1. Introduction
Soccer is one of the most iconic sports games, with a huge number of fans around the world; thus, many soccer-simulation video games are being created. Among the most representative soccer-simulation games are the FIFA series, Football PES, and Football Manager. These digital games continuously release new series to strengthen their market share, and contain the latest technology and new information on soccer players and national leagues. However, these games are restricted to PC or console platforms due to the complexity of their gameplay and the wide range of user controls [
1]. In addition, the gameplay requires vast knowledge and information about the real soccer game which prevents casual game users from easily accessing soccer-simulation games [
2]. AI though mobile platforms provide new opportunities to grow their audience and increase revenue with light gameplay anywhere and at any time, the abovementioned soccer simulation games have difficulties entering the mobile game market due to their volume and weights, in addition to their complex gameplay and high-level user control [
3].
In terms of the machine-learning and artificial intelligence (AI) agent techniques in the field of digital games, team sport simulation games have historically been testbeds for evaluating new algorithms and have recently propelled AI progress [
4]. Beginning with real-time strategy (RTS) games including StarCraft in 2010 [
5,
6], and progressing to multiplayer online battle arena (MOBA) games [
7], and to RoboCup [
8,
9], game AI systems are emphasized to enhance enjoyment and entertainment in a simulated team sports environment. In particular, successful soccer-simulation games were researched because they present a great variety of scenarios according to their game-winning strategies and consist of a competitive environment between two agents in which each of them controls a soccer team composed of 11 players [
10]. Thus, it is very important to acquire stable and veritable results in the context of machine learning of AI agent−players when designing soccer simulators [
11]. However, recent research focuses on the competition between AI agent−players in RoboCup Soccer Simulation [
12,
13]; there has been little research into the application of AI game systems for sports games. In terms of the computer-game rendition of sports, it seems that mainstream PC soccer simulation AAA games including EA’s FIFA aim to make the game closer to the actual game [
14]. However, the purpose of playing the game is to create a particular experience for the players and the game AI and its application should support that experience. Thus, the goal of an AI system and its development depends on a particular game genre, rules, player profile, and even platforms [
15]. In this regard, this paper took into consideration a greatly increasing number of casual players who enjoy the light gameplay of soccer-simulation games on their mobile phones. This paper developed a hyper-casual futsal game as a simplified version of soccer and verified whether it is possible for machine-learned AI agent−players to run on mobile platforms, and in particular for the smooth running of gameplay on mobile devices.
The proposed hyper-casual futsal game was designed with a five vs. five structure consisting of three positions: one goalkeeper, two strikers, and two defenders. In addition, in order to closely verify the player-position learning and interactive AI techniques for visual analytics, an AI agent−player was used to machine-learn how to play well in each position. For this, the paper made a comparison between the proximal policy-optimization (PPO) algorithm and the Soft Actor-Critic (SAC) algorithm using cumulative-reward and entropy graphs. This paper will help to prove the possibility of the application of machine-learned AI agent−players to be run on mobile devices, first, in order to attract more users in the digital soccer game market and, second, to make it possible to play soccer games on mobile platforms.
The rest of this paper is organized as follows;
Section 2 provides a discussion of related studies including soccer-simulation games, soccer-team-management games, hyper-casual games, the PPO and SAC algorithms, and the Unity ML;
Section 3 outlines the design and implementation of the proposed hyper-casual futsal mobile game;
Section 4 provides the results of AI agent machine learning by comparing the PPO and SAC algorithms; and the concluding remarks and future directions are discussed in
Section 5.
2. Related Studies
2.1. Digital Game AI
Traditional game AI includes Finite State Machines (FSM), rule-based systems (RBS), and search and pathfinding techniques. These techniques are still widely used today, but advanced machine-learning techniques are being employed with the aim of providing an entertaining and satisfying gaming experience for the human player [
16]. In the past, video games required AI techniques to create simple obstacles and to simulate the role of the player’s competitor, but various strategies and algorithms have been developed to generate responsive, adaptive, or intelligent behaviors, primarily in non-player characters (NPCs), similar to human-like intelligence. Implementing an artificially intelligent agent such as a robot or a character in video games is becoming more complex as they require complex behaviors to carry out their tasks in dynamic environments.
Many researchers have studied algorithms that attempt to approximate optimal play in computer games including Chess, Checkers, Go, car-racing games, RTS, and Super Mario Bros [
16]. Some interesting advances in algorithmic AI have been made, such as the use of the MiniMax Search Tree and Alpha-Beta pruning in Gomoku; there has also been progress seen in game AI, such as the Monte Carlo Tree Search in the game of Settlers of Catan [
17].
