
Mask–Mediator–Wrapper: A Revised Mediator–Wrapper Architecture for Heterogeneous Data Source Integration

Abstract
:1. Introduction
“…it is time for data integration operators to break free of end-to-end data integration systems and be available in the open source to speed up adoption and progress.”
“The first challenge […] is that progress of data integration and its application in practice are hindered by the fact that there are very few quality tools with which practitioners and researchers can freely experiment.”
2. Research Methodology
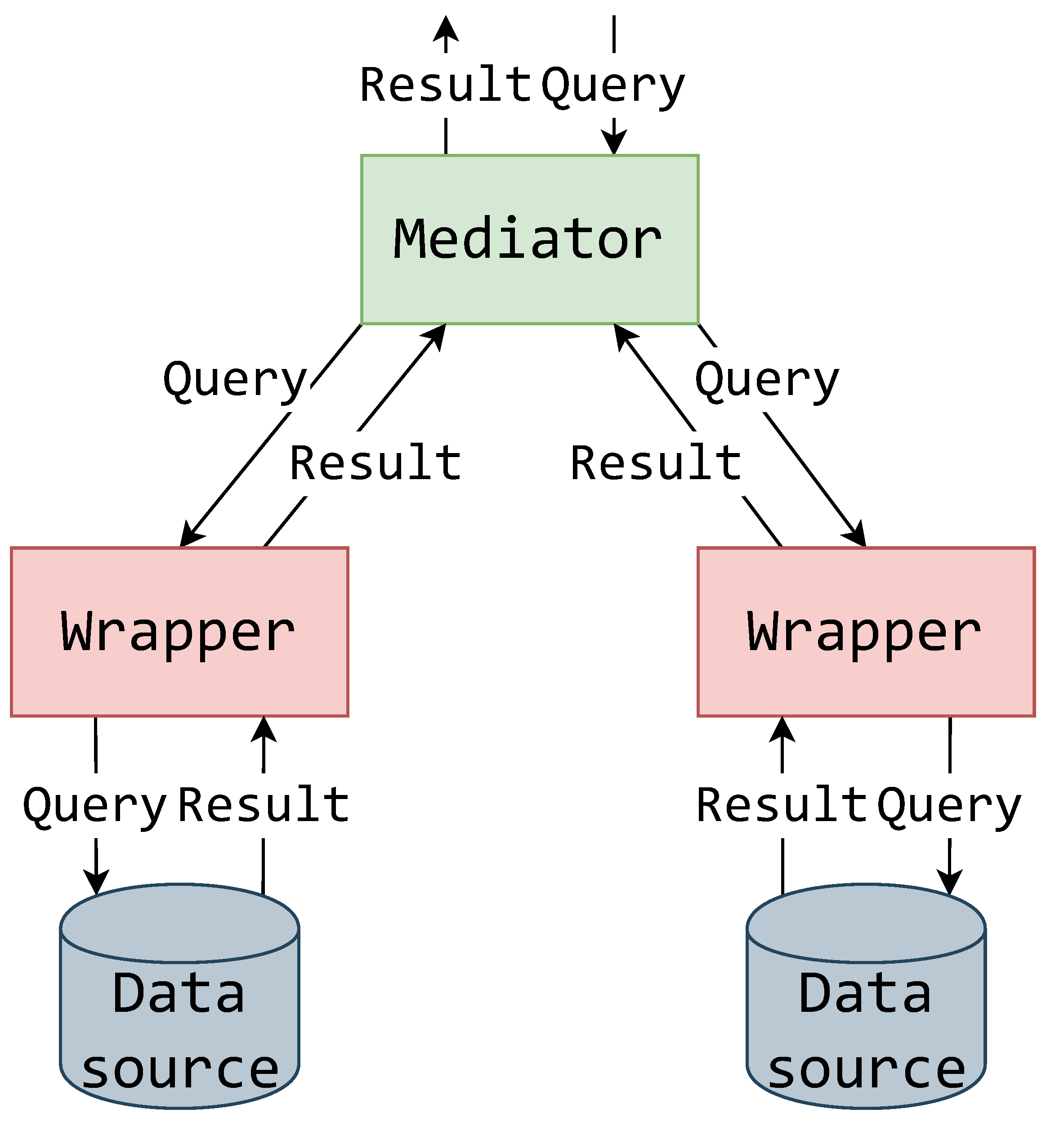
3. The Mediator–Wrapper Architecture
3.1. On the Roles of Mediator–Wrapper Components
- It can be used by other software elements, its “clients”.
- It possesses an official usage description, which is sufficient for a client author to use it.
