
RSMDA: Random Slices Mixing Data Augmentation



Abstract
:1. Introduction
2. Related Work
2.1. Dropout
2.2. Data Augmentation
2.2.1. Single-Image-Based Data Augmentation (SIBDA)
- CutOut: CutOut [34] is data augmentation in which a random part of the image is cut with a square and filled with 0, 255, or the mean of the dataset during training. It was introduced with the purpose of recognizing partially or fully occluded object(s).
- Random erasing: Random erasing (RE) [25] is a data augmentation technique in which a rectangular random region of the image is selected at random and erased with a random value with the aim of minimizing overfitting. During training, different occlusion levels are performed not only to improve the performance of the neural network but also to improve the robustness of the model. RE was designed to deal with occlusion in images, thereby forcing the model to learn the erased features. Here, occlusion is where some part(s) of the image is not clear. RE seems similar to CutOut, but the key difference is that RE randomly determines whether to mask out or not, and it determines the aspect ratio and size of the masked region. On the other hand, CutOut does not consider the aspect ratio.
- Hide and Seek: Hide and seek (HS) [32] is another data augmentation technique in which the image is divided into squares of the same size as a grid. During the training at each step, a random number of squares is hidden to force the neural network to focus on the most discriminated parts and learn the relevant features. At each epoch, it gives a different view of the image being modeled to learn the important features.
- GridMask: GridMask [33] is a type of data augmentation in which uniform masking is applied to mask out regions in the image and the mask square size changes at each step. Previously discussed data augmentations, such as a CutOut, RE, and HS, randomly erase the region(s) in which there are high chances that either an object is removed or contextual information is lost, which can potentially harm the performance of the model. To trade off between losing contextual information or object removal and performance, GridMask is introduced.
