Abstract
Pine trees are more vulnerable to diseases and pests than other trees, so prevention and management are necessary in advance. In this paper, two models of deep learning were mixed to quickly check whether or not to detect pine pests and to perform a comparative analysis with other models. In addition, to select a good performance model of artificial intelligence, a comparison of the recall values, such as Precision (AP), Intersection over Union (IoU) = 0.5, and AP (IoU), of four models including You Only Look Once (YOLOv5s)_Focus+C3, Cascade Region-Based Convolutional Neural Networks (Cascade R-CNN)_Residual Network 50, Faster Region-Based Convolutional Neural Networks, and Faster R-CNN_ResNet50 was performed, and in addition to the mixed model Swin Transformer_Cascade R-CNN proposed in this paper, they were evaluated. As a result of this study, the recall value of the YOLOv5s_Focus+C3 model was 66.8%, the recall value of the Faster R-CNN_ResNet50 model was 91.1%, and the recall value of the Cascade R-CNN_ResNet50 model was 92.9%. The recall value of the model that mixed the Cascade R-CNN_Swin Transformer proposed in this study was 93.5%. Therefore, as a result of comparing the recall values of the performances of the four models in detecting pine pests, the Cascade R-CNN_Swin Transformer mixed model proposed in this paper showed the highest accuracy.
1. Introduction
Pine trees are the most widely distributed trees in the forests of Korea, and their number is also greater than that in other forests. A characteristic of pine trees is that they are strong because they have high endurance in dry or low-landing places, so they grow well in the alpine areas of granite, accounting for 21.9% of all forests in Korea. The areas in which pine trees are used the most are construction, telephone poles, bridges, agricultural implements, implements, and furniture.
In addition, they are used in the paper industry and as a raw material for precious medicinal materials, and pine branches and pine roots are used in various ways as inks and materials for black painting. The extract of pine needles lowers blood pressure and can promote human blood circulation because it is rich in antioxidants and anti-aging substances [1]. However, pine trees are very vulnerable to pests and diseases when compared with other trees. The types of pests include pine leaf black flies, pine bark beetles, and oak wilt [2]. In Korea, after the first outbreak of pine wilt disease in 1988, a special law was enacted (2005), and as a result of active control, such as greatly expanding manpower and budget and supplementing control methods, it showed a decreasing trend. However, in 2013, due to diseases and climatic factors such as high temperatures and drought, damage spread rapidly due to the unauthorized movement of dead pine trees and anthropogenic factors.
According to the “Forestry Statistical Yearbook” issued by the Korea Forest Service, since 2013, the Korea Forest Service, local governments, and related organizations have jointly responded to the control response, and the damage from pine wilt disease has changed. It increased until 2008, but from 2008 onwards, the rate of increase has been showing a slowing trend. In addition, the pine bark beetle pest spread gradually until 2007, but it tended to decrease gradually due to climate and environmental changes. After a lot of damage occurred in the Seoul metropolitan area and provinces of Korea in 2011, it has been intensively occurring in the metropolitan area [3].
It is possible to manage agriculture or forests and orchards using artificial intelligence and manage pests. Currently, deep learning, which belongs to the realm of artificial intelligence, is widely used in image recognition and classification research.
Convolutional neural networks (CNNs or ConvNets) [4] showed excellent performance in classifying diseases according to pests and damage to crops such as orchards in agricultural research [5].
The data that were used in this paper had to be enlarged on a screen to accurately detect very small pests of the pine moth, and the accuracy was poor because the amount of collected data was very small. To solve this problem, this paper used a converter model using a method called ‘Self-Attention’ [6]. Self-Attention was created to overcome the limitations of RNNs (Recurrent Neural Networks, RNNs) [7], which are slow due to parallel processing. We used the Cascade R-CNN_Swin Transformer mixed model to try to detect the causative moth or pest of pine disease.
The main research content of this paper is the tracking and detection of pests that cause pine pests using artificial intelligence models. The artificial intelligence (AI) techniques used in this study include the You Only Look Once (YOLOv5s)_Focus+C3 model, the Faster Region-Based Convolutional Neural Networks (Faster R-CNN)_Residual Network 50 (ResNet50) model, the Cascade Region-Based Convolutional Neural Networks (Cascade R-CNN)_ResNet50 model and we compare them with the model that combines the Swin Transformer and Cascade R-CNN models proposed in this study to find the model with the highest accuracy and apply it to detect pine pests. The data available so far are insufficient because the sizes of the pine pests used here are too small. Therefore, augmented models such as the Gaussian filter model [8], Flip model [9], Rotation model [10], Multiply model [11], and Cutout model [12] were used to increase the amount of data, and they were used for AI learning.