- It is not tied to any fixed set of clients.
- RW1
- The start-up cost to write a specific wrapper should be small. The wrapper itself can be constructed quickly with little need for prior knowledge of the data source integration system internal structure. There is a basic service upon which a specific wrapper is built upon.
- RW2
- Wrappers should be able to evolve. Incremental upgrades to the wrapper should be possible.
- RW3
- Wrappers should be modular and independent. Wrappers for new data sources can be integrated into the existing data source integration system without disturbing user applications, and other wrappers or components.
- RW4
- Wrappers should be participants in query planning. The wrapper may use whatever knowledge it has about a repository’s query and specialized search facilities to dynamically determine how much of a query the repository is capable of handling.
- RMe1
- Structuring mediators into hierarchies should not lead to problems.
- RMe2
- Mediators should drive transformations. Mediators are there to accommodate the need for data and metadata restructuring. Queries are also affected by this restructuring.
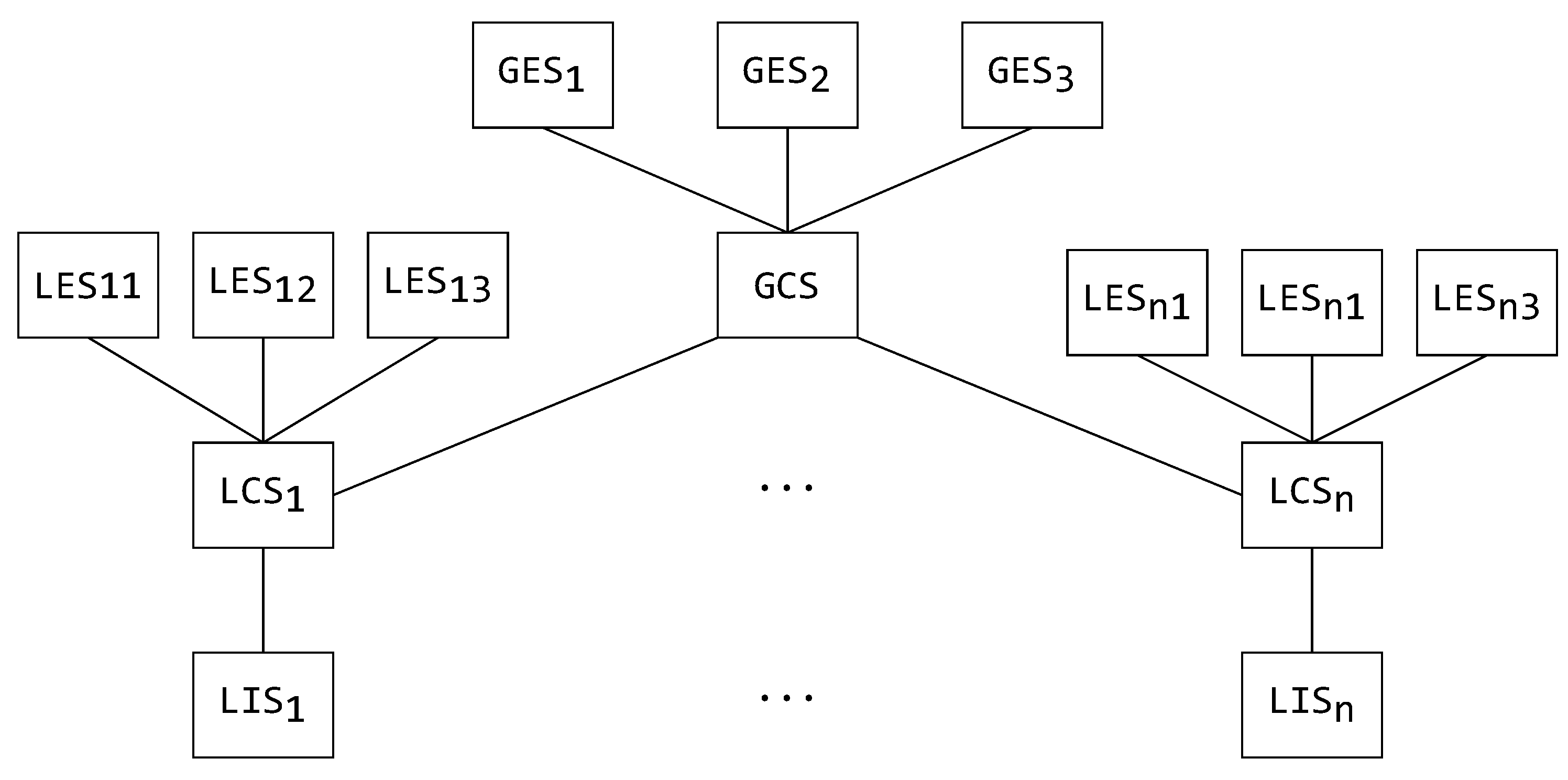
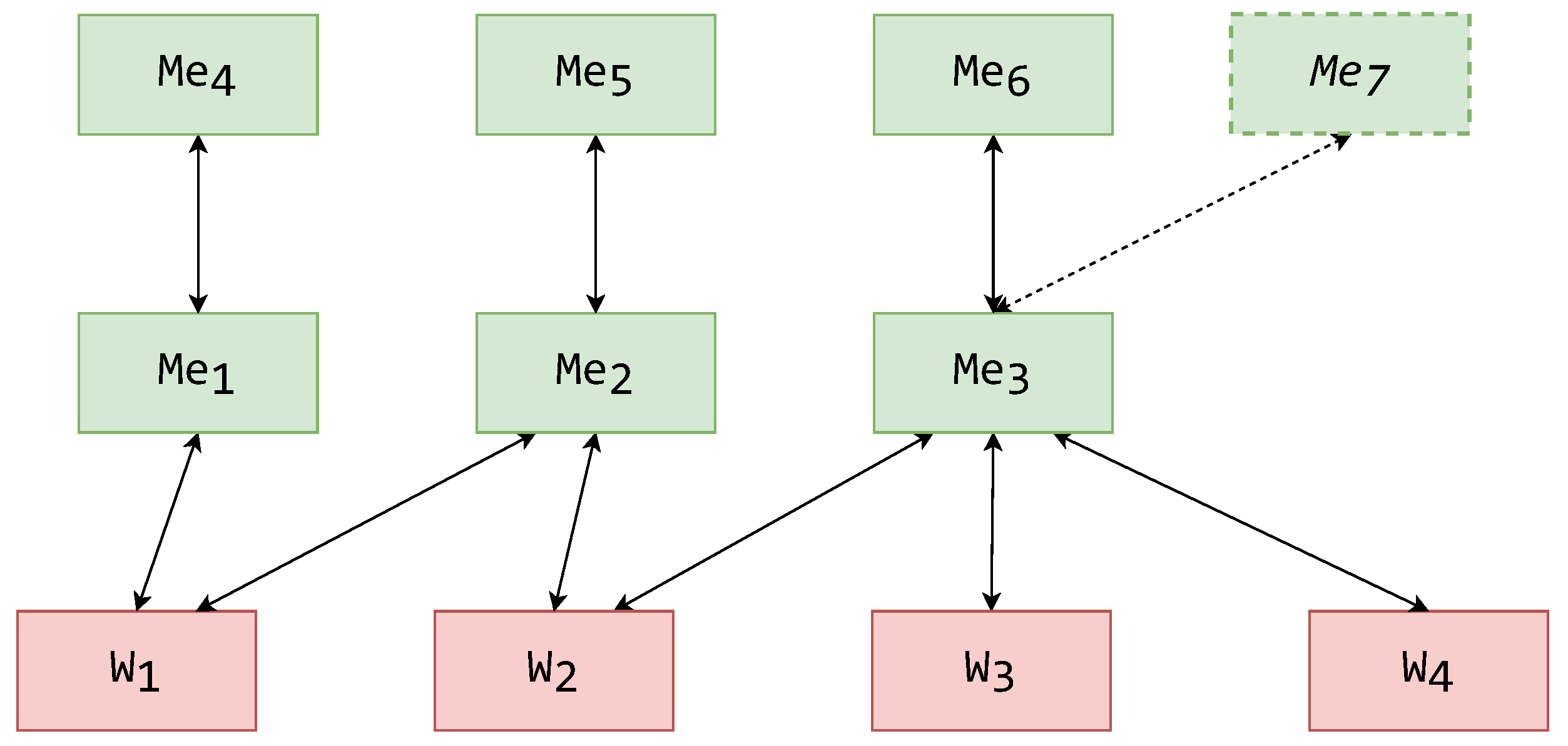
3.2. On Schema Hierarchies in the Mediator–Wrapper Architecture
4. Problems with the Mediator–Wrapper Architecture
- RMe3
- Mediators should be used to mediate, not to represent.
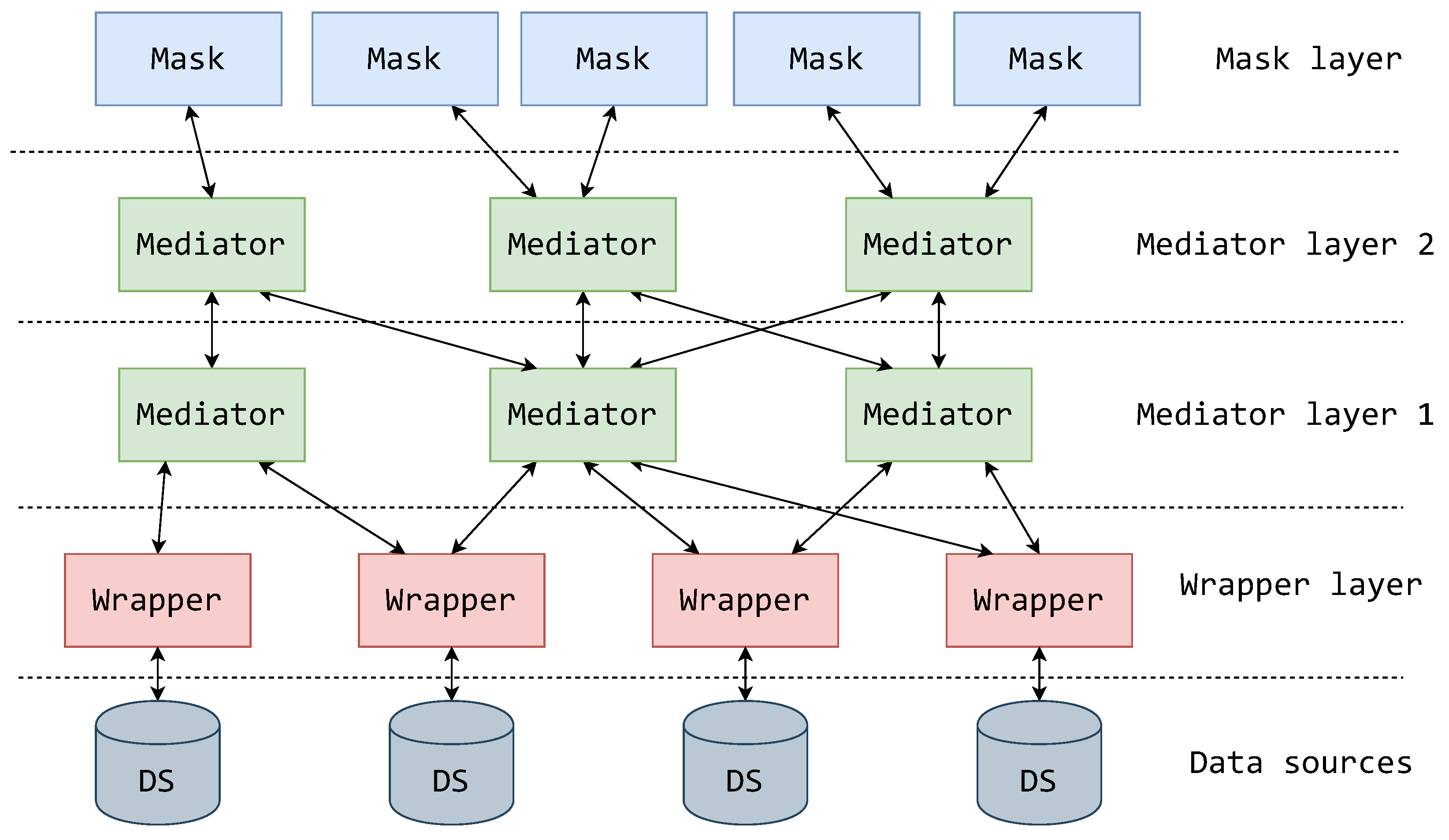
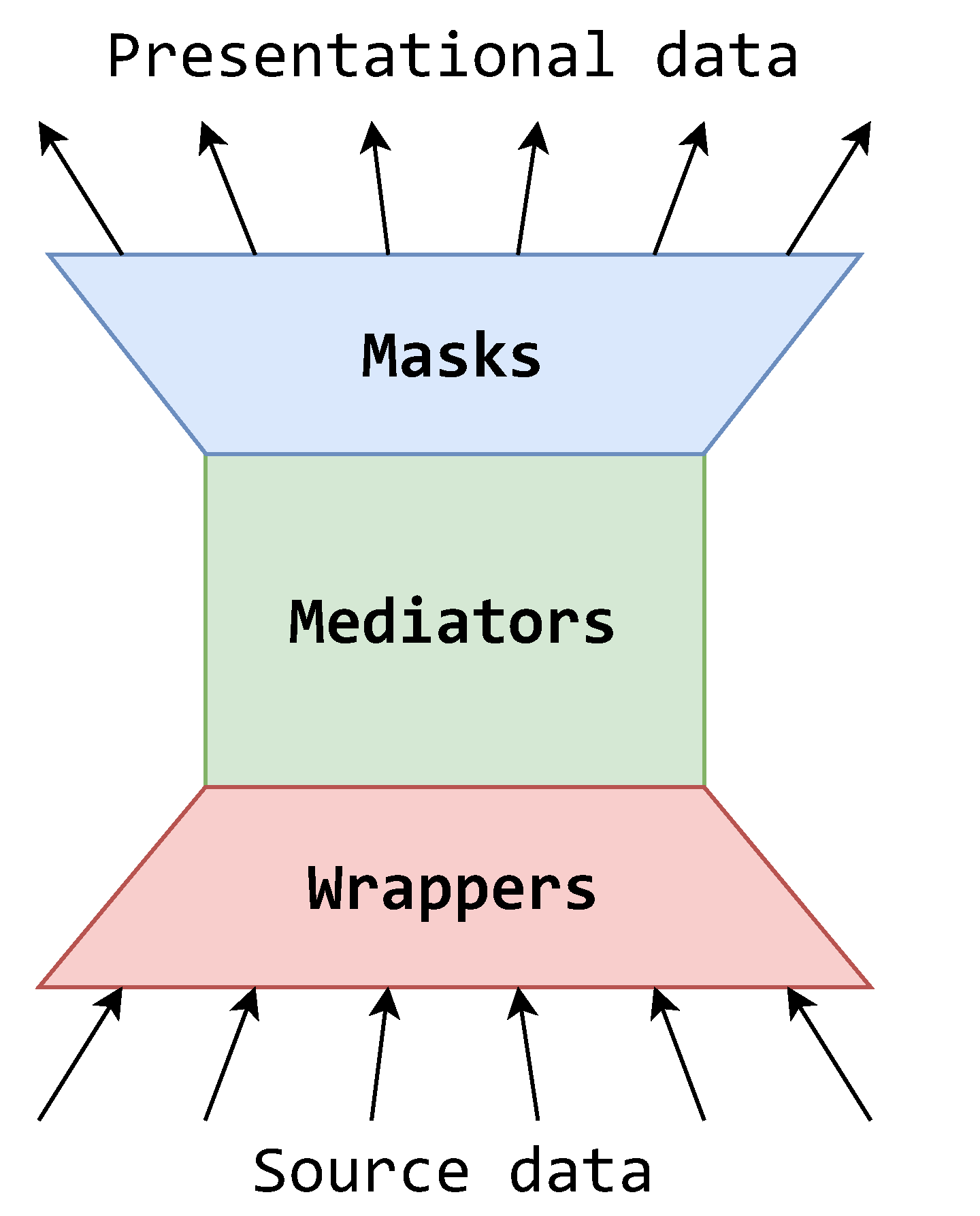
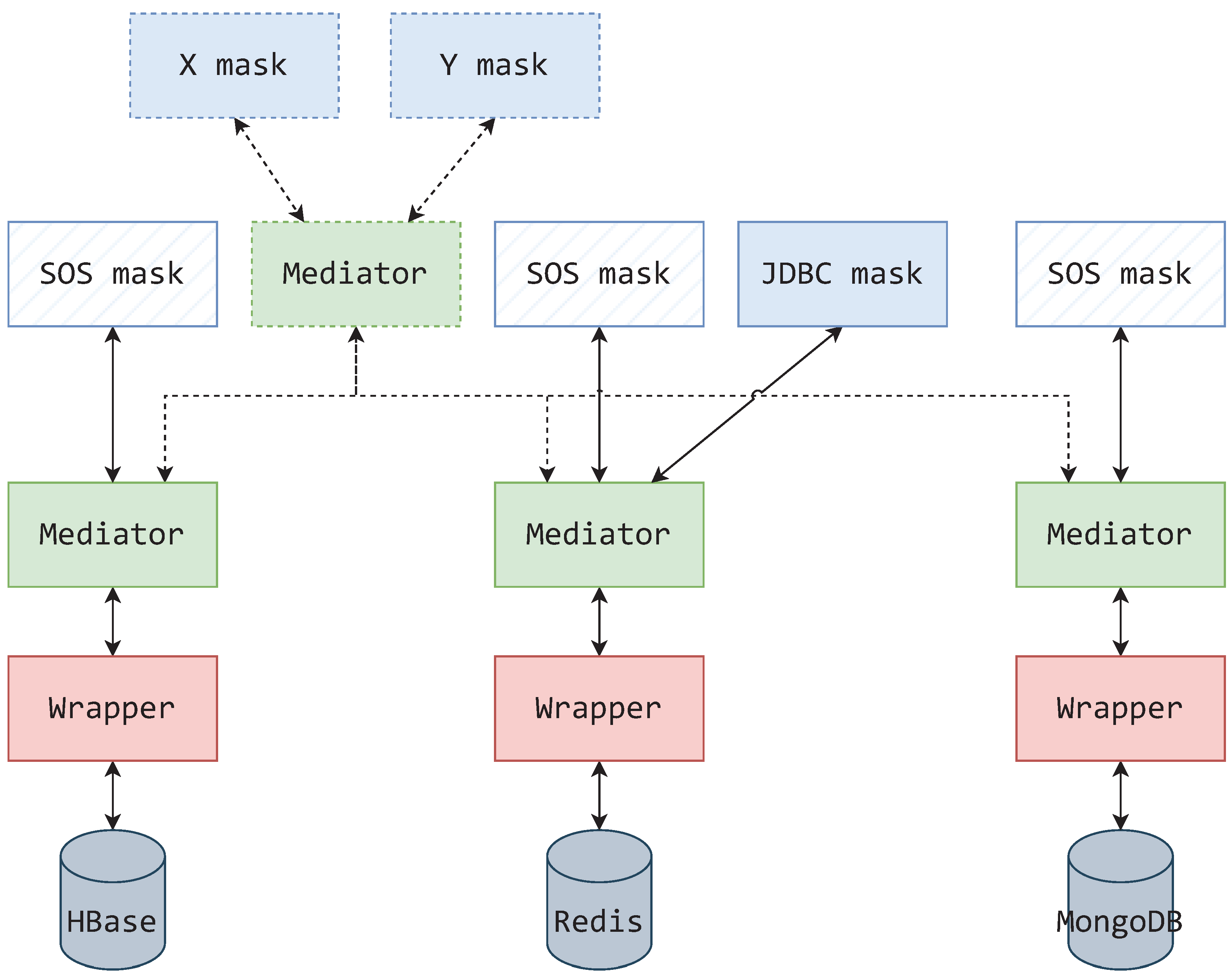
5. Extending the Mediator–Wrapper Architecture
- RMa1
- A mask should be positioned at the top of the architecture.
