
SelfCCL: Curriculum Contrastive Learning by Transferring Self-Taught Knowledge for Fine-Tuning BERT


Abstract
:1. Introduction
- We present a SelfCCL model for fine-tuning BERT based on the combination of curriculum learning and contrastive learning;
- Our model transfers self-taught knowledge to score and sorts input-data triplets;
- Our model surpasses the previous state-of-the-art models;
- The results reveal that the use of curriculum learning along with contrastive learning partially increases the average performance.
2. Related Works
- -
- Her favorite to eat is a date.
- -
- They went on a date tonight.
- -
- What is your date of birth?
3. Background
3.1. Contrastive Learning
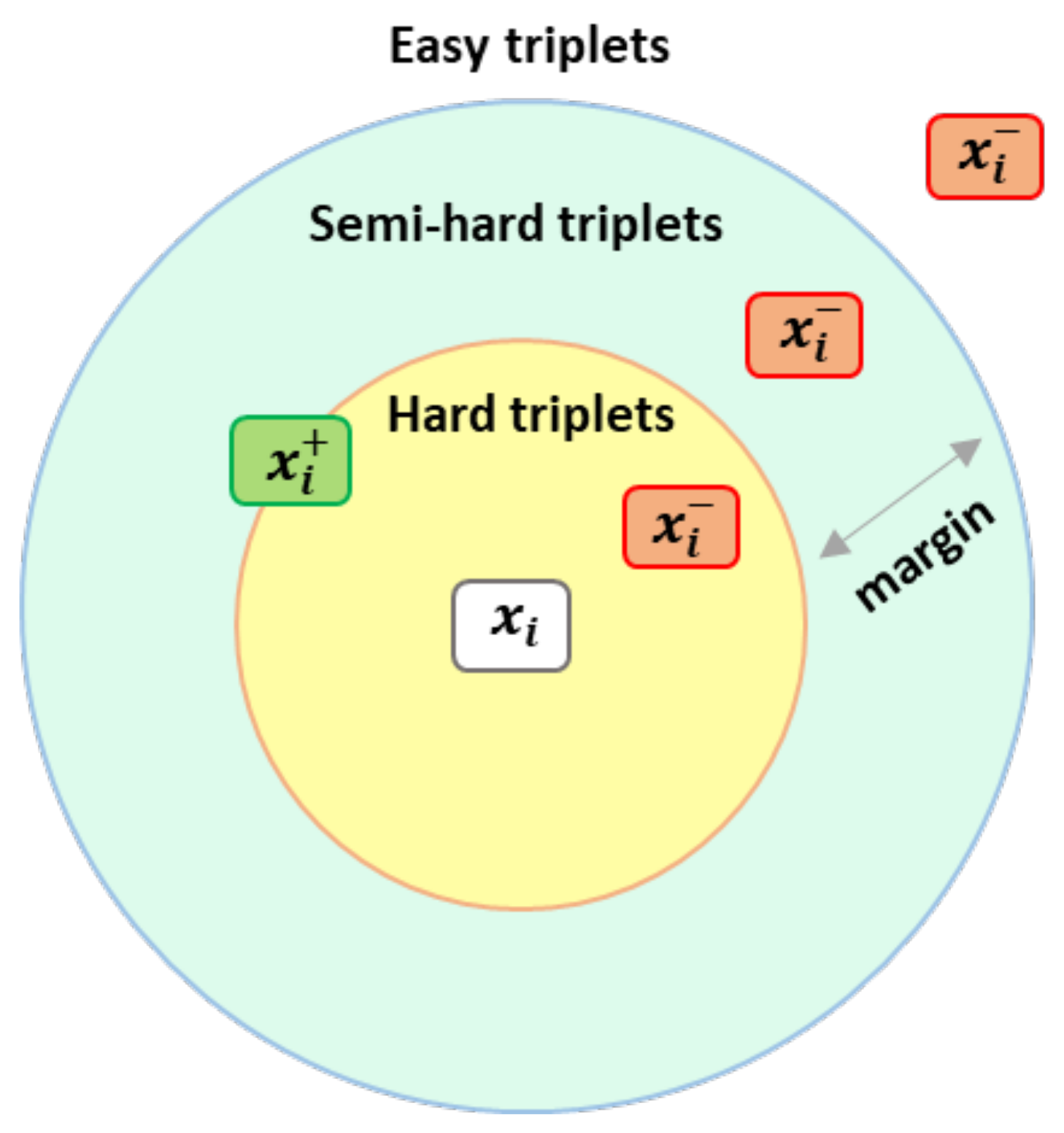
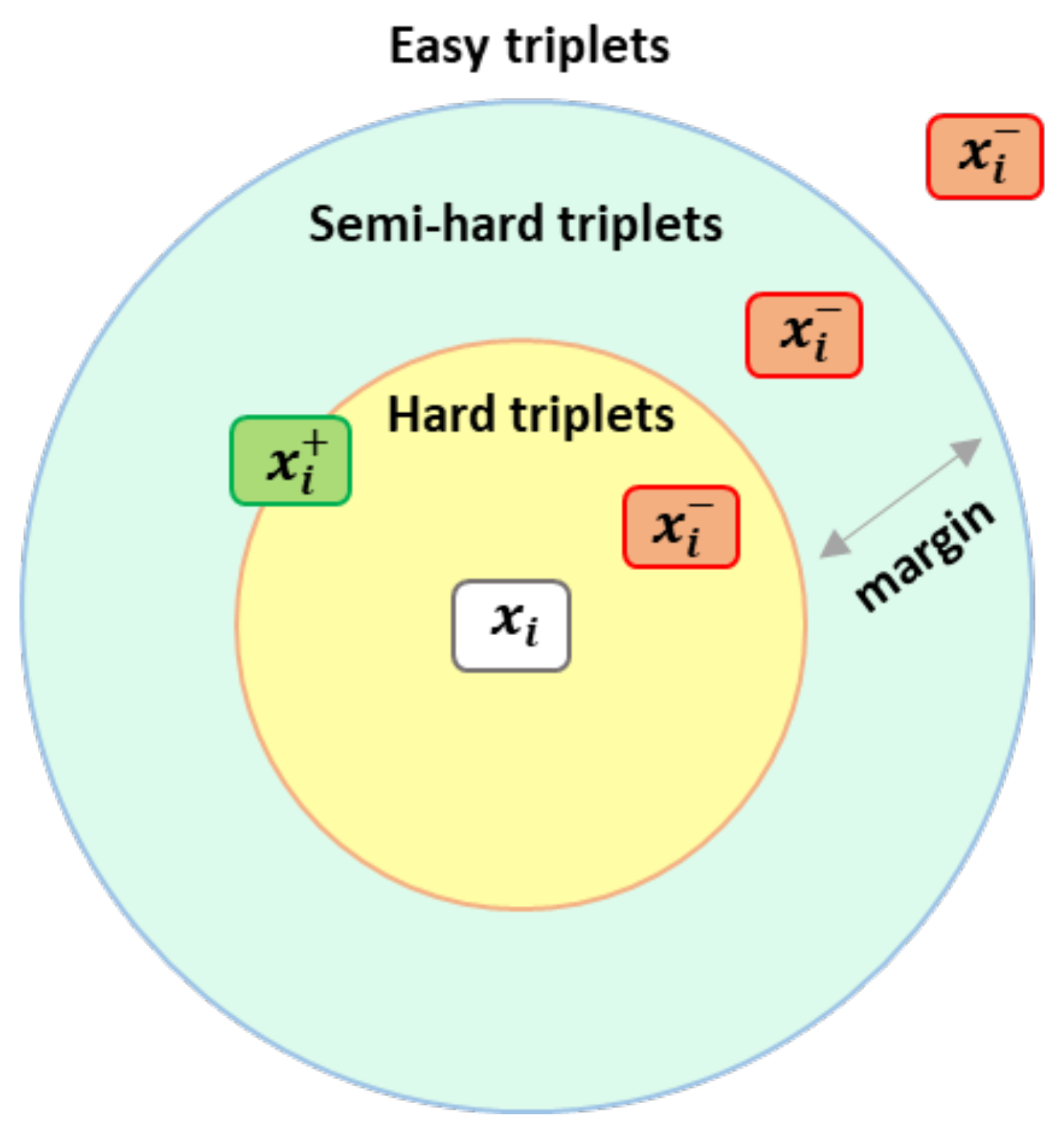
Triplet Mining
3.2. Curriculum Learning
- Scoring function: The scoring function determines the criterion for scoring data to easy and hard samples. For example, in natural language processing tasks, word frequency and sentence length are mostly used as a criterion for difficulty measurer [46]. So, expressed mathematically, the scoring function is a map from an input example, x, to a numerical score, , where a higher score corresponds to a more difficult example [48].
- Pacing function: The pacing function determines when harder samples are presented to the model during the training process. To put it simply, the pacing function determines the size of training data to be used at epoch t.
- The order: The order corresponds to ascending (curriculum), descending (anti-curriculum), and random-curriculum. Anti-curriculum learning uses the scoring function, in which training examples are sorted in descending order of difficulty; thus, the more difficult examples are queried before the easier ones [49]. In the random-curriculum, the size of the batch is dynamically grown over time, while the examples within the batch are randomly ordered [48,50].
