Figure 1.
A depiction of the KT task for a student on mathematical exercises. The knowledge tracing process estimates the number of skills students mastered. A student can choose some exercises (e.g., e, e, e, e) containing different knowledge points from problem sets for practicing and leave his/her response logs. Now, the student wants to answer the exercise e.
Figure 1.
A depiction of the KT task for a student on mathematical exercises. The knowledge tracing process estimates the number of skills students mastered. A student can choose some exercises (e.g., e, e, e, e) containing different knowledge points from problem sets for practicing and leave his/her response logs. Now, the student wants to answer the exercise e.
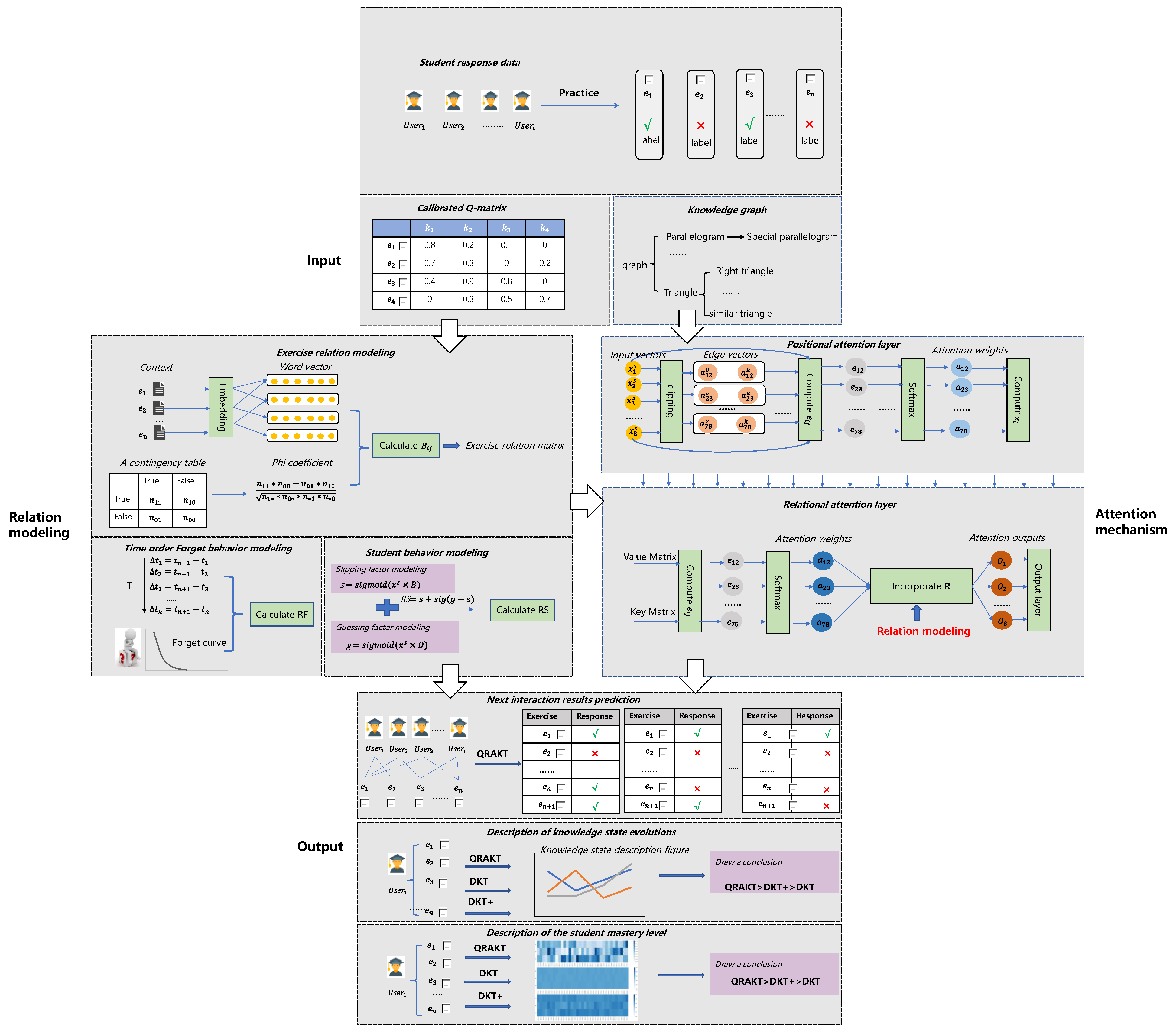
Figure 2.
The general solutions of the calibrated Q-matrix relational attention knowledge tracing model (QRAKT). There exist four parts, the input part, the relation modeling part, the attention mechanism part, and the output part. In the input part, student response data, calibrated Q-matrix, and the knowledge graph are the inputs of the QRAKT model. In the relation modeling part, three types of relation modeling are introduced, exercise relation modeling, time-order forgetting behavior modeling, and student behavior modeling, to obtain the relational coefficient, R. In the attention mechanisms, positional attention and relational attention are applied to incorporate the relational attention coefficient, R, with traditional attention weights and generate the final attention weights. The last part is the output part. The output of the QRAKT model is specified as three aspects: the next interaction result prediction, the description of knowledge state evolution, and the student mastery level.