- RMa2
- A mask only connects to a single mediator.
- RMa3
- A mask is used for representational purposes, representing a schema, querying data, and representing the result data.
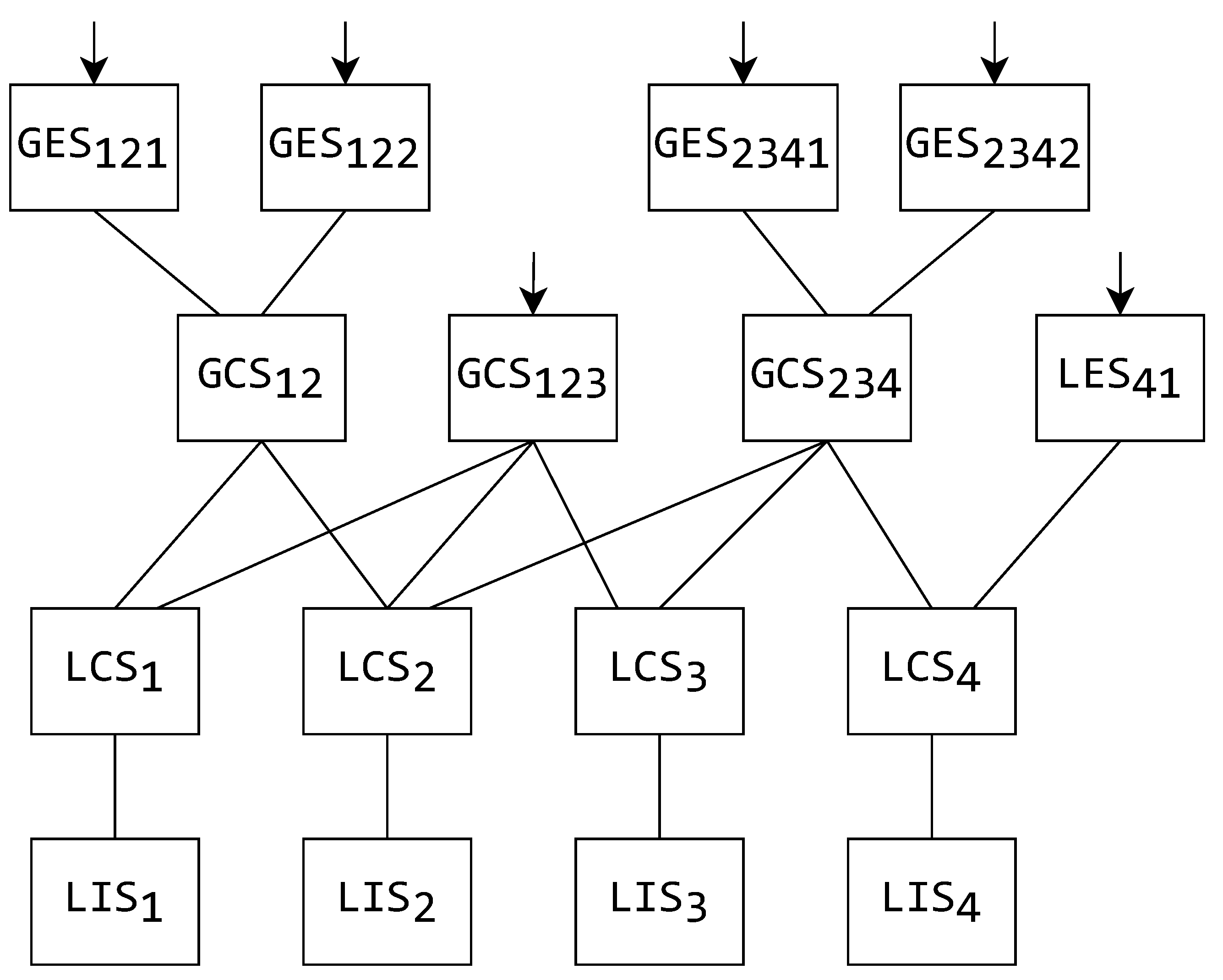
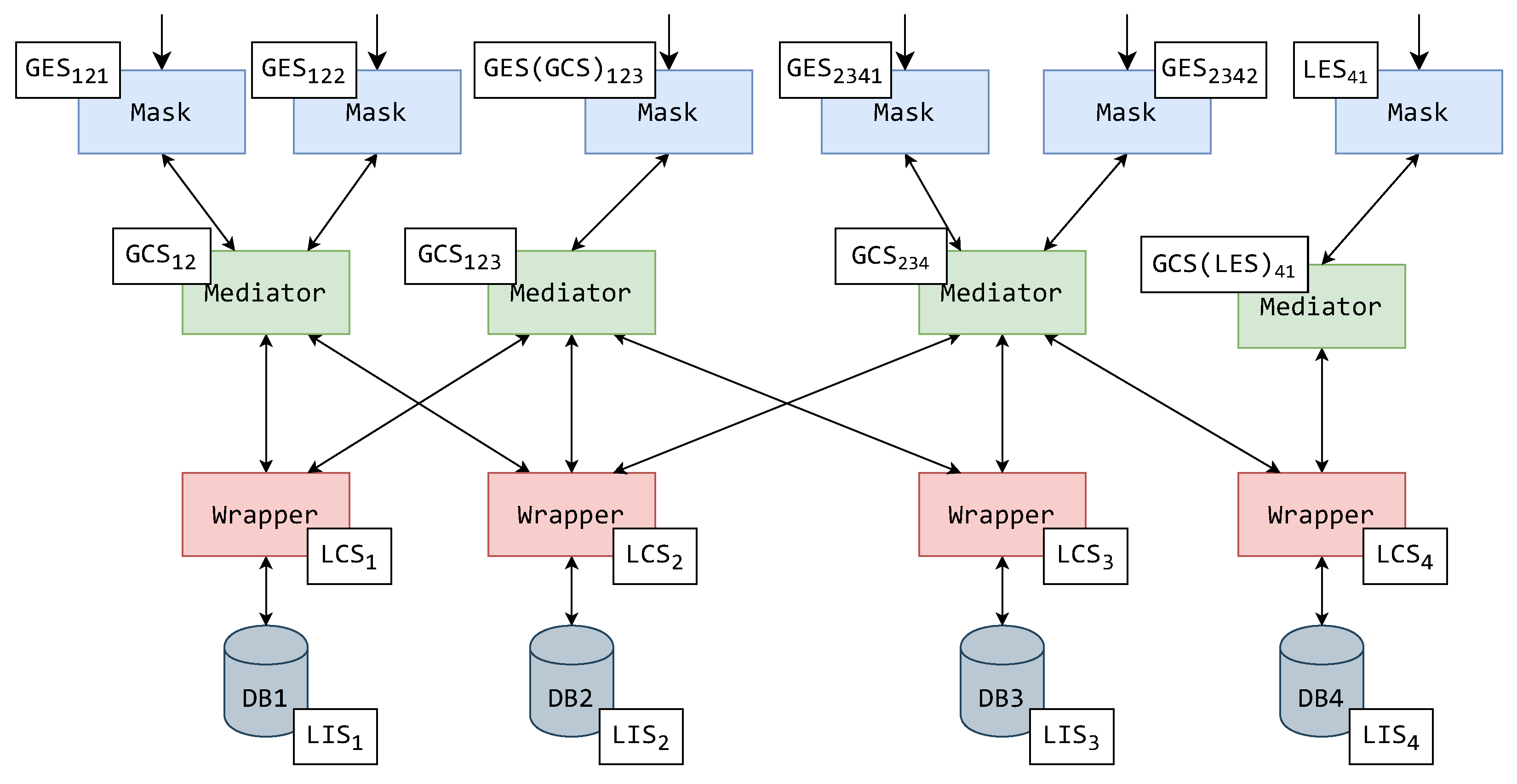
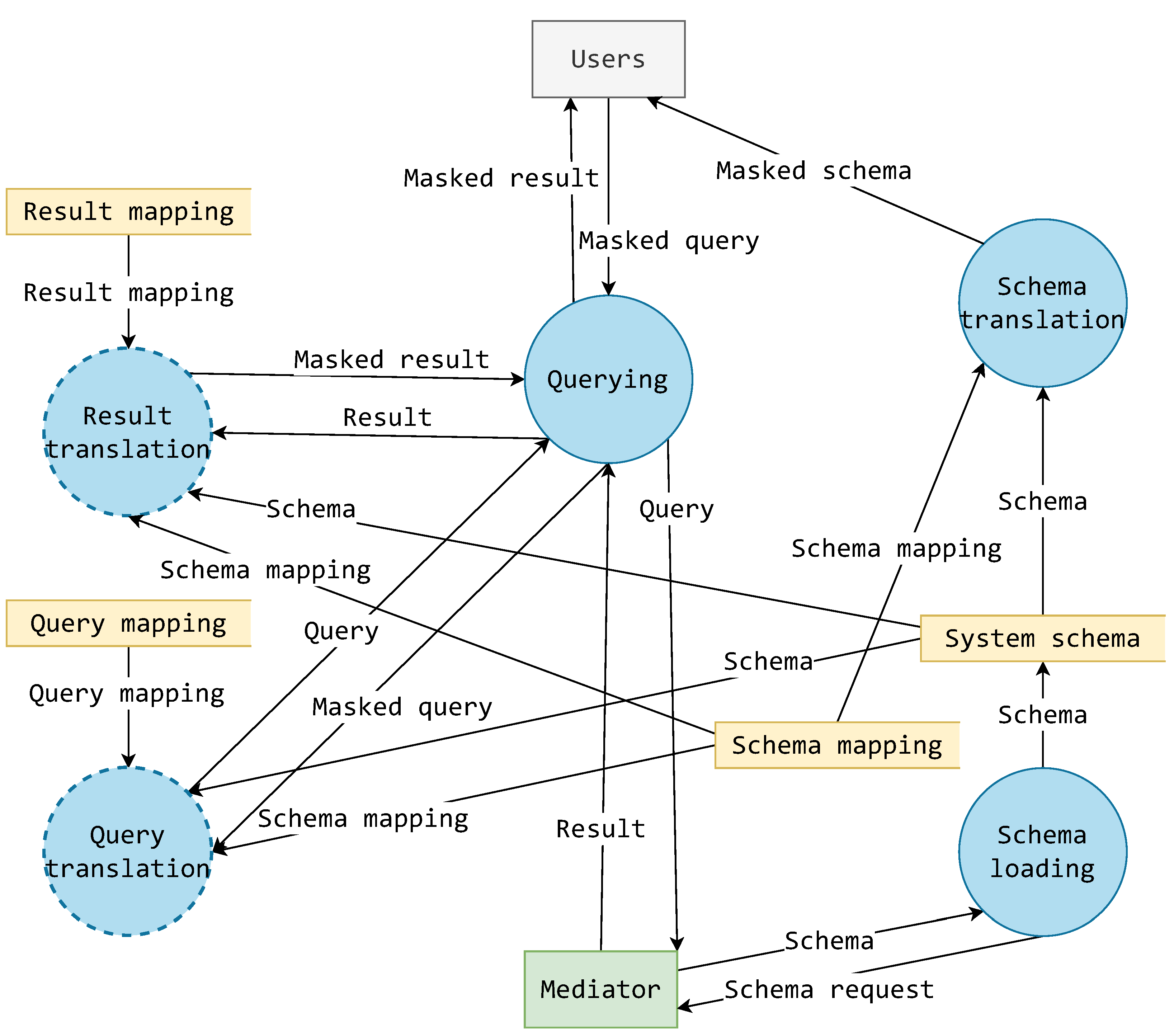
5.1. The Mask’s Effect on the System Schema Hierarchy
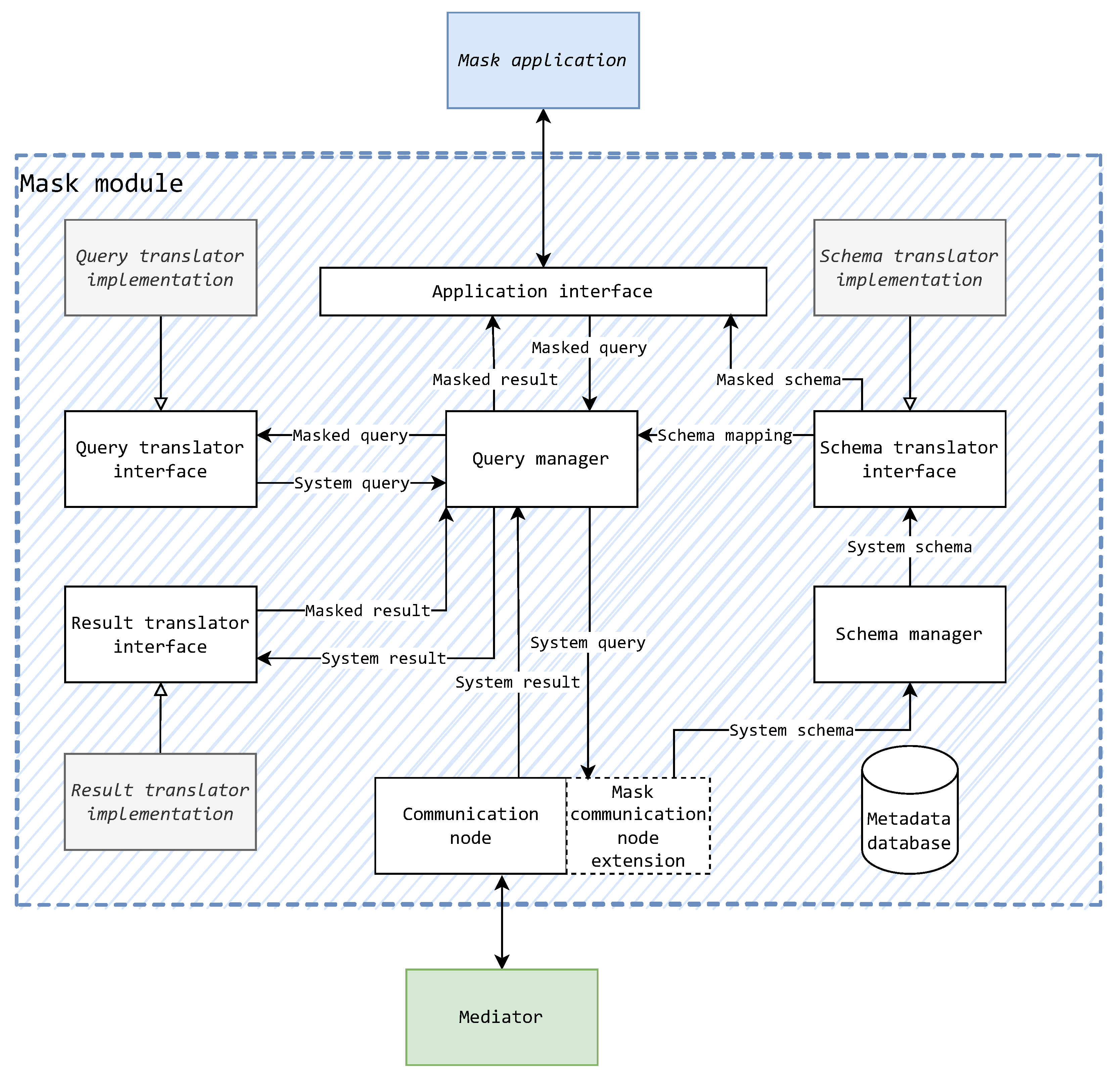
5.2. On the Implementation of a Mask
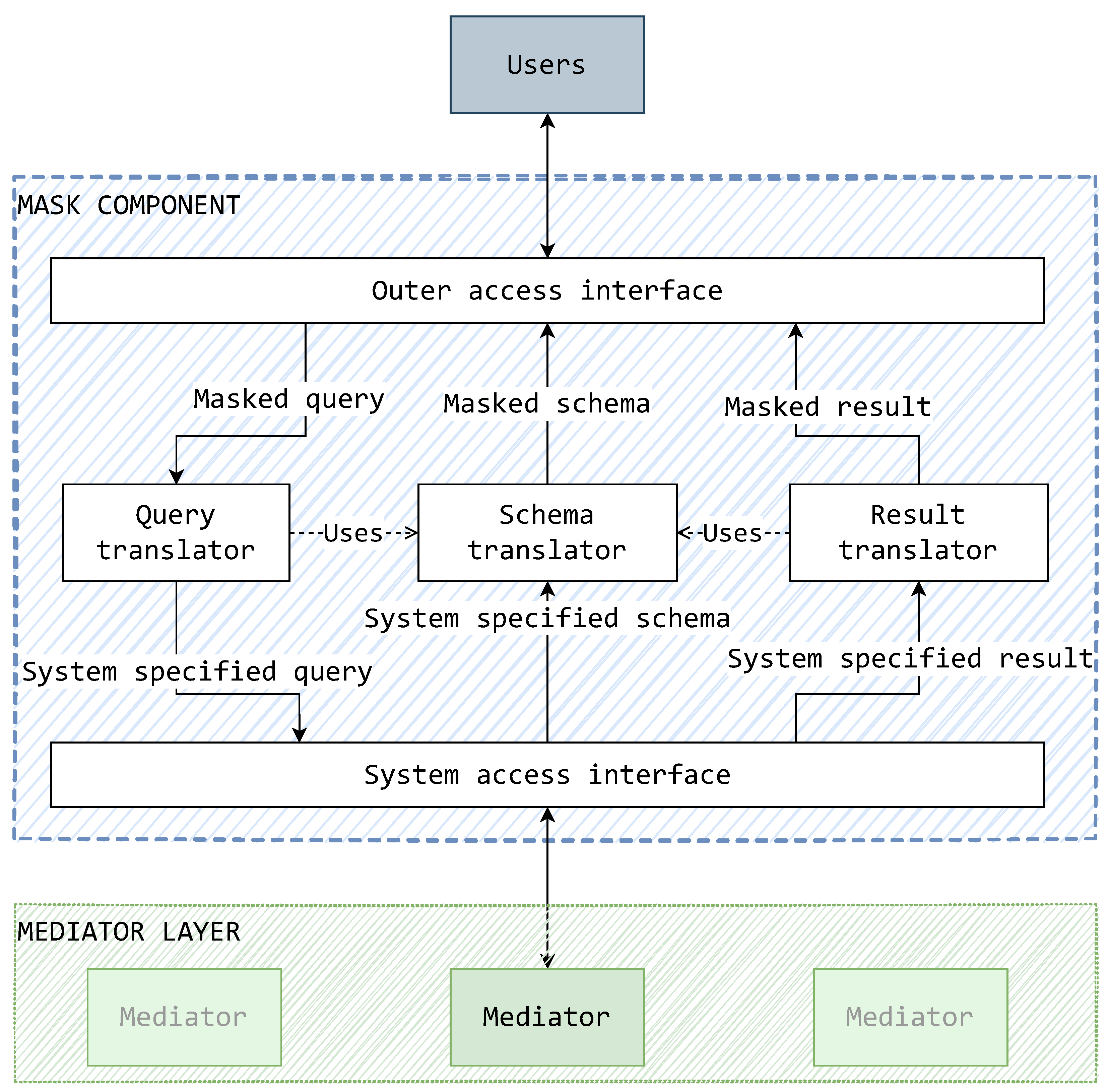
- F1
- The mask must interface with the system via mediators. The mask connects to just one mediator, but it should in general be able to connect to and communicate with any system mediator interchangeably. A connection with a wrapper is feasible, but it is inadvisable and thus not of primary concern.
- F2
- The mask must provide a user access interface. The user access interface is the point of user system access. This interface can take any implementational form, provided that the chosen form has presentational abilities for data storage concerns. This interface is interchangeable and does not have effect on the general way in which data source component translations take place.
- F3
- The mask must translate schemas from the system format to the user access (masked) format. The mask ascertains the system schema provided by its connected mediator and adapts the schema to a defined mask format.
- F4
- The mask must translate queries from the user access (masked) format to the system format. The queries are given by the user through the user access interface in a masked format and are translated to the system format. To determine mask-to-system element mappings, the query translation can use the results of schema translations.
- F5
- The mask must translate results from the system format to the user access (masked) format. The results received through the system must be adapted to the defined mask format. To determine certain metadata aspects (e.g., the naming of attributes) of the data results, the results of the schema translations can be used.
- The acquisition of a mask schema;
- Querying via a masked query;
- Receiving masked results.
- Schema translator implementation;
- Query translator implementation;
- Result translator implementation;
- Mask application.
5.3. Quantitative Analysis on Scenarios
For a set of components of possible types representing a mask, a mediator with representational functionality, a mediator without representational functionality, and a wrapper respectively, and a set of possible actions over those components representing implementation and deployment respectively, us the cost of performing an action over component , with the addition of signifying the cost of setting up a connection between a pair of components
5.3.1. Scenario 1: Adding a New Representation Type
5.3.2. Scenario 2: Adding a New Representation
5.3.3. Scenario 3: Adding a New Mediator
5.3.4. Scenario 4: Adding a New Wrapper to an Existing Mediation
5.3.5. Analysis of the Shift Costs
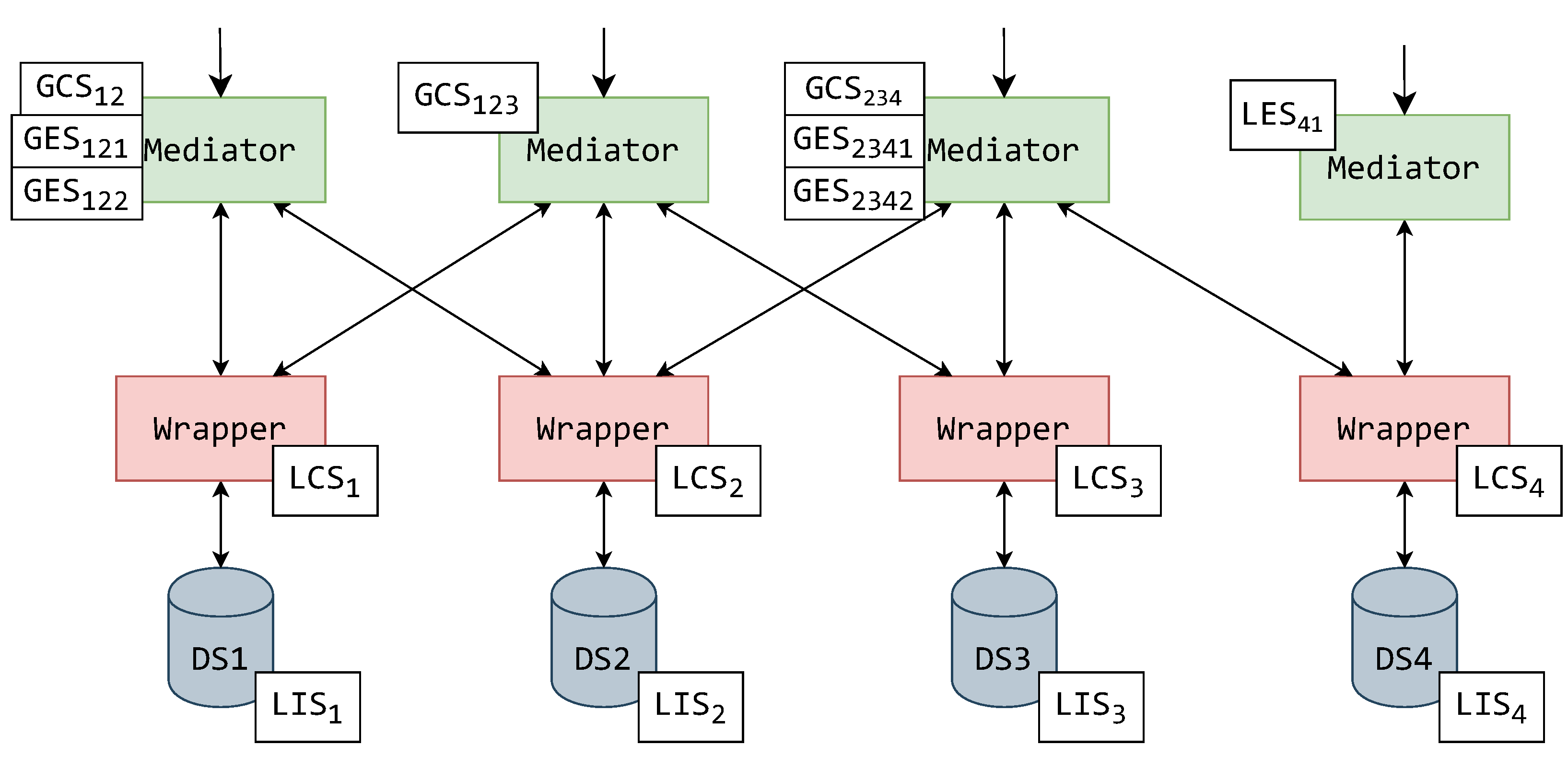
5.4. Hypothetical Implementational Example
6. Discussion
Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sheth, A.; Larson, J. Federated Database-Systems for Managing Distributed, Heterogeneous, and Autonomous Databases. Comput. Surv. 1990, 22, 183–236. [Google Scholar] [CrossRef]
- Roth, M.T.; Arya, M.; Haas, L.; Carey, M.; Cody, W.; Fagin, R.; Schwarz, P.; Thomas, J.; Wimmers, E. The Garlic project. In Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data—SIGMOD’96; ACM Press: Montreal, QC, Canada, 1996; p. 557. [Google Scholar] [CrossRef]
- Roth, M.T.; Schwarz, P. Don’t Scrap It, Wrap It! A Wrapper Architecture for Legacy Data Sources. In Proceedings of the 23rd VLDB Conference, Athens, Greece, 25–29 August 1997; p. 10. [Google Scholar]
- Chawathe, S.S.; Garcia-Molina, H.; Hammer, J.; Ireland, K.; Papakonstantinou, Y.; Ullman, J.; Widom, J. The TSIMMIS Project: Integration of Heterogeneous Information Sources. In Proceedings of the 10th Meeting of the Information Processing Society of Japan (IPSJ 1994), Tokyo, Japan, October 1994; pp. 7–18. [Google Scholar]
- Leavitt, N. Will NoSQL Databases Live Up to Their Promise? Computer 2010, 43, 12–14. [Google Scholar] [CrossRef]
- Papakonstantinou, Y.; Garcia-Molina, H.; Widom, J. Object exchange across heterogeneous information sources. In Proceedings of the Eleventh International Conference on Data Engineering, Taipei, Taiwan, 6–10 March 1995; pp. 251–260. [Google Scholar] [CrossRef]
- Kimball, R.; Caserta, J. The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data, 1st ed.; Wiley: Indianapolis, IN, USA, 2004. [Google Scholar]
- Zhang, Y.; Zhang, Y.; Wang, S.; Lu, J. Fusion OLAP: Fusing the Pros of MOLAP and ROLAP Together for In-memory OLAP (Extended Abstract). In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 2125–2126. [Google Scholar] [CrossRef]
- Forresi, C.; Gallinucci, E.; Golfarelli, M.; Hamadou, H.B. A dataspace-based framework for OLAP analyses in a high-variety multistore. VLDB J. 2021, 30, 1017–1040. [Google Scholar] [CrossRef]
- Bogatu, A.; Fernandes, A.A.A.; Paton, N.W.; Konstantinou, N. Dataset Discovery in Data Lakes. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 709–720. [Google Scholar] [CrossRef]
- Pang, Z.; Lu, Q.; Chen, S.; Wang, R.; Xu, Y.; Wu, J. ArkDB: A Key-Value Engine for Scalable Cloud Storage Services. In Proceedings of the 2021 International Conference on Management of Data; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2570–2583. [Google Scholar]
- Cappuzzo, R.; Papotti, P.; Thirumuruganathan, S. Creating Embeddings of Heterogeneous Relational Datasets for Data Integration Tasks. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Da Trindade, J.M.F.; Karanasos, K.; Curino, C.; Madden, S.; Shun, J. Kaskade: Graph Views for Efficient Graph Analytics. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 193–204. [Google Scholar] [CrossRef]
- Debrouvier, A.; Parodi, E.; Perazzo, M.; Soliani, V.; Vaisman, A. A model and query language for temporal graph databases. VLDB J. 2021, 30, 825–858. [Google Scholar] [CrossRef]
- Chatziantoniou, D.; Kantere, V. DataMingler: A Novel Approach to Data Virtualization. In Proceedings of the 2021 International Conference on Management of Data; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2681–2685. [Google Scholar]
