
Flexible Route Planning for Multiple Mobile Robots by Combining Q–Learning and Graph Search Algorithm

Abstract
:1. Introduction
2. Related Works
2.1. Classification of Route Planning Problems
2.2. Optimization Methods
2.3. Reinforcement Learning Methods
2.4. Contributions of the Article
- We propose a new route planning algorithm that combines a graph search algorithm and an offline Q–learning algorithm.
- The state space of the proposed Q–learning algorithm is restricted by the integration.
- We found that the optimization performance of the proposed algorithm is almost the same as the conventional route planning algorithms for static problem instances, however, the performance for the dynamic problem is much better than the conventional route planning methods.
- The proposed method can flexibly regenerate route planning dynamically when the delay of AGVs or unexpected events occur.
3. Problem Description
3.1. Transportation System Model
- The geometrical size of a vehicle is sufficiently small compared with the size of a node.
- Each vehicle can travel to its adjacent nodes in one unit of time. Therefore, its acceleration and deceleration are not considered.
- A set of an initial node and a destination node represents a transportation task. The time duration defines a task’s transfer period from when the task is loaded at the initial location and is unloaded at the destination location.
- No more than 1 task can be assigned to each vehicle at the same time.
- Loading and unloading time is an integer multiple of one unit time.
- The set of vehicles M and the set of planning periods T are assumed to be constant.
- Conflict on each node and each edge is not allowed.
- The layout of transportation is not changed during the traveling of vehicles.
3.2. Definition of Static Transportation Problem
3.3. Definition of Dynamic Transportation Problem
- Repeat Steps 2 to 6 until the task queue is empty.
- A task is assigned from the task queue to a waiting AGV which has no task at the time.
- Each AGV travels to the loading location indicated in the task.
- Wait for a certain time at the loading point. (Loading the cargo)
- Travel to the unloading point indicated in the task.