The purpose of this study was to achieve a better result in detecting some small pest targets or some obscured disease targets by using the target detection model based on the Swin Transformer feature extraction network with a small amount of original sample data.
In this paper, we try to establish a linear relationship between the samples using image-processing-based data augmentation techniques and improve model safety.
2. Research Model
The artificial intelligence models applied in this study are the YOLOv5s (You Only Look Once v5s) model [13], the Faster R-CNN (Faster Region-Based Convolutional Neuron Networks) model [14], the Cascade R-CNN (Cascade Region-Based Convolutional Neural Network) model [15], and the Swin Transformer model [16], all of which were analyzed.
2.1. YOLOv5s (You Only Look Once v5s) Model
The YOLO (You Only Look Once) model is a deep learning model created to perform real-time object detection. The YOLO model is divided into one-stage detectors and two-stage detectors, and the reason for the appearance of the one-stage model is that the two-stage models have a disadvantage in that their learning speed is slow. In the field of object detection, it is not only necessary to accurately detect an object, but it is also important to detect it quickly.
As shown in Figure 1, the one-stage detector has a YOLO model and a Single-Shot Multi-Box Detector (SSD) model. Herein, the SSD model maintains the speed while increasing the detection performance, which is a problem with the existing YOLO model. The two-stage detector is a model developed by separating the region proposal and object detection stages, and it showed a better detection performance than Faster R-CNN. Two-stage model types include the R-CNN model, Fast R-CNN model, Faster R-CNN model, RFCN model, Mask R-CNN model, etc.
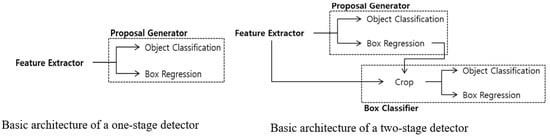
Figure 1.
Basic structures of one-stage and two-stage detectors.
YOLOv5 is divided into five versions according to the size of the model: YOLOv5n (nano), YOLOv5s (small), YOLOv5m (medium), YOLOv5l (large), and YOLOv5x (xlarge). A variety of models can be selected from the YOLOv5n (nano) to YOLOv5x (xlarge) models. The higher the YOLO version, the better the performance, but the model becomes heavier, and the detectable frame per second (FPS) decreases. As this is not advantageous for real-time object detection, it is necessary to find a good model by comparing each model.
This YOLOv5 model also has no major difference from the general object detection configuration, and the configuration is divided into backbone and head. You can check this configuration in more detail in the YOLOv5s.yaml file in the path ~/yolov5/models/. In this study, we apply the YOLOv5 model to perform real-time object detection.
2.2. Faster R-CNN (Faster Region-Based Convolutional Neuron Network) Model
R-CNN has the major drawback of low responsiveness because it has to run one Convolutional Neuron Network (CNN) for every region proposal. Fast R-CNN, developed to complement this, does not extract the detection features from the input image but instead uses RoI (Region of Interest) pooling, a special form of spatial pyramid pooling, on the image shape map that has passed through the CNN. As a method of extracting the image shape, the feature ensures that object detection is performed by performing one CNN. Fast R-CNN also improves the performance speed of object detection, but since an algorithm called selective search was used to generate region proposals that suggest an image detection range, a large number of region proposals were generated, which caused a bottleneck in the data processor.
Faster R-CNN has a network structure called Region Proposal Network (RPN) attached to the inside of the CNN, as shown in Figure 1, for the purpose of generating region proposals to solve the bottleneck problem of Fast R-CNN [17]. In addition, Faster R-CNN extracts features from the feature map using a total of nine anchors with three sizes and three ratios for the input image, and the extracted features are shared by the RPN and RoI pooling layers. The RPN extracts region proposals from the feature map, and the extracted region proposals perform RoI pooling through the RoI pooling layer.