- Magdy, A.; Abdelhafeez, L.; Kang, Y.; Ong, E.; Mokbel, M.F. Microblogs data management: A survey. VLDB J. 2020, 29, 177–216. [Google Scholar] [CrossRef]
- Arenas, M.; Gottlob, G.; Pieris, A. Expressive Languages for Querying the Semantic Web. ACM Trans. Database Syst. 2018, 43, 1–45. [Google Scholar] [CrossRef]
- Krommyda, M.; Kantere, V. Visualization Systems for Linked Datasets. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1790–1793. [Google Scholar] [CrossRef]
- Zhou, J.; Xu, M.; Shraer, A.; Namasivayam, B.; Miller, A.; Tschannen, E.; Atherton, S.; Beamon, A.J.; Sears, R.; Leach, J.; et al. FoundationDB: A Distributed Unbundled Transactional Key Value Store. In Proceedings of the 2021 International Conference on Management of Data, Xi’an, China, 20–25 June 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2653–2666. [Google Scholar]
- Zimányi, E.; Sakr, M.; Lesuisse, A. MobilityDB: A Mobility Database Based on PostgreSQL and PostGIS. ACM Trans. Database Syst. 2020, 45, 1–42. [Google Scholar] [CrossRef]
- Seidemann, M.; Glombiewski, N.; Körber, M.; Seeger, B. ChronicleDB: A High-Performance Event Store. ACM Trans. Database Syst. 2019, 44, 1–45. [Google Scholar] [CrossRef]
- Zhao, X.; Jiang, S.; Wu, X. WipDB: A Write-in-place Key-value Store that Mimics Bucket Sort. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 1404–1415. [Google Scholar] [CrossRef]
- Liang, J.; Chai, Y. CruiseDB: An LSM-Tree Key-Value Store with Both Better Tail Throughput and Tail Latency. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 1032–1043. [Google Scholar] [CrossRef]
- Golshan, B.; Halevy, A.; Mihaila, G.; Tan, W.C. Data Integration: After the Teenage Years. In Proceedings of the 36th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, PODS ’17, Raleigh, NC, USA, 14–19 May 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 101–106. [Google Scholar] [CrossRef]
- Ford, N.; Parsons, R.; Kua, P. Building Evolutionary Architectures: Support Constant Change, 1st ed.; O’Reilly Media: Beijing, China, 2017. [Google Scholar]
- Wiederhold, G. Mediators in the architecture of future information systems. Computer 1992, 25, 38–49. [Google Scholar] [CrossRef]
- Garcia-Molina, H.; Ullman, J.; Widom, J. Database Systems: The Complete Book, 2nd ed.; Pearson: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Özsu, M.T.; Valduriez, P. Principles of distributed database systems, 3rd ed.; Springer Science+Business Media: New York, NY, USA, 2011. [Google Scholar]
- Busse, S.; Kutsche, R.D.; Leser, U.; Weber, H. Federated Information Systems: Concepts, Terminology and Architectures. Forschungsberichte Fachbereichs Informatik 1999, 99, 1–38. [Google Scholar]
- Jurczyk, P.; Xiong, L.; Goryczka, S. DObjects+: Enabling Privacy-Preserving Data Federation Services. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1325–1328. [Google Scholar] [CrossRef]
- De Moura, S.L.; Coutinho, F.; Siqueira, S.W.M.; Melo, R.N.; Nunes, S.V. Integrating repositories of learning objects using Web-services to implement mediators and wrappers. In Proceedings of the International Conference on Next Generation Web Services Practices (NWeSP’05), Seoul, Republic of Korea, 22–26 August 2005; p. 6. [Google Scholar] [CrossRef]
