1. Introduction
In recent periods, the amount of online shopping and payment has been increasing at a great pace. Following this trend, online sales have become the new target of fraudsters in the last decade. Thus, ongoing evolutionary fraud attempts always cause companies to experience serious losses both financially and in terms of customer satisfaction. The aviation industry is one of the well-known sectors for online ticket sales where the most losses are experienced in terms of both financial and reputation due to fraudulent activities. In accordance with civil aviation laws, the airline company has to compensate the loss of the person whose credit card is stolen and used in the purchase of airline tickets or in-flight services. Therefore, airline companies lose millions of dollars each year and/or miss potential customers. To minimize their losses, such companies develop or purchase fraud-detection systems to secure their sale channels and prevent fraudulent attempts. Analyzing the market shows us that the majority of these fraud-detection systems generally exploit traditional rule-based mechanisms [
1,
2]. Unfortunately, rule-based fraud-detection systems are incapable of adapting to the rapidly changing strategies of fraudsters and revealing complex fraud patterns. Therefore, instead of traditional rule-based systems, automated systems that can detect fraud using machine learning or deep learning methods have become prominent [
3,
4]. However, these learning methods alone do not provide the desired effectiveness for an ideal fraud-detection system. Fraud detection is a complex issue that needs to be focused on many different points [
5] and problems, especially regarding the sector facts and dynamics.
One of the main problems for fraud-detection research in the literature is that the well-known datasets consist of individual transactions. However, since fraud is a temporal and chronological problem, the historical links of the transaction are also of great importance. Information about a single transaction may not always be sufficient to detect fraud. Hence, when evaluating a transaction, possessing information about its associated previous transactions enhances the historical robustness of the fraud-detection system. While there can be multiple avenues to leverage this strength, one of the most effective approaches involves transforming traditional systems into profile-based solutions. This transformation is achieved by crafting substantial profiles that can directly influence the detection mechanism through the utilization of historical data associated with each profile. In this study, we introduce a novel profile-based fraud-detection system for suspicious airline ticket activities in order to differentiate a fraudster from an ordinary airline passenger using his/her past activities. In this system, we put forward various historical and in-record profiles by introducing discriminative time-line features that have a direct impact on the success of fraud detection in the airline industry. These additional fields make it possible for each transaction to be aware of the related transactions before itself. In addition, the combinations of these designed profiles were analyzed in order to reveal the superior profile combination for the aviation field.
From the perspective of companies exposed to fraud cases, fraud is a financial problem. Therefore, the primary purpose of developing fraud-detection systems is to reduce financial losses and prevent potential decreases in revenue. However, in most studies [
6,
7], the success results are calculated based on the quantity for both traditional and automated detection systems. These measurement metrics, which are based on the number of false/true detected transactions, cannot show the performance of fraud-detection systems thoroughly. For this reason, in our study, besides the transaction number-based metrics, the cost-based metrics were utilized for the evaluation of the proposed profile-based architecture. In this way, it is also possible to observe to what extent the developed detection system can achieve loss minimization and potential profit optimization. The ability of the detection system to produce both quantity-based and cost-based results is an important criterion in terms of maintaining the balance between company profitability and customer satisfaction.
The scientific goals of the fraud-detection system developed in our study can be summarized in two essential points. First of all, we aim at maximizing the F1 score, which is the most important performance metric for such imbalanced problems. Since a single and static profile structure ends up with low success in fraud detection and with many false positives, we build up historical connections using existing passenger activities obtained from the proposed profiles via feature engineering. The second goal of our study is to overcome the negative effect of the randomly selected instances, as they might not represent the non-fraud data in an efficient manner. Thus, we introduce the BRUS algorithm to include the most representative instances from the airline ticket dataset. This approach has a high negative sample representation ability as well as oversampling, has no misleading synthetic positive record, and provides ease of processing thanks to its smaller size.
Our study makes the following contributions to the literature:
To the best of our knowledge, there is no study in the literature for the aviation industry that provides solutions to fraud-detection problems and builds detection systems using modern supervised learning techniques. In this study, for the first time in the aviation field, a baseline was created using one of the biggest airline activity datasets with a specific data structure and supervised machine learning (ML) algorithms. After we created the baseline and examined the ML results, we applied deep neural network (DNN) as our main classification method to enhance the overall performance of the system. We also customized the DNN architecture utilizing different hyperparameters based on aviation data to boost its performance.
Analyzing passenger activities encouraged us to develop a multi-modal profile-based fraud-detection system in order to get rid of the restrictive structure of transactional datasets in terms of backward connection. This aviation-specific fraud-detection system can establish historical connections by taking power from three different profiles and many statistical parameters within these profiles. Therefore, it significantly increases the success of fraud detection, which is a temporal problem.
Fraud is essentially a financial problem in terms of its consequences. However, considering this problem in the literature, the number of studies using cost-sensitive measurement metrics is quite low. Due to civil aviation laws, airline companies have to regulate customer grievances, so the dimension of financial loss comes to the fore. The success of the fraud-detection system developed in this study was measured not only on the basis of quantity, but also with the cost-sensitive metrics that we recommend, and we tried to achieve a balanced success.
The balanced random undersampling (BRUS) method has been developed to solve the imbalanced dataset problem, which is the most frequently encountered problem in the detection of fraud. In this method, there is a mechanism that evenly distributes the dataset and prevents duplication during sample selection. This method was also utilized as the first step in hybrid sampling tests in our study.
Section 2 presents the literature review on fraud detection.
Section 3 explains our dataset and aviation terminology in general terms. In
Section 4, common challenges in fraud detection and the key points of these challenges are specified. In
Section 5, we introduce the proposed profile-based fraud-detection mechanism and describe it in detail.
Section 6 gives all the technical steps of the proposed fraud-detection system. The results of all experiments are demonstrated and discussed in
Section 7. Final comments and inferences both about the developed detection system and the proposed approaches are given in
Section 8.
2. Literature Review
Fraud cases have been emerging in many sectors, especially with the broad usage of online payment. Most of the studies have been carried out in the banking sector, in which different approaches are recommended to develop successful fraud-detection systems and solve certain fraud-detection problems, such as [
8,
9,
10,
11,
12]. Since the common gateways of sales transactions are made through virtual POS machines belonging to the banks, the frequency of fraud may be higher than in other sectors. The e-commerce sector, where online payment transactions take place intensively, is also among the areas where fraud-detection studies are carried out [
13,
14,
15]. Since large payments can be made in the insurance sector, fraud cases can be seen frequently. Thus, various fraud-prevention studies such as [
16,
17,
18] have been carried out to proactively prevent insurance abuse. Although the aviation sector is one of the sectors most affected by fraud cases, it is not covered much in the literature. Cybersource is a technology provider from which airline companies purchase products or services for fraud detection [
19]. However, since these currently used fraud-detection products are rule-based, they have low effectiveness and sustainability. Fraud-detection studies in the literature can be examined in three main scopes, including traditional rule-based systems, modern automated systems, and systems using history-aware detection techniques.
Some important problems in most fraud-detection systems need to be solved. The most important one is the imbalanced dataset problem. Sampling techniques are frequently used approaches to solve the imbalanced dataset problem [
20,
21]. In some studies, hybrid methods are suggested by modifying sampling techniques in different ways. Hanskunatai [
22] created a three-phase hybrid sampling mechanism using DBSCAN for clustering and undersampling/oversampling techniques for sampling. When this hybrid mechanism is used, an increase of up to 69.91% according to the SMOTE algorithm, up to 19.34% according to the Tomek Links algorithm, and up to 59.93% according to the non-sampling situation was observed on the basis of F1 scores in tests performed on different datasets. The concept of temporality inherent in fraud detection is not addressed in this study, so transactions in some time periods of the dataset may be lost during undersampling. In addition, no direct or indirect precautions were taken for the problem of non-selection of linked transactions that occurs during the undersampling stage. Finally, using only the accuracy metric as a success criterion in the field of fraud, where the imbalanced dataset problem occurs, is a misleading approach. Using precision/recall or F1 score metrics instead will reveal the success of the developed system more clearly.
Rule-based systems were the initial ones developed to prevent fraud cases and these systems are still in use in several companies. In such systems, there are stages of creation of the rules, testing them, and making decisions by examining the cases that are not covered by the rules. All three stages are carried out manually. Therefore, rule-based systems have semi-automated traditional mechanisms where manual effort is high and complex patterns are difficult to detect. Some studies have been conducted in order to reduce the manual effort in rule creation and management processes and to increase the success rate. For example, Garcia [
23] created a fraud-detection rule ontology using Web Ontology Language (OWL) and Semantic Web Rule Language (SWRL). In this study, the authors tried to strengthen existing rule-based systems with a semantic approach. They made use of a dataset containing anti-fraud rules of the existing rule-based system. First, fraud-detection rules and their connections were created. Afterwards, these rules were tested on a real fraud dataset and conflicts were revealed. These revealed conflicts showed the weak points of the system and these weaknesses were eliminated. As a result of this study, it was observed that the accuracy of the results increases by eliminating the rules that lead to wrong decisions. In another rule-based fraud-detection study, Febriyanti [
24] aimed at eliminating the negative effect of strict rules on success by generating dynamic rules as a result of the analysis of business processes. In this study, a rule-based system that can detect fraud by adapting to rapidly changing event logs in the ERP system is proposed. As a work subject, the land-management process in the ERP system of a sugar company is discussed. They utilized a dataset that consists of event logs of the business process. These log records have a data model determined according to business processes. Instead of creating static rules, a mechanism was developed that could extract dynamic rules from business processes. The accuracy increased from 74% to 96% after these automatically generated dynamic rules were combined with the existing static rules. Although Garcia [
23] uses methods that will increase the success of rule-based systems in his work, it requires manual effort to create and control these rules. In addition, in these studies, fraud detection was performed with narrow rules, making it difficult to reveal complex patterns.
Fraud detection is becoming more complex with each passing day, especially due to many zero-day attack techniques. Fraud characteristics do not remain constant and are in a continuous evolution process. For these reasons, fraud-detection mechanisms need to dynamically renew themselves and adapt to unprecedented fraud methods. However, this flexibility and adaptation is not possible via rule-based systems. Adding new rules and reorganizing existing rules according to changing fraud trends requires a great deal of manual effort. In addition, this process, which mostly proceeds with human effort, is open to errors. At this point, automated fraud-detection systems with high adaptability are favored. These systems have the ability to proactively defend against changing fraud flows with minimal manual intervention. While there may be various automated system architectures, machine learning and deep learning methods are mostly utilized in such systems. Alarfaj [
8] compared the fraud-detection success of some machine learning algorithms and the CNN network in his study. The dataset consisted of two-day credit card transactions that took place in October 2018. The well-known shallow learning algorithms, including decision tree, k-NN, logistic regression, SVM, random forest, and XG Boost, were evaluated and compared against the CNN algorithm. The test results showed that the structure they built using CNN had higher success on the basis of accuracy. However, accuracy is a misleading performance metric, since fraud detection has a high level of imbalanced datasets, whereas the F1 score parameter is one of the most accurate success metrics in the fraud detection field. In addition, because the study only covers credit card transactions for two days, it is important to note that the results for such short periods could be deceptive due to the nature of the fraud problem, since transactions in the fraud dataset may be related to transactions that took place a long time ago. Using a temporal distance in the training set as short as 2 days will prevent many fraud patterns from being revealed. Similarly, the results of the deep network architecture created in Yu’s study [
25] were compared with the results of some machine learning algorithms. It has been claimed that the results obtained with deep learning techniques are more successful. However, in this study, the measurement results were evaluated through the accuracy metric and there was no cost-based measurement system. In addition, no solution has been found to the problem of ignoring the connected history caused by the nature of transactional datasets. On the other hand, Chang [
26] claimed that the selection of features that affect the decision mechanism in fraud detection is the most critical process. They claimed that since internet finance scenarios and fraud characteristics are constantly changing, artificial feature production methods are insufficient and become time-consuming. In order to prevent this negation, they proposed an automated feature-engineering method based on deep feature synthesis and feature selection. In this method, feature production is carried out by dividing the original data table into small pieces. The efficiency of the process of creating features and selecting important features for fraud detection is increased. This method does not require the opinions of business experts and significantly reduces manual effort during the feature-engineering phase. However, if a balanced model cannot be created with precise auto-tuning during the feature-engineering phase, overfitting problems will arise. Thus, the features produced will only be successful in the training data. In addition, the deep feature synthesis method may cause high operating costs on large datasets.
