
A Multi-Attention Approach Using BERT and Stacked Bidirectional LSTM for Improved Dialogue State Tracking

 ,
,  ,
,  and
and
Abstract
:1. Introduction
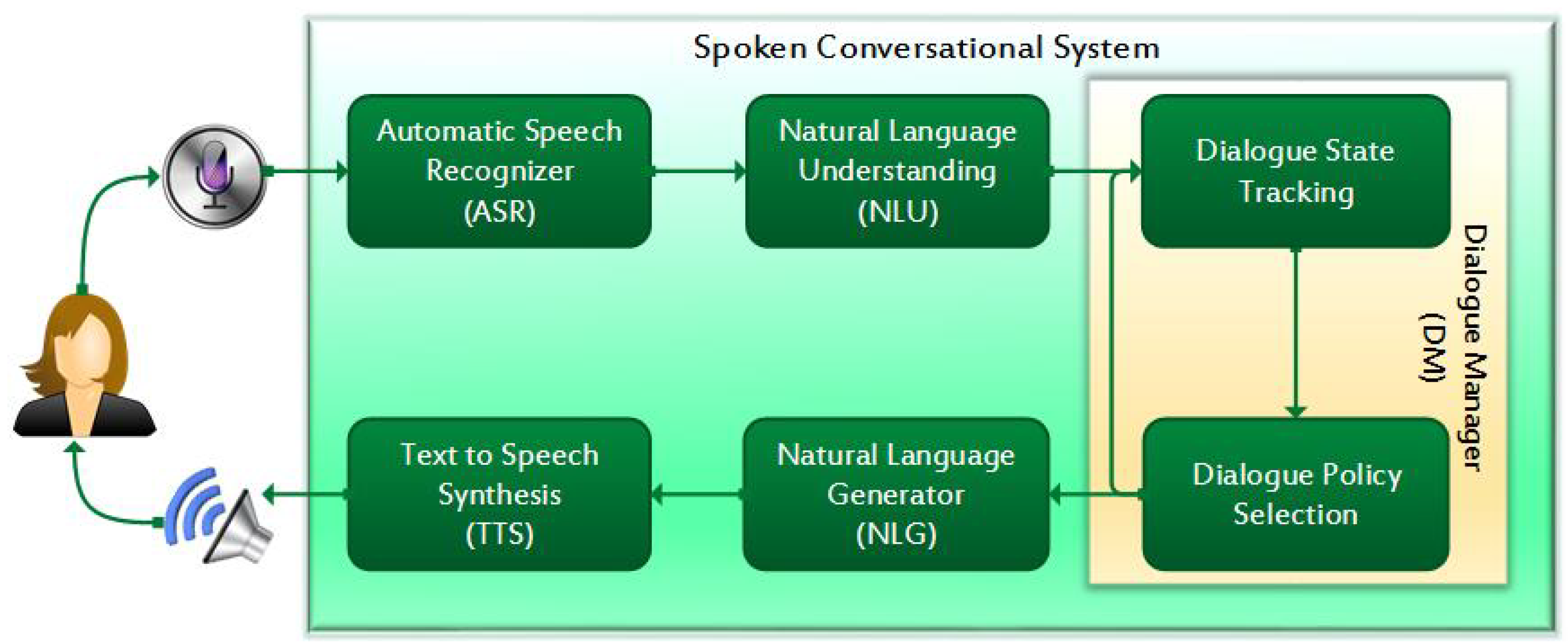
1.1. Research Background
1.2. Key Contributions
- We present BLA to tackle the sentence classification problem in DST by taking a dialogue context and candidate slot value pair to accurately track slots and their corresponding values.
- We propose a model that exploits the sequential and overall features encoded in BERT to improve the performance of neural networks.
- We extract the contextual word features from a dialogue context using the BERT pre-training language model along with Stacked BiLSTM, and multi-attentions.
- Upon evaluating our model on two real-world datasets, we achieved state-of-the-art performance over the current baseline models regarding turn request and joint goal accuracies.
