

Multi-Defect Detection Network for High-Voltage Insulators Based on Adaptive Multi-Attention Fusion


Abstract
:1. Introduction
2. YOLOv5 Target Detection Network
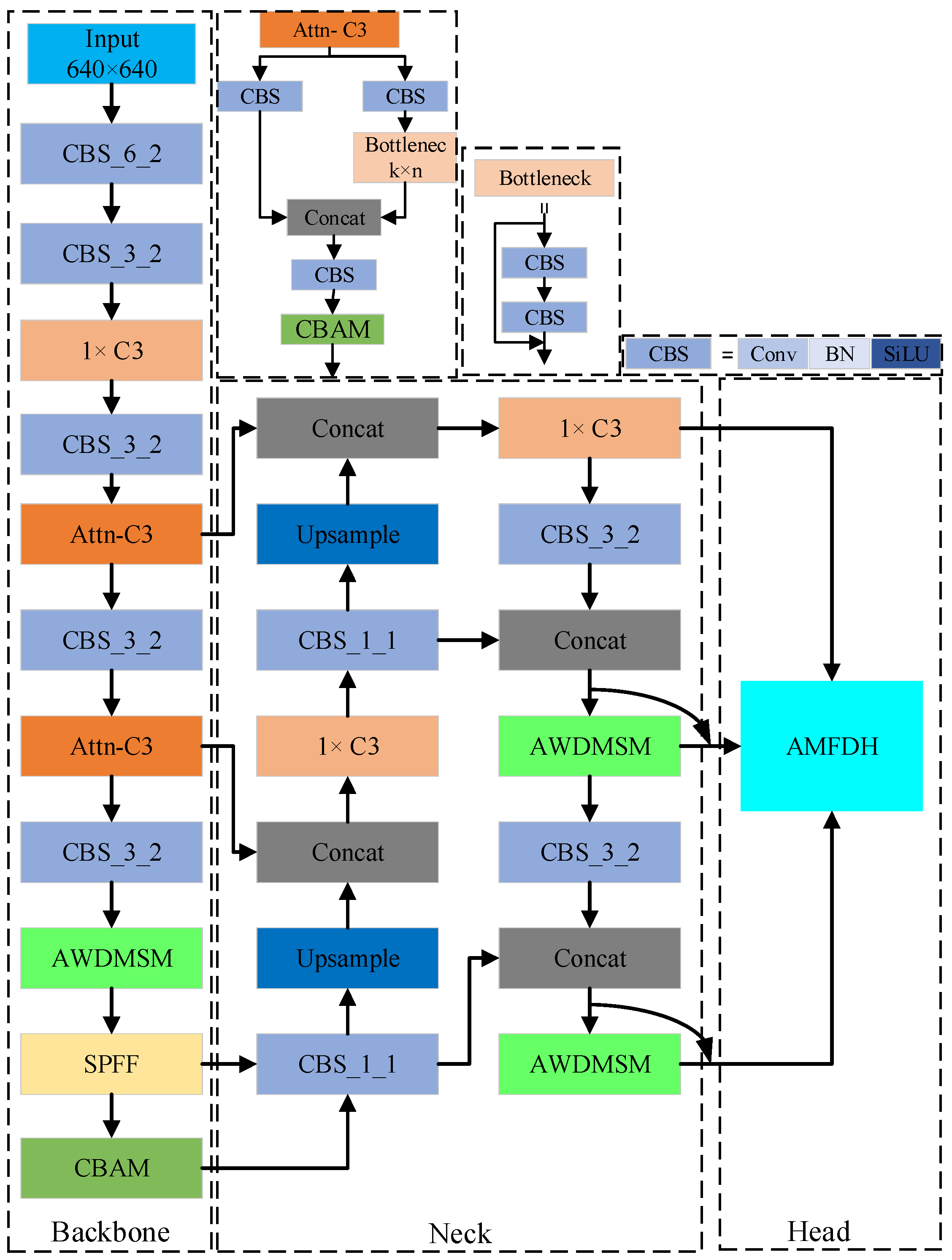
3. AC-YOLO Target Detection Network
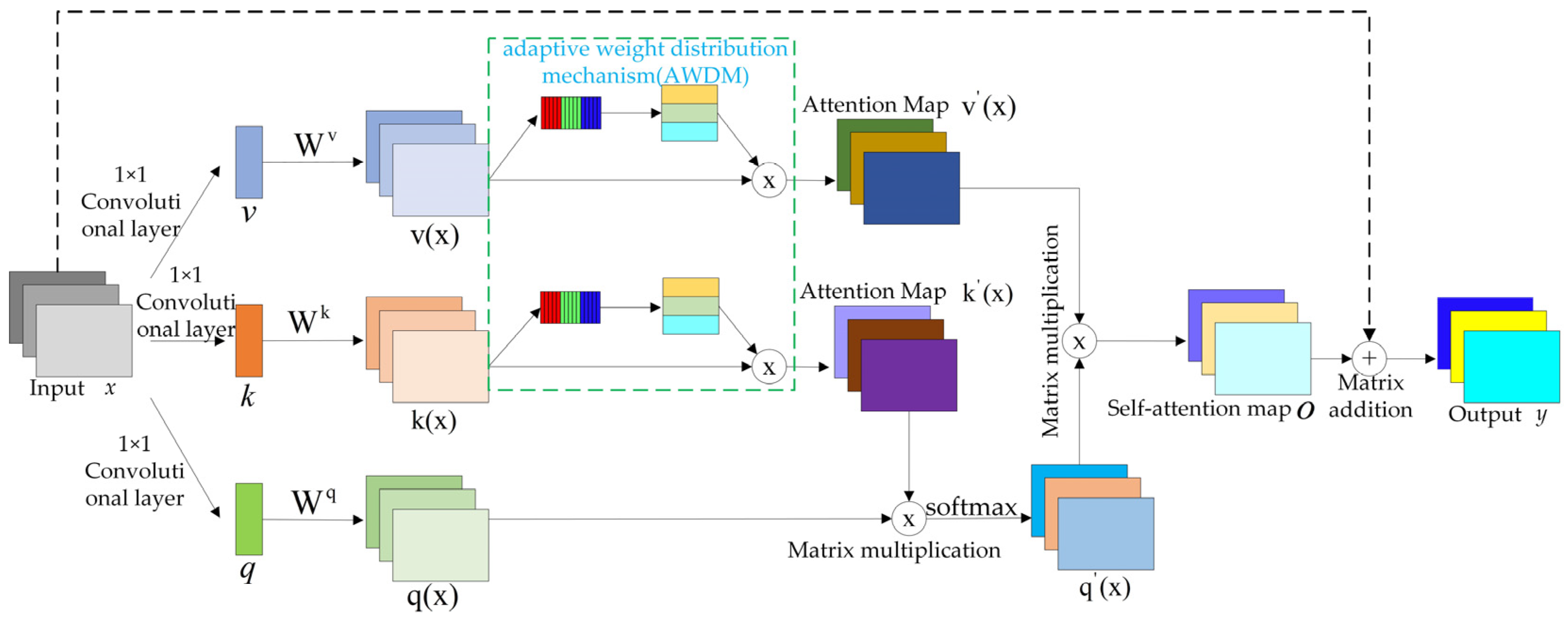
3.1. Adaptive Weight Distribution Multi-Head Self-Attention Module
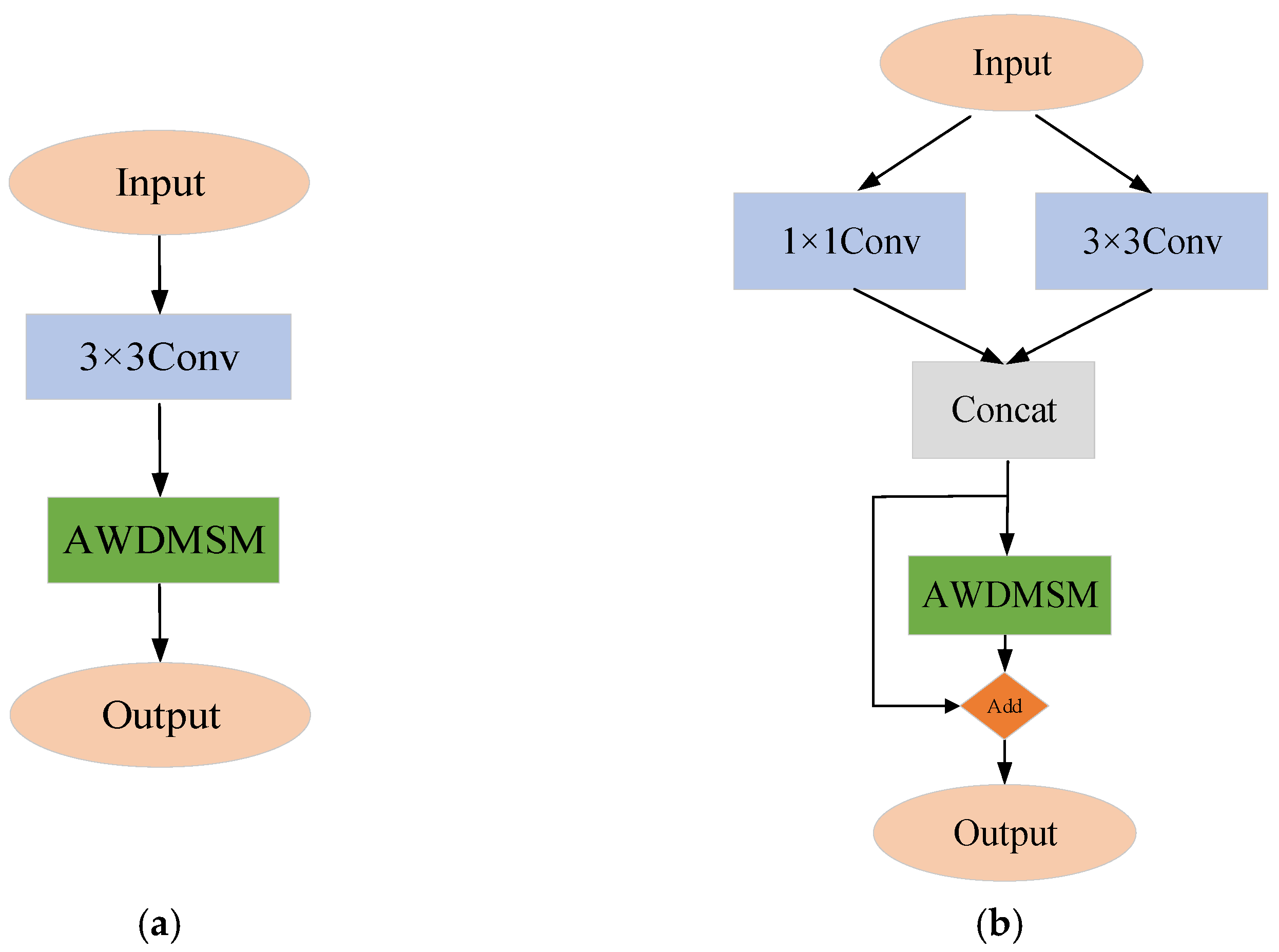
3.2. Embedded AWDMSM Module
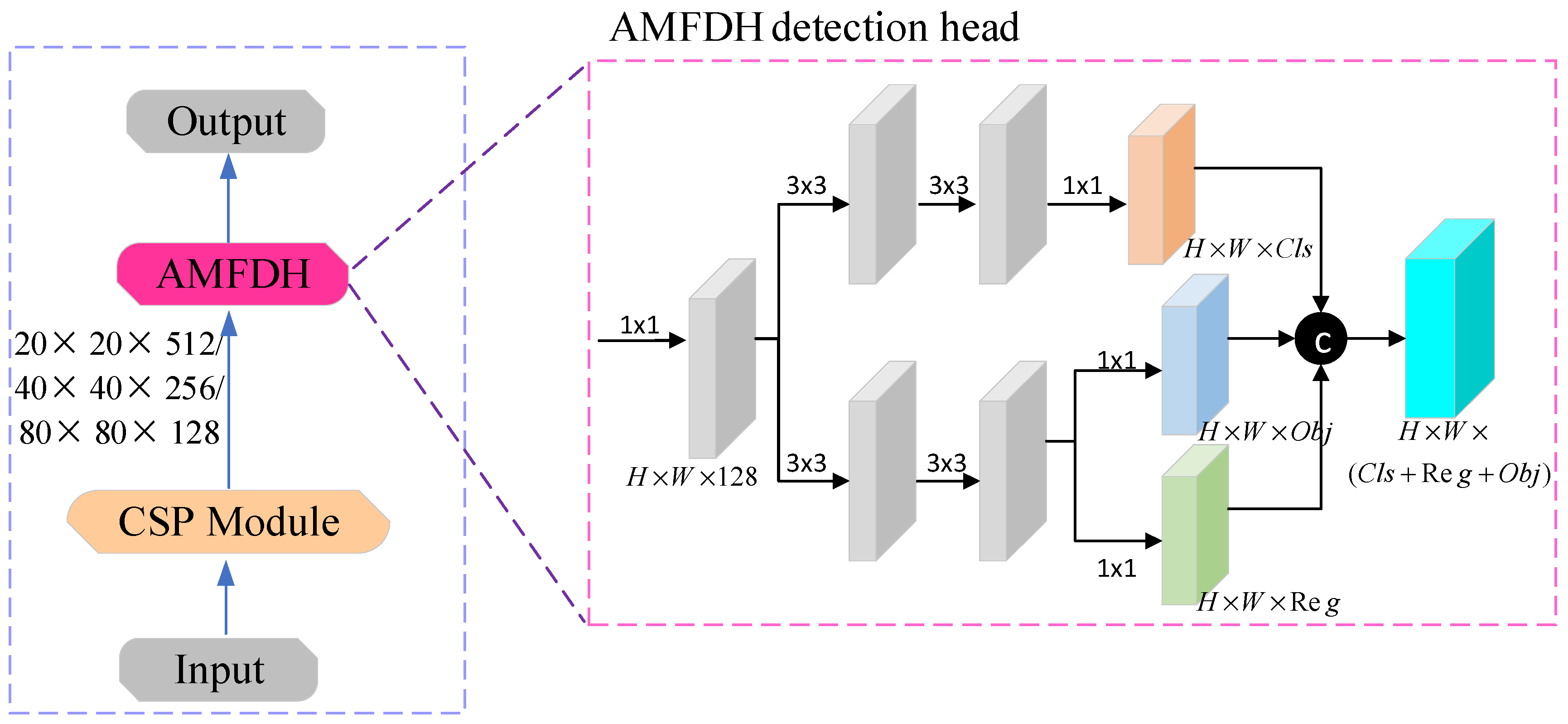
3.3. Adaptive Memory Fusion Detection Head
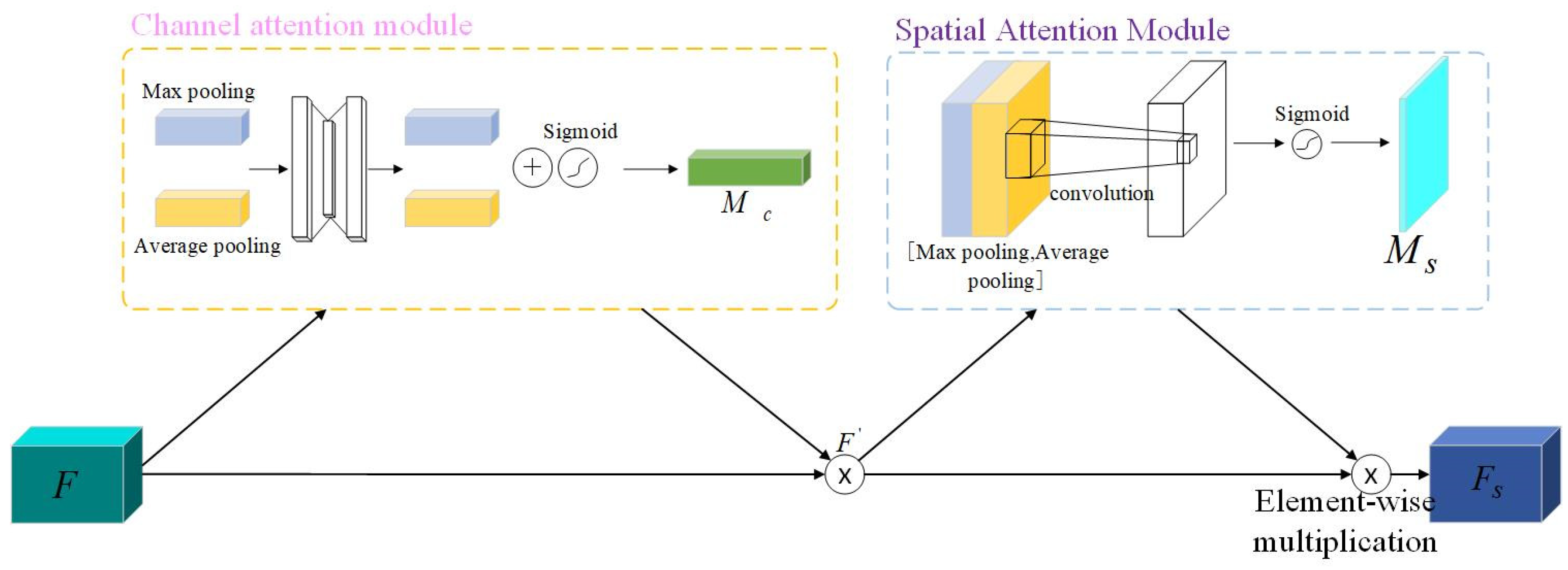
3.4. CBAM Attention Mechanism
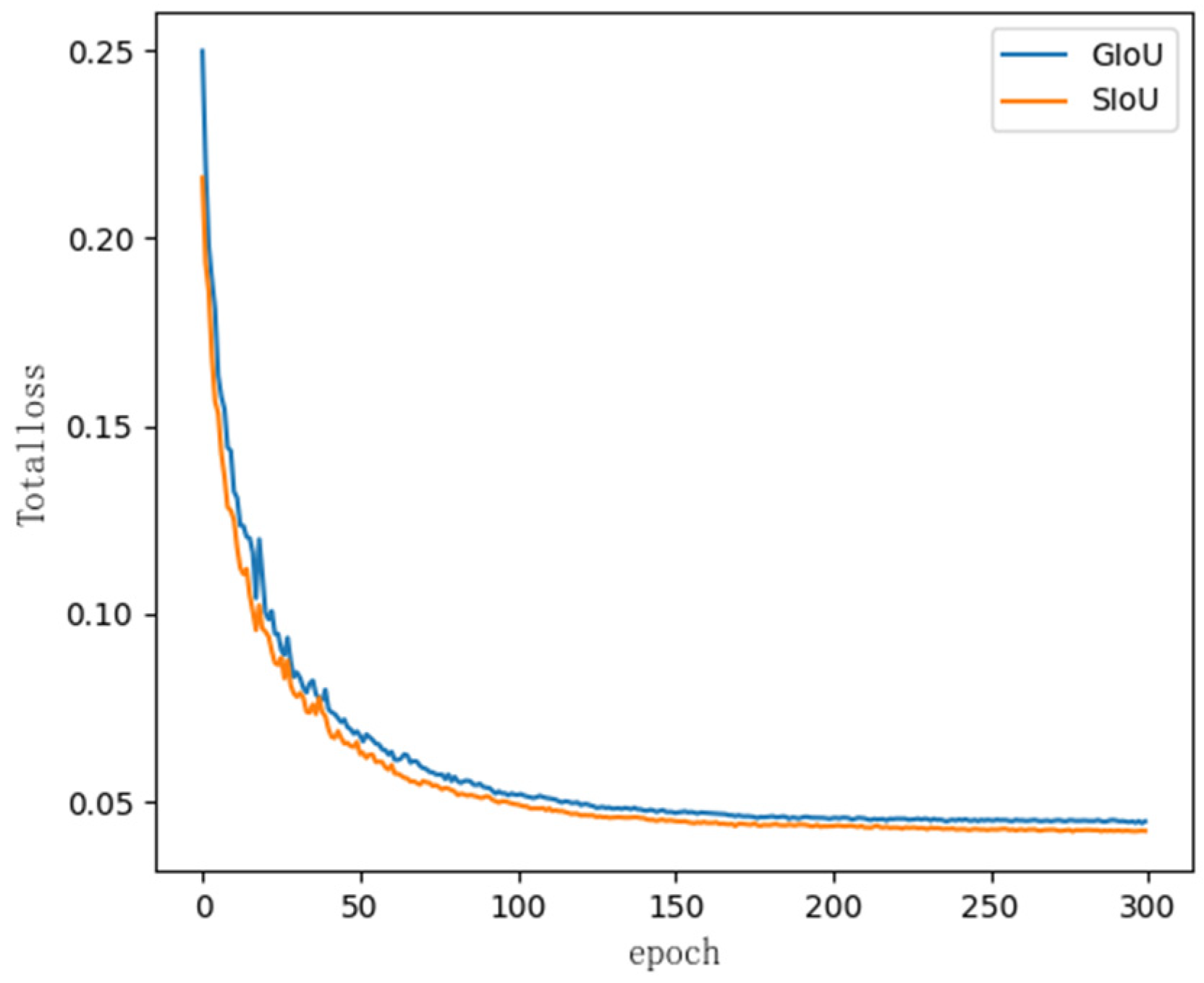
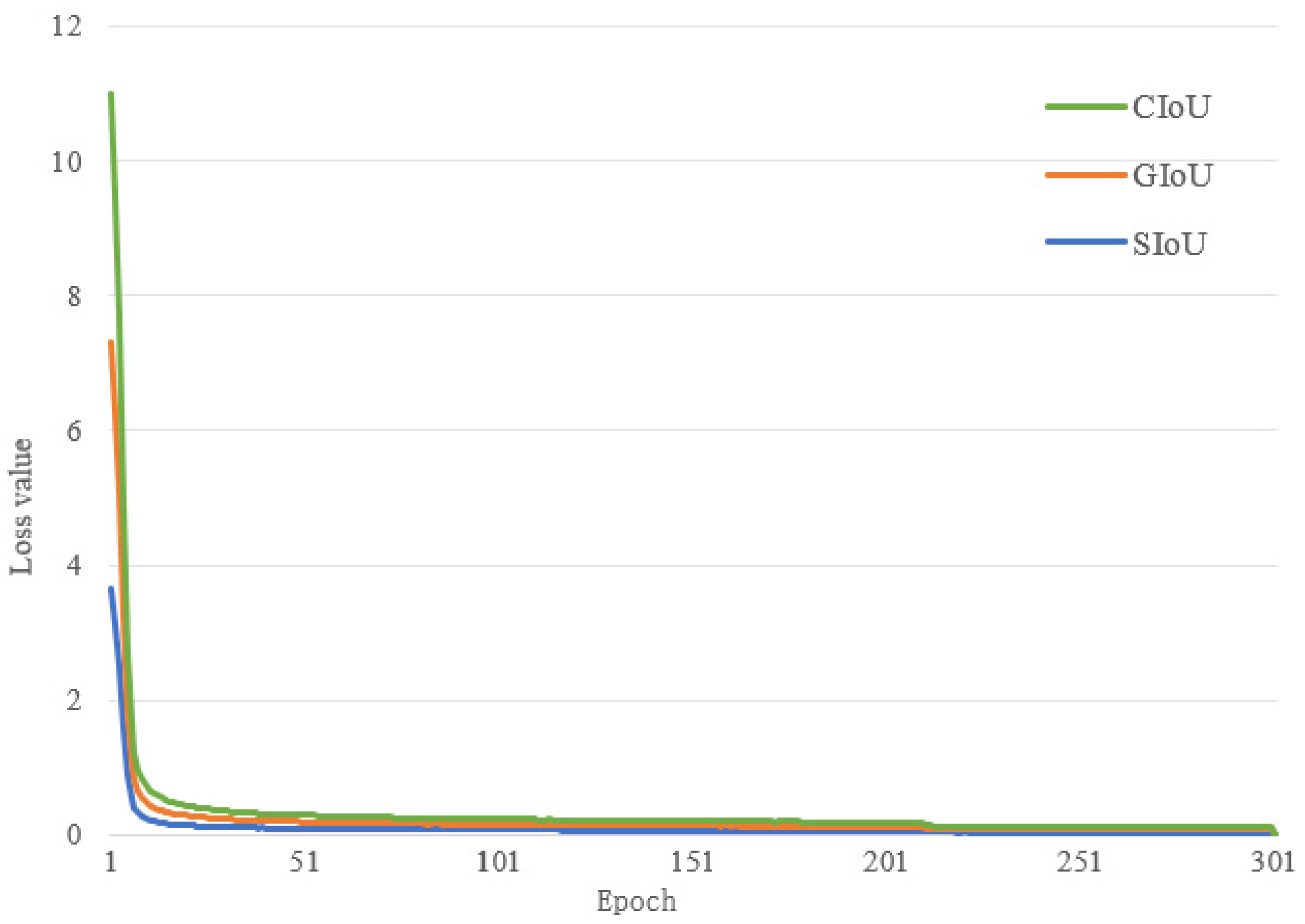
3.5. SIoU Loss Function
4. Experiment Preparation
4.1. Experimental Environment and Dataset
4.2. Evaluation Indicators
5. Experimental Results and Analysis
5.1. Model Parameter Debugging
5.2. Ablation Experiment
5.3. Comparison Experiments of Different Loss Functions
5.4. Performance Comparison of Different Detection Networks