Figure 2.
The general solutions of the calibrated Q-matrix relational attention knowledge tracing model (QRAKT). There exist four parts, the input part, the relation modeling part, the attention mechanism part, and the output part. In the input part, student response data, calibrated Q-matrix, and the knowledge graph are the inputs of the QRAKT model. In the relation modeling part, three types of relation modeling are introduced, exercise relation modeling, time-order forgetting behavior modeling, and student behavior modeling, to obtain the relational coefficient, R. In the attention mechanisms, positional attention and relational attention are applied to incorporate the relational attention coefficient, R, with traditional attention weights and generate the final attention weights. The last part is the output part. The output of the QRAKT model is specified as three aspects: the next interaction result prediction, the description of knowledge state evolution, and the student mastery level.
![Applsci 13 02541 g002]()
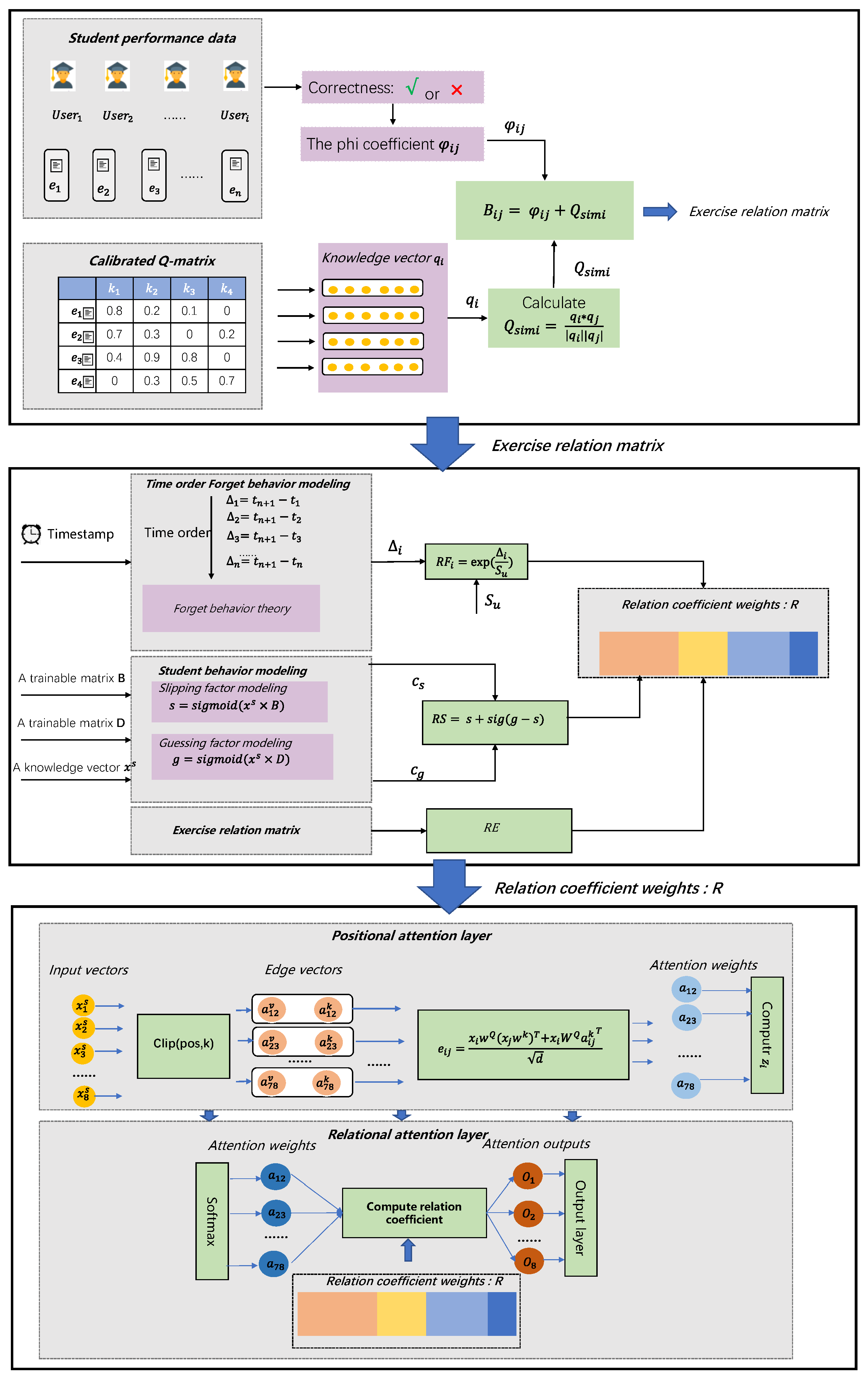
Figure 3.