2.2.2. Multi-Image-Based Data Augmentation
- MixUp: MixUp [35] is a data augmentation that creates a new augmented image using a weighted combination of two images, and label smoothing is performed simultaneously. It demonstrated impressive performance on a variety of tasks.
- CutMix: CutMix [36], a data augmentation method, is introduced to deal with the problems of information loss and the inefficiency of regional dropout methods. In CutMix, a random region of one image is replaced with a patch from another image, and the corresponding labels are mixed as well. It demonstrates high regularization in a wide range of tasks. This method uses only two images.
- Random Image Cropping and Patching Data Augmentation for Deep CNNs (RICAP): RICAP [27] is another data augmentation technique that is similar to CutMix except that it uses four images. RICAP further increases the diversity of the training data, enabling it to learn more features; it has shown good performance. More importantly, the labels of the four images are also mixed.
- Improved Mixed Example Data Augmentation: Improved mixed example data augmentation (IMEDA) [37] is another data augmentation that explores augmentation to check the importance of linearity using non-label preserving data augmentations in its search space. IMEDA explores the number of data augmentations and shows a massive performance gain over the SOTA methods.
- We propose a novel data augmentation technique named random slices mixing data augmentation (RSMDA).
- We propose and investigate three different RSMDA strategies, namely, horizontal (row-wise) slice mixing, vertical (column-wise) slice mixing, and a combination of both.
- We validate this approach using different models’ architectures across different datasets. RSMDA is not only effective in its accuracy performance but also robust against adversarial attacks.
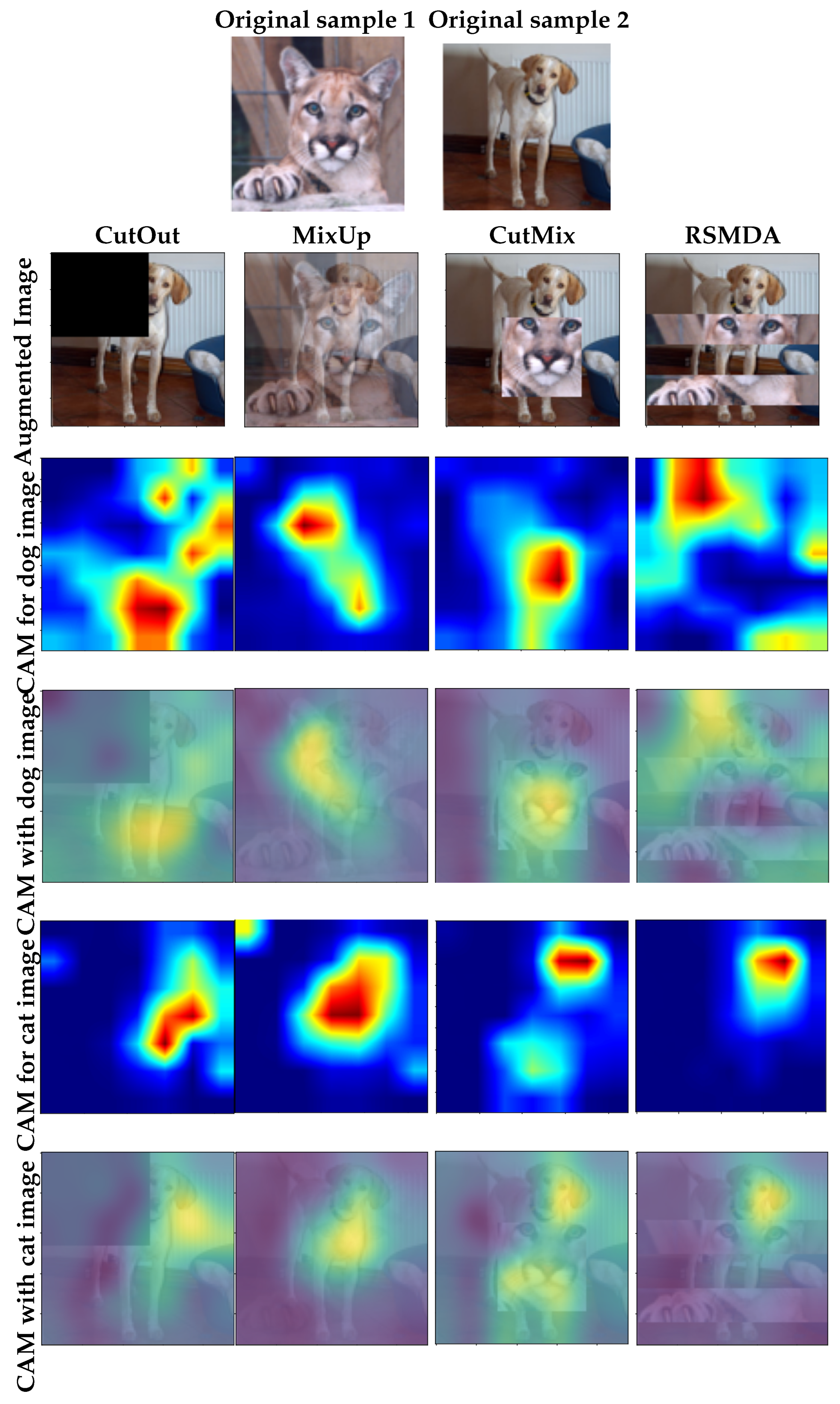