Since fraud is a temporal and historical problem, having information about past records is one of the most important requirements for detection systems. Therefore, we claim that the success achieved using only the transactional dataset cannot exceed a certain level. Different methods including transforming the dataset to include historical connections or using algorithmic memory techniques can be applied to gain this past awareness capability in the fraud-detection system. Few studies have utilized this idea. Olszewski et al. [
27] tried to create a map of users using the self-organizing map (SOM) technique in order to build more successful fraud-detection systems. During this study, not vectors as in the original form of the SOM technique, but matrices consisting of records were included. Thus, the consecutive activities of the users are recorded in these matrices. While trying to detect fraud using these matrices, a new threshold mechanism is proposed. In this study, a grouping was made only on the basis of users’ activities. It is aimed to detect fraudulent transactions based on the anomaly of the user’s activities. However, objects with their own activity history, such as credit cards, were ignored. Malekian [
28] proposed a new mechanism for profile-based fraud-detection systems that could adapt themselves to changing fraud patterns. In this proposed approach, besides the historical profile, there is also a temporary profile where new concepts can be perceived. Both profiles are fed with transactions in a real-time flow. It is understood that at the point where the temporal profile and the historical profile make different decisions, new concepts emerge and the current model begins to lose its up-to-dateness. One of the shortcomings of this study is that only changes in cardholder behavior were taken into account. If attempts are made with more than one credit card, the system will not be able to detect any changes. In order to prevent this problem, changes in all data objects that may affect the result must be evaluated. Moreover, Seyedhossein [
29] claimed that a transaction-level fraud-detection system cannot achieve its maximum potential success. Instead, they proposed a profile-based fraud-detection system where profiling was performed on the daily amounts spent for each credit card and used in the decision phase. They tried to reveal the patterns through the changes in daily spent amounts and the movements over time. In this way, they tried to shorten the time elapsed between the realization and detection of the fraud attempt. However, in this study, only credit card-specific profiling was performed and only the statistics of daily spending amounts were recorded. This is one of the earliest studies exploiting profiling mechanisms but far from multi-modal profiling and/or benefiting from rich profile details.
One of the approaches in which past transactions are taken into account is deep network architecture created via LSTM, where the significant information is kept in memory units. There are a few studies using LSTM to ensure the connection and continuity between transactions in the transactional dataset, such as [
30,
31,
32,
33]. However, where no clustering or profiling is performed on the data in studies using LSTM in this way, the memory units to be created will have a global scope, so unrelated transactions will also be considered. This will cause information complexity in terms of historical connection and the system will not be fully history-aware. In addition, LSTM would lack some profiles that may affect the result and many statistical data fields belonging to them. Thus, it could not provide this level of historical connectivity capability.
To the best of our knowledge, the fraud-detection problem in the aviation industry is hardly discussed and no comprehensive results have been presented so far. This study is the first in the field of aviation to address the fraud-detection problem, to try to develop solutions against challenges, and to present the results comprehensively. In this study, we first give the baseline, then we select the appropriate instances using the proposed BRUS algorithm from the whole dataset in order to remove the negative effect of random selection. We additionally benefit from the oversampling technique and combine it with the BRUS algorithm to find the optimum ratio between fraud and non-fraud instances for a robust fraud-detection model in aviation. We then introduce novice-engineered features obtained from the proposed profiles using the historical connection of passenger activities. Finally, we evaluate the performance of our mechanism not just using classical metrics but also including cost-sensitive measurements.
5. Profile-Based Fraud Detection
Since fraud detection is a chronological and temporal problem, the past movements of the relevant transactions are also of great importance. However, several studies [
50,
51,
52,
53] utilize only transaction information, ignoring their relation to the past. This paradigm causes fraud-detection systems only to have information about the relevant transaction at the time of the decision and completely ignore the past activities of respective user/card/PNR (Passenger Name Record) information. This common approach, which is against the nature of fraud detection, limits the success rates of those systems by failing to notice high-risk user and payment information and/or rejecting ordinary safe ticket sale activities. To address this issue, it is essential to leverage historical transactions by constructing meaningful airline passenger profiles. These profiles can assist in recognizing trustworthy user and card activities, allowing them to be directly integrated into the decision-making process.
In this study, an ability to be aware of the past movements of candidate passengers has been enabled by deriving them from historical statistics of certain airline customer profiles and adding them to the current transactional information. The proposed profile-based fraud-detection system for aviation is built on three basic profiles, as follows:
Credit Card Profile
PNR Profile
Record Profile
Although both the PNR profile and the credit card profile are basically similar profiles, they are separated because they are quite different from each other in terms of their scope. The scope of the credit card profile covers the entire dataset, whereas the PNR profile covers a limited area such as all attempts, additions, and cancellations made by the customer from entering into the system and starting to request a service until the end of this service. The credit card and PNR profiles created in this study benefit from the historical movement strategy. In such profiles, the process is progressing by generating new data fields, which consist of statistical data that are calculated by considering all relevant past transactions of the profile value. In order to utilize such historical movements, first, records must be processed chronologically, just as real-world transaction flow. Thus, the profile information in each transaction only represents the previous history of that transaction. In this way, each record in the dataset will have information not only about themselves but also about all previous transactions that have been linked to them. In contrast, the record profile exploits a local approach to reveal some hidden information in the record. This profile is designed to reveal hidden information in the record and to generate new data fields that have a direct impact on decision-making. On the other hand, some profiling modes have been designed so that the created profiles can be used in different combinations. Using these profiling modes, it will be possible to observe which profiles have more effect on the result. These profiling modes will be explained in detail in the methodology section.
In the following subsections, we aim to illustrate the effectiveness of the proposed profiles by presenting several example scenarios using
Table 2,
Table 3 and
Table 4. It is important to note that the “chargeback” column serves as the ground truth indicator for non-fraud and fraud cases. Additionally, all email addresses and passenger names shown in
Table 3 and
Table 4 are fictional and conceived by the authors just to demonstrate the context.
Another important issue is that there may be sudden changes in spending habits in extraordinary situations such as COVID-19. However, since sudden changes in such situations will occur in all profile objects at the same time, they can be distinguished from fraud cases. Spending changes in fraud cases are mostly more drastic. On the other hand, fraud attacks are evolving in time, so fraud models need to be frequently updated accordingly. Hence, our profile mechanism would adapt itself those changes.
5.1. Credit Card Profiling
This profiling mechanism focuses on the past activities of a given credit card. It scans the entire history of the respective card, as given in
Table 2. Thus, we collect feedback about the card used for purchasing an airline ticket and we form an opinion about the reliability of this card. The following fields are extracted as novice features from the past transactions of the given card:
Number of chargebacks in the past
Number of accepted transactions in the past
Number of rejected transactions in the past
Number of transactions submitted for manual review in the past
Number of domestic flights purchased with this credit card
Number of international flights purchased with this credit card
Number of unique phone numbers used with this credit card
Number of unique emails used with this credit card
Average amount spent with this credit card
Highest amount spent with this credit card
Table 2 contains two credit card profiling scenarios that present the status of the profiling map when each transaction arrives. These scenarios represent how cases that cannot be detected from a transactional perspective can be caught using changes in spending habits from a profile-based perspective. While colorless regions represent legal transactions, green regions represent fraudulent transactions that can be detected from the proposed perspective, and red regions represent fraudulent transactions that cannot be detected from the transactional perspective. Substantial rises in expenditures were observed in transactions marked in red. These increases might show that the card has been taken over by a fraudster and fraudulent transactions are being attempted. However, in transactional datasets, these relative changes cannot be caught by the fraud-detection system. One of the main goals of our credit card profile is to be aware of the spending habits of related credit cards. Thus, a fraud-detection system will be capable of perceiving the suspicious differences between current transactions and past statistics.
The card has been stolen and used by fraudsters in red-marked transactions. Some fraudsters try to purchase high-priced tickets in order to gain the maximum profit. Therefore, after the card is stolen, the spending habits related to the card may change suddenly. Although it is not possible to capture this change with the transactional approach, it can be easily detected with the profile-based approach. With the transactional detection system, the red-marked transaction cannot be detected and then a chargeback occurs. However, it is later understood that this card has been stolen and the green-marked transactions under the red-marked transaction can be blocked even though they are fraud. In summary, the transactional approach will miss all fraud transactions of a stolen card from the moment the first fraudulent transaction occurs until the chargeback feedback is received. However, since the profile-based approach can take into account transaction histories, statistical information, and changes, it has the ability to catch all fraudulent transactions from the first attempt.
5.2. PNR Profiling
PNR refers to a session that covers all transactions of the user after interacting with the sales channel until the end of the customer experience. In this profiling mechanism, we aim to track the short-term activities of a customer regarding the related session. Our analysis of the fraud cases shows us that fraudsters’ activities generally differ from ordinary customers. The following features are engineered via a given PNR number:
Number of chargebacks in the past
Number of accepted transactions in the past
Number of rejected transactions in the past
Number of transactions submitted for manual review in the past
Number of domestic flights purchased in this PNR
Number of international flights purchased in this PNR
Number of unique credit card numbers used in this PNR
Number of unique phone numbers used in this PNR
Number of unique emails used in this PNR
It is obvious that purchase attempts have been made with more than one e-mail and phone number information in the same PNR of two different scenarios in
Table 3. In such cases, the transactional perspective proves ineffective in managing PNR transactions comprehensively, causing it to fail. Conversely, the profile-based approach excels at identifying fraudulent activities. The green regions indicate where the proposed perspective can successfully detect fraudulent transactions, while the red regions signify fraudulent transactions that remain undetected when using the transactional perspective. The fraud-detection system rejected the first attempts because the given e-mail or phone number information poses a high risk. However, the system made a wrong decision on the red attempt by accepting the transaction, and the fee was refunded due to the fraud report. When the transactions are examined visually, it is very clear that we are dealing with a fraudster trying to circumvent the system. Nevertheless, since there is no connection between these transactions in the transactional dataset, this suspicious activity cannot be detected. In order to prevent such vulnerabilities, a PNR profile was created and statistical information for all trials performed on the relevant PNR was added to the records. In this way, a record is made aware of all attempts in the PNR to which it belongs.
5.3. Record Profiling
In this profiling mechanism, new distinctive features are extracted from multiple columns placed only within the record itself. The following two features helped us to detect several suspicious activities during ticket sales.
In
Table 4 there are nine individual record profiling scenarios to represent how some risky patterns can be detected by making the date information and name/surname alignment information in the record meaningful. By comparing the cardholder and passenger information and calculating the time remaining until the flight, cases that go against the natural process can be detected. While colorless regions represent legitimate transactions, green regions represent fraudulent transactions that can be detected from the proposed perspective, and red regions represent fraudulent transactions that cannot be detected from the transactional perspective. In legitimate transactions, the submitted and temporal information seems proper. However, in fraudulent transactions, there are some inconsistencies and cases that may pose a risk in the record. First of all, the fraudulent transactions took place a short time before the flight. This event can be used as a fraud strategy so that there is no time left for manual examination of suspicious transactions. Moreover, in fraudulent transactions, the surname of the cardholder and any of the surnames of the passengers do not match. While this situation may occur naturally when a ticket is purchased for someone outside the family, it also occurs in every fraud attempt. Manual reviews can easily uncover these two suspicious cases. However, due to the dispersion of meaningful information across multiple areas, the system may struggle to detect them efficiently. Hence, within the record, the process of extracting meaningful information that is distributed across multiple fields and converting it into new fields was executed during the record profiling stage.