5.5. Practical Result Verification
6. Conclusions
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, J.F.; Wu, H.; Zhang, H.; Wang, Z.Q.; Xu, W.Y. Insulator-Defect Detection Algorithm Based on Improved YOLOv7. Sensors 2022, 22, 8801. [Google Scholar] [CrossRef] [PubMed]
- Yao, C.Y.; Jin, L.J.; Yan, S.J. Recognition of insulator string in power grid patrol images. J. Syst. Simul. 2012, 24, 1818–1822. [Google Scholar]
- Zhai, Y.J.; Wang, D.; Wu, Y.; Cheng, H.Y. Two-stage recognition method of aerial insulator images based on skeleton extraction. J. North China Electr. Power Univ. Nat. Sci. Ed. 2015, 42, 105–110. [Google Scholar]
- Zhai, Y.; Wang, D.; Zhao, Z.; Cheng, H.Y. Insulator String Location Method Based on Spatial Configuration Consistency Feature. Proc. Chin. Soc. Electr. Eng. 2017, 37, 1568–1577. [Google Scholar]
- Qi, Y.F.; Li, Y.M.; Du, A.Y. Research on an Insulator Defect Detection Method Based on Improved YOLOv5. Appl. Sci. 2023, 13, 5741. [Google Scholar] [CrossRef]
