
Recognition and Classification of Handwritten Urdu Numerals Using Deep Learning Techniques

 ,
,
Abstract
:1. Introduction
- Proposition of new Urdu numerals dataset that contains variations because of crumbled, torn, and ink spotted paper.
- After CNN extracts the features, we use two different activation functions: SVM and Softmax.
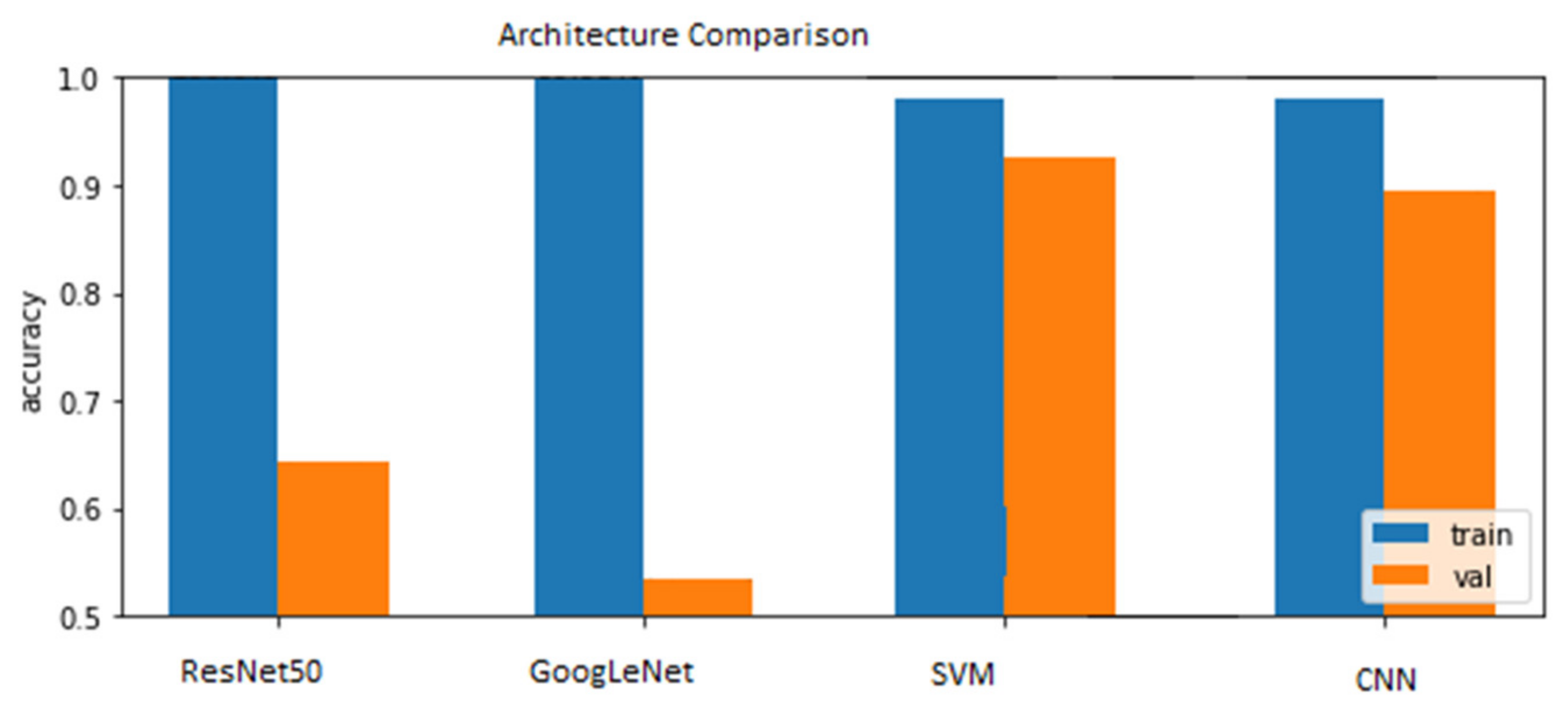
- The proposed CNN is compared with GoogLeNet and ResNet. The conducted experiments suggest our models’ better accuracy.