- With detailed experiments in the ablation study on distinguishing variants of neural networks, we have confirmed the importance of feature extraction from Stacked BiLSTM and Multiple Attention Mechanism for the proposed model in terms of the improvement over turn goal, turn request, and joint goal accuracies.
1.3. Organization of the Paper
2. Related Work
2.1. Traditional DST Approaches
2.2. Deep-Learning-Based Approaches
3. Methodology
3.1. Contextual Word Representation
3.2. Dialogue Context Encoding
3.3. Stacked BiLSTM for Feature Extraction
3.4. Multiple Attention
4. Experiments
4.1. Datasets
4.2. Training Setup
4.3. Evaluation Metrics
4.3.1. Turn Goal Accuracy
4.3.2. Turn Request Accuracy
4.3.3. Joint Goal Accuracy
4.4. Baseline Models
- NBT Neural Belief Tracker (NBT) [20] updates its internal representation of the states of conversion at each turn in data driver fashion. It was the first neural-based approach for DST, and used word embedding performing on par with the models developing engineered lexical rules.
- GLAD Global Locally Self Attentive Dialogue State Tracker (GLAD) [8] consists of two modules. The global module shares parameters among slots through self-attentive RNNs. The local module learns features that consider specific slots. The model uses the previous actions of the system and the current utterance of the user as input to compute meaningful similarities with predefined ontological terms.
- Statenet Universal dialogue state tracker (Statenet) [16] generates a fixed length representation of the dialogue history and compares the distance between the representation and the value vectors in the candidate sets. It uses the original ASR information of the user utterances, information about the machine’s acts, and literal names of slots and their corresponding values. The values from candidate sets are set to be dynamically changed in the model.
- GSAT Global encoder and Slot-Attentive decoders (GSAT) [82] is a highly robust dialogue state tracker that predicts the dialogue states with or without using pre-trained embeddings. In addition, GSAT consists of a recurrent neural network-based single global encoder and slot-attentive decoders as classifiers. The encoder module encodes the current user utterance and previous system action from history to output the context vector and hidden representation for each token. The classifier module processes the hidden representations of the encoder and possible slot values to provide the probability distribution for each possible slot value.
- COMER Conditional Memory Relation Network (COMER) [25] uses two sequential decoders to formulate dialogue state as a sequence generation problem instead of a pair-wise prediction problem. First, its encoder–decoder network generates the slot sequences in the dialogue state and then for each slot generates the corresponding value sequences by conditioning on the dialogue history. The parameters are shared across all the decoders to overcome the scalability of the hierarchical structure of the dialogue state.
- Full Bert is a simple but effective BERT-based model [21] proposed for recourse-limited systems to track the dialogue states. The full BERT approach uses BERT to control the parameters to not grow when the ontology changes. It takes candidate and dialogue contexts and produces a score that indicates the relevance of the candidate by considering a dialogue context and a candidate slot-value pair.
- TEN Neural dialogue state tracking with temporally expressive networks (TEN) [34] maintains the state of the system for tracking the progress of dialogue. In this approach, two aspects of state tracking were iterated to improve results. These include (a) temporal feature dependencies in model design and (b) uncertainties in state aggregation more expressively modeled.
- SUMBT Slot-utterance matching for universal and scalable belief tracking [55] focuses on developing a scalable and universal DST. It uses an encoder to encode the system and user utterances. It provides the contextualized semantic representation of sentences. The encoder also encodes the slots and their corresponding values. It also learns the slot value relationships that appear in dialogues.
- Seq2Seq-DU A sequence-to-sequence approach to dialogue state tracking (Seq2Seq-DU) [61] transforms all the utterances in dialogue into semantic frames. It employs encoding of utterances and schema descriptions sequentially to generate pointers in decoding of dialogue states.
- AG-DST Amendable generation for DST [66] takes the dialogue of the current and previous turns as input. This same process of taking input is in a two-pass process as basic generation and amending generation to output the primitive dialogue state for basic generation and amended dialogue state for amending generation.