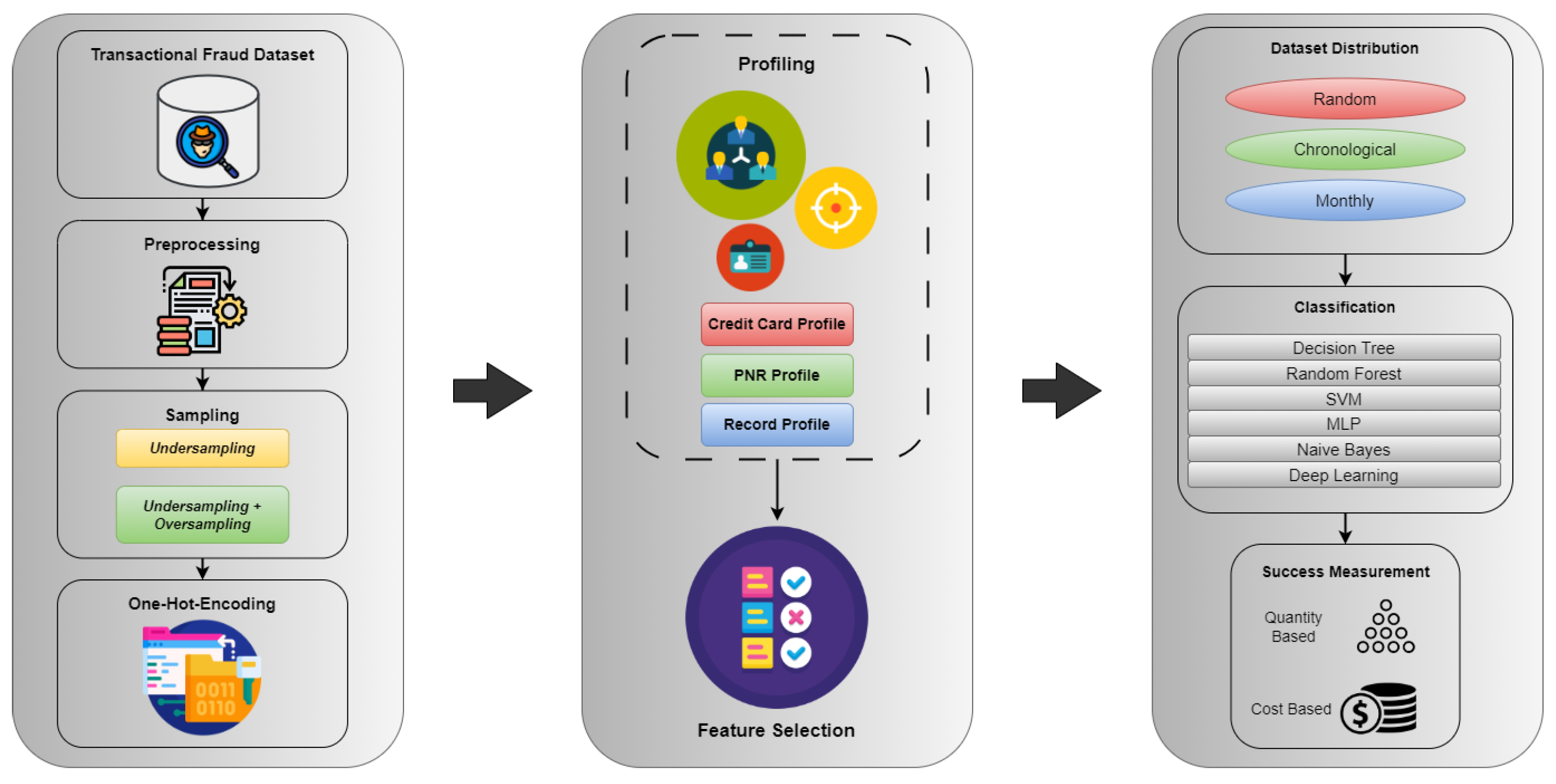
6. Methodology
The system architecture of the developed fraud detection system, created with a holistic view, is given in
Figure 1.
6.1. Data Pre-Processing
At this stage, various operations were applied to the raw data in a single chronologically ordered text file in order to eliminate the data fields with high numbers of missing values and to correct the data containing misleading values. In total, 4369 records and 32 data fields were removed from the dataset for the following reasons.
Non-standard and incorrect representations of date fields
Lines that have lost their structural feature and are corrupted
Data columns with a high rate of missing values
We also filled in the missing values in the categorical data fields that could be inferred according to some business logic. In this filling process, mapping methods were used based on similar records, and assumptions were made according to some aviation business processes. Other steps applied in the data pre-processing phase are given as follows:
Unexpected tokens in the records were corrected or removed from the dataset.
Data values of the same type were standardized to have the same representation.
Columns that have dirty data and are ineffective were removed from the dataset.
Type checking and correction were applied to numeric values.
Data fields with a high number of categories were excluded from the dataset.
Different currencies in the dataset were converted to US dollars.
Min–max normalization was applied to numerical fields.
After the cleaning operations, a dataset consisting of 37,299,328 transactions and 29 data fields with only one numerical field was obtained.
6.2. Sampling
Fraud datasets have a very low percentage of fraud records, causing a serious imbalance problem. The most-commonly used approach for solving this problem is to create a new dataset using sampling techniques on the existing dataset [
31]. Decreasing the number of majority records by randomly or smartly selecting them to some degree while all positive records are included in the new dataset is called undersampling. Similarly, the method of synthetically increasing the number of positive records in the dataset is called oversampling [
32]. However, while working on a very large dataset, as we used in our study, it may not be possible to directly apply the oversampling method. In such cases, hybrid approaches can be used where undersampling and then oversampling are utilized in a cascaded manner. Two different sampling methods were used in this study. The first one is the balanced random undersampling (BRUS) method, and the second one is the hybrid BRUS + oversampling method.
6.2.1. Balanced Random Undersampling (BRUS)
The balanced random undersampling method basically aims at increasing the fraud/legitimate ratio by making a choice between legitimate records. However, it is different from the random undersampling methods that are frequently used in the literature and library implementations. These qualities are as follows:
- ✓
It is guaranteed that the data to be selected from the majority class will be evenly distributed in the dataset
- ✓
Chronological order is guaranteed in the newly created dataset
- ✓
It is not possible to select some records more than once while there are records that have not been selected yet
In order to guarantee these principles and for the BRUS algorithm to work correctly, the dataset must be ordered according to the transaction times. First of all, by comparing the fraud/legal rate in the dataset and the rate desired to be reached, it is decided to what extent the legal records should be reduced. In order to make a balanced negative sample selection on the dataset, the dataset is divided into bins according to the ratio obtained in the previous step. A random negative sample is selected for each created bin, and the desired fraud/legal ratio is reached. Thus, highly representative records with a well-balanced spread over the dataset are selected, and duplication is prevented. Therefore, the conditional differences between different tests on the same dataset will be minimized. The fundamental steps of BRUS are presented in Algorithm 1.
| Algorithm 1 BRUS Algorithm |
| DETERMINATION OF BIN INTERVAL |
- 1:
- 2:
for each do - 3:
if then - 4:
- 5:
end if - 6:
- 7:
end for - 8:
- 9:
|
| |
| NEGATIVE SAMPLE SELECTION |
- 10:
- 11:
for each do - 12:
if then - 13:
- 14:
end if - 15:
if then - 16:
if then - 17:
- 18:
else - 19:
- 20:
end if - 21:
end if - 22:
- 23:
end for
|
Since the majority of negative records are not selected in undersampling methods, the continuity of interconnected records may be lost. In order to eliminate this problem, the entire dataset was profiled before sampling was applied. Thus, a dataset that is aware of previous related records, not only on a user basis but also on a credit card and PNR basis, has emerged. After the profiling stage, statistical information on past transactions is added to all transactions in the dataset. In this way, the records selected with the BRUS algorithm were connected with all unselected related records through profiles.
6.2.2. Oversampling
Oversampling is a sampling method that is generally used to prevent data loss in negative instances. There are several oversampling algorithms like random oversampling, SMOTE, and ADASYN. However, when an oversampling method is directly used on the dataset, the number of total instances will be higher than the original dataset. Because of this fact, a direct oversampling method was not chosen in our study, as we have a very large dataset.
6.2.3. Hybrid BRUS + Oversampling
In cases where the studied dataset contains a large number of records, applying oversampling methods directly may cause resource insufficiency or performance problems at other stages. In this case, the created model completely loses its applicability. In order to avoid this problem, first of all, by applying balanced random undersampling as developed in our study, the fraud/legal ratio was increased to 1:25 and 1:100, and then by applying various oversampling methods on these intermediate data sets, it was reduced to a fraud/legal ratio of 1:5, which we used as the base ratio in our study. The utilized methods for the oversampling phase in the hybrid sampling mechanism are as follows:
Random Oversampling: In this method, synthetic records are produced by randomly selecting and copying records from the minority class. It is important for the success of the detection system that the oversampling algorithm to be developed has a structure that can prevent unbalanced distribution and unbalanced selection.
SMOTE: This is a well-known algorithm that is used in many fraud-detection studies to solve the imbalanced dataset problem [
21,
54,
55]. Minority class records are selected to find k-nearest neighbors of these records. Afterward, a synthetic record is produced by selecting a point between the nearest neighbor and the selected record. Since this algorithm is not suitable for processing categorical data fields and there is a high number of categorical data fields in our data set, it has been observed that the success rates are generally very low.
SMOTENC: This is a variation of the SMOTE algorithm that can also handle categorical data fields [
56,
57]. With the application of this technique, it has been observed that the low success observed in SMOTE is prevented and it exhibits more balanced results compared to the random oversampling technique.
The sampling step was applied before the one-hot-encoding process in order to keep the processing times short and to reduce the resource consumption in SMOTE and SMOTENC algorithms. The dataset was made ready for the sampling step by applying only label encoding. The one-hot-encoding process was carried out in the next step.
6.3. Profiling
6.3.1. Profile-Based Transformation
In order to develop the profile-based fraud-detection system, the dataset should be converted into a profile-based form. Thus, the transactional records in the dataset will have historical information and will be aware of the previous linked records. The profile-based transformation module applied to the dataset was developed using the Java programming language. Since this profiling process must be performed in accordance with real-world scenarios, the dataset must be chronologically ordered. As mentioned in the Profile-based Fraud Detection section, since the credit card and PNR profiles are historical profiles, their conversion processes are carried out using maps containing statistical objects. There is a map for each profile and a statistical object for each unique profile value. The chronologically ordered dataset is scanned for each profile from the first record to the last record, and some basic steps are applied to each record. As a result of the completion of the scanning iteration, the relevant profile is created and added to the dataset. The core steps of profiling mechanism is presented in Algorithm 2.
| Algorithm 2 Profiling Algorithm |
- 1:
for each
do - 2:
- 3:
if then - 4:
- 5:
else - 6:
- 7:
end if - 8:
- 9:
- 10:
end for
|
When a scan iteration is completed on the dataset by applying these steps for each record, the targeted profile is created. As the newly generated fields are incorporated into the respective record during the scanning process, the dataset undergoes a transformation into a profiled dataset once the profiling scans are completed. After the whole profiling process is completed, the dataset is ready for the sampling step.
6.3.2. Profiling Modes
The principles that show how the designed profiles are used in our study can be called profiling modes. By using the existing transactional dataset and new data fields added to the profiles, new datasets in different combinations were created. Our fundamental tests were carried out with these datasets and the efficient profiling modes were determined. The performance analysis was conducted on the following profiling modes:
- 1.
Credit Card Profiling Mode: Transactional Dataset + Credit Card Profile
- 2.
