; Liu, H.; Chen, W.; Liu, H. FECAM: Frequency enhanced channel attention mechanism for time series forecasting. Adv. Eng. Inform. 2023, 58, 102158. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, S.; Yang, J.; Jing, H.; Zhao, W.; Yang, G. A Joint Time-frequency Domain Transformer for Multivariate Time Series Forecasting. arXiv 2023, arXiv:2305.14649. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, T.; Zhao, H.; Wang, Z. Updated Prediction of Air Quality Based on Kalman-Attention-LSTM Network. Sustainability 2022, 15, 356. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Wang, X.; Wang, T.; Sun, Q. An quality prediction model based on CNN-BiNLSTM-attention. Environ. Dev. Sustain. 2022, 12, 1–16. [Google Scholar] [CrossRef]
- Zhang, S.; Guo, B.; Dong, A.; He, J.; Xu, Z.; Chen, S.X. Cautionary tales on air-quality improvement in Beijing. Proc. R. Soc. A 2017, 473, 20170457. [Google Scholar] [CrossRef]
- Chen, X.; Sun, L. Bayesian temporal factorization for multidimensional time series prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4659–4673. [Google Scholar] [CrossRef]
- Alsaber, A.R.; Pan, J.; Al-Hurban, A. Handling complex missing data using random forest approach for an air quality monitoring dataset: A case study of Kuwait environmental data (2012 to 2018). Int. J. Environ. Res. Public Health 2021, 18, 1333. [Google Scholar] [CrossRef]
- Li, W.; Ding, P.; Xia, W.; Chen, S.; Yu, F.; Duan, C.; Cui, D.; Chen, C. Artificial neural network reconstructs core power distribution. Nucl. Eng. Technol. 2022, 54, 617–626. [Google Scholar] [CrossRef]
- Bi, X.; Zhang, C.; He, Y.; Zhao, X.; Sun, Y.; Ma, Y. Explainable time–frequency convolutional neural network for microseismic waveform classification. Inf. Sci. 2021, 546, 883–896. [Google Scholar] [CrossRef]
- Akilandeswari, P.; Manoranjitham, T.; Kalaivani, J.; Nagarajan, G. Air quality prediction for sustainable development using LSTM with weighted distance grey wolf optimizer. Soft Comput. 2023, 1–10. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Huang, G.; Li, X.; Zhang, B.; Ren, J. PM2.5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition. Sci. Total Environ. 2021, 768, 144516. [Google Scholar] [CrossRef]
- Wardana, I.N.K.; Gardner, J.W.; Fahmy, S.A. Optimising deep learning at the edge for accurate hourly air quality prediction. Sensors 2021, 21, 1064. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Search Space |
|---|---|
| optimizer | {Adam, SGD} |
