
On the Interplay between Machine Learning, Population Pharmacokinetics, and Bioequivalence to Introduce Average Slope as a New Measure for Absorption Rate


Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Outline of the Strategy
2.2. Bioequivalence Dataset
2.3. Estimation of the Pharmacokinetic Parameters
2.4. Simulated Datasets
2.5. Machine Learning Approaches
2.5.1. Principal Component Analysis
2.5.2. Random Forest
3. Results
3.1. Actual Data
3.1.1. Relationships among the Pharmacokinetic Parameters
3.1.2. Parameters Contributing to Tmax
3.2. Simulated Datasets
3.2.1. Relationships among the PK Parameters
3.2.2. Parameters Contributing to Tmax
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A. Individual Datasets | |
|---|---|
| Type of absorption kinetics and sampling scheme | Median of Tmax (in hours) |
| Slow absorption | |
| Sparse | 7.00 |
| Typical | 6.50 |
| Dense | 6.00 |
| Typical absorption | |
| Sparse | 3.00 |
| Typical | 3.00 |
| Dense | 2.50 |
| Fast absorption | |
| Sparse | 1.75 |
| Typical | 1.75 |
| Dense | 1.75 |
| B. Merged datasets | |
| Type of sampling scheme | Quartiles of Tmax (in hours) (1st, 2nd, 3rd) |
| Sparse | 1.75, 2.50, 6.00 |
| Typical | 1.75, 2.75, 6.00 |
| Dense | 1.75, 2.67, 5.00 |
References
- Niazi, S. Handbook of Bioequivalence Testing (Drugs and the Pharmaceutical Sciences), 2nd ed.; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2014. [Google Scholar]
- Food and Drug Administration (FDA). Guidance for Industry. Bioavailability and Bioequivalence Studies Submitted in NDAs or INDs-General Considerations. Draft Guidance. U.S. Department of Health and Human Services Food and Drug Administration Center for Drug Evaluation and Research (CDER). December 2013. 2014. Available online: https://www.fda.gov/media/88254/download (accessed on 4 January 2023).
- European Medicines Agency. Committee for Medicinal Products for Human Use (CHMP). Guideline on the Investigation of Bioequivalence. CPMP/EWP/QWP/1401/98 Rev. 1/ Corr**. London. 20 January 2010. Available online: https://www.ema.europa.eu/en/documents/scientific-guideline/guideline-investigation-bioequivalence-rev1_en.pdf (accessed on 4 January 2023).
- Bois, F.; Tozer, T.; Hauck, W.; Chen, M.; Patnaik, R.; Williams, R. Bioequivalence: Performance of several measures of extent of absorption. Pharm. Res. 1994, 11, 715–722. [Google Scholar] [CrossRef] [PubMed]
- Reppas, C.; Lacey, L.F.; Keene, O.N.; Macheras, P.; Bye, A. Evaluation of different metrics as indirect measures of rate of drug absorption from extended-release dosage forms at steady-state. Pharm. Res. 1995, 2, 103–107. [Google Scholar] [CrossRef] [PubMed]
- Endrenyi, L.; Tothfalusi, L. Metrics for the evaluation of bioequivalence of modified-release formulations. AAPS J. 2012, 14, 813–819. [Google Scholar] [CrossRef] [PubMed]
