1. Introduction
Autonomous Underwater Vehicles (AUVs) and underwater vehicle-manipulator systems are attracting more attention in marine survey and intervention applications, such as structure inspection, cleaning and repairing, waste searching and salvage, deepwater rescuing, sediment sampling, etc. [
1,
2,
3,
4]. However, possible thruster degeneration and damage, various payloads, and disturbances from currents inevitably bring tremendous uncertainties to AUV dynamics models [
5]. In addition, other constraints, such as input dead zones and saturations, make it difficult to tune the controller parameters [
6]. This paper explores the feasibility of model-free reinforcement learning approaches to these issues in underwater AUV position regulation problems.
Control problems subject to uncertainties have been investigated over the years. For example, the adaptive controller can to model the uncertainties online, and forces the controlled AUV systems to behave as some given reference models [
7]. The adaptation is based on current states and errors as inputs, while long-term optimality is often neglected. The backstepping controller can guarantee system stability through its design processes but requires a sufficiently accurate dynamics model [
8]. Otherwise, the control gain would be too large for real systems. The controller based on sliding mode requires sufficient time to reach the sliding surface and provide robustness [
9]. These above-mentioned approaches may have provable stabilities without considering the dead zones and saturations of the control inputs.
To be applicable to dynamical systems with input saturations, many existing control approaches assume that the model mismatch is small. Then, these controllers have sufficient margins to suppress uncertainties and input constraints, offering stability to the controlled AUV systems. When applied to real systems, the controller parameters have to be re-tuned according to the altered dynamical system. More importantly, the assumption of small differences in dynamics models may not hold for shallow-water AUVs. In underwater applications, water weeds may tangle one or more thrusters, limiting their maximal thrusts, and the AUVs may be subject to various payloads. All these factors make the model uncertainties quite large.
Controllers based on deep learning have been studied in [
10]. Classical model-free RL can overcome the above-mentioned issues of uncertainties, but often relies on a large number of samples to train controllers from scratch. Millions of interactions between the controller and the targeted system are time-consuming and may damage the system itself. Therefore, it is preferable to train a controller in a simulated system and then apply it to a real AUV system. However, the trained controllers often perform unsatisfactorily on real AUVs. This is because the distributions of the state and AUV dynamics in numerical simulations do not match those of real AUVs. Much effort has been devoted to transferring the controller to a different system, referred to as transfer RL [
11]. In the context of transfer RL, the trained controller is obtained offline from a source domain with source dynamics. The trained controller is referred to as the source controller. Then, the source controller is transferred to a target controller and is applied to a target system in an online target domain, where the target system is often unknown.
The idea of transferring controllers to a different system has been explored in manipulator control [
12]. Recently, a model-free transfer RL on AUV control was validated on numerically simulated AUVs [
13]. In the transfer reinforcement learning of robot control, the source domain and source dynamics are often numerically simulated, while the target domain and the target dynamics pertain to the real systems [
14]. The source controller is trained for the source dynamics in the source domain and transferred to obtain the target controller to control the target dynamical system in the target domain. In another type of transfer reinforcement learning, the source domain and target domain may share the same dynamics model and state spaces but differ in the definitions of objective functions [
15], which is not discussed in this paper.
The correlation across domains is key to transferring the source controller to the target domain [
16]. Domain-invariant essential features and structures were studied to build and transfer the controller across domains [
17]. The correspondence between domains can be found by analyzing the unpaired trajectories between two different domains [
18].
Another issue for sim-to-real transfer RL is robustness. Domain randomization algorithms vary the parameters of the numerically simulated dynamics models and obtain a controller through RL [
19]. RL based on domain randomization [
20] is a popular technique to reduce domain and dynamics mismatches. Instead of directly adding Gaussian noise to the outputs of the simulated dynamics models, the noise is added to the parameters of dynamics models, allowing for more diverse distributions that can cover the actual distributions of the AUV states and dynamics. The trained controller is robust to the simulated dynamics, which has a high probability of covering the actual manipulator states and dynamics. Therefore, the trained controller has better robustness than classical RL. This approach has been successful in the control of manipulators, where an accurate dynamics model is required and a friction model is considered [
20].