The overall architecture of the calibrated Q-matrix relational attention knowledge tracing model. There exist three steps. The first step is to obtain the exercise relation matrix by incorporating the Phi coefficients and the knowledge vectors to generate the exercise relation matrix, RE. The second step is aimed at modeling the forgetting behavior and student behaviors and combining these two types of modeling with the RE to obtain the relational coefficient, R. The last step focuses on the data processing involving the positional attention mechanism and the relational attention mechanism to generate the final attention weights after combining the relational coefficient, R.
Figure 3.
The overall architecture of the calibrated Q-matrix relational attention knowledge tracing model. There exist three steps. The first step is to obtain the exercise relation matrix by incorporating the Phi coefficients and the knowledge vectors to generate the exercise relation matrix, RE. The second step is aimed at modeling the forgetting behavior and student behaviors and combining these two types of modeling with the RE to obtain the relational coefficient, R. The last step focuses on the data processing involving the positional attention mechanism and the relational attention mechanism to generate the final attention weights after combining the relational coefficient, R.
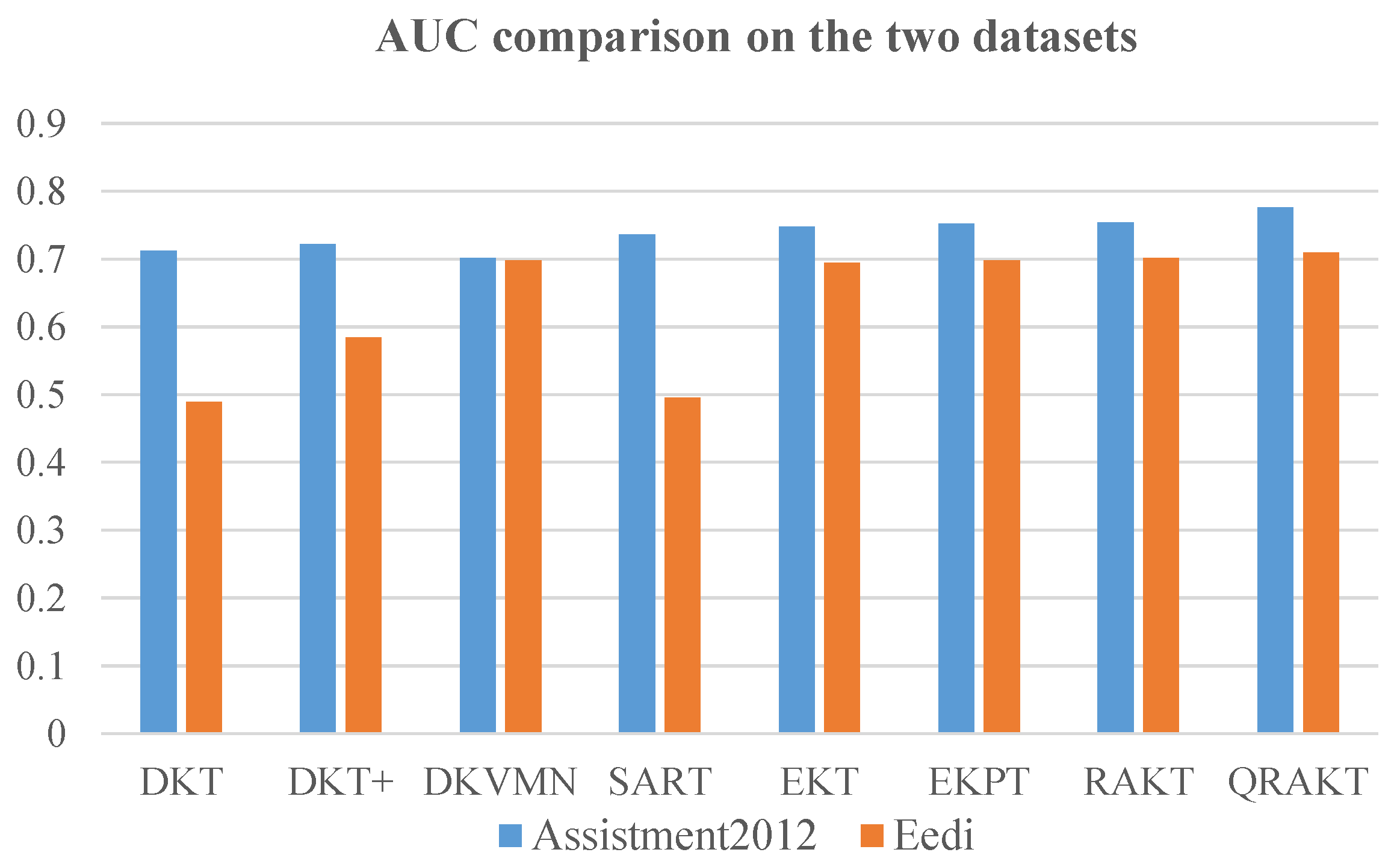
Figure 4.
The comparison of the AUC on the ASSIST2012 dataset and the Eedi dataset. The calibrated Q-matrix relational attention model presented the best results of the AUC compared to the other seven models on the two datasets of 0.771% and 0.707%, respectively.
Figure 4.
