


An Attention-Based Method for Remaining Useful Life Prediction of Rotating Machinery

Abstract
1. Introduction
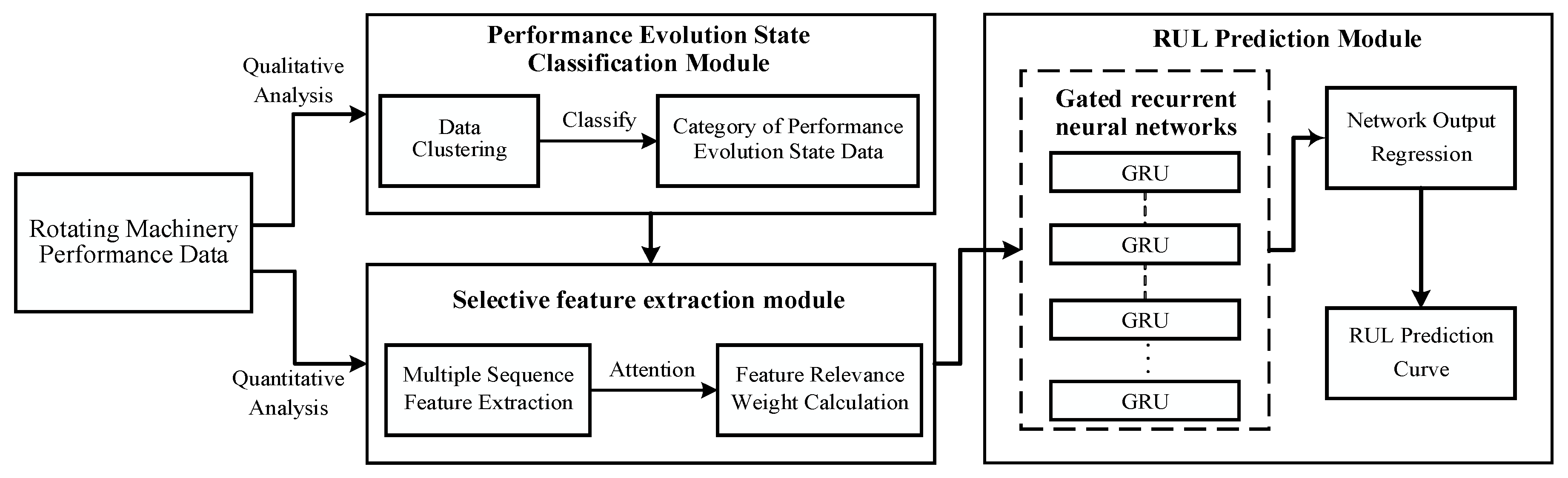
2. Attention-Based RUL Prediction of Rotating Machinery
2.1. Performance Evolution State Data Classification Based on Data Clustering
2.2. Attention-Based GRU for RUL Prediction
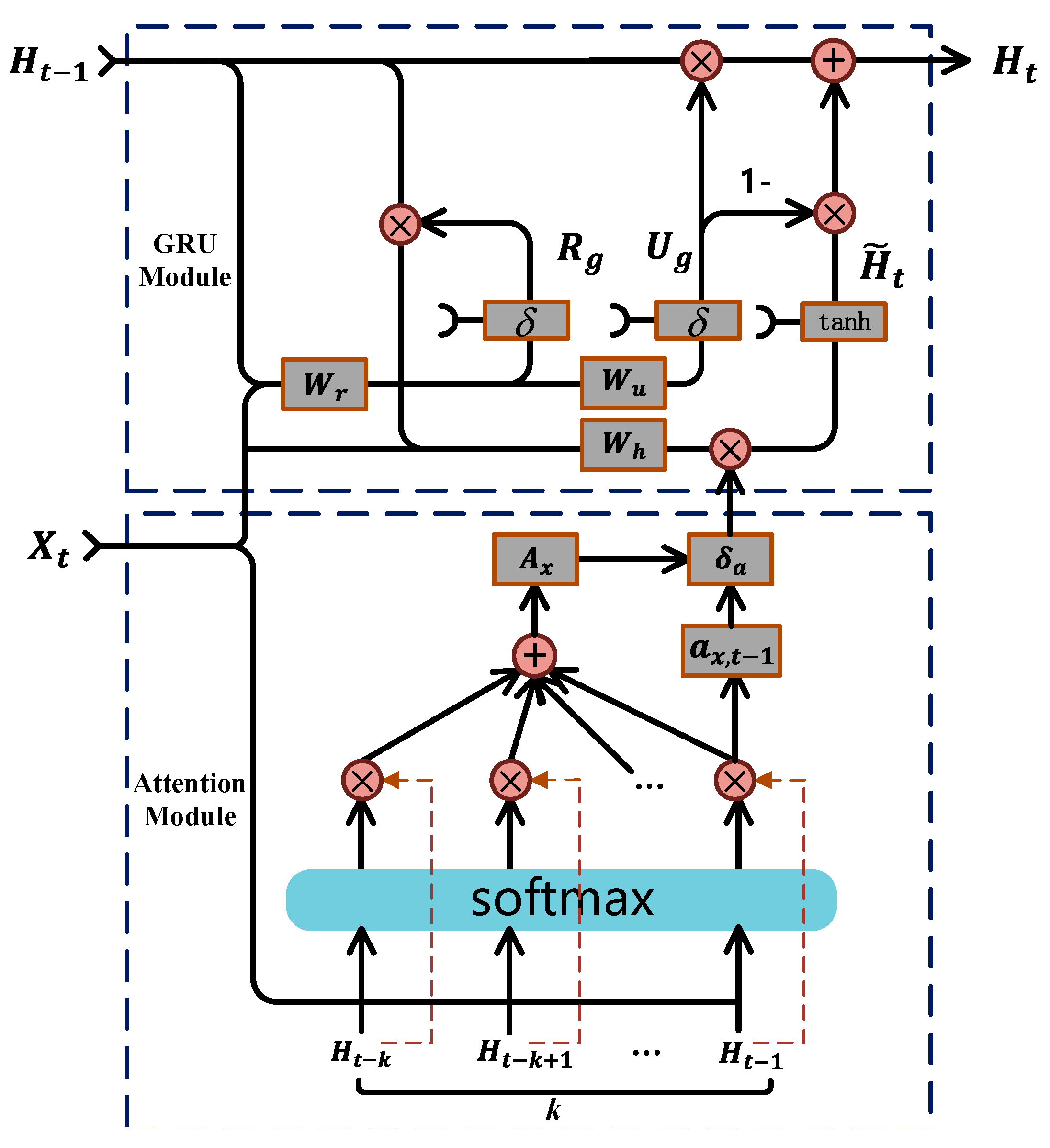
2.2.1. Working Principle of the Attention Mechanism in RNN
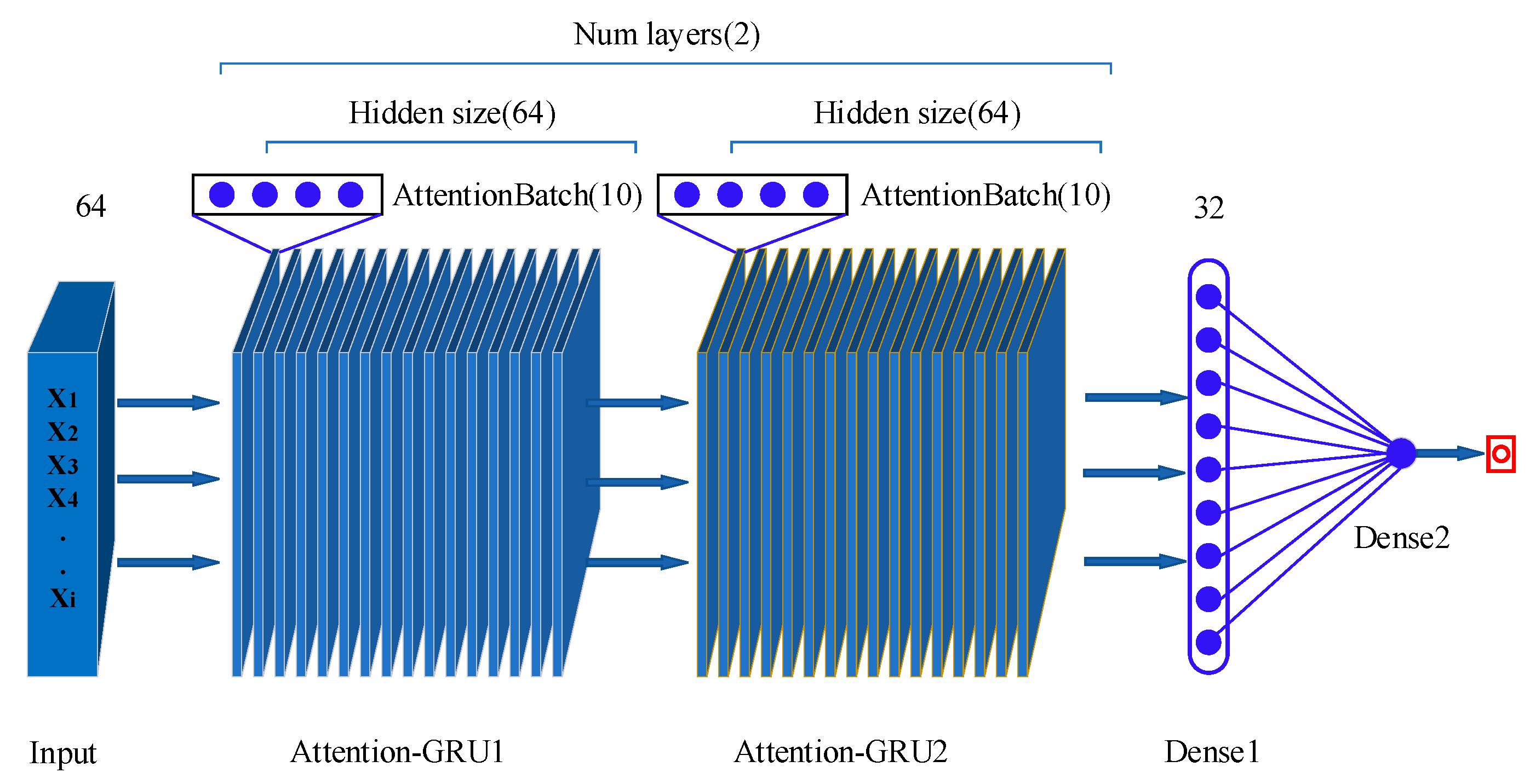
2.2.2. Attention-GRU Model for RUL Prediction
3. Model Verification and Comparison
3.1. Experiment Preparation
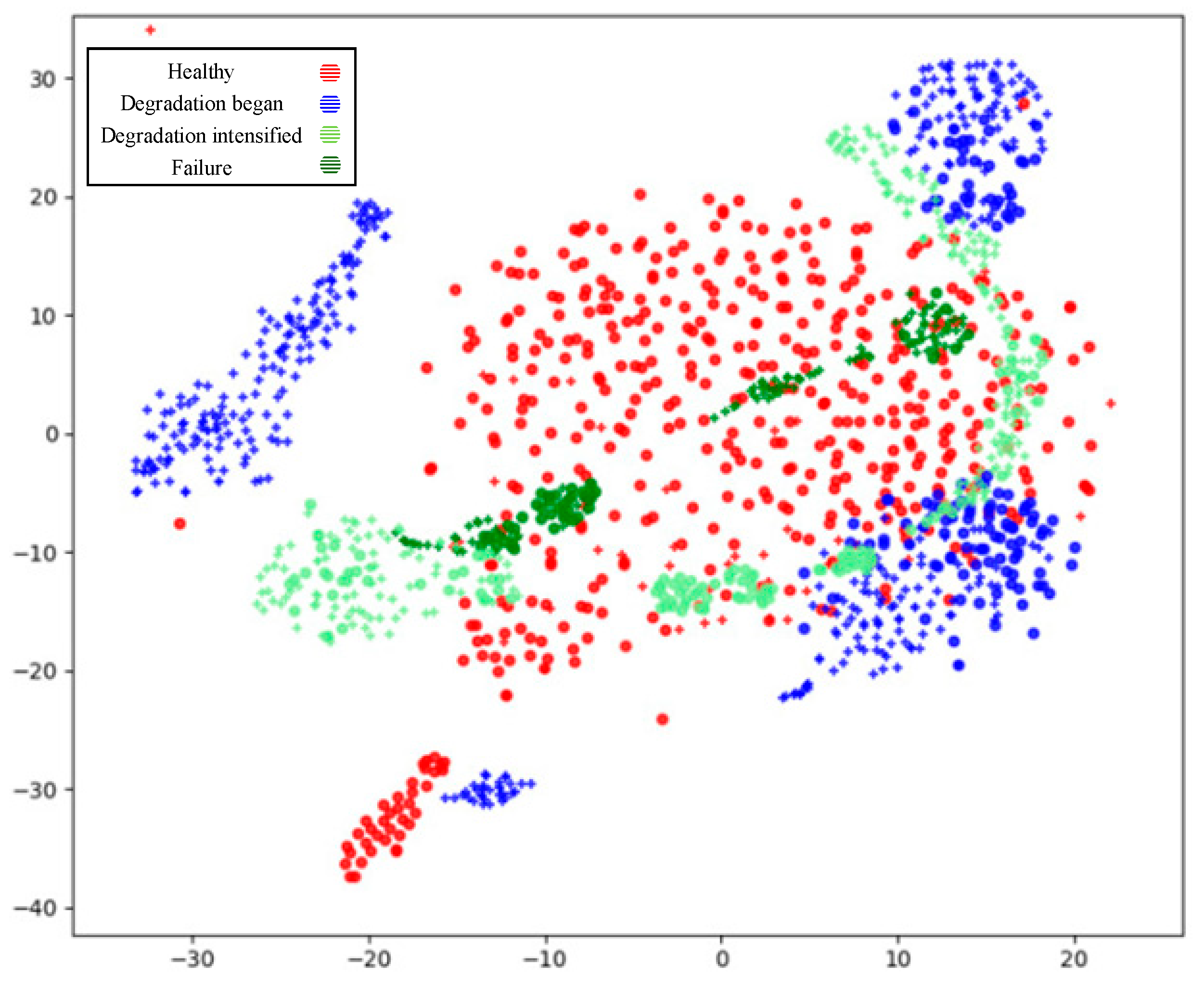
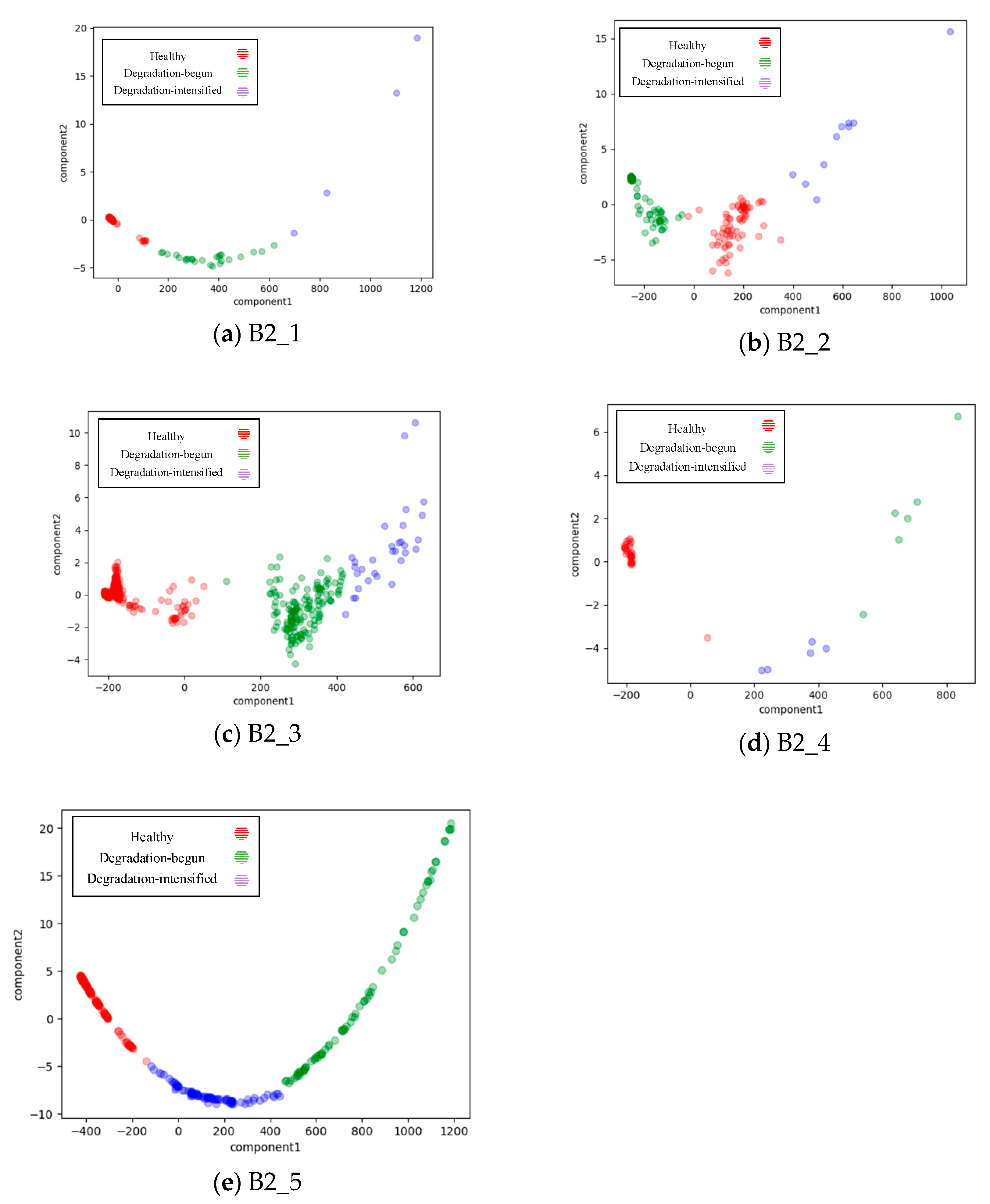
3.2. Experiment for Performance Evolution State Data Region Division
3.2.1. Dataset Configuration
3.2.2. Experimental Result
3.3. Prediction Experiments Using the Attention-GRU Model
3.3.1. Model Parameter Configuration
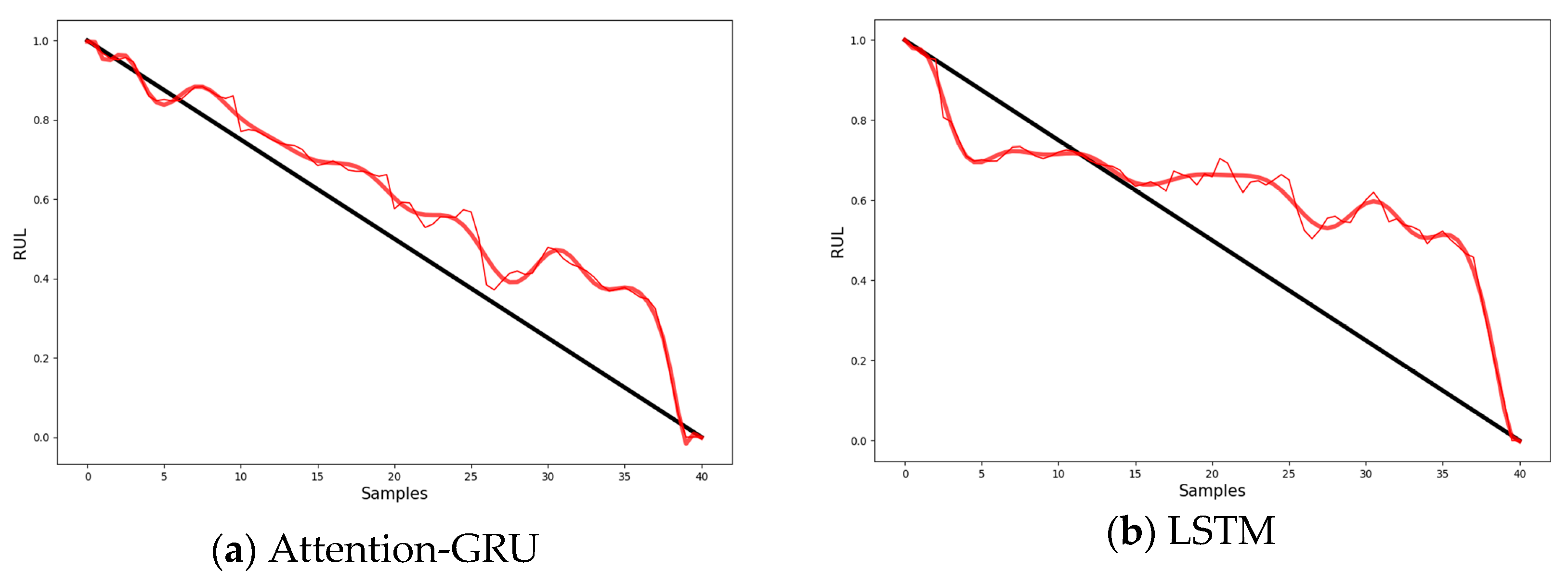