3.3. Transfer Learning and Self-Taught Learning
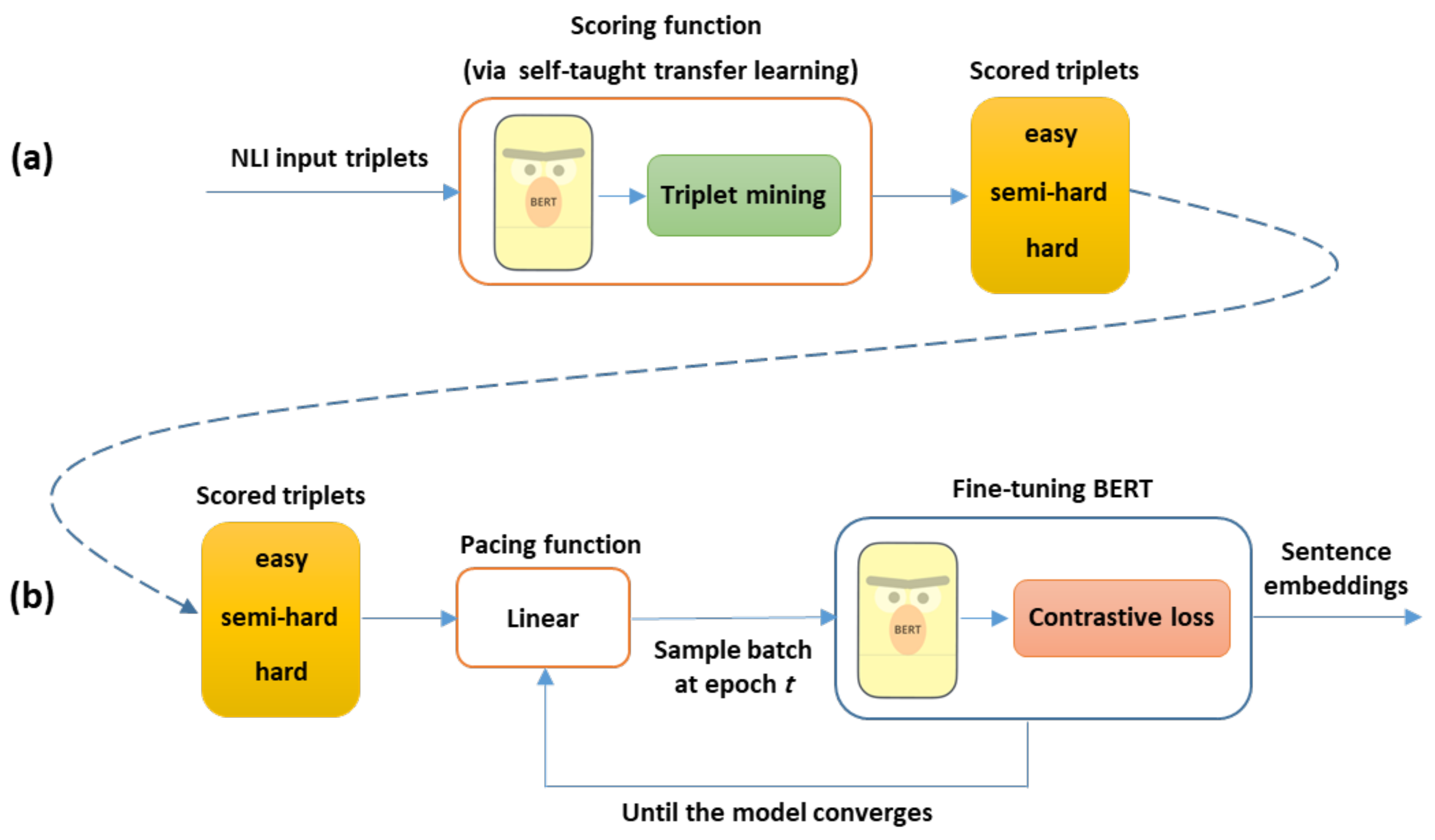
4. SelfCCL: Curriculum Contrastive Learning by Transferring Self-Taught Knowledge for Fine-Tuning BERT
4.1. Methodology
4.2. Training Data
4.3. Curriculum Setting
4.3.1. Scoring Function
- Easy triplets:
- Semi-hard triplets:
- Hard triplets:
4.3.2. Pacing Function
4.4. Training Objective
5. Experiments
5.1. Training Setups
5.2. Baseline and Previous Models
5.3. Reproducing SBERT-Base-Nli-V2 Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | GPU | Number of GPUs Used in Training | Number of Training Epochs | Batch Size | The Form of Input Triplets for Contrastive Objective | Using Curriculum Learning |
|---|---|---|---|---|---|---|
| SupMPN-BERTbase | Nvidia A100 80 GB | 8 | 3 | 512 | No | |
| SimCSE-BERTbase | Nvidia 3090 24 GB | Not reported | 3 | 512 | No | |
| SBERT-base-nli-v2 | Nvidia A100 80 GB | 1 | 3 | 350 | No | |
| SelfCCL-BERTbase | Nvidia A100 80 GB | 4 | 4 | 512 | Yes | |
| SelfCCL-SBERTbase | Nvidia A100 80 GB | 1 | 4 | 350 | Yes |
5.4. First Experiment: Evaluate the Model for STS Tasks
5.5. Second Experiment: Evaluate the Model for Transfer Learning Tasks
- MR [66]: Binary sentiment prediction on movie reviews.
- CR [67]: Binary sentiment prediction on customer product reviews.
- SUBJ [68]: Binary subjectivity prediction on movie reviews and plot summaries.
- MPQA [69]: Phrase-level opinion polarity classification.
- SST-2 [70]: Stanford Sentiment Treebank with binary labels.
- TREC [71]: Question type classification with six classes.
- MRPC [72]: Microsoft Research Paraphrase Corpus for paraphrase prediction.