- Jackson, A. Determination of in vivo bioequivalence. Pharm. Res. 2002, 19, 227–228. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Lesko, L.; Williams, R. Measures of exposure versus measures of rate and extent of absorption. Clin. Pharmacokinet. 2001, 40, 565–572. [Google Scholar] [CrossRef] [PubMed]
- Basson, R.; Cerimele, B.; DeSante, K.; Howey, D. Tmax: An unconfounded metric for rate of absorption in single dose bioequivalence studies. Pharm. Res. 1996, 13, 324–328. [Google Scholar] [CrossRef] [PubMed]
- Rostami-Hodjegan, A.; Jackson, P.; Tucker, G. Sensitivity of indirect metrics for assessing “rate” in bioequivalence studies: Moving the “goalposts” or changing the “game”. J. Pharm. Sci. 1994, 83, 1554–1557. [Google Scholar] [CrossRef] [PubMed]
- Schall, R.; Luus, H. Comparison of absorption rates in bioequivalence studies of immediate release drug formulations. Int. J. Clin. Pharmacol. Ther. Toxicol. 1992, 30, 153–159. [Google Scholar] [PubMed]
- Endrenyi, L.; Al-Shaikh, P. Sensitive and specific determination of the equivalence of absorption rates. Pharm. Res. 1995, 12, 1856–1864. [Google Scholar] [CrossRef] [PubMed]
- Chen, M. An alternative approach for assessment of rate of absorption in bioequivalence studies. Pharm. Res. 1992, 9, 1380–1385. [Google Scholar] [CrossRef] [PubMed]
- Tothfalusi, L.; Endrenyi, L. Without extrapolation, Cmax/AUC is an effective metric in investigations of bioequivalence. Pharm. Res. 1995, 12, 937–942. [Google Scholar] [CrossRef] [PubMed]
- Lacey, L.; Keene, O.; Duquesnoy, C.; Bye, A. Evaluation of different indirect measures of rate of drug absorption in comparative pharmacokinetic studies. J. Pharm. Sci. 1994, 83, 212–215. [Google Scholar] [CrossRef] [PubMed]
- Schall, R.; Luus, H.G.; Steinijans, V.W.; Hauschke, D. Choice of characteristics and their bioequivalence ranges for the comparison of absorption rates of immediate-release drug formulations. Int. J. Clin. Pharmacol. Ther. 1994, 32, 323–328. [Google Scholar] [PubMed]
- Endrenyi, L.; Csizmadia, F.; Tothfalusi, L.; Chen, M.L. Metrics comparing simulated early concentration profiles for the determination of bioequivalence. Pharm. Res. 1998, 15, 1292–1299. [Google Scholar] [CrossRef] [PubMed]
- Macheras, P.; Symmilides, M.; Reppas, C. An improved intercept method for the assession of absorption rate in bioequivalence studies. Pharm. Res. 1996, 13, 1755–1758. [Google Scholar] [CrossRef] [PubMed]
- Stier, E.; Davit, B.; Chandaroy, P.; Chen, M.; Fourie-Zirkelbach, J.; Jackson, A.; Kim, S.; Lionberger, R.; Mehta, M.; Uppoor, R.; et al. Use of partial area under the curve metrics to assess bioequivalence of methylphenidate multiphasic modified release formulations. AAPS J. 2012, 14, 925–926. [Google Scholar] [CrossRef] [PubMed]
- Karalis, V. Modeling and Simulation in Bioequivalence. In Modeling in Biopharmaceutics, Pharmacokinetics and Pharmacodynamics. Homogeneous and Heterogeneous Approaches, 2nd ed.; Macheras, P., Iliadis, A., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 227–255. [Google Scholar]