- Wait for a certain time at the unloading point. (Unloading the cargo)
3.4. Problem Formulation of Static Problem
3.4.1. Given Parameters
3.4.2. Decision Variables
3.4.3. Objective Function
3.4.4. Constraints
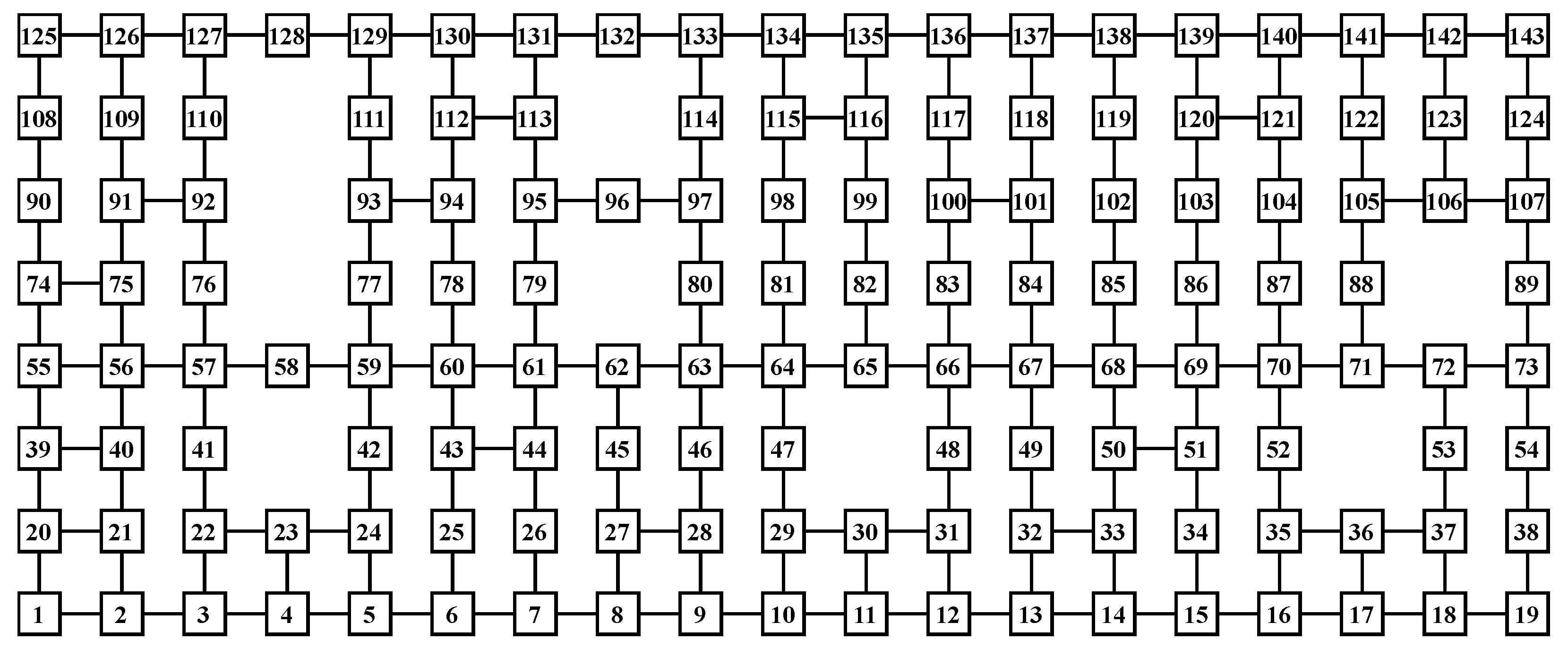
3.5. Modeling Warehousing System with Obstacles with 256 Nodes and 16 Edges
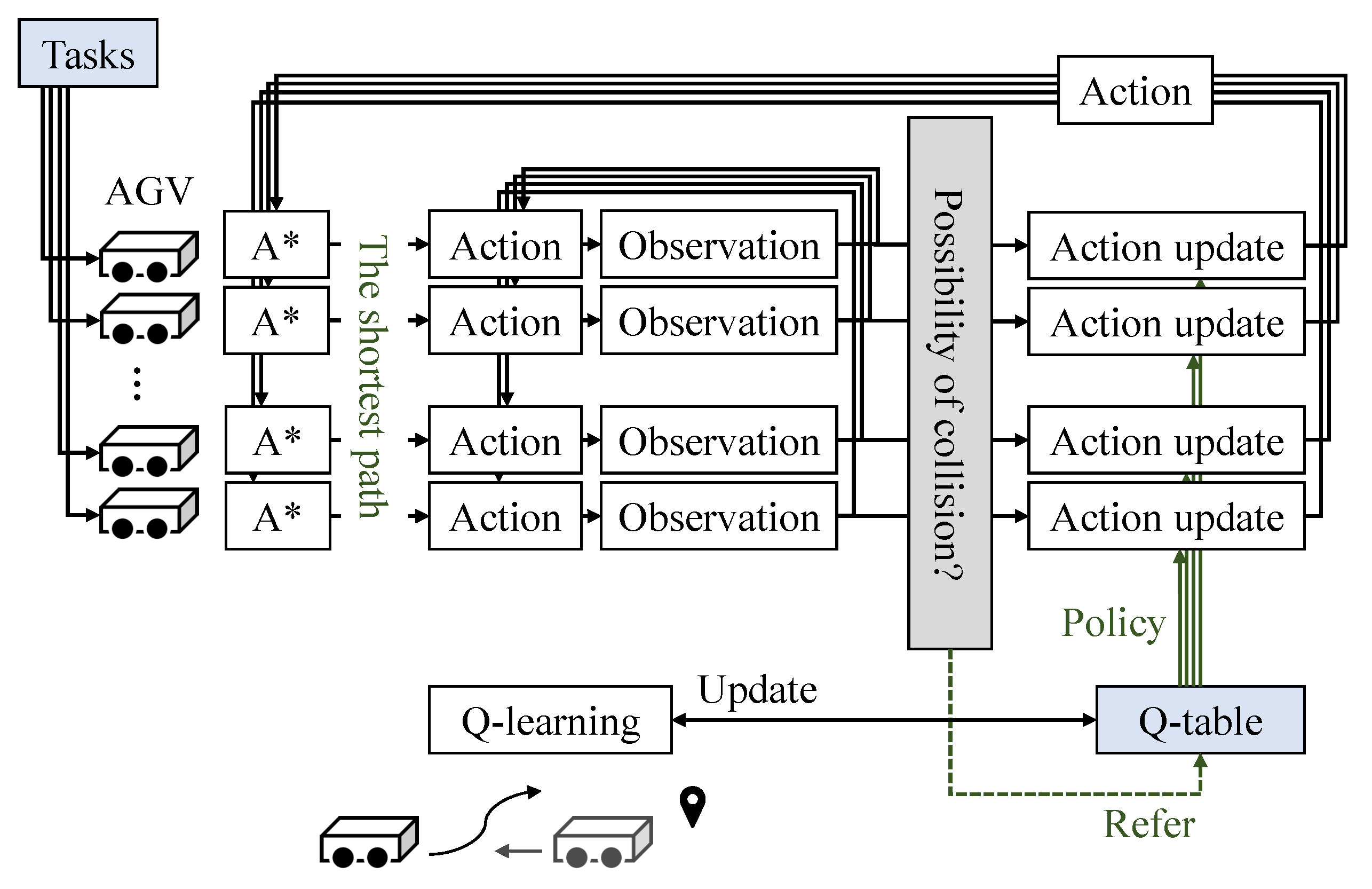
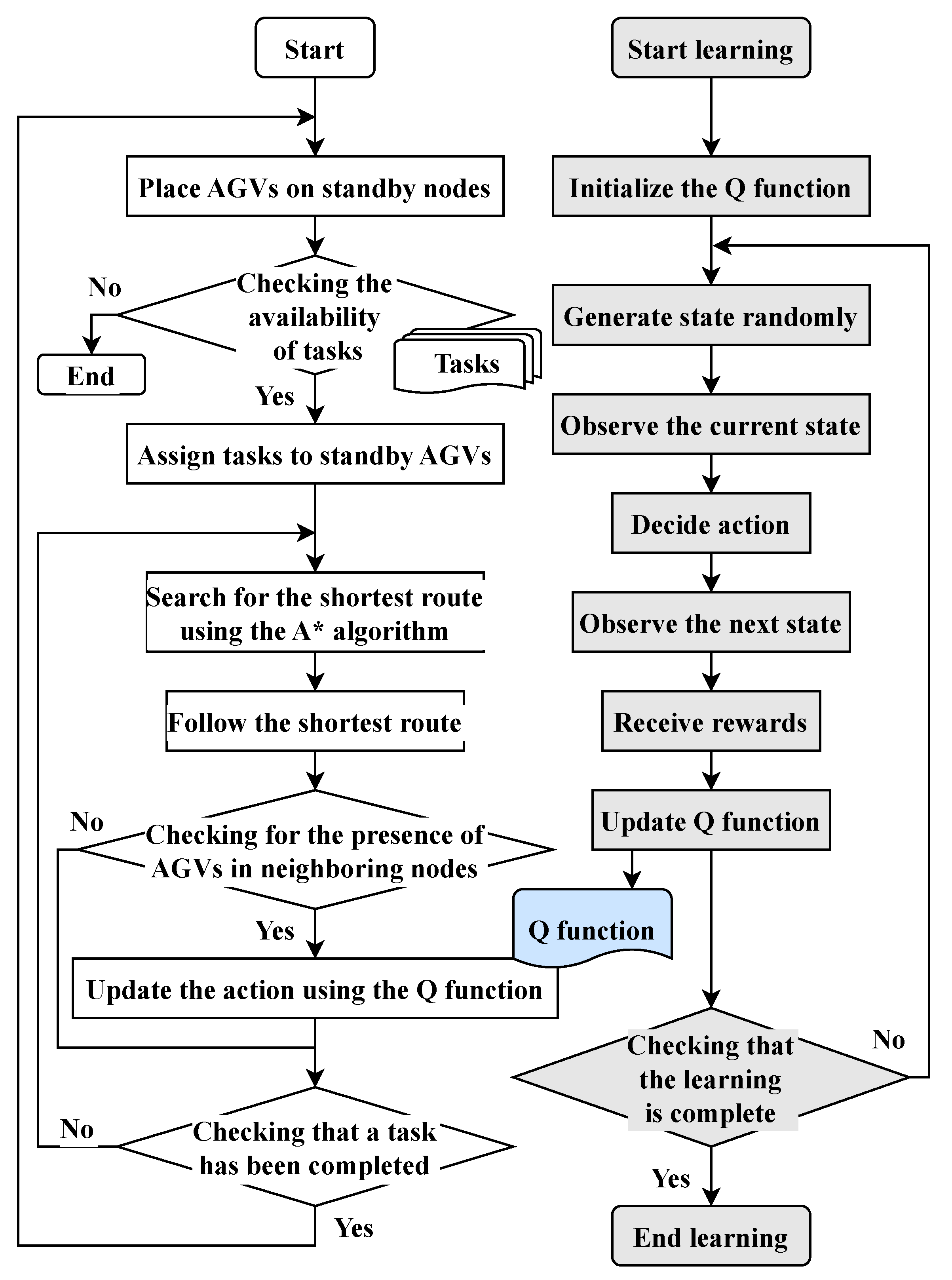
4. Flexible Route Planning Method Combining Q–learning and Graph Search
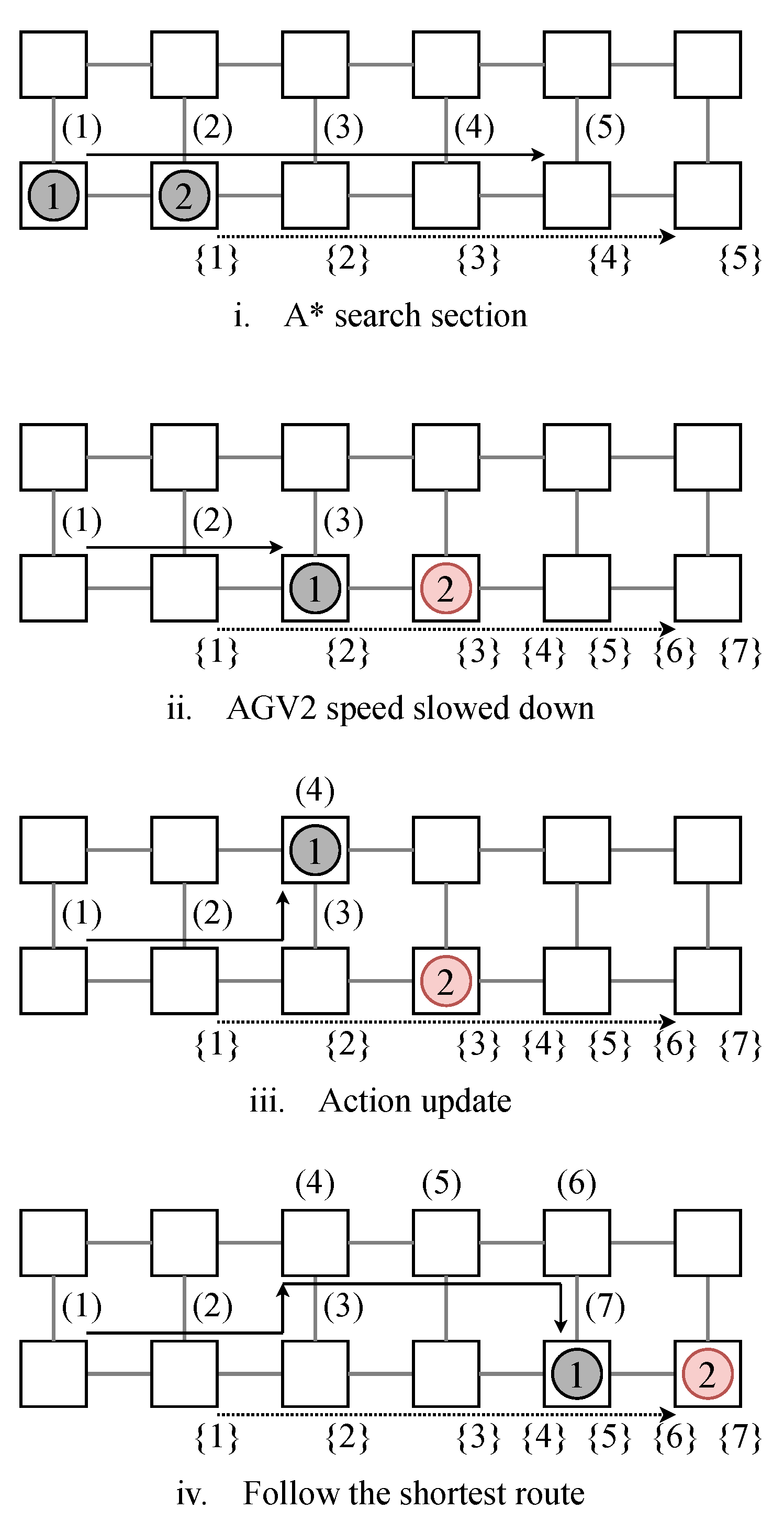
4.1. Outline of the Proposed Method
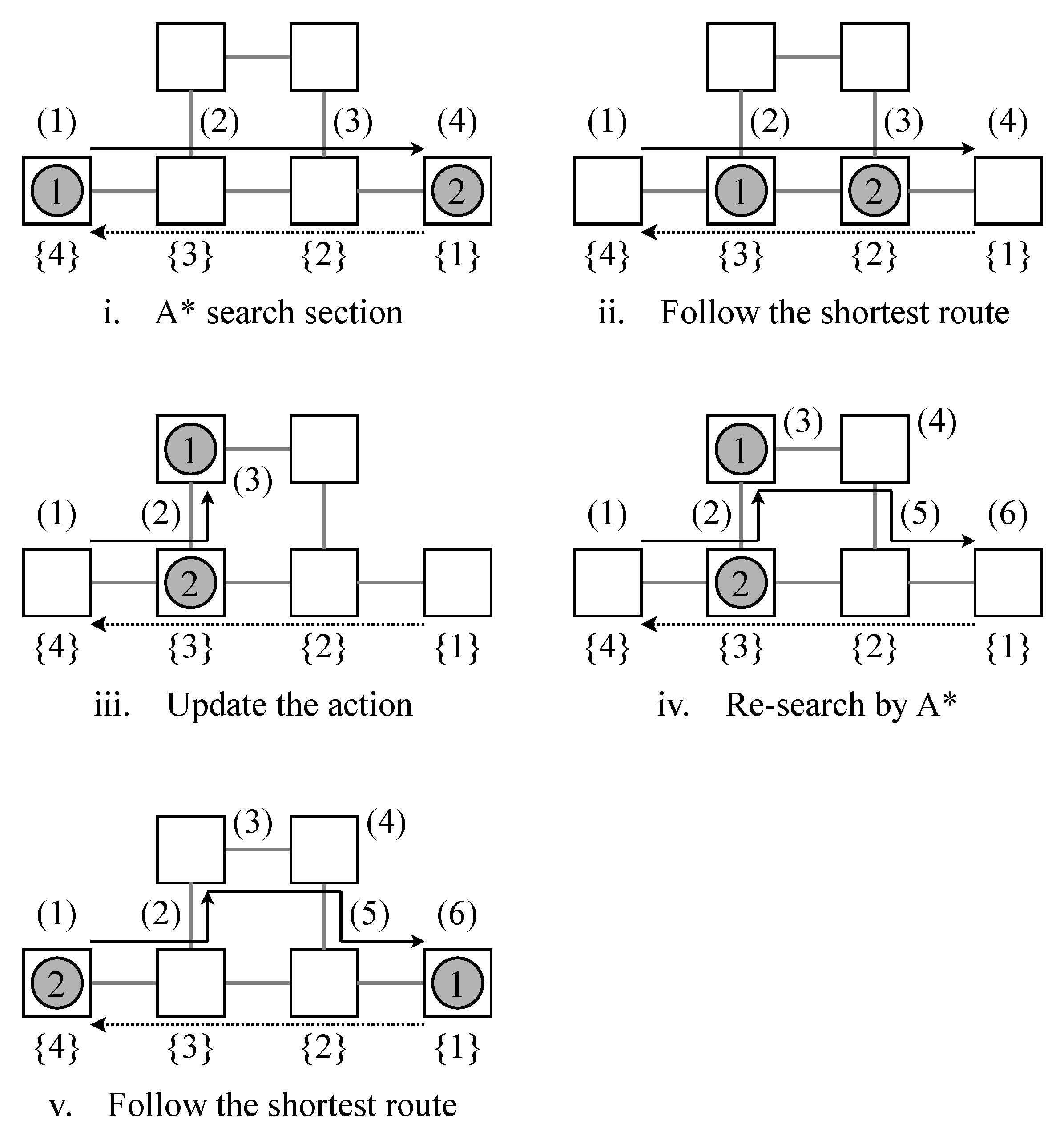
4.2. Combination of A* and Q–learning
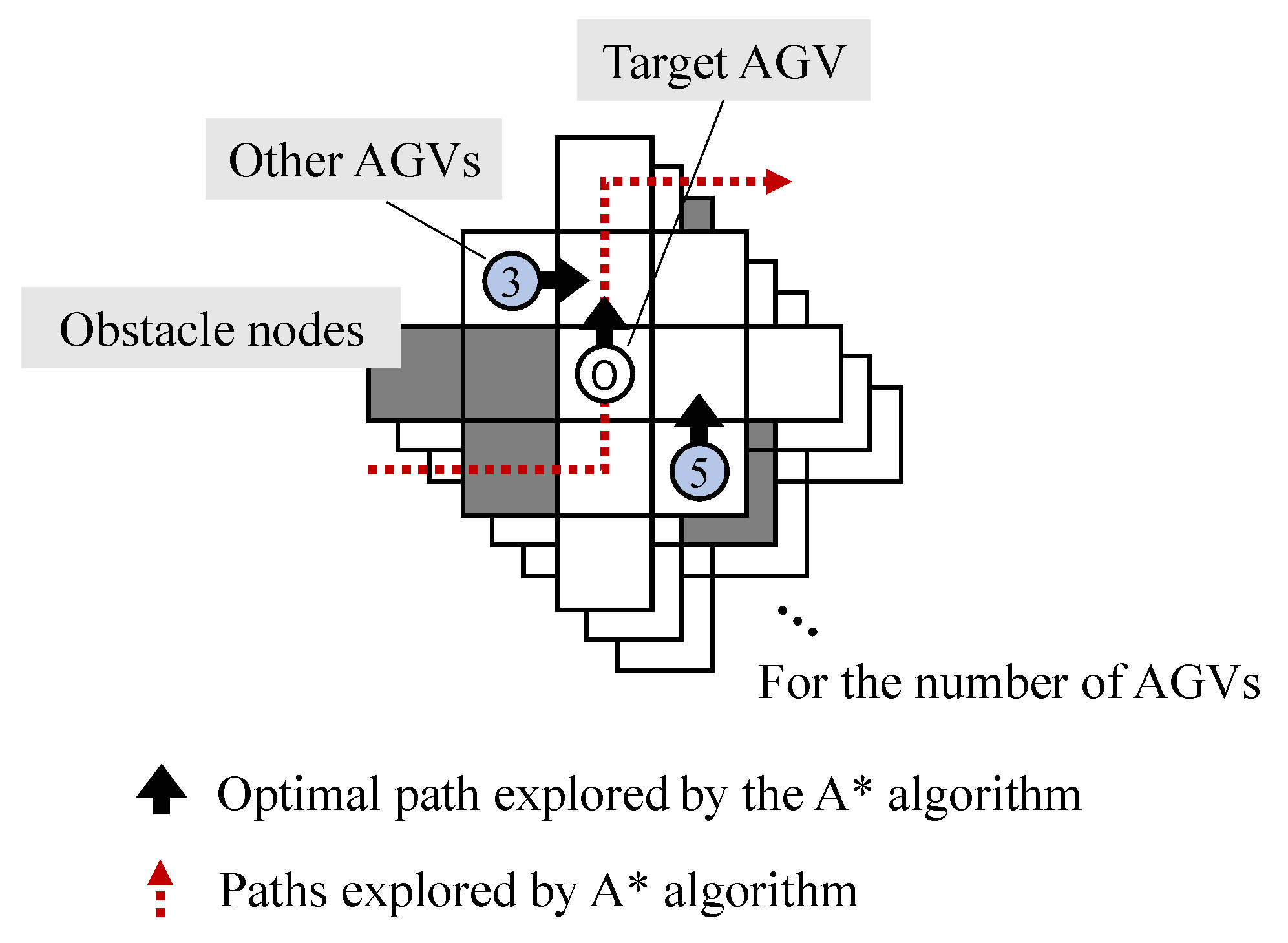
4.2.1. A* Search Algorithm
4.2.2. Q–Learning
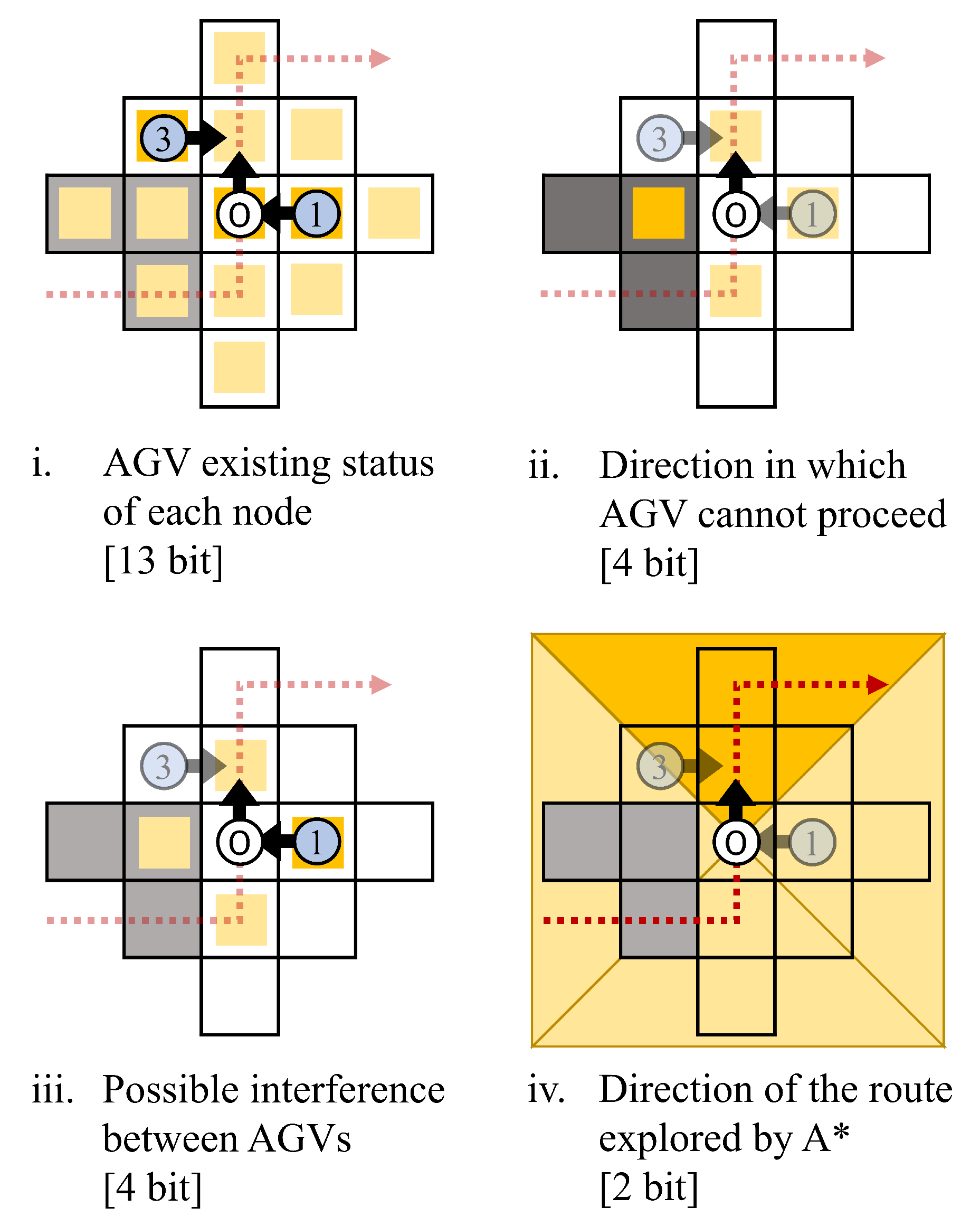
4.2.3. Definition of State Space
4.2.4. Action Spaces
4.2.5. Reward Setting
4.3. Outline of the Proposed Algorithm
5. Computational Experiments
5.1. Experimental Conditions
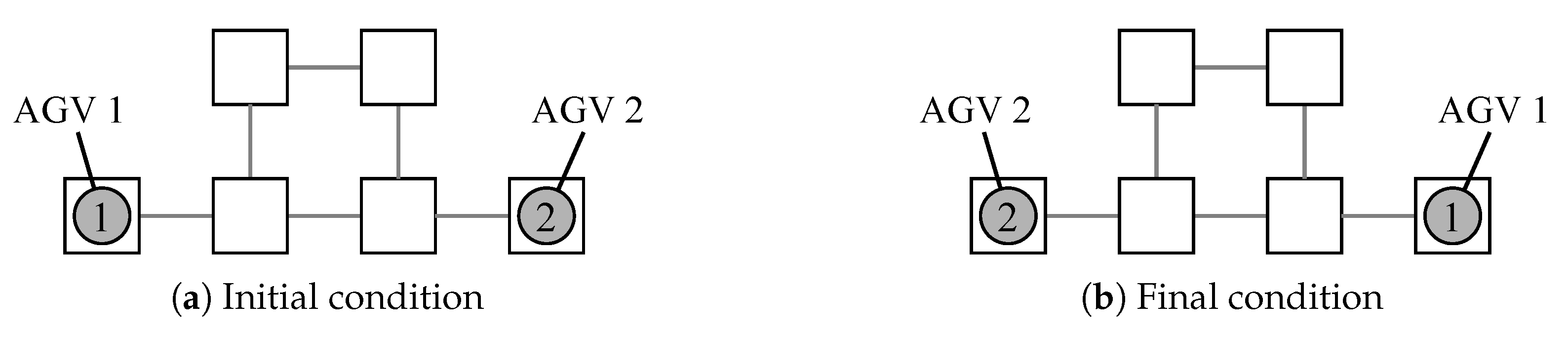
5.2. Application to a Small Scale Instance
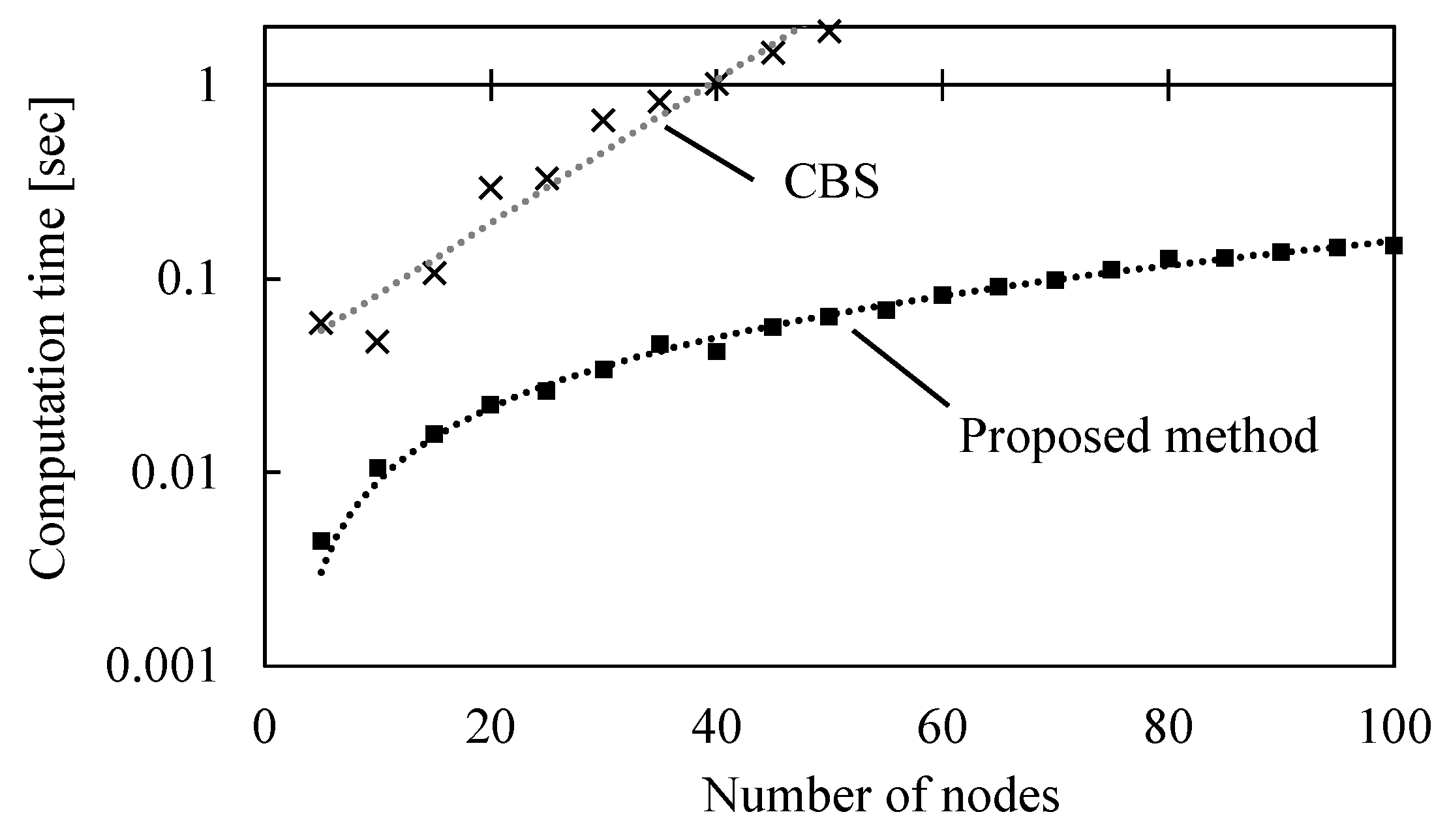
5.3. Computational Experiments for Static Problems