- We investigate the RSMDA hyperparameters in detail, provide analysis, and compare them with SOTA augmentations using class activation maps (CAMs).
- Finally, we provide the full source code for RSMDA in an open repository: https://github.com/kmr2017/Slices-aug (accessed on 8 December 2022).
3. Proposed Method
- Random slices mixing column-wise (RSMDA-C): This is another strategy that we explore, in which we follow the same method used in RSMDA-R, except that we obtain the slices vertically, as shown in Figure 2b.
- Random slices mixing row–column-wise (RSMDA-RC): This is the third strategy. We apply both RSMDA-R and RSMDA-C based on binary randomness to each learning step, as shown in Figure 2c.
4. Experimental Results
4.1. Experimental Setup
4.2. Datasets
4.2.1. FashionMNIST
4.2.2. CIFAR10 and CIFAR100
4.2.3. STL10
4.3. Results
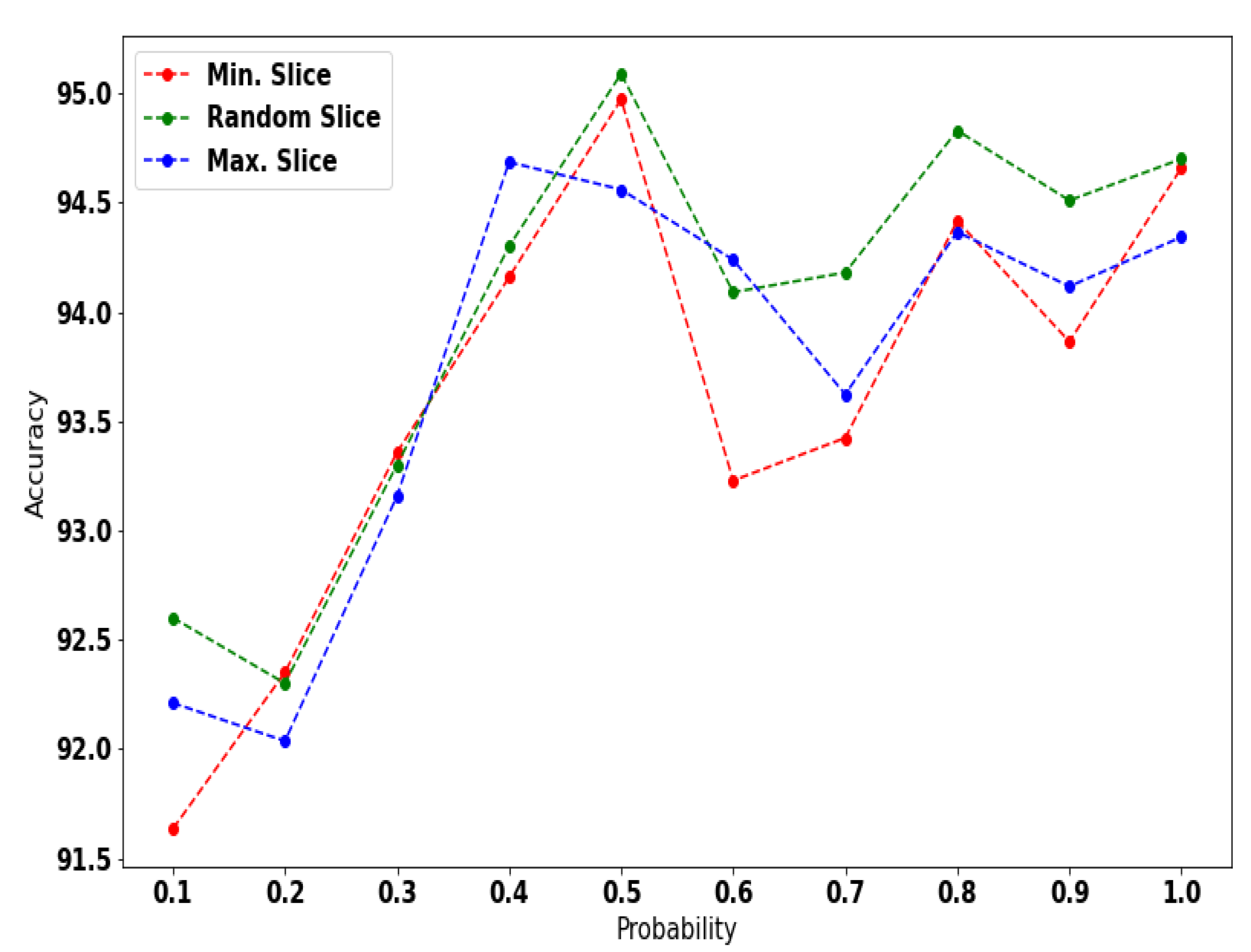
4.3.1. Hyperparameter Study
4.3.2. Classification Results
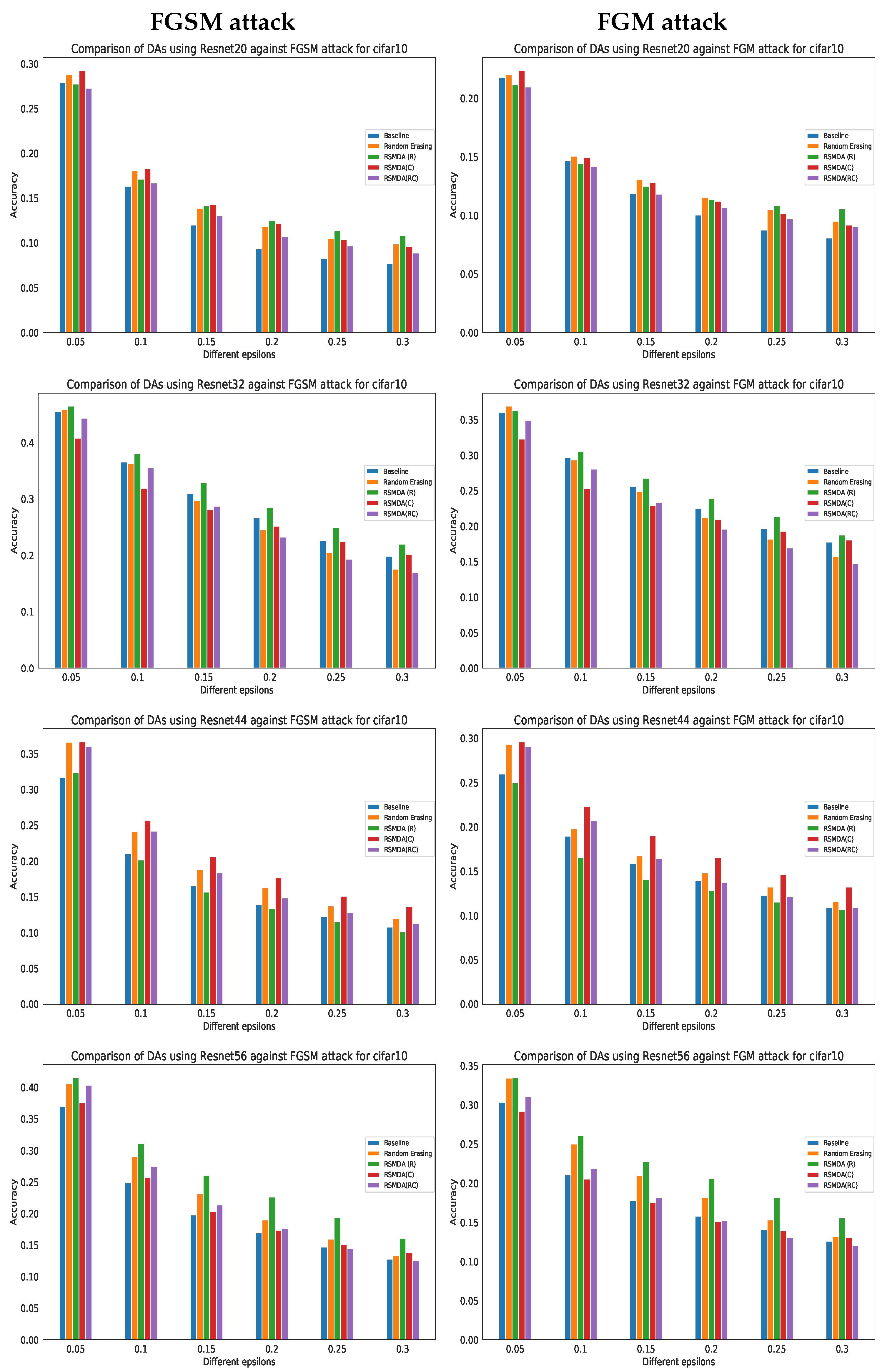
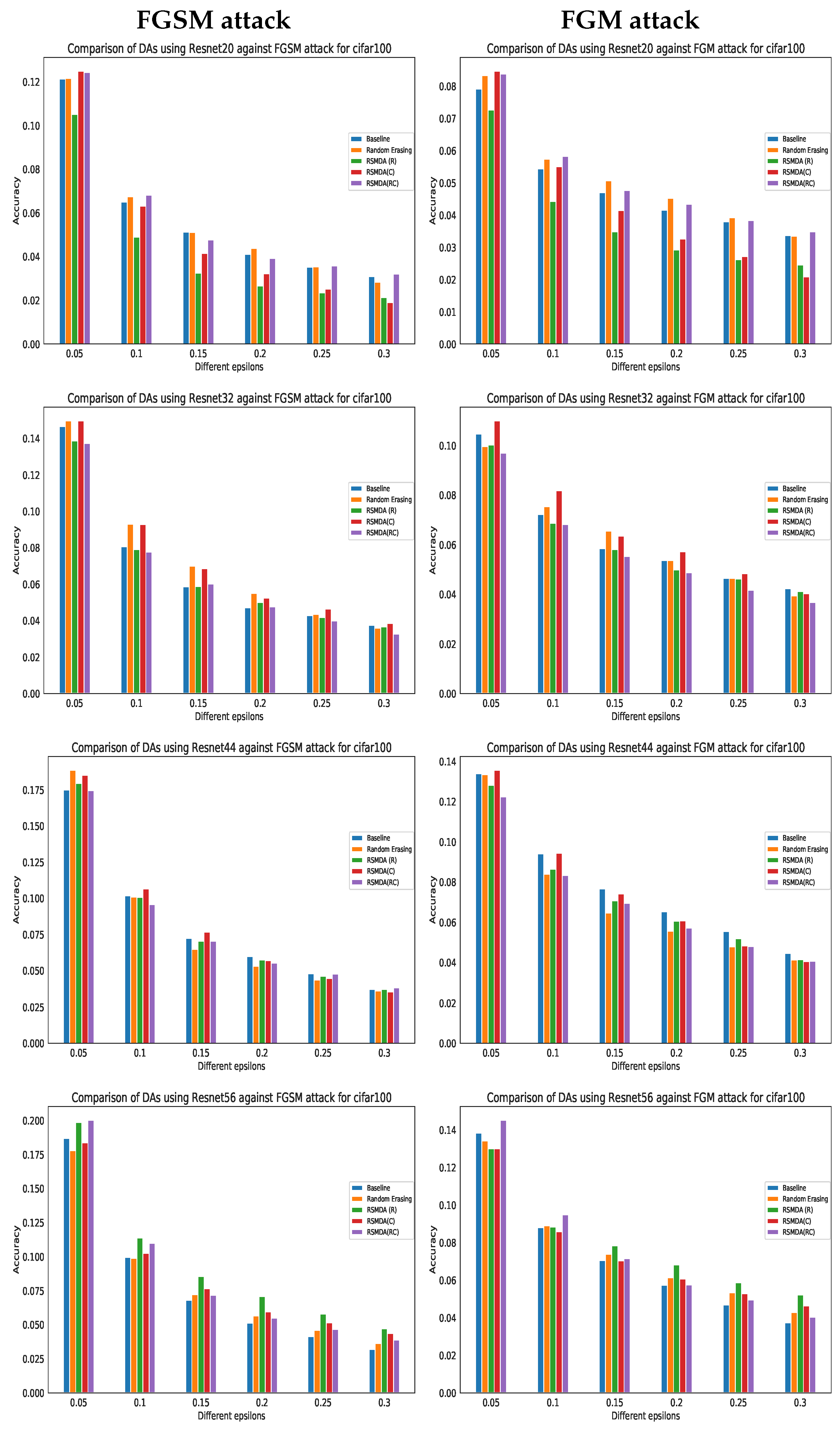
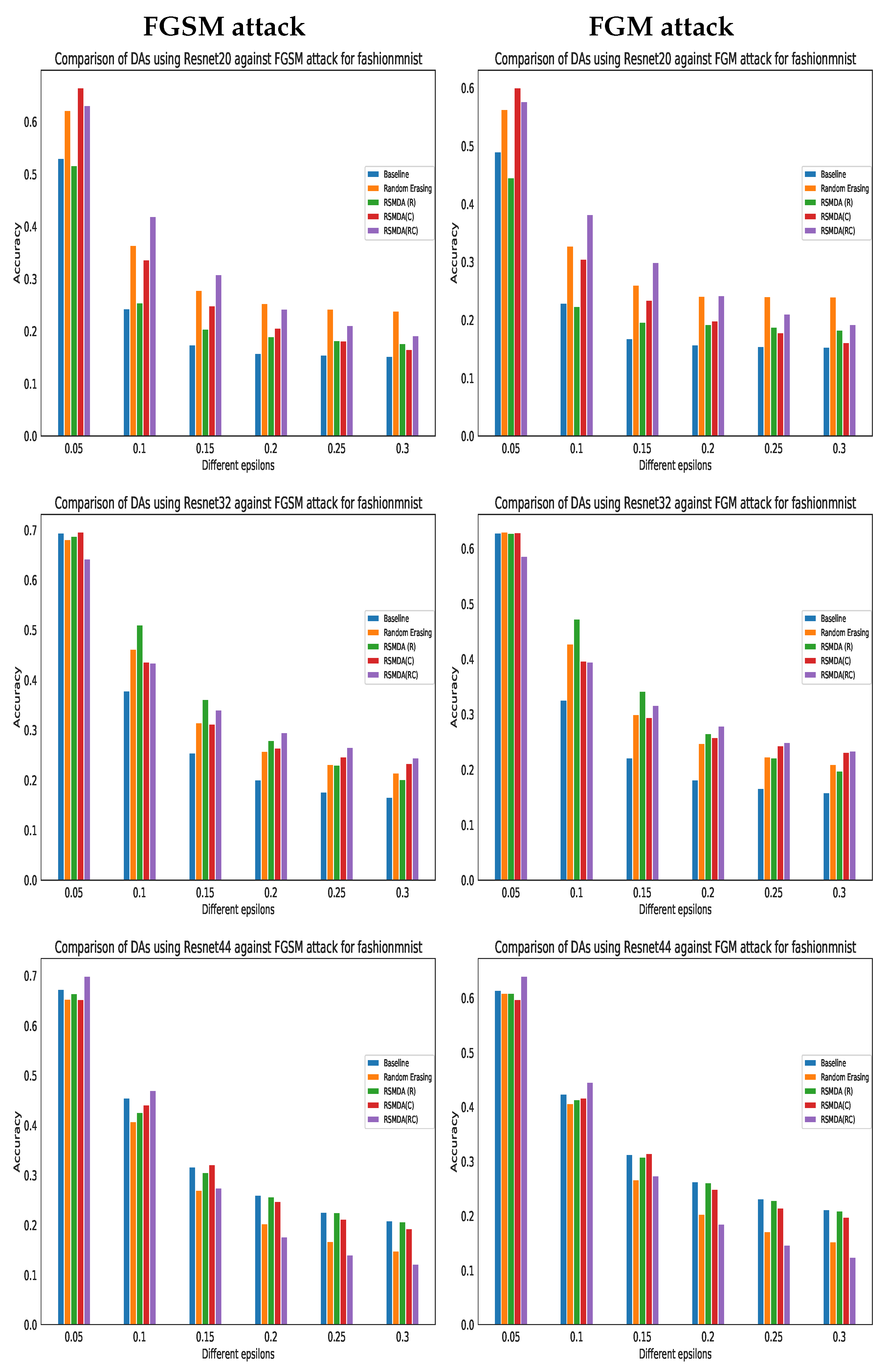
4.3.3. Adversarial Attacks
4.3.4. Class Activation Map (CAM)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, J.; Bedi, P.; Goyal, S.; Shrivastava, A.; Kumar, S. Novel Algorithm for Image Classification Using Cross Deep Learning Technique. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1099, 012033. [Google Scholar] [CrossRef]
- Liu, J.; An, F. Image classification algorithm based on deep learning-kernel function. Sci. Program. 2020, 2020, 7607612. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Meng, F. Research on power equipment recognition method based on image processing. EURASIP J. Image Video Process. 2019, 2019, 57. [Google Scholar] [CrossRef]
- Kumar, T.; Turab, M.; Talpur, S.; Brennan, R.; Bendechache, M. Forged Character Detection Datasets: Passports, Driving Licences And Visa Stickers. Int. J. Artif. Intell. Appl. (IJAIA) 2022, 13, 21–35. [Google Scholar] [CrossRef]