2. Literature Review
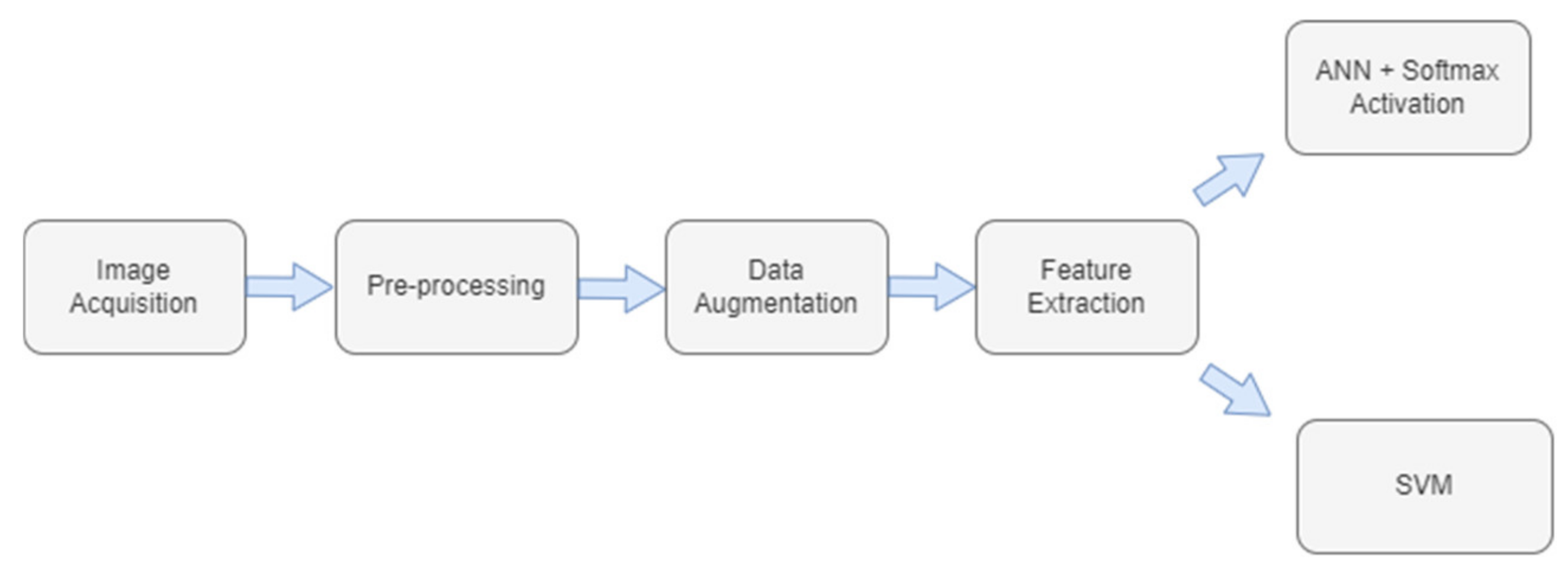
3. Proposed Model
3.1. Image Acquisition
3.2. Preprocessing
3.3. Augmentation
3.4. Feature Extraction
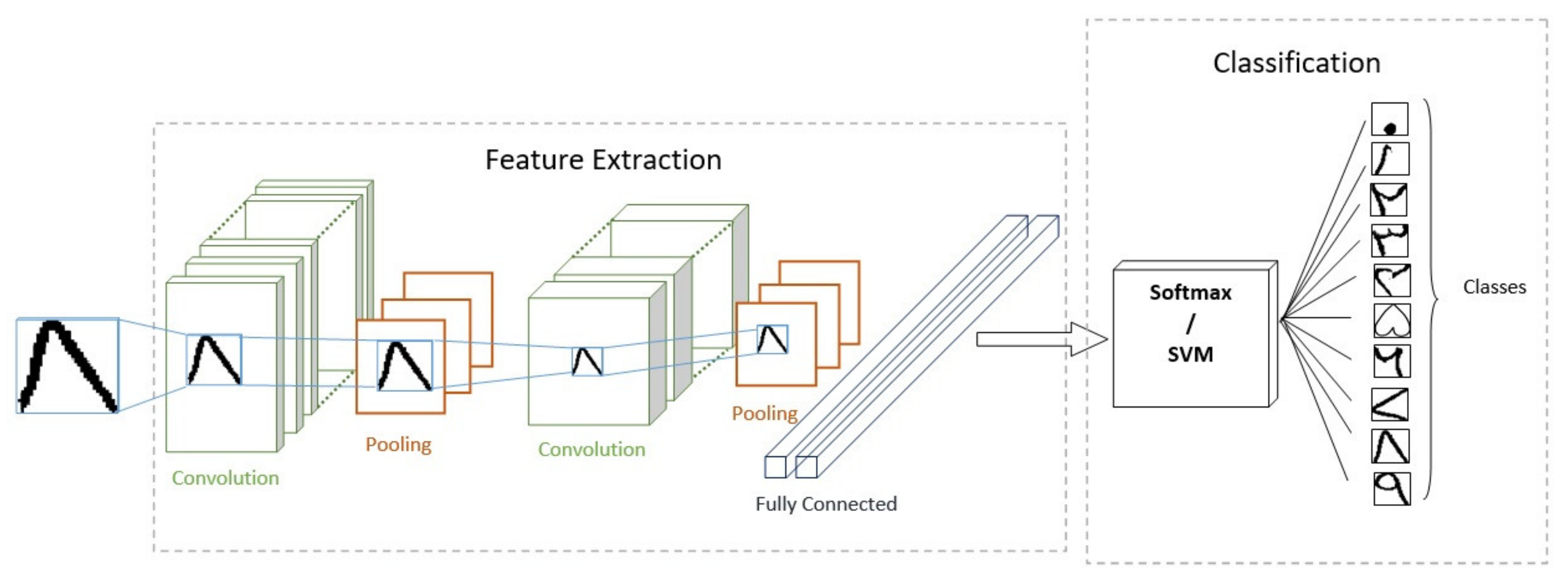
3.4.1. Convolutional Neural Network
- The input layer contains raw pixel values, and, in this case, each image of the size 32 × 32 × 3 pixels is fed to the CNN. Here, 32 represents the width and height of the image while 3 is the color channels—red, green, and blue.
- The convolution layer connects local receptive field of the input with neurons in the next layer. This is achieved through a simple dot product of kernel and input image. A kernel size of 3 × 3 is maintained throughout the model, whereas padding is set to 1. It is followed by batch normalization of convolution layer. Each output of convolution layer uses the ReLU activation function followed by pooling layer. ReLU activations work better than sigmoid function in terms of gradient vanishing problems. ReLU was picked out of other nonlinearities (e.g., tanh, sigmoid) after comparing their results in our CNN model. Batch normalization is applied after each convolution layer to improve generalization [35].
- The pooling layer down samples input along spatial dimensions. One of the most famous pooling layers is ‘Max Pooling’ which is used here to extract the highest pixel value in the current space. These extracted features are then fed to the classifiers which are discussed further. Figure 10 depicts the architecture of our proposed model and Table 2 provides an analysis of required computation resources and learning parameters.