- BLA implements SBL to exploit contextual information from the last hidden state of BERT. The global attention is used over the overall output of SBL, and local attention on the non-zero words from the BERT tokenizer input IDs to extract the words features. Finally, the overall outputs from three modules BERT, SBL, and multiple attentions are concatenated to generate the dialogue state.
5. Results and Discussion
5.1. Comparative Analysis of Experimental Results
5.2. Ablation Study
- Effect of Stacked BiLSTM Network We used variants of neural networks to investigate the performance of BLA in the ablation study. We replaced Stacked BiLSTM with Stacked BiGRU and run the model on Dev and Test parts of the WoZ-2.0 datasets. It clearly indicates that the joint goal accuracy on Dev, and joint goal, turn goal, and turn request accuracies on the Test part improve and utilize more accurate representations regarding SBL.
- Effect of Attention Mechanism To investigate the effect of attention, we conduct multiple attention and self-attention variants with different models. In Table 5, we remove multiple attention from BERT and SBL that lessens the performance on joint goal accuracy on Dev, and on turn request and joint goal accuracies on Test in respect of BLA. Later, multiple attention eliminates from CRF which indicates the insignificant results over turn goal and joint goal Dev accuracies, and upon all three accuracies on the Test dataset. We use self-attention instead of multiple attention in BCLA, which generates the poorest results among all models. It can be perceived clearly from the ablation study that multiple attention enhances the performance of all models wherever in practice.
5.3. Hyper-Parameters
6. Conclusions and Future Work
- The proposed model, upon evaluation on two datasets, revealed that it extracts features more effectively due to the use of Stacked BiLSTM as compared to other DL-based and traditional approaches.
- We experimented with variants of the attention mechanism. The weaker performance of the model on the self-attention layer suggests that the multi-attention mechanism is helpful for understanding the features and phrases for dialogue state tracking.
- During hyper-parameter selection, we noticed that the learning rate was the most important parameter for the proposed model because the model regulates the number of allocated errors for updating weights to perfectly calibrate the accuracies.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abro, W.A.; Qi, G.; Gao, H.; Khan, M.A.; Ali, Z. Multi-turn intent determination for goal-oriented dialogue systems. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Abro, W.A.; Qi, G.; Aamir, M.; Ali, Z. Joint intent detection and slot filling using weighted finite state transducer and BERT. Appl. Intell. 2022, 52, 17356–17370. [Google Scholar] [CrossRef]
- Young, S.; Gašić, M.; Thomson, B.; Williams, J.D. Pomdp-based statistical spoken dialog systems: A review. Proc. IEEE 2013, 101, 1160–1179. [Google Scholar] [CrossRef]
- Abro, W.A.; Aicher, A.; Rach, N.; Ultes, S.; Minker, W.; Qi, G. Natural language understanding for argumentative dialogue systems in the opinion building domain. Knowl.-Based Syst. 2022, 242, 108318. [Google Scholar] [CrossRef]
- Chen, H.; Liu, X.; Yin, D.; Tang, J. A survey on dialogue systems: Recent advances and new frontiers. ACM Sigkdd Explor. Newsl. 2017, 19, 25–35. [Google Scholar] [CrossRef]