- Ciresan, D.; Meier, U.; Masci, J.; Gambardella, L.; Schmidhuber, J. Flexible, high performance convolutional neural networks for image classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Kumar, T.; Park, J.; Ali, M.; Uddin, A.; Ko, J.; Bae, S. Binary-classifiers-enabled filters for semi-supervised learning. IEEE Access 2021, 9, 167663–167673. [Google Scholar] [CrossRef]
- Khan, W.; Raj, K.; Kumar, T.; Roy, A.; Luo, B. Introducing urdu digits dataset with demonstration of an efficient and robust noisy decoder-based pseudo example generator. Symmetry 2022, 14, 1976. [Google Scholar] [CrossRef]
- Chandio, A.; Gui, G.; Kumar, T.; Ullah, I.; Ranjbarzadeh, R.; Roy, A.; Hussain, A.; Shen, Y. Precise single-stage detector. arXiv 2022, arXiv:2210.04252. [Google Scholar]
- Kumar, T.; Park, J.; Ali, M.; Uddin, A.; Bae, S. Class Specific Autoencoders Enhance Sample Diversity. J. Broadcast Eng. 2021, 26, 844–854. [Google Scholar]
- Roy, A.; Bhaduri, J.; Kumar, T.; Raj, K. A Computer Vision-Based Object Localization Model for Endangered Wildlife Detection. Ecol. Econ. Forthcom. 2022. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Brahnam, S.; Paci, M. An ensemble of convolutional neural networks for audio classification. Appl. Sci. 2021, 11, 5796. [Google Scholar] [CrossRef]
- Hershey, S.; Chaudhuri, S.; Ellis, D.; Gemmeke, J.; Jansen, A.; Moore, R.; Plakal, M.; Platt, D.; Saurous, R.; Seybold, B. Others CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Rong, F. Audio classification method based on machine learning. In Proceedings of the 2016 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Changsha, China, 17–18 December 2016; pp. 81–84. [Google Scholar]
- Aiman, A.; Shen, Y.; Bendechache, M.; Inayat, I.; Kumar, T. AUDD: Audio Urdu Digits Dataset for Automatic Audio Urdu Digit Recognition. Appl. Sci. 2021, 11, 8842. [Google Scholar]
- Turab, M.; Kumar, T.; Bendechache, M.; Saber, T. Investigating Multi-Feature Selection and Ensembling for Audio Classification. arXiv 2022, arXiv:2206.07511. [Google Scholar] [CrossRef]
- Park, J.; Kumar, T.; Bae, S. Search for optimal data augmentation policy for environmental sound classification with deep neural networks. J. Broadcast Eng. 2020, 25, 854–860. [Google Scholar]