It is preferable to adjust the parameter noise in the domain randomization according to the actual data. The adaptive domain randomization approach adjusts the weight of parameter particles to narrow the gap between simulators and real AUV dynamics [
21]. However, the effectiveness of such a strategy is based on an accurate parametric dynamics model. This assumption may not be suitable for AUVs. Existing AUV models have more unmodeled dynamics, which are difficult to describe in the simulations via domain randomization techniques. Therefore, it is desirable to quickly modify the simulator to behave as a real AUV through a data-driven module. Still, the process of obtaining a data-enabled module to close the gap between source dynamics and target dynamics may take a tremendous amount of time. Therefore, it is better if only a few samples of the real AUVs are required to quickly adapt the source controller.
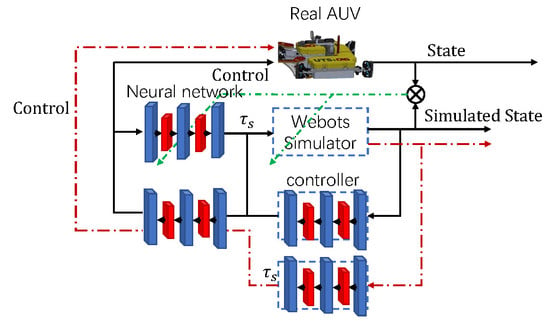
State-of-the-art algorithms based on feedback control may not be able to deal with dynamics that are suffering significant changes, such as shifts in control channels or thruster failures. These changes in dynamics may occur online and jeopardize the AUV system if the same controller is used. On other hand, reinforcement learning approaches require extensive interactions between controllers and the targeted AUV and may adapt themselves to the new dynamics. This paper proposes a transfer RL approach via data-informed domain randomization (DDR) to efficiently adapt the source controller. The contributions are as follows.
- (i)
Data-informed domain randomization. In this paper, the numerical dynamics model (the source model) is built on a Webots simulator. According to the collected data of a real AUV, the control inputs and state outputs regarding the source model are quite different from those of the target model. A neural network is aggregated onto the Webots source model and is quickly adapted online to match the difference between the source model and the target model, reducing the gap between the source and target dynamics.
- (ii)
Controller adaptation mechanism. Based on the matching from the proposed DDR, the correlation between the source and target controllers is used to quickly align the source control signals to the target ones. Since the source task and domain task only differ in dynamics models, the mismatch is captured by a small neural network that can be retrained in less than a second with newly collected data.
- (iii)
Validation through numerical simulations and tank experiments. The proposed RL via DDR was validated by numerical simulations of AUVs with manually designed and mismatched dynamics models: these have different thruster configurations and capabilities. RL via DDR was also tested in a sim-to-real transfer setting, where the transferred controller was tested for an AUV in a tank and the parameters of the AUV were varied.
The remainder of this paper has the following structure. The position regulation problem of an AUV and the transfer RL problem are introduced in
Section 2.
Section 3 outlines the algorithm of classical RL, followed by the DDR approach, and RL via DDR in
Section 4.
Section 5 summarizes the simulation results of transfer RL on the AUVs in the Webots simulator and results on sim-to-real experiments. At last, the discussion and conclusions are given in
Section 6.
2. Problem Formulation
This paper studies the pose regulation problem of the AUV subject to model uncertainties and other input constraints, such as dead zones and input saturations. Let
denote the earth-fixed reference frame and
denote the body-fixed reference frame [
1], as shown in
Figure 1. Axis
and Axis
are in the horizontal plane, Axis
is the gravity direction. The body-fixed frame
is attached to the AUV center and the
axis coincides with the AUV heading. The
axis is along the starboard direction. The AUV pose in the frame
is defined as its position
and attitude
. Similar to many AUVs, the restoring force is often sufficiently large to maintain its roll
and pitch
close to zero under all circumstances. The restoring force can be manually designed by adjusting the distance between the mass center and the buoyancy center of the AUV.
