1. Introduction
The 21st century has witnessed an increasing number of malware incidents reported, causing massive information and financial loss at both personal and corporate scales [
1]. The last few decades did not only witness an increase in malware prevalence but also in their functionalities and impact; malware types have evolved from self-replicating harmless software called worms in the 1980’s to ransomware, which is capable of disabling device operations, in the recent decade. Malware developers are evolving their techniques for creating complex malware to target new technologies and avoiding detection by using obfuscation and encryption techniques [
2].
Traditionally, malware analysis usually follows either static or dynamic approaches, depending on the requirements and goals of the analysis. In static analysis, features are extracted without executing the binary code using tools or open-source libraries. It examines malware behavior by using the original structure data of executable files, such as the byte sequence, which avoids the requirement of running the executable file. In turn, this also avoids potentially harming the operating system and exposing user data. Nevertheless, it remains challenging to detect unknown malware because the typical static technique frequently relies on a sizable malware database. Additionally, it is reliant on intricate analyses of software code and skilled extraction techniques.
Data mining for malware detection was initially introduced by Schultz et al. [
3]. For malware identification, they made use of static properties like strings, byte sequences, and portable executable (PE) files. Following that, Krgel et al. introduced a unique fingerprinting method for identifying polymorphic worms based on structural data from a binary code’s control flow graph (CFG) [
4]. Malware detection methods were also examined and compared [
5]. Finally, an improved version of CFG-based malware detection was proposed by Nguyen et al. [
6]. The authors attempted to bridge the gap between formal approaches that characterize malware activities and deep learning technology.
Static analysis techniques have become increasingly popular in recent years for locating malware. In order to leverage machine learning techniques to identify malicious applications, a combination of permission requests with application programming interface (API) requests was recommended [
7]. This approach can be used to assess and categorize unidentified application packages. The use of visual analysis approaches has just been put forth, which is a significant advancement in the detection of malware. It has greater detection accuracy and fewer characteristics than the conventional static analysis method [
8]. The technique utilizing visualization technology can extract high-dimensional inherent information from data samples, in addition to inheriting the benefits of conventional malware detection technologies. The first to propose the idea of turning malware into grayscale graphics was [
9]. A given malware file transforms into integers that can be looked at as an image.
Conducting a more thorough exploration of the subject, we explore state-of-the-art malware classification techniques, such as that proposed by Ni et al. [
10]. Their approach targeted malware families obtained from images of malware codes with high accuracy. Another classification mechanism was developed by Qiao et al. [
8], which combines malware records with byte information. Further, a design was created in [
11]. The design used deep convolutional neural networks and achieved 98.47% precision. A system was proposed in [
12] that combines a recurrent neural network (RNN) and a CNN. It achieved good results on a single dataset.
Analysis tools have also gained popularity over the past years. A malware analysis tool was introduced by [
13]. The tool utilizes an environment to check malware samples and their corresponding system calls. A strategy investigated by [
14] targeted malware behavior by focusing on system information exchange. Additionally, architecture proposed in [
15] emphasized categorization and utilized normal and harmful software analysis. Additional malware recognition approaches such as [
16] were investigated, which concentrated on the behavioral traits of malware. Similarly, a technique proposed by [
17] utilized invariant modeling to obtain a representation of the graph.
In recent years, the incorporation of artificial intelligence and machine learning algorithms has gained popularity for malware detection applications. Smmarwar et al. have explored the efficacy of a hybrid approach utilizing convolutional neural networks (CNN) and long short-term memory (LSTM) for malware classification, demonstrating promising results [
18]. Concurrently, neural network-based methodologies have gained prominence in the context of Android malware detection, as exemplified in the studies by Ullah et al. [
19] and Mahindru and Sangal [
20].
Given the aforementioned literature analysis, it is clear that using artificial intelligence and machine learning to detect malware has grown in popularity and demonstrated benefits. Positive effects have also been seen through visual depiction. Nonetheless, it is crucial to remember that various file formats still call for various properties in order to identify malware. Given this, the following is a summary of the work’s goals and objectives:
To identify a universal image transformation method that works across multiple file formats, facilitating the development of a unified model with simplified resource requirements for detecting malware across multiple formats.