- James, G.; Hastie, T.; Tibshirani, R.; Witten, D. An Introduction to Statistical Learning with Applications in R, 7th ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Shamout, F.; Zhu, T.; Clifton, D.A. Machine Learning for Clinical Outcome Prediction. IEEE Rev. Biomed. Eng. 2021, 14, 116–126. [Google Scholar] [CrossRef] [PubMed]
- Karalis, V. Machine Learning in Bioequivalence: Towards Identifying an Appropriate Measure of Absorption Rate. Appl. Sci. 2023, 13, 418. [Google Scholar] [CrossRef]
- Basson, R.P.; Ghosh, A.; Cerimele, B.J.; DeSante, K.A.; Howey, D.C. Why rate of absorption inferences in single dose bioequivalence studies are often inappropriate. Pharm. Res. 1998, 15, 276–279. [Google Scholar] [CrossRef] [PubMed]







| Parameter | Description | Software |
|---|---|---|
| Cmax | Maximum observed plasma concentration | PKanalixTM (Monolix SuiteTM 2021R2) |
| AUCt | Area under the concentration-time curve from time zero to the time of the last measurable concentration | PKanalixTM (Monolix SuiteTM 2021R2) |
| AUCinf | Area under the Concentration-time curve extrapolated to infinity | PKanalixTM (Monolix SuiteTM 2021R2) |
| AUCp | Partial AUC from time zero up to the median Tmax of the reference product | PKanalixTM (Monolix SuiteTM 2021R2) |
| Tmax | Time at which Cmax is observed | PKanalixTM (Monolix SuiteTM 2021R2) |
| Cavg | Average concentration calculated as the ratio of AUCt over the time of last measurement | PKanalixTM (Monolix SuiteTM 2021R2) |
| Cmax/AUC | Ratio of Cmax to AUCt | Excel® Microsoft Office 365 |
| Cmax/Cavg | Ratio of Cmax to Cavg | Excel® Microsoft Office 365 |
| Lambda | Apparent terminal elimination rate constant, calculated by applying least squares regression analysis to the terminal log-linear phase of the C-t curve | PKanalixTM (Monolix SuiteTM 2021R2) |
| Cmax/Tmax | Ratio of Cmax to Tmax | MATLAB® R2022b (MathWorks) |
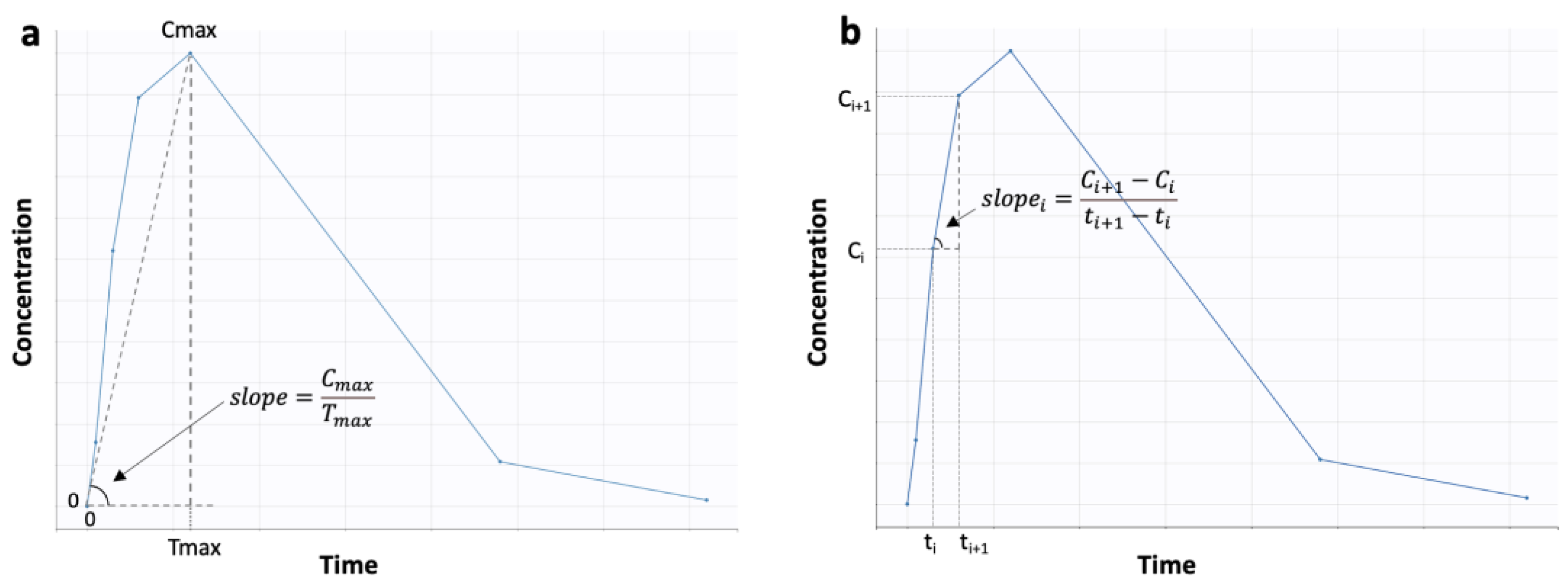
| AS | The “Average Slope” calculated as the average of (C,t) slopes between subsequent time points | MATLAB® R2022b (MathWorks) |
| Type | Sampling Schedule (in Hours) |
|---|---|
| Actual dataset | |
| Sampling according to the study protocol | 0, 0.5, 1, 2, 3, 4, 6, 8, 12, 24, 48, 96, 144, 192 |
| Simulated datasets | |
| Slow absorption (0.5×) | |
| Sparse | 0, 2, 5, 7, 8, 10, 16, 24, 48, 72 |
| Typical | 0, 1, 2, 4, 5, 6, 6.5, 7, 7.5, 8, 9, 10, 12, 16, 24, 36, 48, 72 |
| Dense | 0, 1, 2, 3, 4, 4.5, 5, 5.5, 6, 6.33, 6.67, 7, 7.33, 7.67, 8, 8.5, 9, 10, 12, 14, 16, 24, 36, 48, 72 |
| Typical absorption (1×) | |
| Sparse | 0, 1, 3, 6, 12, 48, 72 |
| Typical | 0, 0.5, 1, 2, 3, 4, 6, 8, 12, 24, 48, 72 |
| Dense | 0, 0.5, 1, 1.5, 2, 2.33, 2.67, 3, 3.33, 3.67, 4, 4.5, 5, 6, 9, 12, 16, 24, 36, 48, 72 |
| Fast absorption (2×) | |
| Sparse | 0, 0.67, 1.25, 1.75, 2.5, 5, 12, 24, 48, 72 |
| Typical | 0, 0.33, 0.67, 1, 1.25, 1.50, 1.75, 2, 2.5, 3, 5, 8, 12, 16, 24, 36, 48, 72 |