As a result, in this paper, the studied AUV is described by motions of four Degrees Of Freedom (DOFs), including the linear motions along the
,
, and
directions and the yaw motion around the
axis. Then, the AUV state pose
with respect to the earth-fixed frame
is redefined as
where
,
, and
are the AUV’s position, and
denotes the AUV’s heading in the earth-fixed frame. Then, the AUV’s velocity
in
is defined as
where
,
, and
are translational velocities in the x-, y-, and z-axes in the inertial frame, and
is the angular velocity along the z-axis in the inertial frame. Then, the generalized velocity in
is given as
where
and
denotes the transform from Frame
to Frame
. Let the generalized control
from lumped thrusts in Frame
be denoted as
, which may not act through the center of mass. In fact, the mapping between thrusts to the generalized control
may not be accurately known, due to manufacturing issues.
The dynamics model of the AUV is often described in the body frame [
22] as
where
denotes the inertia matrix with added mass from motion in the water,
denotes the coefficient matrix of the drag forces,
denotes the Coriolis matrix, and
is the lumped vector of gravity and buoyancy. The value of
can be assumed to be constant, while the values of other matrices are partially determined by the velocities of the AUV and water current, and are, therefore, difficult to estimate. The dynamics model in Equation (
1) only captures the main aspects of the actual system under mild conditions, leaving some effects unmodeled, such as thruster dynamics. The control inputs
are subject to constraints from the phenomena of saturations and dead zones, which are, respectively, given by
where
and
denote the saturation bounds of the control inputs,
denotes the absolute operation, and
denotes the dead band. Let
denote the set of control that satisfies Equation (
2). However, the feasible set
may not be accurately estimated due to varying power supply and current conditions.
Problem 1 (Position Regularation Problem).
Design a controller that can bring the AUV starting at to the origin , subject unknown dynamics model (1), and the constraints of the dead zones and saturations (2). This paper explores the feasibility of RL techniques to train a controller from numerical simulations built on Equation (
1). The continuous-time model in (
1) is converted into a discrete-time model by Taylor’s first-order expansion, as shown below:
where
and
is the sampling time. The forward dynamics model in (
3) is denoted as
.
This model can be simulated with estimates of unknown parameters by the Webots simulator and the controller can be trained to solve Problem 1 of the simulated system (
3). The controller
outputs the control vector
at time
t, i.e.,
where
is the error of position regulation viewed in the body frame and is obtained by
The transformation matrix transforms a point in the body frame to the earth-fixed frame. The controller maps from the AUV velocity and position errors to control inputs. Let and refer as the AUV state at time t. It is assumed that the AUV state can be acquired with small noises at high frequencies.
The controller trained in the source domain
under the source dynamics models
(see Equation (
3)) is denoted as
, referred to as the source controller. The source controller would be applied to a target dynamical system
in a target domain
. The forward dynamics model
presents a real AUV system or a simulated AUV with a different dynamics model. Since the direct application of
on
brings unsatisfactory results,
has to be transferred to obtain
for better performance.
Problem 2 (Controller Transfer Problem). Design an approach to learn a source controller for the source dynamics and to transfer to the target dynamical system and obtain a target controller , such that the Problem 1 of the target system can be solved by .
Model-free RL can deal with uncertainties and train controllers on deterministic dynamical systems with various parameters to improve the stability of the trained controller the. However, dynamics models from through-parameter randomization may not cover those in the target domain. To this end, in this paper, a data-informed domain randomization approach is developed to solve Problem 2. In the meantime, the model mismatches between the source and target dynamics models have to be quickly estimated online to efficiently adjust the controller .