To develop a feature extraction approach that captures vital underlying data information from files.
To conduct a comprehensive assessment of various neural network models, including conventional and compact networks, for effective transfer learning in the specified application.
To establish a foundation for future research expansion to encompass additional file formats, such as audio (MP3) and video, broadening the scope of the study.
Hence, it can be inferred that the proposed approach differs from existing methods by adopting a unified model update and retraining process, avoiding the need to retrain each file type separately. This approach streamlines the workflow, reduces redundancy, and conserves resources, resulting in more convincing results. Its suitability for malicious file identification stems from its ability to efficiently address diverse requirements, offer scalability, and provide cost-effective solutions.
Our study examines different pre-trained compact and regular networks, in addition to series and directed acyclic graph architectures, in malware classification. Our approach utilizes grayscale transform-based features as a standardized feature set to classify malware across PDFs, Microsoft Office Documents, and Windows Portable Executable files. We incorporate multiple datasets in our study, such as Zenodo, jonaslejon, Clean DOC files, Clean XLS files, Clean PDF files, Dike, and Malimg, in order to evaluate their accuracy.
3. Methodology
After a comprehensive evaluation of various feature extraction and neural network techniques, a unified methodology was formulated to classify malware of different file types. This section provides a detailed description of the datasets used, feature engineering, and training process. It is worth noting that this work is a continuation of our prior research, including [
53], which focuses on the categorization of malware within PE files, and [
54], which concentrates on the distinction of malicious images.
3.1. Datasets
Several datasets were utilized in this work to ensure that the developed model possesses good generalization properties. Consequently, we combined multiple datasets comprising malicious and benign files in MS Word documents, PDFs, and Windows PE files. The train-test split ratio that was adopted is 70 to 30. The used dataset in this work is summarized in
Table 2. VirusTotal [
29] was used to validate and add confidence levels to the obtained results.
3.2. Feature Extraction Using Grayscale-Based Image Transforms
Expanding upon our prior research efforts documented in [
53,
54], it is evident that the utilization of image-based features bestows advantages in the detection and categorization of malware within image and PE file formats. Hence, this study extends the previous approach by incorporating image transforms to develop a comprehensive classifier that is capable of detecting malicious files across different file types, including PDFs, Microsoft Office documents, and PE files.
Feature extraction was conducted using a common approach found in the literature that converts the PE file’s features into a grayscale image. This involved converting raw binary codes into eight-bit unassigned vectors and reshaping them into a 2D array. The resulting grayscale image was then reshaped and resized using bicubic interpolation to match the input size requirements of the pre-trained models. Additionally, we observed that the bit conversion approach is compatible with various file types, allowing the creation of a uniform processing pipeline for different formats.
Figure 3 illustrates the adopted approach for converting files into grayscale images. Similarly, the mathematical representation of the steps is also outlined below.
Step 1: Binary Data Representation:
The binary data from the first file are represented as a 2D binary array, denoted as B, with dimensions , where corresponds to the binary value at row i and column j.
Step 2: Conversion to Numerical Array:
A mapping function
is applied to convert the binary array
B into a numerical array
A with the same dimensions (
). This mapping may include translating 0 to 255, following the grayscale encoding scheme. The process can be mathematically expressed as:
Step 3: Grayscale Image Generation:
The numerical array
A is used to generate grayscale images, denoted as
G, with identical dimensions (
). Each numerical value in
A is directly translated into a pixel intensity value for the corresponding location in
G. The mapping is typically such that pixel intensities range from 0 (representing black) to 255 (representing white) and can be expressed as
We used an open-source Python code for the grayscale image generation process [
59]. Grayscale image samples are shown in
Figure 4 and
Figure 5, displaying benign and malicious samples of Microsoft Word and PDF files, respectively.