- Xiang, L.; Zhao, Y.; Zhu, J.; Zhou, Y.; Zong, C. Zero-shot language extension for dialogue state tracking via pre-trained models and multi-auxiliary-tasks fine-tuning. Knowl.-Based Syst. 2023, 259, 110015. [Google Scholar] [CrossRef]
- Hong, T.; Cho, J.; Yu, H.; Ko, Y.; Seo, J. Knowledge-grounded dialogue modelling with dialogue-state tracking, domain tracking, and entity extraction. Comput. Speech Lang. 2023, 78, 101460. [Google Scholar] [CrossRef]
- Zhong, V.; Xiong, C.; Socher, R. Global-Locally Self-Attentive Encoder for Dialogue State Tracking. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 1458–1467. [Google Scholar] [CrossRef] [Green Version]
- Liao, L.; Long, L.H.; Ma, Y.; Lei, W.; Chua, T.S. Dialogue state tracking with incremental reasoning. Trans. Assoc. Comput. Linguist. 2021, 9, 557–569. [Google Scholar] [CrossRef]
- Lee, H.; Jeong, O. A Knowledge-Grounded Task-Oriented Dialogue System with Hierarchical Structure for Enhancing Knowledge Selection. Sensors 2023, 23, 685. [Google Scholar] [CrossRef]
- Ye, F.; Manotumruksa, J.; Zhang, Q.; Li, S.; Yilmaz, E. Slot self-attentive dialogue state tracking. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1598–1608. [Google Scholar]
- Mrkšić, N.; Ó Séaghdha, D.; Wen, T.H.; Thomson, B.; Young, S. Neural Belief Tracker: Data-Driven Dialogue State Tracking. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1777–1788. [Google Scholar] [CrossRef]
- Eric, M.; Goel, R.; Paul, S.; Sethi, A.; Agarwal, S.; Gao, S.; Kumar, A.; Goyal, A.; Ku, P.; Hakkani-Tur, D. MultiWOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines. In Proceedings of the 12th Language Resources and Evaluation Conference; European Language Resources Association: Marseille, France, 2020; pp. 422–428. [Google Scholar]
- Mao, M.; Liu, J.; Zhou, J.; Wu, H. Efficient Dialogue State Tracking by Masked Hierarchical Transformer. arXiv 2021, arXiv:2106.14433. [Google Scholar]
- Kim, S.; Yang, S.; Kim, G.; Lee, S.W. Efficient Dialogue State Tracking by Selectively Overwriting Memory. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 567–582. [Google Scholar]
- Nouri, E.; Hosseini-Asl, E. Toward scalable neural dialogue state tracking model. In Proceedings of the In 2nd Conversational AI workshop on NeurIPS, Montréal, QC, Canada, 7 December 2018. [Google Scholar]
- Wen, T.H.; Vandyke, D.; Mrkšić, N.; Gašić, M.; Rojas-Barahona, L.M.; Su, P.H.; Ultes, S.; Young, S. A Network-based End-to-End Trainable Task-oriented Dialogue System. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 438–449. [Google Scholar]
- Henderson, M.; Thomson, B.; Williams, J.D. The second dialog state tracking challenge. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 263–272. [Google Scholar]
- Ren, L.; Xie, K.; Chen, L.; Yu, K. Towards universal dialogue state tracking. arXiv 2018, arXiv:1810.09587. [Google Scholar]
- Mrkšić, N.; Vulić, I. Fully statistical neural belief tracking. arXiv 2018, arXiv:1805.11350. [Google Scholar]
- Lai, T.M.; Tran, Q.H.; Bui, T.; Kihara, D. A simple but effective bert model for dialog state tracking on resource-limited systems. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Online, 4–8 May 2020; pp. 8034–8038. [Google Scholar]
- Wu, C.S.; Madotto, A.; Hosseini-Asl, E.; Xiong, C.; Socher, R.; Fung, P. Transferable multi-domain state generator for task-oriented dialogue systems. arXiv 2019, arXiv:1905.08743. [Google Scholar]
- Zhu, S.; Li, J.; Chen, L.; Yu, K. Efficient Context and Schema Fusion Networks for Multi-Domain Dialogue State Tracking. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Stroudsburg, PA, USA, 16–20 November 2020. [Google Scholar] [CrossRef]