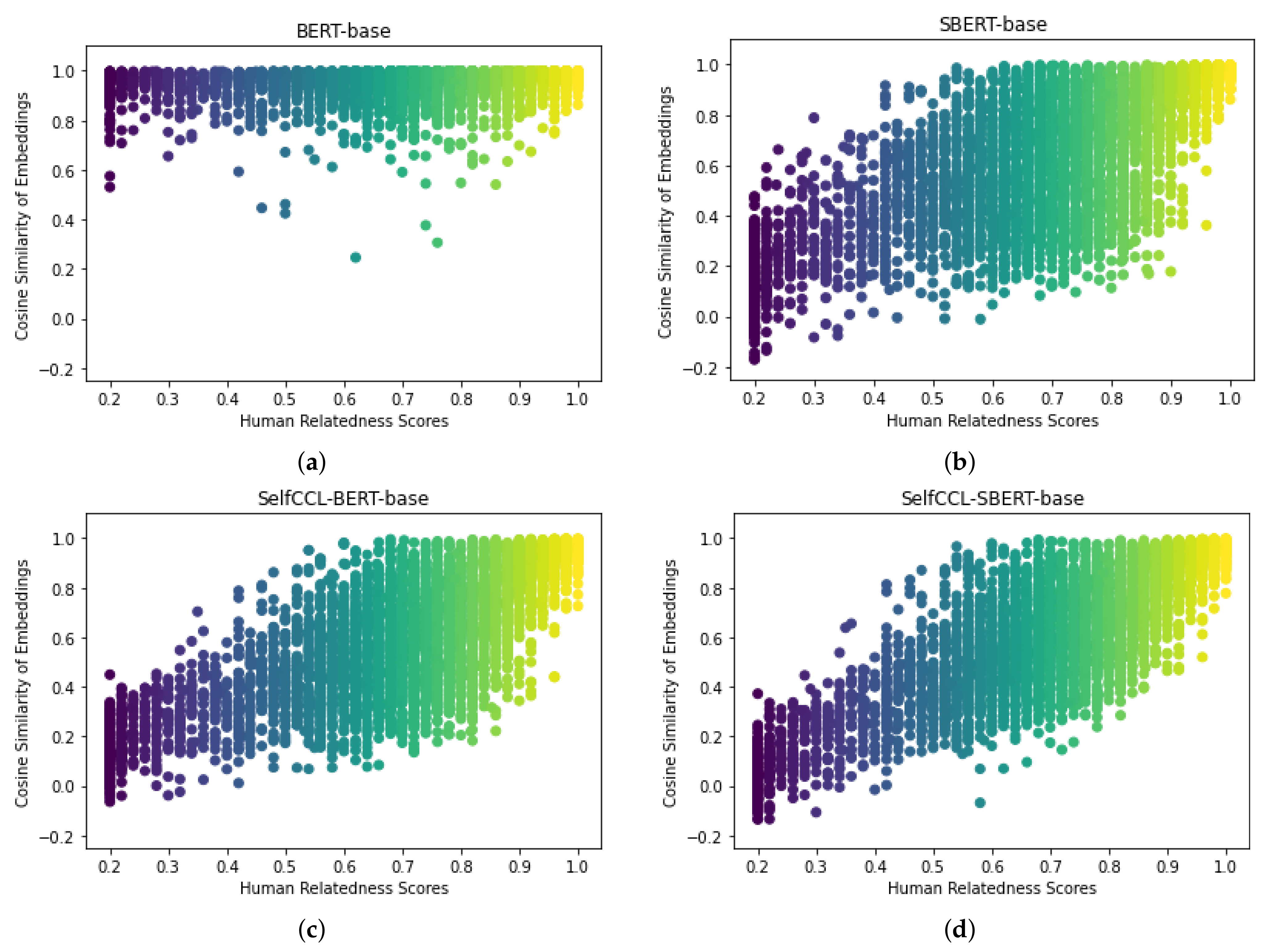
5.6. Third Experiment: Cosine Similarity Distribution
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| Bi-LSTM | Bidirectional Long-Short Term Memory |
| CL | Curriculum Learning |
| ELMo | Embeddings from Language Model |
| MNRL | Multiple Negatives Ranking Loss |
| NLI | Natural Language Inference |
| NLP | Natural Language Processing |
| NT-Xent | Normalized Temperature-scale Cross-Entropy |
| SBERT | Sentence BERT |
| SOTA | State-Of-The-Art |
| STS | Semantic Textual Similarity |
| USE | Universal Sentence Encoder |
References
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3–5 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Sina, J.S.; Sadagopan, K.R. BERT-A: Fine-Tuning BERT with Adapters and Data Augmentation. 2019. Available online: https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/reports/default/15848417.pdf (accessed on 30 November 2022).
- Flender, S. What Exactly Happens When We Fine-Tune BERT? 2022. Available online: https://towardsdatascience.com/what-exactly-happens-when-we-fine-tune-bert-f5dc32885d76 (accessed on 30 November 2022).
- Yan, Y.; Li, R.; Wang, S.; Zhang, F.; Wu, W.; Xu, W. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Volume 1. [Google Scholar] [CrossRef]
- Li, B.; Zhou, H.; He, J.; Wang, M.; Yang, Y.; Li, L. On the Sentence Embeddings from Pre-trained Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Online, 16–20 November 2020; pp. 9119–9130. [Google Scholar] [CrossRef]
- Zhang, Y.; He, R.; Liu, Z.; Lim, K.H.; Bing, L. An unsupervised sentence embedding method by mutual information maximization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1601–1610. [Google Scholar] [CrossRef]
- Wu, Z.; Sinong, S.; Gu, J.; Khabsa, M.; Sun, F.; Ma, H. CLEAR: Contrastive Learning for Sentence Representation. arXiv 2020, arXiv:2012.15466. [Google Scholar] [CrossRef]
- Kim, T.; Yoo, K.M.; Lee, S. Self-Guided Contrastive Learning for BERT Sentence Representations. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Volume 1. [Google Scholar] [CrossRef]
- Giorgi, J.; Nitski, O.; Wang, B.; Bader, G. DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Volume 1. [Google Scholar] [CrossRef]
- Liu, F.; Vulić, I.; Korhonen, A.; Collier, N. Fast, Effective, and Self-Supervised: Transforming Masked Language Models into Universal Lexical and Sentence Encoders. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar] [CrossRef]
- Carlsson, F.; Gyllensten, A.C.; Gogoulou, E.; Hellqvist, E.Y.; Sahlgren, M. Semantic Re-Tuning with Contrastive Tension. International Conference on Learning Representations (ICLR). 2021. Available online: https://openreview.net/pdf?id=Ov_sMNau-PF (accessed on 30 November 2022).