3.3.2. Analysis of Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Biebl, F.; Glawar, R.; Jalali, A.; Ansari, F.; Haslhofer, B.; de Boer, P.; Sihn, W. A Conceptual Model to Enable Prescriptive Maintenance for Etching Equipment in Semiconductor Manufacturing. Procedia CIRP 2020, 88, 64–69. [Google Scholar] [CrossRef]
- da Costa, P.R.D.O.; Akçay, A.; Zhang, Y.; Kaymak, U. Remaining useful lifetime prediction via deep domain adaptation. Reliab. Eng. Syst. Saf. 2020, 195, 106682. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Jia, X.D.; Ma, H.; Luo, Z.; Li, X. Machinery fault diagnosis with imbalanced data using deep generative adversarial networks. Measurement 2020, 152, 107377. [Google Scholar] [CrossRef]
- Ainapure, A.; Lia, X.; Singh, J.; Yang, Q.; Lee, J. Deep Learning-Based Cross-Machine Health Identification Method for Vacuum Pumps with Domain Adaptation. Procedia Manuf. 2020, 48, 1088–1093. [Google Scholar] [CrossRef]
- Chen, Z.; He, G.; Li, J.; Liao, Y.; Gryllias, K.; Li, W. Domain Adversarial Transfer Network for Cross-domain Fault Diagnosis of Rotary Machinery. IEEE Trans. Instrum. Meas. 2020, 11, 8702–8712. [Google Scholar] [CrossRef]