5.3.1. Experimental Setup
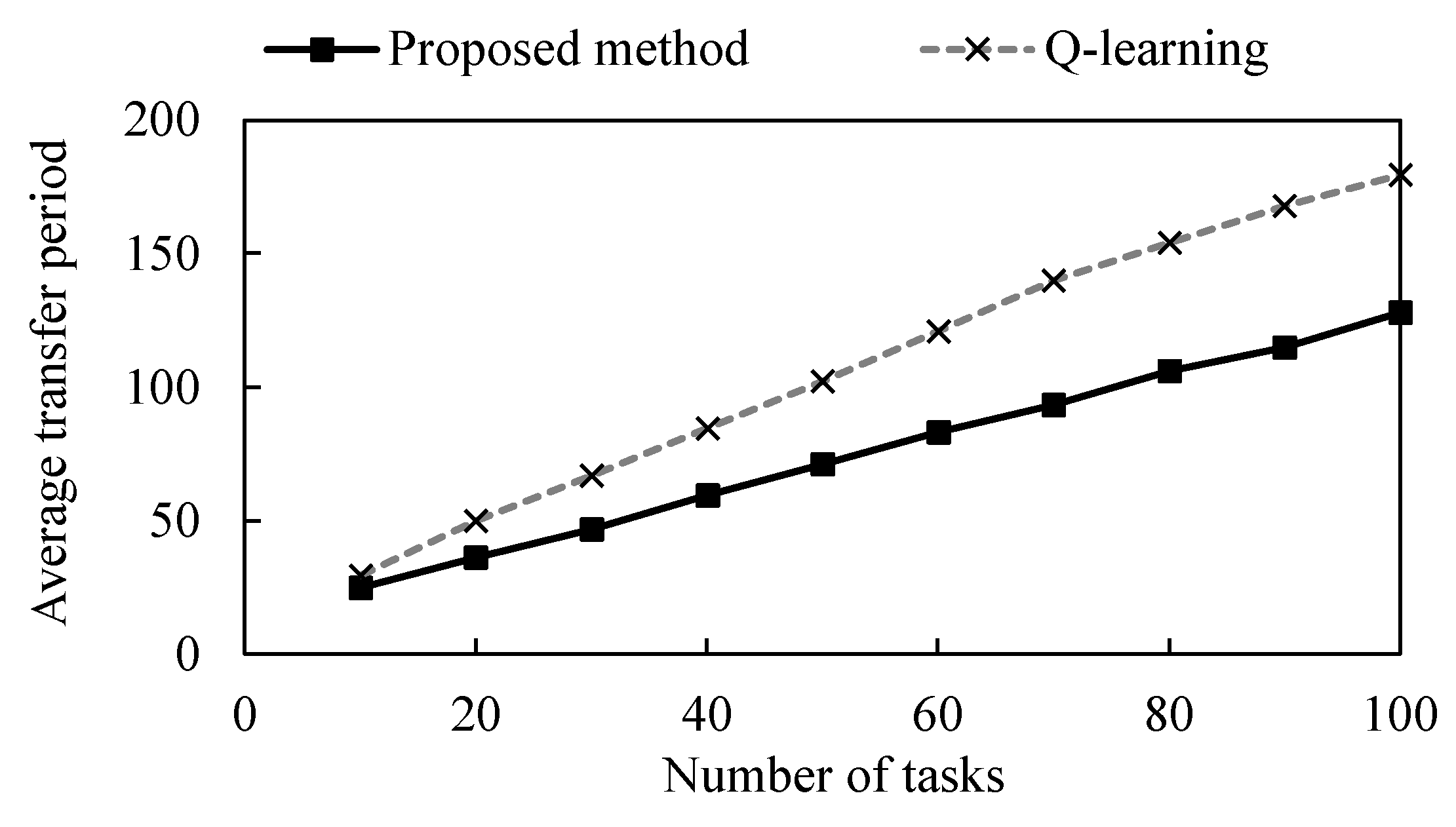
5.3.2. Experimental results
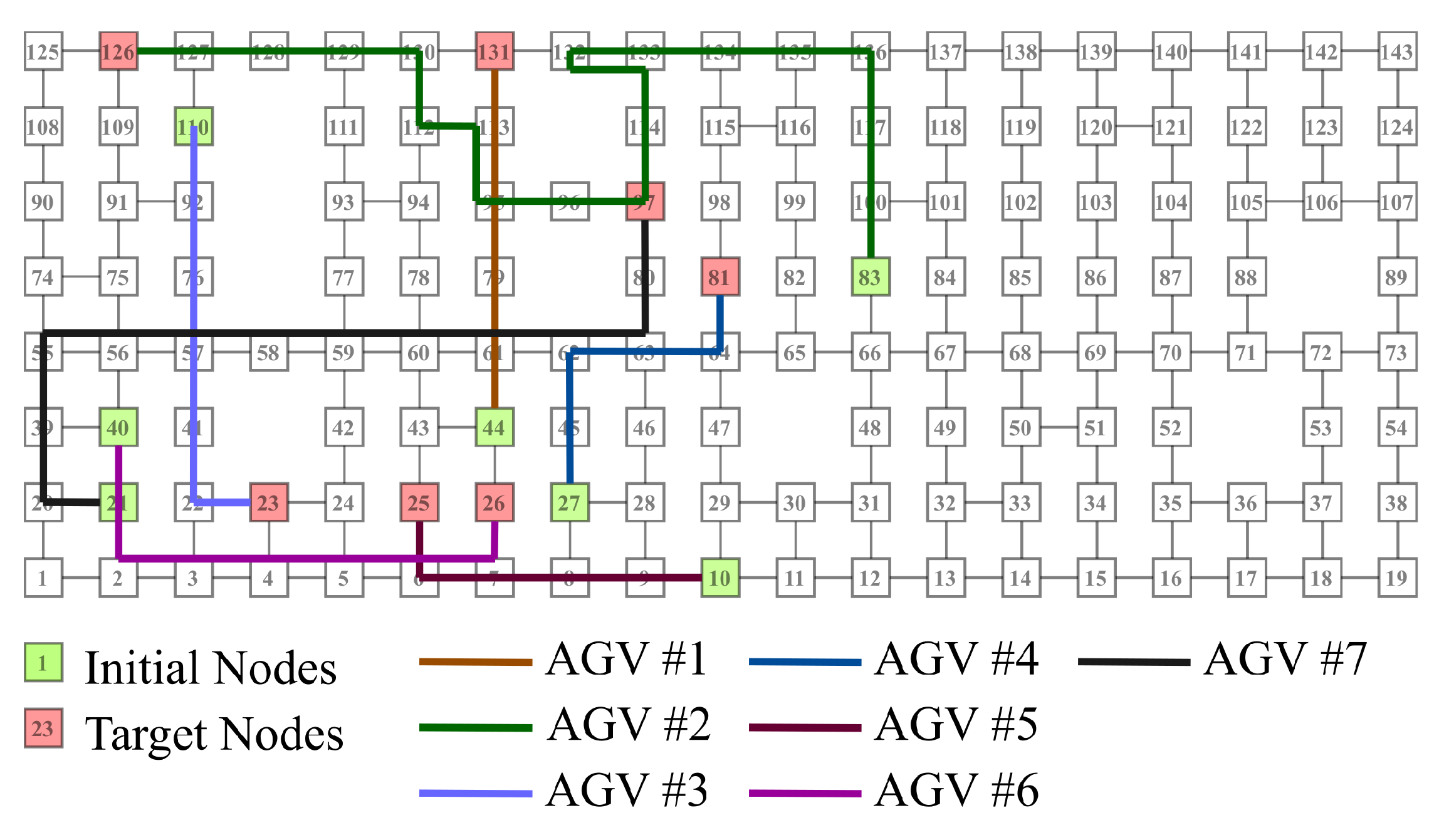
5.3.3. Routing Example
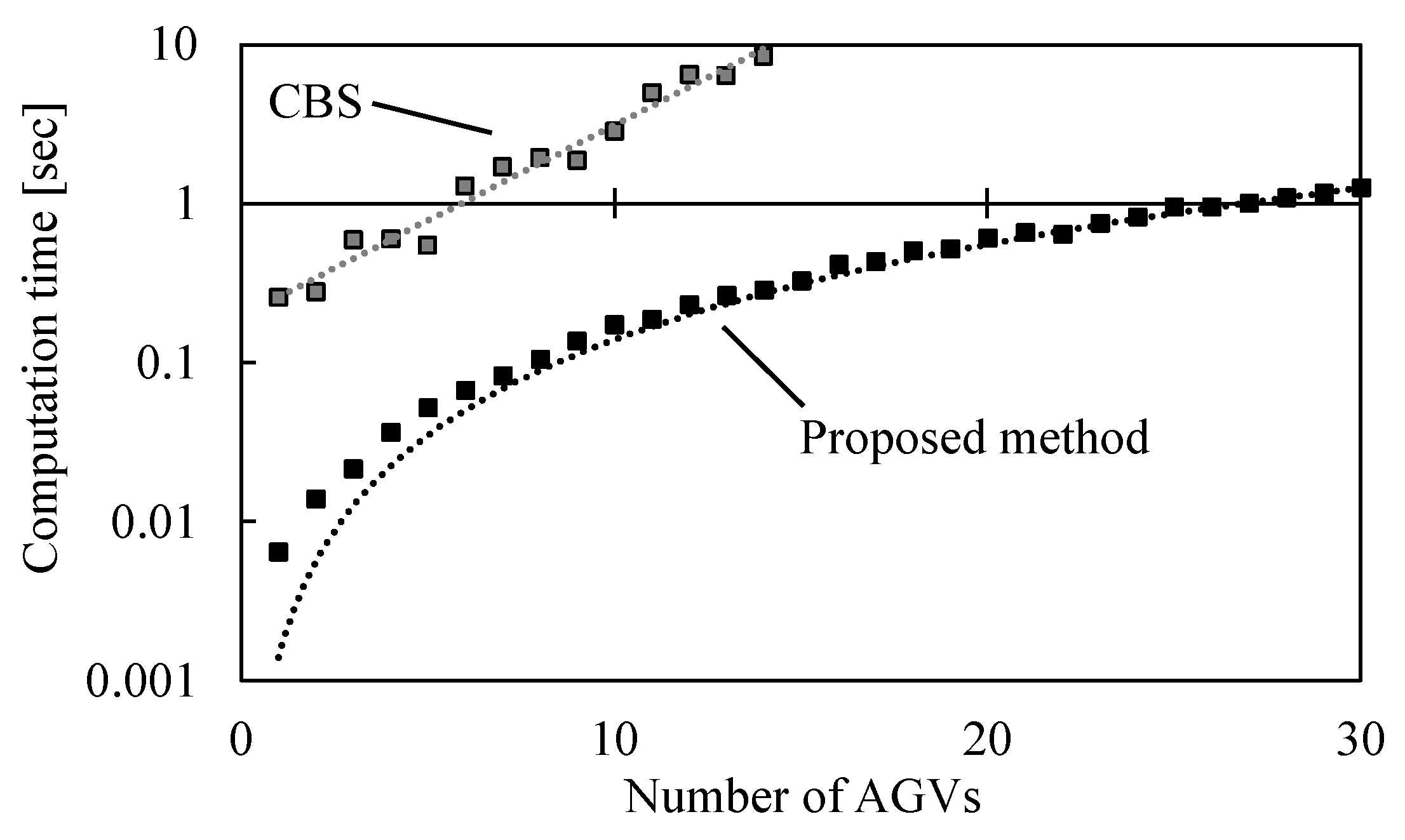
5.4. Experiments in Dynamic Environments
5.4.1. Experimental Setup
5.4.2. Experimental Results
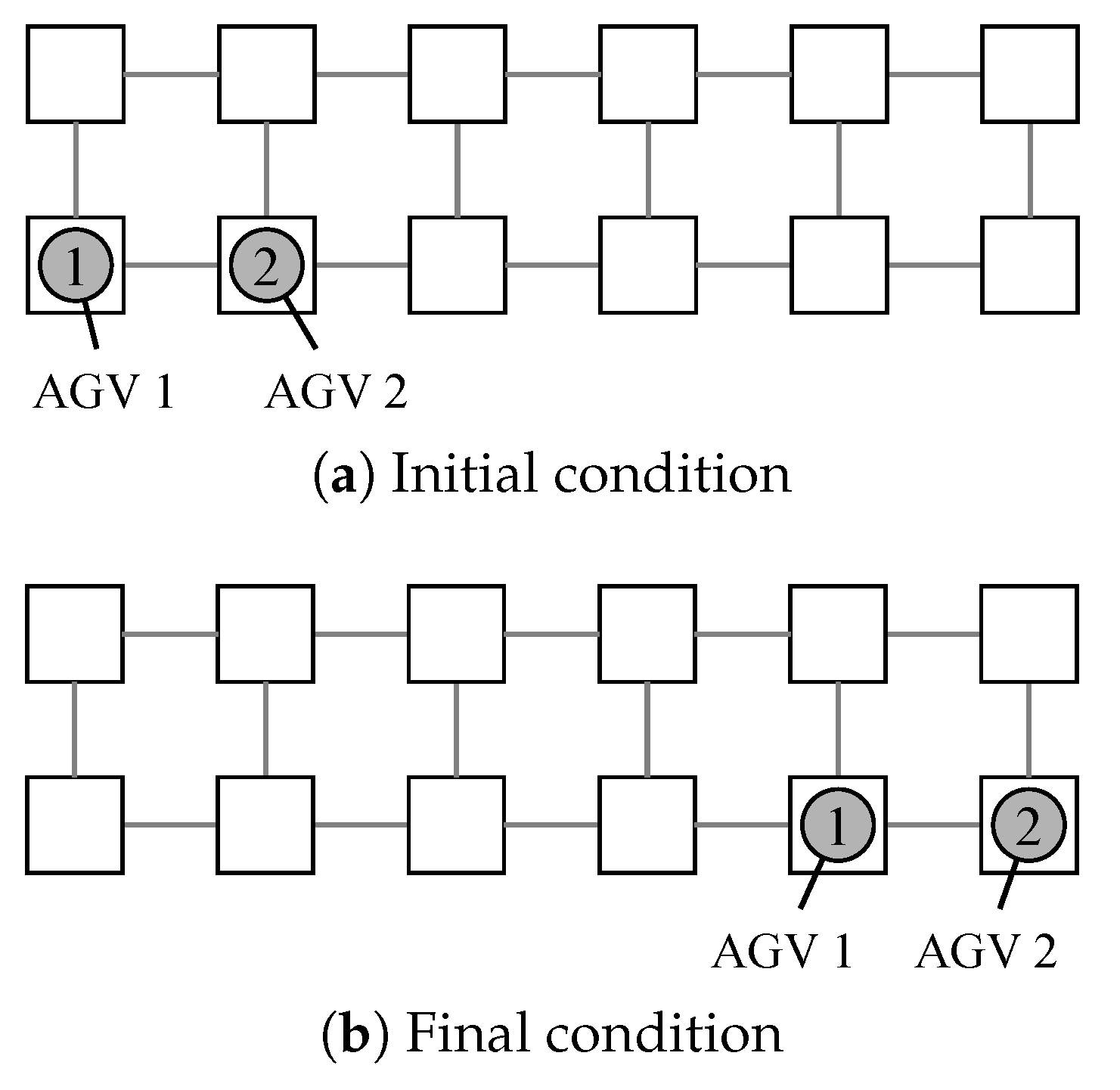
5.5. Flexibility of the Proposed Method
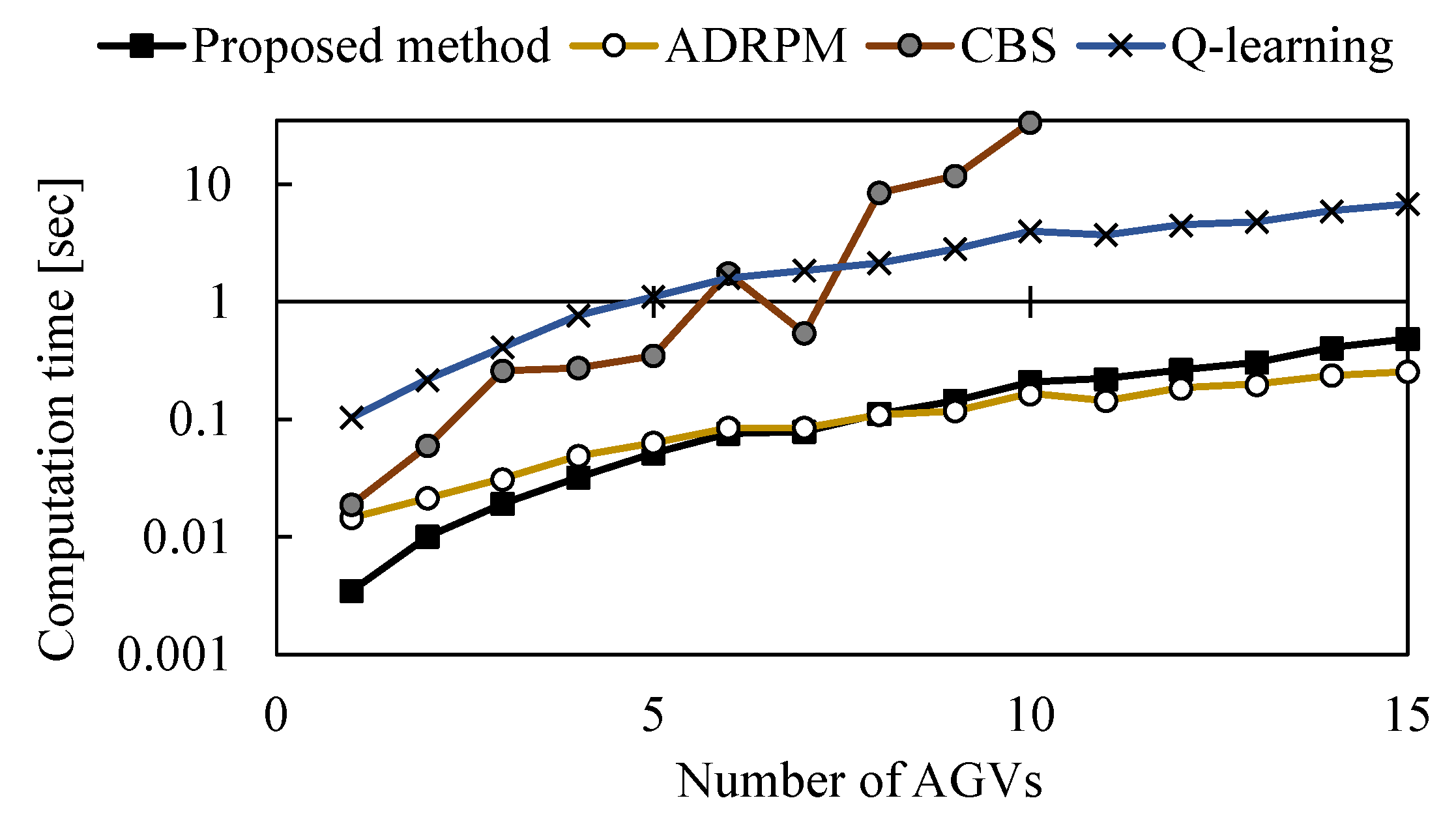
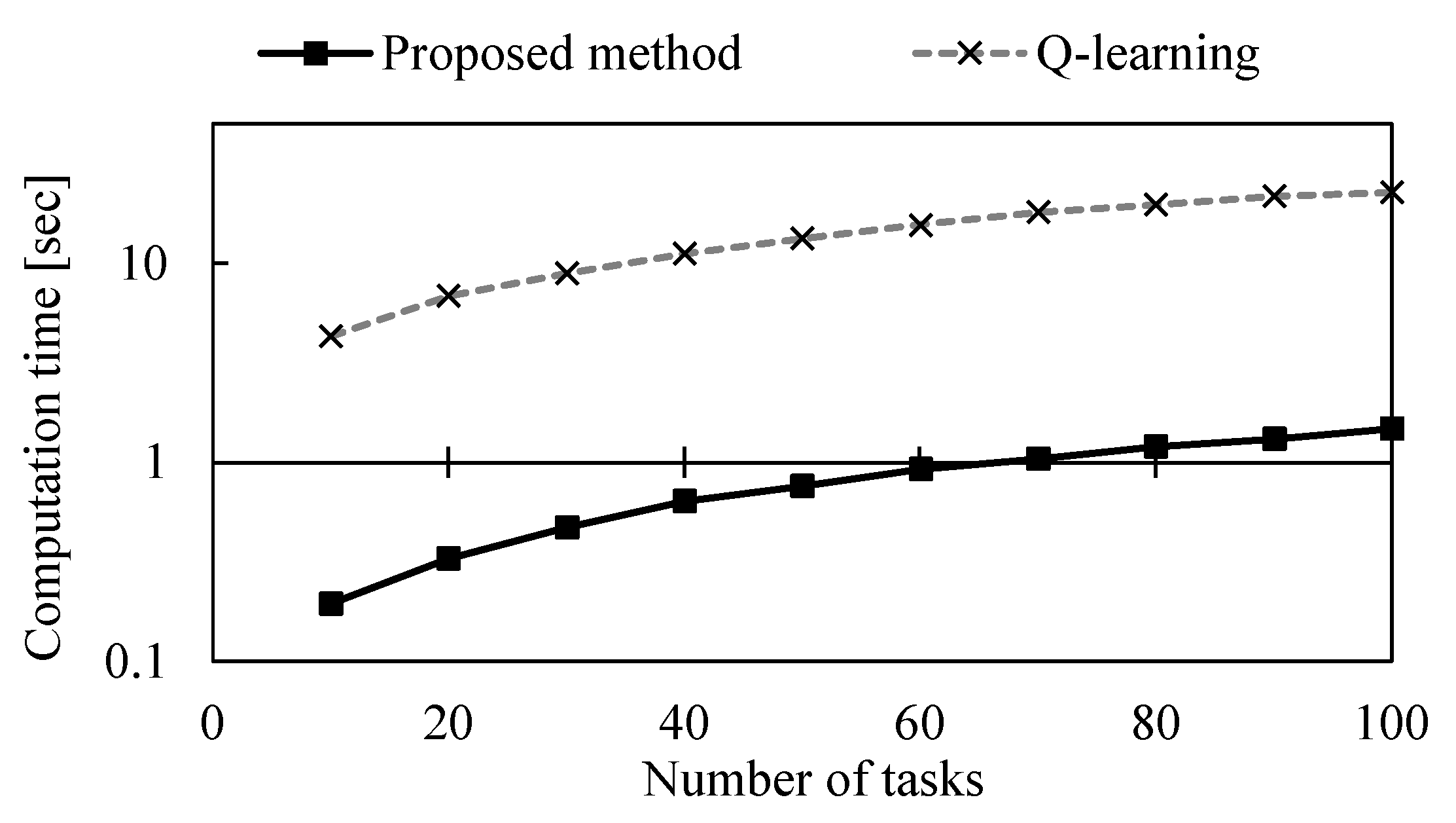
5.6. Computational Efficiency
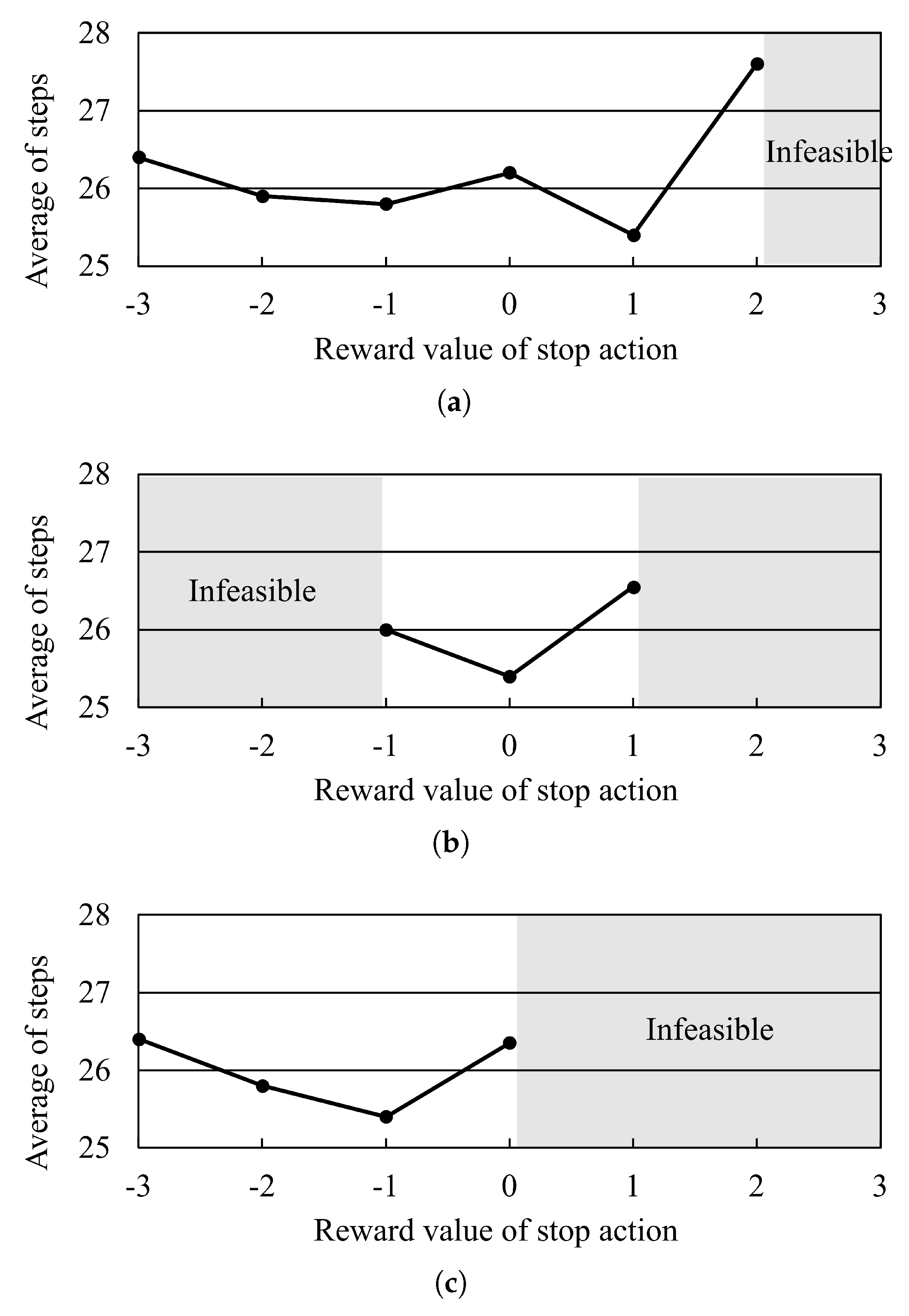
5.7. Impact of Reward Setting
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Le-Anh, T.; de Koster, M.B.M. A Review of Design and Control of Automated Guided Vehicle Systems. Eur. J. Oper. Res. 2006, 171, 1–23. [Google Scholar] [CrossRef]
- Vis, I.F.A. Survey of Research in the Design and Control of Automated Guided Systems. Eur. J. Oper. Res. 2006, 170, 677–709. [Google Scholar] [CrossRef]
- Dowsland, K.A.; Greaves, A.M. Collision Avoidance in Bi-Directional AGV Systems. J. Oper. Res. Soc. 1994, 45, 817–826. [Google Scholar] [CrossRef]
