
Neural Machine Translation of Electrical Engineering Based on Vector Fusion

Abstract
:1. Introduction
2. Related Works
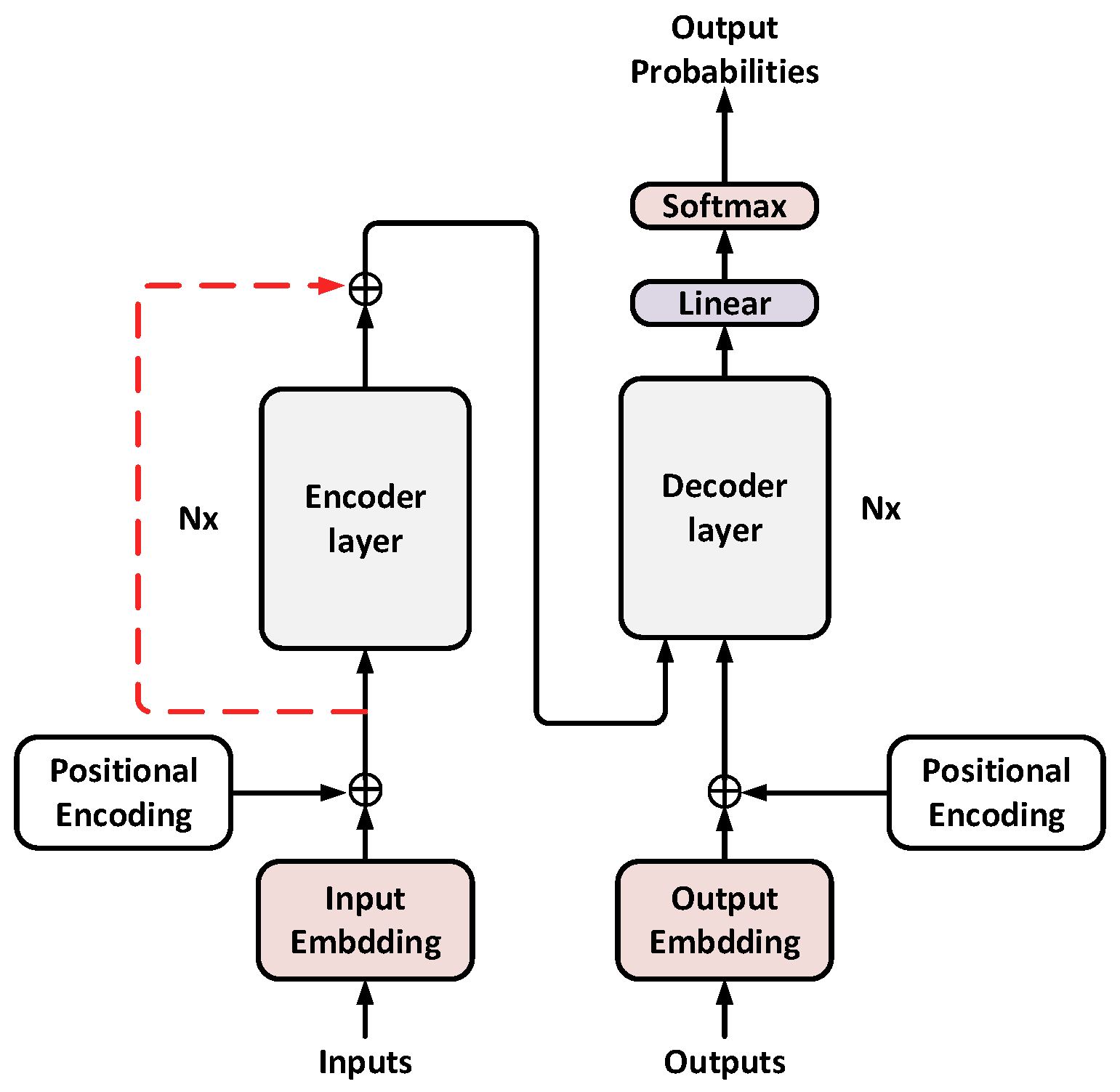
3. Neural Machine Translation Models for Vector Fusion
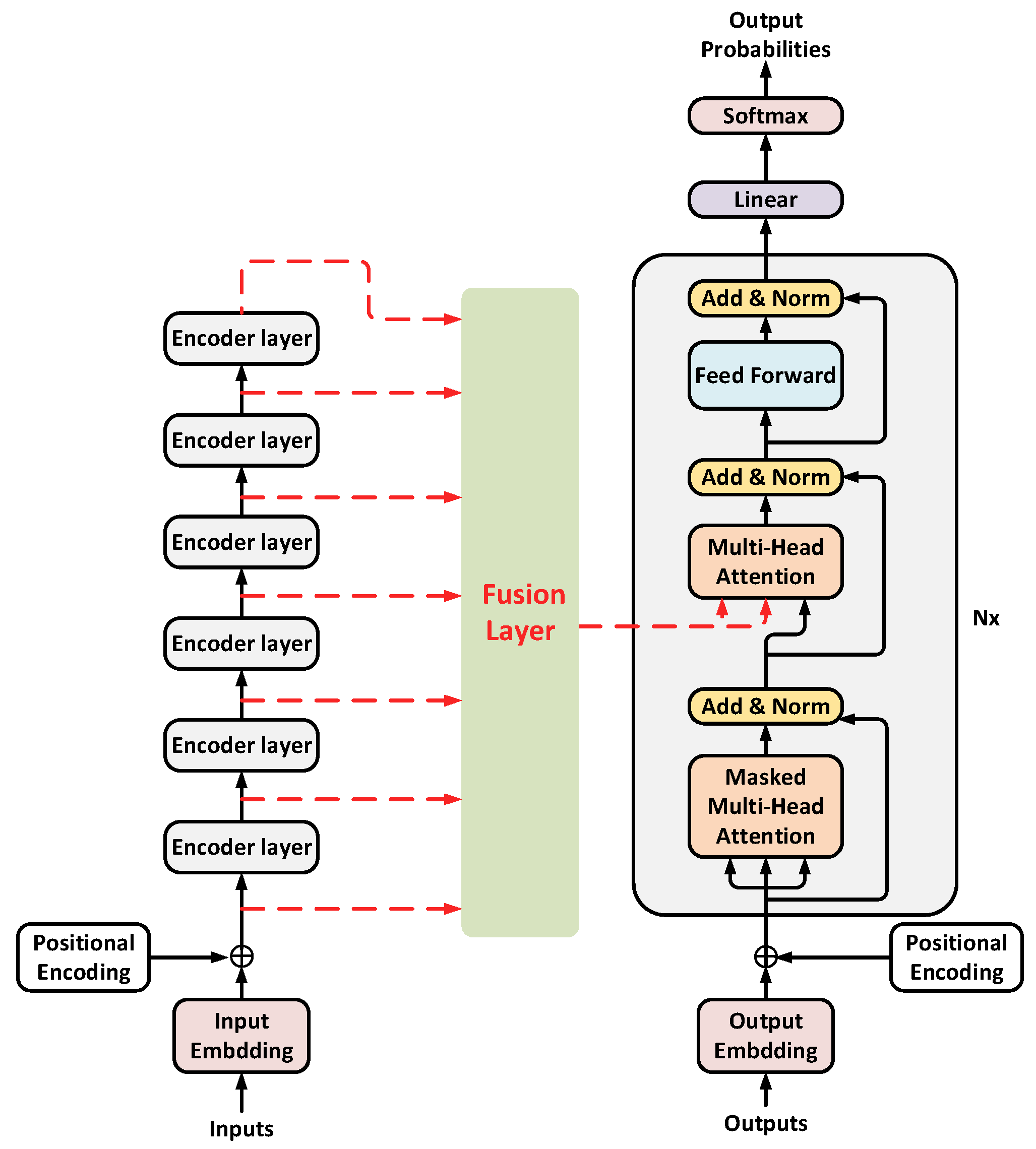
3.1. Encoder for Vector Fusion
3.1.1. Residual Connection Fusion
3.1.2. Average Fusion
3.1.3. Splicing Fusion
3.1.4. Weight Fusion
3.1.5. Gate Mechanism Fusion
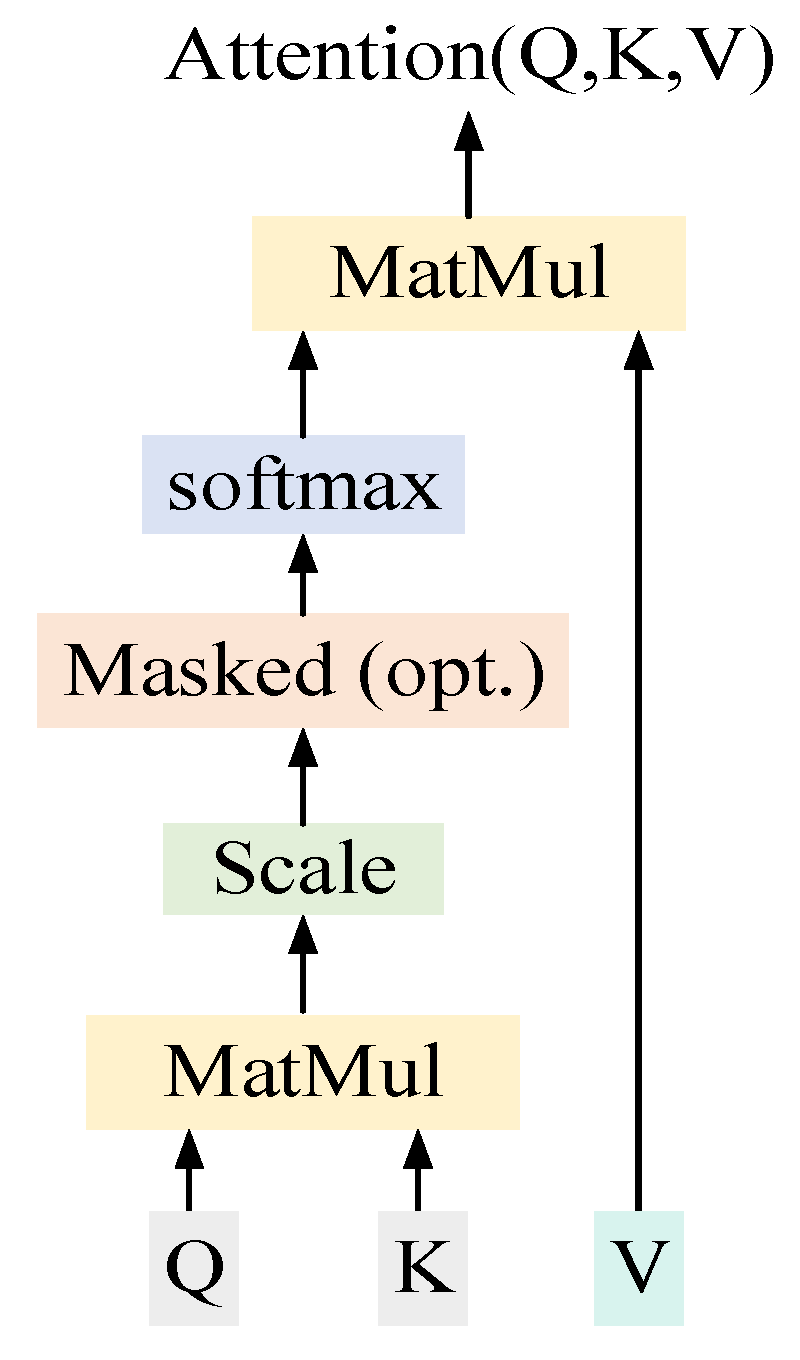
3.2. Multi-Attention Mechanism Translation Model Based on Vector Fusion
4. Experiments and Results
4.1. Dataset
4.2. Experimental Setup
4.3. Results
4.3.1. Results of Vector Fusion
4.3.2. Results of Model Improvement
5. Discussion
5.1. Vector Fusion Experiment
- The improved structure of the residual connection proposed in this paper and the four fusion experiments have improved the translation effect of the model, which verifies that the stacked structure of the network structure will indeed cause the underlying information to be lost