- Li, F.; Tang, T.; Tang, B.; He, Q. Deep Convolution Domain-adversarial Transfer Learning for Fault Diagnosis of Rolling Bearings. Measurement 2021, 169, 108339. [Google Scholar] [CrossRef]
- Jie, Z.; Wang, X.; Gong, Y. Gear fault diagnosis based on deep learning and subdomain adaptation. China Mech. Eng. 2021, 32, 8. [Google Scholar]
- Zhang, L.; Sun, L.; Yu, L.; Dong, X.; Chen, J.; Cai, W.; Wang, C.; Ning, X. ARFace: Attention-aware and regularization for face recognition with reinforcement learning. IEEE Trans. Biom. Behav. Identity Sci. 2021, 4, 30–42. [Google Scholar] [CrossRef]
- Cai, W.; Zhai, B.; Liu, Y.; Liu, R.; Ning, X. Quadratic polynomial guided fuzzy C-means and dual attention mechanism for medical image segmentation. Displays 2021, 70, 102106. [Google Scholar] [CrossRef]
- Ning, X.; Gong, K.; Li, W.; Zhang, L. JWSAA: Joint weak saliency and attention aware for person re-identification. Neurocomputing 2021, 453, 801–811. [Google Scholar] [CrossRef]
- Wu, C.; Sun, H.; Lin, S.; Gao, S. Remaining useful life prediction of bearings with different failure types based on multi-feature and deep convolution transfer learning. Eksploat. I Niezawodn. 2021, 23, 684–694. [Google Scholar] [CrossRef]
- Li, X.; Zhang, K.; Li, W.; Feng, Y.; Liu, R. A Two-Stage Transfer Regression Convolutional Neural Network for Bearing Remaining Useful Life Prediction. Machines 2022, 10, 369. [Google Scholar] [CrossRef]
- Miao, M.; Yu, J.; Zhao, Z. A sparse domain adaption network for remaining useful life prediction of rolling bearings under different working conditions. Reliab. Eng. Syst. Saf. 2022, 219, 108259. [Google Scholar] [CrossRef]
- Lu, H.; Barzegar, V.; Nemani, V.P.; Hu, C.; Laflamme, S.; Zimmerman, A.T. Joint training of a predictor network and a generative adversarial network for time series forecasting: A case study of bearing prognostics. Expert Syst. Appl. 2022, 203, 117415. [Google Scholar] [CrossRef]