| Dense | 0, 0.33, 0.67, 1, 1.25, 1.50, 1.75, 2, 2.33, 2.67, 3, 3.5, 4, 5, 6, 9, 12, 16, 24, 36, 48, 72 |
| Step | Action | Purpose | Software |
|---|---|---|---|
| Actual dataset | |||
| 1 | Parameters estimation | Calculation of pharmacokinetic parameters (see Table 1) in order to apply, in a subsequent step, the machine learning techniques | - PKanalixTM (Monolix SuiteTM 2021R2) - MATLAB® R2022b (MathWorks) |
| 2 | PCA | Application of Principal Component Analysis (PCA) in order to identify relationships among the parameters | - Python v. 3.10.8 |
| 3 | RF | Application of Random Forest (RF) in order to explore the relative contribution of pharmacokinetic parameters to Tmax | - Python v. 3.10.8 |
| 4 | Pharmacokinetic simulations | Perform pharmacokinetic simulations in order to generate 2 × 2 crossover bioequivalence datasets for several absorption kinetics (slow, typical, fast) and sampling schemes (sparse, typical, dense) | - SimulxTM (Monolix SuiteTM 2021R2) |
| Simulated datasets (Steps 1–3 are repeated for each simulated dataset) | |||
| 5 | Parameters estimation | Calculation of pharmacokinetic parameters | - PKanalixTM (Monolix SuiteTM 2021R2) - MATLAB® R2022b (MathWorks) |
| 6 | PCA | Application of PCA in order to identify relationships among the parameters | - Python v. 3.10.8 |
| 7 | RF | Application of RF in order to explore the relative contribution of pharmacokinetic parameters to Tmax | - Python v. 3.10.8 |
| Step | Action | Order of Preference | Parameters with Non-Desired Characteristics |
|---|---|---|---|
| Actual dataset | |||
| 1 | PCA | AS or Cmax/Tmax > Cmax/AUCt > AUCp or Cavg | Cmax, Cmax/Cavg, lambda, AUCt, AUCinf |
| 2 | RF | AS or Cmax/Tmax > AUCp | AUCt, Cmax/AUC, Cmax, lambda |
| 3 | Overall | Best performance: AS or Cmax/Tmax and afterwards AUCp | |
| Simulated datasets | |||
| 4 | PCA | AS or Cmax/Tmax > Cmax/AUC | AUCt, AUCinf, Cmax, AUCp, lambda |
| 5 | RF | AS or Cmax/Tmax | AUCt, Cmax, AUCp, Cmax/AUC, lambda |
| 6 | Overall | Best performance: AS or Cmax/Tmax | |
| Overall findings from steps 1–3 and 4–6 | |||
| 7 | Overall from the entire analysis | Best performance: AS or Cmax/Tmax | All other parameters tested |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karalis, V.D. On the Interplay between Machine Learning, Population Pharmacokinetics, and Bioequivalence to Introduce Average Slope as a New Measure for Absorption Rate. Appl. Sci. 2023, 13, 2257. https://doi.org/10.3390/app13042257
Karalis VD. On the Interplay between Machine Learning, Population Pharmacokinetics, and Bioequivalence to Introduce Average Slope as a New Measure for Absorption Rate. Applied Sciences. 2023; 13(4):2257. https://doi.org/10.3390/app13042257
Chicago/Turabian StyleKaralis, Vangelis D. 2023. "On the Interplay between Machine Learning, Population Pharmacokinetics, and Bioequivalence to Introduce Average Slope as a New Measure for Absorption Rate" Applied Sciences 13, no. 4: 2257. https://doi.org/10.3390/app13042257