
Acoustic Voice and Speech Biomarkers of Treatment Status during Hospitalization for Acute Decompensated Heart Failure

 ,
,
Abstract
:Featured Application
Abstract
1. Introduction
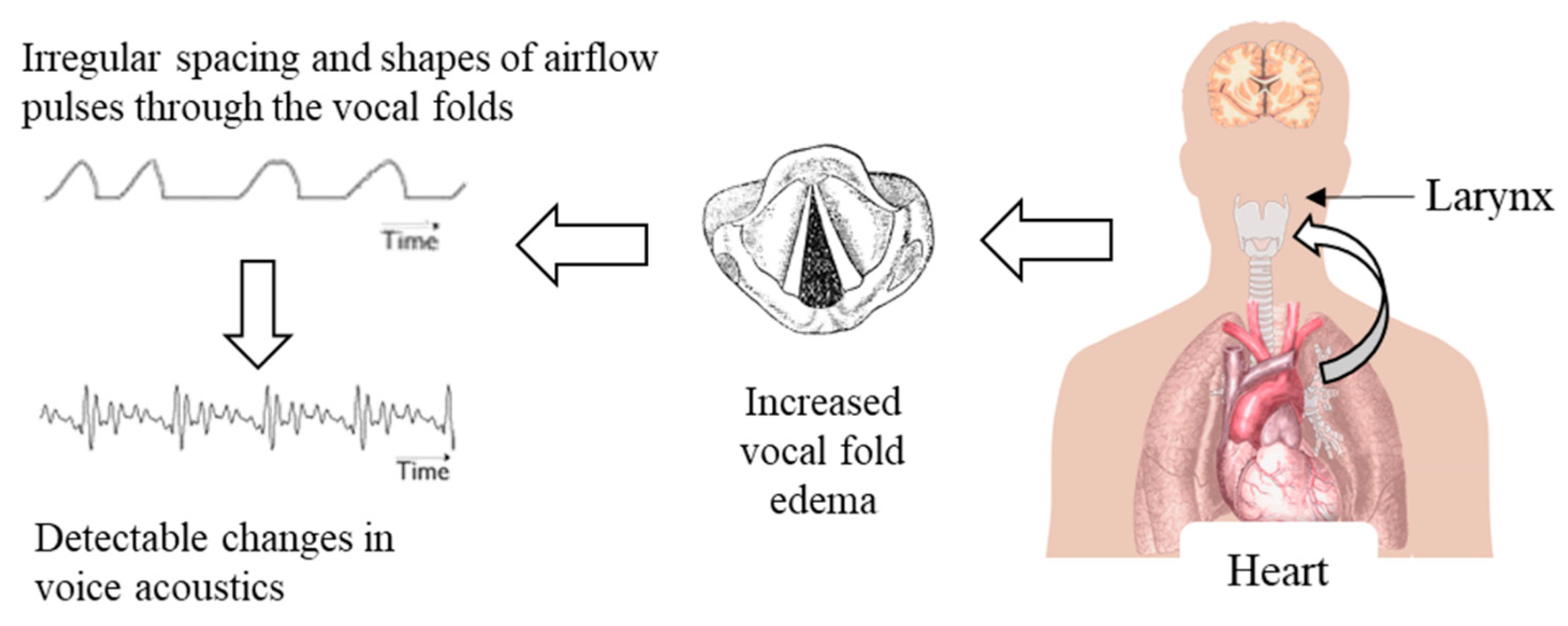
1.1. Linking Voice Physiology to ADHF
1.2. Voice and Speech as Biomarkers of Health
1.3. Current Work
2. Materials and Methods
2.1. Participants
2.2. Data Collection
2.3. Feature Extraction
2.4. Statistics and Machine Learning
3. Results
4. Discussion
4.1. Promising Acoustic Voice and Speech Features
4.1.1. Total Phrase Duration
4.1.2. Maximum Phonation Time
4.1.3. Cepstral Peak Prominence
4.2. Binary Classification Using Logistic Regression
4.3. Day-to-Day Trajectories of Model Performance
4.4. Implications of Accelerometer-Based Results
4.5. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Clark, K.A.A.; Reinhardt, S.W.; Chouairi, F.; Miller, P.E.; Kay, B.; Fuery, M.; Guha, A.; Ahmad, T.; Desai, N.R. Trends in heart failure hospitalizations in the US from 2008 to 2018. J. Card. Fail. 2022, 28, 171–180. [Google Scholar] [CrossRef]
- Curtis, L.H.; Whellan, D.J.; Hammill, B.G.; Hernandez, A.F.; Anstrom, K.J.; Shea, A.M.; Schulman, K.A. Incidence and prevalence of heart failure in elderly persons, 1994–2003. Arch. Intern. Med. 2008, 168, 418–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Groenewegen, A.; Rutten, F.H.; Mosterd, A.; Hoes, A.W. Epidemiology of heart failure. Eur. J. Heart Fail. 2020, 22, 1342–1356. [Google Scholar] [CrossRef]
- GBD 2017 Disease and Injury Incidence and Prevalence Collaborators. Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2018, 392, 1789–1858. [Google Scholar] [CrossRef] [Green Version]
- Kemp, C.D.; Conte, J.V. The pathophysiology of heart failure. Cardiovasc. Pathol. 2012, 21, 365–371. [Google Scholar] [CrossRef]
- Joseph, S.M.; Cedars, A.M.; Ewald, G.A.; Geltman, E.M.; Mann, D.L. Acute decompensated heart failure: Contemporary medical management. Tex. Heart Inst. J. 2009, 36, 510–520. [Google Scholar]
- Boorsma, E.M.; ter Maaten, J.M.; Damman, K.; Dinh, W.; Gustafsson, F.; Goldsmith, S.; Burkhoff, D.; Zannad, F.; Udelson, J.E.; Voors, A.A. Congestion in heart failure: A contemporary look at physiology, diagnosis and treatment. Nat. Rev. Cardiol. 2020, 17, 641–655. [Google Scholar] [CrossRef]
- Desai, A.S.; Stevenson, L.W. Rehospitalization for heart failure: Predict or prevent? Circulation 2012, 126, 501–506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Titze, I.R. The physics of small-amplitude oscillation of the vocal folds. J. Acoust. Soc. Am. 1988, 83, 1536–1552. [Google Scholar] [CrossRef] [PubMed]
- Titze, I.R. Phonation threshold pressure: A missing link in glottal aerodynamics. J. Acoust. Soc. Am. 1992, 91, 2926–2935. [Google Scholar] [CrossRef]
- Sivasankar, M.; Leydon, C. The role of hydration in vocal fold physiology. Curr. Opin. Otolaryngol. Head Neck Surg. 2010, 18, 171–175. [Google Scholar] [CrossRef] [PubMed]