- Cai, W.; Ning, X.; Zhou, G.; Bai, X.; Jiang, Y.; Li, W.; Qian, P. A Novel Hyperspectral Image Classification Model Using Bole Convolution with Three-Directions Attention Mechanism: Small sample and Unbalanced Learning. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–17. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Alian, H.; Konforty, S.; Ben-Simon, U.; Klein, R.; Tur, M.; Bortman, J. Bearing fault detection and fault size estimation using fiber-optic sensors. Mech. Syst. Signal Process. 2019, 120, 392–407. [Google Scholar] [CrossRef]
- Al-Tameemi, H.A.; Long, H. Finite element simulation of subsurface initiated damage from non-metallic inclusions in gearbox bearings. Int. J. Fatigue 2020, 131, 105347. [Google Scholar] [CrossRef]
- LI, H.; Zou, Y.; Zeng, D.; Liu, Y.; Zhao, S.; Song, X. A new method of bearing life prediction based on feature clustering and evaluation. J. Vib. Shock. 2022, 41, 141–150. [Google Scholar]
- Lin, T.; Wang, H.; Guo, X.; Wang, P.; Song, L. A novel prediction network for remaining useful life of rotating machinery. Int. J. Adv. Manuf. Technol. 2022, 11, 1–10. [Google Scholar] [CrossRef]