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar] [CrossRef]
- Chuang, Y.-S.; Dangovski, R.; Luo, H.; Zhang, Y.; Chang, S.; Soljačić, M.; Li, S.-W.; Yih, W.-T.; Kim, Y.; Glass, J. Diffcse: Difference-based contrastive learning for sentence embeddings. arXiv 2022, arXiv:2204.10298. [Google Scholar] [CrossRef]
- Klein, T.; Nabi, M. miCSE: Mutual Information Contrastive Learning for Low-shot Sentence Embeddings. arXiv 2022, arXiv:2211.04928. [Google Scholar] [CrossRef]
- Dehghan, S.; Amasyali, M.F. SupMPN: Supervised Multiple Positives and Negatives Contrastive Learning Model for Semantic Textual Similarity. Appl. Sci. 2022, 12, 9659. [Google Scholar] [CrossRef]
- Kamath, U.; Liu, J.; Whitaker, J. Transfer Learning: Scenarios, Self-Taught Learning, and Multitask Learning. In Deep Learning for NLP and Speech Recognition; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with sub word information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Porner, N.M. Combining Contextualized and Non-Contextualized Embeddings for Domain Adaptation and Beyond. Available online: https://edoc.ub.uni-muenchen.de/27663/1/Poerner_Nina_Mareike.pdf (accessed on 30 November 2022).
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning (ICML 2014), Beijing, China, 21–26 June 2014; pp. 1188–1198. [Google Scholar] [CrossRef]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.; Zemel, R.; Torralba, A.; Urtasun, R.; Fidler, S. Skip-thought vectors. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 3294–3302. [Google Scholar] [CrossRef]
- Hill, F.; Cho, K.; Korhonen, A. Learning Distributed Representations of Sentences from Unlabelled Data. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1367–1377. [Google Scholar] [CrossRef]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 528–540. [Google Scholar] [CrossRef]
- Logeswaran, L.; Lee, H. An efficient framework for learning sentence representations. arXiv 2018, arXiv:1803.02893. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar] [CrossRef]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised learning of universal sentence representations from natural language inference data. arXiv 2017, arXiv:1705.02364. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 169–174. [Google Scholar] [CrossRef]
- Prottasha, N.J.; Sami, A.A.; Kowsher, M.; Murad, S.A.; Bairagi, A.K.; Masud, M.; Baz, M. Transfer Learning for Sentiment Analysis Using BERT Based Supervised Fine-Tuning. Sensors 2022, 22, 4157. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.G.; Kim, M.; Kim, J.H.; Kim, K. Fine-Tuning BERT Models to Classify Misinformation on Garlic and COVID-19 on Twitter. Int. J. Environ. Res. Public Health 2022, 19, 5126. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, A.; Tripathi, S.; Vardhan, M.; Sihag, V.; Choudhary, G.; Dragoni, N. BERT-Based Transfer-Learning Approach for Nested Named-Entity Recognition Using Joint Labeling. Appl. Sci. 2022, 12, 976. [Google Scholar] [CrossRef]
- Fernández-Martínez, F.; Luna-Jiménez, C.; Kleinlein, R.; Griol, D.; Callejas, Z.; Montero, J.M. Fine-Tuning BERT Models for Intent Recognition Using a Frequency Cut-Off Strategy for Domain-Specific Vocabulary Extension. Appl. Sci. 2022, 12, 1610. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar] [CrossRef]
- Williams, A.; Nangia, N.; Bowman, S. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1. [Google Scholar] [CrossRef] [Green Version]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006. [Google Scholar] [CrossRef]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. arXiv 2015, arXiv:1503.03832. [Google Scholar]
- Xuan, H.; Stylianou, A.; Liu, X.; Pless, R. Hard negative examples are hard, but useful. In ECCV 2020: Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Sikaroudi, M.; Ghojogh, B.; Safarpoor, A.; Karray, F.; Crowley, M.; Tizhoosh, H.R. Offline versus Online Triplet Mining based on Extreme Distances of Histopathology Patches. arXiv 2020, arXiv:2007.02200. [Google Scholar]
- Gao, L.; Zhang, Y.; Han, J.; Callan, J. Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup. arXiv 2021, arXiv:2101.06983. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar] [CrossRef]
- Sohn, K. Improved Deep Metric Learning with Multi-class N-pair Loss Objective. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Available online: https://proceedings.neurips.cc/paper/2016/file/6b180037abbebea991d8b1232f8a8ca9-Paper.pdf (accessed on 30 November 2022).
