A gated recurrent unit (GRU) is a variant of an RNN. Conventional RNNs suffer from the problems of exponential explosion of weights and vanishing gradients and cannot capture long-term relations in the time sequence. However, GRU provides a solution to these problems by introducing gates. Moreover, compared with LSTM, GRU has fewer parameters and is therefore easier to train [
21]. One weakness of GRU is that it cannot calculate similarity weights between input vectors and network hidden states. If the attention mechanism is introduced to GRU, the model is can discriminate features, assign different weights to them, and extract additional important information. In this way, the model can produce more accurate results without increasing the computing overhead or memory load of the model.
2.2.1. Working Principle of the Attention Mechanism in RNN
When introduced to an RNN, the attention mechanism calculates the similarity weight between the input vectors and network hidden states.
Figure 4 shows how the attention mechanism works in an RNN; the state is assumed to be comprised of a series of two tuples
.
When the current input sequence is
, the
-th state is expressed as
. There are
hidden states calculated by the RNN; by calculating the similarity or relevance between the input,
, and hidden state,
, we can obtain the weight coefficient of
corresponding to
, namely the relevance weight of the hidden state to
. Then, the weighted sum between the relevance weight and
is calculated to obtain the similarity value between
and the
hidden states. Operations of the similarity value and
are performed to adjust the model outputs. The dot product is used as the similarity calculation function, and the expected attention value in the attention mechanism is obtained by Equation (4), where
is the similarity calculation function:
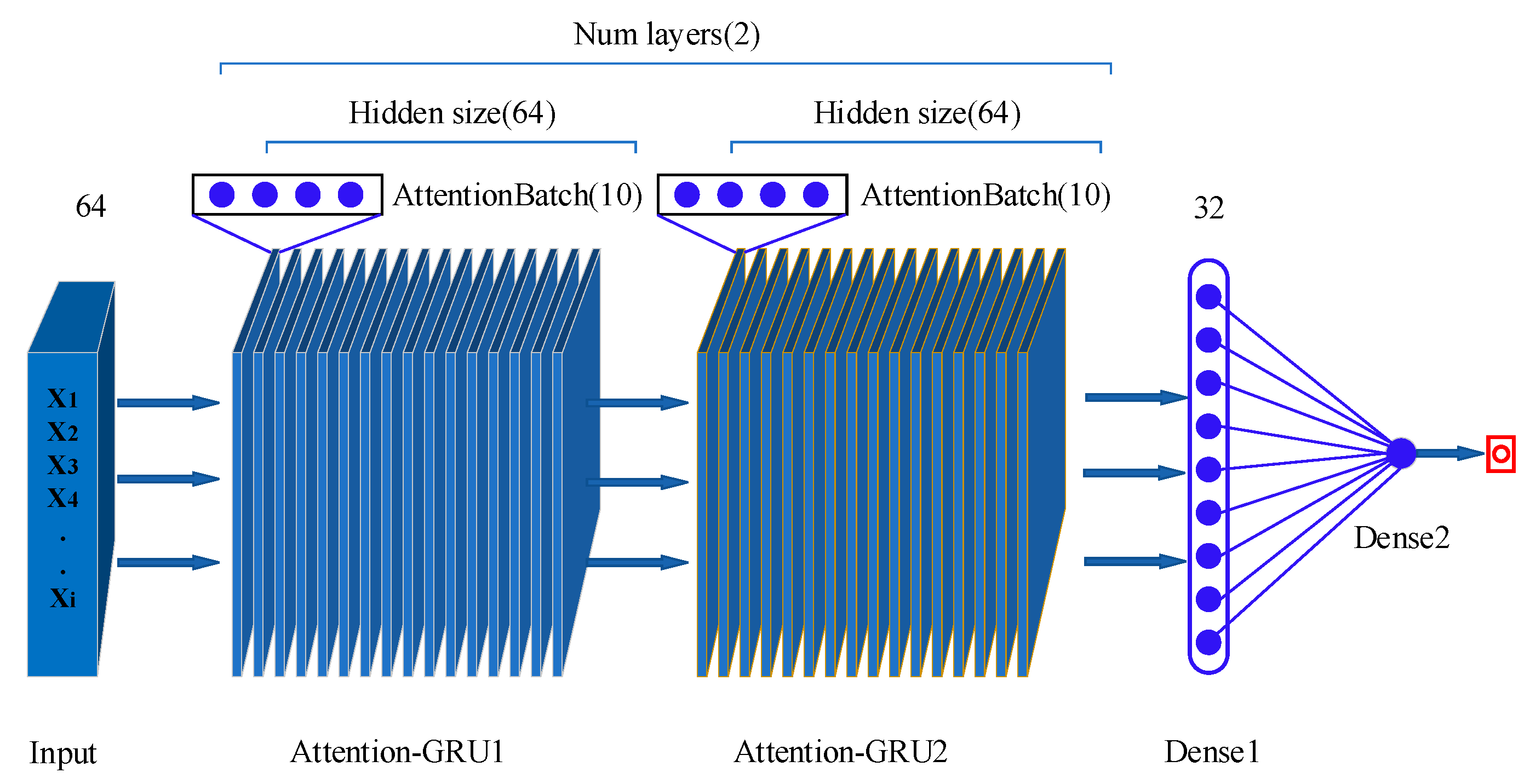
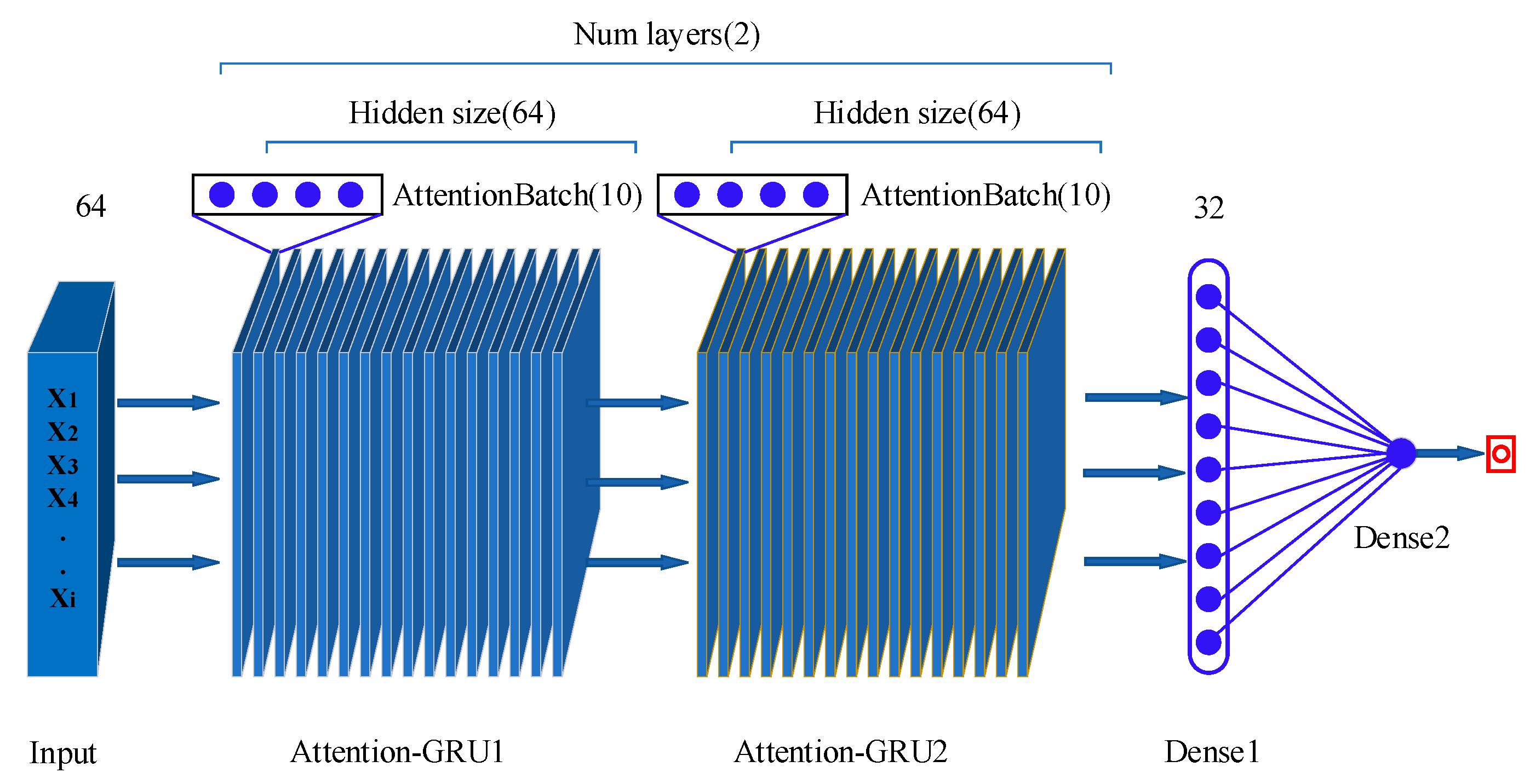
2.2.2. Attention-GRU Model for RUL Prediction
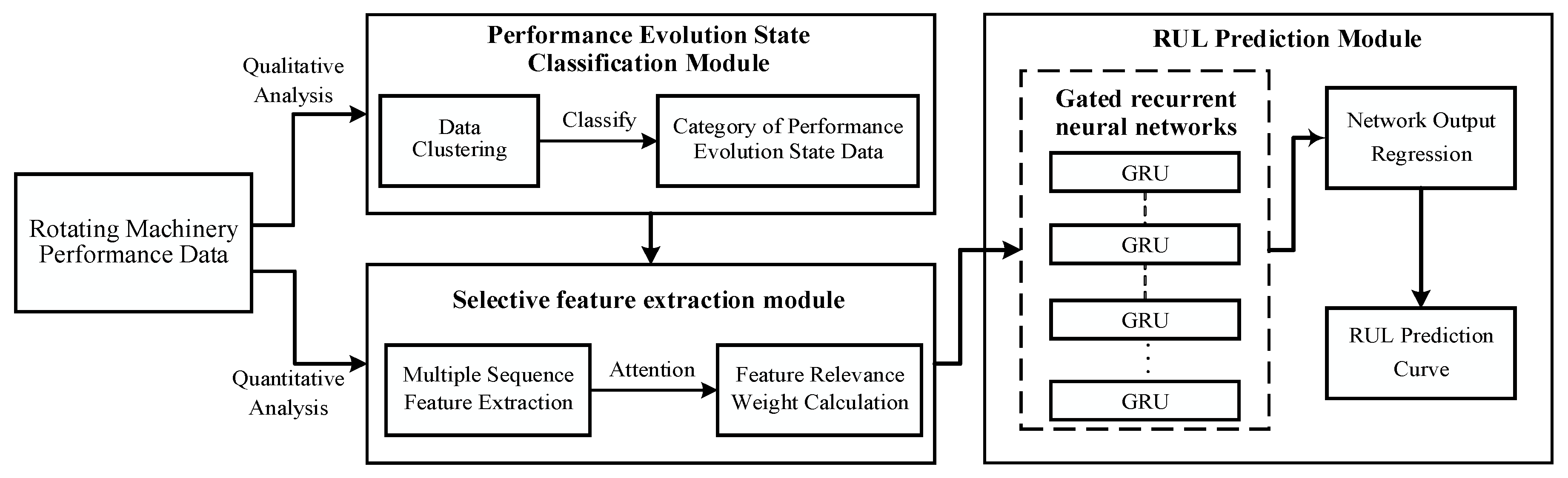
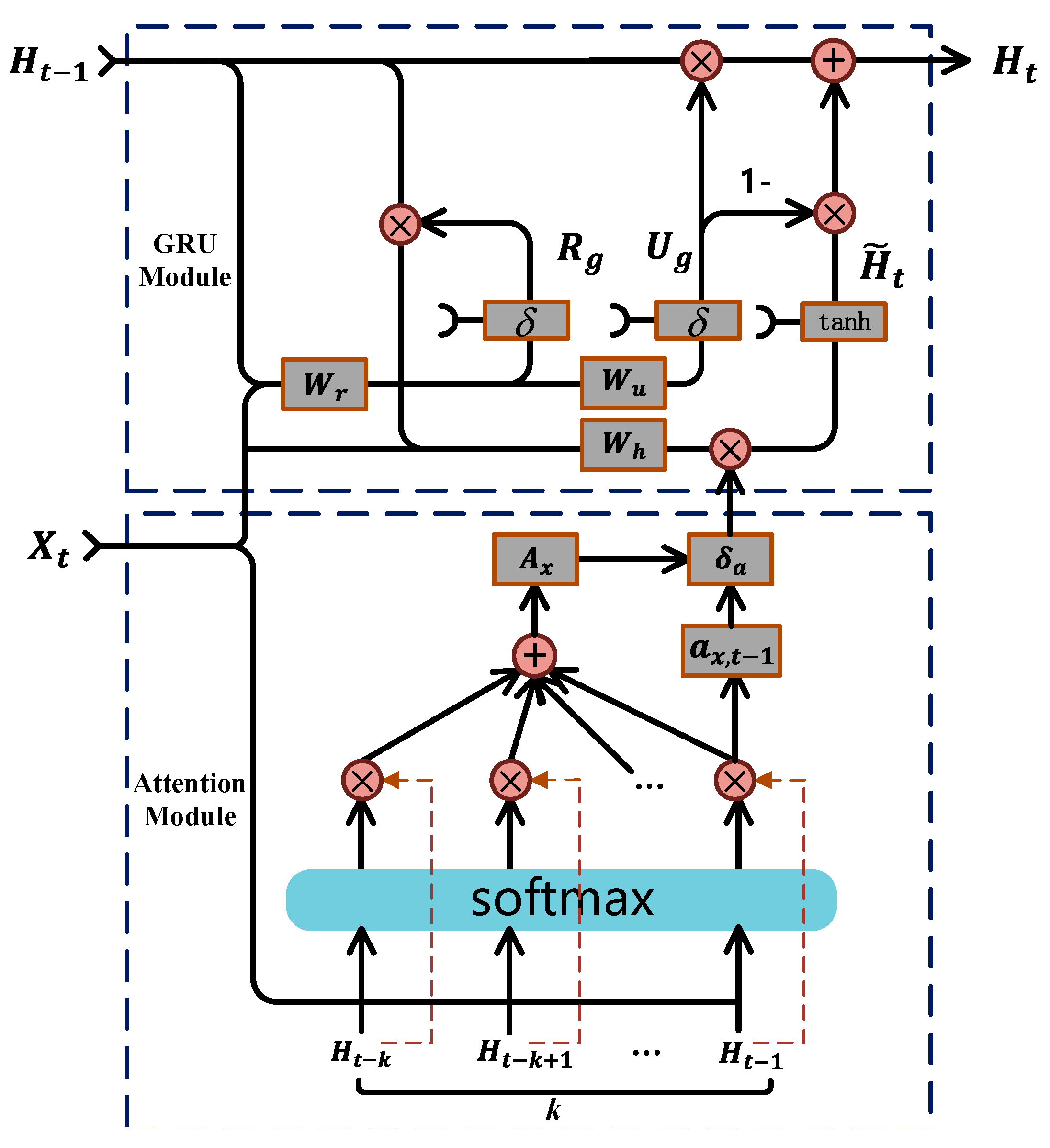
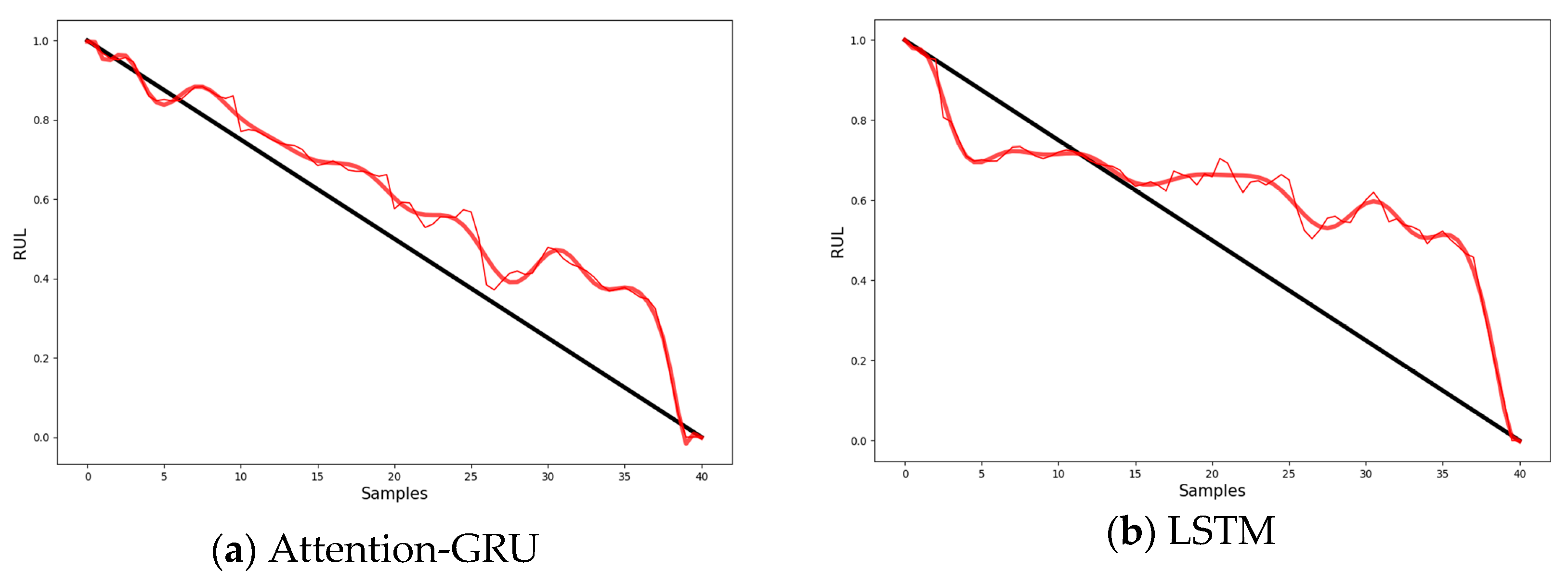
The RUL prediction attention-GRU model consists of two modules: a GRU module and an attention module. The GRU module learns and analyzes the sequence trends and intrinsic relationships of data; it can independently determine whether to retain or discard a feature and is mainly used for predictive calculations. The attention module is used for similarity weights (