- Chen, J.L.; Fu, Z.J.; Cheng, X.; Wang, F. An method for power lines insulator defect detection with attention feedback and double spatial pyramid. Electr. Power Syst. Res. 2023, 218, 7. [Google Scholar] [CrossRef]
- Elhanashi, A.; Gasmi, K.; Begni, A.; Dini, P.; Zheng, Q.; Saponara, S. Machine Learning Techniques for Anomaly-Based Detection System on CSE-CIC-IDS2018 Dataset. In Applications in Electronics Pervading Industry, Environment and Society: APPLEPIES 2022; Springer: Cham, Switzerland, 2023; pp. 131–140. [Google Scholar]
- O’Shea, K.; Ryan, N. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Ren, S.Q.; He, K.M.; Ross, G.; Jian, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Ni, H.X.; Wang, M.Z.; Zhao, L.Y. An improved Faster R-CNN for defect recognition of key components of transmission line. Math. Biosci. Eng. 2021, 18, 4679–4695. [Google Scholar] [CrossRef]
- Szegedy, C.; Sergey, I.; Vincent, V.; Alex, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Lin, T.; Liu, X.W. An intelligent recognition system for insulator string defects based on dimension correction and optimized faster R-CNN. Electr. Eng. 2021, 103, 541–549. [Google Scholar] [CrossRef]
- Redmon, J.; Santosh, D.; Ross, G.; Ali, F. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Wen, B.; Zhu, H.; Yang, C.; Li, Z.C.; Cao, R.X. Feature back-projection guided residual refinement for real-time stereo matching network. Signal Process.-Image Commun. 2022, 103, 8. [Google Scholar] [CrossRef]
- Redmon, J.; Ali, F. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Huang, Y.R.; Jiang, L.Y.; Han, T.; Xu, S.Y.; Liu, Y.W.; Fu, J.H. High-Accuracy Insulator Defect Detection for Overhead Transmission Lines Based on Improved YOLOv5. Appl. Sci. 2022, 12, 12682. [Google Scholar] [CrossRef]