3.4.2. GoogLeNet
3.4.3. ResNet
4. Classification
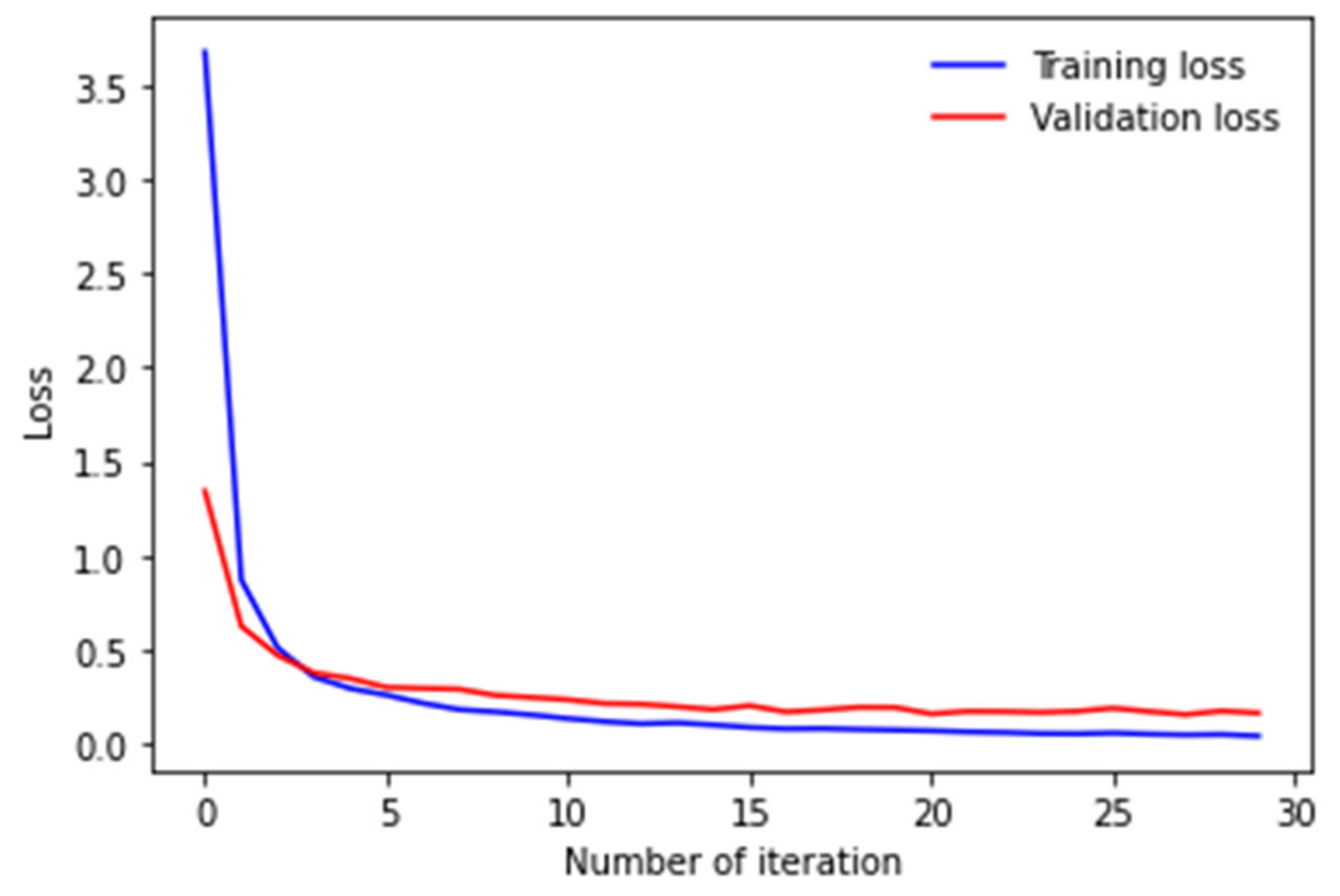
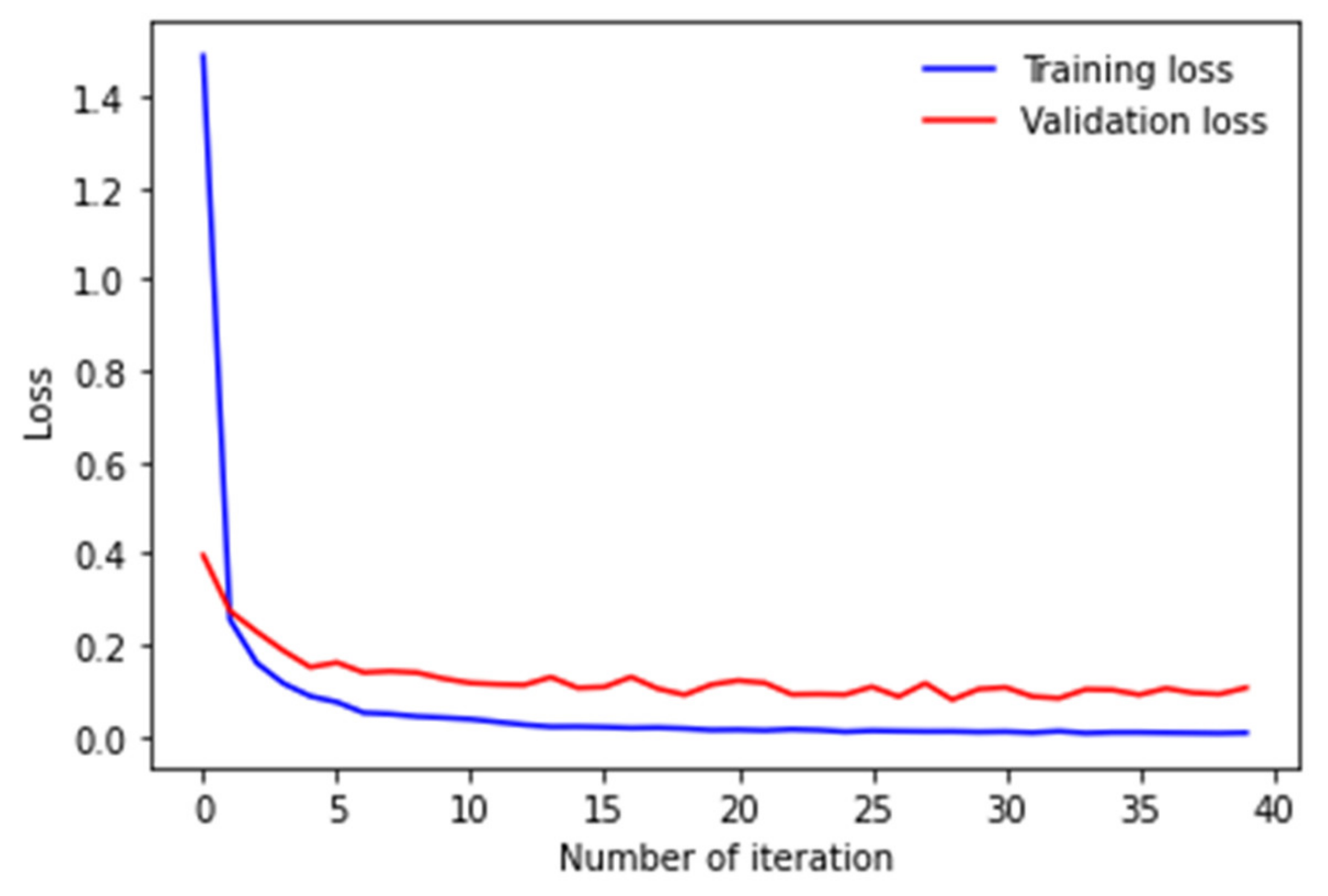
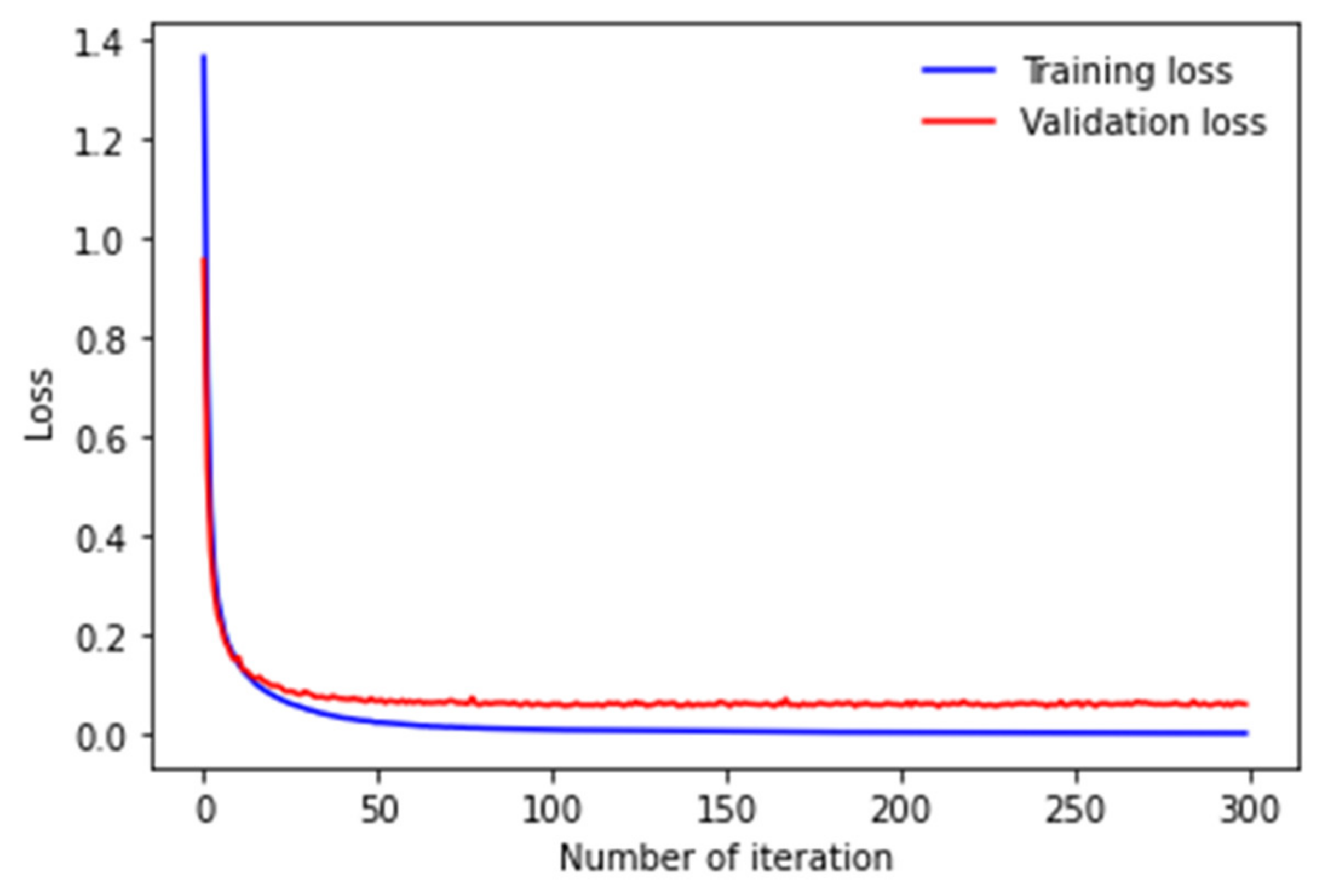
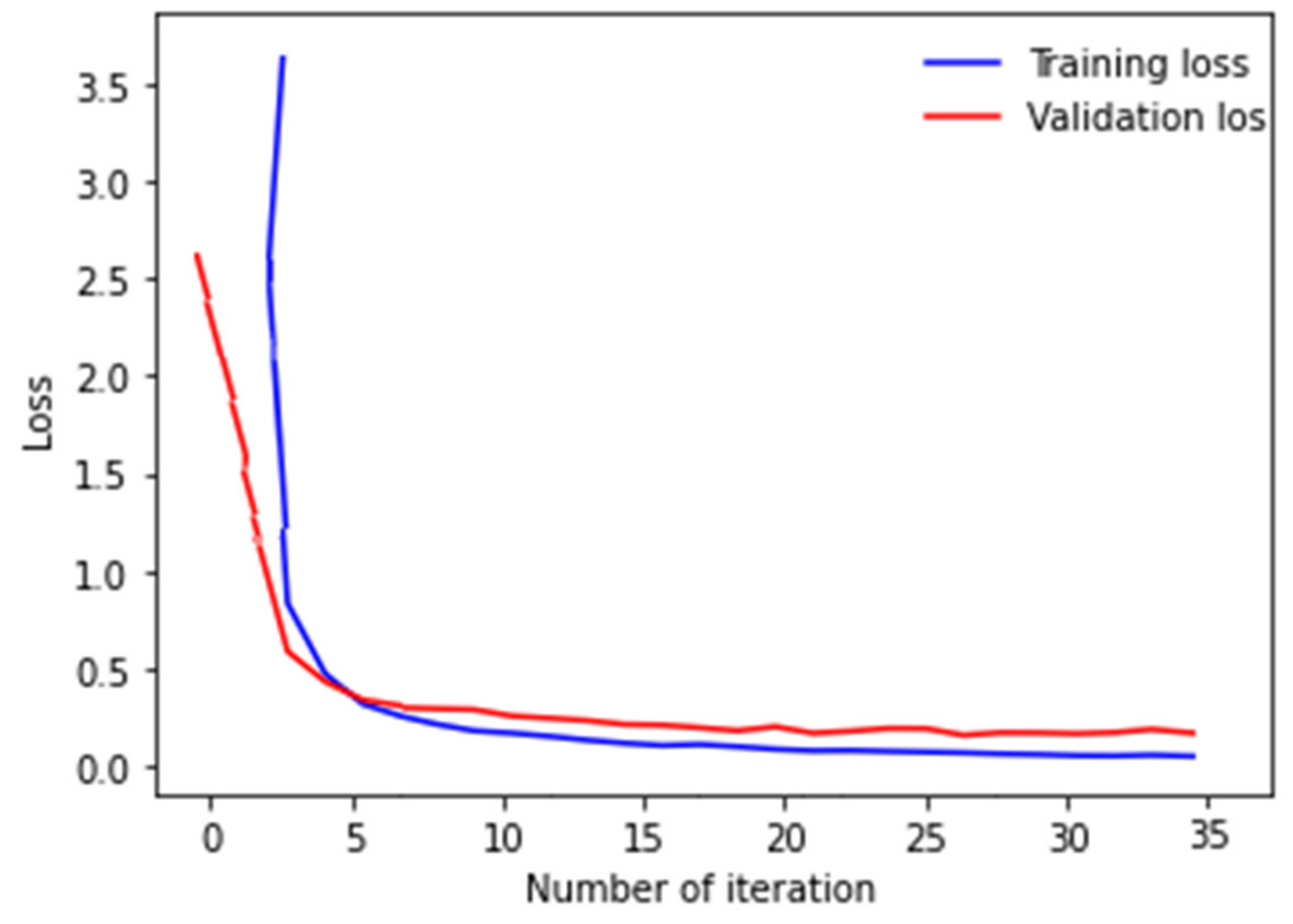
5. Experiment and Discussion
- One is the original one that we proposed initially, and we evaluated it by splitting it into 85–15 ratio.
- The other one is made as a separate set consisting of Pakistani currency note images which are used for testing only but are trained using the Urdu dataset. This is done to test our models on real-life scenarios.
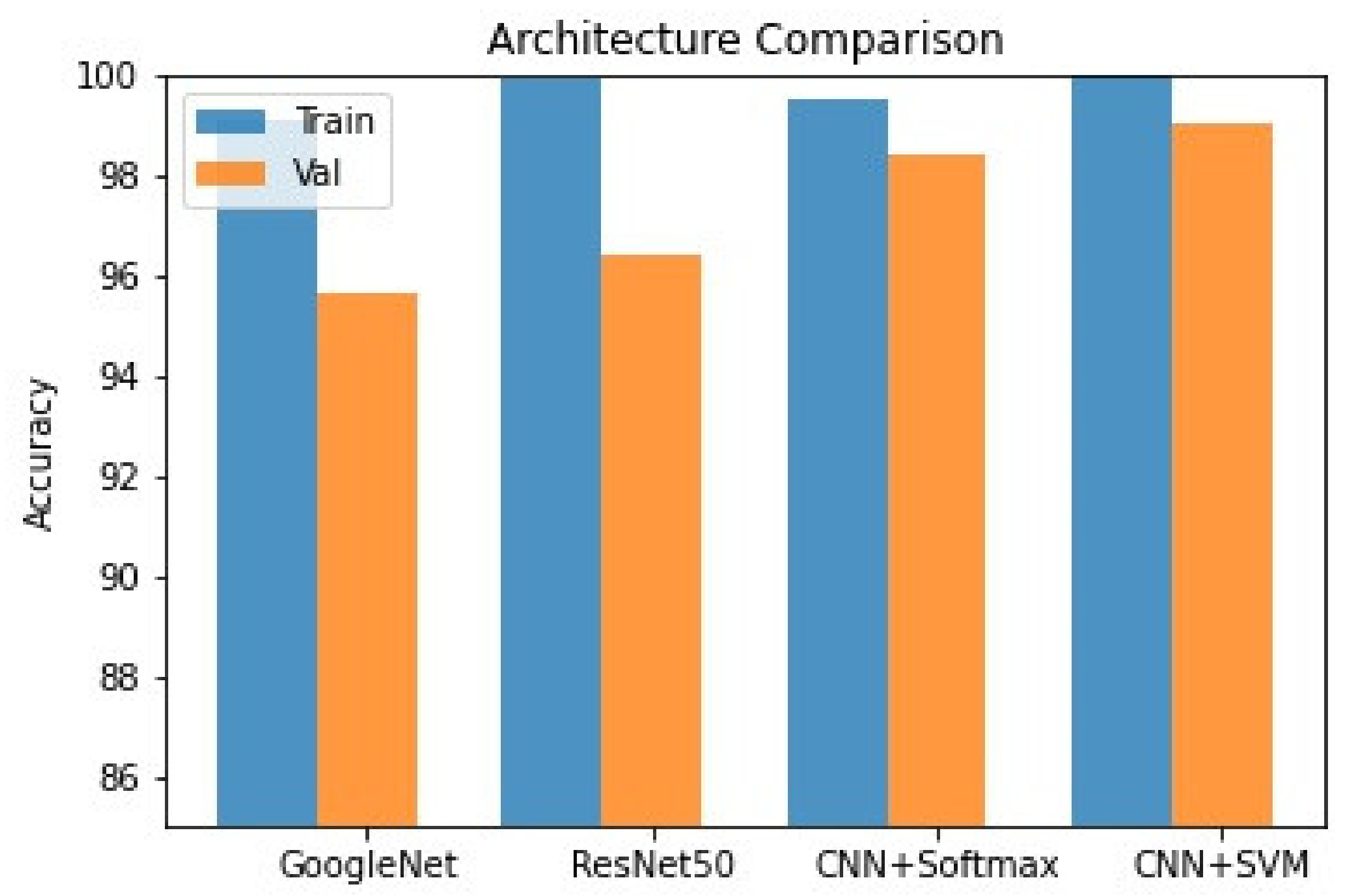
5.1. Comparison with Existing Methods
5.2. Expanded Testing Set
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Singh, R.; Mishra, R.K.; Bedi, S.; Kumar, S.; Shukla, A.K. A Literature Review on Handwritten Character Recognition based on Artificial Neural Network. Int. J. Comput. Sci. Eng. 2018, 6, 753–758. [Google Scholar] [CrossRef]