- Finkelhor, B.K.; Titze, I.R.; Durham, P.L. The effect of viscosity changes in the vocal folds on the range of oscillation. J. Voice 1988, 1, 320–325. [Google Scholar] [CrossRef]
- Verdolini, K.; Min, Y.; Titze, I.R.; Lemke, J.; Brown, K.; van Mersbergen, M.; Jiang, J.; Fisher, K. Biological mechanisms underlying voice changes due to dehydration. J. Speech. Lang. Hear. Res. 2002, 45, 268–281. [Google Scholar] [CrossRef] [PubMed]
- Verdolini-Marston, K.; Sandage, M.; Titze, I.R. Effect of hydration treatments on laryngeal nodules and polyps and related voice measures. J. Voice 1994, 8, 30–47. [Google Scholar] [CrossRef]
- Alves, M.; Krüger, E.; Pillay, B.; van Lierde, K.; van der Linde, J. The effect of hydration on voice quality in adults: A systematic review. J. Voice 2019, 33, 125.e13–125.e28. [Google Scholar] [CrossRef] [Green Version]
- Low, D.M.; Bentley, K.H.; Ghosh, S.S. Automated assessment of psychiatric disorders using speech: A systematic review. Laryngoscope Investig. Otolaryngol. 2020, 5, 96–116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Stan, J.H.; Mehta, D.D.; Hillman, R.E. Recent innovations in voice assessment expected to impact the clinical management of voice disorders. Perspect. ASHA Spec. Interest Groups 2017, 2, 4–13. [Google Scholar] [CrossRef] [Green Version]
- Mehta, D.D.; Van Stan, J.H.; Zañartu, M.; Ghassemi, M.; Guttag, J.V.; Espinoza, V.M.; Cortés, J.P.; Cheyne, H.A., II; Hillman, R.E. Using ambulatory voice monitoring to investigate common voice disorders: Research update. Front. Bioeng. Biotechnol. 2015, 3, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Williamson, J.R.; Quatieri, T.F.; Helfer, B.S.; Horwitz, R.L.; Yu, B.; Mehta, D.D. Vocal biomarkers of depression based on motor incoordination. In Proceedings of the Third International Audio/Visual Emotion Challenge (AVEC 2013), 21st ACM International Conference on Multimedia, Barcelona, Spain, 21 October 2013; pp. 41–48. [Google Scholar]
- Holmes, R.J.; Oates, J.M.; Phyland, D.J.; Hughes, A.J. Voice characteristics in the progression of Parkinson’s disease. Int. J. Lang. Commun. Disord. 2000, 35, 407–418. [Google Scholar] [PubMed]
- Moro-Velazquez, L.; Gomez-Garcia, J.A.; Arias-Londoño, J.D.; Dehak, N.; Godino-Llorente, J.I. Advances in Parkinson’s Disease detection and assessment using voice and speech: A review of the articulatory and phonatory aspects. Biomed. Signal Process. Control 2021, 66, 102418. [Google Scholar] [CrossRef]
- Green, J.R.; Yunusova, Y.; Kuruvilla, M.S.; Wang, J.; Pattee, G.L.; Synhorst, L.; Zinman, L.; Berry, J.D. Bulbar and speech motor assessment in ALS: Challenges and future directions. Amyotroph. Lateral Scler. Front. Degener. 2013, 14, 494–500. [Google Scholar] [CrossRef]
- Maor, E.; Sara, J.D.; Orbelo, D.M.; Lerman, L.O.; Levanon, Y.; Lerman, A. Voice signal characteristics are independently associated with coronary artery disease. Mayo Clin. Proc. 2018, 93, 840–847. [Google Scholar] [CrossRef]