- Han, G.J.; Zhao, L.; Li, Q.; Li, S.D.; Wang, R.J.; Yuan, Q.W.; He, M.; Yang, S.Q.; Qin, L.A. Lightweight Algorithm for Insulator Target Detection and Defect Identification. Sensors 2023, 23, 1216. [Google Scholar] [CrossRef]
- Xu, S.Y.; Deng, J.C.; Huang, Y.R.; Ling, L.Y.; Han, T. Research on Insulator Defect Detection Based on an Improved MobilenetV1-YOLOv4. Entropy 2022, 24, 1588. [Google Scholar] [CrossRef]
- Ashish, V.; Noam, S.; Niki, P.; Jakob, U.; Llion, J.; Aidan, N.; Gomez, L.K.; Illia, P. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ma, N.N.; Zhang, X.Y.; Liu, M.; Sun, J. Activate or Not: Learning Customized Activation. arXiv 2020, arXiv:2009.04759. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Rezatofighi, H.; Nathan, T.; Gwak, J.Y.; Amir, S.; Ian, R.; Silvio, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Ge, Z.; Liu, S.T.; Wang, F.; Li, Z.M.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Alexey, B.; Liao, H.Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Dillon, R.; Jordan, K.; Jacqueline, H.; Ahmad, D. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Lin, T.Y.; Priya, G.; Ross, G.; He, K.M.; Piotr, D. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activation Function | Accuracy (%) |
|---|---|
| AMFDH+ SiLU | 90.1 |
| AMFDH+ HardSwish | 89.5 |
| AMFDH+ Meta-ACON | 91.2 |
| Dataset Category | Label | Number of Targets |
|---|---|---|
| Insulators | insulator | 1825 |
| Breakage defect | posun | 1091 |
| Flashover defect | wushan | 2423 |
| Group | Improvement Methods | P/% | R/% | F1/% | mAP@0.5/% | ||||
|---|---|---|---|---|---|---|---|---|---|
| AMFDH | AWDMSM | Att-CSP Module | GIoU | SIoU | |||||
| 1 | - | - | - | √ | - | 92.5 | 81.2 | 86.3 | 88.3 |
| 2 | - | √ | - | √ | - | 91.8 | 86.6 | 89.0 | 89.8 |
| 3 | - | - | √ | √ | - | 92.7 | 85.2 | 88.3 | 89.2 |
| 4 | - | - | - | √ | 92.8 | 85.2 | 88.3 | 90.5 | |
| 5 | √ | - | - | √ | - | 91.6 | 88.0 | 90.0 | 91.9 |
| 6 | √ | √ | - | √ | - | 92.7 | 90.3 | 91.7 | 92.0 |