2.2. Soccer-Simulation-Game AI
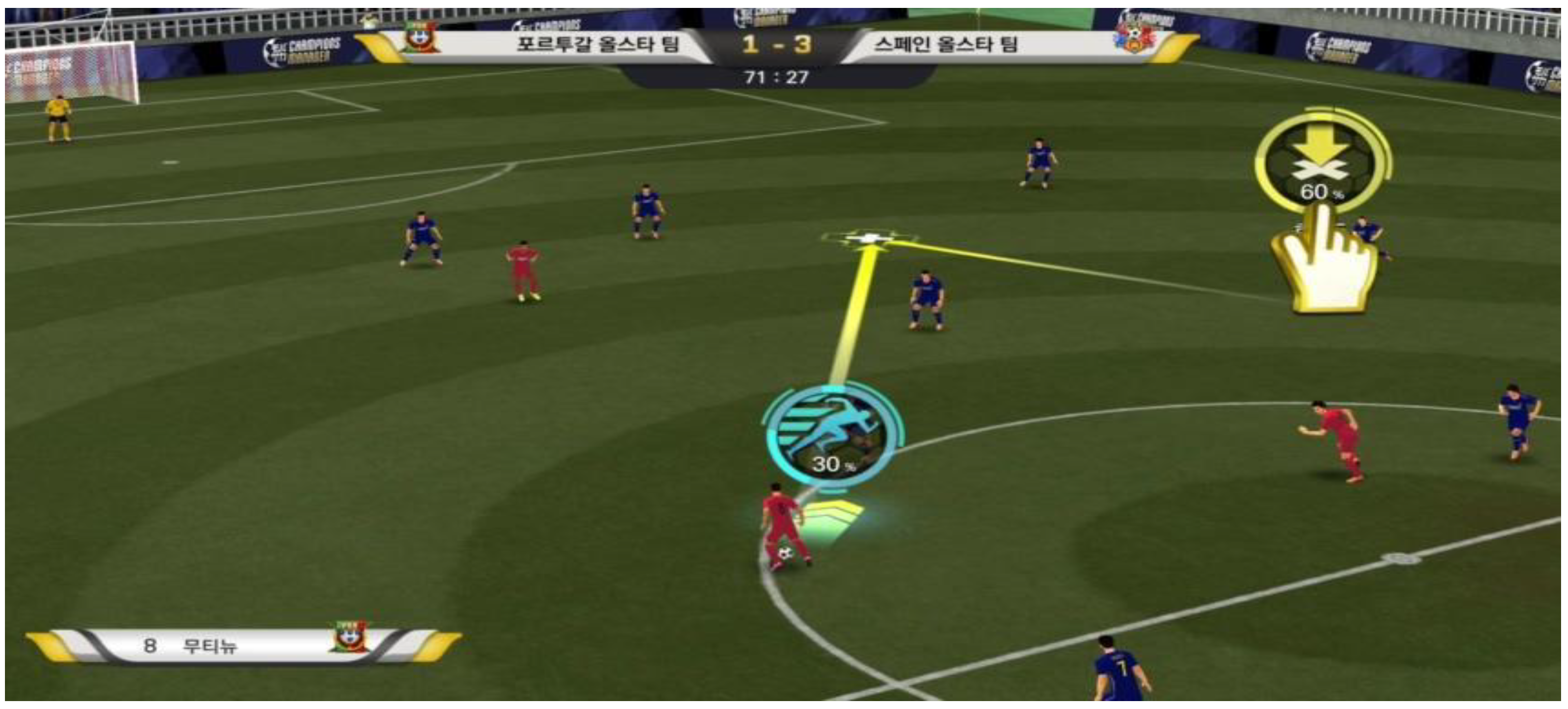
A soccer-simulation game refers to a game genre in which the user directly controls virtual soccer players during gameplay. The user performs the same set of actions as real soccer players such as passing, dribbling, and shooting the ball by manipulating virtual avatar players. The interest of the game is in directing virtual players, which is not too different from real soccer, as shown in
Figure 1. However, it is a very difficult task for a number of player agents to implement and control a different type of behaviors in real time under various conditions. This is the reason that the most popular real-time soccer simulation games in the world have led the PC game market with EA’s FIFA Series, KONAMI’s Winning Eleven, and SEGA’s Football Manager Series, based on their huge capital and long-standing development experience.
The use of AI in soccer-simulation games began with an in-game direction-finding A-Star search algorithm, but recently, it has been advanced to handle action decisions during animation generation or gameplay so that it can analyze soccer players’ behavior data to make it realistic.
Table 1 describes the algorithms that are used for popular soccer-simulation games.
The A-Star Search algorithm is a graph-traversal and pathfinding algorithm. Applied in the FIFA game, the A-Star Search algorithm helps to identify more effective passing opportunities by analyzing the proximity and ambient space of opponents [
18]. To create a more realistic gameplay, FIFA 22 uses HyperMotion technology in which ML-Flow learns the data set of player’s movements and analyzes how many steps they take to touch the ball, the rhythm of movement to touch or pass the ball, how the angle of the kick of the ball changes, and creates animation in real time [
19]. In Football Manager, HFSM is used as a control system that describes players’ behaviors using three points of state, event, and action. The system may move or transition to another state if it receives feedback from specific events. Thus, it is of advantage for a soccer-simulation game that involves a relatively complex set of processes within actions [
20].