PNR Profiling Mode: Transactional Dataset + PNR Profile
- 3.
Record Profiling Mode: Transactional Dataset + Record Profile
- 4.
Only Profiling Mode: All Profiles without Transactional Dataset
- 5.
Multi-Modal Profiling: Transactional Dataset + All Profiles
6.4. One-Hot Encoding
Categorical fields are not directly utilizable for machine learning algorithms and deep neural networks (DNN). Although it is ready to be processed structurally when numbers are given to each category by applying the label-encoding technique, there will be still a semantic inconsistency in the label values. At this point, the one-hot-encoding method in which a binary data field is produced for each category can be used. Thus, a direct connection between the categories and the class can be established. By applying the one-hot-encoding process to 28 categorical fields in the dataset, 1524 binary features were obtained. With the feature-selection stage to be applied to quite a lot of binary fields, the most distinctive categories in all encoded data fields were selected.
6.5. Feature Selection
In order to determine discriminative features and minimize the processing time, we applied feature-selection algorithms to the available dataset. In our study, feature selection was performed with 3 different techniques, including CHI2, PCA, and AutoEncoder, on 1524 transactional binary features, 1 numerical transactional feature, and 21 additional numerical profiled features. Since the desired success scores could not be reached with the number of features above 100, higher-resolution tests were carried out under the number of 100 features. As a result of these tests, it was observed that the most successful results were obtained in the tests performed with the feature numbers between 20–75. Afterwards, the following feature-selection techniques were applied in this range as a standard. Also, some lower and higher features are included in our experiments so that we can control how the results change outside this range.
6.6. Classification
In the classification phase of our fraud-detection system for aviation, five state-of-the-art machine learning algorithms and DNN were exploited. These below-given machine learning algorithms were chosen among the methods that are frequently used and compared in fraud-detection studies in the literature [
8,
58,
59,
60,
61,
62].
Decision Tree
Random Forest
Support Vector Machines
Multilayer Perceptron
Naive Bayes
In addition to the mentioned machine learning algorithms, some experiments were also carried out using deep neural networks. We also conducted several experiments to find the best hyperparameters, including the number of hidden layers, neuron formation, epoch number, batch size, learning rate, and dropout parameters, in order to fine-tune the fraud-detection system based on the aviation domain. The initial parameters were chosen regarding the study [
4], which aimed at detecting credit card fraud.
6.7. Cost-Based Measurement
From the point of view of companies, since fraud is mostly a financial problem, the success criteria based on the number of transactions may not always be consistent. When the developed fraud-detection systems are analyzed according to the number of correctly detected transactions, they may seem successful, but the financial loss faced by the company might be much greater. In many fraud-detection studies in the literature, success is calculated based on only the number of transactions, and the monetary costs of the transactions are ignored [
63,
64,
65]. Therefore, in this study, besides the success criteria based on the number of transactions, cost-based success criteria were also utilized. Accuracy, precision, recall, and most importantly F1 score metrics, which are widely used in fraud detection, are calculated on a cost basis. The cost-based metrics we propose in this study are named C-Accuracy, C-Precision, C-Recall, and C-F1 Score.
While calculating these proposed metrics, first of all, the transaction amounts were standardized by converting them according to currency conversion rates. Afterward, min–max normalization was applied to the amount column within the 0–1 interval. Finally, while creating the cost-based confusion matrix, each transaction was weighted with its c-score and added to the matrix. All metrics calculated using a cost-based confusion matrix have become cost-sensitive. In order to create a cost-sensitive confusion matrix, the operations for calculating the c-score are given in Equation (
1).
7. Experimental Results
In this section, we first give the details of our experimental dataset. We then share the initial results of state-of-the-art learning algorithms and demonstrate the performance contribution of feature selection and sampling techniques to transactional information in terms of quantity and cost. Afterward, we elaborate on the success of the introduced profiling mechanism. Finally, we give the test results of DNN using the combination of hyperparameters in order to demonstrate the performance improvement of the proposed system. All the experiments are carried out to measure the state-of-the-art performance metrics, including accuracy, precision, recall, and F1 score. However, we mostly benefit from the F1 score, since it is the fairest metric for imbalanced dataset problems. The dataset configurations of these experiments are given in
Table 5.
Since the fraud-detection problem is an imbalanced dataset problem, the accuracy metric can be misleading for measuring real success. Such datasets contain a very high number of negative (legal) samples. Thus, the developed detection systems may tend to make negative decisions in all transactions. In this case, the accuracy results will be observed to be very high, but will not reflect the truth. Therefore, precision and recall results should be evaluated together instead of accuracy in fraud-detection studies. To balance their impact, the F1 score obtained by calculating precision and recall metrics together is utilized as the primary metric for such problems. On the other hand, the precision metric gives us information about the rate at which ordinary passengers are wrongly blocked, whereas the recall metric shows how much of the fraudulent transactions are caught. The F1 score value represents how successful the fraud detection and false alarm prevention function is in a holistic manner. For all these reasons, the basic success criterion in this study was the F1 score.
7.1. Performance Improvements on Transactional Dataset
In our previous work [
5], some tests and improvements were carried out in order to achieve maximum success on the transactional dataset. During these tests, several feature-selection mechanisms, measurement metrics, and train/test set organization methods were explored in order to improve fraud-detection performance for aviation. In this study, oversampling techniques and deep learning approaches were analyzed on the airline ticket sale dataset and the results are presented in this subsection. It has been observed that there are important limitations to increasing the success of a transaction-based fraud-detection system in order to prevent financial loss for airline companies and fulfill the sales experience of airline customers. Despite all the improvement and optimization efforts, the precision, recall, and especially the F1 score metrics could not reach acceptable levels either on the number of transactions or on the cost basis.
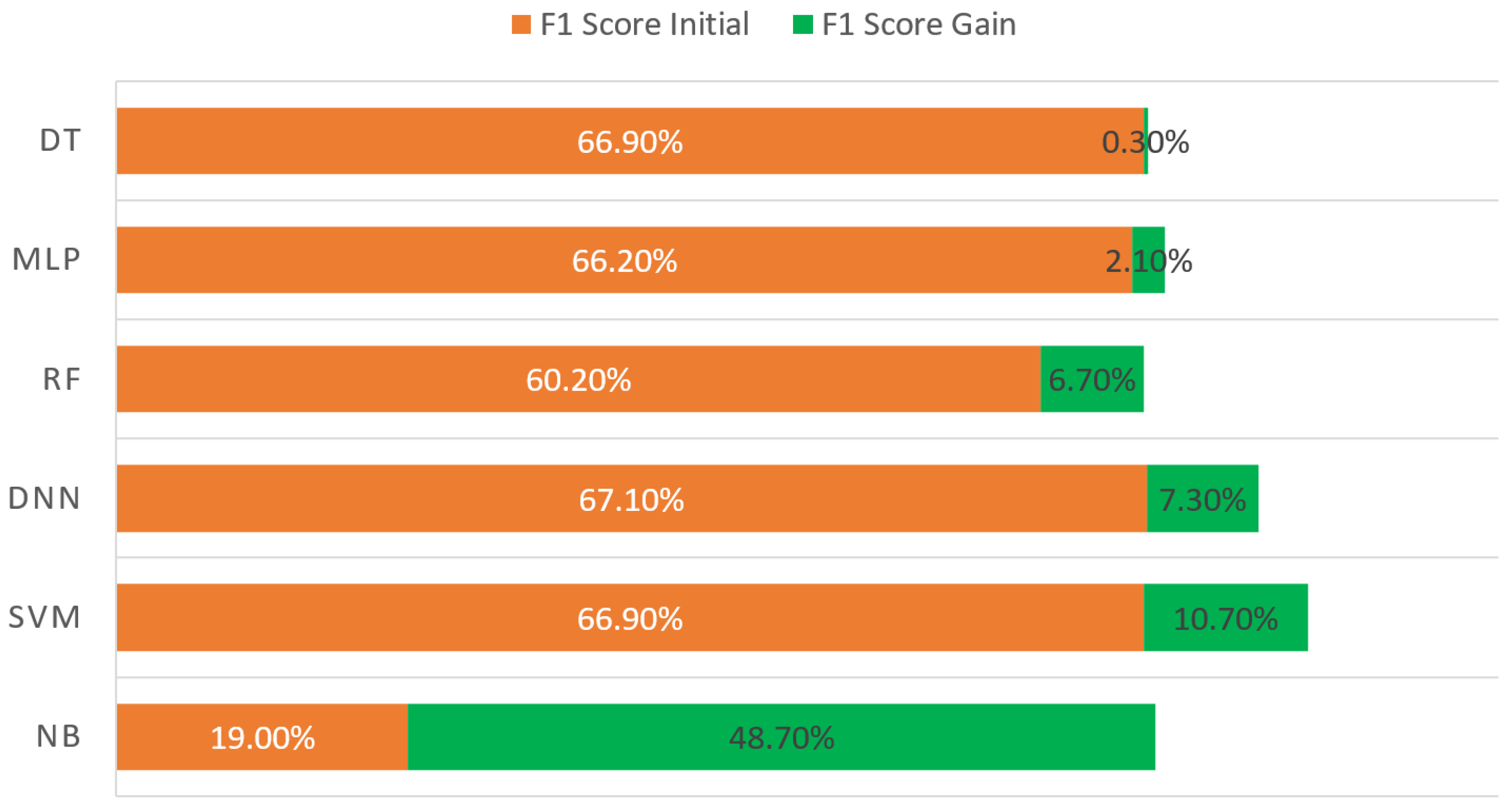
The success rates after the feature-selection process is applied are given in
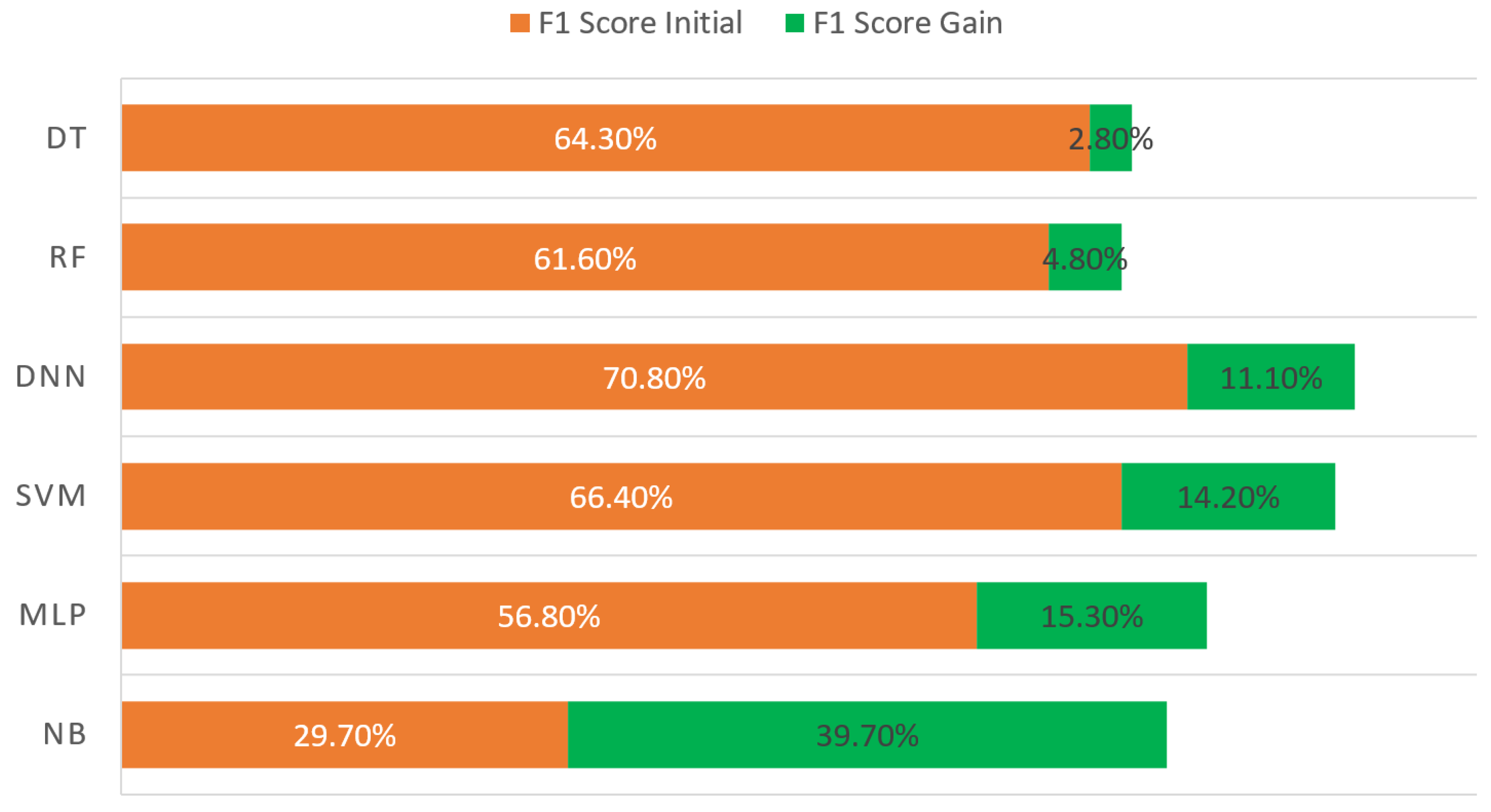
Figure 2. In addition, the newly proposed cost-based measurement metric results are presented in
Figure 3. The first test results using shallow and deep learning algorithms after performing only the necessary cleaning operations on the dataset are given as initial results in these figures. Examining these figures shows us that no significant change was attained for the decision tree algorithm after the feature selection was applied, whereas the naive Bayes algorithm performs greatly after feature selection. The primary cause of the unexpectedly poor performance observed prior to the pre-processing step is the correlation between the provided features. The performance of this basic algorithm was significantly improved by both the feature-selection process and the inclusion of engineered features. Apart from the DT algorithm, we observed a noticeable increase between 2.1% and 48.7% in terms of the quantity-based F1 score. The cost-based evaluation shows that the quantity–cost success balance is preserved and the most successful algorithm is SVM. Based on all these observations, it can be understood that the feature-selection process makes a substantial contribution to the fraud-detection problem in the aviation domain. Even the poor success results obtained via the naive Bayes algorithm increased after feature selection was applied and came to the same success level with other algorithms. In order to observe the effect of the feature-selection process, some tests have been carried out using the CHI
2 and PCA algorithms. The most successful classification algorithm was SVM, whereas the most successful feature-selection method was CHI
2. The number of features that gave the highest success results on average for all algorithms was 55. Also, a significant increase of up to 48.7% was observed in the naive Bayes test results. The details of the test results are given in our previous study [
5].