The comparison of the AUC on the ASSIST2012 dataset and the Eedi dataset. The calibrated Q-matrix relational attention model presented the best results of the AUC compared to the other seven models on the two datasets of 0.771% and 0.707%, respectively.
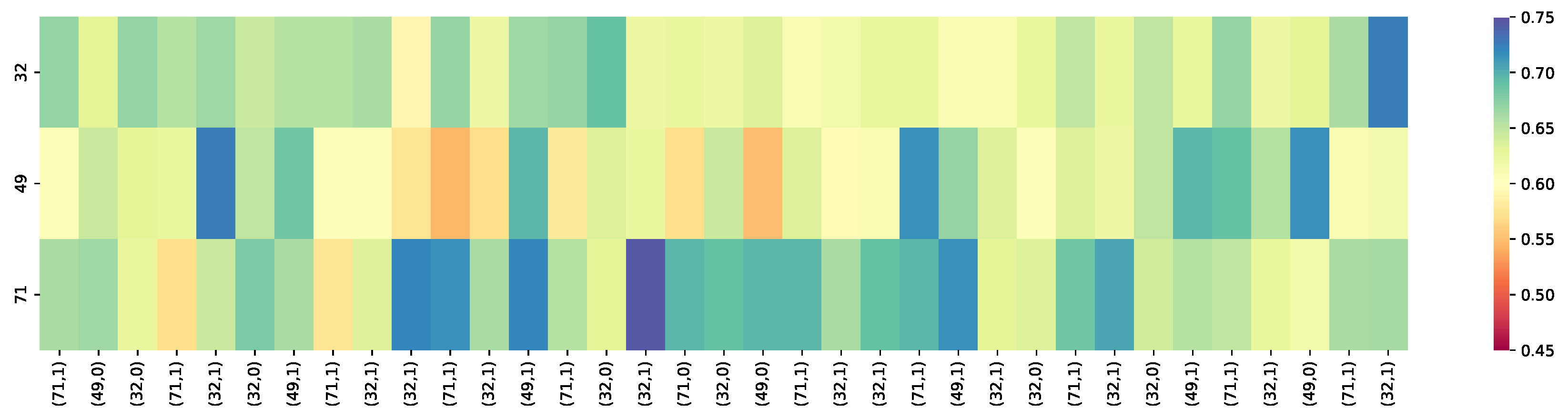
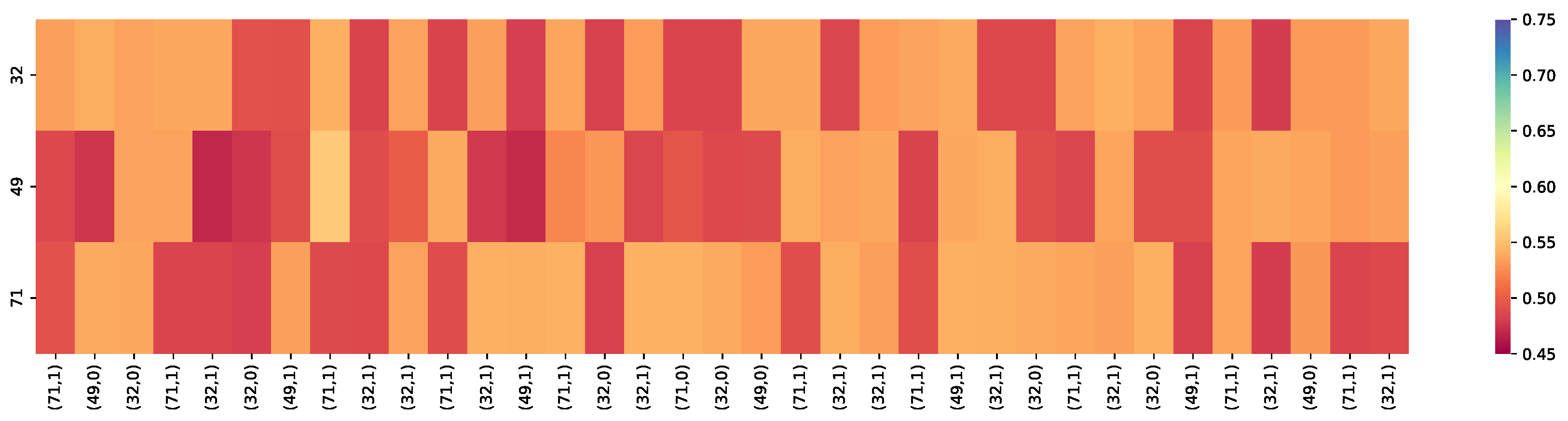
Figure 5.
The knowledge tracing results were based on the calibrated Q-matrix relational attention knowledge tracing model (QRAKT). (71, 1) is a input tuple, and 71 is the skill ID and 1 indicates the student answered the question correctly. The overall prediction results of the skill sets in the QRAKT model fluctuated around 65% for the Accuracy. After the 30th exercise, the student almost mastered those three skills: 32, 49, and 71, with a 68% Accuracy in answering the next exercise correctly.