- Sara, J.D.S.; Maor, E.; Borlaug, B.; Lewis, B.R.; Orbelo, D.; Lerman, L.O.; Lerman, A. Non-invasive vocal biomarker is associated with pulmonary hypertension. PLoS ONE 2020, 15, e0231441. [Google Scholar] [CrossRef] [Green Version]
- Quatieri, T.; Talkar, T.; Palmer, J. A framework for biomarkers of COVID-19 based on coordination of speech-production subsystems. IEEE Open J. Eng. Med. Biol. 2020, in press. [Google Scholar] [CrossRef]
- Maor, E.; Perry, D.; Mevorach, D.; Taiblum, N.; Luz, Y.; Mazin, I.; Lerman, A.; Koren, G.; Shalev, V. Vocal biomarker is associated with hospitalization and mortality among heart failure patients. J. Am. Heart Assoc. 2020, 9, e013359. [Google Scholar] [CrossRef]
- Amir, O.; Abraham, W.T.; Azzam, Z.S.; Berger, G.; Anker, S.D.; Pinney, S.P.; Burkhoff, D.; Shallom, I.D.; Lotan, C.; Edelman, E.R. Remote speech analysis in the evaluation of hospitalized patients with acute decompensated heart failure. JACC Heart Fail. 2022, 10, 41–49. [Google Scholar] [CrossRef]
- Murton, O.M.; Hillman, R.E.; Semigran, M.; Daher, M.; Cunningham, T.; Verkouw, K.; Tabtabai, S.; Steiner, J.; Dec, G.W.; Ausiello, D.; et al. Acoustic speech analysis of patients with decompensated heart failure: A pilot study. J. Acoust. Soc. Am. 2017, 142, EL401–EL407. [Google Scholar] [CrossRef] [Green Version]
- Strömberg, A.; Mårtensson, J. Gender differences in patients with heart failure. Eur. J. Cardiovasc. Nurs. 2003, 2, 7–18. [Google Scholar] [CrossRef]
- Lam, C.S.P.; Arnott, C.; Beale, A.L.; Chandramouli, C.; Hilfiker-Kleiner, D.; Kaye, D.M.; Ky, B.; Santema, B.T.; Sliwa, K.; Voors, A.A. Sex differences in heart failure. Eur. Heart J. 2019, 40, 3859–3868c. [Google Scholar] [CrossRef]
- Dao, Q.; Krishnaswamy, P.; Kazanegra, R.; Harrison, A.; Amirnovin, R.; Lenert, L.; Clopton, P.; Alberto, J.; Hlavin, P.; Maisel, A.S. Utility of B-type natriuretic peptide in the diagnosis of congestive heart failure in an urgent-care setting. J. Am. Coll. Cardiol. 2001, 37, 379–385. [Google Scholar] [CrossRef] [Green Version]
- Kempster, G.B.; Gerratt, B.R.; Verdolini Abbott, K.; Barkmeier-Kraemer, J.; Hillman, R.E. Consensus auditory-perceptual evaluation of voice: Development of a standardized clinical protocol. Am. J. Speech Lang. Pathol. 2009, 18, 124–132. [Google Scholar] [CrossRef]
- Fairbanks, G. Voice and Articulation Drillbook; Harper and Row: New York, NY, USA, 1960. [Google Scholar]
- Mehta, D.; Van Stan, J.; Hillman, R. Relationships between vocal function measures derived from an acoustic microphone and a subglottal neck-surface accelerometer. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 659–668. [Google Scholar] [CrossRef]
- Praat: Doing Phonetics by Computer, Version 6.3.05; Phonetic Sciences, University of Amsterdam: Amsterdam, The Netherlands, 2013. Available online: http://www.praat.org(accessed on 22 February 2017).