2.3. Hyper-Casual Games
A casual game refers to a game genre or trend that can be enjoyed for a short time through simple gameplay or basic control. Casual games are enjoyed by a wide range of age groups, and even users who are not interested in online games. In particular, the casual mobile game market has been developed globally due to the spread of low-end phones, making it one of the reasons for the rapid spread of mobile devices. Casual games have 10 characteristics, as listed in
Table 2 [
21].
A hyper-casual game is an upgraded version of a casual game that provides a game experience that can be enjoyed for a short period of time and is based on simple controls such as stacking, turning, and falling. It adds dynamic stages to the challenges where users can compete. This genre has been growing explosively since its first appearance at the end of 2017. Hyper-casual games are enjoyed by both male and female players, and a variety of user age groups from 20s to 40s [
22]. It was born as a genre that was easy and simple to play and was highly immersive and based on skill; but as time progressed, the games gradually competed with social-media-feed scrolling, and the play tended to become easier. However, in 2021, some hyper-casual games were expected to reach a turning point in the hyper-casual game genre and return to the beginning of the genre by demanding higher techniques and skills from users [
23]. These new trends follow the demand for casualized versions of soccer-simulation games that require mid-core and tactical gameplay.
3. Method
3.1. AI Agent Machine Learning
Artificial intelligence (AI) is a computer system that simulates human intelligence processes by machines, including human learning, reasoning, perceptual ability, and understanding of natural language. Of these, machie learning is a field of AI that implements the intellectual abilities of thinking and learning through computers [
24]. It requires a foundation in specialized writing, and training algorithms in feature extraction and generalization can be said to be the key. Feature extraction is used to determine which features might be useful in training a model and generalization is used to make correct predictions on new, previously unseen data.
Machine-learning algorithms can be divided into categories according to their purpose, including supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. This paper uses reinforcement machine learning for AI agent training. Reinforcement learning allows soft agents to constantly interact with the specific environment and learn information while automatically determining the ideal behavior to find the optimal policy [
25].
Reinforcement learning consists of two parts: agent and environment. The agent observes the environment, selects an action according to the policy, and executes the action. It then receives feedback on the following states and modifies the policy to an environment that maximizes rewards. The learning repeats this process and aims to finally discover the optimal policy.
3.2. PPO and SAC Algorithms
The PPO algorithm is one of the Policy Gradient (PG) techniques introduced by the OpenAI team in 2017 [
26]. The agent alternately performs sampling data through interaction with the environment and optimizing the Surrogate Objective Function using Stochastic Gradient Ascent [
27]. Unlike the conventional method of updating data every time they are sampled, the PPO algorithm uses a new objective function that enables multiple epochs of mini-batch updates. In particular, in autonomous driving, the PPO algorithm shows good performance compared to other AI reinforcement-learning algorithms [
28].
The PPO-Clip pseudocode of the PPO algorithm is shown in Algorithm 1. The algorithm declares the initial parameters θ_0 and initial value function parameters [
29]. The policy of the pseudocode collects trajectories with π_κ = π(θ_κ), calculates the advantage with the rewards-to-go and value function, and updates the policy by maximizing the PPO-Clip.
The PPO algorithm learns a value function using stochastic gradient ascent such as Adam and regression through mean-squared error. It also computes an expression, usually using the gradient descent algorithm and ending with the last iteration [
30].
| Algorithm 1 PPO-Clip |
1: Input: initial policy parameters initial value function parameters
2: For k = 0, 1, 2, … do
3: Collect set of trajectories by running policy in the environment
4: Computer rewards-to-go
5: Compute advantage estimates, (using any method of advantage estimation) based on the current value function
6: Update the policy by maximizing the PPO-Clip objective: d/d. Typically via stochastic gradient ascent with Adam.
7: Fit value function by regression on mean-squared error: Typically via some gradient descent algorithm.
8: End for |
Similar to the PPO algorithm, the Soft Actor−Critic (SAC) algorithm is a policy-based algorithm of policy optimization that solves the exploration problem of reinforcement learning to some extent, inherits the actor−critic structure, and establishes the actor’s skill improvement using KL-Divergence instead of Policy Gradient [
31]. The characteristics of the SAC algorithm are: stable learning; easy-to-obtain efficient samples, suitable for continuous action space and high-dimensional space problems; and use as a baseline for model pre-off policy [
32,
33].