in the process of model training, and the information contained in the hidden layer vector output by the multi-layer encoder unit is biased and different in terms of syntax and lexical meaning.
- As shown in Table 1, the BLEU (bilingual evaluation understudy) value of the translation model after the residual connection is increased by 0.23 percentage points, while the BLEU value of the average fusion translation model is increased by 0.15 percentage points, which is slightly lower than the effect of the residual connection. The reason is that although the average fusion method adds the output vector of the middle layer encoder unit, it also reduces the weight of the top encoder unit and the output vector of the word embedding layer, so their final BLEU value is slightly lower than the residual connection.
- It can be seen from the experimental results that the splicing fusion and the gate mechanism fusion have similar improvements in the translation effect of the model, but the BLEU value of the gate mechanism fusion is slightly higher because the calculation process of the two fusion methods is similar.
- Comparing the BLEU values of the four fusion methods, the average fusion is the lowest because the average fusion assigns the same fixed weight to each vector that needs to be fused. However, in fact, the information of each layer of encoder units contained in the fusion vector finally output by the encoder is definitely different. The fusion of the splicing and the gate mechanism is centered because both use the fully connected layer to convert the dimensions of the seven vectors to be fused inside and compress them into one vector, which is better than the average fusion effect. Weight fusion can achieve the best model translation performance improvement because this method performs random weight assignment directly outside the multiple vectors that need to be fused and makes it change with the subsequent model training process, which is simple and effective.