2.3. Cascade R-CNN (Cascade Region-Based Convolutional Neural Network) Model
Cascade R-CNN is an improved model of Faster R-CNN, and Faster R-CNN must actively select positive and negative samples for overlap thresholds in order to score all RPNs in the image. The detection result is obtained by setting the IoU threshold to ensure that the positive samples match the original target.
Cascade R-CNN adopts the output of the previous detection model as the input of the next detection model with the cascade method, and the IoU threshold of the subsequent detection model increases as the IoU threshold increases. By setting a plurality of dedicated regression amounts of IoU thresholds of different sizes, the detection precision is improved by optimizing step-by-step resampling.
2.4. Swin Transformer Model
The Swin Transformer model is a model in which the Transformer structure used in existing natural language processing is applied to object detection. The Swin Transformer model implements a hierarchical structure similar to a convolutional neural network and processes images so that the model can flexibly process images of different sizes. In addition, the Swin Transformer reduces the complexity of model calculation by adopting window self-attention. Among the four versions of the Swin Transformer, Tiny, Small, Base, and Large, the Tiny version is applied in this paper [18].
3. Designing Models for Pine Pest Detection
Figure 2 shows the development process for pine pest detection. The description of each item is as follows.
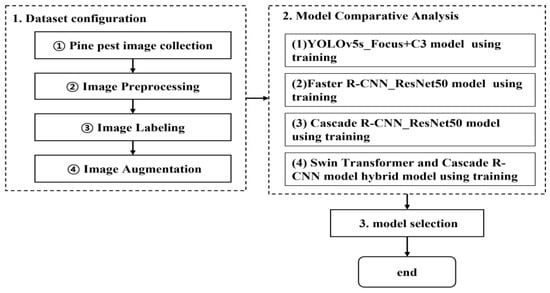
Figure 2.
Process for the comparative analysis of applied artificial intelligence.
The overall description of the dataset configuration shown in Figure 2 is as follows: ① Pine pest image collection collects image data of pine pests from Google, Baidu, and Naver. ② Image preprocessing processes the image data collected in step ① via preprocessing. ③ In image labeling, each image datum preprocessed in ② is labeled. Finally, ④ image augmentation adds new data based on the image data samples labeled in ③.
The overall explanation of the model comparative analysis shown in Figure 2 is as follows: Four types of training are conducted—the YOLOv5s_Focus+C3 model, Faster R-CNN_ResNet50 model, Cascade R-CNN_ResNet50 model, and Cascade R-CNN_Swin Transformer mixed model. Evaluation indicators are then created for the four models.
Model selection selects the model with the highest accuracy through a comparative evaluation and analysis of the performances of the four proposed models with AP (IoU) = 0.5 and AP (IoU = 0.75) and the recall values.
3.1. Design of Pine Pest Detection Using YOLOv5s Model
Figure 3 shows the network structure of YOLOv5s. The backbone consists of a focus structure and a C3 structure. The neck part consists of the Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) [19]. In addition, the backbone transforms the input image into a feature map, and the neck refines and reconstructs the feature map as a part connecting the backbone and the head. The backbone of the YOLOv5 network is a very important part of feature extraction, and the complexity of the backbone can affect the consumption time of the entire algorithm.
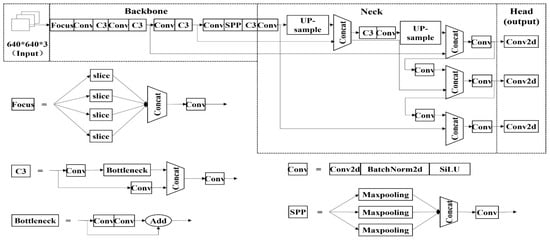
Figure 3.
Design of the YOLOv5s detection model.
As shown in Figure 3, the C3 model divides the original input image into two parts in a format with three convolutions: (Conv) ① reduces the number of channels by half by performing a conv. operation. (Conv) ② is manipulated through the formula of the progress bottleneck. The Concatenate Function (Concat) of ③ functions to integrate the feature map through the contents performed in ① and ②, and it combines the calculation values of the two convolutional layers. This process is undertaken for the model to learn more features [20]. The structure of the Focus model in the backbone of Figure 3 is shown in Figure 2. The focus model slices the input image into four small images to create a low-dimensional feature map as a model that concatenates the convolution operation.
Spatial Pyramid Pooling (SPP) allows the network to input images of any size and to output fixed-length vectors for feature maps of arbitrary size after passing through the SPP layer [18]. In addition, a vector of a fixed length is input into a fully connected layer to perform subsequent classification detection.