- Mao, W.; Feng, W.; Liu, Y.; Zhang, D.; Liang, X. A new deep auto-encoder method with fusing discriminant information for bearing fault diagnosis. Mech. Syst. Signal Process. 2021, 150, 107233. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.P.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, Denver, CO, USA, 18 June 2012. [Google Scholar]
- Lei, Y.; Wang, B. XJTU-SY Bearing Datasets. J. Mech. Eng. 2019, 55, 1. [Google Scholar]
- Guo, C.; Deng, Y.; Zhang, C.; Deng, C. Remaining Useful Life Prediction of Bearing Based on Autoencoder-LSTM. In Proceedings of the International Conference on Mechanical Engineering, Measurement Control, and Instrumentation (MEMCI 2021), Guangzhou, China, 18 July 2021. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | RUL Information | Fault Types | Test Sets |
|---|---|---|---|
| CWRU | Null | 15 | 60 |
| Paderborn | Available | 2 | 32 |
| IMS | Available | 3 | 3 |
| FEMTO-ST | Available | Unlabeled | 14 |
| XJTU-SY | Available | 4 | 15 |
| No. of working conditions | 1 | 2 | 3 |
| Rotational speed (r/min) | 2100 | 2250 | 2400 |
| Radial force/KN | 12 | 11 | 10 |
| Working Condition | Dataset | Sum of Samples | L10 | Actual Useful Life | Position of Faults |
|---|---|---|---|---|---|
| 2 | B2_1 | 491 | 8 h11 min | Inner ring | |
| B2_2 | 161 | 2 h41 min | Outer ring | ||
| B2_3 | 533 | 6.789~11.726 h | 8 h53 min | Bearing cage | |
| B2_4 | 42 | 42 min | Outer ring | ||
| B2_5 | 339 | 5 h39 min | Outer ring |
| Parameter | Optimizer | Attention-GRU | Dense | Batch Size | Epoch | ||||
|---|---|---|---|---|---|---|---|---|---|
| Input Size | Hidden Size | Num Layers | Attention Batch | Dense1 | Dense2 | ||||
| Parameter/class | Adam | 64 | 64 | 2 | 10 | 32 | 1 | 32 | 30 |
| Bearing Group | B2_1 | B2_2 | B2_3 | B2_4 | B2_5 |
|---|---|---|---|---|---|
| Attention-GRU | 0.092 | 0.167 | 0.316 | 0.174 | 0.253 |
| GRU | 0.156 | 0.305 | 0.524 | 0.279 | 0.348 |
| Bearing Group | Attention-GRU | LSTM |
|---|---|---|
| B2_1 | 0.092 | 0.286 |
| B2_2 | 0.167 | 0.227 |