Figure 5.
The knowledge tracing results were based on the calibrated Q-matrix relational attention knowledge tracing model (QRAKT). (71, 1) is a input tuple, and 71 is the skill ID and 1 indicates the student answered the question correctly. The overall prediction results of the skill sets in the QRAKT model fluctuated around 65% for the Accuracy. After the 30th exercise, the student almost mastered those three skills: 32, 49, and 71, with a 68% Accuracy in answering the next exercise correctly.
Figure 6.
The knowledge tracing results were based on the DKT model. (71, 1) is a input tuple, and 71 is the skill ID and 1 indicates the student answered the question correctly. The overall prediction results of the skill sets in the DKT model fluctuated around 51% for the Accuracy, where the effect was the same as randomly guessing an answer. The student failed to master these three skills: 32, 49, and 71.
Figure 6.
The knowledge tracing results were based on the DKT model. (71, 1) is a input tuple, and 71 is the skill ID and 1 indicates the student answered the question correctly. The overall prediction results of the skill sets in the DKT model fluctuated around 51% for the Accuracy, where the effect was the same as randomly guessing an answer. The student failed to master these three skills: 32, 49, and 71.
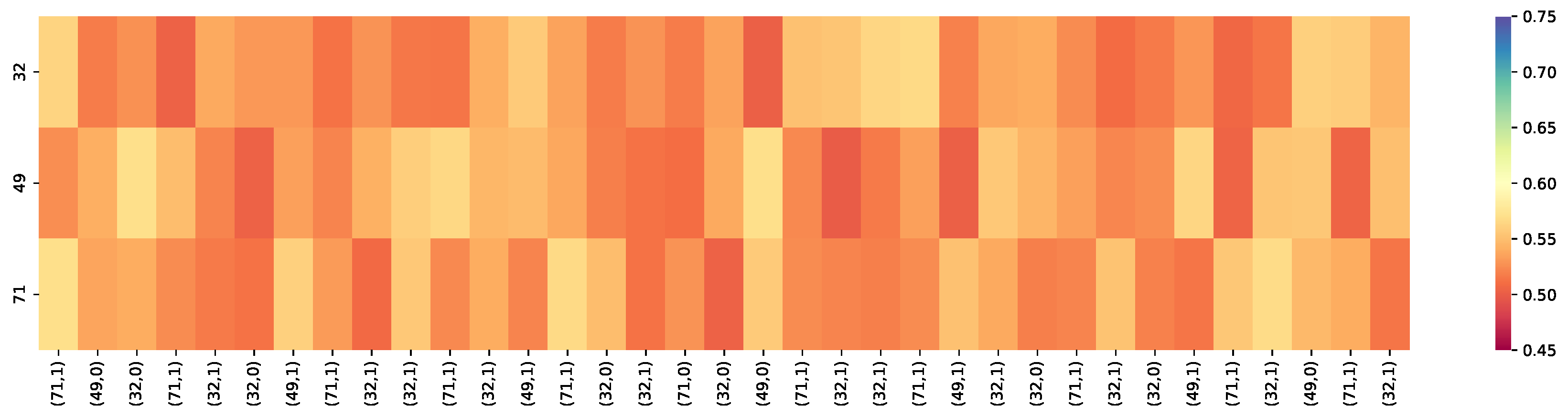
Figure 7.
The knowledge tracing results were based on DKT+. (71, 1) is a input tuple, and 71 is the skill ID and 1 indicates the student answered the question correctly. The overall prediction results of the skill sets in the DKT+ model fluctuated around 55% for the Accuracy. The student mastered these three skills: 32, 49, and 71, at a relatively low mastery level.
Figure 7.
The knowledge tracing results were based on DKT+. (71, 1) is a input tuple, and 71 is the skill ID and 1 indicates the student answered the question correctly. The overall prediction results of the skill sets in the DKT+ model fluctuated around 55% for the Accuracy. The student mastered these three skills: 32, 49, and 71, at a relatively low mastery level.