3. Reinforcement Learning
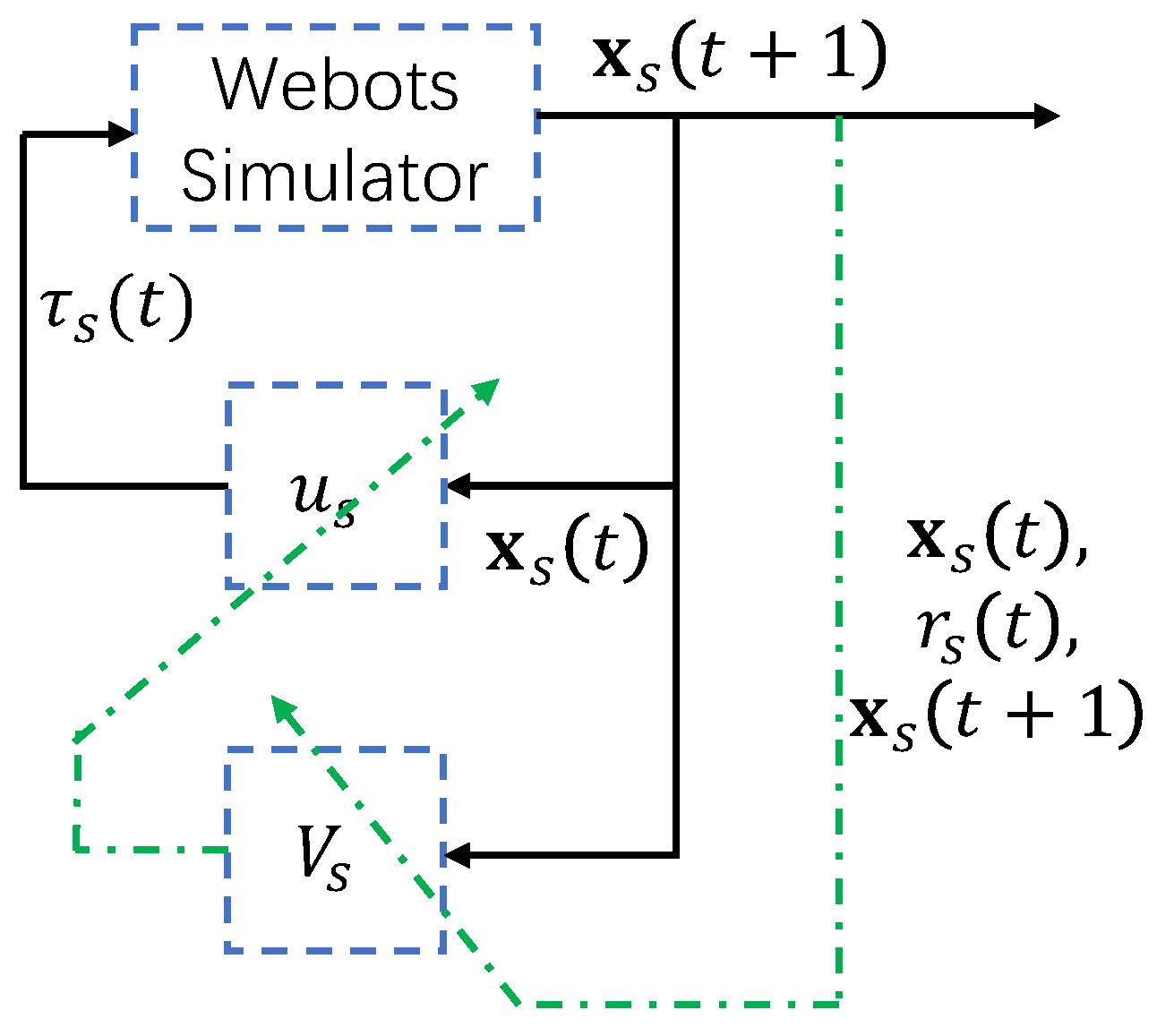
This section briefly describes the RL approach to solve Problem 1 of the simulated AUV. As shown in
Figure 2, the learning procedure interacts with the simulator and collects the trajectories and rewards. The task in Problem 1 is converted to an optimization problem as
where
is a discount factor that penalizes long-term rewards and the reward function
R is defined as follows.
where
denotes
-norm. The term
is the regulation error on positions,
is the AUV’s generalized velocity and it has to be zero when the AUV is at the origin in Frame
, and
denotes the control inputs. The weights
,
, and
are positive parameters and are defined by users. In this paper, they were chosen such that
. The reward function has to be designed or learned to reflect the control perpurse, which is a hot topic as it affects the convergence process in the learning and stability performance of the AUV [
23].
The optimization of the objective (
5) is solved against the equality constraints from the AUV dynamics model (
3) and the inequality constraints from the control dead zones and saturations (
2), outputting the source controller
. These two types of constraints are simulated in the Webots simulator and are rediscovered by the interaction between RL and the simulator by the data
, where
is the index set.