- It can be seen from the comparative data in Table 2 that although the N-1 system fusion method has also achieved some improvements in the translation effect, making the model learn more source language information from multiple angles for the model stack structure of Transformer, only the vector fusion of the output vectors at the top level of multiple encoders cannot make good use of the source language information at the bottom of the encoder. However, the vector fusion method proposed in this paper fuses the multiple hidden layer vectors and the underlying word embedding in the encoder, makes good use of the underlying word meaning information inside the encoder, solves the problem of underlying information loss caused by model stacking to a certain extent, obtains a more comprehensive source language feature vector at the encoder end, and achieves better translation effect, which fully proves the effectiveness of the vector fusion method proposed in this paper.
5.2. Model Improvement Experiment
- It can be seen from Table 3 that the translation effect of the translation model after the improvement of the decoder unit is 0.85 percentage points higher than the BLEU value of the baseline model, which proves that adding an additional attention mechanism in the decoder unit to further extract feature information is effective.
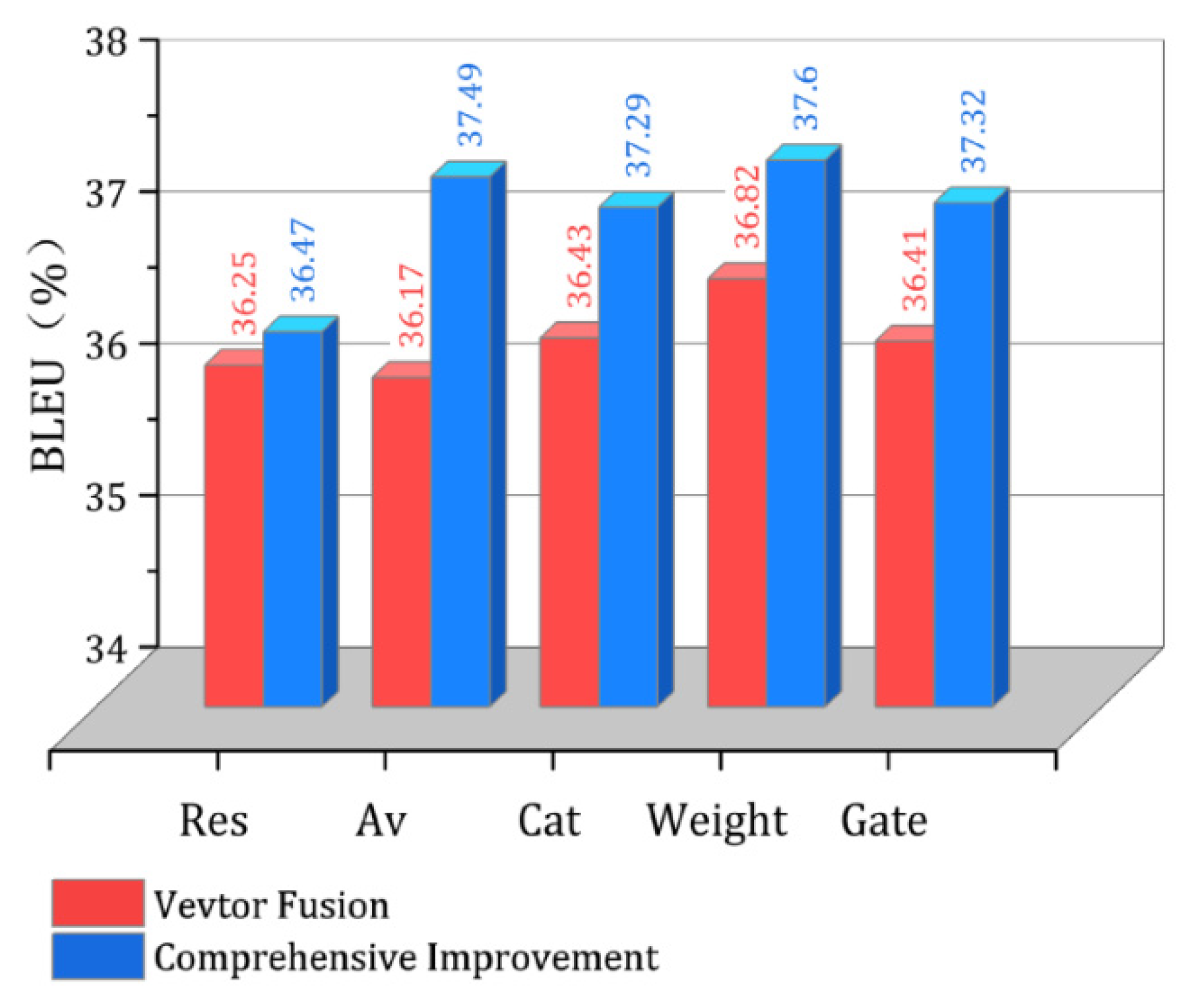
- In this paper, a comparative experiment is carried out on the comprehensive improved model composed of the encoder after vector fusion and the improved decoder. As shown in Figure 5, it can be seen that the translation effect of the improved model has been further improved, and the weight fusion comprehensive improvement model still has the best translation effect; its BLEU value has increased by 1.58 percentage points. The translation effect of the comprehensive improved model of the splicing fusion and the gate mechanism fusion is equivalent, which is consistent with the experimental conclusion of only using vector fusion.