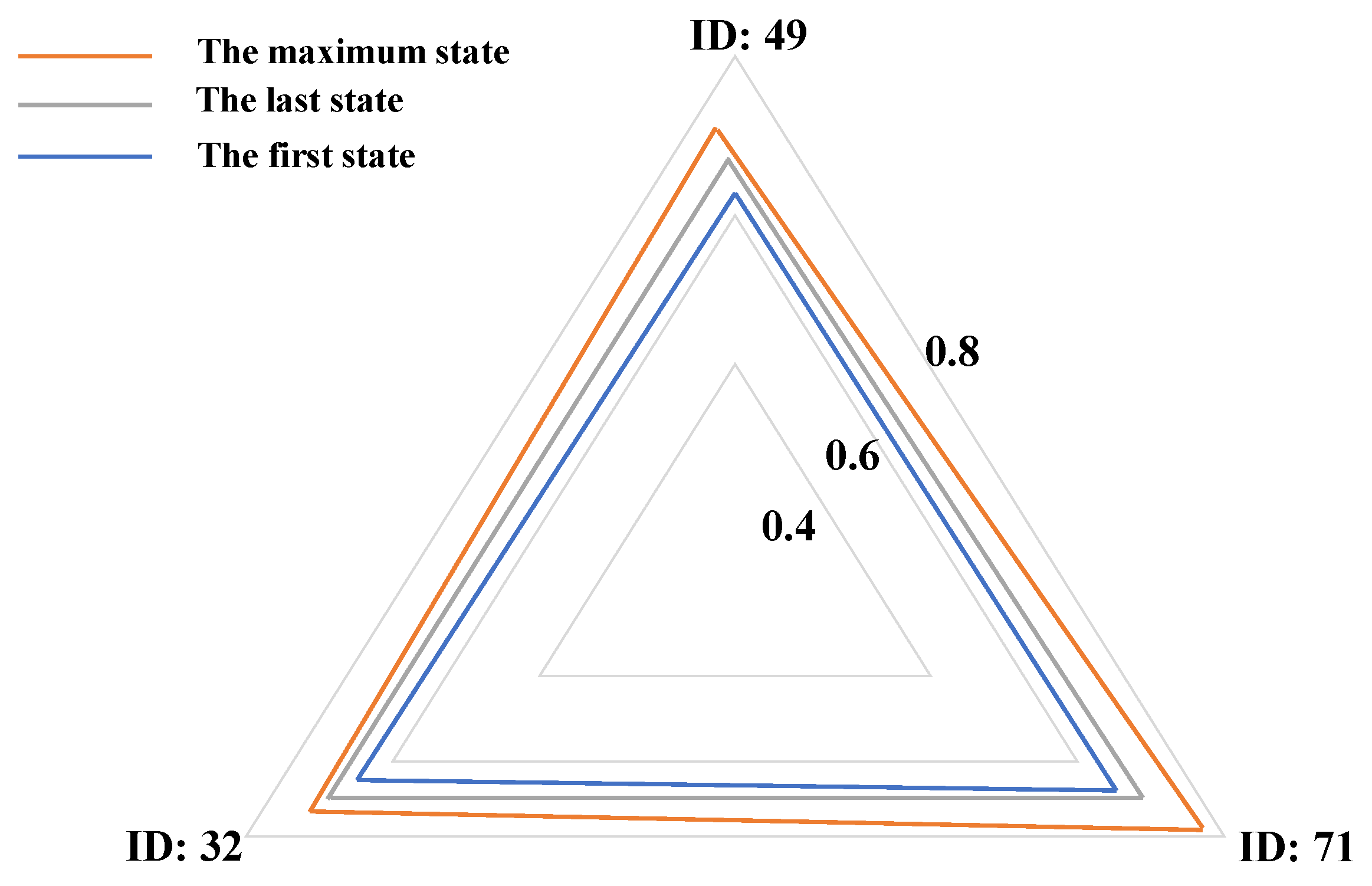
Figure 8.
The radar diagram of the QRAKT model. In the first interaction, the student’s knowledge state was minimum. After a period of study, the performance of the student on Skills 32, 47, and 71 reached the maximum. However, because of the forgetting behaviors and the impact of the guessing factor and the slipping factor, the knowledge state presented some reduction, but it still performed better than the first interaction.
Figure 8.
The radar diagram of the QRAKT model. In the first interaction, the student’s knowledge state was minimum. After a period of study, the performance of the student on Skills 32, 47, and 71 reached the maximum. However, because of the forgetting behaviors and the impact of the guessing factor and the slipping factor, the knowledge state presented some reduction, but it still performed better than the first interaction.
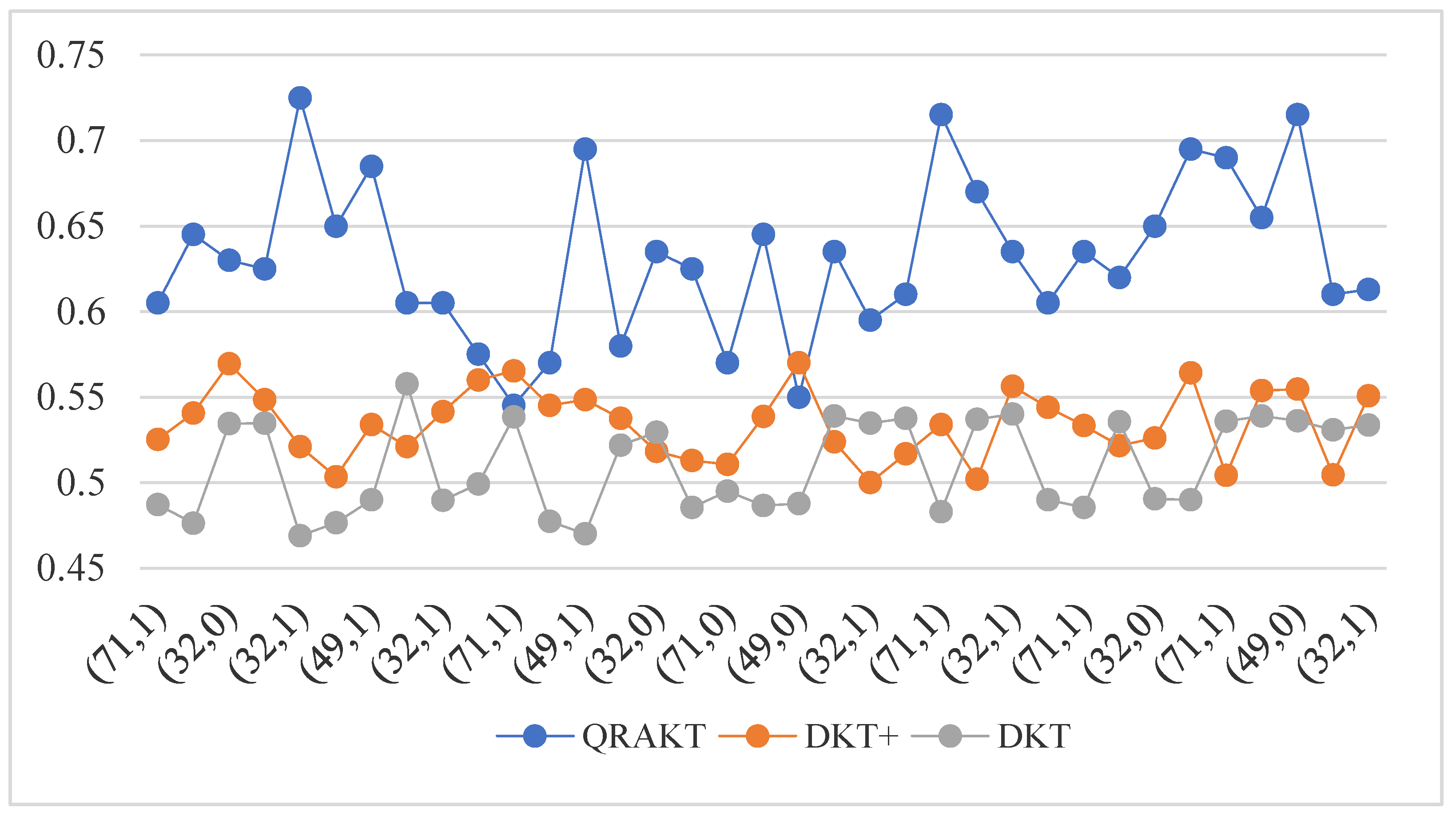
Figure 9.
The comparison of the knowledge tracing result for Skill 49 based on the calibrated Q-matrix relational attention knowledge tracing model (QRAKT), the DKT model, and the DKT+ model. The QRAKT model outperformed the other two models with around a 65% Accuracy on Skill 49. Compared with the performance of the QRAKT model, the DKT model and the DKT+ model performed poorly with around a 48% and a 53% Accuracy on Skill 49.
Figure 9.
The comparison of the knowledge tracing result for Skill 49 based on the calibrated Q-matrix relational attention knowledge tracing model (QRAKT), the DKT model, and the DKT+ model. The QRAKT model outperformed the other two models with around a 65% Accuracy on Skill 49. Compared with the performance of the QRAKT model, the DKT model and the DKT+ model performed poorly with around a 48% and a 53% Accuracy on Skill 49.
Table 1.