- The Online Encyclopedia of Writing Systems and Languages. Available online: https://www.omniglot.com/writing/urdu.htm (accessed on 9 June 2020).
- Spitz, A.L.; Andreas, D. Document Analysis Systems. In Proceedings of the International Association for Pattern Recognition Workshop; World Scientific: Singapore, 1995; pp. 237–292. [Google Scholar]
- Sharif, M.; Ul-Hasan, A.; Shafait, F. Urdu Handwritten Ligature Generation Using Generative Adversarial Networks (GANs). In Proceedings of the Frontiers in Handwriting Recognition: 18th International Conference, ICFHR 2022, Hyderabad, India, 4–7 December 2022; Springer-Verlag: Berlin/Heidelberg, Germany, 2022; pp. 421–435. [Google Scholar] [CrossRef]
- Misgar, M.M.; Mushtaq, F.; Khurana, S.S.; Kumar, M. Recognition of offline handwritten Urdu characters using RNN and LSTM models. Multimed. Tools Appl. 2022, 82, 2053–2076. [Google Scholar] [CrossRef]
- Gautam, N.; Sharma, R.S.; Hazrati, G. Eastern Arabic Numerals: A Stand out from Other Jargons. In Proceedings of the International Conference on Computational Intelligence and Communication Networks (CICN), Jabalpur, India, 12–14 December 2015; pp. 337–338. [Google Scholar] [CrossRef]
- Memon, J.; Sami, M.; Khan, R.; Uddin, M. Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR). IEEE Access 2020, 8, 142642–142668. [Google Scholar] [CrossRef]
- Khan, S. A Mechanism for Offline Character Recognition. Int. J. Res. Appl. Sci. Eng. Technol. 2019, 7, 1086–1090. [Google Scholar] [CrossRef]
- Haghighi, F.; Omranpour, H. Stacking ensemble model of deep learning and its application to Persian/Arabic handwritten digits recognition. Knowl. Based Syst. 2021, 220, 106940. [Google Scholar] [CrossRef]
- Das, N.; Sarkar, R.; Basu, S.; Kundu, M.; Nasipuri, M.; Basu, D.K. A genetic algorithm based region sampling for selection of local features in handwritten digit recognition application. Appl. Soft Comput. 2012, 12, 1592–1606. [Google Scholar] [CrossRef]
- Slimane, F.; Kanoun, S.; Hennebert, J.; Alimi, A.; Ingold, R. A study on font-family and font-size recognition applied to Arabic word images at ultra-low resolution. Pattern Recognit. Lett. 2013, 34, 209–218. [Google Scholar] [CrossRef]
- Center for Language Engineering Urdu Ligatures from Corpus Page. Available online: http://www.cle.org.pk/software/ling_resources/UrduLigaturesfromCorpus.htm (accessed on 11 June 2020).