- The experimental results show that the translation effect of the multi-attention mechanism model based on average fusion leaps beyond that of the improved model based on the splicing and gate mechanism because the improvement of the decoder unit has greatly enhanced the feature extraction effect of the model, and the simple method of average fusion has no effect on the further feature extraction part after the improvement of the decoder unit, while the fusion methods of splicing and gate mechanism both introduce new training parameters into the model network, which affects the parameter training of the subsequent feature extraction part of the decoder to a certain extent.
5.3. Comprehensive Comparison
- From the data in Table 1 and Table 3, it can be seen that the residual connection method and the four vector fusion methods have further improved the translation performance after combining the improved decoder unit experiment, which further verifies the effectiveness of the multi-attention mechanism model.
- Comparing the experimental data in Table 1 and Table 3, it is worth noting that after using the improved decoder unit, the translation effect of average fusion is greatly improved, while the further improvement of the translation effect of the multi-attention mechanism model based on residual connection is not large, indicating that the output vector of the intermediate layer of the encoder has a great effect on the improvement of translation performance after the improved decoder.
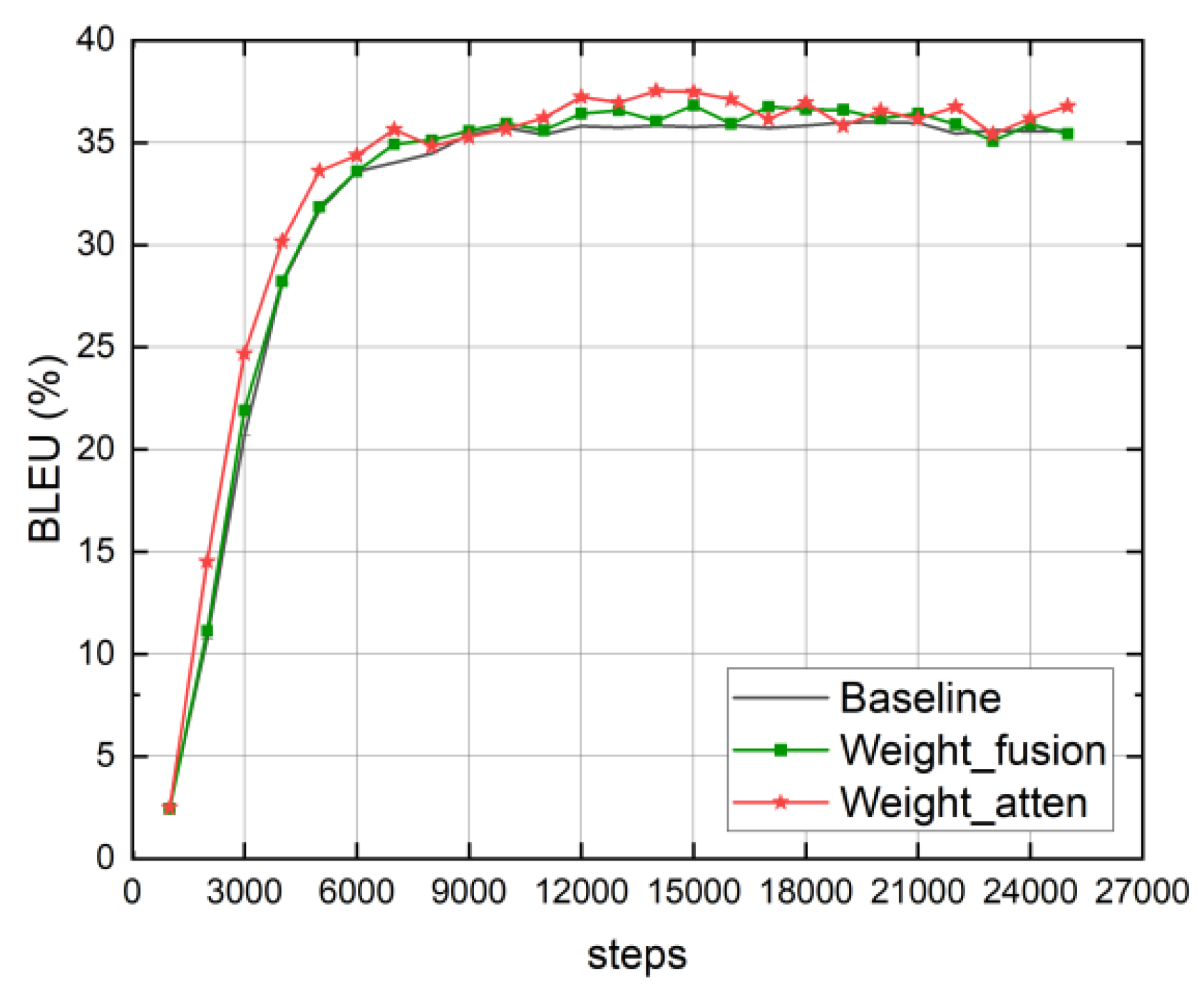
- The comparison between the weight fusion that achieves the best effect in the vector fusion experiment and the translation effect of the multi-attention mechanism model based on weight fusion is shown in Figure 6. It can be seen from the figure that the two improved translation models not only improved the translation effect but also achieved the best translation effect earlier than the baseline model. Furthermore, the multi-attention