- Svestka, P.; Overmars, M.H. Coordinated Path Planning for Multiple Robots. Robot. Auton. Syst. 1998, 23, 125–152. [Google Scholar] [CrossRef] [Green Version]
- Ferrari, C.; Pagello, E.; Ota, J.; Arai, T. Multirobot Motion Coordination in Space and Time. Robot. Auton. Syst. 1998, 25, 219–229. [Google Scholar] [CrossRef]
- Dotoli, M.; Fanti, M.P. Coloured Timed Petri Net Model for Real–Time Control of Automated Guided Vehicle Systems. Int. J. Prod. Res. 2004, 42, 1787–1814. [Google Scholar] [CrossRef]
- Nishi, T.; Maeno, R. Petri Net Decomposition Approach to Optimization of Route Planning Problems for AGV Systems. IEEE Trans. Autom. Sci. Eng. 2010, 7, 523–537. [Google Scholar] [CrossRef]
- Nishi, T.; Tanaka, Y. Petri Net Decomposition Approach for Dispatching and Conflict–free Routing of Bidirectional Automated Guided Vehicle Systems. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2012, 42, 1230–1243. [Google Scholar] [CrossRef]
- Nishi, T.; Ando, M.; Konishi, M. Distributed Route Planning for Multiple Mobile Robots Using an Augmented Lagrangian Decomposition and Coordination Technique. IEEE Trans. Robot. 2005, 21, 1191–1200. [Google Scholar] [CrossRef]