| 7 | √ | √ | √ | √ | - | 92.7 | 88.1 | 90.3 | 92.4 |
| 8 | √ | √ | √ | - | √ | 93.8 | 89.2 | 91.3 | 93.4 |
| Loss Function | P/% | R/% | mAP@0.5/% |
|---|---|---|---|
| GIoU | 92.7 | 86.0 | 90.1 |
| CIoU | 92.4 | 85.6 | 89.3 |
| SIoU | 92.8 | 85.2 | 90.5 |
| Model | AP/% | P/% | R/% | F1/% | mAP@0.5/% | Parameters/M | FPS/(f/s) | ||
|---|---|---|---|---|---|---|---|---|---|
| Insulators | Breakage Defect | Flashover Defect | |||||||
| YOLOv5 | 99.7 | 83.4 | 81.8 | 92.5 | 81.2 | 86.3 | 88.3 | 6.63 | 42.24 |
| YOLOX | 99.7 | 86.3 | 82.4 | 91.8 | 85.8 | 88.3 | 89.5 | 8.94 | 39.20 |
| YOLOv7 | 99.6 | 90.1 | 87.2 | 94.0 | 89.4 | 91.7 | 92.3 | 37.21 | 28.75 |
| YOLOv8 | 99.5 | 89.4 | 82.6 | 92.6 | 86.7 | 89.6 | 90.5 | 11.20 | 40.38 |
| RetinaNet | 99.5 | 81.1 | 44.5 | 95.4 | 65.1 | 74.7 | 73.7 | 36.37 | 24.30 |
| Faster RCNN | 99.7 | 79.6 | 50.8 | 53.9 | 87.9 | 65.3 | 76.7 | 137.08 | 16.31 |
| AC-YOLO | 99.8 | 95.0 | 85.2 | 93.8 | 89.2 | 91.3 | 93.4 | 8.38 | 40.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Wen, B.; Ye, Y.; Yang, C. Multi-Defect Detection Network for High-Voltage Insulators Based on Adaptive Multi-Attention Fusion. Appl. Sci. 2023, 13, 13351. https://doi.org/10.3390/app132413351
Hu Y, Wen B, Ye Y, Yang C. Multi-Defect Detection Network for High-Voltage Insulators Based on Adaptive Multi-Attention Fusion. Applied Sciences. 2023; 13(24):13351. https://doi.org/10.3390/app132413351
Chicago/Turabian StyleHu, Yiming, Bin Wen, Yongsheng Ye, and Chao Yang. 2023. "Multi-Defect Detection Network for High-Voltage Insulators Based on Adaptive Multi-Attention Fusion" Applied Sciences 13, no. 24: 13351. https://doi.org/10.3390/app132413351
APA StyleHu, Y., Wen, B., Ye, Y., & Yang, C. (2023). Multi-Defect Detection Network for High-Voltage Insulators Based on Adaptive Multi-Attention Fusion. Applied Sciences, 13(24), 13351. https://doi.org/10.3390/app132413351