- Wang, H.; Li, J.; He, Z. An effective wrapper architecture to heterogeneous data source. In Proceedings of the 17th International Conference on Advanced Information Networking and Applications, AINA 2003, Xi’an, China, 29 March 2003; pp. 565–568. [Google Scholar] [CrossRef]
- Chang, Y.; Chang, C.; Cheng, H. Applying ontology to geographical scientific data extraction. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; pp. 3397–3402. [Google Scholar] [CrossRef]
- Shao, Y.; Di, L.; Kang, L.; Bai, Y. An integrated framework for geospatial data discovering and standardized processing. In Proceedings of the 2013 Second International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Fairfax, VA, USA, 12–16 August 2013; pp. 334–337. [Google Scholar] [CrossRef]
- Garg, B.; Kaur, K. Integration of heterogeneous databases. In Proceedings of the 2015 International Conference on Advances in Computer Engineering and Applications, Ghaziabad, India, 19–20 March 2015; pp. 1033–1038. [Google Scholar] [CrossRef]
- Schmatz, K.; Berwind, K.; Engel, F.; Hemmje, M.L. An Interface to Heterogeneous Data Sources Based on the Mediator/Wrapper Architecture in the Hadoop Ecosystem. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 1838–1845. [Google Scholar] [CrossRef]
- Doncevic, J.; Fertalj, K. Database Integration Systems. In Proceedings of the 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), IEEE, Opatija, Croatia, 28 September–2 October 2020; pp. 1617–1622. [Google Scholar] [CrossRef]
- Sethi, R.; Traverso, M.; Sundstrom, D.; Phillips, D.; Xie, W.; Sun, Y.; Yegitbasi, N.; Jin, H.; Hwang, E.; Shingte, N.; et al. Presto: SQL on Everything. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1802–1813. [Google Scholar] [CrossRef]
- Meyer, B. The grand challenge of trusted components. In Proceedings of the 25th International Conference on Software Engineering, Portland, OR, USA, 3–10 May 2003; pp. 660–667. [Google Scholar] [CrossRef]
- Atzeni, P.; Bugiotti, F.; Rossi, L. Uniform access to NoSQL systems. Inf. Syst. 2014, 43, 117–133. [Google Scholar] [CrossRef]
- Vathy-Fogarassy, Á.; Hugyák, T. Uniform data access platform for SQL and NoSQL database systems. Inf. Syst. 2017, 69, 93–105. [Google Scholar] [CrossRef]
- Li, R.; Lu, Z.; Xiao, W.; Wu, W. XML-based integration data model and schema mapping in multidatabase systems. J. Syst. Eng. Electron. 2005, 16, 437–444. [Google Scholar]
- Kozankiewicz, H.; Stencel, K.; Subieta, K. Integration of heterogeneous resources through updatable views. In Proceedings of the 13th IEEE International Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprises, Modena, Italy, 14–16 June 2004; pp. 309–314. [Google Scholar] [CrossRef]
- Lawrence, R. Integration and Virtualization of Relational SQL and NoSQL Systems Including MySQL and MongoDB. In Proceedings of the 2014 International Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 10–13 March 2014; Volume 1, pp. 285–290. [Google Scholar] [CrossRef]