- Santos, J.; Rebelo, P.M.; Rocha, L.F.; Costa, P.; Veiga, G. A* Based Routing and Scheduling Modules for Multiple AGVs in an Industrial Scenario. Robotics 2021, 10, 72. [Google Scholar] [CrossRef]
- Standley, T.S. Finding Optimal Solutions to Cooperative Pathfinding Problems. Proc. AAAI Conf. Artif. Intell. 2010, 24, 173–178. [Google Scholar] [CrossRef]
- Goldenberg, M.; Felner, A.; Stern, R.; Sharon, G.; Sturtevant, N.R.; Holte, R.C.; Schaeffer, J. Enhanced partial expansion A*. J. Artif. Intell. Res. 2014, 50, 141–187. [Google Scholar] [CrossRef]
- Wagner, G.; Choset, H. Subdimensional Expansion for Multirobot Path Planning. Artif. Intell. 2015, 219, 1–24. [Google Scholar] [CrossRef]
- Sharon, G.; Stern, R.; Felner, A.; Sturtevant, N.R. Conflict–based Search for Optimal Multi-Agent Pathfinding. Artif. Intell. 2015, 219, 40–66. [Google Scholar] [CrossRef]
- Boyarski, E.; Felner, A.; Stern, R.; Sharon, G.; Tolpin, D.; Betzalel, O.; Shimony, E. ICBS: Improved Conflict–based Search Algorithm for Multi-Agent Pathfinding. Proc. Int. Jt. Conf. Artif. Intell. 2015, 1, 740–746. [Google Scholar] [CrossRef]