| hidden_size of BiLSTM | {1, 2,…, 15} |
| sequence length | {1, 2,…, 20} |
| epochs | {5, 10, 15, 20,…, 40} |
| batch size | {16, 32, 64, 128} |
| learning rate | {0.1, 0.001, 0.0001} |
| S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9 | S10 | S11 | S12 | Mean | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | BiLSTM | 25.7021 | 23.8906 | 21.1004 | 28.3287 | 26.4759 | 28.4701 | 22.4960 | 27.7977 | 27.5000 | 25.0629 | 25.2665 | 28.4127 | 25.8753 |
| BiLSTM-attention | 25.7708 | 24.0441 | 21.4432 | 28.3129 | 26.4545 | 28.3707 | 22.5573 | 27.8118 | 27.6883 | 25.0518 | 25.2951 | 28.6464 | 25.9539 | |
| TF-BiLSTM | 19.1547 | 19.7329 | 17.8799 | 21.8664 | 20.4544 | 21.4437 | 18.8393 | 22.0770 | 20.6508 | 18.9912 | 19.8951 | 23.8156 | 20.4001 | |
| TF-BiLSTM-attention | 19.0154 | 19.9404 | 17.8012 | 21.6904 | 20.4426 | 21.4567 | 18.7613 | 21.9312 | 20.4372 | 18.9155 | 19.8894 | 23.7143 | 20.3330 | |
| MAE | BiLSTM | 14.9132 | 13.5171 | 11.7857 | 16.2541 | 15.4316 | 15.8921 | 11.7416 | 15.8277 | 15.4688 | 14.7648 | 14.2116 | 15.9601 | 14.6474 |
| BiLSTM-attention | 14.9621 | 13.5376 | 11.9318 | 16.3292 | 15.4384 | 15.8559 | 11.8141 | 15.9874 | 15.7161 | 14.8636 | 14.2167 | 16.1878 | 14.7367 | |
| TF-BiLSTM | 10.3375 | 10.3115 | 9.3581 | 11.1289 | 11.0317 | 10.7332 | 8.7072 | 11.1015 | 10.5434 | 10.6783 | 10.0862 | 11.7263 | 10.4787 | |
| TF-BiLSTM-attention | 10.2423 | 10.3312 | 9.3309 | 10.9785 | 11.0520 | 10.7917 | 8.6934 | 10.9732 | 10.4370 | 10.6395 | 10.1646 | 11.6934 | 10.4440 | |
| R2 | BiLSTM | 0.9052 | 0.8916 | 0.8966 | 0.9035 | 0.9075 | 0.8988 | 0.8930 | 0.9004 | 0.8869 | 0.9115 | 0.9041 | 0.9048 | 0.9003 |
| BiLSTM-attention | 0.9047 | 0.8902 | 0.8933 | 0.9036 | 0.9077 | 0.8996 | 0.8924 | 0.9003 | 0.8854 | 0.9116 | 0.9039 | 0.9032 | 0.8996 | |
| TF-BiLSTM | 0.9473 | 0.9261 | 0.9258 | 0.9425 | 0.9448 | 0.9426 | 0.9249 | 0.9372 | 0.9362 | 0.9492 | 0.9405 | 0.9331 | 0.9375 | |
| TF-BiLSTM-attention | 0.9481 | 0.9245 | 0.9264 | 0.9434 | 0.9449 | 0.9425 | 0.9256 | 0.9380 | 0.9376 | 0.9496 | 0.9406 | 0.9337 | 0.9379 | |
| MAPE | BiLSTM | 0.4400 | 0.4512 | 0.5211 | 0.4775 | 0.4393 | 0.4192 | 0.4630 | 0.4646 | 0.4818 | 0.4321 | 0.4454 | 0.4549 | 0.4575 |
| BiLSTM-attention | 0.4463 | 0.4429 | 0.5183 | 0.4830 | 0.4425 | 0.4209 | 0.4659 | 0.4795 | 0.5054 | 0.4481 | 0.4375 | 0.4688 | 0.4632 | |
| TF-BiLSTM | 0.2899 | 0.3227 | 0.4234 | 0.3270 | 0.2868 | 0.2482 | 0.3479 | 0.3039 | 0.3057 | 0.3124 | 0.2937 | 0.3283 | 0.3158 | |