3.2. Design of Pine Pest Detection Model Using the Faster R-CNN Model
Figure 4 shows the model for detecting pine pests using the Faster R-CNN model consisting of ResNet50 of the feature extraction model, the RPN model that creates a candidate area, and one inspection step.
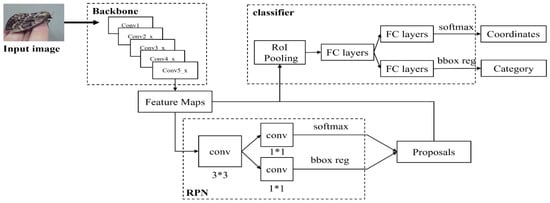
Figure 4.
Design for pine pest detection using the Faster R-CNN model.
In the first step, the backbone is the feature extraction step, and the pest image of the pine tree is the input.
The Faster R-CNN model uses 13 convolutional layers, 13 rectified linear unit (ReLu) layers, and 4 pooling layers to extract image feature maps. The second step is to input the extracted feature map into the RPN and generate candidate regions through the RPN. In the third step, the feature maps and candidate regions input through the RoI pooling layer are collected and synthesized and then recommended feature maps are extracted, and the fully connected layer (FC layer) category is determined to classify the objects.
The classification layer (classifier) is a category for calculating a candidate region using a recommended feature map, and it again obtains the final exact position of a detection frame via bounding box regression.
3.3. Designing Pine Pest Detection Using the Cascade R-CNN Model
Figure 5 shows the design for detecting pine pests using the Faster R-CNN model, using ResNet50 as a model for feature extraction, and it consists of an RPN model that creates a candidate area and one inspection step.
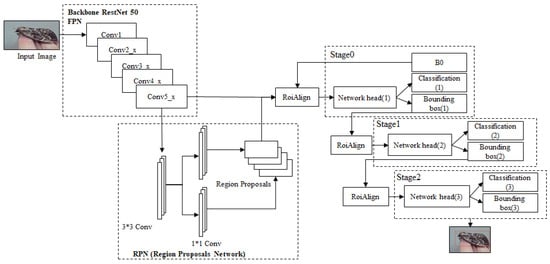
Figure 5.
Design of pine pest Detection using the Cascade R-CNN model.
First, the pest images of pine trees are input into the feature extraction step. The Cascade R-CNN model uses 13 convolutional layers, 13 ReLu layers, and 4 pooling layers to extract image feature maps.
Second, the extracted feature map is input into the RPN to generate a candidate region. Third, the RoI pooling layer processes the input feature map and the candidate region of the RPN, and it sets different IoU thresholds to determine the target category. B0 of stage 0 is used to generate the RPN, and it is a process of classifying objects by classifying the stage output from the network head of each stage into IoU values.
In this paper, the median value of IoU, which is 0.5 and is gradually increased by 0.1, is used to set stage 0 to 0.5, stage 1 to 0.6, and stage 2 to 0.7.
3.4. Design a Structure That Mixes the Swin Transformer Model and the Cascade R-CNN Model
In the research field of object detection, IoU thresholds are used to define positive and negative values. In the research process for the detection of pine pests based on the Faster R-CNN model, a low IoU threshold is applied. The resultant value of the bounding box position appears inaccurate in the detection process, and when a high IoU threshold is applied, the accuracy of the detector is reduced. This can be very bad. These cases can be mainly classified into two causes. First, when the IoU threshold increases, the number of positive numbers decreases exponentially, resulting in overfitting. The second cause is that the IoU threshold shown in the model reasoning process may be an erroneous matching.
In order to solve this problem, this study mixed a multi-stage Cascade R-CNN model to detect pests in pine trees. By changing the backbone in the Cascade R-CNN model and using the Swin Transformer model as the backbone, we wanted to increase the accuracy in detecting pine pests.
Figure 6 shows the design of a model that combines the Swin Transformer model and the Cascade R-CNN model to increase the accuracy of the detection of pine pests in this study.