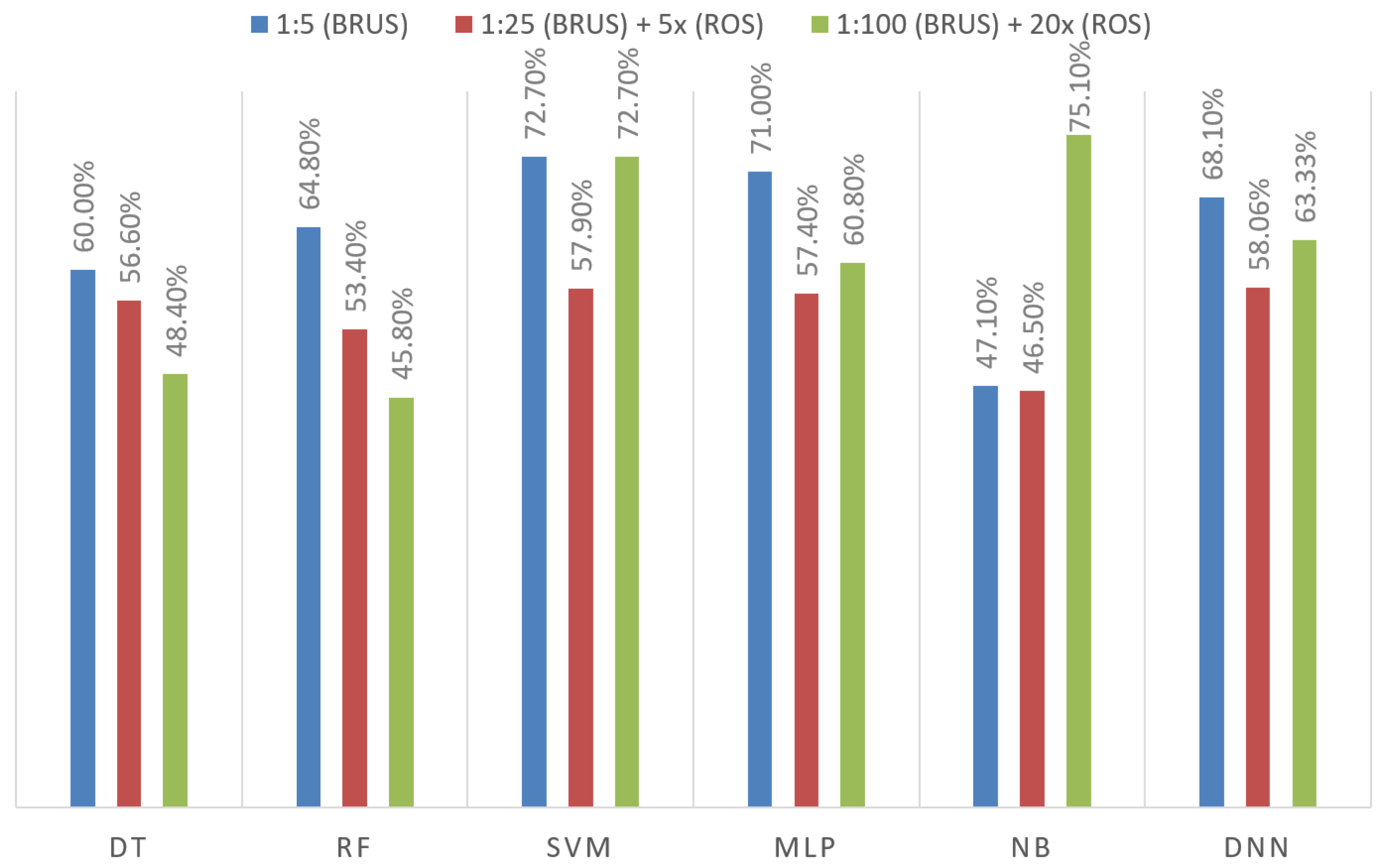
Sampling is a crucial technique for improving the success of solving imbalanced dataset problems. In our previous sampling tests [
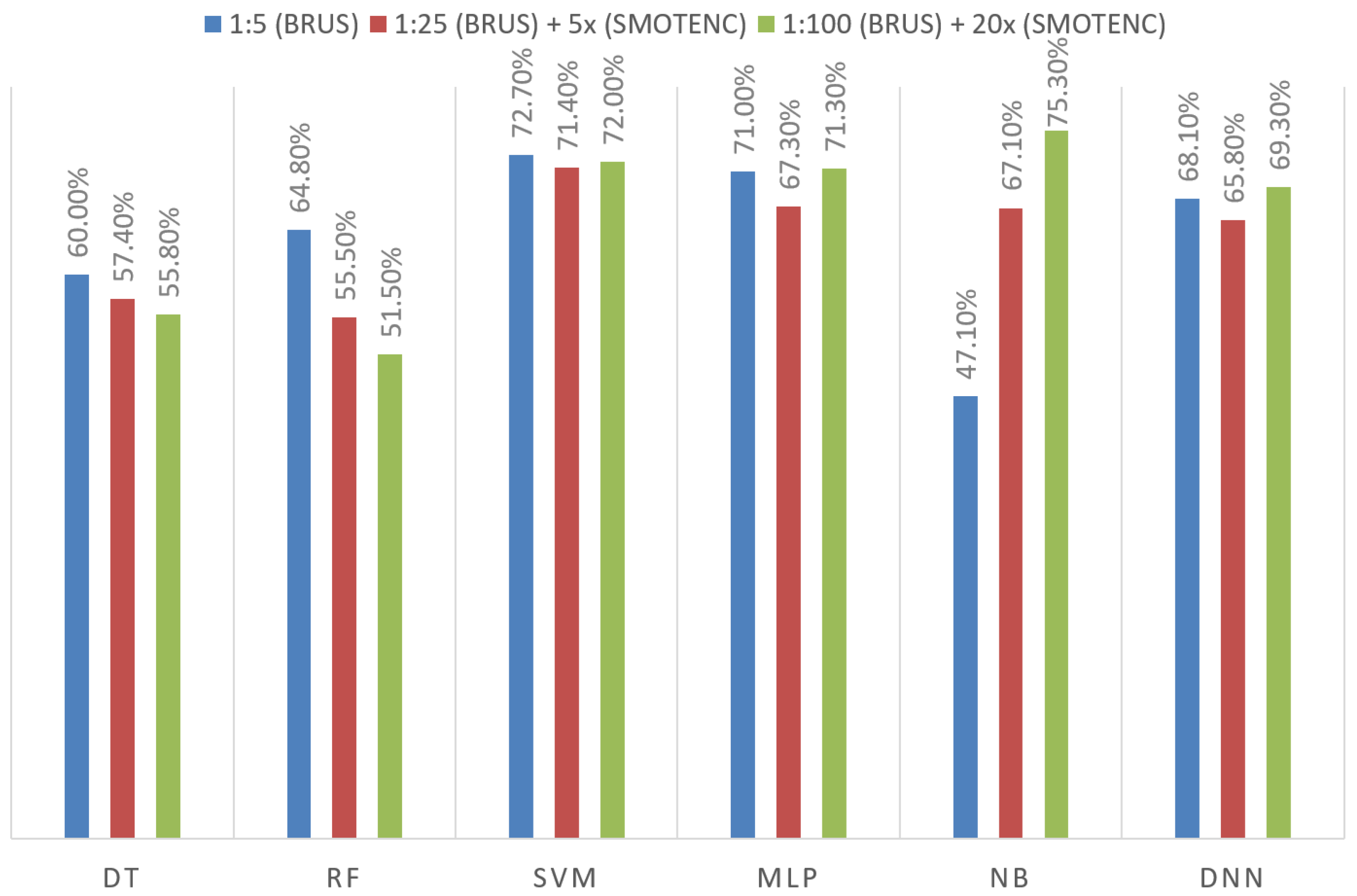
5], we applied only the random undersampling method and we picked a 1:5 fraud/legal ratio as the most successful configuration regarding the test results. The outcomes of the hybrid oversampling methods we implemented to address the issue of imbalanced datasets, along with their comparison to the BRUS algorithm proposed in our study based on F1 score, are presented in
Figure 4 and
Figure 5. Oversampling algorithms were applied in a hybrid manner together with the BRUS algorithm. First, very low success results were obtained since the SMOTE algorithm is not suitable for handling categorical fields. Therefore, the SMOTE algorithm was excluded and its results are not included in this section. Comparing the SMOTENC and Random Oversampling algorithms showed that SMOTENC has a higher success rate of 20.6% and 10.5% for the naive Bayes algorithm and MLP algorithm, respectively. However, in general, oversampling, which is a more costly sampling method, did not show a significant increase compared to the BRUS algorithm. Therefore, in the next stages of our study, we continued with the BRUS algorithm.
To summarize, SVM outperforms other algorithms in terms of quantity-based evaluation, whereas DNN achieved great success against financial loss. On the other hand, we observed that the limit for transaction-based fraud detection in aviation stands at 80% in terms of F1 score for both quantity-based and cost-based measurement.