- Gao, S.; Sethi, A.; Agarwal, S.; Chung, T.; Hakkani-Tür, D.Z. Dialog State Tracking: A Neural Reading Comprehension Approach. In Proceedings of the 20th Annual SIGDIAL Meeting on Discourse and Dialogue, Stockholm, Sweden, 11–13 September 2019; pp. 1876–1885. [Google Scholar]
- Ren, L.; Ni, J.; McAuley, J. Scalable and Accurate Dialogue State Tracking via Hierarchical Sequence Generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 1876–1885. [Google Scholar] [CrossRef] [Green Version]
- Le, H.; Socher, R.; Hoi, S.C. Non-Autoregressive Dialog State Tracking. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020; pp. 199–203. [Google Scholar]
- Zhou, H.; Iacobacci, I.; Minervini, P. XQA-DST: Multi-Domain and Multi-Lingual Dialogue State Tracking. arXiv 2022, arXiv:2204.05895. [Google Scholar]
- Wang, Y.; He, T.; Mei, J.; Fan, R.; Tu, X. A Stack-Propagation Framework With Slot Filling for Multi-Domain Dialogue State Tracking. IEEE Trans. Neural Networks Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Liu, B.; Lane, I. An end-to-end trainable neural network model with belief tracking for task-oriented dialog. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 2506–2510. [Google Scholar]
- Henderson, M.; Thomson, B.; Young, S. Robust dialog state tracking using delexicalised recurrent neural networks and unsupervised adaptation. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), Lake Tahoe, NV, USA, 7–10 December 2014; pp. 360–365. [Google Scholar]
- Henderson, M.; Thomson, B.; Young, S. Word-based dialog state tracking with recurrent neural networks. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 292–299. [Google Scholar]
- Mrkšić, N.; Ó Séaghdha, D.; Thomson, B.; Gašić, M.; Su, P.H.; Vandyke, D.; Wen, T.H.; Young, S. Multi-domain Dialog State Tracking using Recurrent Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers); Association for Computational Linguistics: Beijing, China, 2015; pp. 794–799. [Google Scholar] [CrossRef]
- Ramadan, O.; Budzianowski, P.; Gašić, M. Large-Scale Multi-Domain Belief Tracking with Knowledge Sharing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 432–437. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, R.; Mao, Y.; Xu, J. Neural Dialogue State Tracking with Temporally Expressive Networks. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP; Association for Computational Linguistics: Seoul, Korea, 2020; pp. 1570–1579. [Google Scholar]
- Budzianowski, P.; Wen, T.H.; Tseng, B.H.; Casanueva, I.; Ultes, S.; Ramadan, O.; Gašić, M. MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 5016–5026. [Google Scholar] [CrossRef] [Green Version]
- Sun, K.; Chen, L.; Zhu, S.; Yu, K. The SJTU system for dialog state tracking challenge 2. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 318–326. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N.; Mohamed, A. Hybrid speech recognition with Deep Bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar] [CrossRef] [Green Version]
- Williams, J.D. Challenges and opportunities for state tracking in statistical spoken dialog systems: Results from two public deployments. IEEE J. Sel. Top. Signal Process. 2012, 6, 959–970. [Google Scholar] [CrossRef]
- Serban, I.V.; Lowe, R.; Henderson, P.; Charlin, L.; Pineau, J. A Survey of Available Corpora for Building Data-Driven Dialogue Systems. arXiv 2015, arXiv:1512.05742. [Google Scholar]