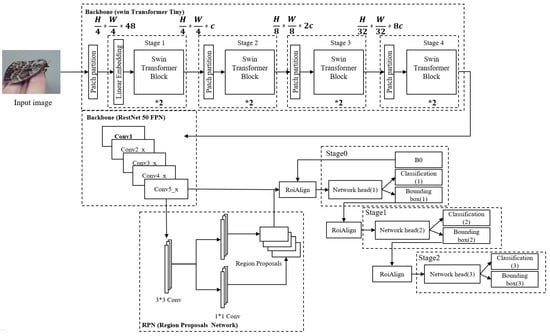
Figure 6.
Design of a mixed model composed of the Swin Transformer model and the Cascade R-CNN model.
Figure 6 shows the structure of the Tiny model of the Swin Transformer used in this study. The composition of the patch of five is a model of the converted patch partition layer and four stages. Herein, each stage is composed of a patch merging layer (PML) and two Swin Transformer Blocks (STBs), except for the linear embedding layer (LEL) of the first stage.
The size of the Tiny model structure of the Swin Transformer is H/4 * W/4 * 48, found by dividing the input image of H * W * 3 into patches of 4 * 4 * 3 so that they do not overlap with each other through the patch partition, making it a feature after stage two, which is the patch merging stage, and the number of patches inside the window is kept constant by merging adjacent 2 * 2 matches.
Figure 6 shows the internal structure of the Swin Transformer Block in four stages. Window multi-head self-attention (W-MSA) and shifted window were used as methods to calculate window-based self-attention in the existing Multi-Headed Self-Attention (MSA). Herein, it has the same structure as the existing standard transformer except for the Shifted Window Multi-Head Self Attention (SW-MSA) model that calculates self-attention.
The reason for choosing the mixed model for this study is that the structure of the Swin Transformer model is more effective than CNN for learning a large amount of data, and the accuracy is also higher. Because it has the advantage of minimizing the inference time discrepancy of the IoU, a design that mixes the two models was designed.
4. Implementation
The development environment for this study was constructed as shown in Table 1, and it was difficult to collect sufficient data because the sizes of pine pests are small. Therefore, in this study, a data augmentation technique was applied to make up for insufficient data because sufficient data for artificial intelligence learning were not secured.

Table 1.
Configuration of development environment.
4.1. Development Environment
In this study, the software environment for the experiment was developed using Python version 3.7; the artificial intelligence library used the PyTorch-based MMDetection API; and the hardware environment was Windows 10 for OS, i9-9900k for CPU, 128 GB for RAM, and 128 GB for GPU. NVIDIA RTX 6000 was used, and the detailed environment is indicated in Table 1.
4.2. Implementation of Data Augmentation
A total of 432 sheets were secured to be used as training image data to detect pests of pine trees. However, to increase the accuracy, 432 chapters of the existing data set were applied to the augmented model. As shown in Figure 7, the Gaussian filter model, Flip model, Rotation model, Multiply model, and Cutout model were used as the five models for data augmentation.
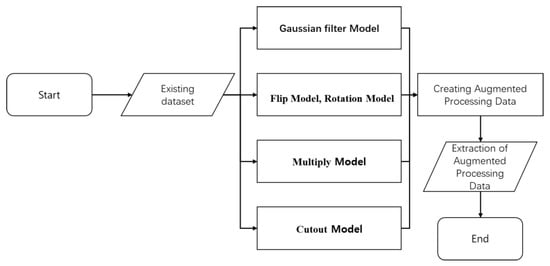
Figure 7.
Process of how to augment data.
As a result of data augmentation using the Gaussian filter model, 1728 images were obtained. A total of 1728 Flip model images, 1728 Rotation model images, 1728 Multiply model images, and 1728 Cutout model images were added. Therefore, the number of augmented images increased to 8640, and the total image data increased to 9072. The data augmentation techniques applied in Table 2 show the results of data set quantity changes.
Table 2.
Data quantity results using model of data augmentation technique.
4.3. Training of the Pine Pest Detection Model
In the training of the YOLOv5s model for optimization, the input image size was 640 * 640, the batch size was 32, and 1000 epochs were performed. During the training process, changes in training loss were recorded and stored in the wandb environment and were then used.
The YOLOv5s model in Table 3 compares 0 steps with 400 steps, and it can be seen that the training loss quickly goes down from 0.07266 to 0.03762, and the training loss from 400 to 800 steps decreased from 0.03762 to 0.034. Herein, the training was terminated because there was no change in the value when learning 800–1000 steps.
Table 3.
Training the detection model for pine pests.