Algorithm 2 shows the reset of the parameters at the start of the SAC algorithm, resetting the target network weight of the initialized parameters as shown in the following equation, and also resetting the pooling to be repeated. In addition, it expresses the policy for the default behavior as a whole, performs the default conversion in the environment, and saves the conversion of the iteration pooling. The following iteration updates the Q function’s parameters and policy weights, adjusts each attribute value, updates the target network weight, and finishes the iteration. Finally, the resulting value becomes the parameter.
| Algorithm 2: Soft Actor−Critic |
| Input: | |
| | ▷ Initial parameters |
| | ▷ Initialize target network weights |
| for each iteration do | ▷ Initialize an empty replay pool |
| for each environment step do | |
| | ▷ Sample action from the policy |
| | ▷ Sample transition from the environment |
| | ▷ Store the transition in the replay pool |
| end for | |
| for each gradient step do | |
| | ▷ Update the Q-function parameters |
| | ▷ Update policy weights |
| | ▷ Adjust temperature |
| | ▷ Update tareget network weights |
| end for | |
| end for | ▷ Optimized parameters |
| Output: | |
This paper used the above PPO and SAC algorithms because digital football-simulation games include organic content that can produce various results according to the rules. To learn the rules of this content, learning algorithms that were compatible with the rules and policies were needed. This paper selected PPO and SAC as representative algorithms based on policy optimization. In addition, the reason for comparing the two algorithms is that they are policy-based algorithms, but there is a difference in learning methods between the two algorithms in that PPO is a general policy-optimization method while SAC is a greedy policy-based method, so significant results will possibly be derived.
3.3. Unity ML
Unity ML is a machine-learning Software Development Kit (SDK) that can run on top of the Unity game engine and acts as an intermediary between TensorFlow, a machine learning library, and a Unity Agent. Unity ML delivers the results learned by machine learning. The structure is shown in
Figure 2 and the communication between the learning environment and the Python API is performed through the Academy’s External Communicator [
25]. The learning results value received from the Python API is transmitted to the Agent through the Academy and becomes the set performance value [
34].
4. Experiment and Analysis
4.1. Design of a Hyper-Casual Futsal Mobile Game
As compared to the general rule of soccer gameplay that it must be played with two teams and each team consisting of 11 players, a hyper-casual futsal game was designed as shown in
Figure 3 as a five vs. five game with only three positions, one goalkeeper, two strikers, and two defenders, for its casual gameplay. Each of the five AI agent−player in the blue and purple teams was created as a square box in either blue or purple. The five agents can move left, right, forwards, and backwards. The agent’s basic behavior control is based on the futsal game position in which the behaviors of attack, pass, and intercept are performed according to signals that are sent from the algorithm.
To develop an automatic play system, gameplay learning must be performed with an appropriate reinforcement-learning algorithm. However, algorithms suitable for hyper-casual soccer games are not currently identified with experimental data. Thus, in this paper, the PPO and SAC algorithms were selected from reinforcement-learning algorithms, with the aim of meeting the criteria needed when choosing algorithms suitable for hyper-football games.
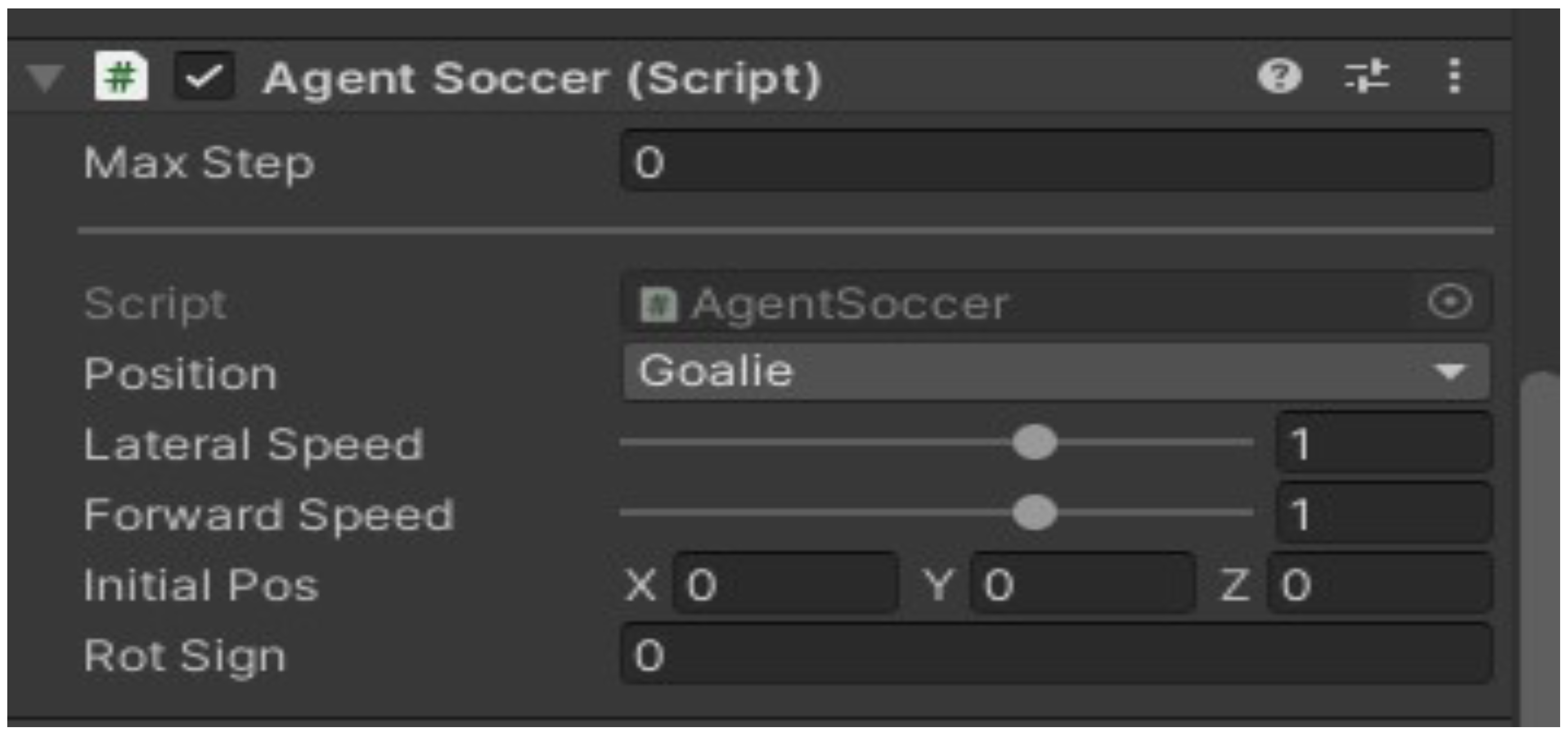
Each AI agent-player’s setting values in the game engine are shown in
Figure 4Figure 5 and