- Elman, J.L. Learning and development in neural networks: The importance of starting small. Cognition 1993, 48, 71–99. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J.O.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar] [CrossRef]
- Soviany, P.; Ionescu, R.T.; Rota, P. Curriculum Learning: A Survey. Int. J. Comput. Vis. 2022, 130, 1526–1565. [Google Scholar] [CrossRef]
- Wang, X.; Chen, Y.; Zhu, W. A Survey on Curriculum Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4555–4576. [Google Scholar] [CrossRef]
- Wu, X.; Dyer, E.; Neyshabur, B. When do curricula work? arXiv 2021, arXiv:2012.03107. [Google Scholar] [CrossRef]
- Hacohen, G.; Weinshall, D. On The Power of Curriculum Learning in Training Deep Networks. arXiv 2019, arXiv:1904.03626. [Google Scholar] [CrossRef]
- Yegin, M.N.; Kurttekin, O.; Bahsi, S.K.; Amasyali, M.F. Training with growing sets: A comparative study. Expert Syst. 2022, 39, e12961. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Gholizade, M.; Soltanizadeh, H.; Rahmanimanesh, M. A Survey of Transfer Learning and Categories. Model. Simul. Electr. Electron. Eng. J. 2021, 1, 17–25. [Google Scholar] [CrossRef]
- Raina, R.; Battle, A.; Lee, H.; Packer, B.; Ng, A.Y. Self-taught learning: Transfer learning from unlabeled data. In Proceedings of the 24th Annual International Conference on Machine Learning held in conjunction with the 2007 International Conference on Inductive Logic Programming, Corvalis, OR, USA, 20–24 June 2007; pp. 759–766. [Google Scholar] [CrossRef]
- Henderson, M.; Al-Rfou, R.; Strope, B.; Sung, Y.; Lukacs, L.; Guo, R.; Kumar, S.; Miklos, B.; Kurzweil, R. Efficient Natural Language Response Suggestion for Smart Reply. arXiv 2017, arXiv:1705.00652. [Google Scholar] [CrossRef]
- Su, J.; Cao, J.; Liu, W.; Ou, Y. Whitening sentence representations for better semantics and faster retrieval. arXiv 2021, arXiv:2103.15316. [Google Scholar] [CrossRef]
- Wang, K.; Reimers, N.; Gurevych, I. TSDAE: Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP, Punta Cana, Dominican Republic, 16–20 November 2021. [Google Scholar] [CrossRef]
- Muennighoff, N. SGPT: GPT Sentence Embeddings for Semantic Search. arXiv 2022, arXiv:2202.08904. [Google Scholar] [CrossRef]
- Agirre, E.; Cer, D.; Diab, M.; Gonzalez-Agirre, A. SemEval-2012 task 6: A pilot on semantic textual similarity. In *SEM 2012: The First Joint Conference on Lexical and Computational Semantics—Volume 1: Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012); Association for Computational Linguistics: Atlanta, GA, USA, 2012; pp. 385–393. Available online: https://aclanthology.org/S12-1051 (accessed on 30 November 2022).
- Agirre, E.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W. *SEM 2013 shared task: Semantic textual similarity. In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 32–43. Available online: https://aclanthology.org/S13-1004 (accessed on 30 November 2022).
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W.; Mihalcea, R.; Rigau, G.; Wiebe, J. SemEval-2014 task 10: Multilingual semantic textual similarity. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 81–91. Available online: https://aclanthology.org/S14-2010 (accessed on 30 November 2022).
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W.; Lopez-Gazpio, I.; Maritxalar, M.; Mihalcea, R.; et al. SemEval-2015 task 2: Semantic textual similarity, English, Spanish and pilot on interpretability. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 252–263. [Google Scholar] [CrossRef]
- Agirre, E.; Banea, C.; Cer, D.; Diab, M.; Gonzalez Agirre, A.; Mihalcea, R.; Rigau Claramunt, G.; Wiebe, J. SemEval-2016 task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016) Association for Computational Linguistics, San Diego, CA, USA, 16–17 June 2016; pp. 497–511. [Google Scholar] [CrossRef]
- Cer, D.; Diab, M.; Agirre, E.; LopezGazpio, I.; Specia, L. SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 1–14. [Google Scholar] [CrossRef]
- Marelli, M.; Menini, S.; Baroni, M.; Entivogli, L.; Bernardi, R.; Zamparelli, R. A SICK cure for the evaluation of compositional distributional semantic models. In Proceedings of the International Conference on Language Resources and Evaluation (LREC), Reykjavik, Iceland, 26–31 May 2014; pp. 216–223. Available online: https://aclanthology.org/L14-1314/ (accessed on 30 November 2022).
- Conneau, A.; Kiela, D. SentEval: An evaluation toolkit for universal sentence representations. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), Miyazaki, Japan, 7–12 May 2018; Available online: https://aclanthology.org/L18-1269 (accessed on 30 November 2022).
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and Summarizing Customer Reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. Available online: https://www.cs.uic.edu/~liub/publications/kdd04-revSummary.pdf (accessed on 30 November 2022).
- Pang, B.; Lee, L. A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. In Proceedings of the 42nd Meeting of the Association for Computational Linguistics (ACL’04), Main Volume, Barcelona, Spain, 21–26 July 2004; pp. 271–278. Available online: https://aclanthology.org/P04-1035 (accessed on 30 November 2022).
- Wiebe, J.; Wilson, T.; Cardie, C. Annotating Expressions of Opinions and Emotions in Language. Lang. Resour. Eval. 2005, 39, 165–210. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. Available online: https://aclanthology.org/D13-1170/ (accessed on 30 November 2022).
- Li, X.; Roth, D. Learning Question Classifiers. In Proceedings of the 19th International Conference on Computational Linguistics—Volume 1, COLING, Taipei, Taiwan, 26–30 August 2002; pp. 1–7. Available online: https://aclanthology.org/C02-1150/ (accessed on 30 November 2022).