| TF-BiLSTM-attention | 0.2850 | 0.3289 | 0.4278 | 0.3240 | 0.2876 | 0.2510 | 0.3465 | 0.2920 | 0.2985 | 0.3204 | 0.2963 | 0.3397 | 0.3165 |
| S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9 | S10 | S11 | S12 | Mean | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | LSTM | 18.1006 | 19.2394 | 17.4561 | 21.1559 | 19.5055 | 21.6548 | 18.1532 | 20.5995 | 21.0374 | 19.3954 | 18.4665 | 23.2015 | 19.8305 |
| BiLSTM | 18.0737 | 19.5708 | 17.4851 | 21.5529 | 19.5199 | 21.5024 | 18.2051 | 20.6116 | 21.0968 | 20.0648 | 18.5075 | 23.2385 | 19.9524 | |
| GRU | 18.2846 | 19.5202 | 17.4705 | 21.3097 | 19.5682 | 21.7809 | 18.3439 | 20.6879 | 20.9501 | 19.7772 | 18.7310 | 23.3706 | 19.9829 | |
| BiGRU | 18.4066 | 19.5196 | 17.5263 | 21.4471 | 19.7659 | 21.8864 | 18.3044 | 20.6079 | 21.1133 | 19.8293 | 18.9517 | 23.6979 | 20.0880 | |
| CNN-LSTM | 18.3998 | 19.7535 | 17.5423 | 21.9600 | 20.0875 | 21.7654 | 18.2582 | 21.3936 | 21.3831 | 20.5814 | 18.4875 | 23.5033 | 20.2596 | |
| CNN-BiLSTM | 18.0460 | 19.5669 | 17.5357 | 21.5193 | 20.0994 | 21.8662 | 18.1882 | 21.4694 | 21.0171 | 21.1142 | 18.6094 | 23.1787 | 20.1842 | |
| CNN-GRU | 18.2183 | 19.6874 | 17.5565 | 21.8348 | 19.7397 | 22.0151 | 18.2250 | 20.8662 | 20.7810 | 20.0161 | 18.5489 | 23.4618 | 20.0792 | |
| CNN-BiGRU | 18.2668 | 19.7464 | 17.5711 | 21.6076 | 19.9810 | 22.1604 | 18.3079 | 20.7632 | 21.0255 | 20.2230 | 18.5808 | 18.5808 | 19.7345 | |
| TF-BiLSTM | 16.1178 | 17.3627 | 15.8417 | 19.8267 | 17.8521 | 18.6915 | 16.7548 | 18.1906 | 17.6451 | 17.3203 | 17.1758 | 20.8809 | 17.8050 | |
| TF-CNN-BiLSTM | 17.9947 | 19.8441 | 17.4662 | 21.8841 | 19.6320 | 22.0485 | 18.4108 | 20.6858 | 20.7671 | 20.3364 | 18.5153 | 23.6375 | 20.1019 | |
| TF-BiLSTM-attention | 15.1313 | 14.8985 | 13.9907 | 19.2926 | 17.1282 | 16.9033 | 15.1524 | 17.4800 | 16.6834 | 16.0785 | 15.6039 | 17.5039 | 16.3205 | |
| MAE | LSTM | 10.2881 | 10.8300 | 9.0488 | 12.0672 | 10.8458 | 11.2159 | 9.1468 | 11.0433 | 11.5139 | 11.5522 | 9.9805 | 12.1749 | 10.8089 |
| BiLSTM | 10.2844 | 10.9388 | 9.1592 | 12.6651 | 10.8806 | 11.3226 | 9.2960 | 11.0438 | 11.6228 | 12.2251 | 10.0081 | 12.1888 | 10.9696 | |
| GRU | 10.5620 | 11.1118 | 9.0461 | 12.3556 | 10.8661 | 11.5645 | 9.4594 | 11.1828 | 11.4348 | 11.6418 | 10.0806 | 12.2258 | 10.9609 | |
| BiGRU | 10.5188 | 10.9987 | 9.0619 | 12.2387 | 10.9713 | 11.5515 | 9.3846 | 11.0888 | 11.5483 | 11.6911 | 10.1389 | 12.3704 | 10.9636 | |