- Saka, A.B.; Oyedele, L.O.; Akanbi, L.A.; Ganiyu, S.A.; Chan, D.W.; Bello, S.A. Conversational artificial intelligence in the AEC industry: A review of present status, challenges and opportunities. Adv. Eng. Inf. 2023, 55, 101869. [Google Scholar] [CrossRef]
- Wang, Z.; Lemon, O. A simple and generic belief tracking mechanism for the dialog state tracking challenge: On the believability of observed information. In Proceedings of the SIGDIAL 2013 Conference, Metz, France, 22–24 August 2013; pp. 423–432. [Google Scholar]
- Henderson, J.; Lemon, O. Mixture Model POMDPs for Efficient Handling of Uncertainty in Dialogue Management. In Proceedings of the ACL-08: HLT, Short Papers; Association for Computational Linguistics: Columbus, OH, USA, 2008; pp. 73–76. [Google Scholar]
- Williams, J.D.; Young, S. Scaling POMDPs for spoken dialog management. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 2116–2129. [Google Scholar] [CrossRef] [Green Version]
- Williams, J.D.; Young, S. Partially observable Markov decision processes for spoken dialog systems. Comput. Speech Lang. 2007, 21, 393–422. [Google Scholar] [CrossRef]
- Henderson, M. Machine learning for dialog state tracking: A review. In Proceedings of the NIPS 2015 Workshop on Machine Learning for Spoken Language Understanding and Interaction, Montreal, QC, Canada, 11 December 2015. [Google Scholar]
- Lee, S.; Eskenazi, M. Exploiting Machine-Transcribed Dialog Corpus to Improve Multiple Dialog States Tracking Methods. In Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue; Association for Computational Linguistics: Seoul, Republic of Korea, 2012; pp. 189–196. [Google Scholar]
- Yu, K.; Sun, K.; Chen, L.; Zhu, S. Constrained markov bayesian polynomial for efficient dialogue state tracking. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2177–2188. [Google Scholar]
- Perez, J.; Liu, F. Dialog state tracking, a machine reading approach using Memory Network. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 305–314. [Google Scholar]
- Metallinou, A.; Bohus, D.; Williams, J.D. Discriminative state tracking for spoken dialog systems. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 466–475. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Li, C.; Chrysostomou, D.; Pinto, D.; Hansen, A.K.; Bøgh, S.; Madsen, O. Hey Max, can you help me? An Intuitive Virtual Assistant for Industrial Robots. Appl. Sci. 2023, 13, 205. [Google Scholar] [CrossRef]
- Ali, Z.; Kefalas, P.; Muhammad, K.; Ali, B.; Imran, M. Deep learning in citation recommendation models survey. Expert Syst. Appl. 2020, 162, 113790. [Google Scholar] [CrossRef]
- Lee, H.; Lee, J.; Kim, T.Y. SUMBT: Slot-Utterance Matching for Universal and Scalable Belief Tracking. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Florence, Italy, 2019; pp. 5478–5483. [Google Scholar] [CrossRef]
- Sun, Z.; Huang, Z.; Ding, N. On Tracking Dialogue State by Inheriting Slot Values in Mentioned Slot Pools. arXiv 2022, arXiv:2202.07156. [Google Scholar]
- Jin, X.; Lei, W.; Ren, Z.; Chen, H.; Liang, S.; Zhao, Y.; Yin, D. Explicit state tracking with semi-supervision for neural dialogue generation. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1403–1412. [Google Scholar]
- Zhang, J.; Hashimoto, K.; Wu, C.S.; Wang, Y.; Yu, P.; Socher, R.; Xiong, C. Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking. In Proceedings of the 9th Joint Conference on Lexical and Computational Semantics; Association for Computational Linguistics: Barcelona, Spain, 2020; pp. 154–167. [Google Scholar]
- Henderson, M.; Thomson, B.; Young, S. Deep neural network approach for the dialog state tracking challenge. In Proceedings of the SIGDIAL 2013 Conference, Metz, France, 22–24 August 2013; pp. 467–471. [Google Scholar]