7.2. Profile-Based Fraud Detection Results
To circumvent the limitations imposed by the transactional dataset and uncover historical patterns of passenger activity related to past transactions, a profile-based fraud-detection approach was introduced. This approach indirectly enhances the overall success of fraud detection. In this subsection, we demonstrate the test results of the proposed profiles for aviation and their contribution to the available transactional point of view.
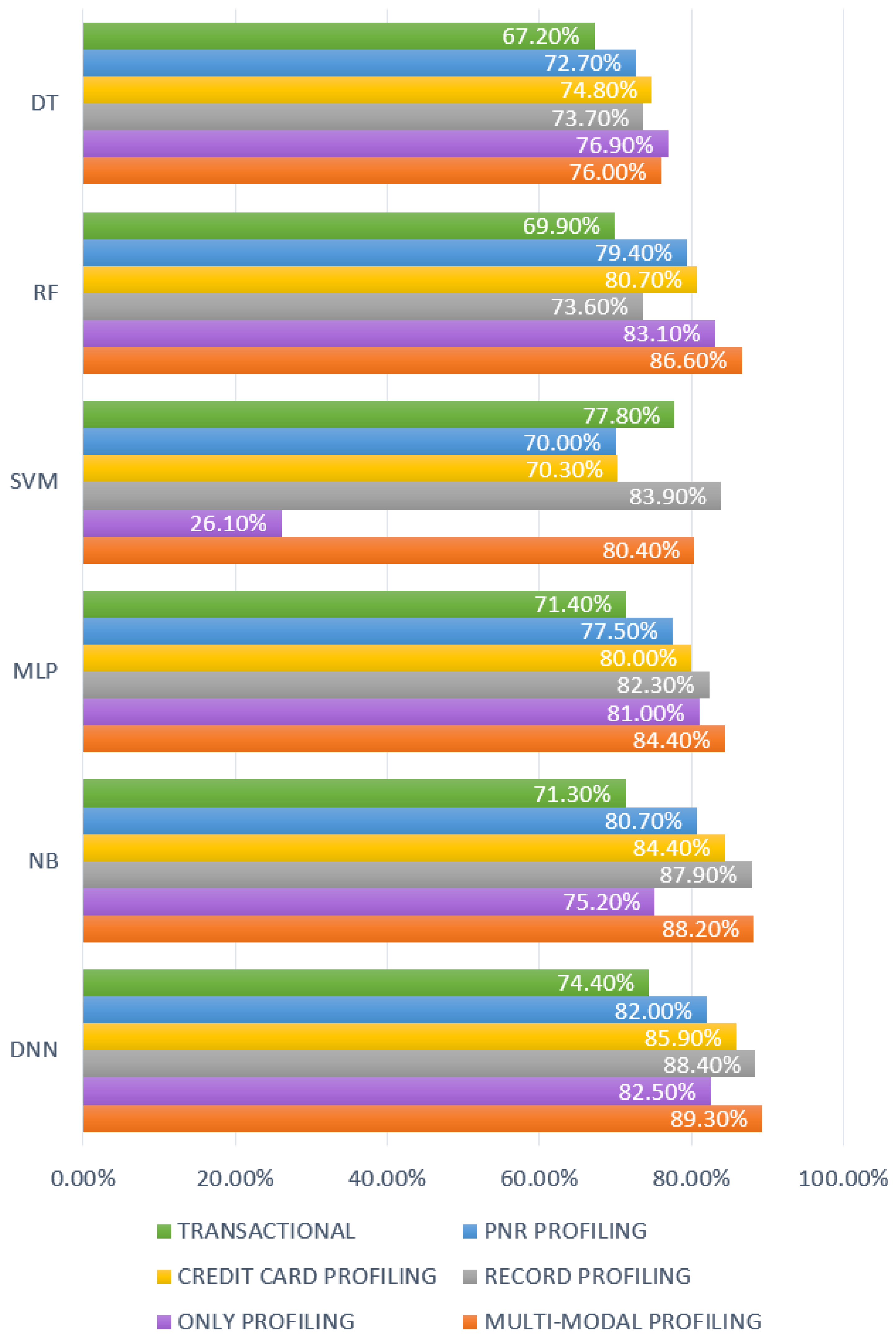
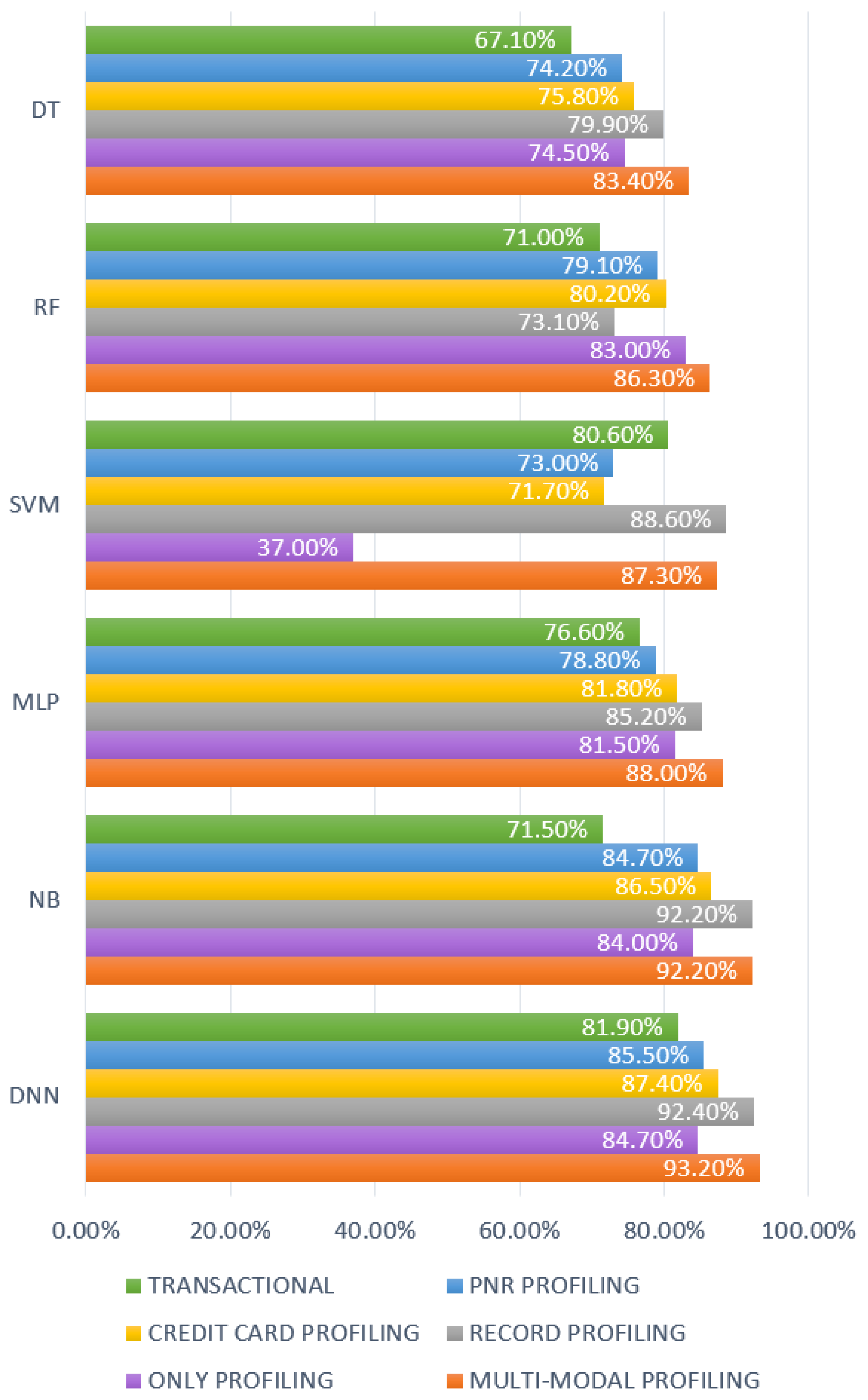
Figure 6 and
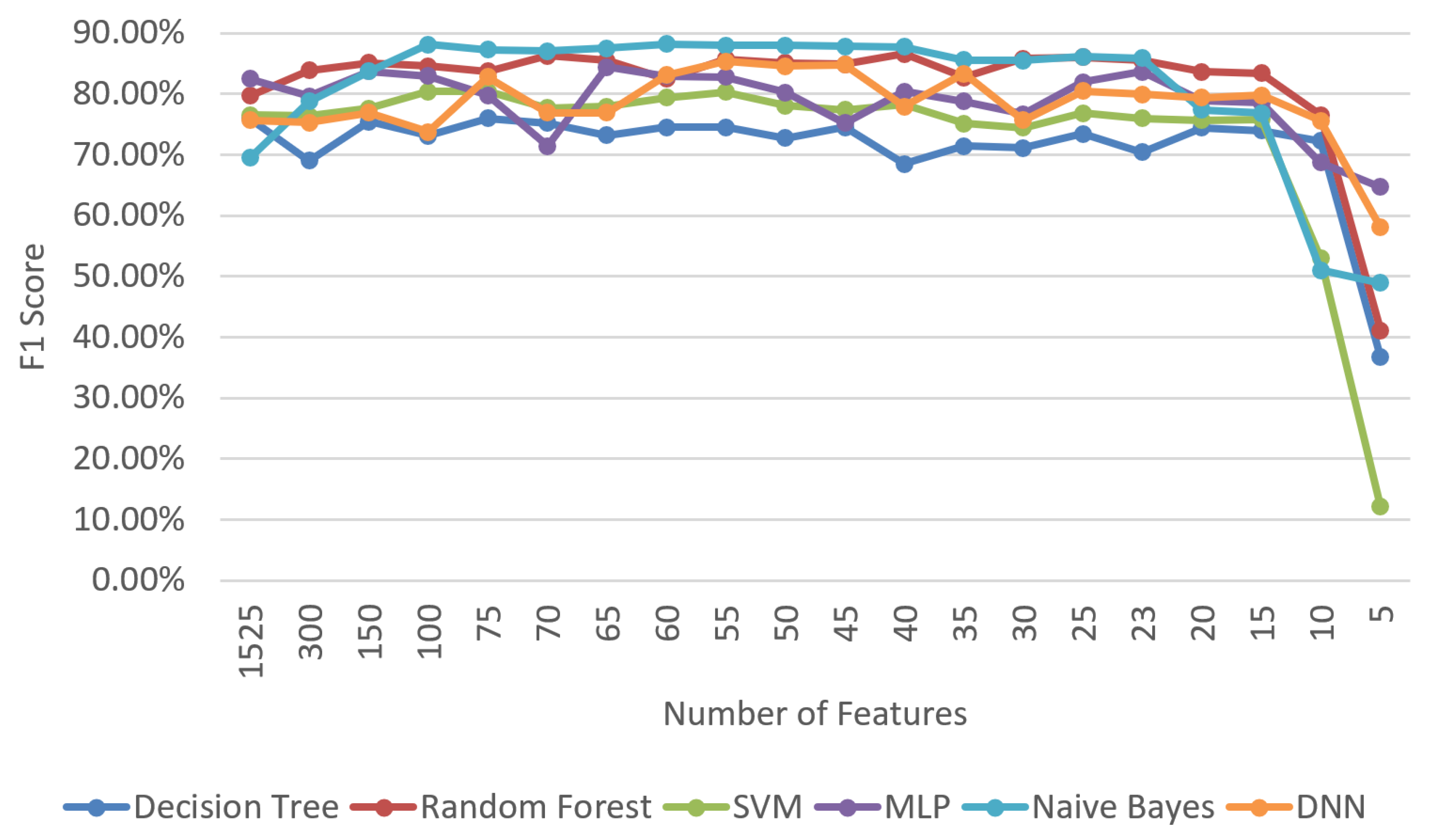
Figure 7 show us that multi-modal profiling has come to the fore as the most successful profiling mode in general. In our study, the highest F1 score success in the transactional fraud-detection system was measured with the SVM algorithm at 77.8% on a quantity basis and with the DNN at 81.9% on a cost basis. However, the naive Bayes algorithm, utilizing multi-modal profiling, achieved a success of 88.2% and 92.2% on quantity basis and cost basis, respectively. A 7- to 17-point increase in the F1 score for the available algorithms encouraged us to introduce this profiling mechanism to the literature. Each profile contributed to this escalation, but both credit card profiling and record profiling made a big difference. On the other hand, we also observed that leaving transactional information out is not an option for a successful fraud-detection system, and utilizing only profiled information falls behind the multi-modal profiling mechanism. After we determined the multi-modal profiling as the most successful one in terms of both quantity and cost basis, comprehensive tests were performed using the multi-modal profiling mode.