| B2_3 | 0.316 | 0.374 |
| B2_4 | 0.174 | 0.216 |
| B2_5 | 0.253 | 0.342 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Y.; Guo, C.; Zhang, Z.; Zou, L.; Liu, X.; Lin, S. An Attention-Based Method for Remaining Useful Life Prediction of Rotating Machinery. Appl. Sci. 2023, 13, 2622. https://doi.org/10.3390/app13042622
Deng Y, Guo C, Zhang Z, Zou L, Liu X, Lin S. An Attention-Based Method for Remaining Useful Life Prediction of Rotating Machinery. Applied Sciences. 2023; 13(4):2622. https://doi.org/10.3390/app13042622
Chicago/Turabian StyleDeng, Yaohua, Chengwang Guo, Zilin Zhang, Linfeng Zou, Xiali Liu, and Shengyu Lin. 2023. "An Attention-Based Method for Remaining Useful Life Prediction of Rotating Machinery" Applied Sciences 13, no. 4: 2622. https://doi.org/10.3390/app13042622
APA StyleDeng, Y., Guo, C., Zhang, Z., Zou, L., Liu, X., & Lin, S. (2023). An Attention-Based Method for Remaining Useful Life Prediction of Rotating Machinery. Applied Sciences, 13(4), 2622. https://doi.org/10.3390/app13042622