- Ahmed, R.; Musa, M. Preprocessing Phase for Offline Arabic Handwritten Character Recognition. Int. J. Comput. Appl. Technol. Res. 2016, 5, 760–763. [Google Scholar] [CrossRef]
- Borse, R.; Ansari, I.A. Offline Handwritten and Printed Urdu Digits Recognition using Daubechies Wavelet; ER Publication: New Delhi, India, 2015. [Google Scholar]
- Kumar, G.; Bhatia, P.K. Analytical Review of Preprocessing Techniques for Offline Handwritten Character Recognition. In Proceedings of the 2nd International Conference on Emerging Trends in Engineering Trends in Engineering and Management ICETEM, Rohtak India, 21–22 July 2013. [Google Scholar]
- Akhtar, P. An Online and Offline Character Recognition Using Image Processing Methods—A Survey. Int. J. Commun. Comput. Technol. 2016, 4, 102. [Google Scholar] [CrossRef]
- Liu, C.; Yin, F.; Wang, D.; Wang, Q. Online and offline handwritten Chinese character recognition: Benchmarking on new databases. Pattern Recognit. 2012, 46, 155–162. [Google Scholar] [CrossRef]
- Baker, P.; Hardie, A.; McEnery, T.; Cunningham, H.; Gaizauskas, R.J. EMILLE, A 67-Million Word Corpus of Indic Languages: Data Collection, Mark-up and Harmonisation. In Proceedings of the Third International Conference on Language Resources and Evaluation (LREC’02) LREC, Las Palmas, Canary Islands Spain, 29–31 May 2002. [Google Scholar]
- Javed, L.; Shafi, M.; Khattak, M.I.; Ullah, N. Hand-written Urdu Numerals Recognition Using Kohonen Self Organizing Maps. Sindh Univ. Res. J. SURJ 2015, 47, 403–406. [Google Scholar]
- Razzak, M.I.; Hussain, S.A.; Belaid, A.; Sher, M. Multi-font Numerals Recognition for Urdu Script based Languages. Int. J. Recent Trends Eng. 2009.
- Kour, H.; Gondhi, N.K. Machine Learning approaches for Nastaliq style Urdu handwritten recognition: A survey. In Proceedings of the 6th Communication International Systems Conference (ICACCSon) Advanced, Coimbatore, India, 23 April 2020; pp. 50–54. [Google Scholar] [CrossRef]
- Yusuf, M.; Haider, T. Recognition of Handwritten Urdu Digits using Shape Context. INMIC 2004. [Google Scholar] [CrossRef]
- Iqbal, T.; Ali, H.; Saad, M.M.; Khan, S.; Tanougast, C. CapsuleNet for Urdu Digits Recognition. In Proceedings of the 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Metz, France, 18–21 September 2019. [Google Scholar]
- Abdelazeem, S. Comparing Arabic and Latin Handwritten Digits Recognition Problems. Int. J. Comput. Inf. Eng. 2009, 3, 1583–1587. [Google Scholar] [CrossRef]
- Abdelazeem, S.; El-Sherif, E. The Arabic Handwritten Digits Databases ADBase & MADBase. Available online: http://datacenter.aucegypt.edu/shazeem/ (accessed on 14 May 2020).
- Ahmed, S.B.; Hameed, I.A.; Naz, S.; Razzak, M.I.; Yusof, R. Evaluation of Handwritten Urdu Text by Integration of MNIST Dataset Learning Experience. IEEE Access 2019, 7, 153566–153578. [Google Scholar] [CrossRef]
- Ebrahimzadeh, R.; Jampour, M. Efficient Handwritten Digit Recognition based on Histogram of Oriented Gradients and SVM. Int. J. Comput. Appl. 2014, 104, 10–13. [Google Scholar] [CrossRef]
- Sufian, A.; Ghosh, A.; Naskar, A.; Sultana, F.; Sil, J.; Hafizur Rahman, M.M. BDNet: Bengali Handwritten Numeral Digit Recognition based on Densely connected Convolutional Neural Networks. J. King Saud Univ. Comput. Inf. Sci. 2020, 34, 2610–2620. [Google Scholar] [CrossRef]
- Prashanth, D.S.; Mehta, R.V.K.; Sharma, N. Classification of Handwritten Devanagari Number An analysis of Pattern Recognition Tool using Neural Network and CNN. Procedia Comput. Sci. 2020, 167, 2445–2457. [Google Scholar] [CrossRef]
- Ahlawat, S.; Choudhary, A. Hybrid CNN-SVM Classifier for Handwritten Digit Recognition. Procedia Comput. Sci. 2020, 167, 2554–2560. [Google Scholar] [CrossRef]
- Baldominos, A.; Saez, Y.; Isasi, P. Evolutionary Convolutional Neural Networks: An Application to Handwriting Recognition. Neurocomputing 2018, 283, 38–52. [Google Scholar] [CrossRef]
- Sabbour, N.; Shafait, F. A segmentation-free approach to Arabic and Urdu OCR. In Proceedings of the SPIE 8658, Document Recognition and Retrieval XX, 86580N, Burlingame, CA, USA, 3–7 February 2013. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.; Naz, S.; Swati, S.; Razzak, M. Handwritten Urdu character recognition using one-dimensional BLSTM classifier. Neural Comput. Appl. 2017, 31, 1143–1151. [Google Scholar] [CrossRef]
- LeCun, Y. The MNIST DATABASE of handwritten digits. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 14 June 2020).
- Shorten, C.; Khoshgoftaar, T. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Prabhu, R. CNN Architectures—LeNet, AlexNet, VGG, GoogLeNet and ResNet. Available online: https://medium.com/@RaghavPrabhu/cnn-architectures-lenet-alexnet-vgg-googlenet-and-resnet-7c81c017b84 (accessed on 14 June 2020).