Figure 6. They depict the AI agent−player’s attribute values in the game according to the positions of goalkeeper (or goalie), striker, and defender. For each position, machine learning was performed after adjusting the scales on player abilities including field movement radius, movement speed according to a specific field range, and ball-tracking speed. To be specific, the goalie shown in
Figure 6 has lateral speed of 1; forward speed of 1 and its Rot Sign indicates the team rotation values to mark the agent’s team. Through the simulation test, the AI agent−player moves in the direction dictated by the signals received from the algorithm. As shown in
Figure 7, the guidelines describe the agent’s pathfinding and ball-searching lines.
The UML diagram of the futsal casual game expressing the overall class structure of the hyper-casual futsal game is described in
Figure 8. To be specific, the PlayerState class is a basic framework responsible for handling the AI agent−player’s movements and collision, and the AgentSoccer class controls the actions required for futsal games based on the data acquired from the PlayerState class. The SoccerBallControl class controls the beginning and end of the overall futsal gameplay. It is also responsible for initializing the ball position to start the game, processing the reward value according to the score, and calculating the playtime. The SoccerFieldArea class is responsible for measuring the position of the agent and giving rewards according to the ball position.
The role of communicating Unity ML’s learning results was performed by the AgentSoccer class, with the flow diagram shown in
Figure 9. OnEpisodeBegin notified the start of learning and called the initialization, while MoveAgent moved an object with the numerical value determined by Unity ML. Then, OnActionReceived delivered the rewards of each position to Unity ML according to the game situation.
4.2. Experiment Environment
In this paper, the experimental environment was constructed as shown in
Table 3. Unity ML-Agents officially released a version of Release 1 after the Beta version, and it has been continuously updated since then. The structure has changed from the Beta version in which Academy and Brain were deleted and the agent was changed to be managed integrally. According to these changes, the experiment was conducted with the Brain file deleted and nn file added, a model file that derived the results learned by machine learning.
4.3. Learning Method Setting
This paper executed four different types of learning methods including Vector Observation, Visual Observation, Simple Heuristic, and Greedy Heuristic as shown in
Table 4. The observation learning method is a method of observing and learning agents who act randomly. It is divided into Vector Observation learning, which observes a vector basis, and Visual Observation learning, which observes a visual element such as color. Next, the heuristic learning method is an imitation learning method that allows agents to move in code that reflects human intuition to some extent without randomly acting the agent; this is termed Simple Heuristic. The method in which human doctors are applied more accurately and in detail to reduce meaningless behavior as much as possible is called the Greedy Heuristic method.
4.4. Comparative Data Setting
In this paper, the AI agent−player for three positions is machine-learned in the simplified futsal game using each algorithm and learning method. Each learning result was derived through Tensorboard. Two key graphs are the cumulative-reward-value graph and the entropy graph. In the cumulative-reward-value graph, the higher the value of this cumulative-reward-value, the higher the agent’s learning performance. The entropy graph is a graph that represents entropy values per number of lessons. The lower the entropy value, the more stable the learning result.