3.3. Model Training
Neural networks are recognized for their advantages in pattern recognition and data classification. Thus, our experiments are focused on comparing different neural network architectures using transfer learning for the specified application.
The utilization of transfer learning can be justified based on its ability to leverage pre-trained models. This approach allows the model to inherit valuable knowledge and features acquired from large and diverse datasets, which can significantly expedite the training process and enhance performance, especially when the dataset is limited. Further, both compact and regular networks are used and compared because of the benefits of these diverse architectures. Compact networks are particularly advantageous in resource-constrained environments, such as mobile devices and edge computing. They strike a balance between model size and performance, making them efficient choices for specific applications. Additionally, compact networks are often less prone to overfitting, which is a crucial advantage when working with smaller datasets.
Both series and directed acyclic graph (DAG) architectures are also considered and compared due to the flexibility that these structures offer. Series architectures are typically used when data flow sequentially, allowing for straightforward modeling of linear dependencies. In contrast, DAG architectures enable more complex and interconnected relationships between layers, which can capture intricate dependencies and patterns in the data. By considering both options, we are able to compare which architecture works best for the specific task’s requirements, ensuring that the model can effectively capture the dependencies inherent in the data.
Given the diversity of the pre-trained model architectures compared, we use accuracy as the basis for determining the top methodology. The input to the models are the extracted grayscale images, which are pre-processed before being fitted in order to align with the input requirements of the model. For example, pre-trained models have specific criteria related to image color scales and dimensions. Consequently, all feature images generated needed to be standardized by concatenating them into a three-dimensional format representing the RGB color scale. Further, these images have to be resized as per the model’s requirements, as previously specified in
Table 1.
3.4. Performance Evaluation Metrics
Throughout the comparisons, the system’s responses are then observed in the following ways:
Effects on the overall accuracy of regular versus compact neural networks.
Effects on performance when utilizing DAG or series architectures.
Effects on system accuracy when training models for a specific file type and general models for multiple file formats.
To assess the effectiveness of the suggested systems, the following aspects are analyzed:
Comparing the features extracted from single and multiple file types using different models at both the individual and overall level.
Examining the impact of enlarging and merging datasets, as well as how the system responds to imbalanced data.
The training for these image transforms was performed using Matlab. The models are then exported in an Open Neural Network Exchange (ONNX) format to achieve compatibility with Python for deployment. It should be noted that, when testing the deployed model in Python, the library OpenCV reads the images in BGR format instead of the usual RGB. Since the model is trained on RGB images, the axes have to be established and interchanged to fit the requirements accordingly.
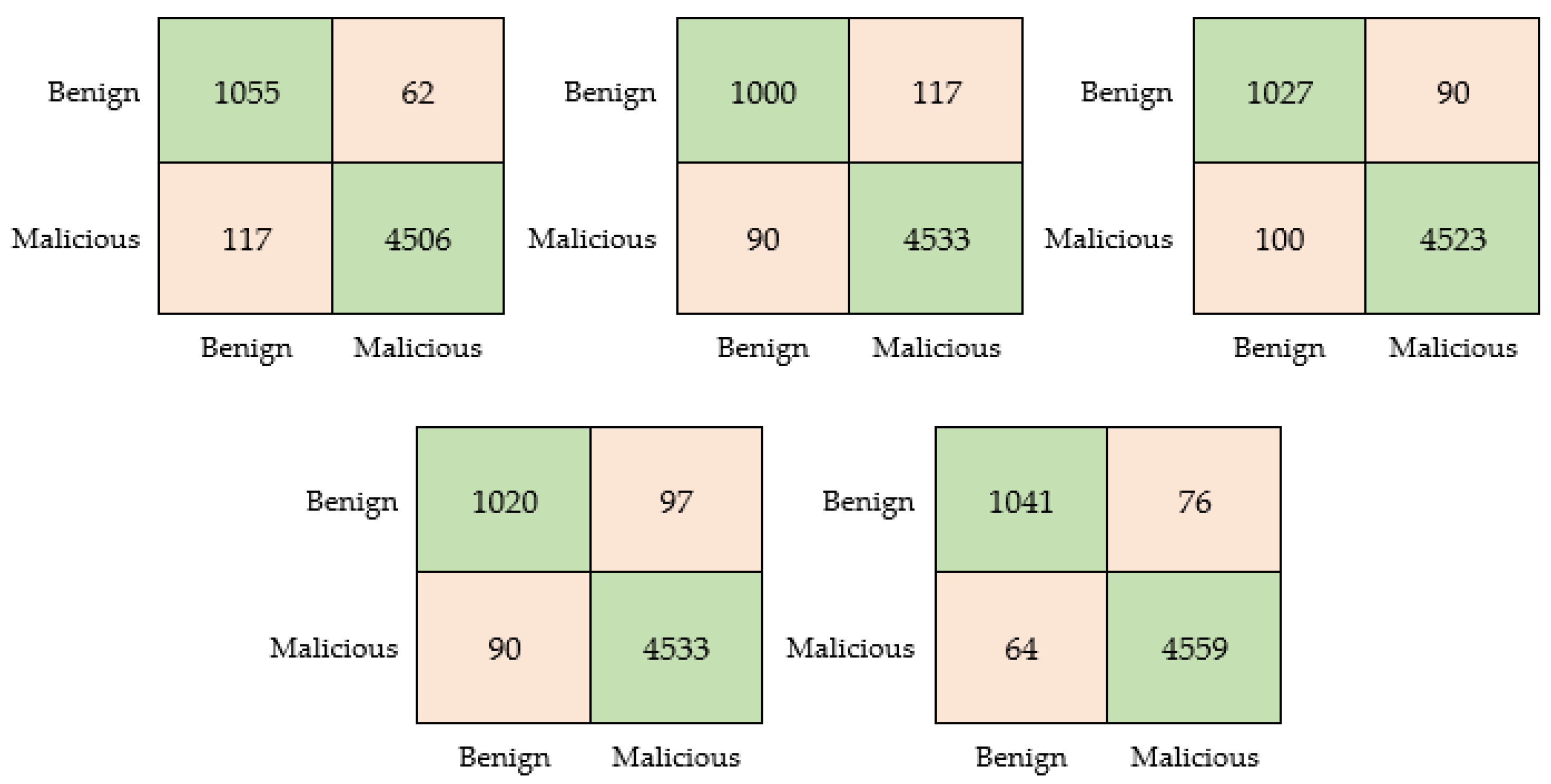
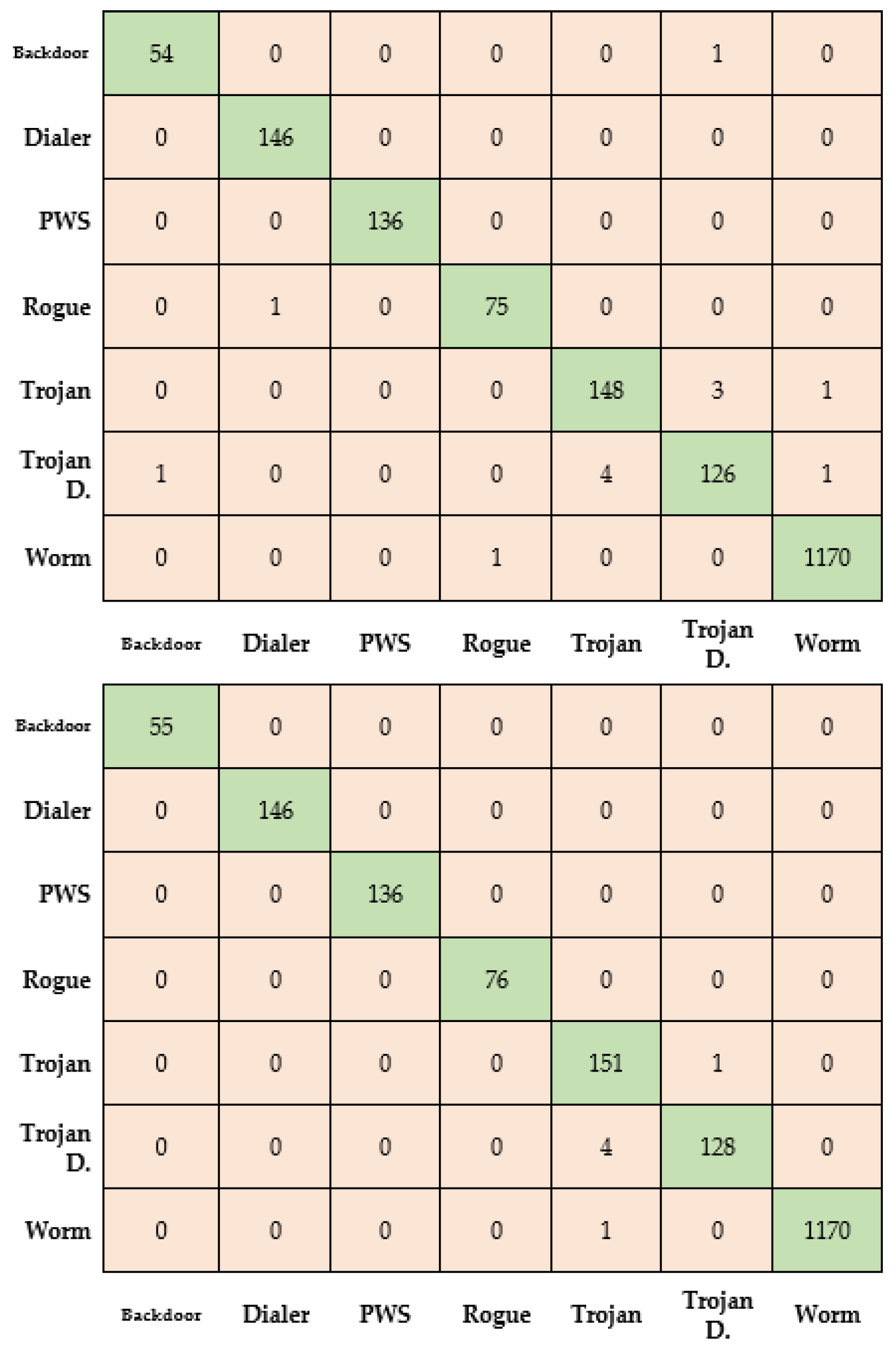
Various measurement criteria were also used to further examine the performance. The evaluation criteria included recall, specificity, precision, Dice score coefficient, overlap between manual and automatic segmentation, accuracy, and the F1 score. It is important to note that a three-fold cross-validation was used consistently throughout the experiments, and the reported results contain the average of these folds.
5. Discussion
The results presented demonstrate that all pre-trained models consistently produced satisfactory outcomes across all experiments. It is worth mentioning that a three-fold cross-validation technique was also conducted in order to ensure the reliability of these findings.
Based on the results found, it can be inferred that employing a compact neural network model can be an advantageous approach. Such models offer a high level of accuracy that is comparable to regular-sized models while also providing benefits from lower resource requirements. The compact size of the produced model enables a more efficient deployment within the intended application. This factor holds particular significance, provided that the primary objective of these experiments is to implement the model in a practical and usable application.
To assess the reliability and accuracy of the trained model further, a detailed testing methodology was performed. In addition to the standard train and test sets, this methodology included a thorough examination of the model’s behavior when exposed to data that fell outside the categories covered by the training and test sets. This involved testing the model against other related databases, thereby simulating real-world scenarios where the model encounters unfamiliar data.
Through this comprehensive testing methodology, we are able to gain insights into the model’s adaptability and generalization capabilities. Evaluating its performance on data from different categories provides a measure of its reliability and potential for real-world deployment. This assessment allowed us to ascertain the effectiveness of the proposed methodology beyond the specific contexts used during training and testing, ensuring its suitability for a broader range of applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}