mechanism model based on vector fusion has better translation performance than the baseline model and the model using only fusion experiments from the beginning of training, indicating that the vector fusion method and the multi-attention mechanism model can improve the translation performance while speeding up the model to reach the best translation performance.
- The reference sentences of some test sets, the translation results of the baseline model and the translation results of the multi-attention mechanism model based on weight fusion are compared, as shown in Table 4. It can be seen that compared with the baseline model, the translation results of the comprehensively improved model not only reduce the number of unlisted words “<unk>”, but also terms and named entities such as “噪声”, “跳闸” and “福建省” in Table 4 can be well translated. Additionally, the improved model can also translate words into their corresponding synonyms, such as “数字一体化” into “数字集成”. This fully shows that the model improvement method based on vector fusion can improve the translation performance of the model.
6. Conclusions
7. Limitations
- Fusion method. Although the five vector fusion methods proposed in this paper have achieved improved translation results, vector fusion based on this simple mathematical method is not flexible enough. It is necessary to give appropriate information guidance in the field of electrical engineering and the target language when vector fusion occurs so that the fused vector can obtain the source language feature vector that is more inclined to the field of electrical engineering and contains the target language knowledge.
- Domain characteristics. Although more comprehensive source language information can be obtained at the encoder end by using vector fusion only, its feature extraction still only depends on the internal self-attention mechanism and does not add more lexical features in the field of electrical engineering into the translation model.