5. Results
This paper conducted visual analytics on whether the AI agent−player for three positions is machine-learned in order to verify its stability and comparability for game elements on mobile platforms. For this proposed futsal game, the Unity ML agent was applied and the PPO and SAC algorithms were used and compared for machine learning. For its performance analysis, learning was carried out 50,000 times for one set, and a total of ten sets of learning was created to draw two resulting graphs of cumulative-reward value and entropy using Tensorboard.
As shown in
Table 5, the learning ability performance for each position was analyzed for both PPO and SAC algorithms. The resulting positive values in both reward-value graphs illustrated that AI agent−players can be successfully machine learned in a mobile platform, even though a negative value was reached at the beginning of the SAC algorithm. In addition, entropy value decreased as learning increased, indicating stable learning.
A histogram of the average cumulative value of the rewards was created while performing reinforcement learning using the algorithms. In the graph, the vertical axis indicates the learning number, while the horizontal axis indicates the reward value. A negative reward is provided for staying-in-place conditions where the agents were set to move actively and then tested. However, when negative rewards were given to two positions other than the striker when the player had the ball, most AI agent−players chose to stay in place. To address this issue, a negative reward was included for ‘staying-in-place’ conditions and retested.
As the learning number increased, the value of the cumulative rewards was between 0.05 and 0.95 using the PPO algorithm, as shown in
Figure 10 while the value using the SAC algorithm was between −0.9 and 1.0, so it became negative. Therefore, the reward value using the PPO algorithm generated positive numbers compared to the SAC algorithm in
Figure 11.
The entropy referred to here is a numerical indicator of impurity, also called the probability variable [
32]. Since it is an index that represents the uncertainty of this probability variable as a numerical value [
34], the closer it get to 0, the lower the uncertainty; that is, the more stable it is. Compared to initial learning, as time increases, both graphs decrease towards 0. However, the SAC algorithm went closer to 0 than the PPO algorithm. Thus, it proves that machine learning using the SAC algorithm attained a more stable state than that achieved using thee PPO algorithm, as shown in
Figure 12 and
Figure 13.
In order to verify whether it is possible to run a soccer simulator on mobile devices, this paper designed a casual version of a futsal demo game and implemented it through the PPO and SAC algorithms and the Unity ML agent for AI agent−player’ machine learning. As the learning was conducted, its performance analysis proved that the three agents for each position reached stable learning.
In addition, the comparative result showed that the PPO algorithm seems to have obtained higher rewards when comparing graphs from the same number of lessons under the same conditions. However, this paper proposed that the SAC algorithm is more compatible for AI agent−player learning in a futsal-simulation digital game. As team sports have a genre-specific uncertainty that situations can be variable according to team strategy and opponent team, stability is considered more important than gameplay or learning [
17]. Thus, this paper set the criterion as an entropy graph, and entropy using the SAC algorithm came closer to 0 than with the PPO algorithm, so that the uncertainty was lowered and the machine learning gained more stability. As a result, the entropy using the SAC algorithm was closer to zero, so it can be said that learning accuracy is higher using the SAC algorithm than using the PPO algorithm.
6. Discussion
In digital games, high-quality AI evokes intense curiosity and the desire to be continuously challenged in game users; it can provide the fun of an immersive experience by realistically simulating various situations. In particular, team-sport-simulation games require a number of agents to implement and control various behaviors in real time under various conditions. With the game industry recently adapting around the mobile environment, it needs to present appropriate AI models that can be executed in low mobile device environments as well as resolving hardware-optimization issues compared to PC hardware. In this regard, this paper designed and machine learnt an AI agent−player in a simplified version of a futsal game in a mobile environment.
First, the results in this paper confirm that the AI agent played in a similar way to an actual soccer player, and the team’s final results were derived in a similarly way to actual soccer game results. Also, the AI agent can be machine learnt even in a mobile environment through both PPO and SAC algorithms.
Second, the results also illustrate that algorithms can be applicable in different genres of games, varying according to game rules, mechanics, and type of experience. Through the simulation test, the SAC algorithm is more appropriate than the PPO algorithm for AI agent−player learning in the soccer-simulation-game genre. In fact, AI agent−players achieve better learning using the PPO algorithm in terms of a high reward values, but learning stability is more valued than learning accuracy in the genre of team sports games so the SAC algorithm can be recommended.
Third, team-sports digital games remain an important testbed for AI learning because of their unexpected variables and different levels of tactical and strategical thinking. These features make team sports an interesting challenge for AI machine learning. The results in this paper show the great potential of the application of machine-learned AI agent−players both for soccer simulators and using mobile platforms.