The important mathematical notations.
Table 1.
The important mathematical notations.
| Notations | Descriptions |
|---|
| n | The total number of exercises |
| d | The dimension of latent variables |
| s | ith interaction of a student |
| e | An exercise solved by a student |
| k | The maximum absolute value |
| k | The total number of knowledge concepts |
| RE | Exercise relation matrix |
| RF | Forget behavior matrix |
| RS | Slip and guess matrix |
| B | Exercise matrix |
| E | Exercise embedding matrix |
| S | Interaction sequence of a student |
| Q | The expert labeled Q-matrix |
| The calibrated Q-matrix |
| X | The input exercise sequence |
| Sta(K) | The Stability rate of the model: K |
Table 2.
The contingency table for exercise i and exercise j. This table is used to calculate the Phi coefficient between two exercises. In this contingency table, “F” means the student answers the exercise incorrectly and “T” means the student answers the exercise correctly.
Table 2.
The contingency table for exercise i and exercise j. This table is used to calculate the Phi coefficient between two exercises. In this contingency table, “F” means the student answers the exercise incorrectly and “T” means the student answers the exercise correctly.
| | exercise i |
|---|
| | | F | T | total |
| exercise j | F | n | n | n |
| | T | n | n | n |
| | total | n | n | n |
Table 3.
The statistics of ASSIST2012 and Eedi.
Table 3.
The statistics of ASSIST2012 and Eedi.
| Statistic | ASSIST2012 | Eedi |
|---|
| Number of records | 4,193,631 | 233,767 |
| Number of students | 39,364 | 2064 |
| Number of questions | 59,761 | 948 |
| Avg exercise record/student | 107 | 113 |
Table 4.
The framework setting for the relational attention knowledge tracing model and the calibrated Q-matrix relational attention knowledge tracing model.