- Parameters. Although the translation effect has been improved due to the change in the model structure, the internal parameters of the model have also increased, increasing the complexity of the model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z. Introduction to Computer Linguistics and Machine Translation; Foreign Language Teaching and Research Press: Beijing, China, 2010; pp. 84–85. [Google Scholar]
- Yu, X. Rule-Based Machine Translation Technology Review. J. Chongqing Univ. Arts Sci. 2011, 30, 56–59. [Google Scholar]
- Liu, Q. Survey on Statistical Machine Translation. J. Chin. Inf. Process. 2003, 17, 1–49. [Google Scholar]
- Nal, K.; Blunsom, P. Recurrent Continuous Translation Models. In Proceedings of the Paper presented at the Conference on Empirical Methods in Natural Language Processing 2013, Seattle, WA, USA, 1–13 October 2013. [Google Scholar]
- Ilya, S.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Paper presented at the NIPS 2014. arxiv 2014. [Google Scholar] [CrossRef]
- Dzmitry, B.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Corrado, Macduff Hughes, and Jeffrey Dean. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Jonas, G.; Auli, M.; Grangier, D.; Dauphin, Y. A Convolutional Encoder Model for Neural Machine Translation. arXiv 2016, arXiv:1611.02344. [Google Scholar]
- Jonas, G.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y. Convolutional Sequence to Sequence Learning. In Proceedings of the Paper Presented at the International Conference on Machine Learning 2017, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Barret, Z.; Yuret, D.; May, J.; Knight, K. Transfer learning for low-resource neural machine translation. arXiv 2016, arXiv:1604.02201. [Google Scholar]
- Min, T. Research on Neural Machine Translation under Low-Resource Conditions; Soochow University: Suzhou, China, 2020. [Google Scholar]
- Xu, B. English-Chinese Machine Translation Based on Transfer Learning and Chinese-English Corpus. Comput. Intell. Neurosci. 2022, 2022, 1563731. [Google Scholar] [CrossRef]
- Wang, H. Short Sequence Chinese-English Machine Translation Based on Generative Adversarial Networks of Emotion. Comput. Intell. Neurosci. 2022, 2022, 3385477. [Google Scholar] [CrossRef]
- Ying, F. A Study on Chinese-English Machine Translation Based on Migration Learning and Neural Networks. Int. J. Artif. Intell. Tools 2022, 18, 2250031. [Google Scholar] [CrossRef]
- Li, C. A Study on Chinese-English Machine Translation Based on Transfer Learning and Neural Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 8282164. [Google Scholar] [CrossRef]
- Kurosawa, M.; Komachi, M. Dynamic Fusion: Attentional Language Model for Neural Machine Translation. arXiv 2019, arXiv:1909.04879. [Google Scholar]
- Zheng, P. Multisensor Feature Fusion-Based Model for Business English Translation. Sci. Program 2022, 2022, 3102337. [Google Scholar] [CrossRef]
- Tan, M.; Yin, M.; Duan, X. A System Fusion Method for Neural Machine Translation. J. Xiamen Univ. (Nat. Sci. Ed.) 2019, 58, 600–607. [Google Scholar]
- Banik, D.; Asif, E.; Pushpak, B.; Bhattacharyya, S. Assembling Translations from Multi-Engine Machine Translation Outputs. Appl. Soft Comput. 2019, 78, 230–239. [Google Scholar] [CrossRef]
- Zoph, B.; Knight, K. Multi-Source Neural Translation. In Proceedings of the Paper Presented at the 15th Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2016, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Banik, D.; Ekbal, A.; Bhattacharyya, P.; Bhattacharyya, S.; Platos, J. Statistical-Based System Combination Approach to Gain Advantages over Different Machine Translation Systems. Heliyon 2019, 5, e02504. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, J.; Zong, C.; Yu, H. Sequence Generation: From Both Sides to the Middle. arXiv 2019. [Google Scholar] [CrossRef]
- Sreedhar, M.N.; Wan, X.; Cheng, Y.; Hu, J. Local Byte Fusion for Neural Machine Translation. arXiv 2022, arXiv:2205.11490. [Google Scholar]
- Wang, Q.; Li, F.; Xiao, T.; Li, Y.; Li, Y.; Zhu, J. Multi-Layer Representation Fusion for Neural Machine Translation. arXiv 2020. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yue, Z.; Ye, X.; Liu, R. Research Review of Pre-training Technology Based on Language Model. J. Chongqing Univ. Arts Sci. 2021, 35, 15–29. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2015, Las Vegas, NV, USA, 27–30 June 2016. pp. 770–777.