7. Conclusions
Mobile games attract more users and higher revenues due to their simple rules and easy user-control gameplays. With the continuous improvement in the computing power of mobile devices and the rapid development of 5G communication technologies, mobile games have gained more popularity. However, due to the inherent constraints of small screen sizes and restrictions of computing, it has been seen as challenging to simulate the complex gameplay of soccer games. In particular, with the development of machine-learning technology, soccer-simulation-game genres have entered the artificial intelligence arena and have begun to be develop using reinforcement learning. In this regard, this paper designed a simplified version of a five vs. five hyper-casual futsal game and tested it to verify whether it is possible to implement an AI agent−player for each position both to machine learn and to run on a mobile device. A demo game with an AI agent−player was simulated, and the results clearly illustrated that each AI agent−player achieved the assigned objectives for each position and successfully machine learned. In addition, when the PPO and SAC algorithms were compared, the SAC algorithm showed a more stable state than the PPO algorithm when SAC directed the gameplay and interactive AI techniques, even though both satisfied the stability for AI machine learning. This also meant that the proposed hyper-casual futsal game for mobile devices gained stability and comparability for game elements.
Given these promising results, the study could extend to include different soccer-game strategies to verify the differences and superiority of each strategy. In addition, further studies could be conducted with a performance comparison among different types of machine-reinforcement learning to increase the diversity and accuracy of the data. To be specific, this paper simplified the soccer gameplay structure into three positions including the goalkeeper, striker, and defender, but in future studies the number of positions would be increased to six to verify whether machine learning would obtain similarly stable values. The extended soccer game and its machine learning would use different algorithms including POCA and the results would be compared and analyzed with the results of the proposed SAC algorithm.
Author Contributions
Conceptualization and methodology, H.A.; software and validation, H.A.; formal analysis, H.A.; data curation and writing—original draft preparation, H.A.; writing—review and editing, J.K.; visualization, H.A.; supervision, J.K.; funding acquisition, J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Ministry of Culture, Sports and Tourism and the Korea Creative Content Agency (Project Number: R2020040243) and Basic Science Research Program through the National Research Foundation of Korea (NRF) by the Ministry of Education (NRF-2022R1F1A1066602).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
This research was supported by Ministry of Culture, Sports and Tourism and the Korea Creative Content Agency (Project Number: R2020040243) and Basic Science Research Program through the National Research Foundation of Korea (NRF) by the Ministry of Education (NRF-2022R1F1A1066602).
Conflicts of Interest
The authors declare no conflict of interest.
References
- No, H.S.; Rhee, D.W. A study on the game character creation using genetic algorithm in football simulation games. J. Korea Game Soc. 2017, 17, 129–138. [Google Scholar] [CrossRef]
- Haslam, J. Out Now! Adjust’s Hype Casual Gaming Report 2020 Is Here. Available online: https://www.adjust.com/blog/hyper-casual-gaming-report-2020-announcement/ (accessed on 22 December 2022).
- Jun, Y.J. No More Simulations, FIFA Mobile, Which Really Pursues Soccer Game. Available online: https://www.donga.com/news/It/article/all/20200610/101449454/1 (accessed on 22 December 2022).
- Mozgovoy, M.; Preuss, M.; Bidarra, R. Team Sports for Game AI Benchmarking Revisited. Int. J. Comput. Game Technol. 2021, 2021, 1–9. [Google Scholar] [CrossRef]
- Ontanon, S.; Synnaeve, G.; Uriatre, A.; Richoux, F.; Churchill, D.; Preuss, M. A survey of real-time strategy game AI research and competition in StarCraft. IEEE Trans. Comput. Intell. AI Games 2013, 5, 293–311. [Google Scholar] [CrossRef]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. StartCraft II: A New Challenge for Reinforcement Learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Juliani, A.; Khalifa, A.; Berges, V.; Harper, J.; Teng, E.; Henry, H.; Crespi, A.; Togelius, J.; Lange, D. Obstacle Tower: A Generalization Challenge in Vision, Control, and Planning. arXiv 2019, arXiv:1902.01378. [Google Scholar]
- Kitano, H.; Asada, M.; Kuniyoshi, Y.; Noda, I.; Osawa, E.; Matsubara, H. RoboCup: A Challenge Problem for AI and robotics. In Proceedings of the Robo Soccer World Cup, Nagoya, Japan, 23–29 August 1997. [Google Scholar]