For the training of the Faster R-CNN model, the input image size was 640 * 640, the batch size was 64, 1000 epochs were performed, and the stochastic gradient descent (SGD) method was applied to optimize it. In addition, comparing 0 steps with 0.4 (10−6) steps, training loss quickly decreases from 2.7628 to 0.3276.
Herein, the train loss from 0.4 (10−6) to 0.8 (10−6) steps changes from 0.3276 to 0.160, where there is little change in value from 0.8 (10−6) to 1.4 (10−6) steps. Because of this, training was terminated.
For training the Cascade R-CNN model, the input image size was 640 * 640, the batch size was 48, 1000 epochs were performed, and the SGD algorithm was applied for optimization. Herein, comparing 0 and 0.4 (10−6) steps, it can be seen that the training loss goes down from 5.0919 to 0.0831, and the training loss from 0.4 (10−6) to 0.6 (10−6) steps decreases from 0.0831 to 0.0166. The training was terminated because there was no difference in value from 0.6 (10−6) to 1.4 (10−6) steps when learning and training.
Lastly, to train the mixed model composed of the Swin Transformer model and Cascade R-CNN model proposed in this study, the input image size was 640 * 640, the batch size was 48, 1000 epochs were performed, and the SGD algorithm was optimized. Comparing 0 steps and 100,000 steps in the mixed model, training loss fell rapidly from 8.1189 to 0.1094. In addition, the training loss from 200,000 to 300,000 steps dropped from 0.1161 to 0.0852, and the training was terminated because there was no difference in the changed values from 300,000 to 700,000 steps.
4.4. Comparison between Models According to the Detection Results of Pine Pests
This study implemented the YOLOv5s model, Faster R-CNN model, Cascade R-CNN model, and the Swin Transformer and Cascade R-CNN mixed model proposed in this paper to detect pine pests, and the performance results were compared and analyzed.
First, in the YOLOv5s model, as a result of detecting pine pests, the AP (IoU = 0.5) was 56.3%, and the recall value was 66.8%. As a result of detecting pine pests using the Faster R-CNN model, the AP (IoU = 0.5) was 92.5%, the AP (IoU = 0.75) was 87.9%, and the recall value was 91.1%. As a result of detecting pine pests using the Cascade R-CNN model, the AP (IoU = 0.5) was 93.2%, the AP (IoU = 0.75) was 89.5%, and the recall value was 92.9%. In addition, the results of detecting pine pests using the Cascade R-CNN_Swin Transformer mixed model proposed in this paper were as follows: the AP (IoU = 0.5) was 94.6%, the AP (IoU = 0.75) was 89.6%, and the recall value was 93.5%.
As shown in Table 4, as a result of comparing the performance of the AP (IoU = 0.5, 0.7) and recall of each of the 4 models for detecting pine pests, the YOLOv5s model showed the lowest accuracy and comparing the models, the Cascade R-CNN model and the Faster R-CNN model showed better values, and the mixed model using the Cascade R-CNN_Swin Transformer models showed the highest accuracy.
Table 4.
Comparison of performances of 4 models for detecting pine pests.
5. Conclusions
In this paper, there were insufficient data in the data collection process of the existing pine pests, and the sizes of the pests were small. Therefore, in this study, data were augmented and used, and a model that combined the advantages of the Swin Transformer model and the Cascade R-CNN model was proposed to detect pine pests.
In the process of collecting artificial intelligence learning data, a data augmentation model was used to increase the image data to 8640 from the original data set.
This paper compared the YOLOv5s, Faster R-CNN, and Cascade R-CNN models to compare their performances with the performance of the Cascade R-CNN_Swin Transformer mixed model.
In the detection of pine pests, for the YOLOv5s model, the AP (IoU = 0.5) was 56.3% and the recall value was 66.8%, and the Faster R-CNN model showed an AP (IoU = 0.5) of 92.5%, the accuracy of the AP (IoU = 0.75) was 87.9%, and the recall was 91.1%. Moreover, the Cascade R-CNN model showed an accuracy of AP (IoU = 0.5) of 93.2%, an AP (IoU = 0.75) of 89.5%, and a recall of 92.9%.