Table 4.
The framework setting for the relational attention knowledge tracing model and the calibrated Q-matrix relational attention knowledge tracing model.
| | ASSIST2012 | Eedi |
|---|
| Attention embed size | 256 | 256 |
| Number of heads | 8 | 8 |
| Training batch size | 200 | 200 |
| Drop out rate | 1 × 10 | 1 × 10 |
| Threshold of exercise matrix | 0.8 | 0.8 |
| 1 | 1 |
Table 5.
Comparison of the results of the baseline models with the relational attention knowledge tracing model (RAKT) and the calibrated Q-matrix relational attention knowledge tracing model (QRAKT). The best model is boldfaced. The RAKT model performed better than the six baseline models, including the DKT model, the DKT+ model, the DKVMN model, and the SAKT model. The QRAKT model further improved the AUC and ACC to some extent compared to the RAKT model and had the best performance in terms of the AUC and ACC.
Table 5.
Comparison of the results of the baseline models with the relational attention knowledge tracing model (RAKT) and the calibrated Q-matrix relational attention knowledge tracing model (QRAKT). The best model is boldfaced. The RAKT model performed better than the six baseline models, including the DKT model, the DKT+ model, the DKVMN model, and the SAKT model. The QRAKT model further improved the AUC and ACC to some extent compared to the RAKT model and had the best performance in terms of the AUC and ACC.
| | ASSIST2012 | Eedi |
|---|
| | AUC | ACC | Sta | AUC | ACC | Sta |
| DKT | 0.712 | 0.679 | 0.125 | 0.489 | 0.489 | 0.125 |
| DKT+ | 0.722 | 0.685 | 0.257 | 0.584 | 0.566 | 0.358 |
| DKVMN | 0.701 | 0.686 | 0.255 | 0.698 | 0.640 | 0.683 |
| SAKT | 0.736 | 0.692 | 0.492 | 0.495 | 0.493 | 0.266 |
| EKT | 0.748 | 0.690 | 0.668 | 0.694 | 0.648 | 0.695 |
| EKPT | 0.752 | 0.693 | 0.706 | 0.698 | 0.651 | 0.704 |
| RAKT | 0.754 | 0.695 | 0.793 | 0.702 | 0.652 | 0.791 |
| QRAKT | 0.771 | 0.702 | 0.967 | 0.707 | 0.670 | 0.961 |
Table 6.
Comparison of the results when the positional attention layer (PA) is removed. The best model is boldfaced. After removing the PA, the AUC of the model on the two datasets decreased by about 1.8% and 19.2%.
Table 6.
Comparison of the results when the positional attention layer (PA) is removed. The best model is boldfaced. After removing the PA, the AUC of the model on the two datasets decreased by about 1.8% and 19.2%.
| | ASSIST2012 | Eedi |
|---|
| | AUC | ACC | AUC | ACC |
| PA | 0.753 | 0.689 | 0.515 | 0.541 |
| PA+CQ | 0.748 | 0.676 | 0.505 | 0.528 |
| PA+RM | 0.732 | 0.668 | 0.500 | 0.530 |
| PA+CQ+RM | 0.731 | 0.665 | 0.489 | 0.525 |
| QRAKT | 0.771 | 0.702 | 0.707 | 0.670 |
Table 7.
Comparison of the results when the calibrated Q-matrix (CQ) is removed. The best model is boldfaced. After removing the CQ, the AUC of the model on the two datasets decreased by about 1.7% and 2.6%.
Table 7.
Comparison of the results when the calibrated Q-matrix (CQ) is removed. The best model is boldfaced. After removing the CQ, the AUC of the model on the two datasets decreased by about 1.7% and 2.6%.
| | ASSIST2012 | Eedi |
|---|
| | AUC | ACC | AUC | ACC |
| CQ | 0.754 | 0.695 | 0.681 | 0.633 |
| PA+CQ | 0.748 | 0.676 | 0.505 | 0.528 |
| CQ+RM | 0.735 | 0.670 | 0.684 | 0.632 |
| PA+CQ+RM | 0.731 | 0.665 | 0.489 | 0.525 |
| QRAKT | 0.771 | 0.702 | 0.707 | 0.670 |
Table 8.
Comparison of the results when removing relation modeling (RM). The best model is boldfaced. After removing the RM, the AUC of the model on the two datasets decreased by approximately 3.1% and 2.3%.
Table 8.
Comparison of the results when removing relation modeling (RM). The best model is boldfaced. After removing the RM, the AUC of the model on the two datasets decreased by approximately 3.1% and 2.3%.
| | ASSIST2012 | Eedi |
|---|
| | AUC | ACC | AUC | ACC |
| RM | 0.740 | 0.678 | 0.684 | 0.637 |
| PA+RM | 0.732 | 0.668 | 0.500 | 0.530 |
| CQ+RM | 0.735 | 0.670 | 0.684 | 0.632 |
| PA+CQ+RM | 0.731 | 0.665 | 0.489 | 0.525 |
| QRAKT | 0.771 | 0.702 | 0.707 | 0.670 |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}