- Ishi, C.T.; Sakakibara, K.I.; Ishiguro, H.; Hagita, N. A method for automatic detection of vocal fry. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 47–56. [Google Scholar] [CrossRef]
- Kane, J.; Drugman, T.; Gobl, C. Improved automatic detection of creak. Comput. Speech Lang. 2013, 27, 1028–1047. [Google Scholar] [CrossRef]
- Murton, O.; Shattuck-Hufnagel, S.; Choi, J.-Y.; Mehta, D.D. Identifying a creak probability threshold for an irregular pitch period detection algorithm. J. Acoust. Soc. Am. 2019, 145, EL379–EL385. [Google Scholar] [CrossRef] [Green Version]
- Drugman, T.; Kane, J.; Gobl, C. Data-driven detection and analysis of the patterns of creaky voice. Comput. Speech Lang. 2014, 28, 1233–1253. [Google Scholar] [CrossRef]
- Patel, R.R.; Awan, S.N.; Barkmeier-Kraemer, J.; Courey, M.; Deliyski, D.; Eadie, T.; Paul, D.; Svec, J.G.; Hillman, R. Recommended protocols for instrumental assessment of voice: American Speech-Language-Hearing Association Expert Panel to develop a protocol for instrumental assessment of vocal function. Am. J. Speech Lang. Pathol. 2018, 27, 887–905. [Google Scholar] [CrossRef]
- Awan, S.N.; Roy, N.; Jetté, M.E.; Meltzner, G.S.; Hillman, R.E. Quantifying dysphonia severity using a spectral/cepstral-based acoustic index: Comparisons with auditory-perceptual judgements from the CAPE-V. Clin. Linguist. Phon. 2010, 24, 742–758. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Mehta, D.D.; Zañartu, M.; Feng, S.W.; Cheyne II, H.A.; Hillman, R.E. Mobile voice health monitoring using a wearable accelerometer sensor and a smartphone platform. IEEE Trans. Biomed. Eng. 2012, 59, 3090–3096. [Google Scholar] [CrossRef] [Green Version]
- Sawilowsky, S. New effect size rules of thumb. J. Mod. Appl. Stat. Methods 2009, 8, 597–599. [Google Scholar] [CrossRef]
- Ramig, L.A. Effects of physiological aging on speaking and reading rates. J. Commun. Disord. 1983, 16, 217–226. [Google Scholar] [CrossRef]
- Linville, S.E.; Skarin, B.D.; Fornatto, E. The interrelationship of measures related to vocal function, speech rate, and laryngeal appearance in elderly women. J. Speech Hear. Res. 1989, 32, 323–330. [Google Scholar] [CrossRef]
- Maslan, J.; Leng, X.; Rees, C.; Blalock, D.; Butler, S.G. Maximum phonation time in healthy older adults. J. Voice 2011, 25, 709–713. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murton, O.; Hillman, R.; Mehta, D. Cepstral peak prominence values for clinical voice evaluation. Am. J. Speech Lang. Pathol. 2020, 29, 1596–1607. [Google Scholar] [CrossRef]
- Cohen, S.M.; Kim, J.; Roy, N.; Asche, C.; Courey, M. Prevalence and causes of dysphonia in a large treatment-seeking population. Laryngoscope 2012, 122, 343–348. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Task | Effect Size (MIC) | Effect Size (ACC) |
|---|---|---|---|
| Total phrase duration | Rainbow Passage | −0.50 | −0.33 |