Finally, the mixed model Cascade R-CNN_Swin Transformer proposed in this study showed an accuracy of 94.6% for AP (IoU = 0.5), 89.6% for AP (IoU = 0.75), and 93.5% for recall in the detection of pine pests. As a result of comparing the performances of the four models for detecting pine pests, YOLOv5s and Faster R-CNN showed a lower performance compared with the Cascade model, and the Cascade R-CNN_Swin Transformer mixed model showed the highest accuracy.
In addition, as a result of this study, it was found that setting a high IoU threshold in the Faster R-CNN-based pine pest detection model resulted in an insufficient number of positive samples and syntheses as a result of training. Setting a low IoU threshold is advantageous for training a model because a large number of samples can be obtained, but there is a problem in that a lot of errors occur when testing is performed. To solve this problem, a Cascade structure can be used. In addition, it is believed that the mixed model presented in this paper can be applied to agriculture and forestry to monitor and predict caterpillars and moths.
Author Contributions
Conceptualization, S.-H.L. and G.G.; methodology, G.G.; software, G.G.; validation, S.-H.L. and G.G.; formal analysis, G.G.; resources, S.-H.L.; data curation, G.G.; writing—original draft preparation, G.G.; writing—review and editing, S.-H.L.; visualization, S.-H.L. and G.G.; supervision, S.-H.L.; project administration, S.-H.L.; funding acquisition, S.-H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Honam University Research Fund, 2022.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lee, D.; Seo, Y.; Choi, J. Estimation and validation of stem volume equations for Pinus densiflora, Pinus koraiensis, and Larix kaempferi in South Korea. For. Sci. Technol. 2017, 13, 77–82. [Google Scholar]
- An, H.; Lee, S.; Cho, S.J. The Effects of Climate Change on Pine Wilt Disease in South Korea: Challenges and Prospects. Forests 2019, 10, 486. [Google Scholar] [CrossRef]
- Choi, W.I.; Nam, Y.; Lee, C.Y.; Choi, B.K.; Shin, Y.J.; Lim, J.-H.; Koh, S.-H.; Park, Y.-S. Changes in Major Insect Pests of Pine Forests in Korea over the Last 50 Years. Forests 2019, 10, 692. [Google Scholar] [CrossRef]
- Farman, H.; Ahmad, J.; Jan, B.; Shahzad, M.; Abdullah, M.; Ullah, A. EfficientNet-Based Robust Recognition of Peach Plant Diseases in Field Images. Comput. Mater. Contin. 2022, 71, 2073–2089. [Google Scholar]
- Al-Wesabi, F.N.; Albraikan, A.A.; Hilal, A.M.; Eltahir, M.M.; Hamzaet, M.A.; Zamani, A.S. Artificial Intelligence Enabled Apple Leaf Disease Classification for Precision Agriculture. Comput. Mater. Contin. 2022, 70, 6223–6238. [Google Scholar] [CrossRef]
- Demigny, D.; Kessal, L.; Pons, J. Fast Recursive Implementation of the Gaussian Filter. In SOC Design Methodologies; Springer: Boston, MA, USA, 2002; pp. 39–49. [Google Scholar] [CrossRef]
- Sahu, A.K.; Swain, G.; Babu, S. Digital Image Steganography Using Bit Flipping. Cybern. Inf. Technol. 2018, 18, 69–80. [Google Scholar] [CrossRef]
- Lohmann, A.W. Image rotation, Wigner rotation, and the fractional Fourier transform. JOSA A 1993, 10, 2181–2186. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Devries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. ArXiv 2017. Available online: https://arxiv.org/abs/1708.04552 (accessed on 29 November 2017).
- Gao, G.; Lee, S.H. Design and Implementation of Fire Detection System Using New Model Mixing. Int. J. Adv. Cult. Technol. 2021, 9, 260–267. [Google Scholar]
- Li, M.T.; Lee, S.H. A Study on Small Pest Detection Based on a Cascade R-CNN-Swin Model. CMC Comput. Mater. Contin. 2022, 72, 6155–6165. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lee, S.H. A Study on Classification and Detection of Small Moths Using CNN Model. Comput. Mater. Contin. 2022, 71, 1987–1998. [Google Scholar]
- Tian, C.; Yuan, Y.; Zhang, S.; Lin, C.-W.; Zuo, W.; Zhang, D. Image Super-Resolution with an Enhanced Group Convolutional Neural Network. ArXiv 2022. Available online: https://arxiv.org/abs/2205.145480 (accessed on 31 July 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).