- Abuzaid, F.; Kraft, P.; Suri, S.; Gan, E.; Xu, E.; Shenoy, A.; Ananthanarayan, A.; Sheu, J.; Meijer, E.; Wu, X.; et al. DIFF: A relational interface for large-scale data explanation. VLDB J. 2021, 30, 45–70. [Google Scholar] [CrossRef]
- Li, Y.; Cao, J.; Chen, H.; Ge, T.; Xu, Z.; Peng, Q. FlashSchema: Achieving High Quality XML Schemas with Powerful Inference Algorithms and Large-scale Schema Data. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1962–1965. [Google Scholar] [CrossRef]
- Lam, H.T.; Buesser, B.; Min, H.; Minh, T.N.; Wistuba, M.; Khurana, U.; Bramble, G.; Salonidis, T.; Wang, D.; Samulowitz, H. Automated Data Science for Relational Data. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2689–2692. [Google Scholar] [CrossRef]
- Gkini, O.; Belmpas, T.; Koutrika, G.; Ioannidis, Y. An In-Depth Benchmarking of Text-to-SQL Systems. In Proceedings of the 2021 International Conference on Management of Data, Xi’an, China, 20–25 June 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 632–644. [Google Scholar]
- Fielding, R.T. Architectural Styles and the Design of Network-Based Software Architectures. Ph.D. Thesis, University of California, Irvine, CA, USA, 2000. [Google Scholar]
- Benedikt, M.; Bourhis, P.; Jachiet, L.; Tsamoura, E. Balancing Expressiveness and Inexpressiveness in View Design. ACM Trans. Database Syst. 2021, 46, 1–40. [Google Scholar] [CrossRef]
- Qin, X.; Luo, Y.; Tang, N.; Li, G. Making data visualization more efficient and effective: A survey. VLDB J. 2020, 29, 93–117. [Google Scholar] [CrossRef]
- Martin, R. Clean Architecture: A Craftsman’s Guide to Software Structure and Design, 1st ed.; Pearson: London, UK, 2017. [Google Scholar]
- Ivanics, P. An Introduction to Clean Software Architecture; Department of Computer Science, University of Helsinki: Helsinki, Finland, 2016. [Google Scholar]
- Eden, A.; Mens, T. Measuring software flexibility. IEE Proc.—Softw. 2006, 153, 113–125. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference (Project) | Data Representation and Access |
|---|---|
| [6] [4] (TSIMMIS) [2] (GARLIC) | specialized desktop application |
| [40] [41] [11] [49] | JSON (+ web API) |
| [42] [46] | XML |
| [13] [15] [14] | graph |
| [44] | JDBC |
| [41] | Web application |
| [43] [44] [38] [20] [45] [21] [47] | tabular data |
| [23] [22] [19] | key-value |
| [17] [18] | semantic web |
| [48] | plain text |
| Sc. | 1LMW | 2LMW | MMW |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dončević, J.; Fertalj, K.; Brčić, M.; Krajna, A. Mask–Mediator–Wrapper: A Revised Mediator–Wrapper Architecture for Heterogeneous Data Source Integration. Appl. Sci. 2023, 13, 2471. https://doi.org/10.3390/app13042471
Dončević J, Fertalj K, Brčić M, Krajna A. Mask–Mediator–Wrapper: A Revised Mediator–Wrapper Architecture for Heterogeneous Data Source Integration. Applied Sciences. 2023; 13(4):2471. https://doi.org/10.3390/app13042471
Chicago/Turabian StyleDončević, Juraj, Krešimir Fertalj, Mario Brčić, and Agneza Krajna. 2023. "Mask–Mediator–Wrapper: A Revised Mediator–Wrapper Architecture for Heterogeneous Data Source Integration" Applied Sciences 13, no. 4: 2471. https://doi.org/10.3390/app13042471