RL is essentially a exploration-and-exploitation algorithm that updates its controller through interactions between the learning agent and the simulator (i.e.,
). After being fitted in Markovian decision processes, the objective function is the cumulated rewards and should be maximized. The reward function is defined in Equation (
5) [
24]. In the
tth iteration, the control inputs
are chosen by the controller
based on the state
(i.e., the current regulation error
and velocities
). The simulator receives the control inputs
and outputs the AUV state
after a one-step simulation and a reward value defined in Equation (
6). The obtained data
are used to update the controller network
and the critic network
, as shown in
Figure 2. The critic
is essentially the objective function evaluated at the state
, conditioned on the controller
, which is not optimal before the convergence of the learning process. The controller
is then updated by maximizing the critic
at given
. The procedures are briefly outlined in Algorithm 1.
While there are many methods to train the controller network, this paper adopts the Soft Actor-Critic (SAC) [
25], which is an open-source off-policy learning algorithm. As reported by many researchers, SAC can achieve sufficient results in benchmark problems.
| Algorithm 1: Learning Source Controller Network |
![Applsci 13 01723 i001]() |
5. Simulation and Experimental Results
The proposed transfer reinforcement-learning-based data-informed domain randomization was tested in numerical simulations and experiments on a real AUV in a lab tank. In both cases, the source domain was the numerical simulations conducted in Webots, where the mass of the AUV was set as 12 kg. The dynamics model of the simulated AUV is given in Equation (
3), with neutral buoyancy. As shown in
Figure 7, the AUV was equipped with six thrusters, each of which can output thrust within
N. The dead band was chosen as
N. As in
Section 2, the AUV is able to move in the
x,
y, and
z directions of the body frame and rotate along the
z axis. In addition, the control input is mapped to PWM signals of four dimensions. An example of the numerical simulation is depicted in
Figure 8, where the origin
in the earth-fixed frame is illustrated as a small red ball.
A source policy was trained by RL through interactions with in the source domain. In each episode, the initial AUV pose and velocities were randomly sampled from a set, where the positions were within a box of and the velocities were within a box of . The controller network output the four-dimensional PWM signal vector, which was converted to a generalized force in the body frame .
In the numerical simulations used to train the source controller, the generalized mass matrix is given as
The coefficient matrix of the drag term is
and the Coriolis matrix
was assumed to be zero. The parameters can be found in
Table 1.
The target domains differ in the numerical simulation tests and the experimental tests. In the numerical simulation tests, the target domain and target dynamics were again simulated in the Webots simulator, subject to parameters and configurations quite different from the simulated source domain and the source dynamics. The tested scenarios in the case are referred to as sim-to-sim transfer tests. In the experimental tests, the target domain and the target dynamics were of the real AUV in the lab tank, the details of which are introduced later.
5.1. Sim-to-Sim Tests
To test the proposed transfer RL via DDR, three scenarios with manually designed model mismatches were simulated. These scenarios were manually designed to reflect possible changes in the real AUV dynamics due to some sudden events. The first scenario involves changing the pose configurations of two thrusters to create a model mismatch between the source dynamics model
and the target dynamics model
. As shown in
Figure 9 and
Figure 10, the source controller
was unable to stabilize the AUV with the target dynamics. This is because the changes in the pose configurations of thrusters with respect to the center of mass introduce a shift in the mapping, from the thrusts to the generalized. The mapping from
to
was quickly learned by a few episodes of data collection regarding the target dynamics. During these episodes, the performance of the position regulation in these episodes was poor and was not analyzed. After that, the mapping
H was updated and the resultant
was able to stabilize the AUV of the target dynamics, as shown in
Figure 9. To illustrate the effectiveness of transfer RL, the trajectories of the AUV in the target domain under
and
are shown in
Figure 10. The dashed line represents the trajectory obtained by
, and the solid line represents the one obtained by
. Let the error of position regulation be defined as the L2 norm of the AUV state. The errors of regulating AUV positions from
and
are shown in
Figure 9. The disturbance effects and control forces are shown in
Figure 11.
A common issue is that the characteristics of a thruster may gradually change during its lifetime or vary suddenly due to certain events. In the second scenario, the gain and the maximum thrust of some thrusters were manually designed to simulate the case in which some thrusters were entangled by some seaweeds. As shown in
Figure 12, when the source controller
was tested on the target dynamics
, the reduced gain of some thrusters introduced additional unwanted torque along
z axis, making the AUV oscillate its heading. The mapping from
to
was quickly learned over a few episodes. Again, the performance of the position regulation in these episodes was not analyzed. The trajectories of the AUV in the target domain under
and
are shown in
Figure 12. The errors when regulating AUV positions from
and
are shown in
Figure 13.