| Total phrase duration | 2nd passage | −0.50 | −0.22 |
| Phonation time | Max phonation | 0.49 | 0.45 |
| F0 mean | Vowel | 0.35 | 0.35 |
| CPP SD | Sentences | −0.27 | −0.30 |
| CPP mean | Sentences | −0.25 | −0.31 |
| CPP median | Sentences | −0.22 | −0.28 |
| CPP median | Vowel | 0.21 | −0.018 |
| CPP SD | Vowel | −0.17 | −0.29 |
| CPP mean | Vowel | 0.17 | −0.036 |
| Feature | Task | Odds Ratio (MIC) | Odds Ratio (ACC) |
|---|---|---|---|
| Creak %: 0.3 threshold | Sentences | 1.92 | |
| F0 mean | Vowel | 1.40 | 1.08 |
| CPP median | Spontaneous | 1.37 | |
| Phrase duration median | Spontaneous | 1.27 | |
| Phrase duration mean | Spontaneous | 1.25 | 1.13 |
| Phrase % | Rainbow Passage | 1.18 | |
| Creak %: 0.02 threshold | Sentences | 1.12 | |
| CPP median | Vowel | 1.08 | |
| Phrase % | Spontaneous | 1.08 | |
| Harmonics-to-noise ratio | Vowel | 1.07 | |
| CPP SD | Rainbow Passage | 0.92 | |
| Phrase count | Rainbow Passage | 0.91 | |
| CPP mean | Sentences | 0.90 | |
| Phrase duration SD | Rainbow Passage | 0.87 | |
| F0 SD | Vowel | 0.85 | |
| F0 SD | Spontaneous | 0.79 | |
| Total phrase duration | Rainbow Passage | 0.70 | 0.92 |
| CPP SD | Sentences | 0.61 | 0.85 |
| Feature | Task | Odds Ratio (MIC) | Odds Ratio (ACC) |
|---|---|---|---|
| Phonation time | Max phonation | 1.34 | 1.03 |
| F0 SD | Sentences | 1.25 | 1.02 |
| Phrase duration median | Spontaneous | 1.11 |
| λ | Model | Accuracy | AUC | TAR | TDR | APV | DPV |
|---|---|---|---|---|---|---|---|
| N/A | MPT− | 0.53 (0.53) | 0.49 (0.53) | 0.51 (0.49) | 0.55 (0.57) | 0.55 (0.54) | 0.51 (0.52) |
| N/A | MPT+ | 0.52 (0.58) | 0.46 (0.54) | 0.48 (0.50) | 0.57 (0.65) | 0.53 (0.59) | 0.52 (0.57) |
| N/A | MPT-only | 0.64 (0.58) | 0.61 (0.60) | 0.63 (0.52) | 0.65 (0.64) | 0.63 (0.57) | 0.65 (0.59) |
| L1 | MPT− | 0.62 (0.56) | 0.66 (0.51) | 0.70 (0.60) | 0.52 (0.52) | 0.61 (0.56) | 0.62 (0.56) |
| L1 | MPT+ | 0.69 (0.68) | 0.65 (0.63) | 0.71 (0.70) | 0.67 (0.65) | 0.68 (0.67) | 0.70 (0.68) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murton, O.M.; Dec, G.W.; Hillman, R.E.; Majmudar, M.D.; Steiner, J.; Guttag, J.V.; Mehta, D.D. Acoustic Voice and Speech Biomarkers of Treatment Status during Hospitalization for Acute Decompensated Heart Failure. Appl. Sci. 2023, 13, 1827. https://doi.org/10.3390/app13031827
Murton OM, Dec GW, Hillman RE, Majmudar MD, Steiner J, Guttag JV, Mehta DD. Acoustic Voice and Speech Biomarkers of Treatment Status during Hospitalization for Acute Decompensated Heart Failure. Applied Sciences. 2023; 13(3):1827. https://doi.org/10.3390/app13031827
Chicago/Turabian StyleMurton, Olivia M., G. William Dec, Robert E. Hillman, Maulik D. Majmudar, Johannes Steiner, John V. Guttag, and Daryush D. Mehta. 2023. "Acoustic Voice and Speech Biomarkers of Treatment Status during Hospitalization for Acute Decompensated Heart Failure" Applied Sciences 13, no. 3: 1827. https://doi.org/10.3390/app13031827