- Kumar, A.; Ku, P.; Goyal, A.; Metallinou, A.; Hakkani-Tur, D. Ma-dst: Multi-attention-based scalable dialog state tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 3, pp. 8107–8114. [Google Scholar]
- Feng, Y.; Wang, Y.; Li, H. A Sequence-to-Sequence Approach to Dialogue State Tracking. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, 1– 6 August 2021; pp. 1714–1725. [Google Scholar] [CrossRef]
- Heck, M.; Lubis, N.; Niekerk, C.v.; Feng, S.; Geishauser, C.; Lin, H.C.; Gašić, M. Robust Dialogue State Tracking with Weak Supervision and Sparse Data. Trans. Assoc. Comput. Linguist. 2022, 10, 1175–1192. [Google Scholar] [CrossRef]
- Williams, J.D. Web-style ranking and SLU combination for dialog state tracking. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 282–291. [Google Scholar]
- Sebt, M.V.; Ghasemi, S.; Mehrkian, S. Predicting the number of customer transactions using stacked LSTM recurrent neural networks. Soc. Netw. Anal. Min. 2021, 11, 86. [Google Scholar] [CrossRef]
- Cui, Z.; Ke, R.; Pu, Z.; Wang, Y. Stacked bidirectional and unidirectional LSTM recurrent neural network for forecasting network-wide traffic state with missing values. Transp. Res. Part Emerg. Technol. 2020, 118, 102674. [Google Scholar] [CrossRef]
- Tian, X.; Huang, L.; Lin, Y.; Bao, S.; He, H.; Yang, Y.; Wu, H.; Wang, F.; Sun, S. Amendable Generation for Dialogue State Tracking. In Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI, Online, 10 November 2021; pp. 80–92. [Google Scholar]
- Shan, Y.; Li, Z.; Zhang, J.; Meng, F.; Feng, Y.; Niu, C.; Zhou, J. A contextual hierarchical attention network with adaptive objective for dialogue state tracking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 6322–6333. [Google Scholar]
- Ye, F.; Feng, Y.; Yilmaz, E. ASSIST: Towards Label Noise-Robust Dialogue State Tracking. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 2719–2731. [Google Scholar] [CrossRef]
- Hu, Y.; Lee, C.H.; Xie, T.; Yu, T.; Smith, N.A.; Ostendorf, M. In-Context Learning for Few-Shot Dialogue State Tracking. arXiv 2022, arXiv:2203.08568. [Google Scholar]
- Uddin, M.N.; Li, B.; Ali, Z.; Kefalas, P.; Khan, I.; Zada, I. Software defect prediction employing BiLSTM and BERT-based semantic feature. Soft Comput. 2022, 26, 7877–7891. [Google Scholar] [CrossRef]
- Abro, W.A.; Qi, G.; Ali, Z.; Feng, Y.; Aamir, M. Multi-turn intent determination and slot filling with neural networks and regular expressions. Knowl.-Based Syst. 2020, 208, 106428. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Wen, T.H.; Gašić, M.; Mrkšić, N.; Rojas-Barahona, L.M.; Su, P.H.; Ultes, S.; Vandyke, D.; Young, S. Conditional Generation and Snapshot Learning in Neural Dialogue Systems. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 2153–2162. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Arefeen, M.A.; Nimi, S.T.; Rahman, M.S. Neural network-based undersampling techniques. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 1111–1120. [Google Scholar] [CrossRef]
- Zhu, C.; Zeng, M.; Huang, X. SIM: A Slot-Independent Neural Model for Dialogue State Tracking. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue; Association for Computational Linguistics: Stockholm, Sweden, 2019; pp. 40–45. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Choubey, P.K.; Huang, R. Improving Dialogue State Tracking by Discerning the Relevant Context. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 576–581. [Google Scholar] [CrossRef]