- Singh, A.; Ranjbarzadeh, R.; Raj, K.; Kumar, T.; Roy, A. Understanding EEG signals for subject-wise Definition of Armoni Activities. arXiv 2023, arXiv:2301.00948. [Google Scholar]
- Kolluri, J.; Razia, D.; Nayak, S. Text classification using machine learning and deep learning models. Int. Conf. Artif. Intell. Manuf. Renew. Energy (ICAIMRE) 2019. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning–based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Nguyen, T.; Shirai, K. Text classification of technical papers based on text segmentation. In Proceedings of the International Conference on Application of Natural Language to Information Systems, Salford, UK, 19–21 Jun2013; pp. 278–284. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Kukačka, J.; Golkov, V.; Cremers, D. Regularization for deep learning: A taxonomy. arXiv 2017, arXiv:1710.10686. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. Proc. Aaai Conf. Artif. Intell. 2020, 34, 13001–13008. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Takahashi, R.; Matsubara, T.; Uehara, K. Data augmentation using random image cropping and patching for deep CNNs. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2917–2931. [Google Scholar] [CrossRef] [Green Version]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Chen, S.; Dobriban, E.; Lee, J. A group-theoretic framework for data augmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 21321–21333. [Google Scholar]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Acción, Á.; Argüello, F.; Heras, D. Dual-window superpixel data augmentation for hyperspectral image classification. Appl. Sci. 2020, 10, 8833. [Google Scholar] [CrossRef]
- Singh, K.; Yu, H.; Sarmasi, A.; Pradeep, G.; Lee, Y. Hide-and-seek: A data augmentation technique for weakly-supervised localization and beyond. arXiv 2018, arXiv:1811.02545. [Google Scholar]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. Gridmask data augmentation. arXiv 2020, arXiv:2001.04086. [Google Scholar]