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. batch normalization: An empirical study of their impact to deep learning. Multimed. Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Husnain, M.; Missen, M.M.S.; Mumtaz, S.; Jhanidr, M.Z.; Coustaty, M.; Muzzamil Luqman, M.; Ogier, J.M.; Choi, G.S. Recognition of Urdu Handwritten Characters Using Convolutional Neural Network. Appl. Sci. 2019, 9, 2758. [Google Scholar] [CrossRef] [Green Version]
- Chandio, A.A.; Jalbani, A.H.; Leghari, M.; Awan, S.A. Multi-Digit Handwritten Sindhi Numerals Recognition using SOM Neural Network. Mehran Univ. Res. J. Eng. Technol. 2017, 36, 8. [Google Scholar] [CrossRef] [Green Version]
- Malik, S.; Khan, S.A. Urdu online handwriting recognition. In Proceedings of the IEEE Symposium on Emerging Technologies, Islamabad, Pakistan, 18 September 2005. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
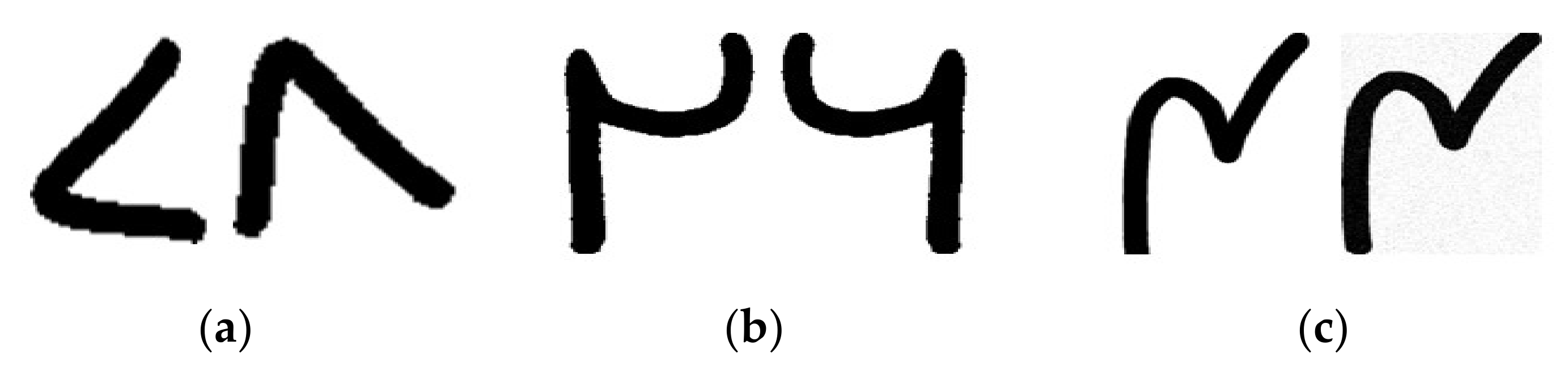{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article Reference | Techniques Applied | Accuracy Achieved |
|---|---|---|
| [19] | Back propagation neural network | 90% |
| [8] | Kohonen self-organization maps | 91% |
| [20] | Shape context-based digit recognition computation | 93% |
| [21] | Fuzzy rule | 97.4% |
| [22] | Capsule-Net | 98.5% |
| Layer | Output Shape | Number of Parameters |
|---|---|---|
| Conv | 32 × 32 × 256 | 7168 |
| Batch Norm | 32 × 32 × 256 | 1024 |
| MaxPool | 16 × 16 × 256 | 0 |
| Conv | 16 × 16 × 128 | 295,040 |
| Batch Norm | 16 × 16 × 128 | 512 |
| MaxPool | 8 × 8 × 128 | 0 |
| Flatten | 8192 | 0 |
| Dense | 90 | 737,370 |
| Dense | 64 | 5824 |
| Dense | 10 | 650 |
| Total parameters | 1,047,588 | |
| Trainable parameters | 1,046,820 | |
| Nontrainable parameters | 768 | |
| Systems | Dataset | Classifier | Accuracy Achieved |
|---|---|---|---|
| [11] | UNHD(Urdu characters and ligatures) | BLSTM | 93.96% |
| [40] | Sindhi handwritten numbers | Self-organizing map neural network | 86.89% |
| [21] | Handwritten Urdu numerals | Rule based technique, HMM | 97.4% (Rule based technique), 96.2% (HMM) |
| [41] | Handwritten Urdu numerals | Daubechies wavelet | 92.05% |
| [42] | Urdu handwritten characters and numerals | Convolutional neural network | 98.3% |
| [26] | Urdu handwritten characters and numerals | Convolutional neural network | 98.3% |
| Our Approach | Handwritten Urdu numerals | GoogLeNet and ResNet | 95.7% |
| Our Approach | Handwritten Urdu numerals | Feature extraction using convolution layer and Softmax Activation for classi cation | 98.41% |
| Feature extraction using convolution layer and SVM for classi cation | 99.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhatti, A.; Arif, A.; Khalid, W.; Khan, B.; Ali, A.; Khalid, S.; Rehman, A.u. Recognition and Classification of Handwritten Urdu Numerals Using Deep Learning Techniques. Appl. Sci. 2023, 13, 1624. https://doi.org/10.3390/app13031624
Bhatti A, Arif A, Khalid W, Khan B, Ali A, Khalid S, Rehman Au. Recognition and Classification of Handwritten Urdu Numerals Using Deep Learning Techniques. Applied Sciences. 2023; 13(3):1624. https://doi.org/10.3390/app13031624
Chicago/Turabian StyleBhatti, Aamna, Ameera Arif, Waqar Khalid, Baber Khan, Ahmad Ali, Shehzad Khalid, and Atiq ur Rehman. 2023. "Recognition and Classification of Handwritten Urdu Numerals Using Deep Learning Techniques" Applied Sciences 13, no. 3: 1624. https://doi.org/10.3390/app13031624
APA StyleBhatti, A., Arif, A., Khalid, W., Khan, B., Ali, A., Khalid, S., & Rehman, A. u. (2023). Recognition and Classification of Handwritten Urdu Numerals Using Deep Learning Techniques. Applied Sciences, 13(3), 1624. https://doi.org/10.3390/app13031624