- Prokopenko, M.; Wang, P.; Marian, S.; Bai, A.; Li, X.; Chen, X. RoboCup 2D Soccer Simulation League: Evaluation Challenges. In Proceedings of the Robot World Cup XXI, Nagoya, Japan, 27–31 July 2017. [Google Scholar]
- Matheus, F.; Rita, J.; Lidia, T. Investing Learning Models and Environment Representation in Construction of Player Agents: Application on FIFA game. In Proceedings of the SBGames 2021, Gramado, Brazil, 18–21 October 2021. [Google Scholar]
- Southey, F.; Xiao, G.; Holte, R.C.; Trommelen, M.; Buchanan, J. Semi-Automated Gameplay Analysis by Machine Learning. In Proceedings of the First Artificial Intelligence and Interactive Digital Entertainment Conference(AIIDE-2005), Marina Del Rey, CA, USA, 1–2 June 2005. [Google Scholar]
- Shi, H.; Lin, Z.; Hwang, K.; Yang, S.; Chen, J. An Adaptive Strategy Selection Method with Reinforcement Learning for Robotic Soccer Games. IEEE Access 2018, 6, 8376–8386. [Google Scholar] [CrossRef]
- Hong, C.; Lee, G.M.; Choi, W.; Kim, J.H. Field Friction Recognition and State Inference in AI Soccer. Robot. Intell. Technol. Appl. 2002, 6, 413–421. [Google Scholar] [CrossRef]
- Sicart, M. A Tale of Two Games: Football and FIFA 12. In Sports Videogames; Consalvo, M., Mitgutsch, K., Stein, A., Eds.; Routledge: New York, NY, USA, 2013; pp. 40–57. [Google Scholar]
- Swiechowski, M. Game AI competitions: Motivation for the imitation game-playing competition. In Proceedings of the 2020 15th Conference on Computer Science and Information Systems (FedCSIS), Sofia, Bulgaria, 6–9 September 2020. [Google Scholar]
- Park, H.S.; Kim, K.J. Recent Research Trends in Game Artificial Intelligence. Commun. Korean Inst. Inf. Sci. Eng. 2013, 31, 8–15. [Google Scholar]
- Perez-Liebana, D.; Samothrakis, S.; Togelius, J.; Lucas, S.M.; Schaul, T. General Video Game AI: Competition, Challenges, and Opportunities. In Proceedings of the Thirthieth AAAI Conference on Artificial Intelligence(AAAI-16), Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Ranjitha, M.; Nathan, K.; Joseph, L. Artificial Intelligence Algorithms and Techniques in the computation of Player-Adaptive Games. J. Phys. Conf. Ser. 2020, 1427, 1–11. [Google Scholar] [CrossRef]
- Good, S.O. FIFA 22’s HyperMotion Is “the Beginning of Machine Learning Taking Over Animation”. Available online: http://www.slideshare.net/SuHyunCho2/sac-overview (accessed on 27 January 2023).
- Baek, K. Design and Implementation of Artificial Intelligence Agent for Real-Time Simulation Football Game in a Mobile Environment. In Proceedings of the Korea Information Processing Society Conference, Seoul, Republic of Korea, 25 April 2016. [Google Scholar]
- Baek, Y.S.; Park, S.H.; Kim, D.W. The effect of the characteristics of mobile casual games on immersion, user satisfaction, and loyalty. Korea Soc. Manag. Inf. Syst. 2015, 16, 256–262. [Google Scholar]
- TOAST eXchange. Analysis of User Propensity by Game. Available online: http://www.slideshare.net/NHNTX/ss-66592098 (accessed on 1 February 2023).
- Steinbach, R. Four Hybercausal Game Trends in 2021. Available online: https://supersonic.com/ko/learn/blog/the-4-biggest-hyper-casual-game-trends-of-2021/ (accessed on 7 January 2023).
- Schulma, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimove, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Shim, W.I.; Park, T.W.; Kim, K.J. Comparison of Policy Optimization Reinforcement Learning for Simulated Autonomous Car Environment. In Proceedings of the Korea Computer Congress 2018, Jeju, Republic of Korea, 20–22 June 2018. [Google Scholar]
- Zade, B.M.H.; Mansouri, N. PPO: A new nature-inspired metaheuristic algorithm based on predation for optimization. Soft Comput. 2021, 26, 1331–1402. [Google Scholar] [CrossRef]
- Juliani, A. Introducing: Unity Machine Learning Agents Toolkit, Unity Blog. Available online: https://blogs.unity3d.com/2017/09/19/introducing-unity-machine-learning-agents/ (accessed on 22 December 2022).
- Song, C. Summary of the Latest Reinforcement Learning Algorithms. Available online: https://brunch.co.kr/@chris-song/102 (accessed on 22 December 2022).
- Cho, S.H. Introduction to SAC. Available online: http://www.slideshare.net/SuHyunCho2/sac-overview (accessed on 7 January 2023).
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspective, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2018, arXiv:1701.07274. [Google Scholar]
- Lee, G.; Yun, W.J.; Jung, S.; Kim, J.; Kim, J. Visualization of Deep Reinforcement Autonomous Aerial Mobility Learning Simulations. In Proceedings of the IEEE Conference on Computer Communications Workshops, Vancouver, BC, Canada, 10–13 May 2021. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft Actor-Critic Algorithms and Applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Park, D.G.; Lee, W.B. Design and Implementation of Reinforcement Learning Agent Using PPO Algorithm for Match 3 Gameplay. J. Converg. Inf. Technol. 2021, 11, 1–6. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}