- Rastogi, A.; Zang, X.; Sunkara, S.; Gupta, R.; Khaitan, P. Schema-guided dialogue state tracking task at dstc8. arXiv 2020, arXiv:2002.01359. [Google Scholar]
- Dey, S.; Kummara, R.; Desarkar, M. Towards Fair Evaluation of Dialogue State Tracking by Flexible Incorporation of Turn-level Performances. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 318–324. [Google Scholar] [CrossRef]
- Balaraman, V.; Magnini, B. Scalable neural dialogue state tracking. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Sentosa, Singapore, 14–18 December 2019; pp. 830–837. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Methodology | Strengths | Limitations | Performance (TG, TR, JGA) |
|---|---|---|---|---|
| GLAD [8] |
|
|
| TG, TR, JGA |
| TEN [34] |
|
|
| JGA |
| Seq2Seq-DU [61] |
|
|
| JGA |
| MSP [56] |
|
|
| JGA |
| Trippy-r [62] |
|
|
| JGA |
| S. No. | Name | Topic | Slots | Total Utterances | Average Turns | Total Dialogues | Total Words |
|---|---|---|---|---|---|---|---|
| 1 | DSTC-2 | Restaurant | area, food, name, price range, address, phone, postcode, signature | 24,049 | 7.88 | 3000 | 432 K |
| 2 | WoZ-2.0 | Restaurant | food, price range, area | 3452 | 4.24 | 1200 | 22,347 |
| Layer | Hyper-Parameter | Size |
|---|---|---|
| BERT | dimension | 786 |
| LSTM | hidden Layer | 256 |
| number of Layers | 2 | |
| Learning Rate | learning rate | 2 × 10−5 |
| LSTM Dropout | dropout | 0.25 |
| Number of Labels | output for input sample | 2 |
| Dropout | dropout rate | 0.25 |
| Warmup-Proportion | warmup steps | 0.1 |
| Models | DSTC-2 | WoZ-2.0 | ||
|---|---|---|---|---|
| Turn Request | Joint Goal | Turn Request | Joint Goal | |
| NBT † | 97.50 | 73.40 | 91.60 | 84.20 |
| GLAD † | - | 74.50 | 97.10 | 88.10 |
| Statenet ‡ | - | 75.50 | - | 88.90 |
| GSAT † | 96.50 | 84.81 | 96.74 | 90.48 |
| COMER ‡ | - | - | 97.10 | 88.60 |
| Full Bert † | - | 74.50 | 97.70 | 90.40 |
| TEN † | - | 77.30 | 97.10 | 90.80 |
| SUMBT ‡ | - | - | 97.10 | 91.00 |
| Seq2Seq-DU ‡ | 85.00 | 74.50 | - | 91.2 |
| AG-DST ‡ | - | - | - | 91.37 |
| BLA | 99.56 | 87.31 | 97.83 | 93.73 |
| Models | DSTC-2 Accuracies | WoZ-2.0 Accuracies | ||||
|---|---|---|---|---|---|---|
| Joint Goal | Turn Request | Turn Goal | Joint Goal | Turn Request | Turn Goal | |
| BSL | 86.95 | 99.33 | 99.11 | 92.48 | 98.19 | 95.54 |
| BSG | 86.55 | 99.38 | 99.16 | 92.65 | 97.83 | 95.66 |
| BLG | 87.13 | 99.31 | 99.18 | 92.16 | 97.59 | 94.57 |
| BLC | 81.74 | 98.55 | 96.92 | 85.66 | 96.86 | 92.28 |
| BLCA | 82.96 | 98.93 | 97.3 | 88.07 | 97.22 | 91.73 |
| BCLA | 87.01 | 99.03 | 97.48 | 37 | 74.11 | 72.23 |
| BLA | 87.31 | 99.56 | 99.11 | 93.73 | 97.83 | 95.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.A.; Huang, Y.; Feng, J.; Prasad, B.K.; Ali, Z.; Ullah, I.; Kefalas, P. A Multi-Attention Approach Using BERT and Stacked Bidirectional LSTM for Improved Dialogue State Tracking. Appl. Sci. 2023, 13, 1775. https://doi.org/10.3390/app13031775
Khan MA, Huang Y, Feng J, Prasad BK, Ali Z, Ullah I, Kefalas P. A Multi-Attention Approach Using BERT and Stacked Bidirectional LSTM for Improved Dialogue State Tracking. Applied Sciences. 2023; 13(3):1775. https://doi.org/10.3390/app13031775
Chicago/Turabian StyleKhan, Muhammad Asif, Yi Huang, Junlan Feng, Bhuyan Kaibalya Prasad, Zafar Ali, Irfan Ullah, and Pavlos Kefalas. 2023. "A Multi-Attention Approach Using BERT and Stacked Bidirectional LSTM for Improved Dialogue State Tracking" Applied Sciences 13, no. 3: 1775. https://doi.org/10.3390/app13031775