| CNN-LSTM | 10.4881 | 11.2544 | 8.9708 | 13.2826 | 11.2823 | 11.5292 | 9.3826 | 11.6358 | 12.0585 | 12.6506 | 10.1415 | 12.3071 | 11.2486 | |
| CNN-BiLSTM | 10.2668 | 11.0377 | 9.0081 | 12.7124 | 11.1819 | 11.4192 | 9.3518 | 11.7242 | 11.5822 | 13.1375 | 10.2952 | 12.1018 | 11.1516 | |
| CNN-GRU | 10.4272 | 11.0820 | 8.9467 | 13.2888 | 10.9788 | 11.5129 | 9.3631 | 11.0701 | 11.2701 | 11.8321 | 9.9739 | 12.2517 | 10.9998 | |
| CNN-BiGRU | 10.3830 | 11.2317 | 8.9172 | 12.8078 | 11.1421 | 11.6240 | 9.2699 | 10.9867 | 11.4748 | 11.8551 | 9.9910 | 9.9910 | 10.8062 | |
| TF-BiLSTM | 8.9259 | 9.0709 | 8.2499 | 11.3809 | 9.7360 | 9.6060 | 8.2254 | 9.4048 | 9.7731 | 11.2918 | 9.6746 | 10.5580 | 9.6581 | |
| TF-CNN-BiLSTM | 10.1281 | 10.8575 | 9.0618 | 13.1646 | 10.8501 | 11.4350 | 9.5689 | 11.0274 | 11.5016 | 12.2689 | 10.0571 | 12.3003 | 11.0184 | |
| TF-BiLSTM-attention | 8.7559 | 8.1511 | 7.3247 | 10.8909 | 9.7660 | 9.0983 | 7.2614 | 8.9792 | 9.7707 | 11.0173 | 8.8407 | 9.1302 | 9.0822 |
| S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9 | S10 | S11 | S12 | Mean | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | LSTM | 0.9530 | 0.9297 | 0.9293 | 0.9462 | 0.9498 | 0.9415 | 0.9303 | 0.9453 | 0.9338 | 0.9470 | 0.9488 | 0.9365 | 0.9409 |
| BiLSTM | 0.9531 | 0.9273 | 0.9290 | 0.9442 | 0.9497 | 0.9423 | 0.9299 | 0.9452 | 0.9335 | 0.9433 | 0.9485 | 0.9363 | 0.9402 | |
| GRU | 0.9520 | 0.9276 | 0.9291 | 0.9454 | 0.9495 | 0.9408 | 0.9288 | 0.9448 | 0.9344 | 0.9449 | 0.9473 | 0.9356 | 0.9400 | |
| BiGRU | 0.9514 | 0.9276 | 0.9287 | 0.9447 | 0.9485 | 0.9402 | 0.9291 | 0.9453 | 0.9334 | 0.9446 | 0.9460 | 0.9337 | 0.9394 | |
| CNN-LSTM | 0.9522 | 0.9259 | 0.9286 | 0.9420 | 0.9468 | 0.9409 | 0.9295 | 0.9410 | 0.9316 | 0.9403 | 0.9486 | 0.9348 | 0.9385 | |
| CNN-BiLSTM | 0.9533 | 0.9273 | 0.9286 | 0.9443 | 0.9467 | 0.9403 | 0.9300 | 0.9406 | 0.9340 | 0.9372 | 0.9480 | 0.9366 | 0.9389 | |
| CNN-GRU | 0.9524 | 0.9264 | 0.9284 | 0.9427 | 0.9486 | 0.9395 | 0.9298 | 0.9439 | 0.9354 | 0.9435 | 0.9483 | 0.9351 | 0.9395 | |
| CNN-BiGRU | 0.9521 | 0.9260 | 0.9283 | 0.9439 | 0.9473 | 0.9387 | 0.9291 | 0.9444 | 0.9339 | 0.9424 | 0.9481 | 0.9481 | 0.9402 | |
| TF-BiLSTM | 0.9627 | 0.9428 | 0.9417 | 0.9527 | 0.9580 | 0.9564 | 0.9406 | 0.9573 | 0.9535 | 0.9577 | 0.9557 | 0.9486 | 0.9523 | |
| TF-CNN-BiLSTM | 0.9535 | 0.9252 | 0.9292 | 0.9424 | 0.9491 | 0.9393 | 0.9283 | 0.9448 | 0.9355 | 0.9417 | 0.9485 | 0.9341 | 0.9393 | |
| TF-BiLSTM-attention | 0.9671 | 0.9579 | 0.9546 | 0.9553 | 0.9613 | 0.9643 | 0.9514 | 0.9606 | 0.9584 | 0.9636 | 0.9634 | 0.9639 | 0.9601 | |