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the Paper Presented at the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2018, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Bimal, K. Modern Power Electronics and AC Drives; Prentice-Hall: Hoboken, NJ, USA, 2001. [Google Scholar]
- Bimal, K. Modern Power Electronics and AC Drive; Wang, C.; Zhao, J.; Yu, Q.; Cheng, H., Translators; Machinery Industry Press: Beijing, China, 2005. [Google Scholar]
- Wang, Q.; Glover, J.D. Power System Analysis and Design (Adapted in English); Machinery Industry Press: Beijing, China, 2009. [Google Scholar]
- Glover, J.D. Power System Analysis and Design (Chinese Edition); Wang, Q.; Huang, W.; Yan, Y.; Ma, Y., Translators; Machinery Industry Press: Beijing, China, 2015. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. Opennmt: Open-Source Toolkit for Neural Machine Translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics (2002), Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fusion Method | BLEU/% | σ |
|---|---|---|
| Baseline | 36.02 | - |
| Res_mode | 36.25 | 0.23 ↑ |
| Av_fusion | 36.17 | 0.15 ↑ |
| Cat_fusion | 36.43 | 0.41 ↑ |
| Weight_fusion | 36.82 | 0.80 ↑ |
| Gate_fusion | 36.41 | 0.39 ↑ |
| Fusion Method | BLEU/% | |
|---|---|---|
| N-1 System Fusion | Vector Fusion | |
| Baseline | - | 36.02 |
| Av_fusion | 36.00 | 36.17 |
| Cat_fusion | 36.42 | 36.43 |
| Weight_fusion | 36.40 | 36.82 |
| Gate_fusion | 36.31 | 36.41 |
| Fusion Method | BLEU/% | σ |
|---|---|---|
| Baseline | 36.02 | - |
| Atten_mode | 36.87 | 0.85 ↑ |
| Res+atten | 36.47 | 0.45 ↑ |
| Av+atten | 37.49 | 1.47 ↑ |
| Cat+atten | 37.29 | 1.27 ↑ |
| Weight+atten | 37.60 | 1.58 ↑ |
| Gate+atten | 37.32 | 1.30 ↑ |
| Source | Reference | Baseline | Weight_Atten | |
|---|---|---|---|---|
| 1 | The Main Factors Which Affect the Design of the Tower Door of the Wind Turbine | 影响风机塔筒门设计的主要因素 | 风力发电机塔筒<unk>的设计要素。 | 影响风力发电机塔筒设计的主要因素如下: |
| 2 | The system can realize the transmission line flat section measuring internal and external in industry digital integration, increase the efficiency greatly, reduce the labor intensity of production personnel. | 使用该系统可以实现输电线路平断面测量内外业数字一体化,极大地提高功效,减轻生产人员的劳动强度. | 该系统可实现输电线路平断面测量内部、<unk>,大大提高了生产人员的工作效率。 | 该系统实现了输电线路平截面测量与工业数字集成,大大提高了工作效率,降低了生产人员的劳动强度。 |
| 3 | A probability distribution function of sampling clock frequency at oversampling and down-sampling stages is designed to minimize the impact of non-uniform sampling noise. | 通过合理设计过采样和降采样2个阶段中非均匀采样时钟频率的概率分布函数,使得频域的非均匀采样噪声可以被忽略。 | 为减小非均匀采样噪声的影响,设计了采样时钟频率在过采样时的概率分布函数。 | 为减小非均匀采样噪声,设计了采样时钟频率的概率分布函数,以最大限度地减小非采样噪声。 |
| 4 | The Monte Carlo method is a non-deterministic numerical method, which involves a lot of calculation, but it is not conducive for calculating lightning trip-out rate of numerous transmission lines. Therefore it is relatively difficult to be applied. | 考虑工频电压影响的MonteCarlo法是一种非确定性的数值方法,计算量大并且不利于大量输电线路的跳闸率计算,实现较为困难。 | 蒙特卡罗法是一种涉及大量计算的蒙特卡罗法,但计算结果<unk>,应用较为困难。 | 蒙特卡罗方法是一种计算量大 的数值方法,但对各种输电线路的雷击跳闸率计算不合理, 应用较为困难。 |
| 5 | This essay introduces the characteristics of cranes for used in nuclear power plants and the regulatory inspection status of the cranes in Fujian province. Analyses the existing problems, then the corresponding solutions is put forward. | 本文介绍了福建省核电站 起重机的安全监管、检验现状和核电站起重机的特点, 分析了存在的问题,并提出 了相应的解决办法。 | 介绍了<unk>用于核电厂的起重机特点和<unk>的监管情况,分析了目前存在的问题, 提出了相应的解决办法。 | 介绍了福建某核电站用起重机的特点及福建省起重机的监管 现状,分析存在的问题,提出 了相应的解决方案。 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Chen, Y.; Zhang, J. Neural Machine Translation of Electrical Engineering Based on Vector Fusion. Appl. Sci. 2023, 13, 2325. https://doi.org/10.3390/app13042325
Chen H, Chen Y, Zhang J. Neural Machine Translation of Electrical Engineering Based on Vector Fusion. Applied Sciences. 2023; 13(4):2325. https://doi.org/10.3390/app13042325
Chicago/Turabian StyleChen, Hong, Yuan Chen, and Juwei Zhang. 2023. "Neural Machine Translation of Electrical Engineering Based on Vector Fusion" Applied Sciences 13, no. 4: 2325. https://doi.org/10.3390/app13042325
APA StyleChen, H., Chen, Y., & Zhang, J. (2023). Neural Machine Translation of Electrical Engineering Based on Vector Fusion. Applied Sciences, 13(4), 2325. https://doi.org/10.3390/app13042325