- Dolan, B.; Quirk, C.; Brockett, C. Unsupervised Construction of Large Paraphrase Corpora: Exploiting Massively Parallel News Sources. In Proceedings of the 20th International Conference on Computational Linguistics, COLING 2004, Geneva, Switzerland, 23–27 August 2004; Available online: https://aclanthology.org/C04-1051 (accessed on 30 November 2022).

| Category | Source Data Labeled? | Target Data Labeled? | Source and Target Task | Source and Target Domains |
|---|---|---|---|---|
| Inductive | Can be labeled and unlabeled | Yes | Different but related | Same |
| Transductive | Yes | No | Same | Different but related |
| Unsupervised | No | No | Different but related | Different but related |
| Premise | Entailment | Contradiction | Score |
|---|---|---|---|
| A man with a beard, wearing a red shirt with gray sleeves and work gloves, pulling on a rope. | A bearded man pulls a rope. | A man pulls his beard. | easy |
| A bearded man is pulling on a rope. | The man was clean shaven. | easy | |
| A man is pulling on a rope. | A man in a swimsuit, swings on a rope. | semi-hard | |
| The man is able to grow a beard. | A man is wearing a black shirt. | semi-hard | |
| A man pulls on a rope. | A bearded man is pulling a car with his teeth. | hard |
| Model | STS12 | STS13 | STS14 | STS15 | STS16 | STS-B | SICK-R | Avg. |
|---|---|---|---|---|---|---|---|---|
| Unsupervised models | ||||||||
| Glove embeddings (avg.) † | 55.14 | 70.66 | 59.73 | 68.25 | 63.66 | 58.02 | 53.76 | 61.32 |
| fastText embeddings ‡ | 58.85 | 58.83 | 63.42 | 69.05 | 68.24 | 68.26 | 72.98 | 59.76 |
| BERTbase (first-last avg.) | 39.70 | 59.38 | 49.67 | 66.03 | 66.19 | 53.87 | 62.06 | 56.70 |
| BERTbase-flow-NLI | 58.40 | 67.10 | 60.85 | 75.16 | 71.22 | 68.66 | 64.47 | 66.55 |
| BERTbase-whitening-NLI | 57.83 | 66.90 | 60.90 | 75.08 | 71.31 | 68.24 | 63.73 | 66.28 |
| IS-BERTbase ♠ | 56.77 | 69.24 | 61.21 | 75.23 | 70.16 | 69.21 | 64.25 | 66.58 |
| CT-BERTbase | 61.63 | 76.80 | 68.47 | 77.50 | 76.48 | 74.31 | 69.19 | 72.05 |
| SG-BERTbase ♢ | 66.84 | 80.13 | 71.23 | 81.56 | 77.17 | 77.23 | 68.16 | 74.62 |
| Mirror-BERTbase ♣ | 69.10 | 81.10 | 73.00 | 81.90 | 75.70 | 78.00 | 69.10 | 75.40 |
| SimCSEunsup-BERTbase | 68.40 | 82.41 | 80.91 | 78.56 | 78.56 | 76.85 | 72.23 | 76.25 |
| TSDAE-BERTbase ★ | 55.02 | 67.40 | 62.40 | 74.30 | 73.00 | 66.00 | 62.30 | 65.80 |
| ConSERT-BERTbase ♦ | 70.53 | 79.96 | 74.85 | 81.45 | 76.72 | 78.82 | 77.53 | 77.12 |
| ConSERT-BERTlarge ♦ | 73.26 | 82.37 | 77.73 | 83.84 | 78.75 | 81.54 | 78.64 | 79.44 |
| DiffCSE-BERTbase ■ | 72.28 | 84.43 | 76.47 | 83.90 | 80.54 | 80.59 | 71.23 | 78.49 |
| miCSE–BERTbase □ | 71.77 | 83.09 | 75.46 | 83.13 | 80.22 | 79.70 | 73.62 | 78.13 |
| RoBERTabase (first-last avg.) | 40.88 | 58.74 | 49.07 | 65.63 | 61.48 | 58.55 | 61.63 | 56.57 |
| CLEAR-RoBERTabase ♡ | 49.00 | 48.90 | 57.40 | 63.60 | 65.60 | 72.50 | 75.60 | 61.08 |
| DeCLUTR-RoBERTabase ‡ | 52.41 | 75.19 | 65.52 | 77.12 | 78.63 | 72.41 | 68.62 | 69.99 |
| Supervised models | ||||||||
| InferSent-GloVe † | 52.86 | 66.75 | 62.15 | 72.77 | 66.87 | 68.03 | 65.65 | 65.01 |
| Universal Sentence Encoder † | 64.49 | 67.80 | 64.61 | 76.83 | 73.18 | 74.92 | 76.69 | 71.22 |
| SBERTbase † | 70.97 | 76.53 | 73.19 | 79.09 | 74.30 | 77.03 | 72.91 | 74.89 |
| SBERTbase-flow | 69.78 | 77.27 | 74.35 | 82.01 | 77.46 | 79.12 | 76.21 | 76.60 |
| SBERTbase-whitening | 69.65 | 77.57 | 74.66 | 82.27 | 78.39 | 79.52 | 76.91 | 77.00 |
| CT-SBERTbase | 74.84 | 83.20 | 78.07 | 83.84 | 77.93 | 81.46 | 76.42 | 79.39 |
| SBERTbase-nli-v2 | 75.33 | 84.52 | 79.54 | 85.72 | 80.82 | 84.48 | 80.77 | 81.60 |