| MAPE | LSTM | 0.3097 | 0.3697 | 0.3620 | 0.4138 | 0.2948 | 0.2795 | 0.3524 | 0.2875 | 0.2745 | 0.2780 | 0.2737 | 0.3005 | 0.3163 |
| BiLSTM | 0.2985 | 0.3743 | 0.3769 | 0.4474 | 0.2916 | 0.2889 | 0.3714 | 0.2896 | 0.2800 | 0.2870 | 0.2679 | 0.2994 | 0.3227 | |
| GRU | 0.3397 | 0.3932 | 0.3519 | 0.4250 | 0.3002 | 0.3145 | 0.3899 | 0.3124 | 0.2825 | 0.2828 | 0.2894 | 0.3168 | 0.3332 | |
| BiGRU | 0.3357 | 0.3847 | 0.3594 | 0.4142 | 0.3137 | 0.3130 | 0.3814 | 0.3178 | 0.2822 | 0.2801 | 0.2849 | 0.3103 | 0.3315 | |
| CNN-LSTM | 0.3301 | 0.4054 | 0.3280 | 0.4645 | 0.3114 | 0.3072 | 0.3746 | 0.2873 | 0.2864 | 0.2979 | 0.2614 | 0.3088 | 0.3303 | |
| CNN-BiLSTM | 0.3087 | 0.3866 | 0.3387 | 0.4533 | 0.3030 | 0.2905 | 0.3677 | 0.2855 | 0.2796 | 0.3008 | 0.2597 | 0.3155 | 0.3241 | |
| CNN-GRU | 0.3270 | 0.3889 | 0.3213 | 0.4807 | 0.2903 | 0.2956 | 0.3728 | 0.2932 | 0.2789 | 0.2821 | 0.2667 | 0.3270 | 0.3270 | |
| CNN-BiGRU | 0.3229 | 0.4047 | 0.3151 | 0.4420 | 0.3071 | 0.2985 | 0.3516 | 0.2865 | 0.2792 | 0.2836 | 0.2801 | 0.2801 | 0.3210 | |
| TF-BiLSTM | 0.2463 | 0.2889 | 0.3538 | 0.3612 | 0.2567 | 0.2090 | 0.3121 | 0.2426 | 0.2542 | 0.3036 | 0.2470 | 0.2694 | 0.2787 | |
| TF-CNN-BiLSTM | 0.3094 | 0.3586 | 0.3686 | 0.4758 | 0.3060 | 0.2687 | 0.3894 | 0.3093 | 0.2741 | 0.2890 | 0.2792 | 0.3148 | 0.3286 | |
| TF-BiLSTM-attention | 0.2365 | 0.2253 | 0.2675 | 0.3375 | 0.2489 | 0.1947 | 0.2728 | 0.2382 | 0.2729 | 0.2736 | 0.2373 | 0.2696 | 0.2562 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, X.; Wu, N.; Pan, Y. Prediction of Particulate Matter 2.5 Concentration Using a Deep Learning Model with Time-Frequency Domain Information. Appl. Sci. 2023, 13, 12794. https://doi.org/10.3390/app132312794
Tang X, Wu N, Pan Y. Prediction of Particulate Matter 2.5 Concentration Using a Deep Learning Model with Time-Frequency Domain Information. Applied Sciences. 2023; 13(23):12794. https://doi.org/10.3390/app132312794
Chicago/Turabian StyleTang, Xueming, Nan Wu, and Ying Pan. 2023. "Prediction of Particulate Matter 2.5 Concentration Using a Deep Learning Model with Time-Frequency Domain Information" Applied Sciences 13, no. 23: 12794. https://doi.org/10.3390/app132312794
APA StyleTang, X., Wu, N., & Pan, Y. (2023). Prediction of Particulate Matter 2.5 Concentration Using a Deep Learning Model with Time-Frequency Domain Information. Applied Sciences, 13(23), 12794. https://doi.org/10.3390/app132312794