- DeVries, T.; Taylor, G. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- Summers, C.; Dinneen, M. Improved mixed-example data augmentation. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1262–1270. [Google Scholar]
- Kumar, T.; Brennan, R.; Bendechache, M. Slices Random Erasing Augmentation. Available online: https://d1wqtxts1xzle7.cloudfront.net/87590566/csit120201-libre.pdf?1655368573=&response-content-disposition=inline%3B+filename%3DSTRIDE_RANDOM_ERASING_AUGMENTATION.pdf&Expires=1674972117&Signature=ThC7JbxC8jJzEQPchixX86VpZwMkalCENMNEEsXuvgtfKsqVspfmkEM89XXh1cjd1PnUAzJbHAw2Gf4WTG7-WD8VzmQwiyuJ3u~ADfswlhW6wb51n2VTgU6M3hLhQFGgWVlUbUUqptbttUU12Nw0QYekjw3fUjm2eS23phjn2HismJS05IcVB6QRyXXUKq1ie2XTRDGixUZLqZCi5OFBCaro5GBZXPMgn1XkJOqKVGDvRTEjgykzgoWx-sZXc0RwUi7CteyXM3YEJM3K2uTFz~wI0OOa8Ff~aEHfiLBGcWASq1Z6aGRtVrDUaXBiSSWD~OcgwlnNW~nKSSzjaegZuQ&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA (accessed on 8 December 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hinton, G.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Ba, J.; Frey, B. Adaptive dropout for training deep neural networks. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Le Cun, Y.; Fergus, R. Regularization of neural networks using dropconnect. Int. Conf. Mach. Learn. 2013, 28, 1058–1066. [Google Scholar]
- Zeiler, M.; Fergus, R. Stochastic pooling for regularization of deep convolutional neural networks. arXiv 2013, arXiv:1301.3557. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, Ma, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Han, D.; Kim, J.; Kim, J. Deep pyramidal residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5927–5935. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Others Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Tront, Toronto, ON, Canada, 2009. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K. Deep networks with stochastic depth. Eur. Conf. Comput. Vis. 2016, 9908, 646–661. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Mitliagkas, I.; Lopez-Paz, D.; Bengio, Y. Manifold mixup: Better representations by interpolating hidden states. Int. Conf. Mach. Learn. 2019, 97, 6438–6447. [Google Scholar]