The third scenario simulated an extreme case, where one of the four horizontal thrusters was damaged and a second thruster suddenly changed its phase in the PWM driver, causing it to rotate in the opposite direction. In this scenario, classical controllers such as PID or adaptive controllers may fail, since these methods often assume that the system reserves the positiveness of the gain matrix. When one of the thrust outputs forces opposite to the desired direction, the AUV system is easily destabilized. After the mapping
H was updated, the transferred controller
was able to stabilize the AUV in the target domain, as shown in
Figure 14. The trajectories of the AUV in the target domain under
and
are shown in
Figure 14. When one of the horizontal thrusters is damaged, the horizontal motion is still fully actuated in a horizontal plane, allowing for
G and
H to be mapped. The position error is shown in
Figure 15. After a quick test, the proposed approach is unstable the AUV if two horizontal thrusters are damaged.
It has been observed that the mapping G can be learned within a few episodes, with each episode lasting for 20 s. The results from three scenarios show that DDR is able to transfer the source controller to the target controller , by creating mappings G and H across the source dynamics and target dynamics.
Then, for each scenario, approximately
initial AUV states were randomly sampled and the resultant trajectories of AUV were recorded. The stable performance of the
j trajectory is given as
Then, the average performance is given as
and the variance
can also be obtained. The mean and variance of
with respect to all above-mentioned scenarios are illustrated in
Figure 16a–c and
Table 2.
5.2. Sim-to-Real Tests
The proposed data-informed domain randomization approach was applied to an underwater robot built on BlueRov2 from Blue Robotics, Inc. (Torrance, CA, USA), as shown in
Figure 17a. It is a tethered ROV with six thrusters. With the given thruster configuration, the ROV is able to translate in three directions, roll, and yaw. The ROV is designed to have a sufficient restoring force, to keep itself horizontal. The ROV communicates with a laptop through the Robot Operating System (ROS) and receives thruster commands in the form of PWM signals. In order to provide real-time state estimation of the ROV, an underwater optical motion capture system from Nokov was implemented, which also communicates via ROS and publishes the pose topic in the form of three-dimensional vectors and quaternions. Since the field of view of cameras is often small in underwater applications, the motion capture system relies on 12 underwater cameras mounted on the walls of the tank. In addition, due to the short visibility distance, the reflective markers are of 30 mm, as shown in
Figure 17b.
The cameras emit blue lights (as shown in
Figure 18a) and capture the pose of a rigid frame (as shown in
Figure 18b) built on markers at 60 Hz. The motion capture system was calibrated with an L-shaped calibrator, which consists of four markers placed in the middle of the pool. The positioning system can reach a sub-centimeter resolution.
The laptop receives the pose estimation from the motion capture system, implements the proposed RL approach, and sends the control signals to the ROV. The whole system is referred to as the testbed of the “AUV”. In the future, a sonar-based localization approach and the proposed transfer RL algorithm will be implemented in the updated hardware of the ROV, making it an AUV.
The dynamics model of the real AUV (i.e., the target dynamics model) is jointly determined by the body morphology and AUV velocities. The mass and other parameters are difficult to estimate. Note that only the dead zones and the saturation of the thrusters were simulated; however, the complex dynamics of the thrusters were not simulated in the source dynamics [
26]. Therefore, there mismatches between the source dynamics model and the target model are inevitable. In addition, external disturbances were generated by a propeller fixed to the tank and an example of external disturbances is shown in
Figure 19. Note that, when testing the algorithm, the AUV was detached from the force-torque sensor and the disturbance values are unknown.
In one of the experimental tests, the AUV started from the position
. Two trajectories were obtained: one
obtained by
and the second
obtained by
. Both trajectories are illustrated in
Figure 20a, where
is shown by the red dashed line and
by the blue solid line. The trajectories demonstrated that the transferred controller
successfully regulated the AUV position, while the controller
was unable to stabilize the AUV around the origin
. The position regulation errors from both trajectories are shown in
Figure 20b. The transferred controller
stabilized the AUV in a sphere of radius
mm at the origin
.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}