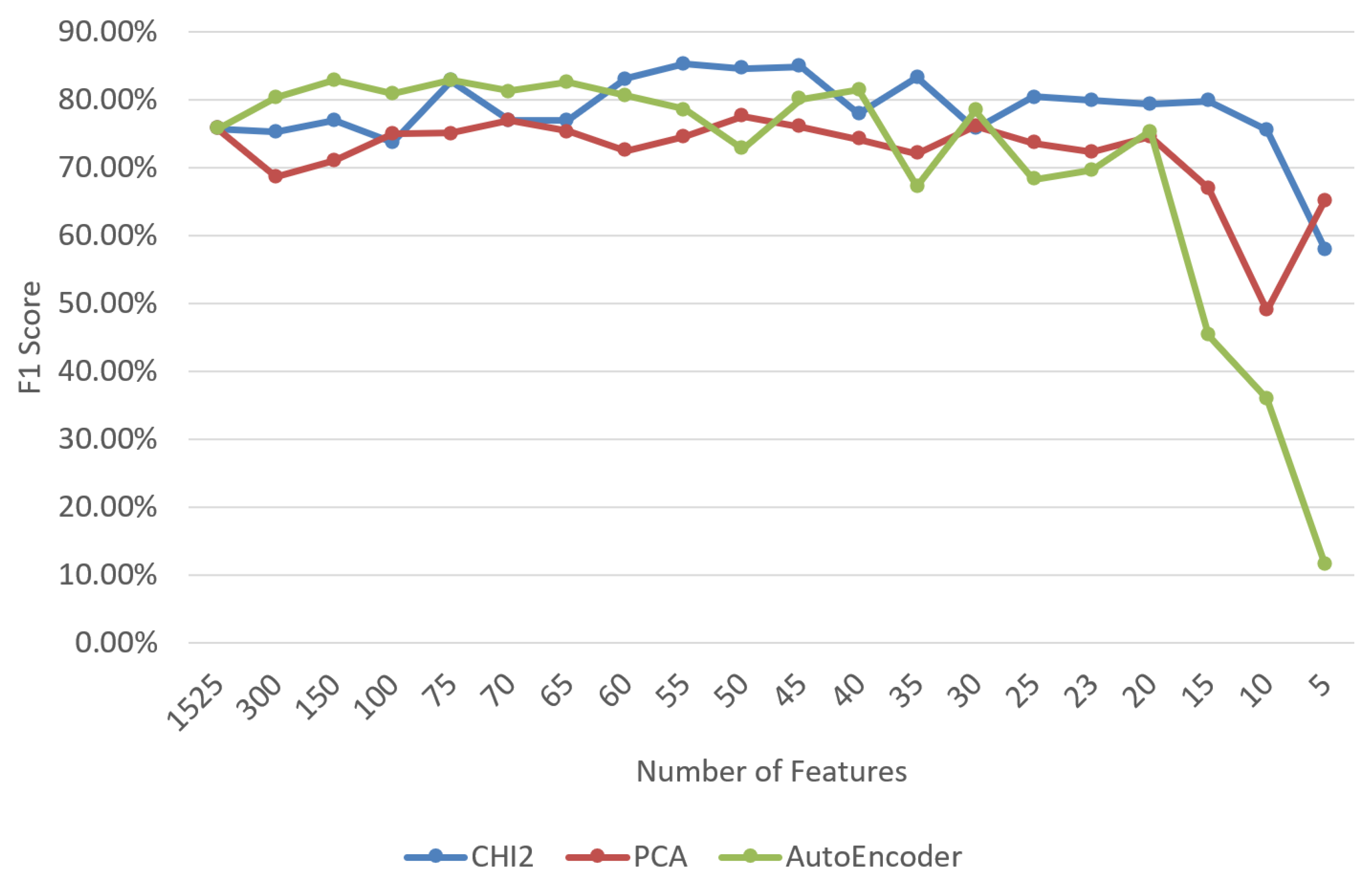
Since new additional features are gathered from introduced profiles, we reran the feature-selection tests by also including Autoencoder due to its harmony with DNN. Contrary to our expectation,
Figure 8 demonstrates that the CHI
2 algorithm is still leading and a 2.4% higher success rate was obtained compared to AutoEncoder and a 7.7% higher than PCA. Thus, CHI
2 was chosen for the feature-selection algorithm to be applied in the DNN tuning tests to be carried out in the next stage. We then conducted experiments for the new feature set obtained from both transactions and profiles, as given in
Figure 9. The most successful algorithm then becomes naive Bayes, with an F1 score of 88.2%, whereas random forest, DNN, and MLP achieved a success rate of 86.6%, 85.3%, and 84.4%, respectively. The promising results of DNN encouraged us to examine the hyperparameters and improve the initial results. For this purpose, an experimental set was created and all tests in this experimental set were performed. Details of this experimental set and comprehensive results including accuracy, precision, and recall are given in
Appendix A. The highest F1 score values were obtained in Experiment 45 on the basis of both quantity and cost. Quantity-based success and cost-based success reached 89.3% and 93.2%, respectively, and DNN takes the first place among others with the help of multi-modal profiling and hyperparameter adjustment. Analyzing the results thoroughly showed us that the network architecture and learning rate made the maximum contribution. It is also important to note that fine-tuning the hyperparameters is the essential step for such systems.
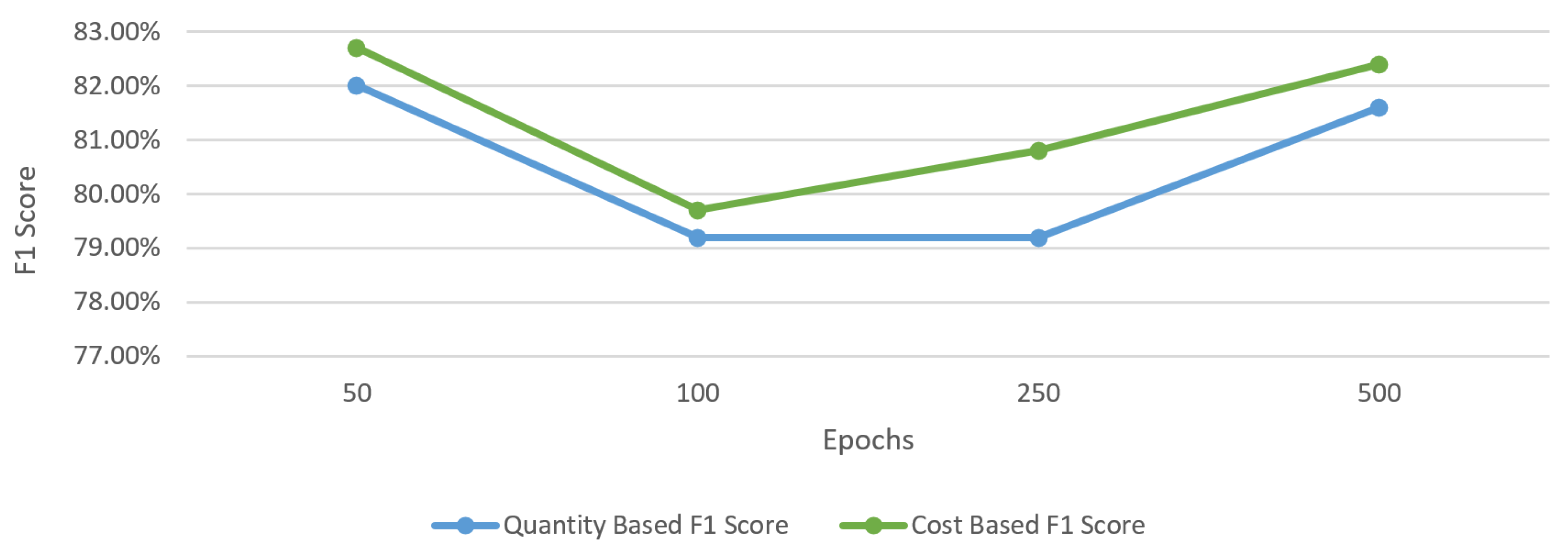
In the tuning tests, we tried to determine the effect of the calibration of the hyperparameters on the system success. For this purpose, only one hyperparameter was changed each time, keeping all other test parameters constant, and the results were examined. As a result of this examination, we observed whether hyperparameters and architectural features have a direct impact on the result. In
Figure 10, the number of epochs was changed between 50 and 500, and the relevant test results were examined. However, it was observed that only the change in the epochs did not have a direct effect on the success. According to the learning rate value, more successful results can be obtained at different epoch numbers.
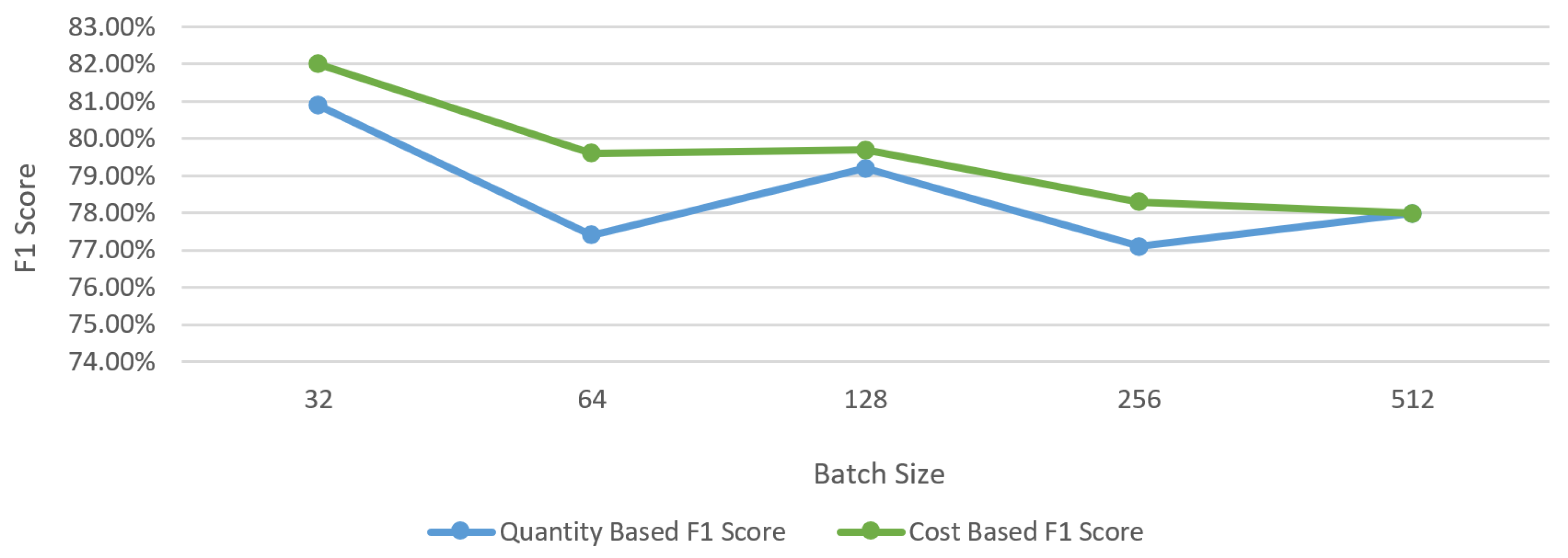
In batch size calibration tests, the results were examined by increasing the batch size by 2× between 32 and 512 each time. As can be seen in
Figure 11, although there are some fluctuations, in general, the F1 score decreased by 2.9% on a quantity basis and 4% on a cost basis as a result of increasing the batch size. This calibration test set shows that higher success can be achieved with a lower batch size. However, it is important to achieve an optimum balance between batch size and training time in order to keep the training cost at an acceptable level.