Figure 5). The attention mechanism gives a larger weight to the part of attention than to the less relevant parts to obtain more effective information. Therefore, adding an attention layer to the GRU model can increase the contribution of important features to the prediction.
(1) As shown in
Figure 5, in contrast to traditional RNNs, the GRU module has only a reset gate (
) and an update gate (
);
is the current input feature; the final output state of the module is the weighted sum of the previous state (
) and the candidate state (
). The reset gate
processes the previous state (
); it receives the current input feature and the previous state and performs a linear calculation. Then, the sigmoid function is employed for normalization. The value range of the reset gate is between 0 and 1; a larger value indicates a higher proportion of the previous state in the candidate state. The value of the reset gate determines the importance degree of the previous state and the current input feature in the candidate state (
).
Let
be the sigmoid function;
be the hyperbolic tangent function;
,
, and
be the network weights, where
is the network weight of the reset gate,
is the weight of the update gate, and
is the network weight of candidate output (
);
and
be the weight parameters of
;
and
be the weight parameters of
; and
and
be the weight parameters of
, as shown in Equation (5):
Let
and
be the bias; then, the reset gate and the candidate state can be calculated by Equations (6) and (7), respectively:
The update gate (
) assigns weights to the input features and the previous state to update the output state (
). The calculation of the update gate resembles that of the reset gate. The update gate also determines the candidate output (
) and the impact of the previous output on the final output (
). The calculation of the update gate and the final estimation state (
) is shown in Equations (8) and (9), respectively:
(2) In the attention module, the current input feature () is considered the inquiry vector (), the groups of previous states () are considered the value vector (), and per se is considered the key vector () for the similarity calculation. The attention calculation involves three parts: first, the dot product of and is calculated to obtain the weight coefficient; then, Softmax is employed to normalize the weight coefficients; finally, the adjusted weight coefficients are used to perform weighted summation of .
The specific calculations are as follows:
represents the normalized weight coefficient, and
represents the weighted sum (
is an important indicator of the relevance between the input feature (
) and the k groups of previous states). A larger
indicates a higher similarity between
and the k sets of previous states, whereas a smaller
indicates the opposite.
is the similarity weight between the
-th hidden state (
) and the input (
).
,
, and
can be calculated by Equations (10)–(12), respectively:
To improve the stability of prediction and reduce the impact of abnormal previous data, the calculation method for the candidate state (
) in the GRU is improved. The correlation coefficient between the current input feature (
) and the next state (
) is marked as
, and the attention factor (
) is introduced to Equation (7) to obtain the improved calculation equation for the candidate state (
), as shown in Equation (13):
Where the attention factor (
) can be calculated by Equation (14):
As Equation (14) shows, when , the current input feature shares high similarity with the previous state, and the change trend is normal and requires no adjustment; when , the current input has more similarity to the state of a prior period of time than to the previous state, which means that the previous state may be an anomaly, and it is necessary to reduce its weight in the calculation of candidate states.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}