- Yamada, Y.; Iwamura, M.; Akiba, T.; Kise, K. Shakedrop regularization for deep residual learning. IEEE Access 2019, 7, 186126–186136. [Google Scholar] [CrossRef]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Agarwal, A.; Singh, R.; Vatsa, M. The Role of’Sign’and’Direction’of Gradient on the Performance of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 646–647. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 2921–2929. [Google Scholar]
- Jiang, P.; Zhang, C.; Hou, Q.; Cheng, M.; Wei, Y. Layercam: Exploring hierarchical class activation maps for localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef] [PubMed]
- Jung, H.; Oh, Y. Towards better explanations of class activation mapping. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1336–1344. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Baselines | RE | RSMDA (R) | RSMDA(C) | RSMDA(RC) |
|---|---|---|---|---|---|
| Fashion-MNIST | |||||
| ResNet20 | 6.21 ± 0.11 | 5.04 ± 0.10 | 4.91 ± 0.12 | 4.72 ± 0.13 | 4.76 ± 0.06 |
| Resnet32 | 6.04 ± 0.13 | 4.84 ± 0.12 | 4.81 ± 0.17 | 4.65 ± 0.15 | 4.81 ± 0.12 |
| Resnet44 | 6.08 ± 0.16 | 4.87 ± 0.1 | 4.07 ± 0.14 | 4.784 ± 0.01 | 4.9 ± 0.25 |
| Resnet56 | 6.78 ± 0.16 | 5.02 ± 0.11 | 5.00 ± 0.19 | 5.00 ± 0.2 | 5.09 ± 0.59 |
| CIFAR10 | |||||
| Resnet20 | 7.21 ± 0.17 | 6.73 ± 0.09 | 7.18 ± 0.13 | 7.38 ±0.254 | 7.48 ± 1.08 |
| Resnet32 | 6.41 ± 0.06 | 5.66 ± 0.10 | 6.31 ± 0.14 | 6.06 ± 0.101 | 6.21 ± 0.76 |
| Resnet44 | 5.53 ± 0.0 | 5.13 ± 0.09 | 5.09 ± 0.10 | 5.26 ± 0.262 | 5.51 ± 0.06 |
| Resnet56 | 5.31 ± 0.07 | 4.89 ± 0.0 | 5.02 ± 0.11 | 5.28 ± 0.02 | 5.97 ± 0.47 |
| VGG11 | 7.88 ± 0.76 | 7.82 ± 0.65 | 7.80 ± 0.65 | 7.82 ± 0.27 | 7.81 ± 0.57 |
| VGG13 | 6.33 ± 0.23 | 6.22 ± 0.63 | 6.18 ± 0.54 | 6.31 ± 0.266 | 6.20 ± 0.38 |
| VGG16 | 6.42 ± 0.34 | 6.21 ± 0.76 | 6.20 ± 0.34 | 6.26 ± 0.196 | 6.35 ± 0.76 |
| CIFAR100 | |||||
| Resnet20 | 30.84 ± 0.19 | 29.97 ± 0.11 | 30.18 ± 0.27 | 30.28 ± 0.33 | 30.46 ± 0.79 |
| Resnet32 | 28.50 ± 0.37 | 27.18 ± 0.32 | 27.08 ± 0.34 | 28.22 ± 0.22 | 28.42 ± 0.12 |
| Resnet44 | 25.27 ± 0.21 | 24.29 ± 0.16 | 24.49 ± 0.23 | 25.21 ± 0.57 | 25.08 ± 0.13 |