Although the effect of the learning rate hyperparameter on the result depends on parameters such as the batch size and epoch number, some calibration tests were carried out by keeping other variables constant. The results of these calibration tests are presented in
Figure 12. As the learning rate decreased from 0.01 to 0.00001, the F1 score increased by 5.4% on a quantity basis and 8.8% on a cost basis. These results show that complex and detailed patterns are of great importance in the field of fraud detection for aviation.
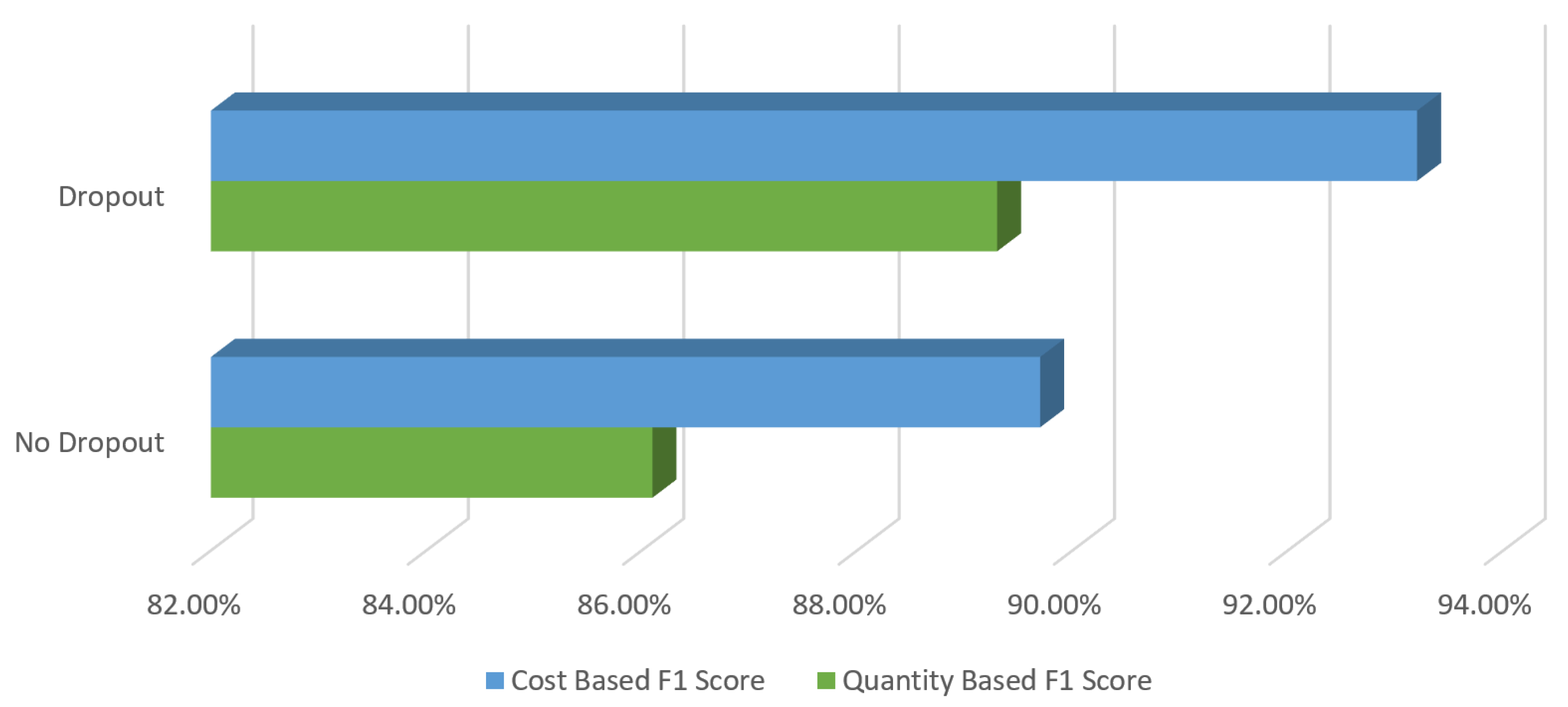
In the DNN created in our study, we aimed to observe the success of dropout on hidden layers. Therefore, the best results between the tests with and without dropout are compared in
Figure 13. As a result of this comparison, it was seen that the application of dropout on the DNN in our fraud-detection system has a positive effect on success. There was an F1 score increase of 3.2% on the basis of quantity and 3.5% on the basis of cost.
Different DNN-layer formations are used in the calibration tests to observe the impact of DNN formation on the detection success. The results of these tests are given in increasing order according to the quantity-based F1 scores in
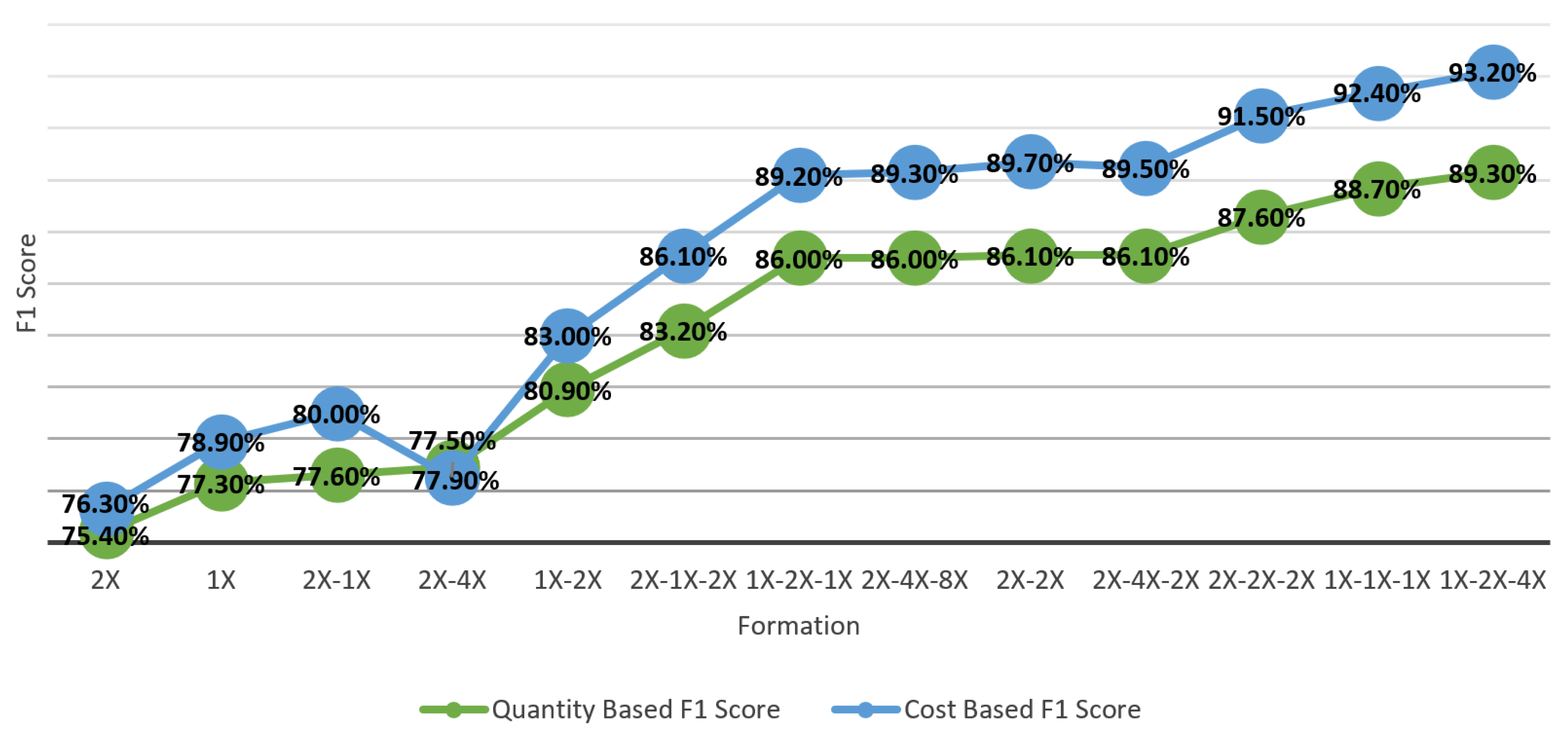
Figure 14. The results clearly indicate that higher success rates are achieved in deep neural network (DNN) structures with more hidden layers. Upon examining the neuron configurations in these hidden layers, it becomes evident that success rates are higher when there is an increase in or a consistent number of neurons during layer transitions compared to other neuron formations.
As a result of the hyperparameter tuning tests, it was observed that the success rate could increase by 14.6% on the basis of the F1 score.
Figure 15, where the test results are ordered from lowest to highest, shows us that a tuning stage performed on DNN has a critical importance for the fraud-detection system developed.
All the test results proved that the profile-based fraud-detection system performs significantly higher than the transaction-based fraud-detection system, as given in
Table 6. The profile-based detection systems achieved approx. 90% and higher F1 scores for both quantity-based and cost-based measurements. The highest gain emerged via deep neural networks after the adjustment of hyperparameters. After deploying DNN with new hyperparameters, 18% and 21.7% improvements were observed on a quantity basis and on a cost basis, respectively.
8. Conclusions
Airline companies have considerably suffered from fraudulent activities in the last decade. Although many studies have aimed at detecting fraud operations, especially credit card fraud in the banking sector, to the best of our knowledge, this study is the initial and comprehensive one for fraudulent activities in aviation. We first gave a baseline for the success rate of the available state-of-the-art learning techniques. Then, several pre-processing techniques were applied to transactional airline sales data to improve the success, and the limit of transactional information for detecting suspicious airline ticket activities was determined. The necessity to benefit from the historical background of a passenger redirects us to creating profiles based on credit card, PNR, and record activities. Following this idea and combining this profiling mechanism with a deep learning approach enabled the proposed fraud system to achieve up to a 33.1% performance improvement in terms of F1 score, whereas we are able to decrease the financial loss by up to 31.6%. Although many fields in the transactional dataset contribute to the success, one of the indispensable fields for the cost-sensitive measurement and multi-modal profiling mechanisms developed in our study is the amount field. Thanks to the amount field, the cost-based success can be calculated and many statistical profile fields can be created. Our analysis showed that engineered features such as the number of chargebacks, e-mail addresses, phone numbers, and domestic and international flights are the prominent ones obtained from the credit card and PNR profiles. Additionally, we observed that information about minutes to flight time and the match status of passenger surname and cardholder surname revealed from record profiles are the salient features for detecting fraud transactions in aviation. We also remarked that fine-tuning the architecture of DNN regarding the aviation data could make a great difference of 14.6% in terms of the F1 score compared to randomly chosen hyperparameters or those taken from available studies about the banking sector. In the future, we are planning to utilize loss functions compatible with imbalanced data and/or to design a new one considering the cost-based gain. On the other hand, the proposed multi-modal profiling mechanism can also be applied to other sectors such as e-commerce and insurance where the data diversity is high. Only in sectors whose data structure is not suitable for multiple profiles, such as banking, a single-modal profiling mechanism based on credit card activities will need to be established instead of multi-modal.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