- Felner, A.; Li, J.; Boyarski, E.; Ma, H.; Cohen, L.T.; Kumar, K.S.; Koenig, S. Adding Heuristics to Conflict–based Search for Multi-Agent Pathfinding. Proc. Int. Conf. Autom. Plan. Sched. 2018, 28, 83–87. [Google Scholar]
- Li, J.; Boyarski, E.; Felner, A.; Ma, H.; Koenig, S. Improved Heuristics for Multi-Agent Path Finding with Conflict–based Search. Proc. Int. Jt. Conf. Artif. Intell. 2019, 1, 442–449. [Google Scholar]
- Hang, H. Graph–based Multi-Robot Path Finding and Planning. Curr. Robot. Rep. 2022, 3, 77–84. [Google Scholar]
- Yang, E.; Gu, D. Multiagent Reinforcement Learning for Multi-Robot Systems: A Survey; Int. Conf. Control, Autom. Robotics. Vision, Singapore. 2004; Volume 1, pp.1–6. Available online: https://www.researchgate.net/profile/Dongbing-Gu/publication/2948830_Multiagent_Reinforcement_Learning_for_Multi-Robot_Systems_A_Survey/links/53f5ac820cf2fceacc6f4f1a/Multiagent-Reinforcement-Learning-for-Multi-Robot-Systems-A-Survey.pdf (accessed on 22 January 2023).