| Resnet56 | 24.82 ± 0.27 | 23.69 ± 0.33 | 23.35 ± 0.26 | 24.33 ± 0.12 | 24.91 ± 0.57 |
| VGG11 | 28.97 ± 0.76 | 28.73 ± 0.67 | 28.26 ± 0.75 | 28.92 ± 0.33 | 28.29 ± 0.43 |
| VGG13 | 25.73 ± 0.67 | 25.71 ± 0.54 | 25.71 ± 0.56 | 25.72 ± 0.26 | 25.72 ± 0.42 |
| VGG16 | 26.64 ± 0.56 | 26.63 ± 0.75 | 26.61 ± 0.65 | 26.63 ± 1.77 | 26.63 ± 0.66 |
| STL10 | |||||
| VGG11 | 22.29 ± 0.13 | 22.27 ± 0.21 | 20.68 ± 0.23 | 21.49 ± 0.02 | 20.79 ± 0.33 |
| VGG13 | 20.64 ± 0.26 | 20.18 ± 0.23 | 19.91 ± 0.92 | 19.60 ± 0.12 | 19.7 ± 0.23 |
| VGG16 | 20.62 ± 0.34 | 20.12 ± 0.65 | 20.09 ± 0.23 | 20.35 ± 0.03 | 20.49 ± 0.44 |
| PyramidNet-200 | Top-1 | Top-5 |
|---|---|---|
| (Params: 26.8 M) | Err | Err |
| Baseline | ||
| + StochDepth [50] | ||
| + Label smoothing [51] | ||
| + Cutout [34] | ||
| + Cutout + Label smoothing | ||
| + DropBlock [8] | ||
| + DropBlock + Label smoothing | ||
| + Mixup ( [35] | ||
| + Mixup ( [35] | ||
| + Manifold Mixup ( [52] | ||
| + Cutout + Mixup ( | ||
| + Cutout + Manifold Mixup | ||
| + ShakeDrop [53] | ||
| + RSMDA(R) | ||
| + CutMix |
| Model | Params | Top-1 | Top-5 Err |
|---|---|---|---|
| PyramidNet-110 [46] | |||
| PyramidNet-110+ RSMDA | |||
| PyramidNet-110+ CutMix | |||
| ResNet-110 | |||
| ResNet-110+ RSMDA | |||
| ResNet-110+ CutMix |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, T.; Mileo, A.; Brennan, R.; Bendechache, M. RSMDA: Random Slices Mixing Data Augmentation. Appl. Sci. 2023, 13, 1711. https://doi.org/10.3390/app13031711
Kumar T, Mileo A, Brennan R, Bendechache M. RSMDA: Random Slices Mixing Data Augmentation. Applied Sciences. 2023; 13(3):1711. https://doi.org/10.3390/app13031711
Chicago/Turabian StyleKumar, Teerath, Alessandra Mileo, Rob Brennan, and Malika Bendechache. 2023. "RSMDA: Random Slices Mixing Data Augmentation" Applied Sciences 13, no. 3: 1711. https://doi.org/10.3390/app13031711
APA StyleKumar, T., Mileo, A., Brennan, R., & Bendechache, M. (2023). RSMDA: Random Slices Mixing Data Augmentation. Applied Sciences, 13(3), 1711. https://doi.org/10.3390/app13031711