| SelfCCL-SBERTbase | 75.50 | 84.81 | 80.05 | 85.53 | 81.07 | 84.77 | 80.67 | 81.77 |
| SG-BERTbase ♢ | 75.16 | 81.27 | 76.31 | 84.71 | 80.33 | 81.46 | 76.64 | 79.41 |
| SimCSEsup-BERTbase | 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.25 | 80.39 | 81.57 |
| SupMPN-BERTbase * | 75.96 | 84.96 | 80.61 | 85.63 | 81.69 | 84.90 | 80.72 | 82.07 |
| SelfCCL-BERTbase | 75.61 | 84.72 | 80.04 | 85.44 | 81.37 | 84.63 | 80.82 | 81.80 |
| Model | MR | CR | SUBJ | MPQA | SST-2 | TREC | MRPC | Avg. |
|---|---|---|---|---|---|---|---|---|
| Unsupervised models | ||||||||
| Glove embeddings (avg.) † | 77.25 | 78.30 | 91.17 | 87.85 | 80.18 | 83.00 | 72.87 | 81.52 |
| Skip-thought ♠ | 76.50 | 80.10 | 93.60 | 87.10 | 82.00 | 92.20 | 73.00 | 83.50 |
| Avg. BERT embedding † | 78.66 | 86.25 | 94.37 | 88.66 | 84.40 | 92.80 | 69.54 | 84.94 |
| BERT-[CLS] embedding † | 78.68 | 84.85 | 94.21 | 88.23 | 84.13 | 91.40 | 71.13 | 84.66 |
| IS-BERTbase ♠ | 81.09 | 87.18 | 94.96 | 88.75 | 85.96 | 88.64 | 74.24 | 85.83 |
| CT-BERTbase ∞ | 79.84 | 84.00 | 94.10 | 88.06 | 82.43 | 89.20 | 73.80 | 84.49 |
| SimCSEunsup-BERTbase | 81.18 | 86.46 | 94.45 | 88.88 | 85.50 | 89.80 | 74.43 | 85.51 |
| SimCSEunsup-BERTbase-MLM | 82.92 | 87.23 | 95.71 | 88.73 | 86.81 | 87.01 | 78.07 | 86.64 |
| DiffCSE-BERTbase ■ | 82.69 | 78.23 | 95.23 | 89.28 | 86.60 | 90.40 | 76.58 | 86.86 |
| Supervised models | ||||||||
| InferSent-GloVe † | 81.57 | 86.54 | 92.50 | 90.38 | 84.18 | 88.20 | 75.77 | 85.59 |
| Universal Sentence Encoder † | 80.09 | 85.19 | 93.98 | 86.70 | 86.38 | 93.20 | 70.14 | 85.10 |
| SBERTbase † | 83.64 | 89.43 | 94.39 | 89.86 | 88.96 | 89.60 | 76.00 | 87.41 |
| SBERTbase-nli-v2 | 83.09 | 89.33 | 94.98 | 90.15 | 87.92 | 87.00 | 75.25 | 86.82 |
| SelfCCL-SBERTbase | 83.02 | 89.46 | 95.05 | 90.18 | 87.97 | 87.00 | 75.94 | 86.95 |
| SG-BERTbase ♢ | 82.47 | 87.42 | 95.40 | 88.92 | 86.20 | 91.60 | 74.21 | 86.60 |
| SimCSEsup-BERTbase | 82.69 | 89.25 | 84.81 | 89.59 | 87.31 | 88.40 | 73.51 | 86.51 |
| SupMPN-BERTbase * | 82.93 | 89.26 | 94.76 | 90.21 | 86.99 | 88.20 | 76.35 | 86.96 |
| SelfCCL-BERTbase | 82.89 | 89.22 | 94.78 | 90.51 | 87.15 | 87.60 | 76.17 | 86.90 |
| Sentence 1 | Sentence 2 | Relation | Human Relatedness Scores |
|---|---|---|---|
| A girl is brushing her hair. | There is no girl brushing her hair. | Contradiction | 4.5 |
| A chubby faced boy is not wearing sunglasses. | A chubby faced boy is wearing sunglasses. | Contradiction | 3.9 |
| The dog is on a leash and is walking in the water. | The dog is on a leash and is walking out of the water. | Contradiction | 3.5 |
| A black sheep is standing near three white dogs. | A black sheep is standing far from three white dogs. | Contradiction | 3.5 |
| A man dressed in black and white is holding up the tennis racket and is waiting for the ball. | A man dressed in black and white is dropping the tennis racket and is waiting for the ball. | Contradiction | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dehghan, S.; Amasyali, M.F. SelfCCL: Curriculum Contrastive Learning by Transferring Self-Taught Knowledge for Fine-Tuning BERT. Appl. Sci. 2023, 13, 1913. https://doi.org/10.3390/app13031913
Dehghan S, Amasyali MF. SelfCCL: Curriculum Contrastive Learning by Transferring Self-Taught Knowledge for Fine-Tuning BERT. Applied Sciences. 2023; 13(3):1913. https://doi.org/10.3390/app13031913
Chicago/Turabian StyleDehghan, Somaiyeh, and Mehmet Fatih Amasyali. 2023. "SelfCCL: Curriculum Contrastive Learning by Transferring Self-Taught Knowledge for Fine-Tuning BERT" Applied Sciences 13, no. 3: 1913. https://doi.org/10.3390/app13031913