- Boyan, J.A. Technical Update: Least-Squares Temporal Difference Learning. Mach. Learn. 2002, 49, 233–246. [Google Scholar] [CrossRef]
- Bai, Y.; Ding, X.; Hu, D.; Jiang, Y. Research on Dynamic Path Planning of Multi-AGVs Based on Reinforcement Learning. Appl. Sci. 2022, 12, 8166. [Google Scholar] [CrossRef]
- Jeon, S.; Kim, K.; Kopfer, H. Routing Automated Guided Vehicles in Container Terminals Through the Q–learning Technique. Logist. Res. 2011, 3, 19–27. [Google Scholar] [CrossRef]
- Hwang, I.; Jang, Y.J. Q (λ) Learning–based Dynamic Route Guidance Algorithm for Overhead Hoist Transport Systems in Semiconductor Fabs. Int. J. Prod. Res. 2019, 58, 1–23. [Google Scholar] [CrossRef]
- Watanabe, M.; Furukawa, M.; Kinoshita, M.; Kakazu, Y. Acquisition of Efficient Transportation Knowledge by Q–learning for Multiple Autonomous AGVs and Their Transportation Simulation. J. Jpn. Soc. Precis. Eng. 2001, 67, 1609–1614. [Google Scholar] [CrossRef]
- Eda, S.; Nishi, T.; Mariyama, T.; Kataoka, S.; Shoda, K.; Matsumura, K. Petri Net Decomposition Approach for Bi-Objective Routing for AGV Systems Minimizing Total Traveling Time and Equalizing Delivery time. J. Adv. Mech. Des. Syst. Manuf. 2012, 6, 672–686. [Google Scholar] [CrossRef] [Green Version]
- Umar, U.A.; Ariffin, M.K.A.; Ismail, N.; Tang, S.H. Hybrid multiobjective genetic algorithms for integrated dynamic scheduling and routing of jobs and automated-guided vehicle (AGV) in flexible manufacturing systems (FMS) environment. Int. J. Adv. Manuf. Technol. 2015, 81, 2123–2141. [Google Scholar] [CrossRef]
- Duinkerken, M.B.; van der Zee, M.; Lodewijks, G. Dynamic Free Range Routing for Automated Guided Vehicles. In Proceedings of the 2006 IEEE International Conference on Networking, Sensing and Control, Ft. Lauderdale, FL, USA, 23–25 April 2006; pp. 312–317.
- Lou, P.; Xu, K.; Jiang, X.; Xiao, Z.; Yan, J. Path Planning in an Unknown Environment Based on Deep Reinforcement Learning with Prior Knowledge. J. Intell. Fuzzy Syst. 2021, 41, 5773–5789. [Google Scholar] [CrossRef]
- Qiu, L.; Hsu, W.J.; Huang, S.Y.; Wang, H. Scheduling and Routing Algorithms for AGVs: A Survey. Int. J. Prod. Res. 2002, 40, 745–760. [Google Scholar] [CrossRef]
- Liang, C.; Zhang, Y.; Dong, L. A Three Stage Optimal Scheduling Algorithm for AGV Route Planning Considering Collision Avoidance under Speed Control Strategy. Mathematics 2023, 11, 138. [Google Scholar] [CrossRef]
- Zhou, P.; Lin, L.; Kim, K.H. Anisotropic Q–learning and Waiting Estimation Based Real–Time Routing for Automated Guided Vehicles at Container Terminals. J. Heuristics 2021, 1, 1–22. [Google Scholar] [CrossRef]
- Pedan, M.; Gregor, M.; Plinta, D. Implementation of Automated Guided Vehicle System in Healthcare Facility. Procedia Eng. 2017, 192, 665–670. [Google Scholar] [CrossRef]
- Yu, J.; LaValle, S.M. Optimal Multirobot Path Planning on Graphs: Complete Algorithms and Effective Heuristics. IEEE Trans. Robot. 2016, 32, 1163–1177. [Google Scholar] [CrossRef]
- Erdem, E.; Kisa, D.G.; Oztok, U.; Schueller, P. A General Formal Framework for Pathfinding Problems with Multiple Agents. In Proceedings of the AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013; pp. 290–296. [Google Scholar]
- Gómez, R.N.; Hernández, C.; Baier, J.A. Solving Sum-Of-Costs Multi-Agent Pathfinding with Answer-Set Programming. AAAI Conf. Artif. Intell. 2020, 34, 9867–9874. [Google Scholar] [CrossRef]
- Surynek, P. Reduced Time-Expansion Graphs and Goal Decomposition for Solving Cooperative Path Finding Sub-Optimally. Int. Jt. Conf. Artif. Intell. 2015, 1916–1922. [Google Scholar]
- Wang, J.; Li, J.; Ma, H.; Koenig, S.; Kumar, T.K.S. A New Constraint Satisfaction Perspective on Multi-Agent Path Finding: Preliminary Results. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 417–423. [Google Scholar]
- Han, S.D.; Yu, J. Integer Programming as a General Solution Methodology for Path–based Optimization in Robotics: Principles, Best Practices, and Applications. In Proceedings of the International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; pp. 1890–1897. [Google Scholar]
- Luna, R.; Bekris, K.E. Push and Swap: Fast Cooperative Path-Finding with Completeness Guarantees. In Proceedings of the International Joint Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; pp. 294–300. [Google Scholar]
- Sajid, Q.; Luna, R.K.; Bekris, E. Multi-Agent Pathfinding with Simultaneous Execution of Single-Agent Primitives. In Proceedings of the 5th Annual Symposium on Combinatorial Search, Niagara Falls, ON, Canada, 19–21 July 2012; pp. 88–96. [Google Scholar]
- Huang, T.; Koenig, S.; Dilkina, B. Learning to Resolve Conflicts for Multi-Agent Path Finding with Conflict–based Search. Proc. Aaai Conf. Artif. Intell. 2021, 35, 11246–11253. [Google Scholar] [CrossRef]
- Huang, T.; Dilkina, B.; Koenig, S. Learning Node-Selection Strategies in Bounded-Suboptimal Conflict–based Search for Multi-Agent Path Finding. In Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, Virtual Conference, Online, 3–7 May 2021; pp. 611–619. [Google Scholar]
- Lim, J.K.; Kim, K.H.; Lim, J.M.; Yoshimoto, K.; Takahashi, T. Routing Automated Guided Vehicles Using Q–learning. J. Jpn. Ind. Manag. Assoc. 2003, 54, 1–10. [Google Scholar]
- Sahu, B.; Kumar Das, P.; Kabat, M.R. Multi-Robot Cooperation and Path Planning for Stick Transporting Using Improved Q–learning and Democratic Robotics PSO. J. Comput. Sci. 2022, 60, 101637. [Google Scholar] [CrossRef]
- Yang, Y.; Li, J.; Peng, L. Multi-robot path planning based on a deep reinforcement learning DQN algorithm. CAAI Trans. Intell. Technol. 2020, 5, 177–183. [Google Scholar] [CrossRef]
- Guan, M.; Yang, F.X.; Jiao J., C.; Chen, X.P. Research on Path Planning of Mobile Robot Based on Improved Deep Q Network. J. Phys. Conf. Ser. 2021, 1820, 012024. [Google Scholar] [CrossRef]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef] [Green Version]
- Choi, H.B.; Kim, J.B.; Han, Y.H.; Oh, S.W.; Kim, K. MARL–based Cooperative Multi-AGV Control in Warehouse Systems. IEEE Access 2022, 10, 100478–100488. [Google Scholar] [CrossRef]
- Chujo, T.; Nishida, K.; Nishi, T. A Conflict–free Routing Method for Automated Guided Vehicles Using Reinforcement Learning. In Proceedings of the International Symposium on Flexible Automation, Virtual Conference, Online, 8–9 July 2020. Paper No. ISFA2020-9620. [Google Scholar]
- Ando, M.; Nishi, T.; Konishi, M.; Imai, J. An Autonomous Distributed Route Planning Method for Multiple Mobile Robots. Trans. Soc. Instrum. Control. Eng. 2003, 39, 759–766. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Problem | Approach | Real–Time Routing | Continuous Space |
|---|---|---|---|---|
| Jeon, S.M. et al. [22] | AGVs in port terminals | Q–learning | ✓ | |
| Lim, J.K. et al. [43] | Multiple AGVs on a grid based network | Q–learning | ✓ | |
| Sahu, B. et al. [44] | 2 actual robots | Q–learning + PSO | ||
| Hwang, I. et al. [23] | Semiconductor wafer fabrication facilities | Non–stationary Q–learning | ✓ | |
| Zhou, P. et al. [31] | Container terminals | Anisotropic Q–learning | ✓ | |
| Yang, Y. et al. [45] | Multiple AGVs on a grid based network | DQN | ✓ | |
| Guan, M. et al. [46] | A single AGV on a grid based network | DQN + reward function with heustick | ✓ | |
| Bae, H. et al. [47] | Multiple AGVs on a grid based network | DQN + prior knowledge | ✓ | |
| Lou, P. et al. [28] | A single AGVs in continuous space | DQN + prior knowledge | ✓ | ✓ |
| Choi, H.B. et al. [48] | Multiple AGVs on a grid based network | QMIX | ✓ | |
| Current research | Multiple AGVs on a grid based network | Q–learning + A* algorithm | ✓ |
| AGV | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Initial node | 44 | 83 | 110 | 27 | 10 | 40 | 21 |
| Destination node | 131 | 126 | 23 | 81 | 25 | 26 | 97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kawabe, T.; Nishi, T.; Liu, Z. Flexible Route Planning for Multiple Mobile Robots by Combining Q–Learning and Graph Search Algorithm. Appl. Sci. 2023, 13, 1879. https://doi.org/10.3390/app13031879
Kawabe T, Nishi T, Liu Z. Flexible Route Planning for Multiple Mobile Robots by Combining Q–Learning and Graph Search Algorithm. Applied Sciences. 2023; 13(3):1879. https://doi.org/10.3390/app13031879
Chicago/Turabian StyleKawabe, Tomoya, Tatsushi Nishi, and Ziang Liu. 2023. "Flexible Route Planning for Multiple Mobile Robots by Combining Q–Learning and Graph Search Algorithm" Applied Sciences 13, no. 3: 1879. https://doi.org/10.3390/app13031879